目录
[OS 是如何把收到的数据,转发给特定端口的?](#OS 是如何把收到的数据,转发给特定端口的?)
[怎么理解 socket ?](#怎么理解 socket ?)
[五、socket 通用结构体](#五、socket 通用结构体)
[socket 通用结构体](#socket 通用结构体)
一、端口号
什么是端口号?
端口号是传输层(TCP/UDP)的一个标识,用一个 2 字节(16 位)的整数 表示,范围是 0 ~ 65535。它的核心作用就是:标识主机内的一个进程。也就是说:光有 IP 只能找到主机,但数据必须交给 "主机内的某一个进程",这就靠端口号。
为什么必须有端口号?
一台主机里有浏览器、QQ、迅雷等多个进程。数据到达主机后,必须知道交给谁?浏览器?QQ?迅雷?端口号就是用来标识 "到底是哪一个进程" 的。所以:IP 定位主机,端口号定位主机内的进程。
端口号和进程PID有什么区别?
端口号和 PID 虽然都能标识进程,但二者的本质不同。PID 是操作系统内核为进程分配的本地唯一标识,只在当前主机内有效,每次进程启动时由系统动态分配,进程退出后就会被回收复用,它的核心作用是让操作系统在本地管理进程,而不是为了网络通信;而端口号是传输层协议定义的逻辑标识,专门用于网络数据交付,它和 IP 地址组合后能在全网唯一标识一个进程。
综上,IP地址用来标识互联网中唯一的一台主机,端口号用来标识该主机上唯一的一个网络进程
IP + 端口号port = 互联网中唯一的一个进程
3. 所以,通信的时候,本质是两个互联网进程代表人来进行通信
4. 所以,网络通信的本质,也是进程间通信
- 因此 我们把 IP+ 端口号port = socket套接字
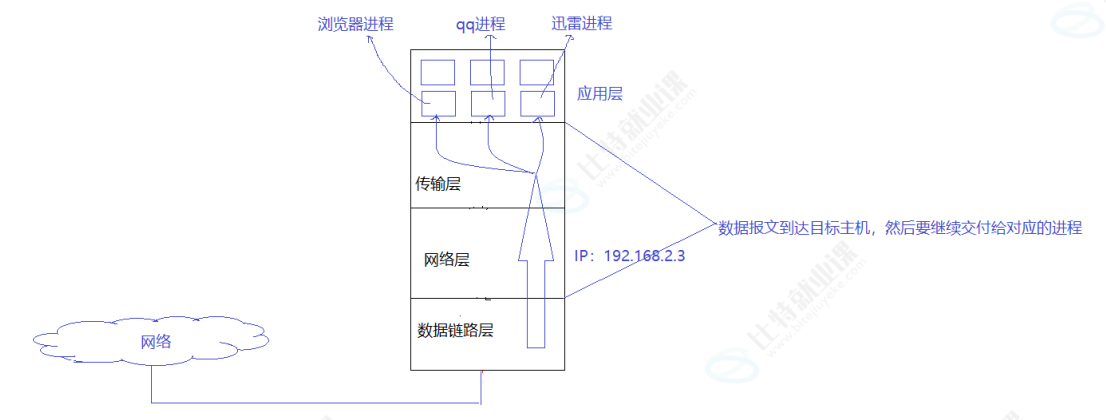
OS 是如何把收到的数据,转发给特定端口的?
