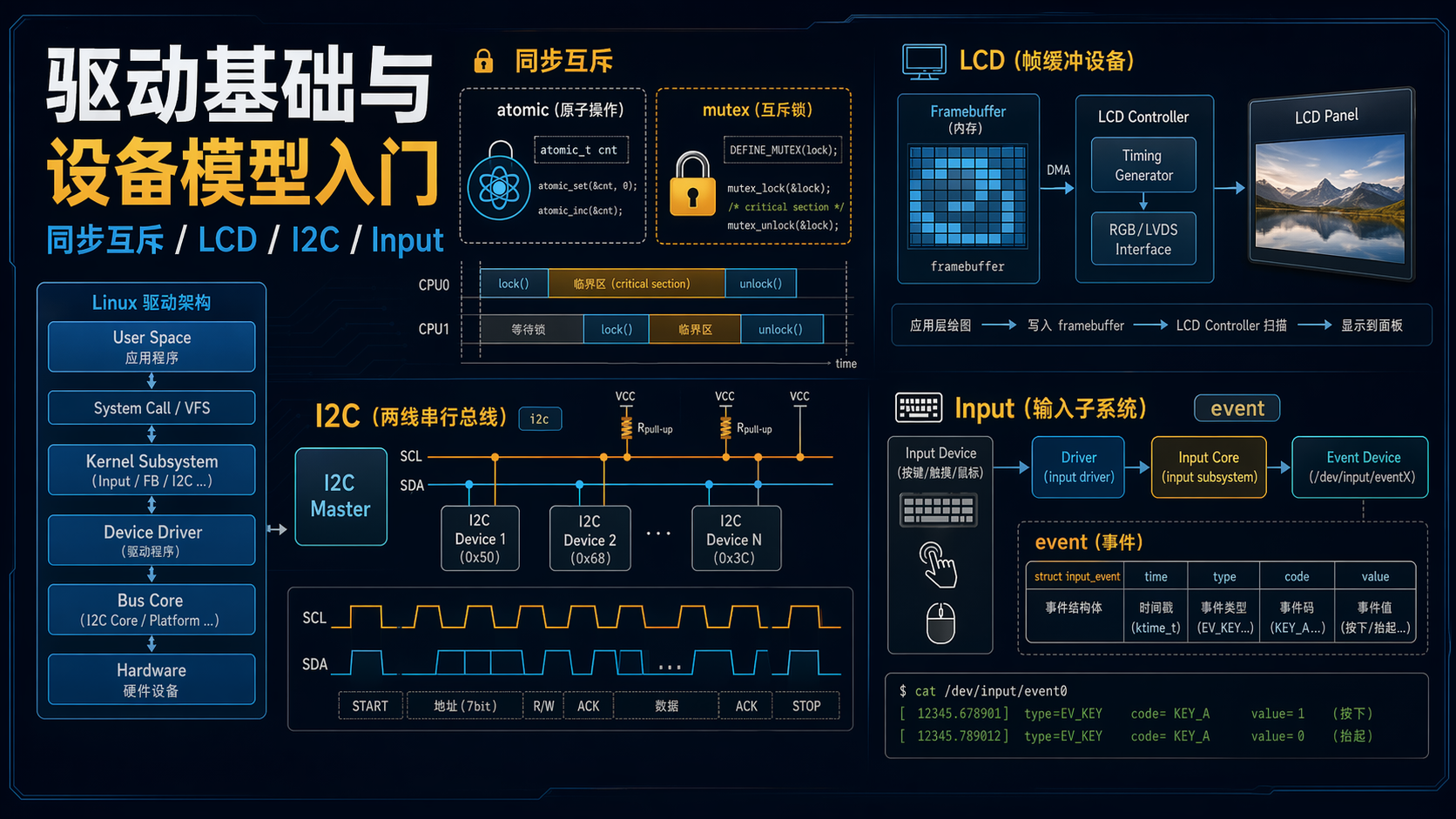
这篇文章整理自课程第 02-05 章,目标不是逐页搬运讲义,而是把初学者最先该建立的驱动脑图串起来:并发基础、显示设备、总线模型、输入子系统。
源文件地址:git clone https://e.coding.net/weidongshan/linux/doc_and_source_for_drivers.git
02_同步与互斥
本章表面上先讲内联汇编,再讲原子操作和各种锁;真正的主线其实只有一条:驱动里的共享状态会被多个执行上下文同时访问时,怎样保证结果正确。后面的 03_LCD、04_I2C、05_Input 都会遇到进程上下文、中断、Softirq、Timer、多核并发这些问题,所以课程把这一章放在驱动细节前面,不是绕路,而是在先补"并发判断力"。
章节定位
如果只站在单线程 C 程序的视角看驱动,很容易以为"读一个变量、改一个变量、写一个寄存器"都是顺序完成的。但 Linux 内核里的真实环境不是这样:有抢占,有中断,有下半部,有 SMP 多核。也就是说,驱动代码写到一半,完全可能被别的执行流打断,回来时共享数据已经变了。
本章先从 01_inline_assembly 这组小实验切入,不是为了教你手写"更快的加法",而是为了让你真正看到:一行 C 代码落到机器层面后,往往会变成多条指令。只要是"读出、修改、写回"这样的序列,就可能暴露竞态条件。理解了这个前提,后面再看 atomic_t、位操作、自旋锁、信号量、互斥量,才不会把它们当成一组需要死记硬背的 API。
所以,这一章给后续驱动学习打的基础主要有 3 个:
- 给"并发"建立最小心智模型:谁会同时访问一份数据,谁会打断谁。
- 给"原子操作"建立硬件基础:为什么 ARM 上要用
ldrex/strex这类指令。 - 给"锁选择"建立判断框架:当前上下文能不能睡眠,要不要关中断,要不要防 Softirq,要不要考虑多核。
核心概念
- 同步:条件还不满足时先等待,等条件满足了再继续。
- 互斥:同一时刻只允许一个执行流进入临界区,独占临界资源。
- 临界资源:驱动里的共享状态,比如
valid标志、引用计数、状态位、缓冲区、队列,甚至某些需要"读改写"的寄存器访问。 - 抢占和并发来源:进程上下文会被更高优先级任务抢占,中断会打断当前执行,Softirq、Tasklet、Timer 也可能参与共享数据访问;到了 SMP 上,另一个 CPU 还能并行执行同一段逻辑。
- 普通 C 语句不等于原子操作。无论是
if (!valid) valid = 0;,还是--valid,在机器层面通常都不是一个不可分割的动作,而是"读出、修改、写回"的组合。 - 关当前 CPU 的中断不是万能解法。文档里的"失败例子 3"已经点明:对单核 UP 系统可能够用,但在 SMP 上,你只能挡住当前 CPU,挡不住别的 CPU。
- 原子操作的关键不在"绝对不被打断",而在"即使被打断,最终效果仍然等价于不可分割"。ARMv6 及以上用
ldrex/strex做的就是这件事:中途如果被别人改过,就放弃写回并重试。 - 锁大致分两类:不能睡眠的上下文用自旋锁;允许睡眠的进程上下文才考虑
mutex或semaphore。真正选择哪一种,取决于竞争双方分别是谁。
先把课程主线看懂:失败例子 1 -> 2 -> 3 -> atomic_t
这一章最重要的,不是把 API 名字背下来,而是看懂课程为什么要连续给你 3 个"失败例子"。它们不是重复,而是在一步步逼你接受一个结论:只要共享状态会被多个执行流同时碰到,就不能靠"感觉上更短"的代码自保。
| 阶段 | 代码思路 | 为什么失败或为什么成立 | 你应该得出的判断 |
|---|---|---|---|
| 失败例子 1 | if (!valid) return -EBUSY; valid = 0; |
检查 valid 和 把 valid 改成 0 之间隔着多条语句,程序 A 可能在写回前被更高优先级程序 B 抢占,结果 A、B 都看到 valid == 1。 |
"先判断、后修改"不是原子操作,只要中间能被抢占,就会出竞态。 |
| 失败例子 2 | if (--valid) { valid++; return -EBUSY; } |
--valid 看起来只有一行,但机器层面仍然是"读出 -> 减 1 -> 写回"三步;A、B 完全可能都先读到旧值 1,再各自算出 0。 |
"代码更短"不等于"不可打断",关键要看底层是不是读改写序列。 |
| 失败例子 3 | 在 --valid 前后加 raw_local_irq_save/restore |
关本地中断只能防住当前 CPU 上的中断和部分抢占,挡不住另一个 CPU 同时访问 valid;所以它不是跨 CPU 的互斥。 |
"本地禁止中断"只解决本地 CPU 的问题,不等于系统级互斥。 |
走向 atomic_t |
用 atomic_t 和原子 API 重写 valid |
对单个共享变量的更新交给 ldrex/strex 这类原子指令或重试机制处理,中间若被别人改过就重来。 |
单变量状态更新优先考虑原子变量;复杂临界区再上锁。 |
读完这一段,你至少要能用一句话分别说清楚:
- 失败例子 1 失败在"检查"和"写回"之间可能被抢占。
- 失败例子 2 失败在"自减"本身仍然是读改写,不是天然原子。
- 失败例子 3 失败在"只关本地中断",没有解决 SMP 上其他 CPU 的并发访问。
atomic_t成立的边界是"单个共享状态的原子更新",不是"整个临界区都不用锁"。
术语小字典
preempt:内核抢占。进程在内核态执行时,也可能被调度器切走,让另一个更高优先级任务先跑。Softirq:软件中断,是硬中断之后处理延后工作的机制;它依然属于不能睡眠的上下文。Tasklet:建立在Softirq之上的一种更易用封装,可以把它理解为"受 Softirq 调度的下半部"。Timer:内核定时器回调;从并发语义上看,它也跑在 Softirq 体系里。ATPCS:ARM Procedure Call Standard,ARM 平台的函数调用约定;例如参数常放在r0-r3,返回值常放在r0。Clobbers:内联汇编的"额外副作用声明";告诉编译器这段汇编还会改哪些寄存器、标志位或内存,别做错误优化。_bh:Bottom Halves 的缩写,历史上指"中断下半部";在这里你可以直接把它理解成"顺带禁止本地 Softirq"。_irqsave:加锁前先保存当前中断状态,再关中断;解锁时恢复到原来的状态,而不是无脑开中断。
源码和实验怎么对应着看
先接受一个事实:仓库里和本章直接配套的源码,主要集中在 source/A7/02_同步与互斥/01_inline_assembly,它对应文档的 1.1 节。文档 1.2 之后关于失败案例、原子操作、锁类型和锁实现,主要靠 同步与互斥.docx 里的伪代码、时序图和内核源码路径来讲,并没有在仓库里再拆成独立实验目录。
建议按下面的"看什么、验证什么、为什么"来读,而不是把目录机械刷一遍:
| 目录 | 重点文件 | 你要看什么 | 你要验证什么 |
|---|---|---|---|
01_c_code |
main.c、test.dis |
不要通读整个反汇编,只定位 <add> 这个符号附近。 |
真正完成加法的核心只有一条 add 指令,其余大多是在做建栈、取参数、回传结果;这就是"C 里一行,底层多步"的证据。 |
02_assembly |
main.c、add.S |
对照 add.S 的 add r0, r0, r1 和 bx lr。 |
ATPCS 是怎么落地的:参数为什么进 r0/r1,返回值为什么回到 r0。 |
03_inline_assembly |
main.c、main2.c |
先读 main.c,再读 main2.c。 |
在 main.c 里把 :"=r"(sum) 当成 OutputOperands,把 :"r"(a), "r"(b) 当成 InputOperands,把 :"cc" 当成 Clobbers;再用 main2.c 看具名操作数只是写法更直观,不是原理变化。 |
04_earlyclobber |
main.c |
重点盯住 =&r。 |
仓库里保留的是修正版:输出寄存器会被提前写坏时,必须用 & 告诉编译器不要和输入复用同一寄存器;否则 a、b 可能在还没用完时就被覆盖。 |
同步与互斥.docx 的 1.2 到 1.7 |
失败例子、atomic_t、锁章节 |
这是本章正文。 | 把"为什么失败""为什么 atomic_t 行""为什么不同场景要换锁"这三条线真正串起来。 |
推荐实验顺序可以直接照着目录走:
bash
cd doc_and_source_for_drivers/STM32MP157/source/A7/02_同步与互斥/01_inline_assembly/01_c_code && make
cd ../02_assembly && make
