系列直播回放及材料链接:CANN - 开源代码托管,代码协作 - AtomGit | GitCode
以前写算子要走写‑跑‑调‑测 四步循环,常常调半天也达不到性能要求。
这次 CANN 把算子编程、运行时调度、性能调优三个环节一次性升级,助力开发者体验升级:
- 几行代码实现Transpose、Pad和Slice等搬运算子
- 一次下发,批量调度,算子跑得更稳
- 调试时直接看到卡在哪儿
从此不再为"搬运太多、同步太慢、调优找不着点"而头疼。
1. 算子编程易用性提升
1.1 一次搬运搞定多维数据
以前 GM → UB 的非连续搬运要写三段 DataCopy 再手动循环,代码又长又难调。
现在只要一次 DataCopy(配合几行配置)就能完成 Slice**、** Pad 、 Broadcast 、 Transpose 四种常见操作:
| 场景 | 传统实现 | NDDMA 一键实现 |
|---|---|---|
| 2‑D Slice | for + DataCopy 3 次 | DataCopy<T,2>(dst, src, params) |
| 2‑D Pad | 手动填充 + DataCopy | loopLpSize/loopRpSize 参数自动补齐 |
| 2‑D Broadcast | 多次拷贝 + 条件判断 | loopSize + loopDstStride 一次搬运 |
| 2‑D Transpose | 两层循环 + 临时缓冲 | loopSrcStride/loopDstStride 直接转置 |
核心概念:
- LoopInfo描述每维的stride、size、左/右Pad,一次指令即可完成Slice / Pad / Broadcast / Transpose。
- NdDmaDci()刷新DCI,保证DMA引擎读取最新的局部寄存器配置,几乎没有额外开销。
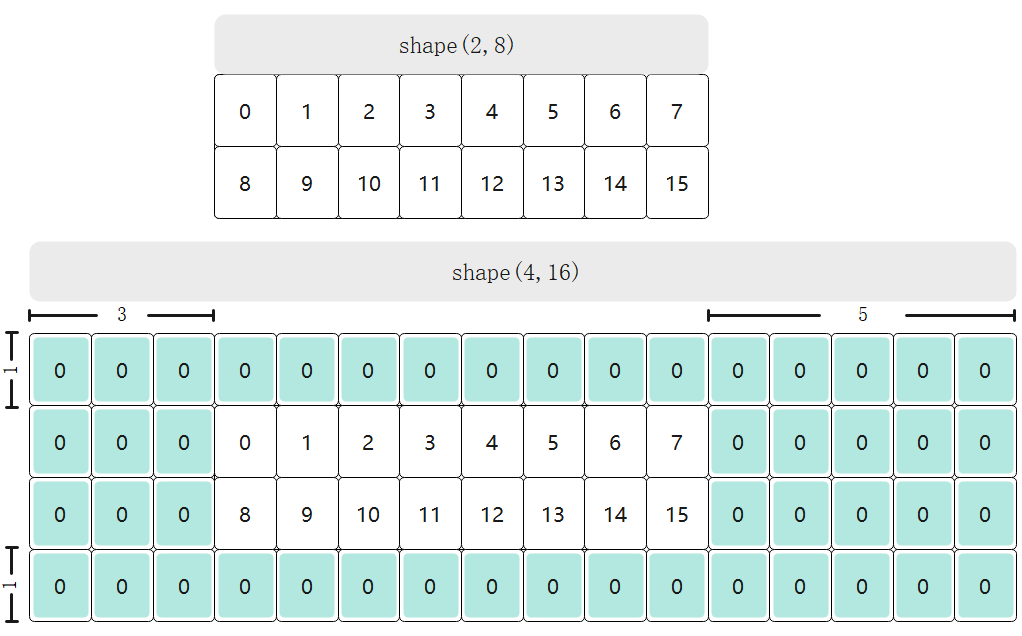
cpp
// xGmShape:[2, 8],搬运8列2行数据,左Padding 3,上Padding 1,右Padding 5,下Padding 1,xLocalShape:[4, 16]
AscendC::NdDmaLoopInfo<2> loopInfo{{1, 8}, {1, 16}, {8, 2}, {3, 1}, {5, 1}};
// padding的值为0
AscendC::NdDmaParams<T, 2> params{loopInfo, 0};
// 刷新cache
AscendC::NdDmaDci();
// 使用默认参数,也可以不传
static constexpr AscendC::NdDmaConfig dmaConfig;