OS(操作系统)把收到的数据转发给特定端口的过程,是靠传输层协议(TCP/UDP)和端口号管理机制实现的,整个流程可以这样理解:
当数据通过网络到达主机时,网卡将数据向上交给数据链路层处理;数据链路层取出 IP 数据报后交给网络层,网络层剥除 IP 头,根据 IP 首部中的 "协议字段",判断数据属于 TCP 还是 UDP 协议,再把数据交给对应的传输层模块。
传输层拿到数据后,会解析 TCP 或 UDP 首部中的 "目的端口号",然后查询操作系统内部维护的端口号 - 进程映射哈希表,找到绑定了该端口的进程。因为一个端口在同一时间只能被一个进程占用,所以操作系统能精准定位到唯一的目标进程,再把数据交付给它处理。
这个过程的核心,就是靠端口号来标识主机内的进程,让操作系统知道 "数据该交给谁",而 IP 地址 + 端口号的组合,也成了 Socket 通信中唯一标识网络进程的关键。
二、理解网络通信的本质
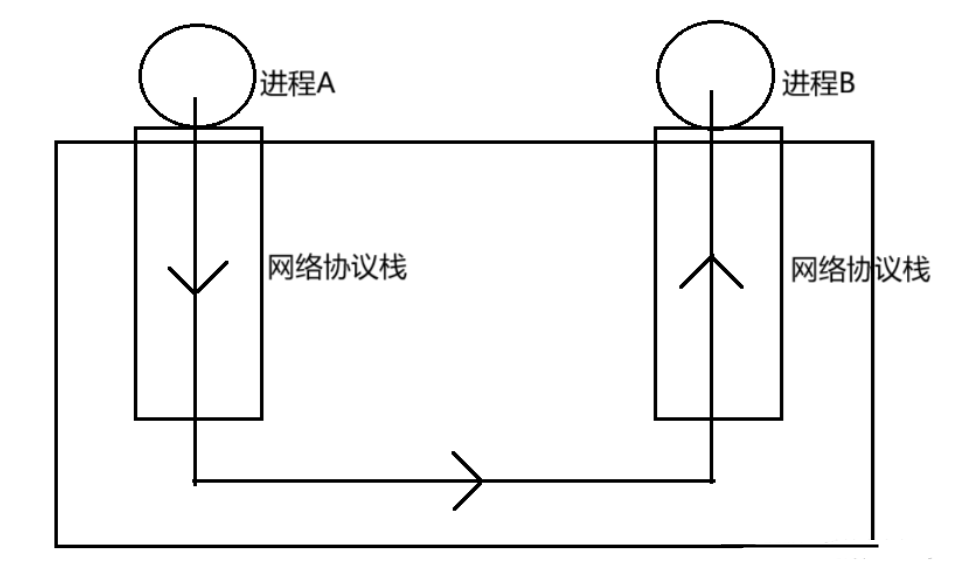
我们上面说过,网络通信的本质,也就是进程间通信,我们结合下面的场景来理解一下 :
-
很多人以为 "网络通信就是两台电脑之间的对话",但实际上,电脑本身是没有 "意识" 的,它只是一个硬件载体,真正在发起请求、接收响应、处理数据的,是运行在电脑里的程序。
-
就像我们在刷抖音,我们的电脑不会主动去 "要视频",是我们启动的抖音 App 进程在发请求;抖音服务器也不会主动给我们推视频,是服务器上运行的抖音服务进程在处理请求、返回数据。这两个进程,才是网络通信里真正的 "对话双方",而电脑和网络,只是它们用来传递数据的 "通道" 而已。
-
表面上看,数据是在两台电脑之间来回传输,我们会觉得是 "电脑 A 和电脑 B 在通信"。但本质上,通信的主体是电脑 A 上的进程 A 和电脑 B 上的进程 B,电脑只是提供了硬件环境和操作系统支持,让进程能运行起来、通过网络协议栈收发数据。
-
进程本身是无法直接在网络上收发数据的,它必须依赖操作系统提供的网络协议栈。协议栈就像一个 "全能管家":发送时,它会把进程的数据,从应用层到链路层,一层层加上端口号、IP 地址、MAC 地址这些 "地址标签",封装成标准的数据包,交给网卡发出去;接收时,它会把收到的数据包,从链路层到应用层,一层层剥掉标签,还原出原始数据,再交给对应的进程处理。
-
网络通信,本质上也是一种进程间通信,和管道、共享内存这些本地 IPC 的核心逻辑是一样:
- 管道、共享内存 : 让同一台电脑上的两个进程,通过操作系统内核看到同一份内存资源,实现数据交换;
- 网络通信:让两台不同电脑上的两个进程,通过网络协议栈和网络设备,看到同一份网络数据资源,实现数据交换。
-
它们的区别只是 "资源载体" 不同,一个是本地内存,一个是网络数据,但核心都是 "让两个进程看到同一份资源,从而完成通信"。
-
再结合我们平时刷抖音的场景,我们打开抖音 App,它就变成了电脑上的进程 A;滑动屏幕刷视频,进程 A 就会向抖音服务器发送视频请求。
-
进程 A 把请求数据交给操作系统的网络协议栈,协议栈给数据加上我们的 IP、进程的端口号、服务器的 IP 和端口号,再加上链路层的 MAC 地址,封装成数据包,通过网卡发出去。
-