cd ../03_inline_assembly && make
cd ../04_earlyclobber && make如果本机没有 arm-linux-gnueabihf- 交叉编译环境,不必卡住。每个目录里已经有现成的反汇编或源码,直接对着源码和反汇编一起看,照样可以完成这一章最重要的学习目标。
这里再把 3 个最容易看偏的点钉死:
test.dis不要从第一行开始硬看,只看<add>附近那十几行就够了;你不是在学 ELF 格式,而是在找"真正做加法的是哪一条指令"。03_inline_assembly/main.c的核心不是会不会写asm,而是能不能把OutputOperands、InputOperands、Clobbers三段一眼拆开。04_earlyclobber/main.c不是在教一个冷门语法点,而是在告诉你:如果不把副作用告诉编译器,编译器就可能"帮倒忙"。
另外要注意,文档里明确写了"失败例子"这一节在 GIT 上没有源码。也就是说,1.2 那些 valid 的例子、后面很多内核实现代码,重点是帮助你建立判断方法,而不是让你在仓库里把每一段都找到对应目录。
你需要真正掌握什么
锁选择最小场景表
初学者最容易卡住的不是"锁有哪些",而是"我现在到底该选哪一个"。先把课程里最常用的 3 个场景记牢:
| 场景 | 竞争双方 | 能不能睡眠 | 首选 | 为什么 |
|---|---|---|---|---|
| 用户态 vs 用户态 | 两个进程上下文都可能进入同一临界区 | 可以 | mutex 或 semaphore |
两边都在进程上下文,拿不到锁时可以休眠,不需要自旋。默认先用 mutex;只有需要计数资源或"一个执行流等待、另一个执行流释放"的同步语义时再考虑 semaphore。 |
| 用户态 vs Softirq / Tasklet / Timer | 进程上下文会和下半部共享同一资源 | 不可以让下半部睡眠 | spin_lock_bh |
你不仅要互斥,还要在进入临界区前先挡住本地 Softirq;Tasklet、Timer 都属于这类。 |
| Softirq / 用户态 vs IRQ | 共享资源既可能被下半部访问,也可能被硬中断访问 | 不可以 | spin_lock_irqsave |
你要同时防住"当前 CPU 被 IRQ 打断"和"其他 CPU 并发抢锁";_irqsave 还能保证解锁时恢复到进入前的中断状态。 |
这张表不是全量锁手册,但已经够你应付后续大多数驱动入门场景。真正落到代码前,先问 3 个问题:
- 当前执行流能不能睡眠?
- 竞争者是不是 Softirq / Tasklet / Timer / IRQ?
- 我需要保护的是"单个共享变量",还是"一段包含多步逻辑的临界区"?
mutex 和 semaphore 怎么快速区分
课程里专门把这两个放在一起比较,原因是它们都属于"休眠型锁",很容易被初学者混成一个东西。最小差异先记这张表:
| 维度 | semaphore |
mutex |
|---|---|---|
count 能否大于 1 |
可以,本质上是计数资源 | 不可以,只表示"锁着/没锁" |
| 谁加锁谁解锁 | 不强制要求同一执行流,适合同步语义 | 学习和写驱动时应按"谁 mutex_lock 谁 mutex_unlock"来用 |
| 能否用于中断上下文进入临界区 | 不适合,down() 可能睡眠 |
不适合,mutex_lock() 可能睡眠 |
这里有一个很重要的初学者提醒:文档里说 semaphore 的释放方可以是"别的程序、中断等",这描述的是它更适合做"等待者 / 唤醒者"同步,不等于你应该在 IRQ 里用 down() 去拿一个休眠锁。只要"获取锁"这一步可能睡眠,就不该放进中断上下文。
这一章你至少要做到的事
- 能用自己的话说清楚:同步是"等条件",互斥是"抢临界区",两者经常一起出现,但不是同一个概念。
- 能把"失败例子 1 -> 失败例子 2 -> 失败例子 3 ->
atomic_t"这条递进链完整复述出来。 - 能理解为什么"只用一个全局变量判断一下"在驱动里不可靠,特别是在可抢占内核和 SMP 上。
- 能说出
raw_local_irq_save()这类做法为什么只能解决本地 CPU 的问题,不能天然推广成跨核互斥。 - 能理解
atomic_t解决的是"单个共享状态的原子更新",不是"任意复杂临界区都不需要锁"。 - 能把
01_c_code -> 02_assembly -> 03_inline_assembly -> 04_earlyclobber这条线串起来:先看懂普通 C 会被拆成什么指令,再理解汇编函数和内联汇编,最后理解为什么内核里的原子操作和位操作必须精确描述寄存器约束。 - 能根据上面的最小场景表做基本选型:进程上下文且允许睡眠,优先考虑
mutex/semaphore;牵涉 Softirq、Tasklet、Timer、IRQ 时,优先回到自旋锁变体。 - 能接受一个非常重要的事实:后面驱动里所谓"并发正确",不是看代码看起来像顺序执行,而是要看它在抢占、中断、多核条件下是否仍然成立。
初学者常见误区
- 误区 1:源码只有一行,所以操作就是原子的。实际要看机器指令,不看源码行数。
- 误区 2:把
--valid这种写法当成天然安全。它仍然是读、改、写三步,竞态条件一点没少。 - 误区 3:只要关中断就万事大吉。对单核局部场景可能够用,但在 SMP 上,别的 CPU 依然能同时访问共享资源。
- 误区 4:用了
atomic_t就不再需要锁。原子变量适合很小的状态更新;只要临界区里有多步逻辑、多个共享对象,还是要靠锁保护整体一致性。 - 误区 5:
spin_lock_bh只是"给 Tasklet 用的锁"。不对,_bh真正防的是本地 Softirq;Tasklet、Timer 都只是 Softirq 家族里的具体成员。 - 误区 6:
spin_lock_irq()和spin_lock_irqsave()只是名字不同。前者是"直接关中断",后者是"先记住原状态再关中断";当代码可能在不同上下文复用时,_irqsave更稳。 - 误区 7:
mutex和semaphore都能睡眠,所以随便用哪个都行。实际上默认应优先用mutex解决互斥;semaphore更适合计数资源和同步语义。 - 误区 8:本章只有内联汇编,和后面的驱动关系不大。实际上内联汇编只是入口,它是在给后面的原子操作、寄存器级并发和锁实现铺路。
- 误区 9:把"内核内存里的原子更新"和"设备寄存器的原子访问"混为一谈。后面做驱动时,
atomic_t保护的是共享内存状态;设备寄存器的readl/writel往往还要结合锁和访问时序来考虑。
学完后如何迁移到驱动开发
到了后面的 LCD、I2C、Input 章节,你可以把本章直接迁移成一个固定问法:谁在共享这份数据,谁可能打断谁,当前上下文能不能睡眠。只要这 3 个问题问清楚,很多驱动里的同步选择就不会凭感觉。
- 如果目标是"设备一次只允许一个进程打开",你应该先判断这是"单个状态位"问题还是"打开到关闭之间整段生命周期"问题:前者常见于
atomic_t,后者常见于mutex。 - 如果进程上下文和中断 / Softirq 要共享缓冲区、队列、状态位,你应该首先想到自旋锁及其变体,而不是在不能睡眠的上下文里硬上
mutex。 - 如果后面需要维护标志位、引用计数、状态计数,本章的
atomic_t和位操作心智模型会直接复用。 - 如果后面要做寄存器读改写,这一章给你的最大提醒是:不要把"读寄存器、改某一位、再写回"想成天然安全。只要这个寄存器可能被另一个执行上下文同时访问,就必须回到本章的判断方法,重新选择保护手段。
- 如果以后读内核源码时看到
atomic.h、bitops.h、spinlock.h、semaphore.h、mutex.h,你也不会只把它们看成 API 头文件,而会知道它们背后分别解决的是哪类并发问题。
一句话概括:这章真正要你掌握的,不是锁函数表,而是"先判断并发来源,再选择正确同步原语"的工作方式。后面的驱动章节换的是硬件对象和子系统,复用的却正是这套方法。
03_LCD
一句话摘要:这一章是整套课程里第一个大型真实驱动专题。它不再只讲某个局部 API,而是第一次把"硬件原理、内核框架、设备树、平台资源、应用验证、显示体验优化"连成一条完整学习链路。
章节定位
如果把前两章看成"进场"和"打地基",这一章才是第一次真正面对一个完整外设。
- 第 1 章解决的是课程入口和资料入口。
- 第 2 章解决的是驱动开发的工程基础:共享资源、临界区、并发意识。
- 第 3 章开始,你要把这些基础落到一个真实设备上,第一次同时处理硬件、内核、设备树和实验现象。
所以,LCD 之所以是课程里的第一个大型真实驱动专题,不是因为"显示最重要",而是因为它足够完整,能把驱动开发最核心的方法论一次性讲透:
