目录
[一、 AI 训练算力资源标准图谱](#一、 AI 训练算力资源标准图谱)
[二、 任务匹配与算力效能指南](#二、 任务匹配与算力效能指南)
[1. 预训练阶段 (Pre-training) ------ "算力黑洞"](#1. 预训练阶段 (Pre-training) —— “算力黑洞”)
[2. 指令微调阶段 (SFT/LoRA) ------ "成本敏感区"](#2. 指令微调阶段 (SFT/LoRA) —— “成本敏感区”)
[3. 推理阶段 (Serving/RAG) ------ "延迟与吞吐"](#3. 推理阶段 (Serving/RAG) —— “延迟与吞吐”)
[三、 一线/二线资源配置标准图谱](#三、 一线/二线资源配置标准图谱)
[四、 给架构师的资源选择决策树](#四、 给架构师的资源选择决策树)

如果您喜欢此文章,请收藏、点赞、评论,谢谢,祝您快乐每一天。
在 AI 工程实践中,构建"算力梯队"的核心目标是匹配性价比与任务规模。盲目使用顶级 GPU 进行小模型微调是资源浪费,而尝试用消费级显卡训练百亿参数模型则是徒劳。
以下是一份 AI 训练产区算力资源标准图谱,将算力分为一线主力(核心训练/研发)与二线补充(推理/微调/验证),并对任务匹配度进行拆解。
一、 AI 训练算力资源标准图谱
| 梯队 | 类型 | 代表显卡 (GPU) | 核心特性 | 典型应用场景 |
|---|---|---|---|---|
| 一线主力 | HPC/集群级 | H100, A100, B200 | 极致 FP8/BF16 算力,NVLink 高带宽互联 | 预训练 (Pre-training), SFT 大模型全量微调 |
| 一线主力 | 高性能专业卡 | A800, L40S, 4090D | 均衡算力与内存带宽,支持集群化 | LoRA 微调, RAG 向量库构建, 中型模型训练 |
| 二线补充 | 高性价比/推理卡 | L4, T4, A10 | 低功耗,高推理吞吐,内存适中 | 模型服务 (Inference), 小规模数据增强, 验证测试 |
| 二线补充 | 桌面/边缘卡 | RTX 4090/3090 | 高核心频率,大显存 (24GB) | 开发环境原型, 个人实验, 轻量级 Fine-tuning |

