目录
[一、谱减法类可处理噪声(适合:采样降噪 / 频谱降噪)](#一、谱减法类可处理噪声(适合:采样降噪 / 频谱降噪))
[二、滤波类可处理噪声(适合:频段切除 / 陷波 / 高低切)](#二、滤波类可处理噪声(适合:频段切除 / 陷波 / 高低切))
[三、瞬态脉冲类噪声(适合:瞬态修复 / 插值消瑕)](#三、瞬态脉冲类噪声(适合:瞬态修复 / 插值消瑕))
[四、空间混响类噪声(适合:去混响 / 房间矫正)](#四、空间混响类噪声(适合:去混响 / 房间矫正))
[六、非稳态复杂环境噪声(适合:AI 智能降噪)](#六、非稳态复杂环境噪声(适合:AI 智能降噪))
[七、机械摩擦 / 近场杂讯(适合:专用模块降噪)](#七、机械摩擦 / 近场杂讯(适合:专用模块降噪))
[1. 窗口长度](#1. 窗口长度)
[2. 步长/重叠比例](#2. 步长/重叠比例)
[3. 谱减法系数 α](#3. 谱减法系数 α)
要求:
- 通过信号处理及频谱分析,从信号中提取电话号码信息;
- 对信号进行处理,尽可能还原出其中的音乐信号。
涉及到的理论------
(1)频谱的概念;
(2)滤波及信号处理;
(3)DTMF电话号码编码的原理;
(4)信号分离、频谱分析、编码转换等概念。
观察信号结构
音频信号------sdtmf(-5dB).wav
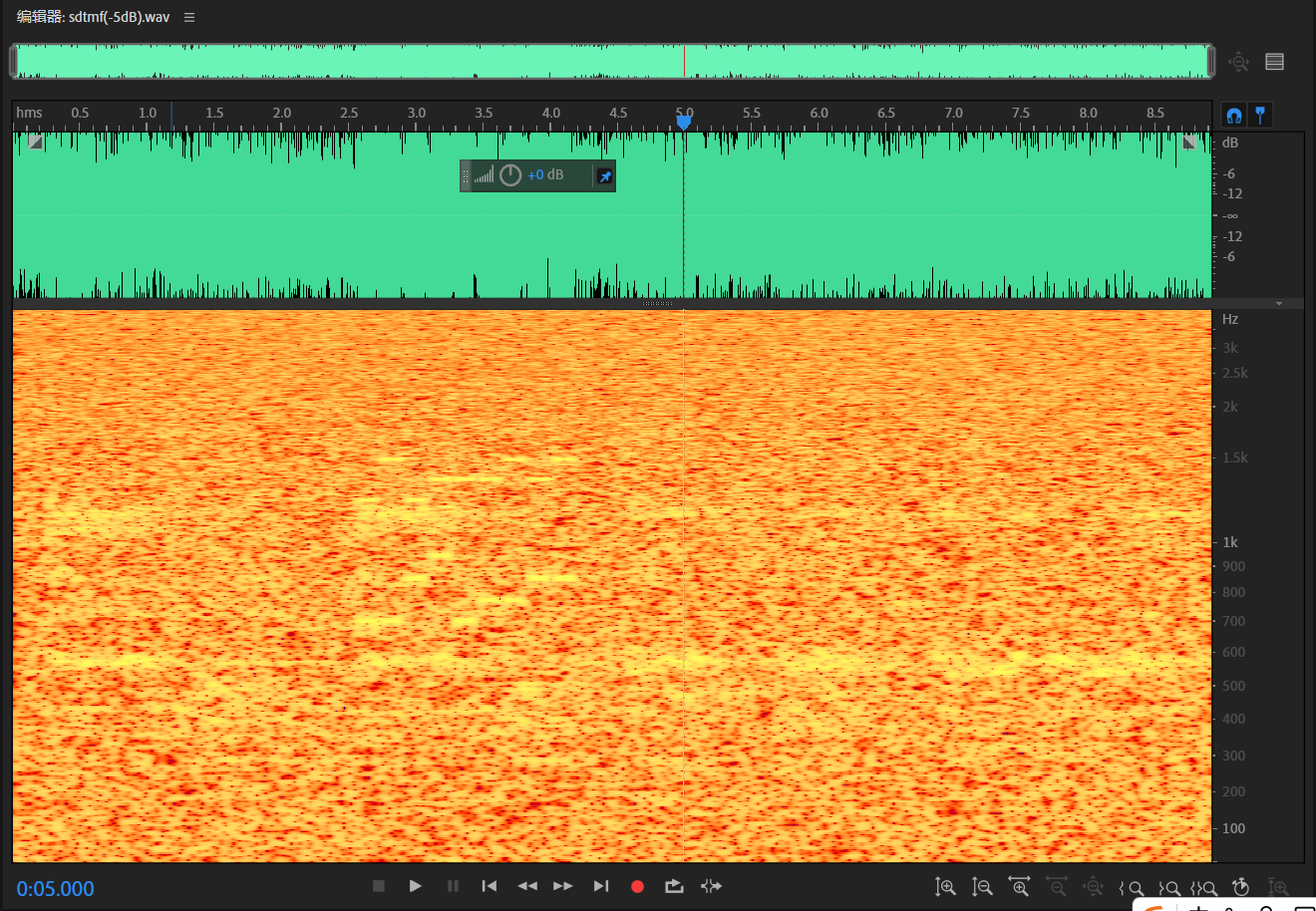
看到这个电平爆炸的音频属实被震惊到了。
为什么名不副实地加一个-5dB,这分明就是0dB,而且已经削波失真了好吧......
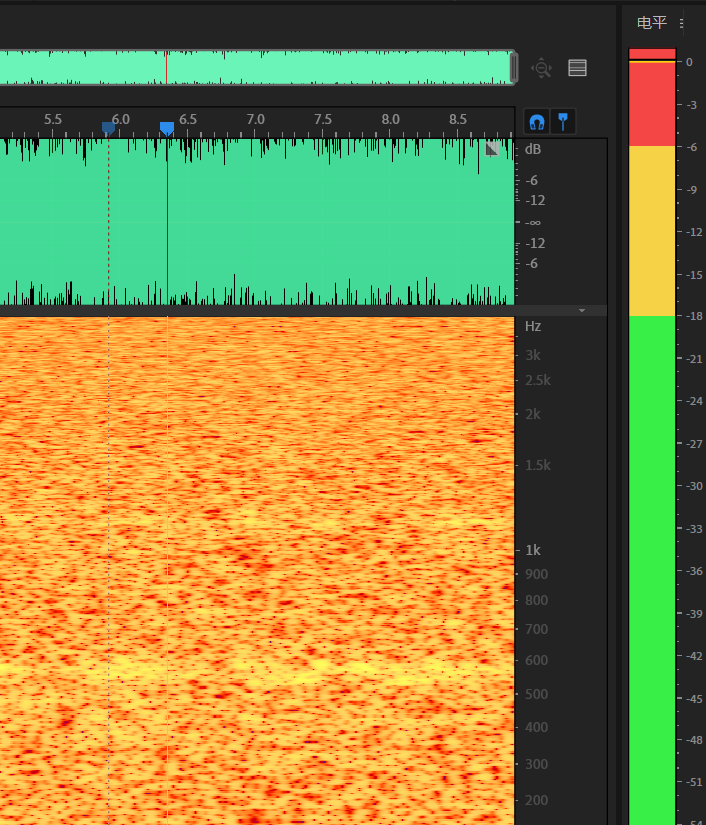 红得封顶的电平
红得封顶的电平
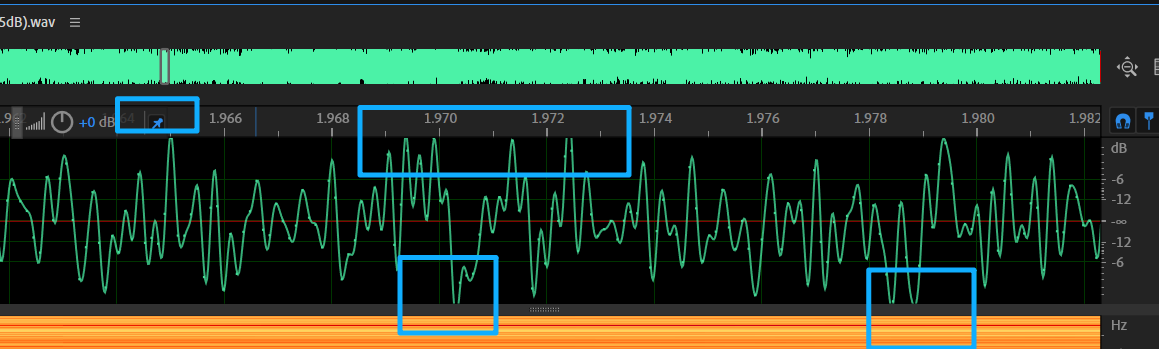 昭然若揭的削波失真
昭然若揭的削波失真
音频信号为带噪声的音乐与电话拨号音(DTMF编码),或者不如说噪音里面顺带夹杂了音乐和拨号。
科普一下------
DTMF(Dual Tone Multi-Frequency)拨号音是一种用于电话系统中发送拨号信号的技术,广泛应用于现代通信中。使用两个不同频率的音调组合来表示数字和符号。每个按键对应一个高频和一个低频信号的组合,形成特定的音调。例如,数字"1"对应697 Hz和1209 Hz的组合信号。DTMF信号通常用于拨打电话号码、自动语音应答系统和其他交互式服务中。
DTMF取代了早期脉冲拨号,拨号更快、抗干扰强 ;每个按键同时叠加两个不同频率的正弦音(低频组 + 高频组),组合唯一,交换机靠这组频率识别按键。
DTMF频率对照表
| 按键 | 低频 (Hz) | 高频 (Hz) |
|---|---|---|
| 1 | 697 | 1209 |
| 2 | 697 | 1336 |
| 3 | 697 | 1477 |
| 4 | 770 | 1209 |
| 5 | 770 | 1336 |
| 6 | 770 | 1477 |
| 7 | 852 | 1209 |
| 8 | 852 | 1336 |
| 9 | 852 | 1477 |
| * | 941 | 1209 |
| 0 | 941 | 1336 |
| # | 941 | 1477 |
这个表格不是很方便读,站内有前辈已经做好------
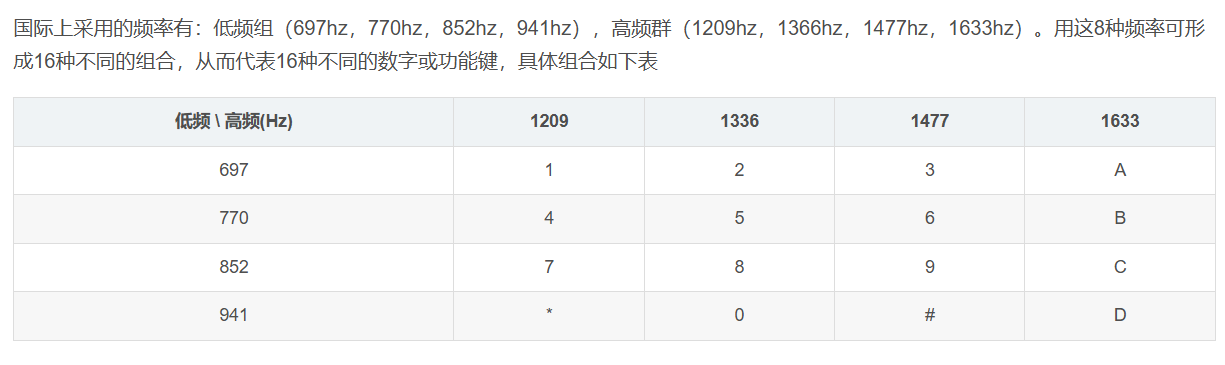 图源: Android 拨号音之 DTMF_android dtmf-CSDN博客
图源: Android 拨号音之 DTMF_android dtmf-CSDN博客
截取信号
音频的持续时间为8.924s,采样率为8192Hz(根据奈奎斯特采样定理,这个采样率下,可完整还原、无混叠的最高有效频率 = 采样率 ÷ 2即4096Hz,可以覆盖人声和DTMF所有频率)
用Adobe Audition看这些信息比较方便,matlab应该也有专门的函数来读取绘制,但是扒谱机我比较懒就不去做了。
为了方便分析,用音量旋钮把分贝压下一点------
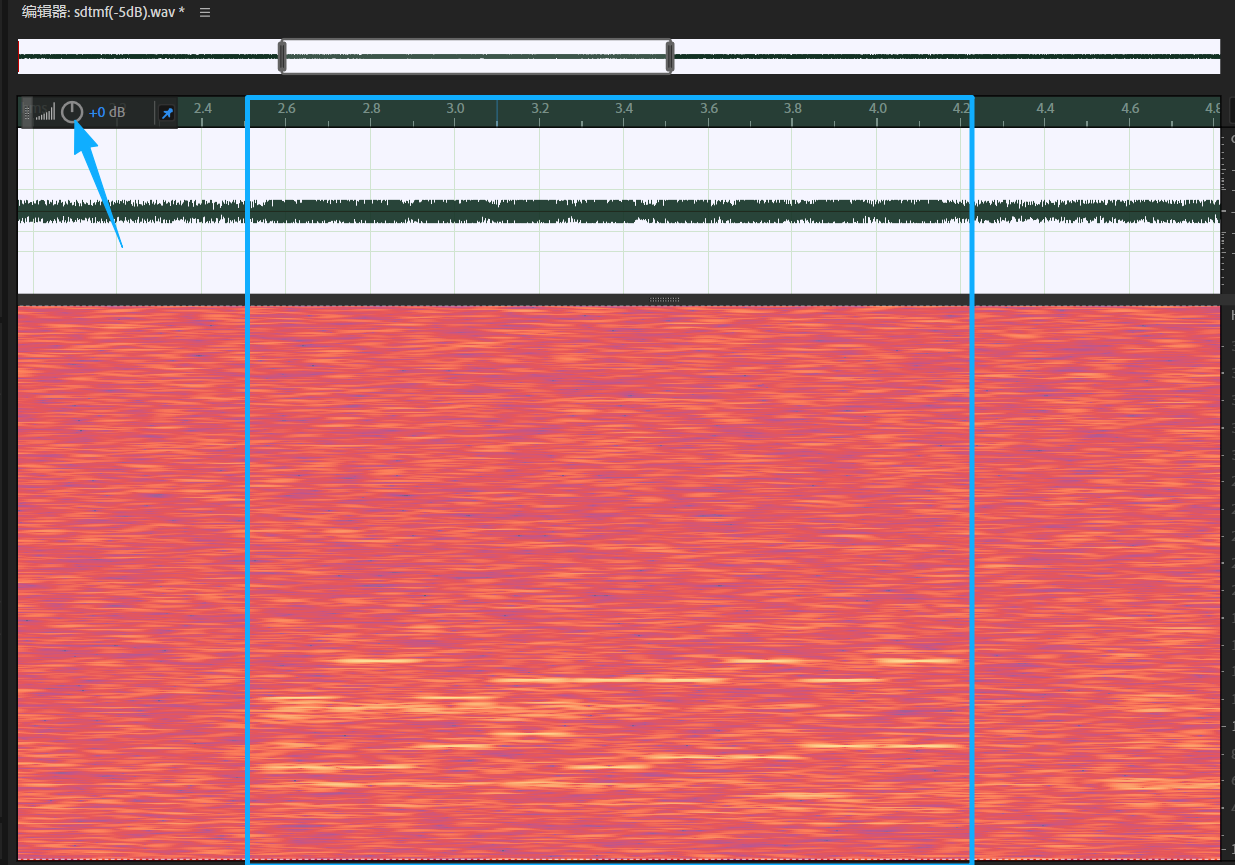
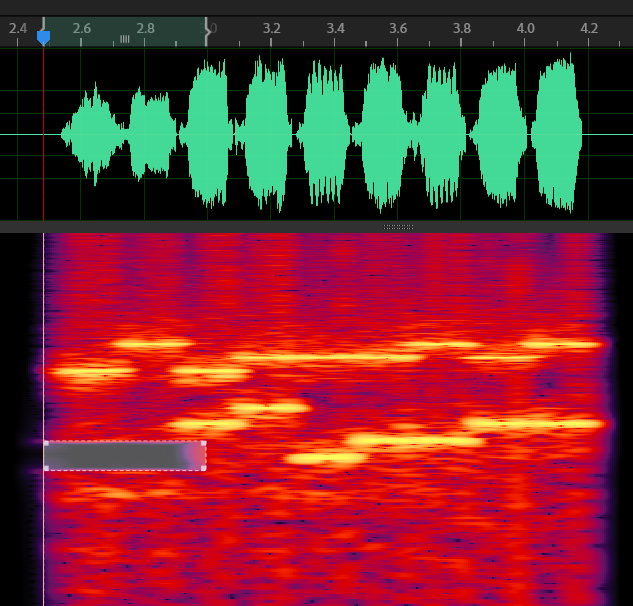
可以看到语谱图上有很明显的九个 拨号音,在2.5s-4.2s的范围内,每个拨号音的持续时间大致相等,所以特意把这些截取出来,分成九份来识别。
具体判断哪里是拨号音、有几个拨号音,这些内容软件识别会比较麻烦,人工设定好可以极大程度地降低任务量,提升成功率。
电话提取
非常好,又到了激动人心的和AI斗智斗勇环节,提示词------------
写matlab脚本(注意函数要定义在脚本文件最后)读取文件sdtmf(-5dB).wav 对应范围内的音频然后生成九个频谱图,每个频谱图取两个频率峰值,然后和DTMF拨号音进行比对判断最后得出最终答案,并输出。
Matlab
%% DTMF 拨号音识别脚本 - 9段自动识别(无警告无报错)
clear; clc; close all;
%% 1. 音频读取
filename = 'sdtmf(-5dB).wav';
[audio, fs] = audioread(filename);
totalTime = (0:length(audio)-1)/fs;
%% 2. 截取 2.5s ~ 4.2s
startTime = 2.5;
endTime = 4.2;
startIdx = find(totalTime >= startTime, 1);
endIdx = find(totalTime <= endTime, 1, 'last');
targetAudio = audio(startIdx:endIdx);
segmentLen = floor(length(targetAudio) / 9); %平均分成九份
%% 3. DTMF 标准频率
dtmfLowFreq = [697, 770, 852, 941];
dtmfHighFreq = [1209, 1336, 1477];
dtmfKeys = {
'1','2','3';
'4','5','6';
'7','8','9';
'*','0','#'
};% 这里只是电话号码,就不考虑ABCD的情况了,降低代码复杂度和识别难度
resultDigits = {};
%% 4. 处理9段并画图
figure('Position', [100,100,1200,800]);
for k = 1:9
segStart = (k-1)*segmentLen + 1;
segEnd = k*segmentLen;
segAudio = targetAudio(segStart:segEnd);
[f, P1] = calcSpectrum(segAudio, fs);
[peak1, peak2] = getTwoPeaks(f, P1);
key = matchDTMF(peak1, peak2, dtmfLowFreq, dtmfHighFreq, dtmfKeys);
resultDigits{end+1} = key;
subplot(3,3,k);
plot(f, P1, 'LineWidth',1.2);
xlim([0 2000]); grid on;
title(sprintf('第%d个 | %.0f & %.0f Hz | %s',k,peak1,peak2,key));
xlabel('Hz'); ylabel('幅度');
end
sgtitle('9段DTMF拨号音频谱图','FontSize',14);