硬件原理 -> framebuffer 框架 -> QEMU 最小驱动 -> 结合 APP 分析 -> STM32MP157 实机移植 -> 多 framebuffer
这条主线的价值在于,它让你第一次建立稳定的心智模型:
- 用户程序看到的是
/dev/fb0 - 内核里承上启下的是
fbmem.c - 具体驱动要准备的是
fb_info、fb_ops、显存和硬件初始化 - 到实机上,驱动还必须从设备树里拿到引脚、时钟、显示时序、寄存器资源
- 真正把屏点亮后,还要继续面对显示撕裂、多 buffer 这些"能用"和"好用"之间的问题
换句话说,这一章不是单独学 LCD,而是在学"如何把一个硬件外设变成 Linux 里的可用设备"。
核心概念
1. 先把显示链路看成数据流,不要一上来就背代码
文档 01_单片机_Linux下不同接口的LCD硬件操作原理、07_硬件_8080接口LCD时序分析、08_硬件_TFT-RGB接口LCD时序分析、09_硬件_STM32MP157的LCD控制器 解决的是同一个问题:像素数据到底怎么到屏上去。
这一层要先想清楚 5 个对象:
- 像素:一个点的颜色
bpp:每个像素用多少位表示- framebuffer:一块连续内存,保存一整帧或多帧像素数据
- LCD 控制器:从 framebuffer 取数据,按时序送给屏
- LCD 接口和时序:决定什么时候送数据、送多少数据、信号极性是什么
只有先知道这些概念,后面代码里的 xres、yres、bits_per_pixel、line_length、pixel clock、hsync/vsync 才不是"魔法数字"。
2. framebuffer 是本章的软件主线
本章的软件主线可以先记成:
APP -> /dev/fb0 -> fbmem.c -> fb_info/fb_ops -> screen_base -> LCD 控制器 -> LCD
这里最关键的是 fb_info。它不是一个普通结构体,而是 framebuffer 驱动和上层应用之间的契约。
var表示可变显示参数:分辨率、颜色格式、虚拟分辨率等fix表示相对固定的信息:显存物理地址、显存总大小、每行字节数等screen_base是内核可访问的显存虚拟地址fbops描述驱动愿意提供哪些操作
初学者最容易混淆的是:var 更像"这一帧该怎么解释",fix 更像"这块显存和硬件资源长什么样"。
3. QEMU 阶段学的是框架,不是偷懒
04_最简单的LCD驱动_基于QEMU 和 05_上机实验_基于QEMU 的设计非常关键。它不是为了绕开硬件,而是为了先把问题拆开。
真实 SoC 上,点亮 LCD 往往要同时处理:
- 引脚复用
- 时钟树
- 控制器寄存器
- 显存分配
- 屏参和时序
这些因素一次性压上来,初学者很容易分不清到底是框架错了,还是硬件没配对。QEMU 的作用,就是把硬件复杂度压到最低,让你先看清 framebuffer 驱动的骨架。
4. 设备树不是"顺手写一下",而是实机驱动的输入
从 06_lcd_drv_framework_use_devicetree 开始,章节重点发生变化:驱动不再只靠硬编码参数运行,而是通过设备树拿平台资源。
这一层要理解的是:
compatible决定驱动和设备节点怎么匹配pinctrl-*决定 LCD 引脚复用backlight-gpios决定背光 GPIOclocks和clock-names决定像素时钟来源display、display-timings决定分辨率、时序、极性等显示参数reg决定控制器寄存器的物理地址范围
也就是说,设备树不是"配置文件",而是平台资源到驱动入口之间的桥。
5. LTDC 是 STM32MP157 这一章真正的硬件难点
09_硬件_STM32MP157的LCD控制器、10_分析内核自带的LCD驱动程序_基于STM32MP157、15_编程_配置LCD控制器之寄存器操作_基于STM32MP157 共同回答一个问题:拿到屏参之后,怎么把它们写进 LTDC。
这一层要抓住两件事:
- 时序参数最后都要落到 LTDC 寄存器里,比如同步宽度、前后肩、有效显示区域、总周期
- framebuffer 的地址和像素格式也要写到 LTDC 图层寄存器里,比如显存基址、每行长度、像素格式、图层窗口范围
所以,实机阶段的本质,不是"再写一个 framebuffer 驱动",而是把通用的 framebuffer 框架,接到 STM32MP157 这颗芯片的 LTDC 控制器上。
6. 多 framebuffer 说明"点亮"不是终点
17_单Buffer的缺点与改进方法 和 18_STM32MP157内核自带的LCD驱动不支持多buffer 把章节又往前推进了一步:显示不是只要有 /dev/fb0 就结束了。
单 buffer 的问题,本质上是"LCD 控制器正在读这一帧,APP 也正在改这一帧"。结果就是:
- 慢速绘制时,用户能看到逐步画出来的过程
- 高速整屏刷新时,容易出现撕裂和闪烁
多 buffer 要解决的就是这个问题:显示一帧、准备下一帧、再切换。这里既涉及驱动是否提供足够显存和 pan display 能力,也涉及应用如何正确使用 yres_virtual、yoffset 和 FBIOPAN_DISPLAY。
源码和实验怎么对应着看
不要把本章按目录平均用力。最有效的方式,是顺着主线看"每一步到底新增了什么"。
建议顺序
- 先看硬件文档,建立像素、时序、控制器的物理直觉。
- 再看 framebuffer 框架和最小骨架,搞懂 Linux 这边的抽象。
- 在 QEMU 上把最小驱动跑通,再结合 APP 看
/dev/fb0的使用链路。 - 然后进入 STM32MP157,按"框架 -> 引脚 -> 时钟 -> 屏参 -> LTDC 寄存器 -> 实机跑通"的顺序读源码。
- 最后再看多 framebuffer,这时你才能分清它是"体验优化"和"驱动能力边界"。
第一段:用文档建立硬件直觉
| 先看什么 | 为什么先看 | 看完后你应该知道什么 |
|---|---|---|
01_单片机_Linux下不同接口的LCD硬件操作原理 |
先搞清像素、颜色格式、framebuffer 是什么 | 为什么显存大小和 xres * yres * bpp 有关 |
07_硬件_8080接口LCD时序分析 |
了解 MCU 风格 LCD 的命令/数据时序 | 不是所有 LCD 都是"直接吐像素流" |
08_硬件_TFT-RGB接口LCD时序分析 |
这是本章实机路线最直接相关的接口 | 为什么要关心 hsync/vsync/de/pclk |
09_硬件_STM32MP157的LCD控制器 |
先认识 LTDC 再看寄存器代码 | LTDC 到底帮 CPU 做了什么 |
这一段不用停太久,但不能跳过。跳过之后,后面所有显示参数都会变成死记硬背。
第二段:先看 framebuffer 最小骨架
01_fb_info 是整章最应该"抄一遍、改一遍、背后的逻辑讲一遍"的目录。
| 源码目录 | 这一步新增了什么 | 真正的学习点 |
|---|---|---|
01_fb_info |
只做 3 件事:framebuffer_alloc、设置 fb_info、register_framebuffer |
一个 framebuffer 驱动最小需要哪些软件对象 |
读 01_fb_info/lcd_drv.c 时,重点不是每一行都记住,而是抓住这几个动作:
- 分配
fb_info - 填
var和fix - 分配显存,得到
screen_base和smem_start - 设置
fbops - 注册 framebuffer
如果这一层没看懂,后面你会把所有"硬件相关代码"误以为是驱动的主体。
第三段:QEMU 阶段只解决"最小可运行"
| 源码目录 | 这一步新增了什么 | 你要观察什么 |
|---|---|---|
02_lcd_drv_qemu |
在最小骨架之上,增加 QEMU 虚拟 LCD 寄存器映射和写寄存器操作 | framebuffer 物理地址、分辨率、bpp 是怎么告诉硬件的 |
03_lcd_drv_qemu_ok |
补齐 fix.id、line_length、xres_virtual/yres_virtual、pseudo_palette、fb_setcolreg |
为什么"能点亮"还不等于"能被通用 fb 应用正确使用" |
这两个目录一定要连着读。02_lcd_drv_qemu 教你"最小硬件初始化",03_lcd_drv_qemu_ok 教你"面向 APP 使用的完整度"。
这里强烈建议结合 06_结合APP分析LCD驱动程序 一起看。因为它把 open、ioctl(FBIOGET_VSCREENINFO)、ioctl(FBIOGET_FSCREENINFO)、mmap 这些调用一路追到了 fbmem.c,这一步会帮你彻底搞明白:
- 为什么 APP 不是直接操作硬件寄存器
- 为什么
fb_info->var和fb_info->fix要提前填好 - 为什么
mmap能直接映射 framebuffer