二、 任务匹配与算力效能指南
1. 预训练阶段 (Pre-training) ------ "算力黑洞"
- 任务属性:极高吞吐、极高计算强度、超大规模并行。
- 算力匹配 :必须是一线集群级 (H100/A100)。
- 工程标准:单机 8 卡仅是起点,需通过 RDMA 网络实现万卡集群互联。
- 关键指标:MFU (模型浮点算力利用率)。若 MFU < 30%,说明网络互联或数据载入存在严重瓶颈,应优先优化分布式存储 (如 Lustre/JuiceFS) 而非堆砌显卡。
2. 指令微调阶段 (SFT/LoRA) ------ "成本敏感区"
- 任务属性:内存占用高(激活值),计算强度中等。
- 算力匹配 :
- 全量微调 (Full Fine-tuning):建议一线高性能卡 (A800/A100)。
- 高效微调 (LoRA/QLoRA):二线显存大卡 (RTX 4090/3090) 表现极佳,24GB 显存足以覆盖 7B-14B 参数模型的 LoRA 微调。
- 工程标准:FlashAttention 必须开启,以降低显存冗余。
3. 推理阶段 (Serving/RAG) ------ "延迟与吞吐"
- 任务属性:延迟敏感、IO 密集型、显存带宽限制。
- 算力匹配 :二线补充 (L4/T4)。
- 工程标准:优先采用模型量化 (Int8/Int4) 或 FP8 格式。推理卡应关注 TensorRT-LLM 或 vLLM 的吞吐量优化,而非单卡原始浮点算力。
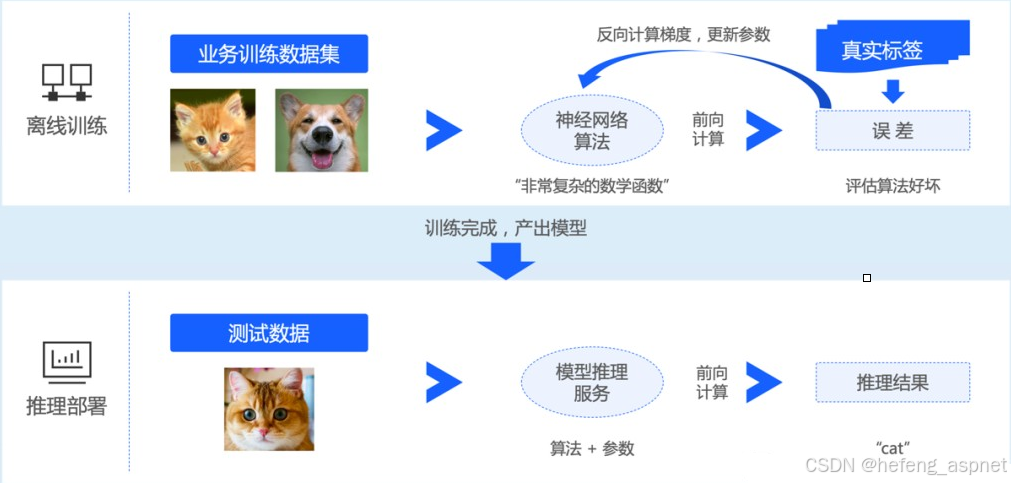
三、 一线/二线资源配置标准图谱
一线产区(资源池标准:集群化与高性能)
- 架构定义:采用计算与存储分离架构。
- 资源标准 :
- 显存需求:80GB 以上显存规格为主,以支持更大 Batch Size。
- 互联标准:必须配备 400Gbps+ InfiniBand 网络。
- 调度优化:使用 Kubernetes + Volcano 调度,实现 GPU 细粒度切分与算力平摊。
- 资源配比 :训练资源与推理资源配比通常为 1:4。
二线产区(资源池标准:轻量化与多模态)
- 架构定义:采用 Serverless 化容器部署。
- 资源标准 :
- 单卡限制:RTX 3090/4090 不建议大规模组集群(稳定性差,P2P 通信受限)。
- 服务形态:采用按需(On-demand)实例,支持弹性扩容。
- 主要任务:模型评测、数据清洗、Prompt Engineering 实验、小型垂直模型部署。

四、 给架构师的资源选择决策树
- 问:该模型需要训练多久?
- < 24 小时:直接租用云端一线卡(按需实例)。
-
1 周:自建/合租一线算力集群(降低 TCO)。
- 问:显存够不够?
- 显存不足是训练中断的最主要原因。如果单卡显存不足,优先选择 模型并行 (Pipeline Parallelism) 或 DeepSpeed ZeRO 技术,而不是简单换卡。
- 问:瓶颈在哪里?
- 如果 GPU 利用率一直处于低位:检查数据预处理是否在 CPU 侧阻塞?检查
num_workers设置是否合理? - 如果是通信延迟过高:检查是否开启了多机多卡训练,以及是否在同一网络分区(VPC)内?
- 如果 GPU 利用率一直处于低位:检查数据预处理是否在 CPU 侧阻塞?检查
总结
"算力梯队"的核心不在于卡有多贵,而在于架构能否承载相应的训练范式。
- 一线资源:是生产力,是用于构建技术壁垒的"重型武器",应追求极致的集群并行效率。
- 二线资源:是敏捷力,是用于快速试错和低成本落地的"轻骑兵",应追求极致的响应效率和单机性价比。
如果您喜欢此文章,请收藏、点赞、评论,谢谢,祝您快乐每一天。