AnimateDiff 简介:它在 AI 视频生成领域处于什么位置?
摘要
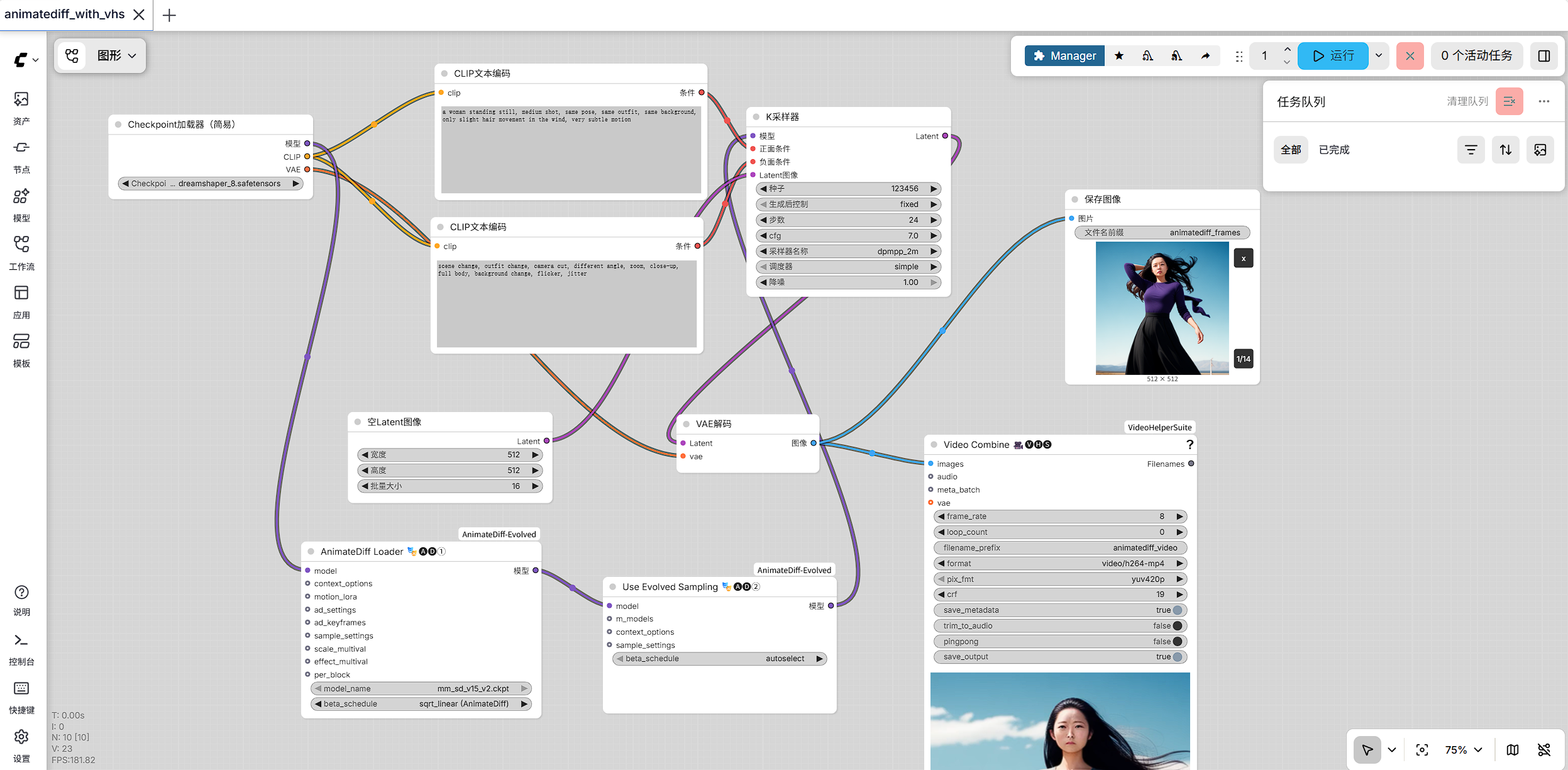
AnimateDiff 是 Stable Diffusion 视频生态中一个非常有代表性的开源方案。它的核心价值,不是简单把多张图片拼成视频,而是尝试在采样阶段引入时间维度,让多帧之间具备连续关系。以一套典型工作流为例,AnimateDiff 可以通过 ADE_AnimateDiffLoaderGen1 加载 mm_sd_v15_v2.ckpt,再通过 ADE_UseEvolvedSampling 进入时序采样流程,结合 EmptyLatentImage 中的 512×512、16 帧设置,以及 VHS_VideoCombine 以 8 fps、video/h264-mp4 输出视频 。本文从历史发展、竞品分析、行业定位、优势与局限等角度,对 AnimateDiff 做一篇简要梳理,并讨论它在当前热门 AI 短片创作中的定位。
一、什么是 AnimateDiff?