如果只看驱动、不看 APP,这一章的软件主线会少一半。
第四段:STM32MP157 的关键不是重写,而是逐步移植
进入实机阶段后,最好的办法不是直接盯着 11_lcd_drv_stm32mp157_ok,而是按增量阅读 06 到 11。
| 源码目录 | 这一步比上一版多了什么 | 你真正该抓住的点 |
|---|---|---|
06_lcd_drv_framework_use_devicetree |
从简单模块入口改成 platform_driver + of_match + probe/remove |
实机驱动的入口不再是"主动加载即运行",而是"匹配设备节点后再初始化" |
07_lcd_drv_pin_config_use_devicetree |
从设备树获取 backlight-gpios,用 GPIO 子系统打开背光 |
引脚复用和 GPIO 控制开始进入驱动主线 |
08_lcd_drv_clk_config_use_devicetree |
devm_clk_get、clk_set_rate、clk_prepare_enable |
像素时钟必须匹配屏的要求,时钟是 LCD 成败的核心因素之一 |
09_lcd_drv_lcdcontroller_config_use_devicetree |
解析 display 节点、bits-per-pixel、bus-width、display-timings |
显示参数不该硬编码在 C 里,而应该由设备树输入 |
10_lcd_drv_lcdcontroller_reg_config_use_devicetre |
引入 LTDC 寄存器结构体和 lcd_controller_init,把时序和图层信息真正写入控制器 |
这一版才是"从 framebuffer 框架走到 STM32MP157 硬件"的关键跃迁 |
11_lcd_drv_stm32mp157_ok |
做成最终可运行版本,修正显存分配设备归属,按设备树时序设置分辨率和时钟,并配合 DTS 禁用原有面板链路冲突 | 实机移植从来不是只改 C 文件,设备树冲突、内核自带驱动冲突也要一起处理 |
这里有两个非常重要的阅读策略。
第一,不要把 06 到 11 当成 6 个平级示例,它们本质上是一次连续移植过程。
第二,不要只读 lcd_drv.c,要把对应 DTS 一起看:
07_lcd_drv_pin_config_use_devicetree/stm32mp157c-100ask-512d-lcd-v1.dts08_lcd_drv_clk_config_use_devicetree/stm32mp157c-100ask-512d-lcd-v1.dts09_lcd_drv_lcdcontroller_config_use_devicetree/stm32mp157c-100ask-512d-lcd-v1.dts10_lcd_drv_lcdcontroller_reg_config_use_devicetre/stm32mp157c-100ask-512d-lcd-v1.dts11_lcd_drv_stm32mp157_ok/stm32mp157c-100ask-512d-lcd-v1.dts
把 DTS 和驱动对照着读,你才能真正看懂一条完整链路:
compatible怎么触发probedisplay怎么把时序交给驱动clocks怎么交给时钟子系统reg怎么变成 LTDC 寄存器映射backlight-gpios怎么变成背光控制
其中 11_lcd_drv_stm32mp157_ok 的 DTS 还特意把原有 panel 和 panel_backlight 置为 disabled。这件事非常重要,因为它说明实机移植时,你经常不是"从零开始接管硬件",而是在和板子原有显示链路做资源隔离。
第五段:多 framebuffer 要和应用一起看
多 framebuffer 这一段,如果只看理论,不容易真的吃透。建议把文档和两个应用目录绑在一起看。
| 资料/目录 | 作用 | 你要看什么 |
|---|---|---|
17_单Buffer的缺点与改进方法 |
解释为什么单 buffer 会撕裂 | 明白问题根源是"显示和写入在抢同一帧" |
13_multi_framebuffer_example |
一个更完整的应用侧多 buffer 示例 | 看它怎么根据 smem_len 算可用帧数,怎么用 FBIOPAN_DISPLAY 切换 |
14_use_multi_framebuffer |
一个精简测试程序 | 看 yres_virtual、yoffset、FBIOPUT_VSCREENINFO、FBIOPAN_DISPLAY 之间的最小关系 |
18_STM32MP157内核自带的LCD驱动不支持多buffer |
给出平台边界 | 明白"理论支持"和"当前驱动支持"不是一回事 |
14_use_multi_framebuffer/multi_framebuffer_test.c 非常值得反复看,因为它把多 buffer 的应用侧逻辑压缩到了最小:
- 先通过
FBIOGET_FSCREENINFO和FBIOGET_VSCREENINFO得到显存总大小和单帧大小 - 再根据
fix.smem_len / screen_size判断有几个 buffer - 再设置
var.yres_virtual - 最后通过修改
var.yoffset并调用FBIOPAN_DISPLAY来切换显示帧
这段代码会逼着你重新理解 fix 和 var 的边界,也会让你明白为什么驱动如果不支持 pan display,APP 再努力也做不出真正的多 buffer。
你需要真正掌握什么
学完这一章,不是会背目录名,而是要真正掌握下面这些能力。
- 能从头讲清楚这条链路:像素数据先写入 framebuffer,LCD 控制器按时序从显存取数据,再通过接口送到面板,Linux 用
/dev/fb0把这条链路暴露给应用。 - 能分清
fb_info里哪些信息属于显示参数,哪些信息属于显存和硬件资源,尤其是var、fix、screen_base、smem_start、line_length。 - 能解释为什么课程先用 QEMU,再上 STM32MP157:前者是拆开学习框架,后者是补齐平台资源和真实硬件。
- 能看懂设备树里哪些字段会进入驱动:
compatible、reg、clocks、pinctrl-*、backlight-gpios、display/display-timings。 - 能把
display_timing里的分辨率、同步宽度、前后肩、极性,和 LTDC 的时序寄存器一一对应起来。 - 能知道一个 LCD 驱动的排错顺序:先确认驱动是否匹配、
/dev/fb0是否存在、APP 能否取到var/fix,再查背光、引脚、时钟、时序、显存地址、控制器寄存器。 - 能明白多 framebuffer 不是"高级技巧",而是显示体验优化;它依赖驱动、显存布局和应用三者配合。
如果你现在还只是"会抄一个能亮屏的例子",还不算真正掌握。真正掌握的标志,是你能说清每一步为什么要这样做,以及换一块屏、换一颗 SoC 之后哪些地方必须重新确认。
初学者常见误区
-
误区一:一上来就盯寄存器。
正确做法是先看硬件链路,再看 framebuffer 框架,再看具体控制器寄存器。否则你很容易把"平台细节"误以为"驱动主线"。
-
误区二:觉得
fb_info只是模板代码。实际上它就是上层 APP 和底层驱动之间的契约。
fix.line_length、fix.smem_len、var.xres_virtual这些字段一旦理解不准,APP 侧就会出问题。 -
误区三:跳过
03_lcd_drv_qemu_ok,直接看 STM32MP157 最终版。这样会把平台差异和驱动通用逻辑混在一起,最后什么都不稳。最该吃透的是"相邻版本之间新增了什么"。
-
误区四:把设备树当成抄模板。
display-timings、时钟、GPIO、寄存器资源都必须和板子、屏幕、SoC 对得上。设备树写错,不是"配置不优雅",而是硬件根本不会按预期工作。 -
误区五:看到屏亮了就认为驱动完成了。
亮屏只说明最小链路可能通了,不代表分辨率、颜色格式、行长度、用户态访问、撕裂控制都正确。
-
误区六:以为多 buffer 只是应用层小技巧。
没有足够显存、没有
yres_virtual、没有FBIOPAN_DISPLAY支持,应用层根本做不成真正的双 buffer。 -
误区七:混淆课程自写的 framebuffer 驱动和内核自带的 DRM/LTDC 驱动。
课程刻意用 framebuffer 这条线讲原理,是为了降低学习门槛;但在真实产品里,显示系统常常走 DRM/KMS,这一点要在脑子里分开。
学完后如何迁移到驱动开发
这一章最值得迁移的,不是 LCD 本身,而是它提供的驱动分析框架。
以后你看任何一个外设驱动,都可以先套这 6 个问题:
- 这个硬件的数据是怎么流动的,真正和 CPU 交互的是什么寄存器或总线?