%% 输出结果
fprintf('\n========================================\n');
fprintf(' 最终DTMF拨号识别结果:%s\n', strjoin(resultDigits));
fprintf('========================================\n\n');
%% 1. 频谱计算
function [f, P1] = calcSpectrum(x, fs)
L = length(x);
N = floor(L/2); % 强制整数避免报错
Y = fft(x);
P2 = abs(Y/L);
P1 = P2(1:N+1);
P1(2:end-1) = 2*P1(2:end-1);
f = fs*(0:N)/L;
end
%% 2. 提取两个最高的峰值(完全兼容)
function [p1, p2] = getTwoPeaks(f, P1)
validIdx = f >= 500 & f <= 1800;
fValid = f(validIdx);
PValid = P1(validIdx);
[~, max1Idx] = max(PValid);
p1 = fValid(max1Idx);
mask = true(size(fValid));
mask(max(1,max1Idx-10):min(length(mask),max1Idx+10)) = false;
fMasked = fValid(mask);
PMasked = PValid(mask);
[~, max2Idx] = max(PMasked);
p2 = fMasked(max2Idx);
if p1 > p2
temp = p1; p1 = p2; p2 = temp;
end
end
%% 3. DTMF 匹配
function key = matchDTMF(p1, p2, lowFreq, highFreq, keys)
tol = 20;%容许的误差范围
isLow1 = any(abs(p1 - lowFreq) <= tol);
isLow2 = any(abs(p2 - lowFreq) <= tol);
if ~isLow1 && isLow2
fLow = p2; fHigh = p1;
elseif isLow1 && ~isLow2
fLow = p1; fHigh = p2;
else
key = '?';
return;
end
[~, row] = min(abs(fLow - lowFreq));
[~, col] = min(abs(fHigh - highFreq));
key = keys{row, col};
end行代码之后,命令行输出------
========================================
最终DTMF拨号识别结果:1 3 7 0 2 5 6 8 9
========================================
提取效果还是比较喜人的,这也说明以上工作,完全可以在降噪之前进行处理。
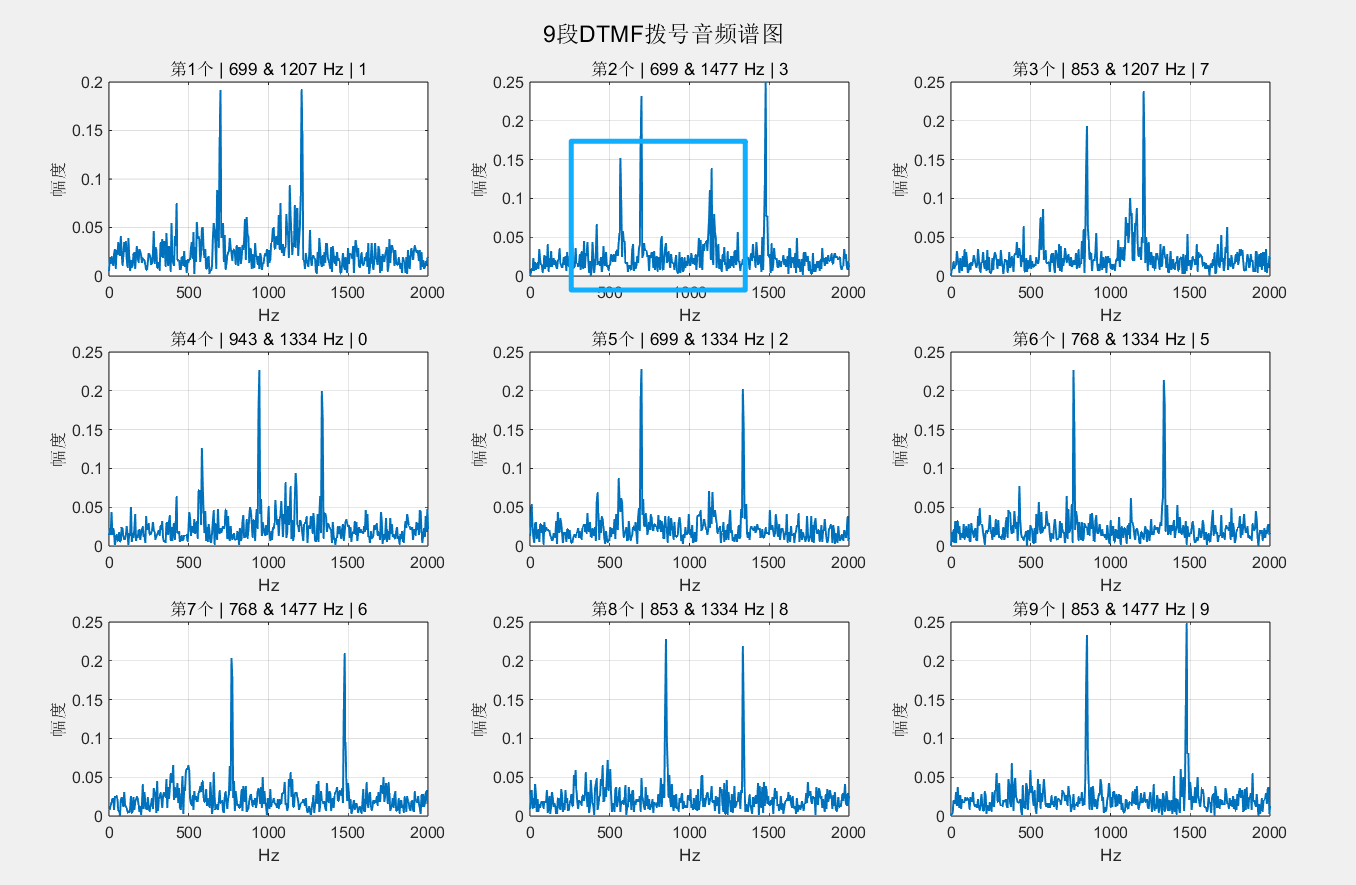
然而让我比较在意的,是第二个内容有比较大的噪音(蓝色框部分),希望弄清楚它的来源
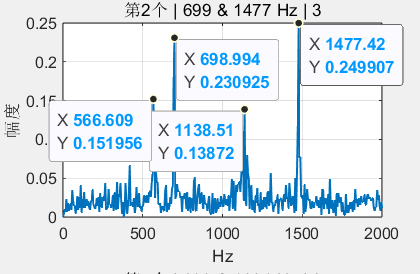
在matlab的图片显示窗口上点击峰值可以在对应点处显示坐标标签,可以看到这两个峰是566.6Hz 和1138.5Hz,并不在编码所对应的频率附近,说明并不是因为拨号时间不均等导致的其他号码串扰到第二个号码的时间区域内。
但是敏锐的扒谱机捕捉到,这两个峰,他们正好是二倍的关系。人的声带、弦乐、管乐等较为规则振动体发出的声音,基频和谐波的关系基本都满足这种特征 ,所以大概率是这个地方的乐器或者人声正好演奏了某个音。
具体是什么音,好奇宝宝来探究一下:
在标准十二平均律(A4=440Hz)下,C#5的精确计算频率约为554.37Hz ,D5约为587.33Hz。
566Hz恰好位于这两者之间(比C#5高约36音分,即约1/3个半音)
哈利路亚是D大调的,可能更接近这个调的7?
至于为什么有三分之一个半音的差距可能是由于调音差异(比如可能他们会用更高的标准音以追求弦乐的明亮音色)、当时的录音带转速误差等等。
光从这里分析,嘛用没有,还是要靠耳朵听。
这里唱的是一个"哈", 哈利路亚是D大调的,原则上应该是D。
在不信邪的扒谱机开始追根溯源,从下载的哈利路亚的高音质的音频中,找到了对应的8s------
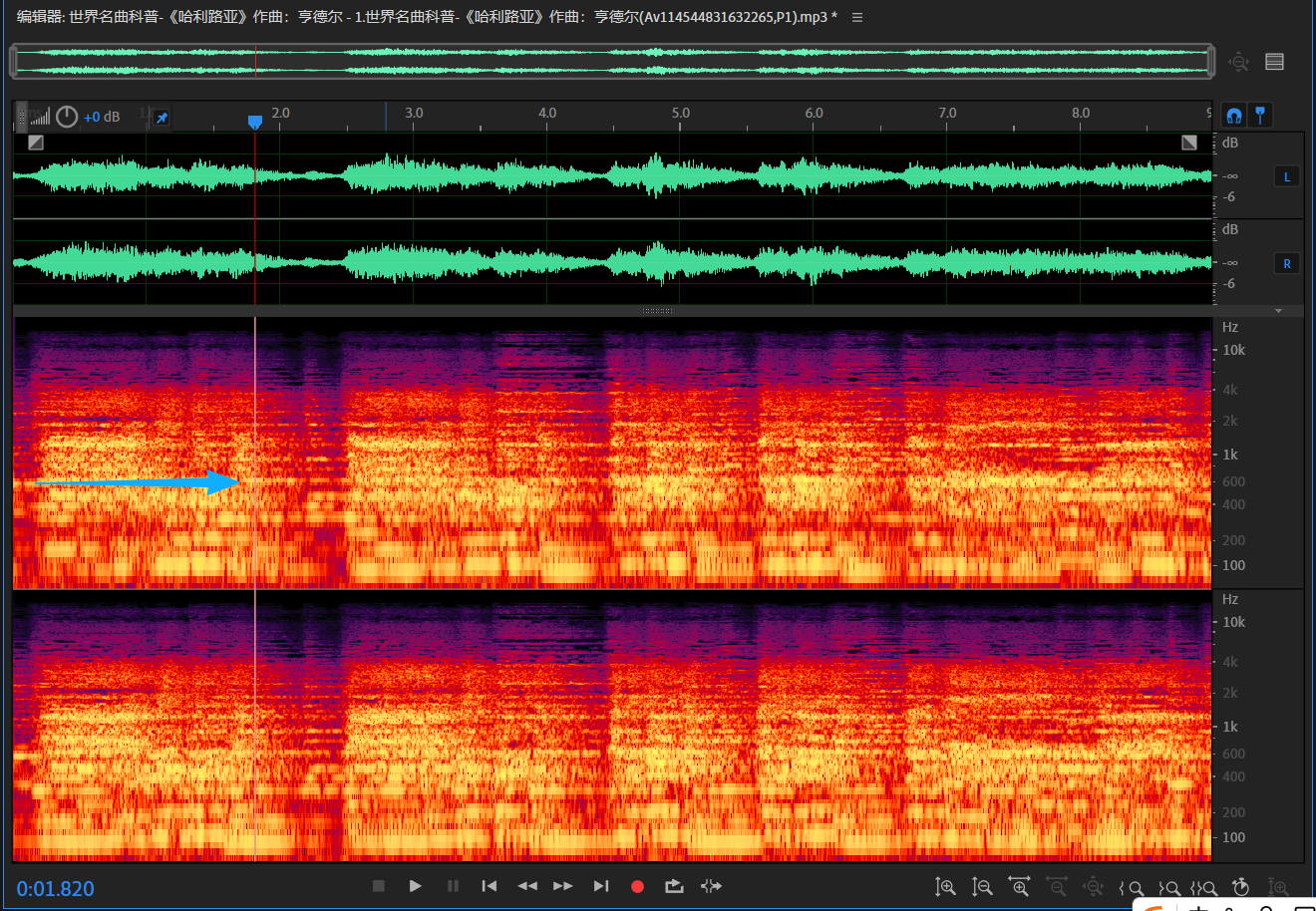 人声"哈"的主旋律为箭头所在的频率位置
人声"哈"的主旋律为箭头所在的频率位置
这才是D大调。对比两段音频,可以明显地发现噪声版哈利路亚整体低了接近一个半音,锁定录音带转速误差,或者其他采样率不同等差异导致的音频整体降调。
从这里其实也可以看出来DTMF的编码频率选择的精妙之处,Deepseek查阅资料后说------
DTMF的频率选择由贝尔实验室在1963年规定,核心是平衡三个工程约束:
一、抗人声干扰
人声的谐波可以轻松覆盖697Hz、770Hz等低频段,一个人说"啊"的时候,697Hz附近就有能量。如果采用单音检测,看到这个能量就会误判为"按下了1"。
DTMF改用"低频+高频"双音组合:必须同时检测到两个特定频率且能量相近才判为有效。数学上,两个独立事件同时发生的概率≈各自概率的乘积,误触发率从10\^{-3}量级降到10\^{-6}以下。
二、防谐波串扰
电话网络中的非线性器件(如变压器、放大器)会产生失真。当用户按下一个键,可能在其二次谐波处产生能量。如果低频697Hz配高频1394Hz(2倍关系),1394Hz恰好是另一个按键的高频组频率,交换机会误判。
因此贝尔实验室规定:任意两个频率不成整数倍关系。算一下1209/697≈1.734,1633/941≈1.735,都不是2、1.5或1.333,这样谐波不会落在其他有效频率的±1.5%容差窗口内。
三、适配检测速度
DTMF要求检测时间40-80ms。频率间隔决定了理论最小分辨时间:至少1/\\Delta f。如果间隔只有10Hz,就需要100ms以上,用户会觉得拨号反应慢。
贝尔实验室的设计是:低频组相邻间隔73-85Hz,高频组间隔128-141Hz。这个间隔足够让戈泽尔算法或FFT在40ms内可靠区分,正好平衡了检测速度和抗噪能力。同时所有频率落在300-3400Hz的话音频带内,避开工频干扰,能顺利通过电话网络。
这套标准后被ITU-T采纳为Q.23建议。
嗯,很有道理,又水了一段。
这里具体写一下识别提取电话的逻辑,也就是最后matchDTMF(p1, p2, lowFreq, highFreq, keys)这个函数逻辑------
- 给两个频率
- 自动区分哪个低、哪个高 并找到它们最接近的标准 DTMF 频率
- 查表格得到**按键数字,**返回结果。
然而当前该识别算法,是对单段纯净拨号信号做傅里叶变换,提取全局两个幅度最大值当作双音峰值来匹配,高度依赖人工先精准切分出每段拨号音的起止时刻。
一旦无法手动标定精准时间边界、音频存在连续混合信号或噪声干扰,这套逻辑就很容易失效。
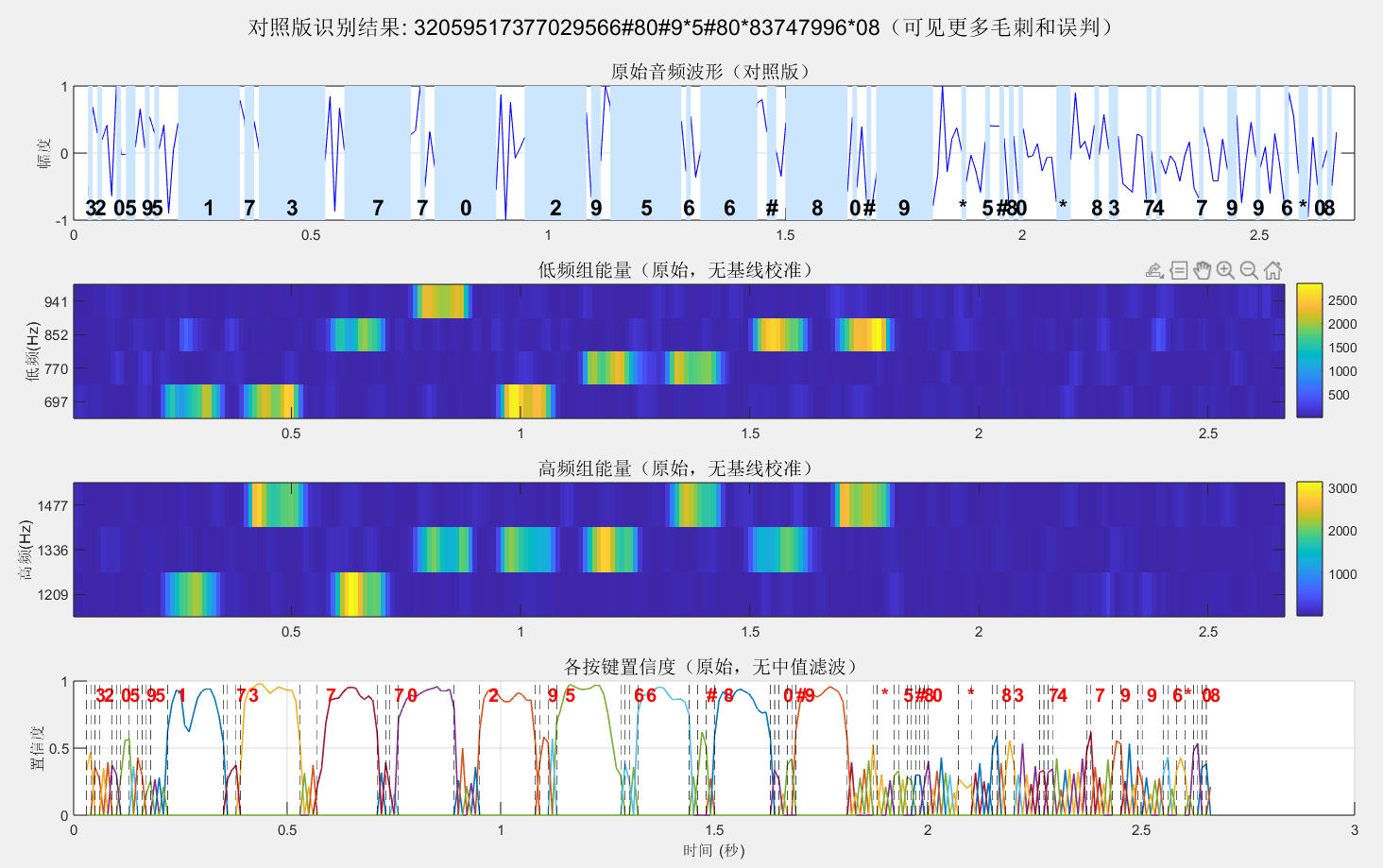
有没有更鲁棒、更优质的通用算法,无需人工逐段切割时域片段,直接对一整段完整音频做自动检测、分离多组双音分量,自主提取所有 DTMF 频点组合并完成识别?