在 Stable Diffusion 生态中,大家最熟悉的是文生图和图生图。但如果目标从"生成一张图"变成"生成一段视频",问题就会立刻复杂起来。因为视频不只是多了几张图,而是多了一个非常关键的维度:
时间。
AnimateDiff 可以理解为一种让 Stable Diffusion 具备"时间建模能力"的方案。
普通的 Stable Diffusion 更擅长生成单张图片,而 AnimateDiff 的目标是让模型在生成多帧时,能够考虑帧与帧之间的关系,从而输出一段连续的短视频或动画。
简单来说:
- 普通 SD 更关注"单张图像质量"
- AnimateDiff 更关注"多帧之间是否连续、是否像在动"
这也是为什么 AnimateDiff 在 AI 视频生成领域一直有较高关注度------它是很多开源视频工作流的起点。
二、AnimateDiff 的基本工作方式
AnimateDiff 的核心不在于"最后导出一个视频文件",而在于:
在采样阶段,就把一组 latent 当作连续帧来处理。
从一个典型的最小工作流来看,AnimateDiff 通常包括以下几个关键部分:
EmptyLatentImage设置画面尺寸和帧数,例如512 × 512、16帧ADE_AnimateDiffLoaderGen1加载 motion module,例如mm_sd_v15_v2.ckptADE_UseEvolvedSampling将处理后的模型接入时序采样流程KSampler执行真正的扩散去噪VAEDecode把 latent 解码成图像VHS_VideoCombine以8 fps、video/h264-mp4的形式输出视频
这说明 AnimateDiff 的本质不是"把 16 张图拼起来",而是:
在生成过程中,就试图让这 16 帧之间保持某种时间关联。
这也是它和普通批量出图最大的区别。
三、AnimateDiff 的历史发展
AnimateDiff 的出现,并不是一个孤立事件,而是整个 Stable Diffusion 生态向视频方向发展的自然结果。
1. 从文生图走向文生视频
Stable Diffusion 开源之后,图像生成能力快速普及。很快,大家就开始思考一个更进一步的问题:
- 能不能让图动起来?
- 能不能在本地完成视频生成?
- 能不能把现有 SD 模型扩展到短视频场景?
在这个背景下,AnimateDiff 的价值开始显现。它不是完全推翻原有 SD 体系,而是在 SD 基础上增加 motion module,使模型从"只会出图"转向"可以生成短视频"。
2. 从逐帧重绘到时序建模
在 AnimateDiff 之前,很多 AI 视频工作流本质上是:
- 抽帧
- 每帧重绘
- 再拼成视频
这种方式虽然可行,但缺点非常明显:
- 帧间不稳定
- 镜头容易跳
- 角色容易漂
- 视频更像一组相似图片,而不是连续画面
AnimateDiff 的意义就在于,它尝试把"时间一致性"引入扩散采样过程,而不是只在输出阶段做视频拼接。
3. 随着 ComfyUI 普及而走向工作流化
ComfyUI 兴起后,AnimateDiff 很快成为开源视频工作流中的常见模块。
例如在一套典型工作流里:
ADE_AnimateDiffLoaderGen1用于加载mm_sd_v15_v2.ckptADE_UseEvolvedSampling负责进入时序采样VHS_VideoCombine负责视频封装输出
这意味着 AnimateDiff 已经从"论文概念"变成了真正可落地、可调试、可集成的工作流组件。
四、AnimateDiff 的核心价值
如果只用一句话概括 AnimateDiff 的价值,可以这样理解:
它是开源 Stable Diffusion 视频生态中,最早一批真正把"单图生成"推进到"时序生成"的关键方案。
它的价值主要体现在以下几个方面。
1. 本地可运行,门槛相对较低
相比很多闭源视频平台,AnimateDiff 的优势之一是:
- 可本地部署
- 可深度调参
- 可与现有 SD 模型体系结合
- 对已有 SD 使用经验的用户更友好
对于已经熟悉 ComfyUI、ControlNet、LoRA、IPAdapter 的用户来说,AnimateDiff 的接入成本并不算高。
2. 非常适合作为 AI 视频学习入口
如果目标是学习 AI 视频生成原理,而不是一上来就追求商业级成片,那么 AnimateDiff 是一个很好的入口。
因为它能帮助理解:
- 视频和单图的本质差别
- 为什么帧与帧之间需要连续性
- 为什么
EmptyLatentImage里的16更接近 16 帧,而不是普通 batch - 为什么
VHS_VideoCombine只是封装视频,而真正的运动是在前面的采样阶段决定的
3. 可以与开源生态深度组合
AnimateDiff 的另一个优势是,它并不是孤立存在的。
它可以与很多开源工具结合,例如:
- ControlNet
- IPAdapter
- LoRA
- 图生视频工作流
- 视频重绘工作流
- 后期补帧和超分工具
这使它更像一个"工作流模块",而不是一个单独的视频产品。
五、竞品分析:AnimateDiff 和其他视频方案相比如何?