数据包经过路由器转发,最终到达抖音服务器;服务器的网络协议栈剥掉数据包的链路层和网络层标签,把请求数据交给服务器上的抖音服务进程 B。
-
进程 B 处理请求,找到对应的视频数据,再通过服务器的协议栈封装成响应数据包,发回给我们的电脑;电脑协议栈剥掉标签,把视频数据交给进程 A,最终我们就能在抖音里看到视频了。
-
整个过程里,电脑和网络只是传递数据的通道,真正在对话、处理数据的,一直是进程 A 和进程 B。
总结:
不同网络之间的通信,最终落到实处,就是跨主机的进程间通信 ,而网络本身就相当于一个被大家共用的公共资源,就像同一台机器里的管道、共享内存是本地进程的公共资源一样,只不过网络把这个 "公共资源" 扩展到了不同主机之间,让分布在不同位置、不同局域网里的进程,都能借助这套统一的 IP 与端口机制,借助路由器屏蔽底层差异后,通过这个公共的网络通道交换数据,实现彼此间的通信
三、引入Socket套接字
怎么理解 socket ?
我们都知道 : 进程之间要通信,就需要一个公共资源,在同一台机器内通信时,可以通过管道、共享内存、消息队列这几种方式进行通信。但是在不同的机器之间通信就需要跨网络通信,所以网络本身就是公共资源。
但进程不能直接碰网络硬件、不能直接写 IP 包,操作系统也不允许。于是,操作系统又加了一层软件抽象,这一层就叫 socket(套接字)。所以 socket 就是:操作系统给应用进程开的一个 "网络接口",让进程不用管底层网络细节,只需要读写 socket,就能完成网络通信。
我们可以这么串起来理解:两个跨网络的进程要通信,它们不能直接对话,也不能直接操作网卡、IP、路由,此时操作系统就给每个进程创建一个 socket,进程只需要往 socket 里写数据、从 socket 里读数据,底层的封装、拆包、IP 路由、端口查找、哈希表匹配...... 全都由操作系统内核搞定。
所以 socket 是用户态进程和内核网络协议栈之间的接口,通信的两端,本质就是两个 socket 在对话,一个 socket 唯一对应:{IP, 端口},一对通信就是那个四元组{srcIP, srcPort, dstIP, dstPort}。
那 socket 就是相当于一个公共资源吗?和管道一样,两个进程之间给里面读写数据吗?
是的,Socket 和管道底层逻辑一样 :都是操作系统在内核里开辟一块公共内核缓冲区资源 ,两头进程一头写、一头读。管道只在同一台电脑两个进程共用这块内存缓冲区 ; Socket 也是内核缓冲区公共资源,只不过它能跨电脑、跨路由器、跨局域网,全网通用。
Linux 一切皆文件,socket 也是文件 fd,和管道一样通用 read、write 读写。进程完全不用管网卡、IP、路由、封包拆包,只往 socket 里写数据、读数据就行。一对配对好的 socket,就是两端进程的通信通道,四元组精准锁定两边进程。
三、认识UDP/TCP协议
-
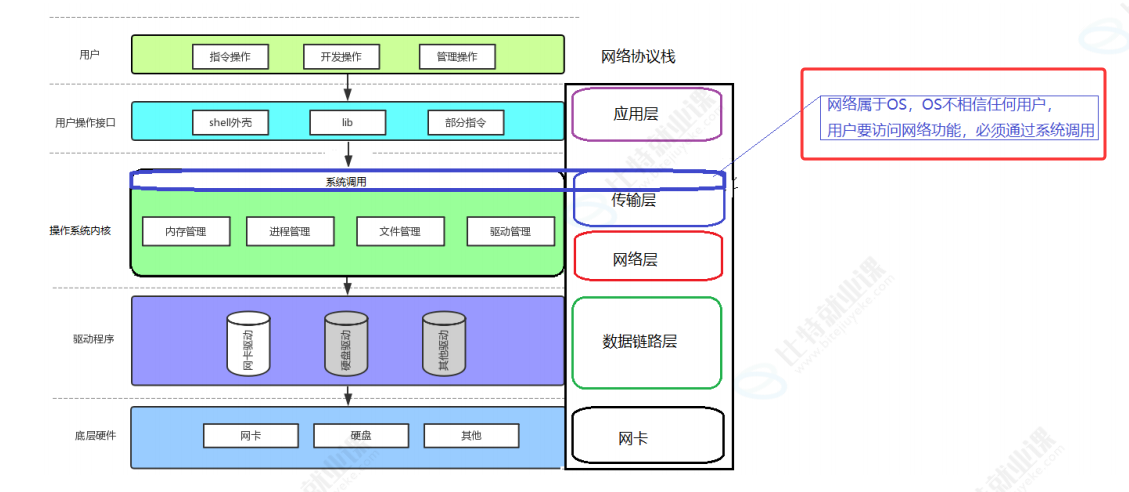
传输层、网络层完完全全都属于操作系统内核,传输层(TCP/UDP)、网络层(IP)、数据链路层都写在内核里,用户态代码不能直接碰内核里的 TCP、IP 协议栈。要实现网络通信,就必须通过系统调用,而用户要使用的就是 socket 那一套 bind/listen/connect/read/write 系统调用。用户程序只能通过这一层系统调用,才能调用内核传输层、网络层的协议栈能力。