AscendC::DataCopy<T, 2, dmaConfig>(xLocal, xGm, params);只需要三行代码(声明 NdDmaLoopInfo、构造 NdDmaParams、调用 DataCopy),即可在 GM & UB之间完成任意多维、非连续、带Pad 的搬运。代码不再被搬运细节淹没,算子核心逻辑一目了然。
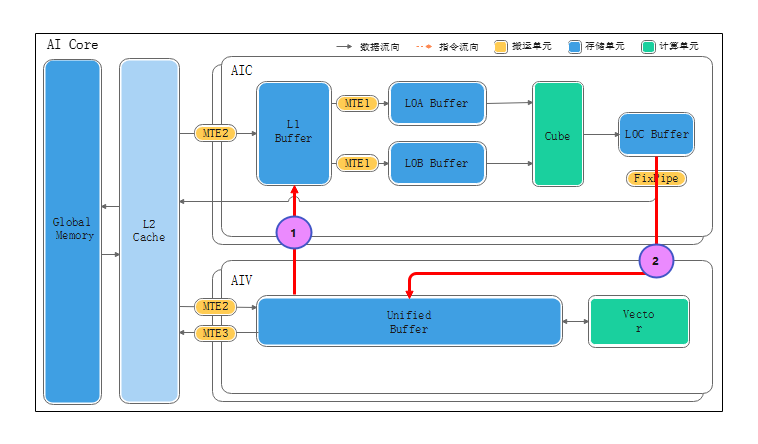
1.2 矩阵算子直连通路
在旧架构下,矩阵结果必须 写回 GM → 再读回 UB,导致两次访存、两次同步,性能受限。
CANN 新增 UB ↔ L1 ↔ L0C 直连通路,并配合 Fixpipe 指令:
- 搬入:DataCopy<LocalTensor, LocalTensor> 把数据直接从 UB 送到 L1。
- 搬出:Fixpipe 把 L0C 直接写回 UB,一次完成后处理。
跨核同步也改进为 CrossCoreSetFlag / CrossCoreWaitFlag,从微秒级降到亚纳秒级,等待时间几乎可以忽略。
cpp
// AIC代码示例(关注计算流和核间同步,忽略核内同步)
__aicore__ inline void CubeOperator(const LocalTensor<DstT> &ubBuffer, bool transpose) {
// ...
// 1. 搬运和加载阶段忽略
// ...
// 3. 计算阶段: 使用MMad进行计算
MmadParams mmadParams = { /*...*/ };
Mmad(l0C, l0A, l0B, mmadParams);
// 4. 搬出阶段:将计算结果搬出到UB中
FixpipeParamsC310<CO2Layout::ROW_MAJOR> fixpipeParams(nLength, mLength, mLength, nLength);
fixpipeParams.params = { 1, 0, 0 };
// 调用Fixpipe直接输出到UB中
Fixpipe<DstT, L0cT, CFG_ROW_MAJOR>(ubBuffer, l0C, fixpipeParams);
// 5. 通知Vector
CrossCoreSetFlag<SYNC_MODE4, PIPE_FIX>(SYNC_AIV_AIC_FLAG);
}
// AIV代码示例(关注计算流和核间同步,忽略核内同步)
__aicore__ inline void CubeOperator(const LocalTensor<DstT> &ubBuffer, bool transpose) {
// ...
// 1. 等待Cube通知
CrossCoreWaitFlag<SYNC_MODE4, PIPE_V>(SYNC_AIV_AIC_FLAG);
// ...