如果把 AnimateDiff 放到当前 AI 视频生成市场里,它面对的竞争对象大致可以分成两类:
1. 开源视频方案
例如:
- Stable Video Diffusion(SVD)
- 各类图生视频模型
- 视频重绘工作流
- 基于 SD 生态的其他 motion module 方案
2. 闭源视频平台
例如:
- Runway
- Pika
- Luma
- Gen-3
- Kling
- 可灵、即梦等平台
这两类对手的比较方式完全不同。
(一)AnimateDiff vs 开源视频模型
和 SVD、图生视频模型相比,AnimateDiff 的特点是:
优势
- 更贴近 Stable Diffusion 原有生态
- 更容易融入 ComfyUI 节点工作流
- 更适合作为教学与研究对象
- 与 LoRA、ControlNet、IPAdapter 兼容空间更大
- 本地可控性强
劣势
- 纯文生视频容易发散
- 长视频一致性不足
- 大动作表现有限
- 需要较强的工作流理解和调参能力
简单理解:
AnimateDiff 更像"开源视频工作流底层模块",而不是一键出片型模型。
(二)AnimateDiff vs Runway / Pika / Kling / Gen-3
如果和这些成熟的视频平台相比,AnimateDiff 的短板会更明显。
闭源平台的优势
- 上手成本低
- 产品完成度高
- 更接近"开箱即用"
- 生成结果往往更接近完整成片
- 对普通创作者更友好
AnimateDiff 的优势
- 本地部署能力
- 高度可控
- 可以深度定制
- 能与私有模型、LoRA、角色体系整合
- 更适合技术研究与工作流搭建
所以两者并不是简单的"谁替代谁"的关系,而更像是:
- 闭源平台偏产品化
- AnimateDiff 偏工具化、模块化、工作流化
如果目标是快速出热门视频、尽量少调参,那么闭源平台通常更高效。
如果目标是自己掌握流程、搭建本地链路、做教程和研究,那么 AnimateDiff 依然很有价值。
六、AnimateDiff 在视频生成领域的地位
如果用一句话概括它在行业中的位置:
AnimateDiff 不是当前效果最强的视频模型,但它依然是开源 AI 视频工作流中非常具有代表性的基础方案。
它的重要性主要体现在三个方面。
1. 它是很多人进入 AI 视频领域的第一站
对很多使用 ComfyUI 的用户来说,AnimateDiff 往往是从"会出图"走向"会做视频"的第一步。
它帮助使用者第一次真正理解:
- 视频不是多出几张图
- 帧间连续性为什么重要
- 为什么视频工作流比单图复杂得多
2. 它是开源工作流中的常用组件
在大量视频工作流中,AnimateDiff 仍然是常见模块,尤其适合:
- 短片段生成
- 人物微动作
- 角色动态化
- 二次元短动画
- 风格化动态内容
3. 它是"图像生成"通往"视频生成"的典型过渡层
AnimateDiff 的意义,不一定体现在它是否始终最强,而在于它建立了一种重要认知:
从单图生成迈向视频生成,真正需要解决的是时间关系,而不是单纯增加输出张数。
这也是它在技术发展中的长期价值所在。
七、AnimateDiff 的局限在哪里?
虽然 AnimateDiff 很重要,但它的短板也非常明显。
1. 纯文生视频容易发散
如果只依赖 prompt 生成视频,通常容易出现:
- 镜头漂移
- 构图跳变
- 背景变化
- 服装变化
- 角色一致性不足
这也是很多人第一次使用 AnimateDiff 时,会觉得生成结果更像"一组风格相近的图片",而不是一段稳定视频。
2. 更适合短片段,而不是长镜头
AnimateDiff 通常更适合:
- 短时长视频
- 微动作
- 头发、衣摆等细微运动
- 轻微镜头推进
- 简单动态化内容
如果目标是:
- 长时长叙事视频
- 大动作镜头
- 高一致性剧情短片
那么仅靠 AnimateDiff 往往不够。
3. 调参与工作流门槛较高
AnimateDiff 的可控性很强,但这也意味着:
- 需要理解 motion module
- 需要理解采样逻辑
- 需要理解视频输出节点
- 需要理解稳定性为什么会出问题
这对新手来说,比直接使用闭源平台要难得多。
八、未来怎么看?