- Linux 为这类设备提供了什么框架或子系统?
- 驱动和 APP 之间的接口是什么?
- 平台资源从哪里来,哪些放在设备树里?
probe里必须拿到哪些资源,初始化顺序是什么?- 除了"能工作",还有哪些体验或性能问题要继续处理?
把这个方法迁到后面几章会非常自然。
- 到
04_I2C时,你会把 framebuffer 主线换成adapter/client/transfer主线,但"框架 + 设备树 + 实验 + 实机验证"的套路是一样的。 - 到
05_Input时,你会把/dev/fb0换成输入事件设备,但"应用如何感知、内核如何抽象、驱动如何注册"的思路仍然一样。 - 如果以后继续走显示方向,这一章就是你进入 DRM/KMS、panel、backlight、regulator、vsync、page flip 的前置基础。
从第一性原理看,这一章真正教会你的,是把一个"板子上的硬件功能"拆成四层去理解:
- 硬件层:屏和控制器到底怎么工作
- 框架层:Linux 用什么抽象来管理它
- 平台层:设备树、引脚、时钟、寄存器资源怎么交给驱动
- 验证层:应用怎么证明驱动真的可用
如果你能把这四层拆开,再把它们重新串起来,你就已经开始具备迁移到其他驱动开发的能力了。
04_I2C 学习总结
TL;DR:这一章真正要学会的,不是"会调一个 EEPROM",而是建立一条稳定主线:
协议认知->用户态直接访问->i2c-dev/通用模型->i2c_driver/i2c_client->adapter 驱动->GPIO 模拟 I2C->STM32MP157 具体平台。后面的 Input、传感器、触摸屏驱动,很多都只是把"如何通过 I2C 和芯片通信"嫁接到别的子系统上。
章节定位
04_I2C 是前 5 章里第一次把"总线子系统"讲完整的章节。
在 03_LCD 里,你更多是在理解某个具体外设怎么挂到设备树、怎么被驱动;到了这一章,课程开始把视角抬高,回答一个更关键的问题:Linux 为什么能用一套统一框架去管理很多不同的 I2C 设备。
这一章的课程位置可以这样理解:
- 往前承接
03_LCD:你已经接触过设备树、字符设备、平台驱动,I2C 章把这些零散知识串成"总线 + 设备 + 驱动"的整体模型。 - 往后支撑
05_Input:很多输入设备,尤其是触摸屏、距离/光照传感器,底层通信就是 I2C。后面再学 Input,你会发现那是在 I2C 通信之上再加一层"事件上报"。 - 对后续传感器驱动同样重要:AP3216C 这种传感器,当前章节只是先用字符设备把通信链路讲清楚;实际项目里,它往往还会继续接入 Input、IIO、hwmon 等子系统。
所以,这一章的核心不是"某颗芯片怎么读",而是:
- I2C 协议在硬件上怎么工作
- Linux 用哪些对象描述 I2C 总线和设备
- 用户态、通用驱动、具体芯片驱动、adapter 驱动之间是怎么接起来的
核心概念
先抓住整章学习主线
建议你严格按下面这条线学,不要一上来就扎进某个具体芯片驱动:
协议认知
先看02_I2C协议.md、03_SMBus协议.md,弄清楚SCL/SDA、Start/Stop、ACK/NACK、Repeated Start。否则后面看到i2c_msg或i2c_smbus_read_word_data时,只会背 API,不知道总线上究竟发了什么。用户态直接访问
先用i2c-tools和01_at24c02_test证明总线是通的、地址是对的、读写格式没问题。先把"硬件通不通"和"驱动写没写对"拆开,是初学者最划算的做法。i2c-dev/通用模型
再看07_通用驱动i2c-dev分析.md,理解/dev/i2c-X为什么存在,为什么用户态ioctl(I2C_SMBUS)最后还是会落到 I2C Core。i2c_driver/i2c_client
这一步开始真正进入 Linux 驱动模型。你要明白驱动模板怎么注册,设备实例怎么出现,probe为什么会触发。adapter 驱动
再回头看总线底层。adapter不是某个从设备驱动,而是"谁来把 I2C 时序真正发出去"。GPIO 模拟 I2C
这是把 adapter 本质讲透的一步。只要你能按协议拉出波形、实现master_xfer,Linux 就承认这是一条 I2C 总线。具体芯片平台
最后再回头看 STM32MP157 的真实 I2C 控制器驱动。此时你会发现,SoC 专用驱动和虚拟 adapter、GPIO adapter 的区别,不在框架,而在master_xfer背后换成了寄存器、中断和 DMA。
这几个关键词在学习中的位置
| 关键词 | 它是什么 | 在这一章里的位置 |
|---|---|---|
adapter |
一条 I2C 总线的控制者,通常对应 SoC 的 I2C 控制器或软件模拟总线 | 它回答"这条总线怎么发时序、怎么完成传输" |
client |
总线上的一个设备实例,至少要知道地址、挂在哪条总线上 | 它回答"总线上现在到底有谁" |
driver |
某类 I2C 设备的驱动模板 | 它回答"如果出现这种设备,内核该怎么初始化和访问它" |
message |
struct i2c_msg,一次传输描述单元,包含地址、方向、长度、缓冲区 |
它是"协议动作"在 Linux 里的数据表示;读 EEPROM 往往要用两个 message |
i2c-tools |
用户态工具集,也是很好的示例代码来源 | 它是最适合初学者的"观察窗口",先验证总线和设备,再写驱动 |
如果只记一句话,请记住这句:
无论你是用 i2c-tools、自己写 APP,还是写一个具体的 i2c_driver,最后都会落到 i2c_transfer 或 i2c_smbus_xfer,再由某个 i2c_adapter 的 master_xfer 去真正完成传输。
adapter、client、driver、message 是怎么串起来的
可以先把链路记成:
用户程序/i2c-tools -> i2c-dev 或具体芯片驱动 -> I2C Core -> i2c_adapter -> i2c_msg[] -> i2c_client 对应的设备
这条链里最容易混淆的是下面 3 点:
adapter关心的是"怎么发",不关心 AP3216C、AT24C02 这些设备的寄存器语义。client是设备实例,不是驱动;一个driver可以匹配多个client。message不是"一个寄存器",而是"一次传输描述"。例如 AT24C02 读数据,往往先发一个写message送内部地址,再发一个读message取数据,中间依赖Repeated Start。
源码和实验怎么对应着看
这一章最好的学习方式,不是"把所有代码从头到尾看完",而是让每个源码目录只承担一个明确任务。
| 目录 | 它在主线里的角色 | 重点看什么 | 你要验证什么 |
|---|---|---|---|
01_at24c02_test |
用户态直接访问 I2C 设备 | at24c02_test.c 里 open_i2c_dev、set_slave_addr、i2c_smbus_write_byte_data、i2c_smbus_read_i2c_block_data;配套的 smbus.c、i2cbusses.c 来自 i2c-tools |
用户态也能通过 i2c-dev 直接访问 EEPROM;写 EEPROM 要考虑写周期,所以代码里有 nanosleep(20ms) |
02_i2c_driver_example |
最小 i2c_driver 骨架 |
i2c_driver_example.c 里的 of_match_table、id_table、probe_new、i2c_add_driver |
先理解"驱动模板长什么样",不要一开始就被具体芯片细节分散注意力 |
03_ap3216c |
把骨架替换成真实传感器访问 | a3216c_drv.c 里 ap3216c_open、ap3216c_read,以及对 i2c_smbus_read_word_data 的调用 |
设备驱动真正关心的是芯片寄存器语义;同时也能看到:只写 driver 壳子还不够,匹配表和 client 生成还没补完整 |
04_ap3216c_ok |
把 i2c_driver + i2c_client + 测试 这条链补齐 |
ap3216c_drv.c、ap3216c_client.c、ap3216c_drv_test.c、stm32mp157c-100ask-512d-lcd-v1.dts |
client 既可以通过代码 i2c_get_adapter + i2c_new_device 创建,也可以由设备树 ap3216c@1e 节点生成;匹配成功后才会进入 probe,再导出 /dev/ap3216c |
05_i2c_adapter_framework |
adapter 驱动的最小框架 | i2c_adapter_drv.c 里的 i2c_bus_virtual_master_xfer、i2c_bus_virtual_algo、i2c_add_adapter,以及 i2c_adapter.dts |
adapter 驱动本质上是在注册一条新的 I2C bus,核心不是设备寄存器,而是 master_xfer |
06_i2c_adapter_virtual_ok |
用虚拟 adapter 模拟 EEPROM,把上层链路跑通 | i2c_adapter_drv.c 里的 eeprom_emulate_xfer 和 i2c_bus_virtual_master_xfer |