// 3. 使用UBBuffer进行计算处理
// Vector计算
Cast();
}- 核间同步:借助全新的CrossCoreSetFlag / CrossCoreWaitFlag机制,核之间的协同已经从原先的微秒级阻塞迈入亚纳秒级响应的范畴,极大压缩了跨核等待的时间窗口,使算子调度的时序更加紧凑、流畅。
- 算子流水:通过引入UB & L1 & L0C的直连搬运通路,算子在执行过程中不再需要重复的 "写回‑读回"循环,数据流动实现了真正的无缝衔接,从而显著提升整体吞吐效率,尤其在ResNet‑50、YOLO‑v5等典型网络的端到端运行中能够感受到明显的性能提升。
1.3 代际兼容与API演进------一次迁移,兼容全平台
基础API(兼容API)接口面向所有算子,在910系列和950等不同芯片上都保持语义不变、签名不变,只要算子使用了基础API,编译器、运行时以及硬件的底层实现细节会在内部自动适配,开发者无需关心每代芯片的寄存器宽度、DMA通道数或内部缓存结构的差异。
基础API(ISASI API)是面向特定指令集或硬件特性的扩展接口,例如NDDMA多循环搬运、Fixpipe直连通路、跨核同步模式 3 等新指令。这些API不保证跨代兼容------它们的出现往往是因为底层硬件提供了全新功能,只有在对应芯片上才能被真正调度。通过宏或编译选项,开发者可以在同一个算子代码中同时保留基础调用和ISASI调用,编译器会在目标芯片不支持时自动降级为基础实现,确保算子仍能跑通。
在过去,芯片升级往往意味着要对搬运路径、寄存器布局甚至内部缓存大小进行大幅度改写,导致项目的维护成本呈指数级增长。CANN通过统一的CMake变量 --npu-arch,把这种硬件差异抽象成编译选项。
cpp
target_compile_options(my_op PRIVATE
$<$<COMPILE_LANGUAGE:ASC>:--npu-arch=dav-2201> # 910B
# $<$<COMPILE_LANGUAGE:ASC>:--npu-arch=dav-3510> # 950(只需打开注释)
)- 同一套源代码:算子文件、头文件、测试脚本全部保持不动。
- 一次编译,多个目标:只需在CMakeLists.txt中切换dav-2201→dav-3510,即可生成针对 910B/910C 或950的二进制。
- 内部自动适配:编译器在解析 --npu-arch 时,会依据目标芯片的指令集描述文件(ISA JSON)自动选择对应的NdDmaConfig默认值、寄存器对齐方式以及内存访问最优策略。
2. 运行时接口易用性提升
2.1 KernelLaunch高阶特性
- 传统:使用 <<<>>>方式下发算子虽然简单易用,但无法使用Runtime的高阶特性。
- 升级后:使用aclrtLaunchKernelWithHostArgs下发算子,并启用 aclrtLaunchKernelCfg 参数,可以提供 batch调度、超时报错l1 等特性。
cpp
// 加载算子二进制
aclrtBinHandle bin;
aclrtBinaryLoadFromFile("add_custom.o", nullptr, &bin);
// 通过kernel名获取kernel句柄
aclrtFuncHandle add_custom;
aclrtBinaryGetFunction(bin, "add_custom", &add_custom);
