目录
- [1. 距离字典两次编辑以内的单词](#1. 距离字典两次编辑以内的单词)
- [2. 分隔链表](#2. 分隔链表)
- [3. 不同的二叉搜索树](#3. 不同的二叉搜索树)
1. 距离字典两次编辑以内的单词
给你两个字符串数组 queries 和 dictionary 。数组中所有单词都只包含小写英文字母,且长度都相同。
一次 编辑 中,你可以从 queries 中选择一个单词,将任意一个字母修改成任何其他字母。从 queries 中找到所有满足以下条件的字符串:不超过 两次编辑内,字符串与 dictionary 中某个字符串相同。
请你返回 queries 中的单词列表,这些单词距离 dictionary 中的单词 编辑次数 不超过 两次 。单词返回的顺序需要与 queries 中原本顺序相同。
示例 1:
输入:queries = "word","note","ants","wood", dictionary = "wood","joke","moat"
输出:"word","note","wood"
解释:
- 将 "word" 中的 'r' 换成 'o' ,得到 dictionary 中的单词 "wood" 。
- 将 "note" 中的 'n' 换成 'j' 且将 't' 换成 'k' ,得到 "joke" 。
- "ants" 需要超过 2 次编辑才能得到 dictionary 中的单词。
- "wood" 不需要修改(0 次编辑),就得到 dictionary 中相同的单词。
所以我们返回 "word","note","wood" 。
示例 2:
输入:queries = "yes", dictionary = "not"
输出:\[\]
解释:
"yes" 需要超过 2 次编辑才能得到 "not" 。
所以我们返回空数组。
思路1
暴力搜索,将每个queries里的单词与dictionary里的单词进行比较,统计不同字符的次数,超过两次直接退出,加速判断
java
class Solution {
public List<String> twoEditWords(String[] queries, String[] dictionary) {
List<String> ans = new ArrayList<>();
int m = queries.length,n=dictionary.length;
for(int i=0;i<m;i++){
if(compareTwo(queries[i],dictionary)){
ans.add(queries[i]);
}
}
return ans;
}
private boolean compareTwo(String word1,String[] dictionary){
int n = word1.length();
for(int i=0;i<dictionary.length;i++){
int edit = 0;
for(int j=0;j<n&&edit<=2;j++){
if(word1.charAt(j)!=dictionary[i].charAt(j)){
edit++;
}
}
if(edit<=2){
return true;
}
}
return false;
}
}时间复杂度: O ( n q d ) O(nqd) O(nqd) n 字典数组长度,q queries中单词长度,d 字典中单词长度
空间复杂度: O ( 1 ) O(1) O(1)
思路2
字典树,将dictionary中的每个单词加入字典树中,然后查询queries中的每个单词
java
class Solution {
static class TrieNode {
TrieNode[] child = new TrieNode[26];
//是否叶子节点
boolean isEnd = false;
}
TrieNode root = new TrieNode();
void insert(String word){
TrieNode node = root;
for(char c:word.toCharArray()){
int idx = c - 'a';
if(node.child[idx]==null){
node.child[idx] = new TrieNode();
}
node = node.child[idx];
}
node.isEnd = true;
}
boolean dfs(String word, int i, TrieNode node,int cnt){
if(cnt>2||node==null){
return false;
}
if(i==word.length()){
return node.isEnd;
}
int idx = word.charAt(i)-'a';
//不修改
if(node.child[idx] != null){
if(dfs(word,i+1,node.child[idx],cnt)){