只要 adapter 正确处理 i2c_msg[],上层 i2c-tools、APP、设备驱动都不用改;这最能说明 Linux I2C 框架的分层价值 |
07_i2c_gpio_dts_stm32mp157 |
GPIO 模拟 I2C 和 STM32MP157 板级落地 | stm32mp157c-100ask-512d-lcd-v1.dts 里的 i2c_gpio_100ask 节点,以及 &i2c1 下的 ap3216c@1e |
软件 bit-bang 也能成为正规 adapter;板级 DTS 既要描述设备,也要描述这条总线怎么被创建 |
建议这样配对资料和实验
- 先读
02_I2C协议.md、03_SMBus协议.md、04_I2C系统的重要结构体.md。
目标:先把协议和adapter/client/message的抽象对上。 - 再读
05_无需编写驱动直接访问设备_I2C-Tools介绍.md,并在板子上先执行:i2cdetect -li2cdetect -F 0i2cdetect -y -a 0
目标:先确认系统里有哪些 bus、这些 bus 支持哪些功能、设备地址是否真的存在。
- 再看
01_at24c02_test。
目标:把i2c-tools的调用方式变成你自己的程序,感受"APP 直接访问 I2C 设备"是什么体验。 - 再读
07_通用驱动i2c-dev分析.md。
目标:把刚才用户态看到的现象,和i2c-dev的open/ioctl路径串起来。 - 再看
08_I2C系统驱动程序模型.md、09_编写设备驱动之i2c_driver.md,配合02_i2c_driver_example和03_ap3216c。
目标:明白i2c_driver是模板,probe成功的前提是系统里先出现了匹配的client。 - 再看
10_编写设备驱动之i2c_client.md,配合04_ap3216c_ok。
目标:把"设备怎么出现"这件事彻底弄清楚,包括设备树、代码和用户态new_device三种思路。 - 最后看
11到15这几份资料,配合05_i2c_adapter_framework、06_i2c_adapter_virtual_ok、07_i2c_gpio_dts_stm32mp157。
目标:把"设备驱动"和"总线驱动"彻底区分开,再回头读 STM32MP157 的i2c-stm32f7.c时就不会是黑盒。
这一章最值得你亲手观察的现象
01_at24c02_test里,为什么写每个字节后都要延时。04_ap3216c_ok/ap3216c_client.c里,为什么i2c_get_adapter(0)能创建一个地址为0x1e的client。04_ap3216c_ok/stm32mp157c-100ask-512d-lcd-v1.dts里,为什么把ap3216c@1e挂到&i2c1下就能触发probe。05_i2c_adapter_framework里,为什么只要注册i2c_adapter,系统里就会多出一条 bus。06_i2c_adapter_virtual_ok里,为什么上层工具完全不知道"下面其实是个假 EEPROM"。07_i2c_gpio_dts_stm32mp157里,为什么加载i2c-gpio后,i2cdetect -l会多出一条i2c-3。
你需要真正掌握什么
这一章真正的验收标准,不是"我记住了几个 API 名字",而是你是否具备下面这些能力:
- 能独立讲清楚一条完整链路:
用户程序为什么能通过i2c-dev访问设备,i2c_driver为什么会被匹配,底层又为什么一定要靠adapter->master_xfer。 - 能区分 4 类问题:
- 协议层问题:地址、读写方向、
Repeated Start、ACK 是否正确。 - bus 层问题:这条 I2C bus 有没有被注册出来,
i2cdetect -l能不能看到。 - client 层问题:设备有没有被实例化出来,设备树/
new_device/代码创建是否正确。 - driver 层问题:
compatible、id_table、probe、寄存器读写流程是否正确。
- 协议层问题:地址、读写方向、
- 能看懂
i2c_msg[]在表达什么,知道"读 EEPROM 常常需要两个message"并不是技巧,而是协议要求。 - 能把
i2c-tools放在正确位置上:它是最好的验证工具和示例代码来源,但它不是最终产品驱动。 - 能理解
04_ap3216c_ok的教学用意:这里故意先用字符设备把焦点放在 I2C 通信本身,而不是一上来就引入更复杂的传感器子系统。 - 能把 STM32MP157 的板级事实记牢:设备树里的
i2c1在本课程资料里对应的是 I2C BUS0 ,不要把节点名和/dev/i2c-X机械地一一对应。
如果你能独立回答下面这个问题,就说明这章真的学进去了:
某个 I2C 设备为什么会出现在某条总线上,它为什么会匹配到某个驱动,而你从用户态发起的一次读写为什么最终一定会落到某个 adapter 的传输函数。
初学者常见误区
- 误区 1:把
adapter当成某颗芯片的设备驱动。
纠正:adapter是总线控制者,负责"怎么发时序";AP3216C、AT24C02 这些才是总线上的设备。 - 误区 2:把
client和driver当成一回事。
纠正:client是设备实例,driver是驱动模板;一个driver可以匹配多个client。 - 误区 3:觉得
message就等于"读一个寄存器"。
纠正:message是传输描述单元,一次完整读操作可能要用多个message才能完成。 - 误区 4:一上来就写驱动,不先用
i2c-tools或用户态程序验证。
纠正:先排除总线、地址、接线、功能位问题,再写驱动,调试效率会高很多。 - 误区 5:以为写了
i2c_driver就一定会进probe。
纠正:系统里还必须先出现匹配的i2c_client,它可能来自设备树、代码,也可能来自/sys/bus/i2c/devices/.../new_device。 - 误区 6:把设备树节点名
i2c1直接等同于/dev/i2c-1。
纠正:在这套 STM32MP157 资料里,i2c1对应的是 I2C BUS0,总线编号是内核注册后的逻辑编号。 - 误区 7:看到
i2cdetect里的UU就以为硬件坏了。
纠正:UU很多时候表示这个地址已经被某个内核驱动占用了,不是设备损坏。 - 误区 8:觉得 GPIO 模拟 I2C 是"旁门左道"。
纠正:它仍然是标准的 adapter 驱动,只是把专用控制器换成了软件 bit-bang。 - 误区 9:忽略 EEPROM 写周期。
纠正:01_at24c02_test里每次写完都nanosleep(20ms),不是多余,而是在等待芯片完成内部写入。
学完后如何迁移到驱动开发
这一章和后续 Input、传感器、触摸屏驱动之间的关系,可以用一句话概括:
I2C 章解决"怎么跟芯片通信",后续子系统章节解决"通信得到的数据该怎样以 Linux 认可的方式暴露出去"。
和 Input、传感器、触摸屏的关系
AP3216C本身就是传感器例子。
课程里先把它做成字符设备,是为了让你先专注在i2c_client、i2c_driver、寄存器读写这条链,而不是被更复杂的上层框架分散注意力。- 到
05_Input时,你会看到另一层抽象。
触摸屏驱动通常是:i2c_driver.probe里拿到client,申请中断,分配input_dev,中断里通过 I2C 读坐标,再上报ABS_X/ABS_Y/BTN_TOUCH这类事件。 - 这意味着:
I2C负责把数据从芯片读出来。Input负责把这些数据变成应用层可消费的输入事件。
- 很多真实项目驱动其实都是"总线子系统 + 功能子系统"的组合:
- 触摸屏:
I2C + Input - 环境传感器:
I2C + IIO/hwmon - 简单控制芯片:
I2C + misc/char device
- 触摸屏:
真正进入驱动开发时,建议按这个顺序落地
- 先用
i2cdetect、i2cget、i2cset或自己的测试程序确认硬件链路真的通。 - 再确认设备实例化方式。
先决定是放到设备树里,还是调试期用new_device,还是像ap3216c_client.c一样在代码里创建。 - 再写
i2c_driver骨架。
先把compatible、id_table、probe/remove跑通,再填芯片寄存器逻辑。 - 把寄存器访问封成少量 helper。
例如read_reg、write_reg、read_block,不要把i2c_smbus_*调用散落在整个驱动里。 - 最后再接入上层子系统。
如果设备最终是给应用读事件,就接 Input;如果是周期采样传感器,就考虑 IIO 或 hwmon;如果只是课程验证,字符设备也可以。 - 只有在 bus 本身有问题时,才向下钻 adapter 层。
这时就回来看05_i2c_adapter_framework、06_i2c_adapter_virtual_ok、07_i2c_gpio_dts_stm32mp157,以及真实平台驱动i2c-stm32f7.c。
对初学者来说,这一章最有价值的迁移能力其实是:以后你再遇到任何 I2C 传感器、I2C 触摸屏、I2C 电源管理芯片,都不会再把问题混成一团,而是能自然地分成"协议格式""bus 是否存在""client 是否生成""driver 是否匹配""上层子系统如何接入"这几步去排查和实现。
05_Input 学习总结
TL;DR:这一章真正要学会的,不是"怎么直接读某块按键或触摸屏硬件",而是把 GPIO 按键、QEMU 触摸屏、I2C 电容屏都看成"输入事件源",再通过 Input 子系统统一地暴露给