// 申请算子所需的tensor内存
void *d_x, *d_y, *d_z;
// 下发算子任务
uint32_t numBlocks = 48;
void* args[] = {d_x, d_y, d_z};
size_t argsSize = 3 * sizeof(void*);
aclrtLaunchKernelWithHostArgs(add_custom, numBlocks, stream, nullptr, args, argsSize, nullptr, 0);典型场景:
- Batch调度(schemMode=1)确保所有核同时空闲后才启动算子,解决全核同步算子(如大矩阵乘)在多流并发场景下的抢占冲突。
- 超时时间(timeoutUs)在模型推理服务中防止异常算子长时间占用AICORE资源,当执行时间超过阈值则Runtime接口报错。
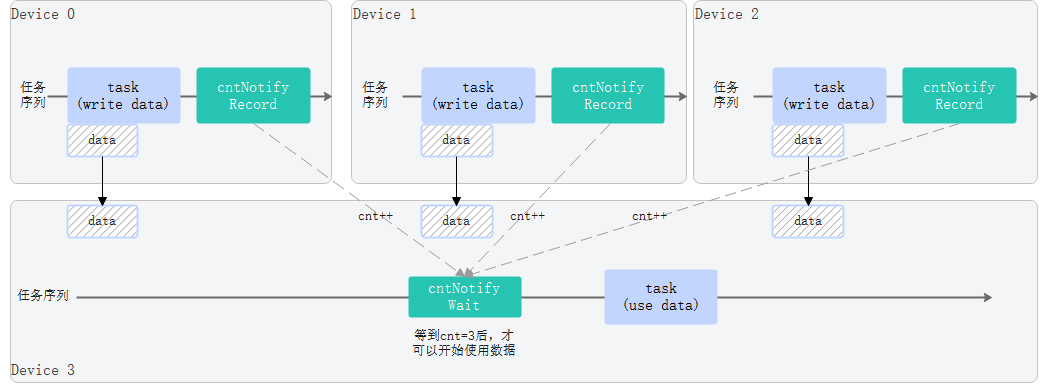
2.2 Count Notify简化1等N的同步编程
Count Notify是Ascend 950引入的一个新特性,可以在多流/多卡场景下,简化1等N的同步编程。
cpp
// 创建count notify
aclrtCntNotify cntNotify;
aclrtCntNotifyCreate(&cntNotify, 0);
// 设置count notify为累加模式
aclrtCntNotifyRecordInfo info = {ACL_RT_CNT_NOTIFY_RECORD_ADD_MODE, 1};
// stream0将count notify计数+1
aclrtCntNotifyRecord(cntNotify, stream0, &info);
// stream1将count notify计数+1
aclrtCntNotifyRecord(cntNotify, stream1, &info);
// stream2将count notify计数+1
aclrtCntNotifyRecord(cntNotify, stream2, &info);
// stream3等待stream0/1/2的record都到齐
aclrtCntNotifyWaitInfo info = {ACL_RT_CNT_NOTIFY_WAIT_EQUAL_MODE, 3, 0, true, 0};
aclrtCntNotifyWaitWithTimeout(cntNotify, stream3, &info);- count notify record可以配置为赋值、累加、位或、位与等模式。
- count notify wait可以配置为小于、等于、大于、大于等于、掩码等模式。
3. 调优 Profiling易用性提升
3.1 msprof + MindStudio Insight双引擎
- msprof 采样频率从100 Hz → 10 kHz,实现每0.1 ms捕获一次片上带宽。
- 支持采集新增CCU通信算子内部负载。
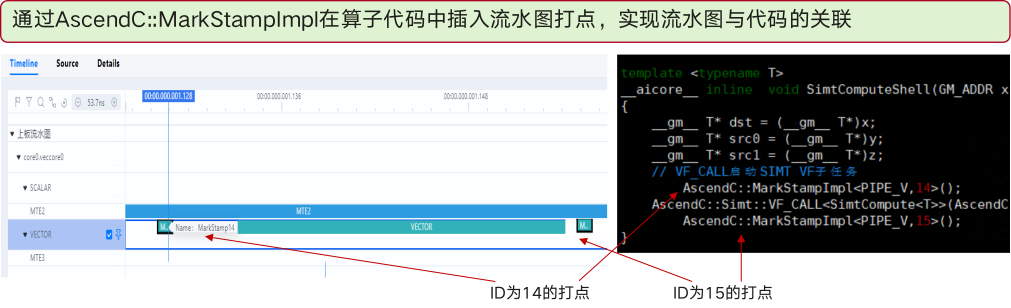
- MindStudio Insight将Timeline、Roofline、Cache热力图与源码打点(AscendC::MarkStampImpl)无缝关联,开发者只要在算子代码里插入MarkStamp,即可在UI中看到每一步搬运、每一次算子调用的时序图。
核心价值:
- 解决搬运瓶颈 :直接看到NDDMA的实际吞吐与理论带宽的偏差,快速定位stride对齐或Pad过大的根因。
- 解决计算瓶颈:CCU、SIMT、Vector三类计算单元的指令占比一目了然,帮助决定是算子拆分还是指令调度。
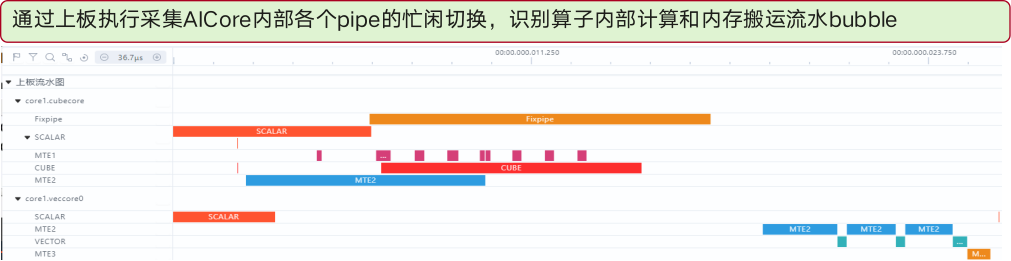
3.2 Pipe流水图 & Bubble检测
通过Pipe采样,系统自动标记busy → idle的切换点。配合MarkStamp,用户可以快速定位算子内部的流水bubble(如搬运与计算交叉等待),并在代码层面加入双向流水(DataCopy ↔ Mmad)的交叉调度。
在ResNet‑101的Bottleneck Block中,原始实现把数据搬运放在计算之前,导致Pipe 0在搬运阶段大段空闲,整体流水线出现明显的"空洞"。通过Pipe交叉调度------即在搬运完成后立刻触发Mmad计算,使得搬运与计算在同一流水线上交错进行,流水线的利用率得到显著提升,整体算子执行更趋于连续、紧凑。
3.3 SIMT寄存器分析 & Stall Sampling
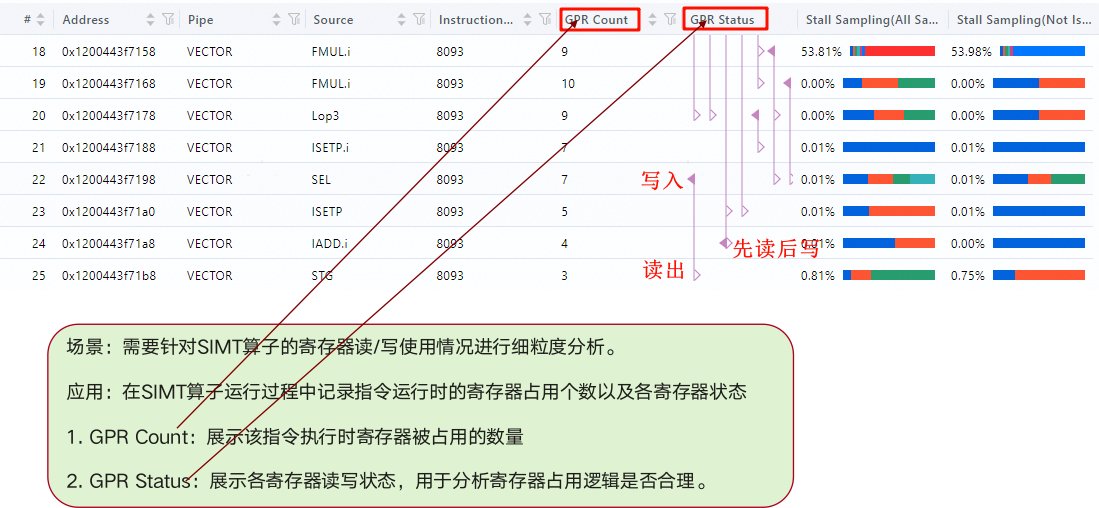
- SIMT寄存器分析:实时展示每条指令的GPR占用与读写状态,帮助判断寄存器溢出与指令重排的必要性。
- Stall Sampling:采样9种硬件stall状态(如Memory‑Dependency、Execution‑Dependency、Branch‑Mispredict),并以热力图形式呈现,定位最频繁的 stall,针对性调优。
在Transformer‑XL的执行流里,分支预测失误占据了相当比例的停顿窗口(约30 % ~ 40 %),导致算子在进入关键的注意力计算阶段时出现不必要的等待。通过把原来的 if‑else条件分支改写为查表(table‑lookup)的方式,使得分支路径在硬件层面可以提前确定,进而削减了这部分不确定性带来的停顿。整体上,模型的推理时延出现了可观的下降(约 10 % ~ 15 %),从而提升了整体吞吐表现。
4.结语
| 维度 | 传统痛点 | 升级后收益 |
|---|---|---|
| 算子编写 | 多段 DataCopy+ 手写循环,代码冗余 | NDDMA 一行搬运,代码简洁 70% |
| 算子迁移 | 新芯片需重写搬运路径 | 同一 DataCopy 自动适配 950/910B/910C |
| 核间同步 | Event + Flag 组合,延迟数 µs | CrossCore Mode3 + Count‑Notify,延迟 < 200 ns |
| 性能调优 | 只能看整体 runtime,难定位瓶颈 | msprof 10 kHz + MindStudio 打点,瓶颈定位秒级 |
| 产品上线 | 调度冲突导致服务卡顿 | KernelLaunch 超时/批量模式,自动容错与弹性伸缩 |
依托本次升级,CANN大幅简化算子开发与调优流程:
- 无需编写数十行数据搬运循环逻辑,通过DataCopy<T,dim>即可一行代码实现高效数据搬移。
- 借助CrossCoreSetFlag/CountNotify实现低延迟、高可靠同步。
- 告别调优过程中的盲目试错,通过msprof + MindStudio精准观测每一次stall与带宽波动。
本次 CANN 算子开发体验全面升级,将算子开发转化为高效流畅的创新实践,助力开发者开启便捷上手、极速迭代、精准调优的全新开发路径。