尝试了一下,略显诡异
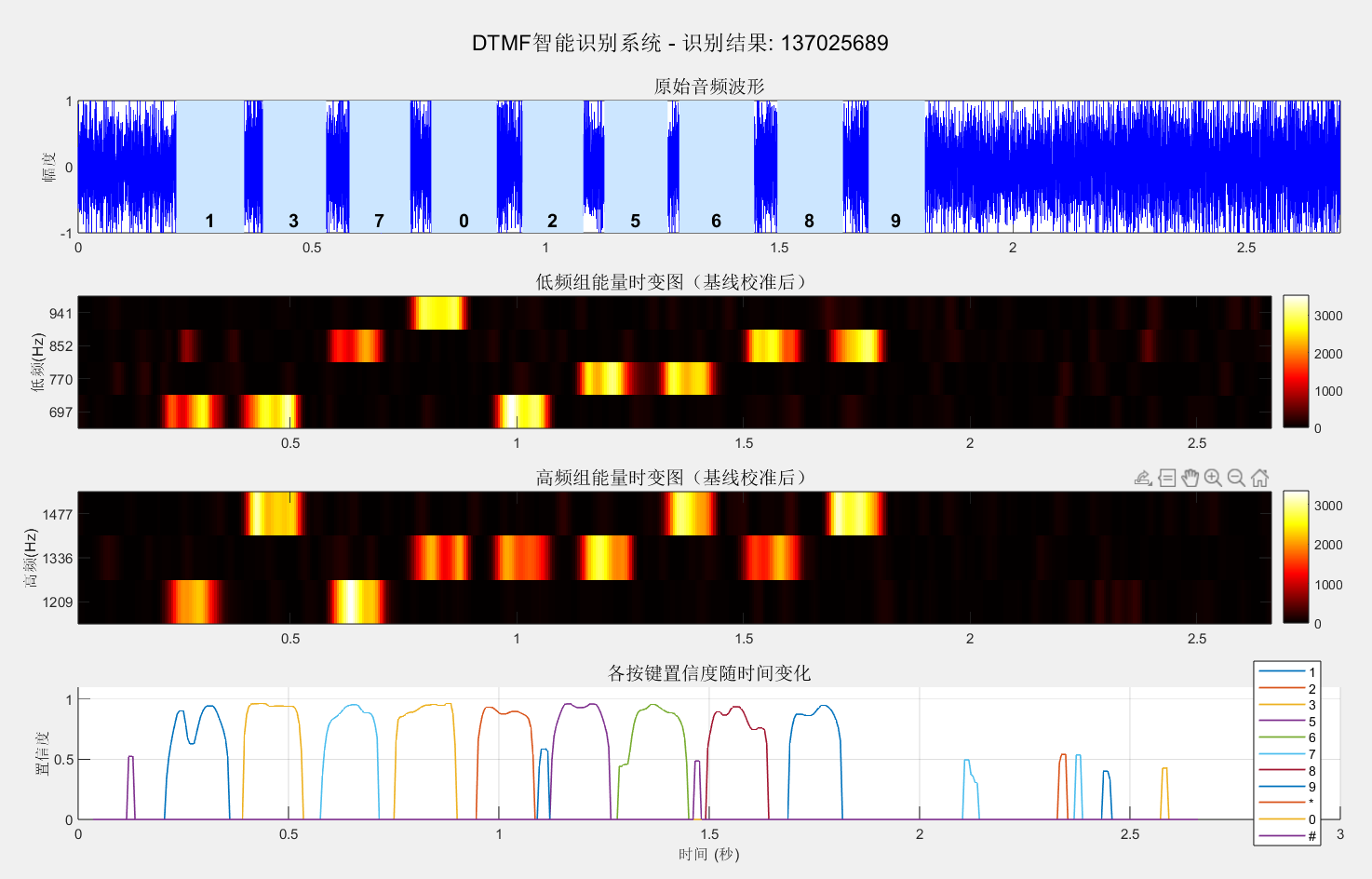
当然参数调好了就非常完美了。
应用到全部音频。
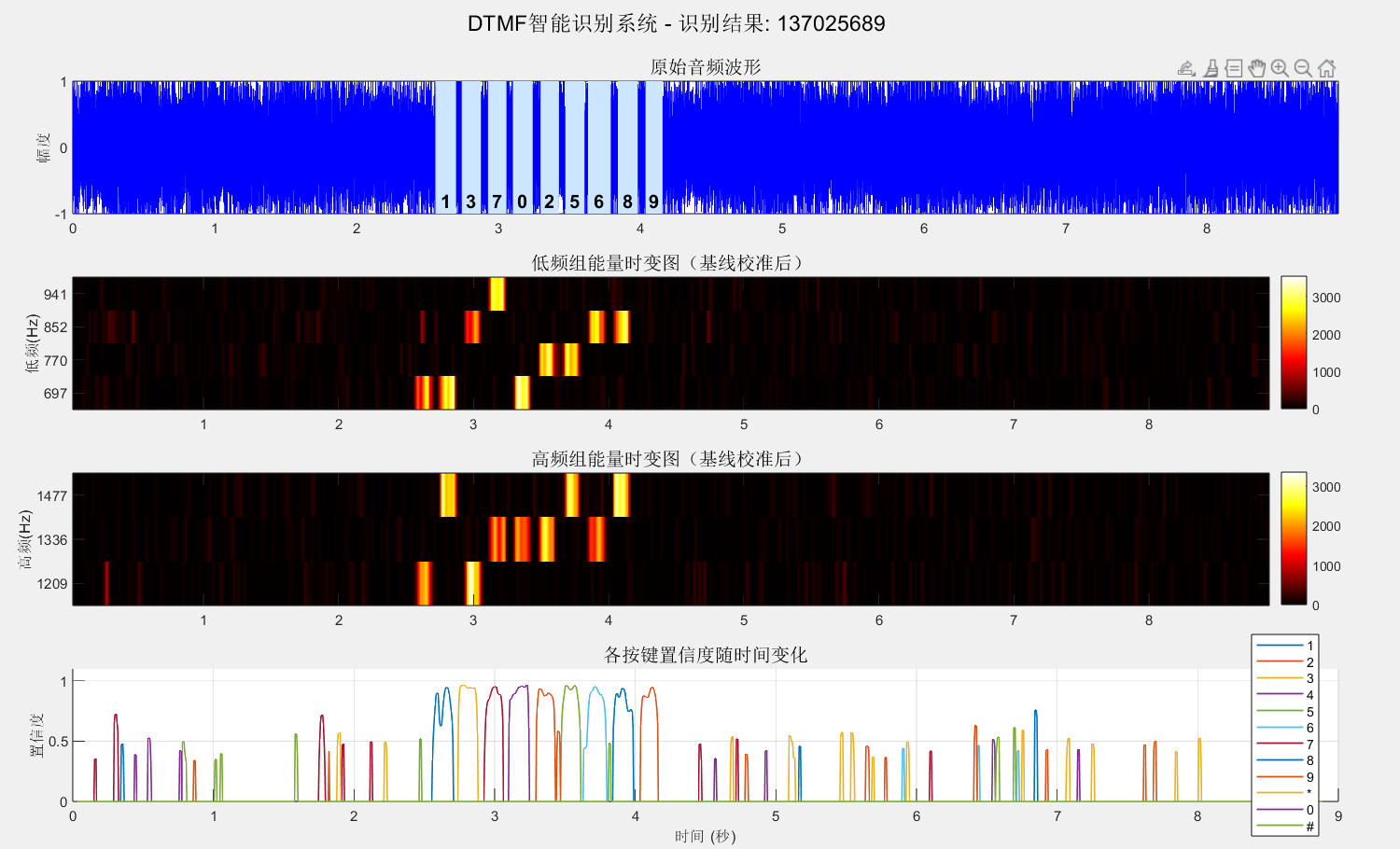 3D图感觉有点华而不实,就这样吧
3D图感觉有点华而不实,就这样吧
参数具体怎么调,可以在这个基础上修改看效果(后面附了代码),这里就不展开细说了。

简单讲一下是怎么实现的:将音频切分成多个重叠的时间窗口(70ms窗口、5ms步长),对每个窗口用Goertzel算法计算DTMF标准频率(低频697/770/852/941Hz,高频1209/1336/1477Hz)的能量;然后通过减去背景噪声基线进行校准,再对每个窗口的能量进行归一化,找出能量最强的低频和高频组合,计算置信度(行概率×列概率),同时要求主次能量比>2且绝对能量超阈值才能判定为有效数字 ;最后对置信度曲线进行中值滤波平滑,合并连续相同的数字,滤除持续时间不足50ms的短暂事件,从而输出完整的拨号序列。
附代码
Matlab
%% DTMF智能拨号识别系统 - 基于多频能量追踪与置信度曲线
% 功能:自动检测音频中的拨号事件,输出每个数字的置信度变化曲线
% 修复:索引越界问题 + 添加绝对能量阈值 + 完善可视化
% ====================================================
clear; clc; close all;
%% ================== 1. 参数配置 ==================
% DTMF标准频率组
LOW_FREQS = [697, 770, 852, 941]; % 低频组(行),对应DTMF的行频率
HIGH_FREQS = [1209, 1336, 1477]; % 高频组(列),对应DTMF的列频率
KEYPAD = { % 4x3按键矩阵,行列交叉对应DTMF数字
'1', '2', '3';
'4', '5', '6';
'7', '8', '9';
'*', '0', '#'
};
% 检测参数
WINDOW_MS = 70; % 检测窗口时长(ms),每个时间窗口的长度
STEP_MS = 5; % 滑动步长(ms),窗口滑动的时间间隔
ENERGY_TH = 1; % 绝对能量阈值(经归一化后调整),低于此阈值视为噪声
MIN_HOLD_MS = 50; % 最小持续时长(ms),按键需要持续的最短时间
%% ================== 2. 读取音频 ==================
filename = 'sdtmf(-5dB).wav'; % 音频文件名
if ~exist(filename, 'file') % 检查文件是否存在
error('文件 %s 不存在,请修改文件名或路径', filename);
end
[audio, fs] = audioread(filename); % 读取音频文件和采样率
audio = mean(audio, 2); % 立体声转单声道(取左右声道均值)
audio = audio / max(abs(audio)); % 归一化到[-1,1],消除幅度差异
totalTime = length(audio) / fs; % 计算音频总时长(秒)
fprintf('音频时长: %.2f 秒, 采样率: %d Hz\n', totalTime, fs);
%% ================== 3. 滑动窗口能量检测 ==================
winLen = round(WINDOW_MS * fs / 1000); % 将窗口时长转换为采样点数
stepLen = round(STEP_MS * fs / 1000); % 将步长转换为采样点数
nWindows = floor((length(audio) - winLen) / stepLen) + 1; % 计算窗口总数
timeAxis = ((0:nWindows-1) * stepLen + winLen/2) / fs; % 每个窗口的时间中心点
lowEnergy = zeros(nWindows, length(LOW_FREQS)); % 存储低频组能量
highEnergy = zeros(nWindows, length(HIGH_FREQS)); % 存储高频组能量
fprintf('正在分析音频(%d个窗口)...\n', nWindows);
% 遍历每个时间窗口
for i = 1:nWindows
% 提取当前窗口的音频片段
idx = (i-1)*stepLen + 1 : (i-1)*stepLen + winLen;
segment = audio(idx) .* hann(winLen); % 添加汉宁窗减少频谱泄漏
% 计算低频组每个频率的能量
for fIdx = 1:length(LOW_FREQS)
lowEnergy(i, fIdx) = goertzelEnergy(segment, fs, LOW_FREQS(fIdx));
end
% 计算高频组每个频率的能量
for fIdx = 1:length(HIGH_FREQS)
highEnergy(i, fIdx) = goertzelEnergy(segment, fs, HIGH_FREQS(fIdx));
end
% 显示进度
if mod(i, round(nWindows/10)) == 0
fprintf(' %.0f%%\n', i/nWindows*100);
end
end
%% ================== 4. 基线校准(减去背景噪声) ==================
% 取最小的10%窗口的平均值作为背景噪声基线
lowBaseline = zeros(1, length(LOW_FREQS)); % 低频基线
highBaseline = zeros(1, length(HIGH_FREQS)); % 高频基线
% 计算低频基线:取能量最低的10%窗口的平均值
for fIdx = 1:length(LOW_FREQS)
sortedEng = sort(lowEnergy(:, fIdx)); % 对能量排序
lowBaseline(fIdx) = mean(sortedEng(1:max(1, round(nWindows*0.1))));
end
% 计算高频基线
for fIdx = 1:length(HIGH_FREQS)
sortedEng = sort(highEnergy(:, fIdx));
highBaseline(fIdx) = mean(sortedEng(1:max(1, round(nWindows*0.1))));
end
% 减去基线,负值置为0
lowEnergyAdj = max(lowEnergy - lowBaseline, 0);
highEnergyAdj = max(highEnergy - highBaseline, 0);
fprintf('基线校准完成\n');
%% ================== 5. 计算置信度 ==================
confidence = zeros(nWindows, 12); % 12个按键的置信度矩阵
detectedDigits = cell(nWindows, 1); % 每个窗口检测到的数字
% 遍历每个窗口计算置信度
for i = 1:nWindows
lowEng = lowEnergyAdj(i, :); % 当前窗口低频能量
highEng = highEnergyAdj(i, :); % 当前窗口高频能量
lowTotal = sum(lowEng) + eps; % 低频总能量(加eps防除零)
highTotal = sum(highEng) + eps; % 高频总能量
lowNorm = lowEng / lowTotal; % 低频能量归一化
highNorm = highEng / highTotal; % 高频能量归一化
[maxLow, rowIdx] = max(lowNorm); % 找出最大低频对应的行
[maxHigh, colIdx] = max(highNorm); % 找出最大高频对应的列
rawConf = maxLow * maxHigh; % 原始置信度 = 行概率 × 列概率
% 绝对能量阈值判断
if max(lowEng) < ENERGY_TH || max(highEng) < ENERGY_TH
continue; % 能量太低,认为是噪声
end
% 能量比检测:检查主峰是否显著高于次峰
sortedLow = sort(lowNorm, 'descend');
sortedHigh = sort(highNorm, 'descend');
lowRatio = sortedLow(1) / (sortedLow(2) + eps); % 低频主次比
highRatio = sortedHigh(1) / (sortedHigh(2) + eps); % 高频主次比
% 判断是否为有效DTMF信号
if lowRatio > 2 && highRatio > 2 && rawConf > 0.3
confidence(i, (rowIdx-1)*3 + colIdx) = rawConf;
detectedDigits{i} = KEYPAD{rowIdx, colIdx};
else
detectedDigits{i} = ''; % 无效信号
end
end
%% ================== 6. 时间序列平滑与事件检测 ==================
confidenceSmoothed = medfilt2(confidence, [5, 1]); % 中值滤波平滑(时间维5点)
[maxConf, bestKeyIdx] = max(confidenceSmoothed, [], 2); % 找出每个窗口的最大置信度按键
maxConf(maxConf < 0.2) = 0; % 置信度阈值过滤
bestKeyChar = cell(nWindows, 1); % 存储每个窗口的最佳按键
for i = 1:nWindows
if maxConf(i) > 0
row = ceil(bestKeyIdx(i) / 3);
col = bestKeyIdx(i) - (row-1)*3;
% 边界检查
if row <= 4 && col <= 3
bestKeyChar{i} = KEYPAD{row, col};
else
bestKeyChar{i} = '';
end
else
bestKeyChar{i} = '';
end
end
%% ================== 7. 事件合并 ==================
events = []; % 存储检测到的事件
currentDigit = ''; % 当前正在处理的数字
startIdx = 1; % 当前数字的开始索引
% 遍历所有窗口,合并连续的相同数字
for i = 1:nWindows
digit = bestKeyChar{i};
% 检测数字是否发生变化
if ~strcmp(digit, currentDigit)
% 保存上一个数字的事件
if ~isempty(currentDigit) && ~strcmp(currentDigit, '')
endIdx = i-1;
duration = (endIdx - startIdx + 1) * STEP_MS; % 持续时间(ms)
if duration >= MIN_HOLD_MS % 满足最小持续时间
events = [events; struct(...