/dev/input/eventX、tslib和uinput。04_I2C解决的是"怎么把数据从芯片里读出来",05_Input解决的是"读出来的数据怎样变成标准输入事件"。
章节定位
05_Input 是前 5 章里第一次把"功能子系统抽象"讲完整的章节。
在 04_I2C 里,你已经学过怎样通过总线把寄存器数据读出来;到了这一章,课程把视角再抬高一层,回答的是另一个更关键的问题:Linux 为什么不让应用直接面对某个具体硬件,而是把它们统一抽象成输入事件。
这章和前后章节的关系可以这样看:
- 往前承接
02_同步与互斥:Input 驱动里同样有中断、定时器、等待队列、异步通知,前一章的并发判断会直接复用。 - 往前承接
04_I2C:真实电容屏控制器往往挂在 I2C 上,I2C 章负责"怎么通信",Input 章负责"怎样把通信结果上报成标准事件"。 - 同时复用 GPIO 和中断知识:GPIO 按键、QEMU 触摸屏、真实触摸芯片,底层触发方式不同,但最终都要上报
EV_KEY、EV_ABS这一类标准事件。 - 往后给触摸屏、按键、传感器类驱动打基础:你以后再看
gpio_keys.c、goodix.c,就不会只看到"又一个平台驱动",而会知道它们是在往 Input Core 里注册一个input_dev。
为什么 Input 子系统要抽象"输入事件",而不是让应用直接操作硬件
如果没有 Input 子系统,每种输入设备都可能有一套私有 API:
- GPIO 按键可能自己定义"按下/松开"的字符设备格式
- 电阻屏可能直接返回 ADC 值
- 电容屏可能直接暴露 I2C 寄存器布局
- USB 鼠标、键盘又会是另一套协议
这样做的结果是:驱动无法复用,应用也必须理解每种硬件细节。
Input 子系统做的事情正好相反:它把"硬件差异"压在驱动内部,把"用户真正关心的事情"抽出来,统一成 type + code + value 形式的输入事件。比如:
- 按键最终都是
EV_KEY - 鼠标移动最终都是
EV_REL - 触摸坐标最终都是
EV_ABS - 一批事件上报完成后用
SYN_REPORT收尾
这样一来:
- 驱动开发者只要负责"从硬件读数据 -> 翻译成标准事件"
- 应用开发者只要面向
/dev/input/eventX、tslib、libinput这类统一接口 evdev这类 handler 还能把同一份事件同时分发给多个应用
所以,这一章的核心不是"某块硬件怎么操作",而是建立一条稳定的数据链路:
硬件中断/轮询 -> 设备驱动读取数据 -> input_event/input_sync -> Input Core -> evdev 等 handler -> /dev/input/eventX -> APP/tslib
学习顺序建议
不要一上来就看 goodix.c 或 QEMU 触摸屏驱动。对初学者来说,最省力的路径就是按"先看事件消费者,再看事件生产者"来学。
- 先学应用层事件怎么看
先看02_先学习输入系统应用编程.md、03_输入系统应用编程.docx,再对照source/A7/05_Input/01_input_app。
这一阶段只解决 3 件事:/dev/input/eventX是什么、struct input_event长什么样、应用到底怎么读取事件。 - 再学 Input Core 的对象关系
接着看01_Input子系统视频介绍.md、DRV_01_Input子系统框架详解.md。
这一阶段要把input_dev、input_handler、input_handle、evdev的角色彻底分开。 - 再学最小
input_dev驱动骨架
然后看DRV_02_编写input_dev驱动框架.md,配合source/A7/05_Input/02_input_dev_framework。
重点不是立刻跑通,而是知道一个 Input 驱动最少要做哪几步:分配input_dev、声明支持哪些事件、注册设备、处理中断并上报事件。 - 再看具体案例,把抽象落地
先看DRV_03_编写最简单的触摸屏驱动程序_基于QEMU.md和03_touchscreen_qemu,再看DRV_05_GPIO按键驱动分析与使用.md、DRV_06_I2C接口触摸屏驱动分析.md。
这一步的重点是:虽然底层一个是 GPIO,一个是 QEMU 虚拟硬件,一个是 I2C 触摸芯片,但上报给 Input Core 的仍然是标准事件。 - 最后再学
uinput
最后看DRV_07_UInput分析_用户态创建input_dev.md和04_uinput。
只有你先理解"内核驱动怎样创建输入设备",再回头看"用户态怎样伪造一个输入设备",uinput才不会像魔法。
如果只给自己保留一条强制主线,请记住:
应用层事件 -> Input 子系统抽象 -> input_dev 驱动框架 -> 触摸屏/按键案例 -> uinput
Input 子系统的核心对象
先把最小数据流记成一句话:
input_dev 负责描述"我是什么输入设备";
驱动通过 input_event/input_sync 上报数据;
input_handler 负责接住这些数据并决定怎么往上层分发;
evdev 是最常见的通用 handler;
应用通过 /dev/input/eventX 或 tslib 读事件;
uinput 则反过来让用户态伪造一个新的 input_dev。
这几个关键词必须分清
| 关键词 | 它是什么 | 这章里要抓住什么 |
|---|---|---|
input_dev |
一个输入设备对象 | 驱动在 probe 里分配、设置能力位、注册它;它代表"这个设备能产生哪些事件" |
input_event |
一条标准输入事件 | 本质是 time + type + code + value;应用最终读到的就是它 |
input_handler |
事件处理者 | 它不直接操作硬件,而是决定"这些事件要怎么被消费" |
input_handle |
input_dev 和 input_handler 的绑定关系 |
匹配成功后由 Input Core 建立,用来把设备和 handler 连起来 |
evdev |
最常用的通用 handler | 它把事件排进缓冲区、唤醒等待者,并提供 /dev/input/eventX 给应用读取 |
tslib |
用户态触摸屏库 | 它不是驱动,而是在 evdev 之上帮你做校准、过滤、触摸数据处理 |
uinput |
用户态创建虚拟输入设备的接口 | 它不是绕过 Input Core,而是让用户态也能走同一套 Input 事件分发链路 |
input_dev、input_event、handler 为什么经常混淆
input_dev是"设备描述",不是"一次事件"。
比如驱动会说"我支持EV_KEY、EV_ABS,我有BTN_TOUCH、ABS_X、ABS_Y",这些都是能力声明。input_event是"实时上报的数据"。
比如"现在按下了""X 坐标是 100""Y 坐标是 200"。input_handler/evdev是"消费和分发这些事件的人"。
驱动不负责自己实现poll/select/fasync的整套接口,evdev已经把这些统一做好了。
对初学者最关键的一句话是:
设备驱动负责产生事件,evdev 负责把事件变成 /dev/input/eventX,tslib 负责在用户态进一步处理触摸屏事件。
应用层要看到什么,驱动层就要上报什么
从 03_输入系统应用编程.docx 和 01_input_app 里,你至少要建立 3 个映射:
- 按键类设备常见的是
EV_KEY - 单点触摸常见的是
BTN_TOUCH + ABS_X + ABS_Y - 多点触摸常见的是
ABS_MT_SLOT + ABS_MT_TRACKING_ID + ABS_MT_POSITION_X + ABS_MT_POSITION_Y
这里的 SYN_REPORT 也很重要。它表示"一批相关事件上报结束了"。没有它,应用层拿到的往往是一串零散字段,不知道哪些值属于同一次触摸或同一次按键动作。
源码与实验地图
这一章最好的学习方式,不是把所有代码从头刷到尾,而是让每个目录只承担一个明确任务:它到底是在教你"怎么读事件"、还是"怎么造事件"、还是"怎么模拟一个输入设备"。
| 目录或资料 | 在主线里的角色 | 重点看什么 | 你要确认什么 |
|---|---|---|---|
01_input_app/01_app_demo |
先从应用层认识事件 | 01_get_input_info.c 里的 EVIOCGID、EVIOCGBIT;02_input_read.c 的阻塞/非阻塞 read;03_input_read_poll.c、04_input_read_select.c、05_input_read_fasync.c |
同一个 /dev/input/eventX 既可以直接 read,也可以走 poll/select/fasync;应用关心的是标准事件,不关心底层是 GPIO、I2C 还是 USB |
01_input_app/02_tslib |
认识 tslib 在用户态的位置 |
mt_cal_distance.c 里的 ts_setup、ts_read_mt、EVIOCGABS(ABS_MT_SLOT) |
tslib 是建在 evdev 之上的用户态库;多点触摸应用并不是直接自己解释每个 slot |
DRV_01_Input子系统框架详解.md |