-
整个 Linux 体系就是两套一模一样的架构:
- 左边:存储 IO 体系(用户代码→lib 库→系统调用→内核文件管理→磁盘驱动→硬盘)
- 右边:网络通信体系(用户代码→socket→系统调用→内核传输 / 网络层协议栈→网卡驱动→网卡)
- socket 就是网络版的文件接口,TCP/IP 协议栈就是网络版的内核文件管理模块,网卡就是网络版的硬盘,全程一一镜像对应。所有用户网络通信,必须经过socket 用户接口 → 系统调用陷入内核 → 内核传输层 + 网络层协议栈 → 网卡驱动 → 网卡硬件这条固定链路,完全不能跳过内核直接操作网络。
认识TCP协议
- TCP协议(Transmission Control Protocol 传输控制协议),下面是TCP协议的一些特点 :
- 传输层协议
- 有连接
- 可靠传输
- 面向字节流
-
TCP协议是一个传输层协议,当使用TCP协议进行数据传输网络通信的时候,TCP协议要和通信主机建立连接,并且保证数据真的被发到了对方的主机上,并且保证数据不丢失,TCP协议是基于字节流发送数据的,即将数据基于一个字节一个字节的发送给对方主机。
-
TCP协议由于其安全可靠,所以在一些支付领域,安全方面使用较多,例如支付宝,银行,要使用TCP协议保证安全性。
-
同样的,我们也应该看到TCP协议的另一面,效率相对较低 ,由于使用TCP协议,首先就要建立连接,连接的建立必然要花费时间,并且TCP协议要保证数据不丢失,那么也就意味,当TCP没有收到对方发来的确认收到的数据的信息之前,当TCP把数据通过网络协议栈发到网络中的时候,TCP不会将数据直接丢弃,而是将数据暂时保存起来,不丢弃数据,暂时保存数据也是一种对系统的消耗。
-
并且在数据发送到网络中的时候,TCP还要时刻进行数据检测算法,时刻检测也是要花费时间的,一旦检测到数据丢失或者数据乱序,还要重新发送数据,或者调整数据顺序并且重新发送数据
由此可见TCP协议为了保证可靠,安全传输做了很多的工作,那么也就必然决定了TCP协议的效率相对较低。
认识UDP协议
- UDP协议(User Datagram Protocol 用户数据报协议),下面是UDP协议的一些特点 :
- 传输层协议
- 无连接
- 不可靠传输
- 面向数据报
-
UDP协议是一个传输层协议,UDP使用网络协议栈进行网络通信,向对方主机发送数据的时候,不会和对方主机建立连接,UDP协议是一个不可靠传输,即UDP协议一旦将数据发送出去,那么在本地就会立即将数据丢失(释放内存资源,效率高),不会去做数据检测,并且不会再去关心据究竟有没有丢失,数据有没有乱序,数据有没有发送到对方主机上,并且我们还可以看出UDP协议不去做这些可靠性,安全性的工作,那么在一定程度上UDP协议是效率高的,低延迟的,并且UDP协议是比TCP协议快的。
-
UDP协议是面向数据报的,即直接一次性的将数据全部发送给对方主机。
-
UDP协议的应用场景也有很多,例如电子邮件,音视频通信,网络监控和日志传输等。
-
TCP协议和UDP协议没有谁好谁坏之分,所谓的特点仅仅是对应协议的特征,我们在实际的应用场景中要理性的使用TCP协议和UDP协议。
相关问题:
1. 传输层和系统调用是什么关系?