return true;
}
}
if(cnt<2){
for(int c=0;c<26;c++){
if(c == idx){
continue;
}
if(node.child[c] != null){
if(dfs(word,i+1,node.child[c],cnt+1)){
return true;
}
}
}
}
return false;
}
public List<String> twoEditWords(String[] queries, String[] dictionary) {
for(String w:dictionary){
insert(w);
}
List<String> ans = new ArrayList<>();
for(String q:queries){
if(dfs(q,0,root,0)){
ans.add(q);
}
}
return ans;
}
}时间复杂度: O ( k ∗ n + q ⋅ n 2 ∗ 25 2 ) O(k*n+q⋅n^2*25^2) O(k∗n+q⋅n2∗252)
空间复杂度: O ( d n ) O(dn) O(dn) 字典树存储空间, d d d表示字典中单词长度, n n n表示单词长度
2. 分隔链表
给你一个链表的头节点 h e a d head head和一个特定值 x x x,请你对链表进行分隔,使得所有小于 x x x的节点都出现在大于或等于 x x x的节点之前。
你应当保留两个分区中每个节点的初始相对位置。
示例 1 : 示例 1: 示例1:
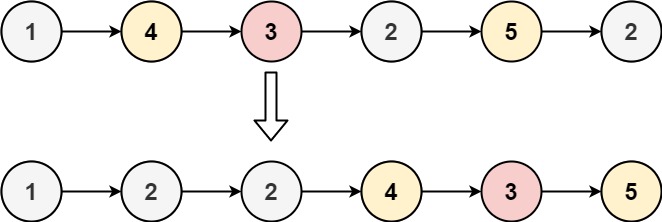
输入:head = 1,4,3,2,5,2, x = 3
输出:1,2,2,4,3,5
示例2:
输入:head = 2,1, x = 2
输出:1,2
思路
将单链表拆解成两个链表, l 1 l1 l1, l 2 l2 l2, l 1 l1 l1表示小于 x x x的链表, l 2 l2 l2表示大于等于 x x x的链表,针对当前节点,若大于等于 x x x,则放入 l 2 l2 l2,否则放入 l 1 l1 l1
java
class Solution {
public ListNode partition(ListNode head, int x) {
ListNode h1 = new ListNode(-1), h2 = new ListNode(-1), t1 = h1, t2 = h2;
ListNode curNode = head;
while(curNode!=null){
if(curNode.val<x){
t1.next = curNode;
t1 = t1.next;
}else{
t2.next = curNode;
t2 = t2.next;
}
curNode = curNode.next;
}
t1.next = h2.next;
t2.next = null;
return h1.next;
}
}时间复杂度: O ( n ) O(n) O(n) n为链表长度
空间复杂度: O ( 1 ) O(1) O(1)
3. 不同的二叉搜索树
给你一个整数 n ,求恰由n个节点组成且节点值从1到n互不相同的二叉搜索树有多少种?返回满足题意的二叉搜索树的种数。
示例 1:
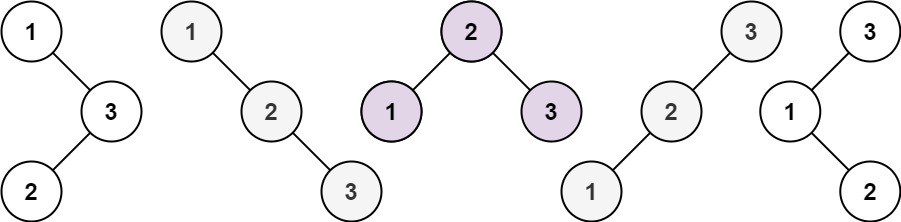
输入:n = 3
输出:5
示例 2:
输入:n = 1
输出:1
思路
动态规划,思路很简单
以10为例,10个节点的树中,可以分为1,2,3,...,10为根节点这10种情况
以5作为根节点为例,则节点1-4在左侧,节点6-10在右侧,现在不考虑具体数字
左边是4个节点,4个点可以构成的子树设为f(4),右边有5个节点,5个节点可以构成的子树为f(5),则以5为根节点的十个节点构成的树的个数为f(4)*f(5)。取dpn表示n个节点构成不同树的个数,则dp10=dp0∗dp9+dp1∗dp8+dp2∗dp7+...+d8∗dp1+dp9∗dp0
解释一下,这里dp0=1,表示空树,dp9表示9个节点的树个数
dp0*dp9表示根节点为1,左子树为空树,右子树有9个节点
dp1*dp8表示根节点为2,左子树有1个节点,右子树有8个节点
...
dp8*dp1表示根节点为9,左子树有8个节点,右子树一个节点
dp9*dp0表示根节点为10,左子树有9个节点,右子树为空树
java
class Solution {
public int numTrees(int n) {
int[] dp = new int[n+1];
dp[0] = 1;//空树算一种情况
for(int i=1;i<=n;i++){
for(int j=0;j<i;j++){
dp[i] += dp[j]*dp[i-j-1];
}
}
return dp[n];
}
}时间复杂度: O ( n 2 ) O(n^2) O(n2)
空间复杂度: O ( 1 ) O(1) O(1)