建立 Input Core 心智模型 | input_dev、input_handler、input_handle 三者关系,以及 input_register_device、input_register_handler 的匹配流程 |
以后再看 evdev.c、gpio_keys.c、goodix.c 时,不会把"设备驱动"和"事件处理者"混成一层 |
02_input_dev_framework |
最小 input_dev 骨架 |
input_dev.c 里 devm_input_allocate_device、__set_bit、input_set_abs_params、input_register_device、request_irq |
这个目录是教学骨架,不是开箱即跑的完整驱动:ISR 里还有 XX 占位,input_dev.dts 的 interrupts = <...>; 也是未填完整示例 |
03_touchscreen_qemu/01_irq_ok |
先把中断接通 | touchscreen_qemu.c 里 of_get_gpio、gpio_to_irq、request_irq |
QEMU 触摸屏驱动不是一上来就全做完,而是先验证"硬件事件能不能进中断" |
03_touchscreen_qemu/02_all_ok |
把单点触摸链路补全 | touchscreen_qemu.c 里 INPUT_PROP_DIRECT、BTN_TOUCH、ABS_X、ABS_Y、定时器轮询坐标;touchscreen_qemu.dts 的 reg = <0x021B4000 16> 和 gpios = <&gpio1 5 1> |
QEMU 例子是单点触摸 ,主要看 BTN_TOUCH + ABS_X + ABS_Y;它的作用是把 Input 抽象讲透,不是替代真实电容屏驱动 |
DRV_05_GPIO按键驱动分析与使用.md |
连接 GPIO、中断和 Input | gpio_keys 设备树属性、去抖思路、input_event(...EV_KEY...) |
GPIO 按键本质上就是"GPIO/IRQ + Input"的组合;按键去抖往往要靠定时器或延时策略 |
DRV_06_I2C接口触摸屏驱动分析.md |
连接 I2C 和 Input | 文档里的 goodix_ts_probe、goodix_request_irq、goodix_ts_irq_handler、input_mt_slot、input_mt_report_slot_state |
真实电容屏通常是 I2C + Input 的组合:I2C 负责读触点数据,Input 负责把它组织成多点触摸事件 |
04_uinput |
从用户态反向创建输入设备 | uinput_test.c 里 UI_SET_PROPBIT、UI_SET_EVBIT、UI_SET_KEYBIT、UI_SET_ABSBIT、UI_DEV_CREATE |
uinput 不是"伪造几条随机事件"这么简单,而是先声明设备能力,再创建虚拟设备,然后按规范发送事件流 |
建议这样做一轮最小实验
- 先执行
cat /proc/bus/input/devices,确认系统里有哪些输入设备。 - 再用
01_get_input_info.c或hexdump /dev/input/eventX看看某个事件节点到底支持哪些EV_*类型。 - 然后跑
02_input_read.c、03_input_read_poll.c、04_input_read_select.c、05_input_read_fasync.c,对比应用拿事件的 4 种方式。 - 再看
02_input_dev_framework/input_dev.c,把"应用层看到了什么"反推回"驱动应该声明哪些能力位、应该上报哪些事件"。 - 再看
03_touchscreen_qemu/02_all_ok/touchscreen_qemu.c,把BTN_TOUCH、ABS_X、ABS_Y、INPUT_PROP_DIRECT这些概念落到一个完整驱动上。 - 最后再看
DRV_06_I2C接口触摸屏驱动分析.md和04_uinput/uinput_test.c,理解真实多点触摸和用户态虚拟输入设备分别怎样接进同一套框架。
uinput 实验前置条件要先说死
04_uinput 这段最容易让初学者误判成"写几个事件就行",实际前置条件至少有这些:
- 先编出并加载
uinput.ko - 确认
/dev/uinput设备节点已经出现 - 再运行
uinput_test uinput_test里先暂停 60 秒,是为了给ts_calibrate、ts_test留出发现新设备的时间- 如果系统里已经有真实触摸屏,可能要先导出
TSLIB_TSDEVICE=/dev/input/eventX,明确让tslib绑定到虚拟设备
也就是说,uinput 本质上是在用户态"先注册一个虚拟 input_dev,再上报事件",它并没有跳过 Input Core。
初学者最容易混淆的点
- 混淆 1:以为 Input 子系统是在教"怎么直接操作触摸屏硬件"。
实际上,这章教的是"怎么把各种输入硬件统一翻译成输入事件"。硬件访问本身往往分散在 GPIO、I2C、USB 等子系统里。 - 混淆 2:把
input_dev当成"应用读到的那个结构体"。
错。应用读到的是struct input_event;input_dev是驱动在内核里注册的设备对象。 - 混淆 3:把
evdev当成具体设备驱动。
错。evdev是通用事件处理者,它负责把事件排队、唤醒等待者,并导出/dev/input/eventX。 - 混淆 4:把
tslib当成驱动。
错。tslib是用户态库,主要做校准、过滤和触摸数据处理,它依赖下面已经存在的事件节点。 - 混淆 5:把
02_input_dev_framework/input_dev.c当成可直接运行的成品。
错。这个文件明显保留了教学占位:ISR 里有XX,设备树里interrupts也没有填满,它的作用是帮你看清"最小骨架"。 - 混淆 6:把 QEMU 触摸屏和真实 Goodix 电容屏当成同一种事件模型。
不完全对。QEMU 例子是单点触摸 ,主看BTN_TOUCH + ABS_X + ABS_Y;真实 Goodix 电容屏是多点触摸 ,主看ABS_MT_SLOT + ABS_MT_TRACKING_ID + ABS_MT_POSITION_X/Y。 - 混淆 7:觉得
BTN_TOUCH和ABS_X/ABS_Y足以描述所有触摸屏。
对电阻屏或简单单点触摸大体够用,但对电容多点触摸不够;这就是 Type B 协议存在的原因。 - 混淆 8:觉得
uinput是"旁门左道",和真实驱动无关。
错。uinput恰好能反向帮助你理解 Input 子系统:真实驱动是在内核态创建input_dev,uinput是在用户态通过uinput.c做同样的事情。 - 混淆 9:以为事件节点编号固定不变。
错。/dev/input/eventX的编号会随设备注册顺序变化,实验时不要把event1、event2写死。
学完后的迁移方向
学完本章后,你至少应该能做到什么
- 能解释为什么 Input 子系统要抽象"事件",而不是暴露每种硬件的私有读法。
- 能说清
input_dev、input_event、input_handler、evdev、tslib、uinput各自在整条链路里的位置。 - 能自己写一个最小的
input_dev骨架:分配设备、声明能力、注册设备、在中断或定时器里上报事件。 - 能区分单点触摸和多点触摸的上报思路,知道
BTN_TOUCH + ABS_X/Y和ABS_MT_*不是一回事。 - 能从应用层反推驱动层:如果应用希望
poll/select/fasync正常工作,那么驱动最好接到 Input/evdev这套标准框架里,而不是自己临时发明接口。
之后怎样迁移到真实驱动开发
- 做 GPIO 按键时,你会自然把它拆成:GPIO/IRQ 负责感知,Input 负责上报
EV_KEY。 - 做 I2C 电容屏时,你会自然把它拆成:I2C 负责读触点数据,Input 负责组织
ABS_MT_*事件。 - 做简单触摸测试和自动化回归时,你会想到
uinput,因为它能在没有真实手指、没有真实硬件的前提下给应用喂标准输入事件。 - 再看
drivers/input/keyboard/gpio_keys.c、drivers/input/touchscreen/goodix.c、drivers/input/evdev.c、drivers/input/misc/uinput.c时,你不会再把这些文件当成一团黑盒,而能看出它们分别属于"设备驱动""通用 handler""用户态入口"哪一层。
一句话概括这章的迁移价值:
以后你再遇到任何按键、触摸屏、手柄、甚至某些传感器的人机输入场景,都可以先问自己两件事:底层数据是怎么来的?上层应该把它当成什么输入事件。
资料边界说明
本章同时参考了 05_Input 目录下的 Markdown 讲义、03_输入系统应用编程.docx 提取出来的正文片段,以及 source/A7/05_Input 的示例源码。
其中 03_输入系统应用编程.docx 的正文文字可以提取到应用层 API、触摸屏数据格式、Type B 协议等关键信息;但原文里的部分截图、排版和图片细节无法完整还原。因此,这份总结里凡是涉及应用层实验现象、tslib 用法、QEMU 单点触摸实现的地方,都是结合目录结构和示例源码交叉补全的,没有对未明确读到的图示内容做臆测。