传输层(TCP/UDP 协议栈)都是内核态代码,直接在操作系统内核里运行,用户进程不能直接访问它。
而系统调用(比如 socket()、connect()、send()、recv())是内核给用户进程开的 "大门",用户进程只能通过这扇门,陷入内核态,让内核里的传输层模块帮自己干活。
举个例子:用户写的 send() 函数,最终会变成 sys_sendto 这类系统调用,内核接收到请求后,才会交给传输层的 TCP 或 UDP 模块处理。
所以总结一下,传输层是内核里干活的 "模块",系统调用是用户进程调用它的 "接口"。
2. 传输层为什么要提供多种协议?
- 核心原因就是为了应对不同的应用场景,因为 "可靠性" 和 "效率" 本质是矛盾的,单一协议无法同时满足这两个需求,所以就会出现 UDP 和 TCP 等多种传输层的协议。
2.TCP(面向连接、可靠传输):为了满足支付、文件传输、网页加载这类 "宁可慢一点,也不能丢数据" 的场景,用三次握手、确认重传、流量控制保证数据 100% 到达。
3.UDP(无连接、不可靠传输):为了满足音视频通话、游戏、直播这类 "宁可丢一点数据,也不能卡顿延迟" 的场景,去掉所有确认和重传,只做最基础的校验,用低延迟换效率。
- 一句话总结:多种协议,就是为了给不同场景提供 "可靠性 / 效率" 的不同权衡方案,让应用能选最适合自己的那一种。
3. 所以 TCP 和 UDP 就是未来我们进行网络通信时在传输层上采用的两种模式?
完全正确。TCP 和 UDP,就是传输层给应用层提供的两种核心通信模式,我们创建 socket 时选 SOCK_STREAM 就是 TCP 模式,选 SOCK_DGRAM 就是 UDP 模式。
所有网络通信,在传输层本质上都是在这两种模式里二选一,或者基于它们做二次封装(比如 QUIC 协议就是基于 UDP 实现的类 TCP 可靠传输)。
我们写代码时,不用直接和 TCP/UDP 打交道,只需要通过 socket 系统调用选择模式,内核会自动帮你执行对应协议的所有逻辑。
四、网络字节序
在讲网络字节序之前,我们先了解一下大端和小端:
什么是大端和小端?
对于数据本身而言,有高权值(高位)和低权值(低位)之分,比如 int a = 0x11223344 里,11 是高权值,44 是低权值。
对于内存地址而言,有低地址(比如 0xF0)和高地址(比如 0xF3)之分。
大端和小端,本质就是:这两种权值和地址的对应关系。
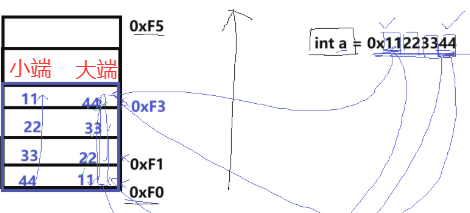
1. 当低权值写在低地址处时,就是小端模式("小小小"),比如 0x11223344 中,44是最低权值,它存在最低地址 0xF0,33 存在 0xF1,22 存在 0xF2,11是最高权值,存在最高地址 0xF3,此时内存里从低到高看:44 33 22 11。用一句口诀记忆就是 : "小小小",低权值(小)存低地址(小)。现在绝大多数 PC、手机的 CPU(x86、ARM)默认都是小端模式。
2. 当低权值写在高地址处时,就是大端模式 ,比如 0x11223344 中,11 是最高权值,存在最低地址 0xF0,22 存在 0xF1,33 存在 0xF2,44 最低权值,存在最高地址 0xF3,内存里从低到高看:11 22 33 44。大端的特点是就是内存里的顺序和我们写数字的顺序是一样的,一眼就能看懂。因为网络数据流中的地址规定先发出数据的是低地址,后发出的是高地址 。所以在大端模式下内存从低到高看就和我们写数字的顺序一样。网络传输中统一用的就是大端模式,所以它也叫 "网络字节序"。
为什么网络中必须区分大小端?