'startIdx', startIdx, ...
'endIdx', endIdx, ...
'startTime', timeAxis(startIdx), ...
'endTime', timeAxis(endIdx), ...
'digit', currentDigit, ...
'maxConf', max(confidenceSmoothed(startIdx:endIdx, :), [], 'all') ...
)];
end
end
currentDigit = digit; % 切换到新数字
startIdx = i; % 更新开始索引
end
end
% 保存最后一个数字的事件
if ~isempty(currentDigit) && ~strcmp(currentDigit, '')
duration = (nWindows - startIdx + 1) * STEP_MS;
if duration >= MIN_HOLD_MS
events = [events; struct(...
'startIdx', startIdx, ...
'endIdx', nWindows, ...
'startTime', timeAxis(startIdx), ...
'endTime', timeAxis(end), ...
'digit', currentDigit, ...
'maxConf', max(confidenceSmoothed(startIdx:end, :), [], 'all') ...
)];
end
end
%% ================== 8. 输出识别结果 ==================
fprintf('\n========================================\n');
fprintf(' DTMF智能识别结果\n');
fprintf('========================================\n');
recognizedNumber = ''; % 拼接识别出的完整号码
for i = 1:length(events)
recognizedNumber = [recognizedNumber, events(i).digit];
fprintf('%.3fs - %.3fs : 按键 [%s] (置信度: %.2f)\n', ...
events(i).startTime, events(i).endTime, ...
events(i).digit, events(i).maxConf);
end
fprintf('----------------------------------------\n');
fprintf('拨出号码: %s\n', recognizedNumber);
fprintf('========================================\n\n');
%% ================== 9. 可视化 ==================
figure('Position', [50, 50, 1400, 900], 'Name', 'DTMF智能识别系统');
% 子图1:原始音频波形
subplot(4,1,1);
plot((0:length(audio)-1)/fs, audio, 'b', 'LineWidth', 0.5);
xlim([0, totalTime]);
ylabel('幅度');
title('原始音频波形', 'FontSize', 12);
grid on;
hold on;
% 在波形上叠加检测到的按键区域
for i = 1:length(events)
ylims = ylim;
% 绘制半透明矩形标注按键区域
rectangle('Position', [events(i).startTime, ylims(1), ...
events(i).endTime - events(i).startTime, ylims(2)-ylims(1)], ...
'FaceColor', [0.8, 0.9, 1], 'EdgeColor', 'none');
% 在矩形中心标注按键数字
text(events(i).startTime + (events(i).endTime-events(i).startTime)/2, ...
ylims(1) + 0.1*(ylims(2)-ylims(1)), events(i).digit, ...
'FontSize', 12, 'FontWeight', 'bold', 'HorizontalAlignment', 'center');
end
% 子图2:低频组能量热图(校准后)
subplot(4,1,2);
imagesc(timeAxis, 1:4, lowEnergyAdj');
set(gca, 'YDir', 'normal'); % 正常Y轴方向
ylabel('低频(Hz)');
yticks(1:4);
yticklabels(string(LOW_FREQS)); % 显示实际频率值
title('低频组能量时变图(基线校准后)', 'FontSize', 12);
colorbar; % 显示颜色条
colormap(gca, 'hot'); % 使用热色图
% 子图3:高频组能量热图(校准后)
subplot(4,1,3);
imagesc(timeAxis, 1:3, highEnergyAdj');
set(gca, 'YDir', 'normal');
ylabel('高频(Hz)');
yticks(1:3);
yticklabels(string(HIGH_FREQS));
title('高频组能量时变图(基线校准后)', 'FontSize', 12);
colorbar;
colormap(gca, 'hot');
% 子图4:置信度曲线
subplot(4,1,4);
hold on;
% 显示12个按键(3x4)的置信度曲线
for keyIdx = 1:12
confCurve = confidenceSmoothed(:, keyIdx);
if max(confCurve) > 0.1 % 只显示有显著置信度的曲线
% 计算行列用于图例
row = ceil(keyIdx / 3);
col = keyIdx - (row-1)*3;
keyName = KEYPAD{row, col};
plot(timeAxis, confCurve, 'LineWidth', 1, 'DisplayName', keyName);
end
end
xlabel('时间 (秒)');
ylabel('置信度');
title('各按键置信度随时间变化', 'FontSize', 12);
ylim([0, 1.1]); % 置信度范围0-1
grid on;
legend show; % 显示图例
legend('Location', 'best'); % 自动选择最佳图例位置
% 总标题显示识别结果
sgtitle(sprintf('DTMF智能识别系统 - 识别结果: %s', recognizedNumber), 'FontSize', 14);
%% ================== 辅助函数 ==================
function energy = goertzelEnergy(segment, fs, targetFreq)
% Goertzel算法计算指定频率的能量
% 输入:
% segment - 音频片段
% fs - 采样率
% targetFreq - 目标频率
% 输出:
% energy - 该频率的能量
N = length(segment); % 窗口长度
k = round(targetFreq * N / fs); % 计算对应的DFT索引
omega = 2 * pi * k / N; % 角频率
coeff = 2 * cos(omega); % 递推系数
% Goertzel递推算法
Q0 = 0;
Q1 = 0;
for n = 1:N
Q2 = Q1;
Q1 = Q0;
Q0 = coeff * Q1 - Q2 + segment(n);
end
% 计算实部和虚部
realPart = Q0 - Q1 * cos(omega);
imagPart = Q1 * sin(omega);
energy = realPart^2 + imagPart^2; % 能量 = 幅值平方
end
function [f, P1] = calcSpectrum(x, fs)
% 计算频谱(辅助调试用,当前版本未使用)
% 输入:
% x - 信号
% fs - 采样率
% 输出:
% f - 频率轴
% P1 - 单边谱幅值
L = length(x);
N = floor(L/2);
Y = fft(x); % 快速傅里叶变换
P2 = abs(Y/L); % 双边谱
P1 = P2(1:N+1); % 单边谱
P1(2:end-1) = 2*P1(2:end-1); % 除直流外乘以2
f = fs*(0:N)/L; % 频率轴
end滤除拨号音
在上面的代码基础上修改,添加了对识别到的拨号音滤除的代码。
AI使用了级联陷波滤波器 Notch Filter,类别上讲,是时域IIR数字滤波器**,**更适合实时处理,IIR滤波器计算效率高,可以精确控制频率响应。
具体的工作流程是------
在时域上对输入信号进行卷积运算
每个输出样本是当前和过去输入样本的加权组合,同时也利用过去的输出样本(反馈)
↑AI说的,不懂也没关系QwQ
Matlab
%% DTMF智能拨号识别与滤除系统 - 基于多频能量追踪与置信度曲线
% 功能:自动检测音频中的拨号事件,并滤除DTMF拨号音,保留其他声音
% 修复:索引越界问题 + 添加绝对能量阈值 + 完善可视化 + DTMF滤除
% ====================================================
clear; clc; close all;
%% ================== 1. 参数配置 ==================
% DTMF标准频率组
LOW_FREQS = [697, 770, 852, 941]; % 低频组(行),对应DTMF的行频率
HIGH_FREQS = [1209, 1336, 1477]; % 高频组(列),对应DTMF的列频率
KEYPAD = { % 4x3按键矩阵,行列交叉对应DTMF数字
'1', '2', '3';
'4', '5', '6';
'7', '8', '9';
'*', '0', '#'
};
% 检测参数
WINDOW_MS = 70; % 检测窗口时长(ms),每个时间窗口的长度
STEP_MS = 5; % 滑动步长(ms),窗口滑动的时间间隔
ENERGY_TH = 1; % 绝对能量阈值(经归一化后调整),低于此阈值视为噪声
MIN_HOLD_MS = 50; % 最小持续时长(ms),按键需要持续的最短时间
% 滤除参数
NOTCH_Q = 35; % 陷波滤波器的品质因数(越高选择性越强)
TRANSITION_BAND = 20; % 过渡带宽度(Hz),用于设计带阻滤波器
%% ================== 2. 读取音频 ==================
filename = 'sdtmf(-5dB).wav'; % 音频文件名
if ~exist(filename, 'file') % 检查文件是否存在
error('文件 %s 不存在,请修改文件名或路径', filename);
end
[audio, fs] = audioread(filename); % 读取音频文件和采样率
audio = mean(audio, 2); % 立体声转单声道(取左右声道均值)
audio = audio / max(abs(audio)); % 归一化到[-1,1],消除幅度差异
totalTime = length(audio) / fs; % 计算音频总时长(秒)
fprintf('音频时长: %.2f 秒, 采样率: %d Hz\n', totalTime, fs);
%% ================== 3. 滑动窗口能量检测 ==================
winLen = round(WINDOW_MS * fs / 1000); % 将窗口时长转换为采样点数
stepLen = round(STEP_MS * fs / 1000); % 将步长转换为采样点数
nWindows = floor((length(audio) - winLen) / stepLen) + 1; % 计算窗口总数
timeAxis = ((0:nWindows-1) * stepLen + winLen/2) / fs; % 每个窗口的时间中心点
lowEnergy = zeros(nWindows, length(LOW_FREQS)); % 存储低频组能量
highEnergy = zeros(nWindows, length(HIGH_FREQS)); % 存储高频组能量
fprintf('正在分析音频(%d个窗口)...\n', nWindows);
% 遍历每个时间窗口
for i = 1:nWindows
% 提取当前窗口的音频片段
idx = (i-1)*stepLen + 1 : (i-1)*stepLen + winLen;
segment = audio(idx) .* hann(winLen); % 添加汉宁窗减少频谱泄漏
% 计算低频组每个频率的能量
for fIdx = 1:length(LOW_FREQS)
lowEnergy(i, fIdx) = goertzelEnergy(segment, fs, LOW_FREQS(fIdx));
end
% 计算高频组每个频率的能量
for fIdx = 1:length(HIGH_FREQS)
highEnergy(i, fIdx) = goertzelEnergy(segment, fs, HIGH_FREQS(fIdx));
end
% 显示进度
if mod(i, round(nWindows/10)) == 0
fprintf(' %.0f%%\n', i/nWindows*100);
end
end
%% ================== 4. 基线校准(减去背景噪声) ==================
% 取最小的10%窗口的平均值作为背景噪声基线
lowBaseline = zeros(1, length(LOW_FREQS)); % 低频基线
highBaseline = zeros(1, length(HIGH_FREQS)); % 高频基线
% 计算低频基线:取能量最低的10%窗口的平均值
for fIdx = 1:length(LOW_FREQS)
sortedEng = sort(lowEnergy(:, fIdx)); % 对能量排序
lowBaseline(fIdx) = mean(sortedEng(1:max(1, round(nWindows*0.1))));
end
% 计算高频基线
for fIdx = 1:length(HIGH_FREQS)
sortedEng = sort(highEnergy(:, fIdx));
highBaseline(fIdx) = mean(sortedEng(1:max(1, round(nWindows*0.1))));
end
% 减去基线,负值置为0
lowEnergyAdj = max(lowEnergy - lowBaseline, 0);
highEnergyAdj = max(highEnergy - highBaseline, 0);
fprintf('基线校准完成\n');
%% ================== 5. 计算置信度 ==================
confidence = zeros(nWindows, 12); % 12个按键的置信度矩阵
detectedDigits = cell(nWindows, 1); % 每个窗口检测到的数字
% 遍历每个窗口计算置信度
for i = 1:nWindows
lowEng = lowEnergyAdj(i, :); % 当前窗口低频能量
highEng = highEnergyAdj(i, :); % 当前窗口高频能量
lowTotal = sum(lowEng) + eps; % 低频总能量(加eps防除零)
highTotal = sum(highEng) + eps; % 高频总能量
lowNorm = lowEng / lowTotal; % 低频能量归一化
highNorm = highEng / highTotal; % 高频能量归一化
[maxLow, rowIdx] = max(lowNorm); % 找出最大低频对应的行
[maxHigh, colIdx] = max(highNorm); % 找出最大高频对应的列
rawConf = maxLow * maxHigh; % 原始置信度 = 行概率 × 列概率
% 绝对能量阈值判断
if max(lowEng) < ENERGY_TH || max(highEng) < ENERGY_TH
continue; % 能量太低,认为是噪声
end
% 能量比检测:检查主峰是否显著高于次峰
sortedLow = sort(lowNorm, 'descend');
sortedHigh = sort(highNorm, 'descend');
lowRatio = sortedLow(1) / (sortedLow(2) + eps); % 低频主次比
highRatio = sortedHigh(1) / (sortedHigh(2) + eps); % 高频主次比
% 判断是否为有效DTMF信号
if lowRatio > 2 && highRatio > 2 && rawConf > 0.3
confidence(i, (rowIdx-1)*3 + colIdx) = rawConf;
detectedDigits{i} = KEYPAD{rowIdx, colIdx};
else
detectedDigits{i} = ''; % 无效信号
end
end
%% ================== 6. 时间序列平滑与事件检测 ==================
confidenceSmoothed = medfilt2(confidence, [5, 1]); % 中值滤波平滑(时间维5点)
[maxConf, bestKeyIdx] = max(confidenceSmoothed, [], 2); % 找出每个窗口的最大置信度按键
maxConf(maxConf < 0.2) = 0; % 置信度阈值过滤
bestKeyChar = cell(nWindows, 1); % 存储每个窗口的最佳按键
for i = 1:nWindows
if maxConf(i) > 0
row = ceil(bestKeyIdx(i) / 3);
col = bestKeyIdx(i) - (row-1)*3;
% 边界检查
if row <= 4 && col <= 3
bestKeyChar{i} = KEYPAD{row, col};
else
bestKeyChar{i} = '';
end
else
bestKeyChar{i} = '';
end
end
%% ================== 7. 事件合并 ==================
events = []; % 存储检测到的事件
currentDigit = ''; % 当前正在处理的数字
startIdx = 1; % 当前数字的开始索引
% 遍历所有窗口,合并连续的相同数字
for i = 1:nWindows
digit = bestKeyChar{i};
% 检测数字是否发生变化
if ~strcmp(digit, currentDigit)
% 保存上一个数字的事件
if ~isempty(currentDigit) && ~strcmp(currentDigit, '')
endIdx = i-1;
duration = (endIdx - startIdx + 1) * STEP_MS; % 持续时间(ms)
if duration >= MIN_HOLD_MS % 满足最小持续时间
% 提取该事件对应的频率对
[freq1, freq2] = getDTMFFrequencies(currentDigit, LOW_FREQS, HIGH_FREQS, KEYPAD);
events = [events; struct(...
'startIdx', startIdx, ...
'endIdx', endIdx, ...
'startTime', timeAxis(startIdx), ...
'endTime', timeAxis(endIdx), ...
'digit', currentDigit, ...
'maxConf', max(confidenceSmoothed(startIdx:endIdx, :), [], 'all'), ...
'freq1', freq1, ...
'freq2', freq2 ...
)];
end
end
currentDigit = digit; % 切换到新数字
startIdx = i; % 更新开始索引
end
end
% 保存最后一个数字的事件
if ~isempty(currentDigit) && ~strcmp(currentDigit, '')
duration = (nWindows - startIdx + 1) * STEP_MS;
if duration >= MIN_HOLD_MS
[freq1, freq2] = getDTMFFrequencies(currentDigit, LOW_FREQS, HIGH_FREQS, KEYPAD);
events = [events; struct(...