从趋势上看,AnimateDiff 很可能不会成为"唯一的视频生成方案",但它仍然会长期存在于以下几个方向。
1. 作为开源视频工作流模块继续存在
尤其在 ComfyUI 体系中,AnimateDiff 依然有很强的组合价值。
未来即便出现更多更强的视频模型,它也很可能继续作为:
- 开源工作流组件
- 动态化模块
- 教学模块
- 短视频实验模块
存在于整个生态中。
2. 与一致性方案结合变得更重要
AnimateDiff 自身的短板,未来更可能通过外围能力来弥补,例如:
- IPAdapter
- FaceID
- InstantID
- ControlNet
- 角色 LoRA
- 视频补帧和后期处理
也就是说,它未来未必会以"单独一个模型解决一切"的方式演进,而更可能作为系统中的一个组成部分长期存在。
3. 在学习和研究场景中持续有价值
即使未来闭源视频模型越来越强,AnimateDiff 依然适合:
- 做教学
- 做研究
- 做工作流拆解
- 做本地实验
- 理解视频生成的基本原理
这种价值不会因为新模型出现就消失。
九、现在还适不适合做热门 AI 短片?
答案是:
适合学习,适合实验,适合做某一类短片,但不适合把它当成"最省心的一站式热门短片生产工具"。
更具体地说。
适合的场景
- AI 视频学习
- 角色轻微动态
- 二次元短片段
- 风格化动态视频
- 图像动态化
- 视频重绘链路中的一环
不太适合的场景
- 一上来就做高质量商业短剧
- 长时长叙事短片
- 强剧情连续镜头
- 完全依赖单一模型做热门短片
原因很简单:
当前热门 AI 短片,往往依赖的是完整生产流程,而不是单一 AnimateDiff。
真正能做出"像样短片"的,通常是这些能力的组合:
- AnimateDiff 或图生视频模型
- ControlNet 控结构
- IPAdapter / FaceID 锁角色
- 分镜拆段
- 补帧
- 剪辑
- 配音
- 音效
- 调色和包装
所以 AnimateDiff 可以是短片制作中的重要一环,但不能把全部期待都放在它身上。
十、结论:现在做 AI 热门短片,AnimateDiff 应该怎么定位?
如果把 AnimateDiff 放到当前 AI 视频创作环境里来看,更合适的定位不是"最终成片工具",而是:
开源视频工作流中的基础能力模块、学习入口和可控生成组件。
一方面,它仍然很有价值。
在一个典型工作流中,可以通过 ADE_AnimateDiffLoaderGen1 加载 mm_sd_v15_v2.ckpt,再通过 ADE_UseEvolvedSampling 进入时序采样链路,同时配合 EmptyLatentImage 中的 512 × 512、16 帧设置,以及 VHS_VideoCombine 以 8 fps、video/h264-mp4 输出视频 。这说明 AnimateDiff 非常适合:
- 学习 AI 视频生成原理
- 搭建本地可控工作流
- 做短片段、轻动作、风格化动态内容
- 作为图生视频、视频重绘、一致性控制链路中的一个环节
但另一方面,如果目标是当前热门 AI 短片,尤其是那种:
- 镜头组织完整
- 角色高度一致
- 叙事稳定
- 可以直接用于运营或商业传播
那么 AnimateDiff 通常不应该被当成唯一方案。
更现实的理解方式是:
AnimateDiff 负责短动态生成和时序能力补充,而真正决定热门短片完成度的,往往是分镜设计、一致性控制、后期补帧、剪辑、音频与整体包装。
因此,现阶段更合理的定位是:
AnimateDiff 适合学、适合用、也适合进入生产流程,但更适合作为"模块"和"能力层",而不是单独承担热门短片全部制作任务。
如果目标是做热门 AI 短片,更推荐的思路是:
- 先用 AnimateDiff 学会视频生成的基本逻辑
- 再结合图生视频、ControlNet、IPAdapter 和角色一致性方案
- 最后通过剪辑和后期,把多个短片段整合成真正可发布的内容
换句话说:
AnimateDiff 更像是 AI 短片制作流程中的发动机之一,而不是整辆车本身。