我们自己电脑里的大小端模式,只有 CPU 本身能懂。但数据在网络上传输时,会经过不同的设备(不同 CPU 架构、不同大小端模式),如果不统一规则,对方就会把你的 0x11223344 读成 0x44332211,数据直接乱掉。这就是大小端差异带来的数据不一致问题。
所以网络协议规定:所有跨主机传输的多字节数据,都必须使用大端模式(网络字节序)。因此,写网络程序时,我们必须用 htons()、htonl() 这类函数,把主机字节序(可能是小端)转换成网络字节序(大端),才能保证所有设备都能正确解析数据。
所以为了解决大小端差异带来的数据不一致问题,所以网络中规定 :网络中传递的数据,必须是大端数据序列。
-
不管这台主机是大端机还是小端机,都会按照这个 TCP/IP 规定的网络字节序来发送 / 接收数据;如果当前发送主机是小端,就需要先将数据转成大端;否则就忽略,直接发送即可;
-
为使网络程序具有可移植性,使同样的 C 代码在大端和小端计算机上编译后都能正常运行,可以调用以下库函数做网络字节序和主机字节序的转换。
- 这些函数名很好记,h 表示 host, n 表示 network, l 表示 32 位长整数,s 表示 16 位短整数。
- 例如 htonl 表示将 32 位的长整数从主机字节序转换为网络字节序,例如将 IP 地址转换后准备发送。
- 如果主机是小端字节序,这些函数将参数做相应的大小端转换然后返回;
- 如果主机是大端字节序,这些函数不做转换,将参数原封不动地返回。

五、socket 通用结构体
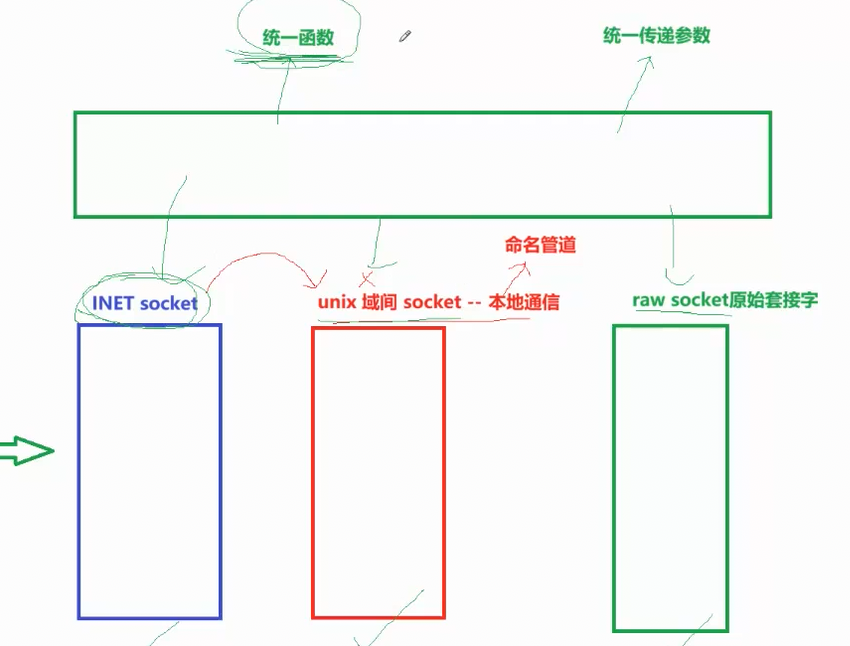
我们前面已经知道:Socket 本质就是应用层和传输层之间的接口。不管是本机通信,还是跨网络通信,所有进程要收发数据,都可以通过 socket 来完成。同时 socket 根据通信范围、通信方式、底层依赖的不同,socket 被分成了 3 种具体的通信类型。
1️⃣网络套接字(INET 套接字)
网络套接字主要用于跨主机的网络通信,也就是我们常说的 TCP/UDP 网络编程。使用 IP 地址 + 端口号作为通信地址。它分为两种主要模式:一个是面向连接、可靠、有序,适合文件传输、网页访问的TCP 套接字。另一个则是无连接、不可靠,适合音视频、游戏的UDP 套接字。目前绝大多数网络应用(微信、浏览器、游戏)都基于这种套接字开发。