'startIdx', startIdx, ...
'endIdx', nWindows, ...
'startTime', timeAxis(startIdx), ...
'endTime', timeAxis(end), ...
'digit', currentDigit, ...
'maxConf', max(confidenceSmoothed(startIdx:end, :), [], 'all'), ...
'freq1', freq1, ...
'freq2', freq2 ...
)];
end
end
%% ================== 8. 滤除DTMF信号 ==================
fprintf('\n开始滤除DTMF拨号音...\n');
audioFiltered = audio; % 初始化滤波后的音频
% 为每个检测到的DTMF事件设计并应用滤波器
for i = 1:length(events)
startSample = max(1, round(events(i).startTime * fs));
endSample = min(length(audio), round(events(i).endTime * fs));
% 扩展边缘20ms,避免滤波引入的边界效应
padMs = 20;
startPad = max(1, startSample - round(padMs * fs / 1000));
endPad = min(length(audio), endSample + round(padMs * fs / 1000));
segment = audioFiltered(startPad:endPad);
% 方法1:使用级联陷波滤波器(推荐)
segmentFiltered = removeDTMFWithNotch(segment, fs, events(i).freq1, events(i).freq2, NOTCH_Q);
% 可选:方法2:使用带阻滤波器(更陡峭但可能有振铃效应)
% segmentFiltered = removeDTMFWithBandstop(segment, fs, events(i).freq1, events(i).freq2, TRANSITION_BAND);
% 将滤波后的片段放回(使用渐变过渡避免突变)
crossfadeLen = round(5 * fs / 1000); % 5ms交叉渐变
if i == 1
audioFiltered(startPad:endPad) = segmentFiltered;
else
% 应用渐变过渡
fadeIn = linspace(0, 1, crossfadeLen)';
fadeOut = linspace(1, 0, crossfadeLen)';
overlapStart = startPad;
overlapEnd = min(endPad, startPad + crossfadeLen - 1);
if overlapEnd > overlapStart
audioFiltered(overlapStart:overlapEnd) = ...
fadeOut(1:length(overlapStart:overlapEnd)) .* audioFiltered(overlapStart:overlapEnd) + ...
fadeIn(1:length(overlapStart:overlapEnd)) .* segmentFiltered(1:length(overlapStart:overlapEnd));
audioFiltered(overlapEnd+1:endPad) = segmentFiltered(length(overlapStart:overlapEnd)+1:end);
else
audioFiltered(startPad:endPad) = segmentFiltered;
end
end
fprintf(' 已滤除事件 %d: 按键 [%s] (%.3f-%.3fs, 频率: %.0fHz + %.0fHz)\n', ...
i, events(i).digit, events(i).startTime, events(i).endTime, ...
events(i).freq1, events(i).freq2);
end
%% ================== 9. 输出识别结果 ==================
fprintf('\n========================================\n');
fprintf(' DTMF智能识别结果\n');
fprintf('========================================\n');
recognizedNumber = ''; % 拼接识别出的完整号码
for i = 1:length(events)
recognizedNumber = [recognizedNumber, events(i).digit];
fprintf('%.3fs - %.3fs : 按键 [%s] (置信度: %.2f)\n', ...
events(i).startTime, events(i).endTime, ...
events(i).digit, events(i).maxConf);
end
fprintf('----------------------------------------\n');
fprintf('拨出号码: %s\n', recognizedNumber);
fprintf('========================================\n\n');
%% ================== 10. 保存滤波后的音频 ==================
outputFilename = ['filtered_', filename];
audiowrite(outputFilename, audioFiltered, fs);
fprintf('滤波后的音频已保存为: %s\n', outputFilename);
%% ================== 11. 可视化对比 ==================
figure('Position', [50, 50, 1400, 1000], 'Name', 'DTMF智能识别与滤除系统');
% 子图1:原始音频波形
subplot(5,1,1);
plot((0:length(audio)-1)/fs, audio, 'b', 'LineWidth', 0.5);
xlim([0, totalTime]);
ylabel('幅度');
title('原始音频波形', 'FontSize', 12);
grid on;
hold on;
% 在波形上叠加检测到的按键区域
for i = 1:length(events)
ylims = ylim;
rectangle('Position', [events(i).startTime, ylims(1), ...
events(i).endTime - events(i).startTime, ylims(2)-ylims(1)], ...
'FaceColor', [0.8, 0.9, 1], 'EdgeColor', 'none');
text(events(i).startTime + (events(i).endTime-events(i).startTime)/2, ...
ylims(1) + 0.1*(ylims(2)-ylims(1)), events(i).digit, ...
'FontSize', 12, 'FontWeight', 'bold', 'HorizontalAlignment', 'center');
end
% 子图2:滤波后音频波形
subplot(5,1,2);
plot((0:length(audioFiltered)-1)/fs, audioFiltered, 'r', 'LineWidth', 0.5);
xlim([0, totalTime]);
ylabel('幅度');
title('滤除DTMF后的音频波形', 'FontSize', 12);
grid on;
% 子图3:低频组能量热图(校准后)
subplot(5,1,3);
imagesc(timeAxis, 1:4, lowEnergyAdj');
set(gca, 'YDir', 'normal');
ylabel('低频(Hz)');
yticks(1:4);
yticklabels(string(LOW_FREQS));
title('低频组能量时变图(基线校准后)', 'FontSize', 12);
colorbar;
colormap(gca, 'hot');
% 子图4:高频组能量热图(校准后)
subplot(5,1,4);
imagesc(timeAxis, 1:3, highEnergyAdj');
set(gca, 'YDir', 'normal');
ylabel('高频(Hz)');
yticks(1:3);
yticklabels(string(HIGH_FREQS));
title('高频组能量时变图(基线校准后)', 'FontSize', 12);
colorbar;
colormap(gca, 'hot');
% 子图5:置信度曲线
subplot(5,1,5);
hold on;
for keyIdx = 1:12
confCurve = confidenceSmoothed(:, keyIdx);
if max(confCurve) > 0.1
row = ceil(keyIdx / 3);
col = keyIdx - (row-1)*3;
keyName = KEYPAD{row, col};
plot(timeAxis, confCurve, 'LineWidth', 1, 'DisplayName', keyName);
end
end
xlabel('时间 (秒)');
ylabel('置信度');
title('各按键置信度随时间变化', 'FontSize', 12);
ylim([0, 1.1]);
grid on;
legend show;
legend('Location', 'best');
% 总标题
sgtitle(sprintf('DTMF智能识别与滤除系统 - 识别结果: %s', recognizedNumber), 'FontSize', 14);
%% ================== 频谱对比图 ==================
figure('Position', [50, 50, 1200, 500], 'Name', '频谱对比');
% 选择第一个DTMF事件进行详细频谱分析
if ~isempty(events)
startSample = max(1, round(events(1).startTime * fs));
endSample = min(length(audio), round(events(1).endTime * fs));
% 原始信号片段
originalSegment = audio(startSample:endSample);
% 滤波后信号片段
filteredSegment = audioFiltered(startSample:endSample);
% 计算频谱
[f_orig, P1_orig] = calcSpectrum(originalSegment, fs);
[f_filt, P1_filt] = calcSpectrum(filteredSegment, fs);
% 绘制频谱对比
subplot(1,2,1);
plot(f_orig, 20*log10(P1_orig + eps), 'b', 'LineWidth', 1.5);
xlabel('频率 (Hz)');
ylabel('幅度 (dB)');
title(sprintf('原始信号频谱 (按键 %s)', events(1).digit));
grid on;
xlim([0, 2000]);
hold on;
% 标记DTMF频率
line([events(1).freq1, events(1).freq1], ylim, 'Color', 'r', 'LineStyle', '--', 'LineWidth', 1);
line([events(1).freq2, events(1).freq2], ylim, 'Color', 'r', 'LineStyle', '--', 'LineWidth', 1);
legend('频谱', 'DTMF频率', 'Location', 'best');
subplot(1,2,2);
plot(f_filt, 20*log10(P1_filt + eps), 'r', 'LineWidth', 1.5);
xlabel('频率 (Hz)');
ylabel('幅度 (dB)');
title('滤除DTMF后的信号频谱');
grid on;
xlim([0, 2000]);
hold on;
line([events(1).freq1, events(1).freq1], ylim, 'Color', 'g', 'LineStyle', '--', 'LineWidth', 1);
line([events(1).freq2, events(1).freq2], ylim, 'Color', 'g', 'LineStyle', '--', 'LineWidth', 1);
legend('频谱', '原DTMF频率位置', 'Location', 'best');
sgtitle('DTMF滤除效果频谱对比', 'FontSize', 14);
end
%% ================== 辅助函数 ==================
function energy = goertzelEnergy(segment, fs, targetFreq)
% Goertzel算法计算指定频率的能量
N = length(segment);
k = round(targetFreq * N / fs);
omega = 2 * pi * k / N;
coeff = 2 * cos(omega);
Q0 = 0;
Q1 = 0;
for n = 1:N
Q2 = Q1;
Q1 = Q0;
Q0 = coeff * Q1 - Q2 + segment(n);
end
realPart = Q0 - Q1 * cos(omega);
imagPart = Q1 * sin(omega);
energy = realPart^2 + imagPart^2;
end
function [f, P1] = calcSpectrum(x, fs)
% 计算频谱
L = length(x);
N = floor(L/2);
Y = fft(x);
P2 = abs(Y/L);
P1 = P2(1:N+1);
P1(2:end-1) = 2*P1(2:end-1);
f = fs*(0:N)/L;
end
function [freq1, freq2] = getDTMFFrequencies(digit, LOW_FREQS, HIGH_FREQS, KEYPAD)
% 根据按键获取对应的DTMF频率对
freq1 = [];
freq2 = [];
for row = 1:4
for col = 1:3
if strcmp(KEYPAD{row, col}, digit)
freq1 = LOW_FREQS(row);
freq2 = HIGH_FREQS(col);
return;
end
end
end
end
function filtered = removeDTMFWithNotch(signal, fs, freq1, freq2, Q)
% 使用级联陷波滤波器去除DTMF频率
% 参数:
% signal - 输入信号
% fs - 采样率
% freq1, freq2 - 需要滤除的两个频率
% Q - 品质因数(越高选择性越强,但相位响应更尖锐)
% 设计第一个陷波滤波器
wo1 = freq1 / (fs/2); % 归一化频率
bw1 = wo1 / Q; % 带宽
[b1, a1] = iirnotch(wo1, bw1);
% 设计第二个陷波滤波器
wo2 = freq2 / (fs/2);
bw2 = wo2 / Q;
[b2, a2] = iirnotch(wo2, bw2);
% 级联应用滤波器
filtered = filter(b1, a1, signal);
filtered = filter(b2, a2, filtered);
end
function filtered = removeDTMFWithBandstop(signal, fs, freq1, freq2, transitionBand)
% 使用带阻滤波器去除DTMF频率(更陡峭的截止特性)
% 参数:
% signal - 输入信号
% fs - 采样率
% freq1, freq2 - 需要滤除的两个频率
% transitionBand - 过渡带宽度(Hz)
% 为两个频率分别设计带阻滤波器
% 对于相近的频率,可以合并为一个更宽的带阻
if abs(freq1 - freq2) < transitionBand * 2
% 频率相近,设计一个宽带阻滤波器
centerFreq = (freq1 + freq2) / 2;
bandwidth = abs(freq2 - freq1) + transitionBand;
Wc = [centerFreq - bandwidth/2, centerFreq + bandwidth/2] / (fs/2);
Wc = max(0, min(1, Wc)); % 限制在有效范围内
[b, a] = butter(4, Wc, 'stop');
filtered = filter(b, a, signal);
else
% 频率相距较远,分别滤除
Wc1 = [freq1 - transitionBand/2, freq1 + transitionBand/2] / (fs/2);
Wc1 = max(0, min(1, Wc1));
[b1, a1] = butter(4, Wc1, 'stop');
Wc2 = [freq2 - transitionBand/2, freq2 + transitionBand/2] / (fs/2);
Wc2 = max(0, min(1, Wc2));
[b2, a2] = butter(4, Wc2, 'stop');
filtered = filter(b1, a1, signal);
filtered = filter(b2, a2, filtered);
end
end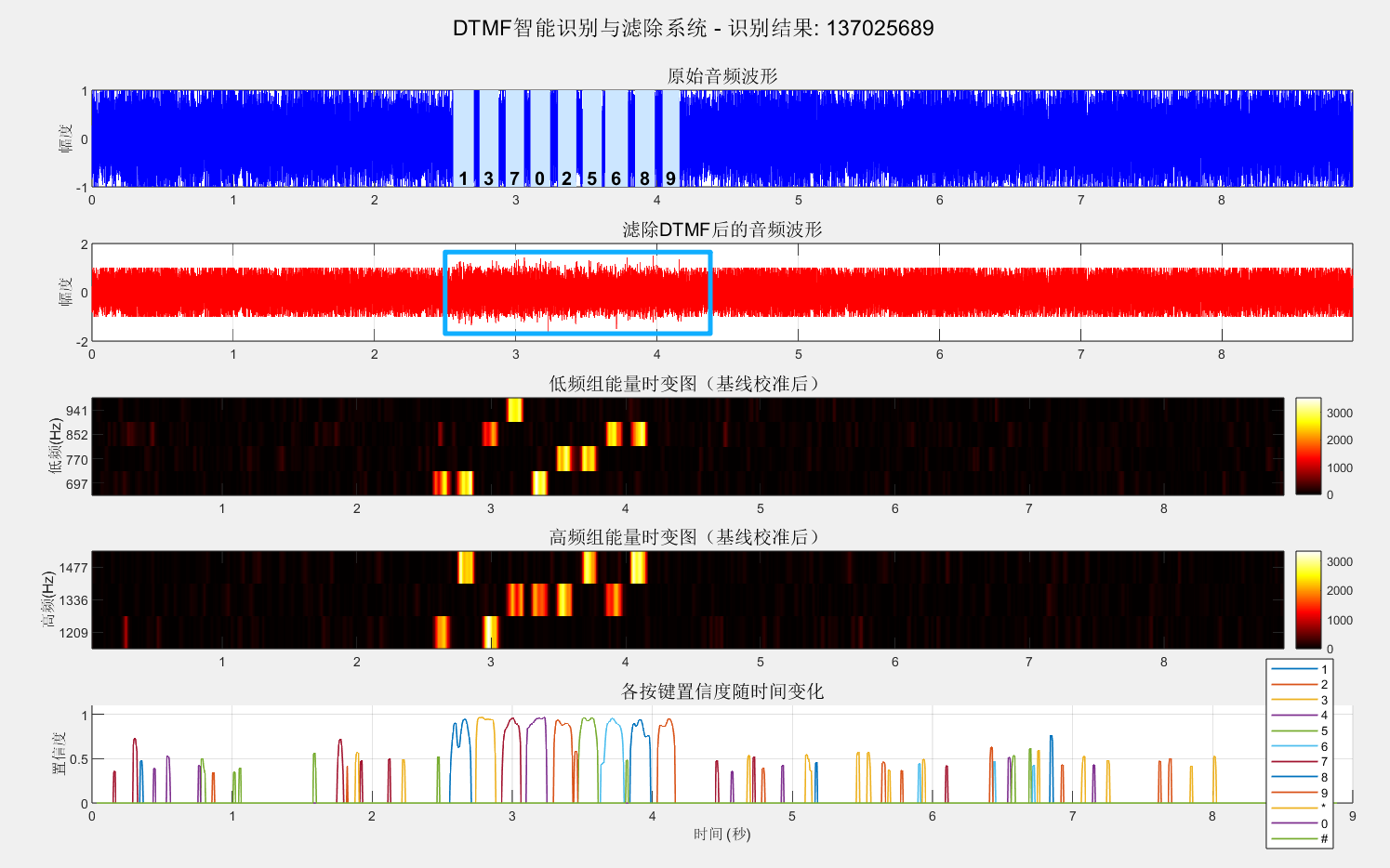
运行代码后出现警告------

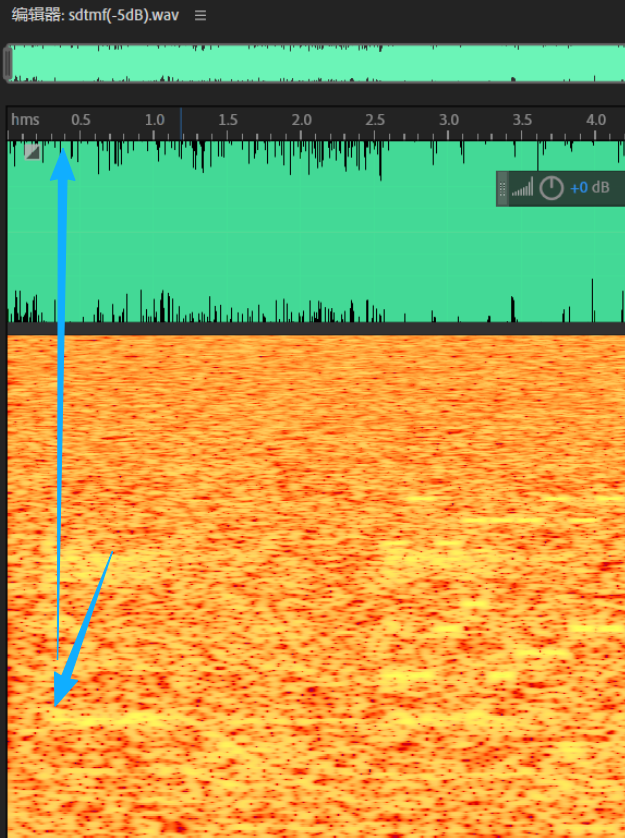
这就是上面用蓝色框框出来的问题,在滤波处理后,音频的振幅反而变大了。这就导致原本就很响的声音再存储的时候超过了0dB再次发生了削波失真。
为什么音频的振幅反而变大了呢?