2️⃣ 域间套接字(Unix 域套接字)
域间套接字是同一主机内的进程间通信(IPC),不走网络协议栈、也不经过网卡。通过使用文件系统路径(如 /tmp/socket.sock)作为通信地址,相当于进程之间的 "文件通道"。管道可以看成是域间套接字的子集。
3️⃣原始套接字(Raw Socket)
原始套接字则是绕过传输层(TCP/UDP),直接操作网络层 / 数据链路层的一种通信模式。可以自己构造 IP 头、TCP/UDP 头,实现自定义协议。可以直接接收 / 发送网卡的原始数据包。常是用于编写一些网络工具,例如抓包工具等。
-
这三种套接字不是独立的东西,而是 socket 这个大接口下的 3 种具体实现、3 种通信模式。
-
如果我们按照历史的发展来看,最开始 UNIX 只有管道、命名管道做本机进程通信;网络通信也各自杂乱,没有通用收发接口。Socket 最原始诞生目的,就是为了解决跨主机网络通信,最早就是我们说的【网络套接字】,统一封装 TCP/IP,给进程一套标准化跨网收发接口。又因为UNIX 系统本来就极度依赖文件系统做进程交互,开发者不想再搞一套全新 IPC 接口,索性就直接复用成熟的 socket 这套统一读写模型,向下兼容本机进程通信于是就扩展出了【Unix 域间套接字】,用文件路径替代 IP 端口,复用一模一样的 bind/listen/connect/read/write 全套接口,不用新增任何系统调用,完美兼容老进程通信生态。后面网络底层运维、抓包需求越来越多,又再扩展出能直接操作 IP 层、链路层的【原始套接字】,依旧套在 socket 统一文件式接口里。
-
所以 Socket 是一套统一文件式 IO 接口。网络套接字、域间套接字、原始套接字,是这套接口顺着 UNIX 网络发展历史,一步步扩展出来的 3 种通信场景实现。内核只需要维护一套用户态系统调用逻辑,就能同时覆盖:跨外网通信、本机 IPC 进程通信、底层网卡抓包运维三大场景,极致复用设计。
socket 通用结构体