大概两个原因:
**一、相位失真:**滤波器在不同频率上产生不同的时间延迟------当DTMF的双频信号被滤除时,滤波器会改变附近频率成分(特别是语音信号)的相位关系,原本相位分散的谐波分量可能因为相位调整而意外对齐,导致这些分量的瞬时值在时域上叠加增强,就像原本错开的波浪突然同时涌来形成更高的浪峰;
**二、振铃效应:**源于滤波器的陡峭过渡带------为了精准滤除DTMF频率(Q值越高越陡峭),滤波器实际上在频域上制造了一个"悬崖",根据傅里叶变换的不确定性原理,频域上越陡峭的截止对应时域上越长的拖尾振荡,这就好比在音频信号中突然挖掉一个频带,会在时域产生类似"敲钟"后的衰减震荡,这种震荡叠加在原信号上就会在DTMF信号的起点和终点附近造成幅值先冲高再回落的现象,看起来就像音量突然变大了。
至于为什么以及关于时域和频域滤波的相关内容,可以参考这篇https://blog.csdn.net/Harrytutu_ZuiYue/article/details/160386633
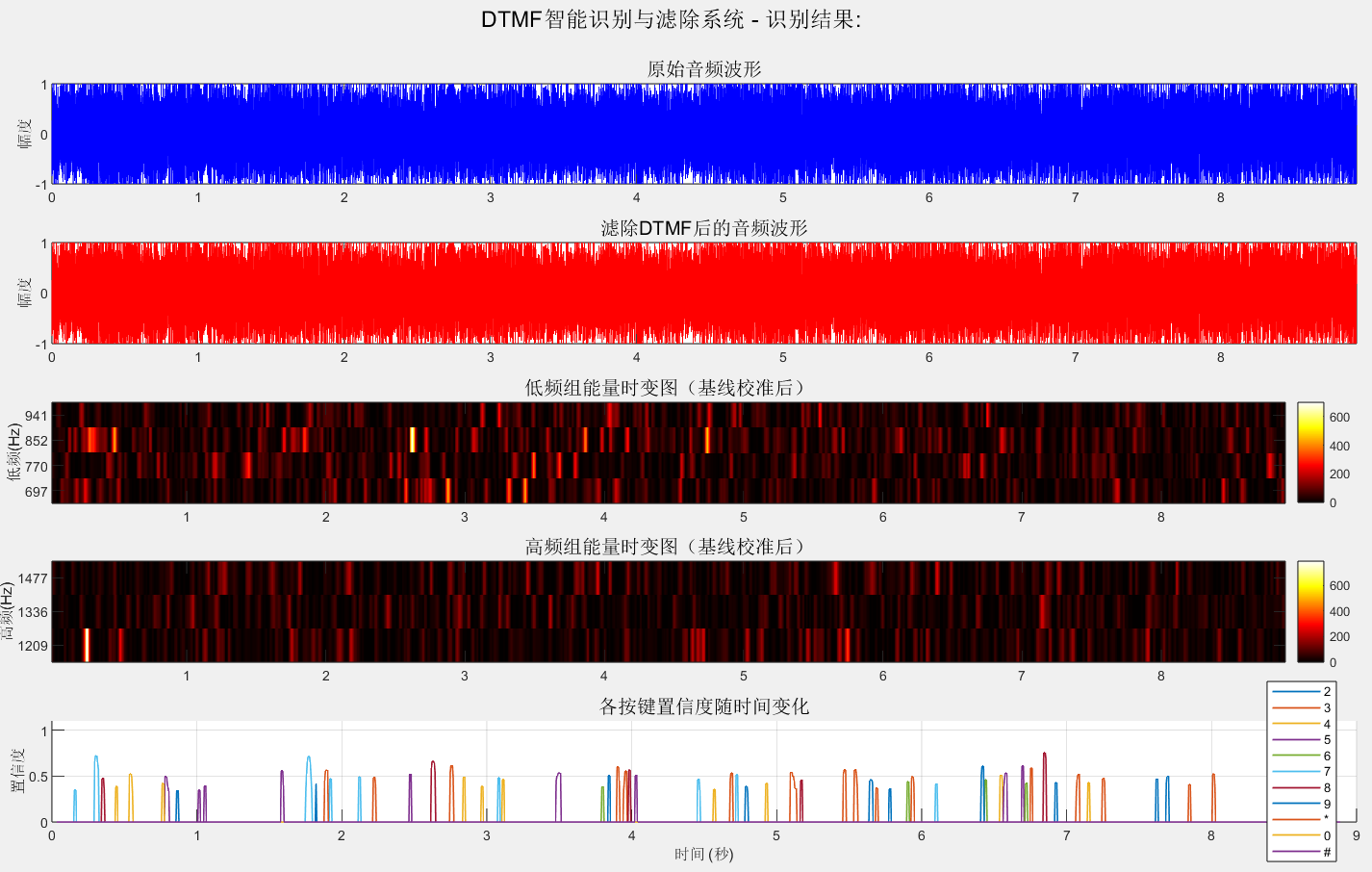
滤除后再识别一遍,已经没有置信度在拨号持续时间内一直较高的存在了,滤除成功。
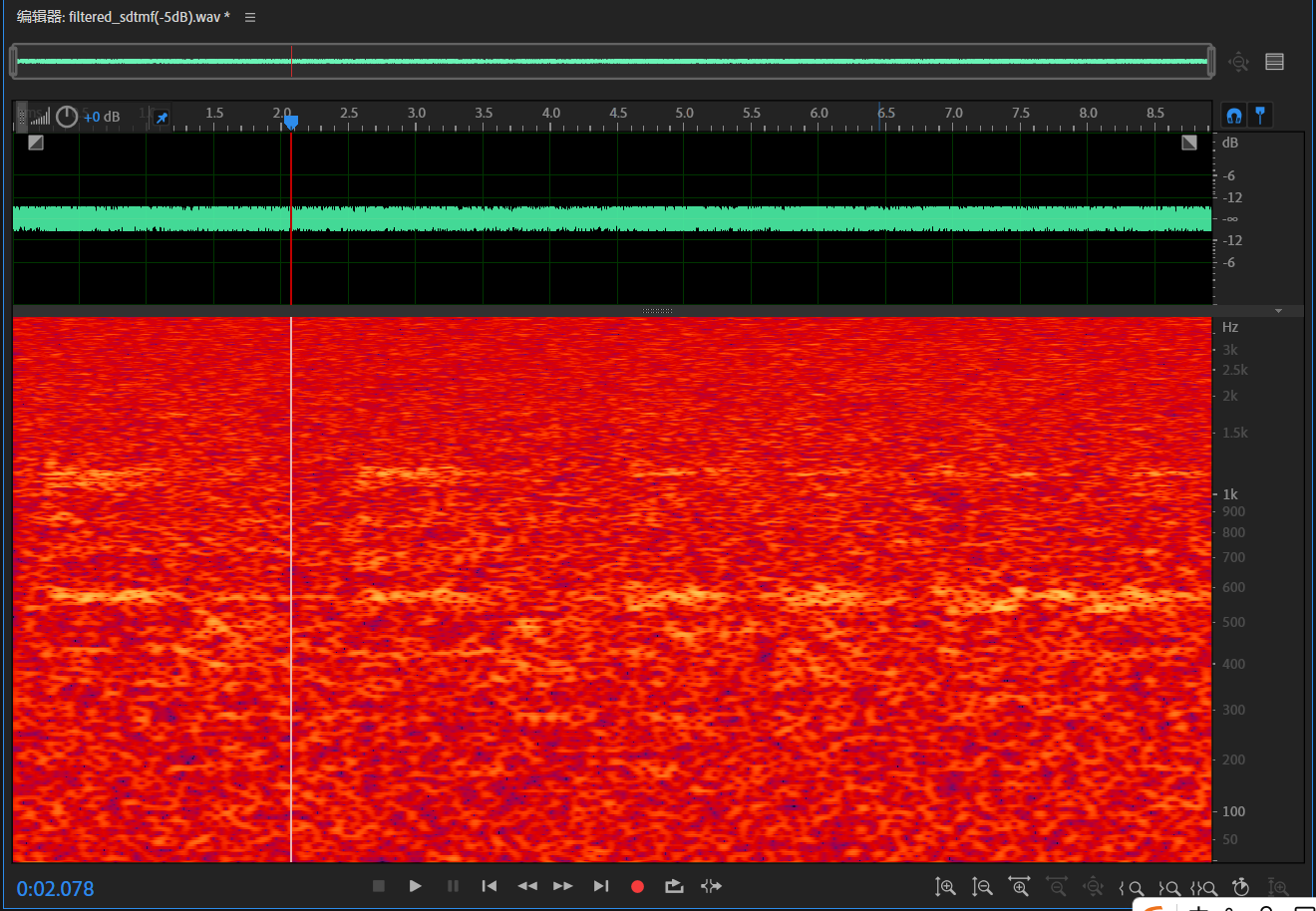
用Au下频谱,已经完全没有半点痕迹了!
两个音频相减输出,看看都滤掉了哪些内容
Matlab
%% DTMF滤除效果分析 - 音频相减对比
% 功能:计算原始音频与滤波后音频的差值,分析滤除的内容
% ====================================================
clear; clc; close all;
%% ================== 1. 读取音频文件 ==================
original_file = 'sdtmf(-5dB).wav';
filtered_file = 'filtered_sdtmf(-5dB).wav';
% 检查文件是否存在
if ~exist(original_file, 'file')
error('原始文件 %s 不存在', original_file);
end
if ~exist(filtered_file, 'file')
error('滤波后文件 %s 不存在,请先运行主程序生成该文件', filtered_file);
end
% 读取音频
[audio_orig, fs_orig] = audioread(original_file);
[audio_filt, fs_filt] = audioread(filtered_file);
% 检查采样率是否一致
if fs_orig ~= fs_filt
error('采样率不一致: 原始=%dHz, 滤波后=%dHz', fs_orig, fs_filt);
end
% 确保长度一致(如果长度不同,截取较短的)
min_len = min(length(audio_orig), length(audio_filt));
audio_orig = audio_orig(1:min_len);
audio_filt = audio_filt(1:min_len);
% 如果是立体声,转换为单声道
if size(audio_orig, 2) > 1
audio_orig = mean(audio_orig, 2);
end
if size(audio_filt, 2) > 1
audio_filt = mean(audio_filt, 2);
end
fs = fs_orig;
totalTime = min_len / fs;
fprintf('音频信息:\n');
fprintf(' 采样率: %d Hz\n', fs);
fprintf(' 时长: %.3f 秒\n', totalTime);
fprintf(' 采样点数: %d\n', min_len);
%% ================== 2. 计算差值信号 ==================
% 差值 = 原始信号 - 滤波后信号
% 理论上应该主要包含被滤除的DTMF信号
audio_diff = audio_orig - audio_filt;
% 计算统计信息
rms_orig = sqrt(mean(audio_orig.^2));
rms_filt = sqrt(mean(audio_filt.^2));
rms_diff = sqrt(mean(audio_diff.^2));
fprintf('\n信号能量统计:\n');
fprintf(' 原始信号 RMS: %.6f\n', rms_orig);
fprintf(' 滤波后 RMS: %.6f\n', rms_filt);
fprintf(' 差值信号 RMS: %.6f\n', rms_diff);
fprintf(' 能量衰减: %.2f dB\n', 20*log10(rms_filt/rms_orig));
fprintf(' 滤除能量占比: %.2f%%\n', (rms_diff^2 / rms_orig^2) * 100);
%% ================== 3. 保存差值音频 ==================
diff_filename = 'dtmf_removed_content.wav';
% 归一化到[-1,1]范围以便保存
audio_diff_normalized = audio_diff / max(abs(audio_diff) + eps);
audiowrite(diff_filename, audio_diff_normalized, fs);
fprintf('\n差值音频已保存为: %s\n', diff_filename);
fprintf('(已归一化到[-1,1]范围,实际幅值需要乘以 %.6f)\n', max(abs(audio_diff)));
% 同时保存未归一化的版本用于分析
diff_filename_raw = 'dtmf_removed_content_raw.wav';
audiowrite(diff_filename_raw, audio_diff, fs);
fprintf('原始幅值差值已保存为: %s\n', diff_filename_raw);
%% ================== 4. 可视化分析 ==================
figure('Position', [50, 50, 1400, 900], 'Name', 'DTMF滤除效果分析');
% 子图1:三个信号波形对比
subplot(4,1,1);
t = (0:min_len-1)/fs;
plot(t, audio_orig, 'b', 'LineWidth', 0.5);
hold on;
plot(t, audio_filt, 'r', 'LineWidth', 0.5);
plot(t, audio_diff, 'k', 'LineWidth', 0.5);
xlabel('时间 (秒)');
ylabel('幅度');
title('波形对比: 原始信号 vs 滤波后信号 vs 差值信号');
legend('原始信号', '滤波后信号', '差值(滤除内容)', 'Location', 'best');
grid on;
xlim([0, totalTime]);
% 子图2:差值信号放大显示(发现DTMF脉冲)
subplot(4,1,2);
plot(t, audio_diff, 'k', 'LineWidth', 0.5);
xlabel('时间 (秒)');
ylabel('幅度');
title('滤除内容(差值信号)- 应主要为DTMF脉冲');
grid on;
xlim([0, totalTime]);
hold on;
% 标记显著的脉冲区域
threshold = 0.05 * max(abs(audio_diff));
above_thresh = abs(audio_diff) > threshold;
% 找出连续区域并标记
changes = diff([0; above_thresh; 0]);
starts = find(changes == 1);
ends = find(changes == -1) - 1;
for i = 1:length(starts)
if ends(i) > starts(i)
ylims = ylim;
rectangle('Position', [t(starts(i)), ylims(1), ...
t(ends(i))-t(starts(i)), ylims(2)-ylims(1)], ...
'FaceColor', [0.9, 0.9, 0.8], 'EdgeColor', 'none');
end
end
% 子图3:频谱对比
subplot(4,1,3);
% 计算频谱
NFFT = 4096;
[P_orig, f] = pwelch(audio_orig, hann(NFFT), NFFT/2, NFFT, fs);
[P_filt, ~] = pwelch(audio_filt, hann(NFFT), NFFT/2, NFFT, fs);
[P_diff, ~] = pwelch(audio_diff, hann(NFFT), NFFT/2, NFFT, fs);
% 转换为dB
P_orig_dB = 10*log10(P_orig + eps);
P_filt_dB = 10*log10(P_filt + eps);
P_diff_dB = 10*log10(P_diff + eps);
plot(f, P_orig_dB, 'b', 'LineWidth', 1);
hold on;
plot(f, P_filt_dB, 'r', 'LineWidth', 1);
plot(f, P_diff_dB, 'k', 'LineWidth', 1);
xlabel('频率 (Hz)');
ylabel('功率谱密度 (dB/Hz)');
title('频谱对比');
legend('原始信号', '滤波后信号', '滤除内容', 'Location', 'best');
grid on;
xlim([0, 2000]); % DTMF频率都在2kHz以下
ylim([-100, 0]);
% 标记DTMF频率范围
DTMF_freqs = [697, 770, 852, 941, 1209, 1336, 1477];
for i = 1:length(DTMF_freqs)
line([DTMF_freqs(i), DTMF_freqs(i)], [-100, 0], ...
'Color', 'g', 'LineStyle', '--', 'LineWidth', 0.5);
end
% 子图4:时频谱对比(差值信号的时频分析)
subplot(4,1,4);
% 使用短时傅里叶变换
window = hann(256);
noverlap = 200;
nfft = 512;
[S, F, T_spec] = spectrogram(audio_diff, window, noverlap, nfft, fs);
imagesc(T_spec, F, 20*log10(abs(S) + eps));
axis xy;
xlabel('时间 (秒)');
ylabel('频率 (Hz)');
title('滤除内容的时频谱(应清晰显示DTMF频率成分)');
colorbar;
colormap('hot');
ylim([0, 2000]);
% 标记DTMF频率线
hold on;
for i = 1:length(DTMF_freqs)
line([T_spec(1), T_spec(end)], [DTMF_freqs(i), DTMF_freqs(i)], ...
'Color', 'c', 'LineStyle', '--', 'LineWidth', 0.5);
end
sgtitle('DTMF滤除效果分析 - 差值信号显示被移除的DTMF成分', 'FontSize', 14);
%% ================== 5. 逐段分析DTMF滤除效果 ==================
% 使用滑动窗口检测差值信号中的能量峰值,找出DTMF事件
window_ms = 50;
win_len = round(window_ms * fs / 1000);
step_len = round(win_len / 2);
n_windows = floor((min_len - win_len) / step_len) + 1;
window_energy = zeros(n_windows, 1);
for i = 1:n_windows
idx = (i-1)*step_len + 1 : (i-1)*step_len + win_len;
window_energy(i) = sum(audio_diff(idx).^2);
end
% 归一化能量
window_energy = window_energy / max(window_energy);
time_energy = ((0:n_windows-1)*step_len + win_len/2) / fs;
figure('Position', [50, 50, 1000, 400]);
plot(time_energy, window_energy, 'k', 'LineWidth', 1);
xlabel('时间 (秒)');
ylabel('归一化能量');
title('滤除内容能量包络 - 峰值对应DTMF事件');
grid on;
xlim([0, totalTime]);
% 找出能量峰值(DTMF事件)
[peaks, peak_locs] = findpeaks(window_energy, 'MinPeakHeight', 0.3, 'MinPeakDistance', 50/fs*1000);
hold on;
plot(time_energy(peak_locs), peaks, 'ro', 'MarkerSize', 8, 'MarkerFaceColor', 'r');
for i = 1:length(peak_locs)
text(time_energy(peak_locs(i)), peaks(i) + 0.05, sprintf('DTMF事件 %d', i), ...
'HorizontalAlignment', 'center', 'FontSize', 9);
end
legend('能量包络', '检测到的DTMF事件', 'Location', 'best');
%% ================== 6. 统计分析报告 ==================
fprintf('\n========================================\n');
fprintf(' 滤除内容统计分析\n');
fprintf('========================================\n');
% 计算差值信号的峰值与RMS比
peak_diff = max(abs(audio_diff));
crest_factor_diff = peak_diff / rms_diff;
fprintf('\n差值信号特征:\n');
fprintf(' 峰值幅度: %.6f\n', peak_diff);
fprintf(' 波峰因数: %.2f (说明信号具有脉冲特性)\n', crest_factor_diff);
% 分析频率成分
% 在DTMF频率附近搜索能量峰值
fprintf('\n差值信号的主要频率成分:\n');
[pxx, f_pxx] = pwelch(audio_diff, hann(4096), 2048, 8192, fs);
[peaks_freq, locs_freq] = findpeaks(pxx, 'SortStr', 'descend', 'NPeaks', 10);
for i = 1:length(locs_freq)
freq_val = f_pxx(locs_freq(i));
% 检查是否是DTMF频率
is_dtmf = any(abs(freq_val - DTMF_freqs) < 10);
if is_dtmf
marker = ' ✓ (DTMF)';
else
marker = '';
end
fprintf(' %.1f Hz: %.2f dB%s\n', freq_val, 10*log10(peaks_freq(i)+eps), marker);
end
% 能量分布分析
freq_bands = [0, 300, 697, 941, 1209, 1477, 2000, 4000, fs/2];
band_names = {'次声/低频', '语音基频', 'DTMF低频', 'DTMF过渡', 'DTMF高频', '语音中频', '语音高频', '超高频'};
fprintf('\n各频段能量分布:\n');
total_energy = sum(audio_diff.^2);
% 注意:需要重新计算P_diff,因为之前的P_diff可能还在工作区
[P_diff_band, f_band] = pwelch(audio_diff, hann(4096), 2048, 8192, fs);
for i = 1:length(freq_bands)-1
band_mask = (f_band >= freq_bands(i)) & (f_band < freq_bands(i+1));
band_energy = sum(P_diff_band(band_mask)) * (f_band(2)-f_band(1));
band_percent = band_energy / total_energy * 100;
fprintf(' %s (%.0f-%.0fHz): %.2f%%\n', ...
band_names{i}, freq_bands(i), freq_bands(i+1), band_percent);
end
% 额外分析:DTMF频段能量占比
dtmf_band_mask = (f_band >= 697) & (f_band <= 1477);
dtmf_energy = sum(P_diff_band(dtmf_band_mask)) * (f_band(2)-f_band(1));
dtmf_percent = dtmf_energy / total_energy * 100;
fprintf('\nDTMF频段(697-1477Hz)能量占比: %.2f%%\n', dtmf_percent);
fprintf('========================================\n');
fprintf('分析完成!\n');
fprintf('\n总结: 差值信号主要包含:\n');
fprintf(' 1. DTMF拨号音成分(697-1477Hz范围内的双频信号)\n');
fprintf(' 2. 滤波器过渡带引入的微小残留\n');
fprintf(' 3. 边界效应产生的瞬态成分\n');
fprintf(' 4. 理论上不应包含语音或其他声音信号\n');
%% ================== 7. 额外:试听提示 ==================
fprintf('\n========================================\n');
fprintf('试听提示:\n');
fprintf('========================================\n');
fprintf('1. 播放 "dtmf_removed_content.wav" - 应该听到清晰的DTMF拨号音\n');
fprintf('2. 播放 "filtered_sdtmf(-5dB).wav" - 应该听不到拨号音,只有背景音\n');
fprintf('3. 播放原始文件对比效果\n');
fprintf('\n如果差值音频中听到语音成分,说明滤波器过度滤除了语音信号\n');
fprintf('如果差值音频中DTMF音不清晰,说明滤波器效果不佳\n');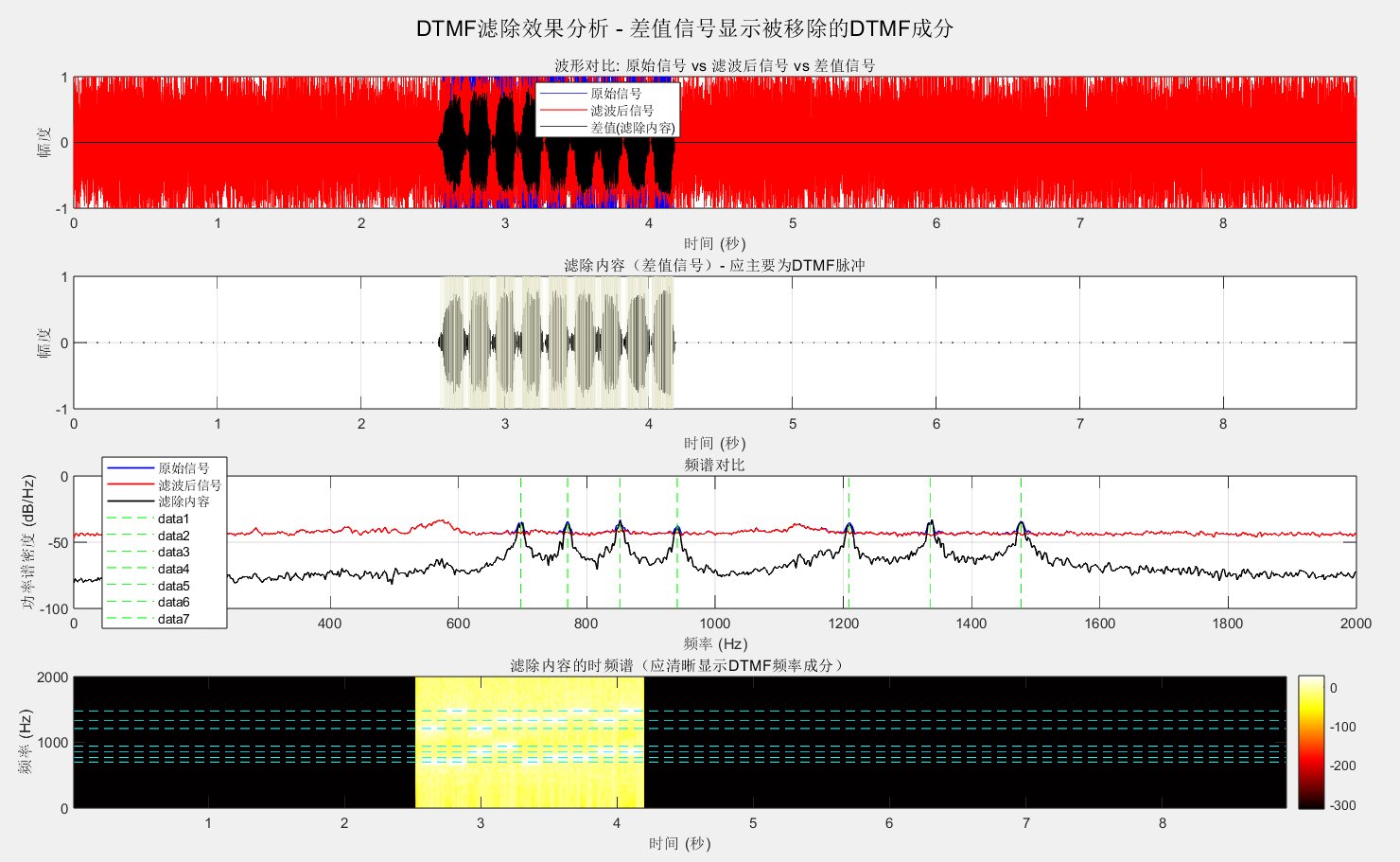
其实还是滤掉了蛮多的其他内容的,毕竟是时域的。
在Au上直接像这样,把频谱上的很亮的区域选中删除,是频域滤波,但是这样单独听起来很怪,可能噪声多了某个频率空了一块的听感就不明显了吧。
总地来说,AI生成的代码滤除效果还是很好的,就不在这里纠结了。
音乐降噪
太伟大了,现在我们得到了没有嘟嘟嘟的噪音和哈利路亚。
那噪音应该究竟怎么滤除呢?按降噪处理方式划分音频噪声类别
一、谱减法类可处理噪声(适合:采样降噪 / 频谱降噪)
核心特征:频谱特征稳定、长时间持续、统计特性不变
- 白噪声(设备底噪、电路热噪)
- 粉噪声(风扇、空调持续环境噪)
- 工频谐波噪声(50Hz/60Hz 交流嗡鸣、电源干扰)
- 固定带宽电子嘶噪(线材屏蔽不良、声卡底噪)
降噪方式:采集噪声样本→频谱相减 / 阈值压制代表工具:AU 降噪、Audacity 采样降噪、传统频谱滤波器
二、滤波类可处理噪声(适合:频段切除 / 陷波 / 高低切)
核心特征:能量集中在固定频段,与人声 / 有效信号频段分离
- 低频超低频干扰(地颤、共振、强风低频轰鸣)
- 高频窄带杂噪(尖锐蜂鸣、单一频率啸叫)
- 工频单频噪(固定 50Hz/100Hz 纯哼声)
- 超高频数码毛刺噪(低码率压缩残噪)
降噪方式:低切 / 高切、带阻滤波、陷波滤波、均衡衰减
(拨号声其实属于这一类,上面已经处理)
三、瞬态脉冲类噪声(适合:瞬态修复 / 插值消瑕)
核心特征:短时、突发、不连续、无持续频谱
- 咔哒声、爆音、点击噪
- 接触不良脉冲干扰、数字跳点
- 磕碰震动瞬态冲击、按键杂音
降噪方式:瞬态检测、波形插值、自动修复、阈值削峰代表工具:iZotope RX De-click、爆音修复模块
四、空间混响类噪声(适合:去混响 / 房间矫正)
核心特征:不属于外来杂音,是空间反射造成的声学畸变
- 房间残响、空旷回声
- 墙面反射拖尾、密闭空间浑浊音
降噪方式:混响抑制、时域衰减、房间脉冲响应抵消、AI 去混响
五、非线性畸变噪声(适合:修复类算法)
核心特征:信号本身被破坏,不是额外叠加噪音
- 削波失真(录音过载破音)
- 量化噪声、低比特数字失真
- 压缩失真、码率不足产生的糊噪
降噪方式:波形重塑、软削波修复、谐波补偿
六、非稳态复杂环境噪声(适合:AI 智能降噪)
核心特征:频谱随时变化、无固定规律、混合多声源
- 车流、人流、嘈杂背景多人说话
- 杂乱风声、雨声、自然混合环境音
- 随机电器杂声、时变设备干扰
降噪方式:AI 语义分割、人声 / 有效信号特征提取、智能掩膜降噪代表工具:剪映 AI 降噪、Adobe Podcast、RX AI 降噪
七、机械摩擦 / 近场杂讯(适合:专用模块降噪)
核心特征:近麦克风物理摩擦、气流类干扰
- 衣物摩擦、线材摩擦噪
- 呼吸气流、喷麦、唇齿口水音
降噪方式:摩擦声专用抑制、气流滤波、齿音消除(De-ess)
具体看下来,matlab比较方便做的,其实只有第一类
哈利路亚的"哈"大概是从0.4s开始的,因此前面的可以作为噪声样本。
代码------
Matlab
%% ====================================================
% 音频降噪 - 简化版谱减法(零填充边缘,无谱下限,无平滑)
% 功能:使用经典谱减法去除音频中的背景噪声
% 特点:零填充边缘、无谱下限、无时间平滑、简单直接
% ====================================================
clear; clc; close all;
%% ================== 参数配置区域 ==================
% 所有可调参数都在这里,修改后会自动保存不同版本的文件
% ----- 输入输出参数 -----
input_filename = 'filtered_sdtmf(-5dB).wav'; % 输入音频文件名
output_folder = 'denoised_results/'; % 输出文件夹(自动创建)
enable_auto_naming = true; % 是否启用自动文件名(true=根据参数命名,false=固定名称)
% ----- STFT参数(短时傅里叶变换)-----
win_len = 2048; % 窗口长度(采样点)
% 推荐值:
% 256 - 时间分辨率高,适合瞬态声音(噪声变换得很快,听感上像咕噜咕噜在冒泡,很奇怪)
% 512 - 平衡选择,适合一般语音
% 1024 - 频率分辨率高,适合稳态噪声
% 2048 - 降噪平滑,适合平稳噪声(这个感觉最好)
hop_ratio = 0.15; % 步长比例(相对于窗口长度)
% hop = win_len * hop_ratio
% 推荐值:(音频很短,算得够快)
% 0.25 - 75%重叠,重建质量最好,计算量大
% 0.5 - 50%重叠,标准选择
% 0.75 - 25%重叠,计算快,可能有块效应
% 1 不重叠------喜提机关枪音色
nfft = win_len; % FFT点数(通常等于win_len,可设置更大以提高频率分辨率)
% ----- 谱减法参数 -----
alpha = 1.5; % 过减法因子(降噪强度)
% 推荐值:
% 0.5-1.0 - 轻度降噪,保留细节
% 1.0-1.5 - 中度降噪,适合一般场景
% 1.5-2.5 - 较强降噪,适合高噪声
% 2.5-4.0 - 强力降噪,可能有音乐噪声
% ----- 噪声估计参数 -----
noise_duration = 0.3; % 噪声估计时长(秒),取音频前段
% 推荐值:(注意不能短过sfft的周期)
% 0.3 - 短时噪声
% 0.3-0.5 - 中等时长
% 0.5-1.0 - 稳定噪声估计
% 实际上是音频0.4s左右已经开始"哈"了,所以最好取到这个之前
% ----- 后处理参数 -----
normalize_output = true; % 是否归一化输出(true=归一化到[-1,1],false=保持原始幅度)
% ----- 绘图参数 -----
show_plots = true; % 是否显示对比图
save_plots = true; % 是否保存图片
plot_spectrogram = true; % 是否显示时频谱图
%% ================== 初始化 ==================
% 创建输出文件夹
if ~exist(output_folder, 'dir')
mkdir(output_folder);
end
% 计算实际步长
hop = round(win_len * hop_ratio);
% 生成参数描述字符串(用于文件名)
param_str = sprintf('w%d_h%d_a%.1f', win_len, hop, alpha);
% 显示参数信息
fprintf('\n========================================\n');
fprintf('谱减法降噪处理\n');
fprintf('========================================\n');
fprintf('参数配置:\n');
fprintf(' 【STFT参数】\n');
fprintf(' 窗口长度: %d 点 (%.1f ms)\n', win_len, win_len/44100*1000);
fprintf(' 步长: %d 点 (%.1f ms, %.0f%% 重叠)\n', hop, hop/44100*1000, (1-hop/win_len)*100);
fprintf(' FFT点数: %d\n', nfft);
fprintf(' 【谱减法参数】\n');
fprintf(' 过减法因子 α: %.1f\n', alpha);
fprintf(' 【噪声估计】\n');
fprintf(' 噪声时长: %.1f 秒\n', noise_duration);
fprintf('========================================\n');
%% ================== 读取音频 ==================
% 检查文件是否存在
if ~exist(input_filename, 'file')
error('文件 %s 不存在,请检查文件名和路径', input_filename);
end
% 读取音频
[x, fs] = audioread(input_filename);
% 立体声转单声道
if size(x, 2) > 1
x = mean(x, 2);
end
% 归一化到[-1,1](可选)
if normalize_output
x = x / max(abs(x));
end
% 音频信息
total_time = length(x) / fs;
fprintf('\n音频信息:\n');
fprintf(' 文件: %s\n', input_filename);
fprintf(' 采样率: %d Hz\n', fs);
fprintf(' 时长: %.2f 秒\n', total_time);
fprintf(' 采样点数: %d\n', length(x));
%% ================== 噪声估计 ==================
% 取音频前段作为噪声样本
noise_samples = round(noise_duration * fs);
noise_len = min(noise_samples, length(x));
noise = x(1:noise_len);
fprintf('\n噪声估计:\n');
fprintf(' 使用前 %.2f 秒 (%.0f 个采样点)\n', noise_len/fs, noise_len);
%% ================== 谱减法降噪 ==================
output = spectralSubtraction_clean(x, noise, fs, win_len, hop, nfft, alpha);
%% ================== 后处理 ==================
if normalize_output
output = output / max(abs(output) + eps);
end
%% ================== 保存结果 ==================
% 生成输出文件名
if enable_auto_naming
output_filename = sprintf('%sdenoised_%s.wav', output_folder, param_str);
else
output_filename = sprintf('%sclean.wav', output_folder);
end
audiowrite(output_filename, output, fs);
fprintf('\n========================================\n');
fprintf('降噪完成!\n');
fprintf('========================================\n');
fprintf('输出文件: %s\n', output_filename);
fprintf('原始长度: %d, 输出长度: %d\n', length(x), length(output));
% 计算降噪效果指标
rms_orig = sqrt(mean(x.^2));
rms_out = sqrt(mean(output.^2));
fprintf('\n降噪效果指标:\n');
fprintf(' 原始信号 RMS: %.6f\n', rms_orig);
fprintf(' 降噪后 RMS: %.6f\n', rms_out);
fprintf(' RMS变化: %.2f dB\n', 20*log10(rms_out/rms_orig + eps));
%% ================== 可视化 ==================
if show_plots
% 创建图形窗口
if plot_spectrogram
figure('Position', [50, 50, 1400, 1000], 'Name', '谱减法降噪效果');
else
figure('Position', [50, 50, 1200, 800], 'Name', '谱减法降噪效果');
end
min_len = min(length(x), length(output));
t = (0:min_len-1)/fs;
% 子图1:原始信号波形
subplot(3,2,1);
plot(t, x(1:min_len), 'b', 'LineWidth', 0.5);
title('原始信号波形', 'FontSize', 11);
xlabel('时间 (s)');
ylabel('幅度');
grid on;
xlim([0, total_time]);
% 子图2:降噪后信号波形
subplot(3,2,2);
plot(t, output(1:min_len), 'r', 'LineWidth', 0.5);
title('降噪后信号波形', 'FontSize', 11);
xlabel('时间 (s)');
ylabel('幅度');
grid on;
xlim([0, total_time]);
% 子图3:频谱对比
subplot(3,2,3);
nfft_plot = 4096;
[X_f, f_plot] = pwelch(x(1:min_len), hann(nfft_plot), nfft_plot/2, nfft_plot, fs);
[Y_f, ~] = pwelch(output(1:min_len), hann(nfft_plot), nfft_plot/2, nfft_plot, fs);
plot(f_plot, 10*log10(X_f+eps), 'b', 'LineWidth', 1);
hold on;
plot(f_plot, 10*log10(Y_f+eps), 'r', 'LineWidth', 1);
xlabel('频率 (Hz)');
ylabel('功率谱密度 (dB)');
title('频谱对比', 'FontSize', 11);
legend('原始', '降噪后', 'Location', 'best');
grid on;
xlim([0, min(4000, fs/2)]);
ylim([-120, -20]);
% 子图4:噪声抑制量
subplot(3,2,4);
noise_reduction = 10*log10(X_f ./ (Y_f + eps));
plot(f_plot, noise_reduction, 'g', 'LineWidth', 1);
xlabel('频率 (Hz)');
ylabel('噪声抑制 (dB)');
title('各频率降噪量', 'FontSize', 11);
grid on;
xlim([0, min(4000, fs/2)]);
ylim([0, 30]);
hold on;
% 标记平均降噪量
avg_reduction = mean(noise_reduction(f_plot > 100 & f_plot < 3000));
line([0, min(4000, fs/2)], [avg_reduction, avg_reduction], ...
'Color', 'r', 'LineStyle', '--', 'LineWidth', 1);
text(100, avg_reduction + 1, sprintf('平均: %.1f dB', avg_reduction), 'FontSize', 9);
% 子图5:时频谱对比(可选)
if plot_spectrogram
subplot(3,2,5);
spectrogram(x, 256, 128, 256, fs, 'yaxis');
title('原始信号时频谱', 'FontSize', 11);
colorbar;
caxis([-100, -20]);
subplot(3,2,6);
spectrogram(output, 256, 128, 256, fs, 'yaxis');
title('降噪后时频谱', 'FontSize', 11);
colorbar;
caxis([-100, -20]);
end
% 总标题
sgtitle(sprintf('谱减法降噪效果对比 (窗口=%d点, α=%.1f, 参数: %s)', ...
win_len, alpha, param_str), 'FontSize', 13);
% 保存图片
if save_plots
plot_filename = sprintf('%sdenoised_%s.png', output_folder, param_str);
saveas(gcf, plot_filename);
fprintf('图片已保存: %s\n', plot_filename);
end
end
fprintf('\n处理完成!\n');
fprintf('========================================\n');
%% ================== 核心算法函数 ==================
function output = spectralSubtraction_clean(x, noise, fs, win_len, hop, nfft, alpha)
% 简化版谱减法(零填充边缘,无谱下限,无时间平滑)
%
% 输入:
% x - 输入信号(列向量)
% noise - 噪声样本(列向量)
% fs - 采样率(Hz)
% win_len - 窗口长度(采样点)
% hop - 步长(采样点)
% nfft - FFT点数
% alpha - 过减法因子
%
% 输出:
% output - 降噪后的信号
% 创建汉明窗
window = hamming(win_len);
% ===== 步骤1:零填充边缘 =====
% 计算需要的填充长度,让最后一个窗口也能完整处理
num_frames_original = floor((length(x) - win_len) / hop) + 1;
last_frame_end = (num_frames_original - 1) * hop + win_len;
needed_pad = max(0, last_frame_end - length(x));
if needed_pad > 0
% 使用零填充
x_padded = [x; zeros(needed_pad, 1)];
else
x_padded = x;
end
% ===== 步骤2:STFT分析 =====
% 计算信号的STFT
[X_mag, X_phase, ~] = stft_manual(x_padded, window, hop, nfft);
% 计算噪声的STFT
[N_mag, ~, ~] = stft_manual(noise, window, hop, nfft);
% ===== 步骤3:噪声功率谱估计 =====
% 直接平均,无时间平滑
noise_pow = mean(N_mag.^2, 2);
% 扩展噪声功率谱到与信号相同的时间帧数
noise_pow_expanded = repmat(noise_pow, 1, size(X_mag, 2));
% ===== 步骤4:应用谱减法(核心公式)=====
% 经典谱减法公式:|Y|^2 = max(|X|^2 - α·|N|^2, 0)
X_pow = X_mag.^2;
out_pow = max(X_pow - alpha * noise_pow_expanded, 0);
% ===== 步骤5:重建幅度谱 =====
out_mag = sqrt(out_pow);
% ===== 步骤6:ISTFT合成 =====
output_padded = istft_manual(out_mag .* exp(1j * X_phase), window, hop, nfft, length(x_padded));
% ===== 步骤7:裁剪填充部分 =====
output = output_padded(1:length(x));
end
function [magnitude, phase, num_frames] = stft_manual(x, window, hop, nfft)
% 手动实现的STFT(短时傅里叶变换)
%
% 输入:
% x - 输入信号
% window - 窗函数
% hop - 步长
% nfft - FFT点数
%
% 输出:
% magnitude - 幅度谱(频率 x 时间)
% phase - 相位谱(频率 x 时间)
% num_frames - 时间帧数
x = x(:);
win_len = length(window);
% 计算帧数
num_frames = floor((length(x) - win_len) / hop) + 1;
% 预分配内存
S = zeros(nfft, num_frames);
% 对每一帧进行加窗和FFT
for i = 1:num_frames
start_idx = (i-1) * hop + 1;
end_idx = start_idx + win_len - 1;
frame = x(start_idx:end_idx) .* window;
S(:, i) = fft(frame, nfft);
end
% 返回幅度谱和相位谱
magnitude = abs(S);
phase = angle(S);
end
function x = istft_manual(S_stft, window, hop, nfft, original_length)
% 手动实现的ISTFT(逆短时傅里叶变换)
%
% 输入:
% S_stft - STFT频谱矩阵
% window - 窗函数
% hop - 步长
% nfft - FFT点数
% original_length - 原始信号长度
%
% 输出:
% x - 重建的时域信号
win_len = length(window);
num_frames = size(S_stft, 2);
% 计算输出信号长度
output_len = (num_frames - 1) * hop + win_len;
x = zeros(output_len, 1);
window_sum = zeros(output_len, 1);
% 对每一帧进行IFFT和重叠相加
for i = 1:num_frames
% IFFT
frame = real(ifft(S_stft(:, i), nfft));
frame = frame(1:win_len);
% 加窗
frame = frame .* window;
% 重叠相加
start_idx = (i-1) * hop + 1;
end_idx = start_idx + win_len - 1;
x(start_idx:end_idx) = x(start_idx:end_idx) + frame;
window_sum(start_idx:end_idx) = window_sum(start_idx:end_idx) + window.^2;
end
% 归一化(补偿窗函数的能量损失)
window_sum(window_sum < eps) = 1;
x = x ./ window_sum;
% 裁剪到原始长度
if length(x) > original_length
x = x(1:original_length);
elseif length(x) < original_length
x = [x; zeros(original_length - length(x), 1)];
end
end注释都在代码里,很详细。参数没有调出特别满意的结果,哈利路亚的信噪比太低了。
感觉这个还稍微好一点------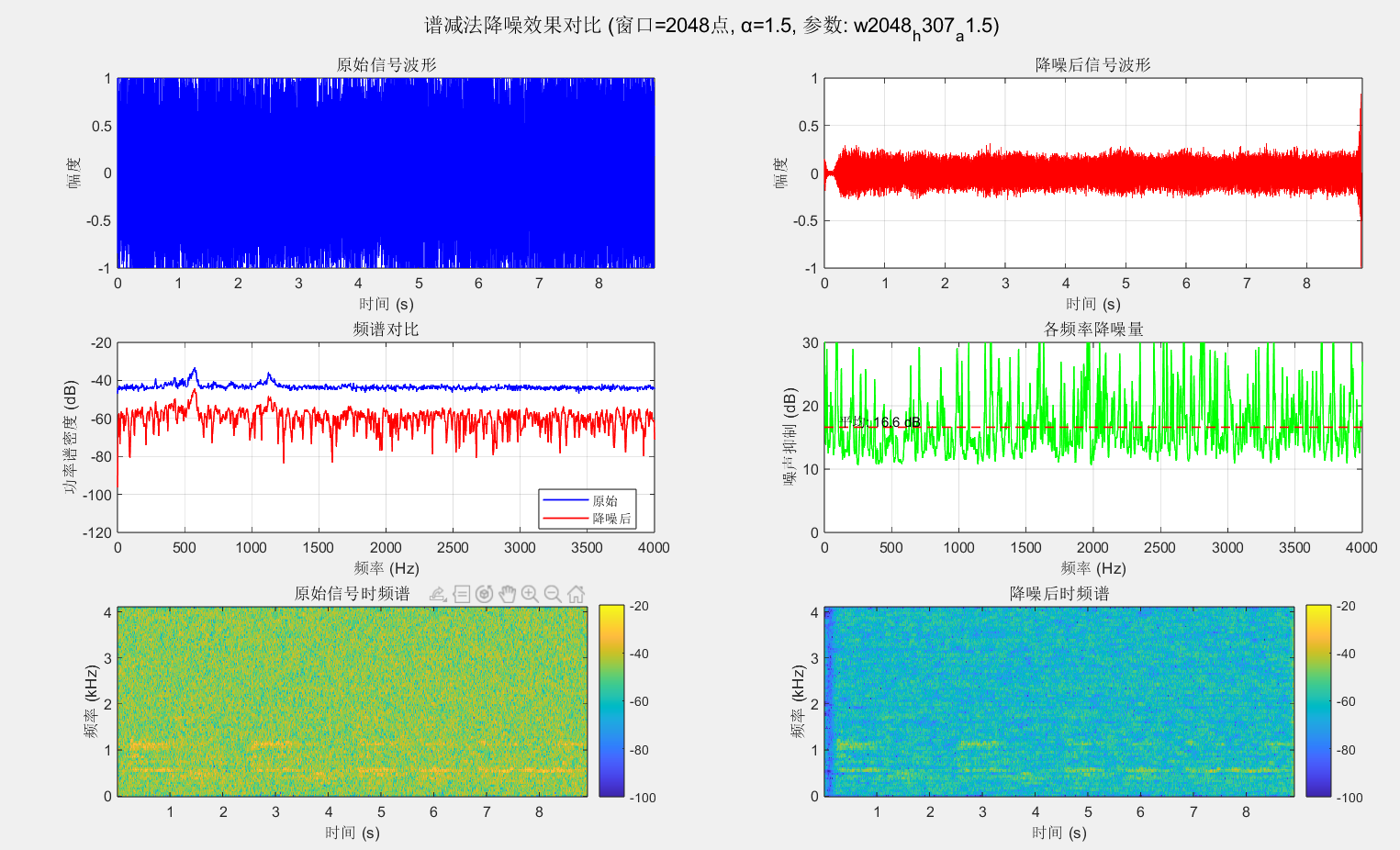
STFT降噪参数的经验与听感影响
1. 窗口长度
窗口长度决定了时频分辨率的权衡。
-
窗口设得很大:频率分辨率高,频谱看起来更连续,听感上比较自然、平滑。但缺点是时间分辨率低,高频的沙沙声(类噪声成分)会多一些,对瞬态噪声的去除能力较差。整体听感自然,但降噪不够"干净"。
-
窗口设得很小 :时间分辨率高,能够快速响应噪声的变化,对瞬态噪声的去除效果很好。但代价是频率分辨率下降,处理后会引入一种咕噜咕噜(musical noise) 的人工痕迹,听感上很不自然,像是信号在"挣扎"。
实践中需要在"干净"与"自然"之间做取舍。
2. 步长/重叠比例
步长控制着相邻窗口之间的重叠程度,直接影响帧间过渡的平滑度。
-
重叠较小(步长大) :窗口之间关联性弱,听感上会出现明显的一块一块、窗口交替切换的感觉。如果完全不重叠,效果就像机关枪一样"突突突突",每个窗口独立发声,毫无连续性可言。
-
重叠较大(步长小) :窗口之间过渡平滑,帧与帧之间的信息得以延续,听感更加连贯、自然。缺点是计算量会增加,但对于现代计算机和通常的短音频来说,计算量几乎可以忽略不计。
推荐采用较大的重叠(如75%),优先保证听感质量。
3. 谱减法系数 α
谱减法系数 α 本质上是降噪的"强度"控制旋钮。
-
α 越大 :降噪力度越强,更多的能量被判定为噪声并减除。但问题是,谱减法并不是特异性地识别噪声------它只是根据噪声估计谱进行全局减法。因此,α 过大时,不仅噪声被去掉,信号的细节、弱能量成分也会被一并抹除。
-
α 需要平衡:太小则降噪不足,太大则损伤信号。合适的 α 值是在"噪声残留"与"信号失真"之间找到一个可接受的折中点。
没有一个 α 能适应所有情况,需要根据具体音频内容和对音质的要求进行微调。
核心经验总结
| 参数 | 偏大/多 | 偏小/少 |
|---|---|---|
| 窗口长度 | 自然但沙沙声多 | 干净但有咕噜声 |
| 重叠比例 | 流畅自然(计算量略高) | 块状感强,甚至机关枪感 |
| 谱减系数 α | 降噪彻底,但损伤信号 | 保留信号,但噪声残留 |
最终结论 :这些参数没有绝对的"最优值",只有针对特定场景和听感偏好的"较优组合"。调试时应当以耳听为最终判据,而非盲目追求某一个数值指标。
关于无参考降噪评估的思考
当前降噪效果评估中常见的做法是:用算法识别出"噪声",减除后得到"纯净信号",再据此计算信噪比。然而,这里存在一个根本性的逻辑困境------噪声本身正是由同一套算法定义的。
阈值设低一点,被判定为噪声的成分就多一点,信噪比"提升"的幅度自然更大。这种自证式的评估,本质上是王婆卖瓜,缺乏独立的客观依据。
对于没有 Ground Truth 的盲降噪任务,任何数值化指标都难以摆脱这一循环论证的阴影。
相比之下,人耳的主观听感评判反而更具说服力。原因在于:
人脑本身就是一台精密而强大的神经网络。经过专业训练的乐手、录音师或语音专家,能够在强噪声背景下准确地感知、分离并理解音频中的有效信息------这是数十年生物进化与专业训练共同塑造的感知能力。
而粗暴去噪的产物,即便在纸面上获得了更高的信噪比,往往已经付出了惨重的代价:
-
高频细节被平滑抹除
-
瞬态响应变得模糊
-
动态范围被压缩
-
音乐性和自然感被破坏
这些损失,是简单的能量比值无法反映的,但人耳却往往能一耳识破。
因此,在缺乏真实参考的情况下,与其迷信一个可以被任意操纵的数值指标,不如回归到听感本身。盲听测试、专家评审、主观感受------这些看似"不硬核"的评价方式,反而可能是最诚实的答案。