前面我们已经理清:Socket 最初为跨主机网络通信诞生,后续为兼容本地进程 IPC、底层网络抓包需求,一步步迭代扩展出网络套接字、Unix 域间套接字、原始套接字三种成熟的通信模式。
但是三种套接字负责不同通信场景,底层内核实现差异极大:网络套接字走 TCP/IP 协议栈、本地套接字走内核内存 IPC、原始套接字直接操作网络层。
如果开发者针对每一种套接字,单独写一套系统调用函数,会导致接口完全割裂、并且学习成本高,对用户极度不友好。因此 Linux 内核专门设计了一层软件层,用一套通用系统调用函数,兼容全部 3 种套接字通信模式,大幅降低网络开发门槛。
这套统一抽象里,最核心就是 socket 地址结构体设计,并且也体现出 C 语言继承多态的特性:
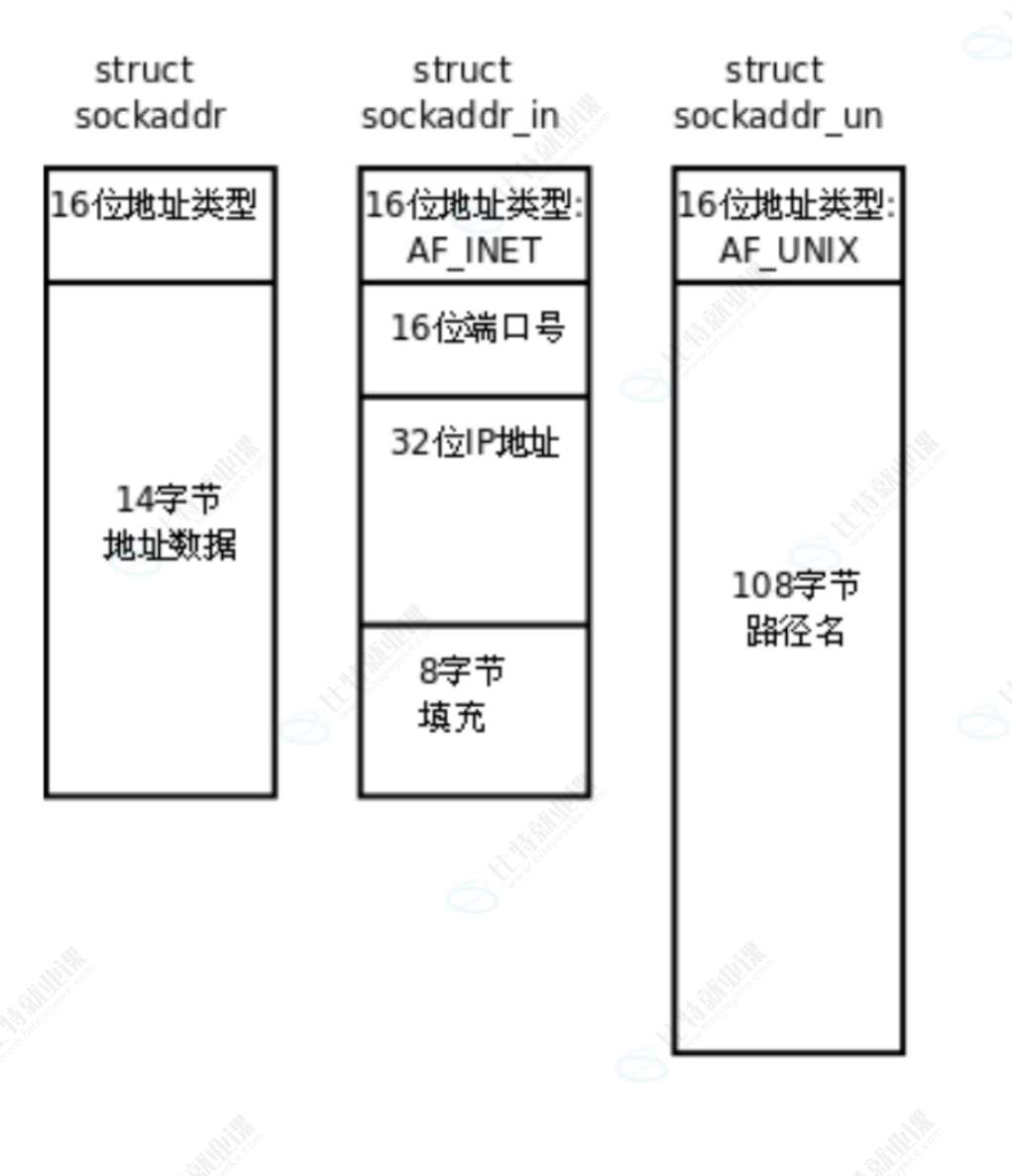
struct sockaddr:是通用基类结构体,固定开头16 位地址类型字段,后面预留通用地址数据区,作为统一入参格式,给 bind/coect 等系统调用统一传参。
struct sockaddr_in、struct sockaddr_un 是两种业务子类结构体 :
- 网络套接字专用 sockaddr_in:首字节同样是 16 位协议类型AF_INET,后面填充端口、IP 地址网络通信参数
- 域间套接字专用 sockaddr_un:首字节同样是 16 位协议类型AF_UNIX,后面填充文件路径本地通信参数
两个子类结构体首地址、首字段完全对齐基类,就可以实现基类指针指向子类对象。
这样用户开发时,只需要定义对应通信模式的子类结构体,填充 IP 端口 / 文件路径业务参数 ;调用 bind 等系统调用时,强制转成通用 sockaddr 基类指针传入;内核拿到指针后,只读取结构体最开头16 位地址类型字段,就能精准识别:当前是网络通信、还是本地进程通信,自动走对应套接字内核逻辑。原始套接字也沿用同一套设计逻辑,整套 bind/listen/connect 读写函数完全通用,用户只需要换结构体、填对应地址参数,不用学习三套完全不一样的接口。
简单来说:三种套接字通过通用 sockaddr 结构体 + 统一系统调用,这就是包裹在外面的简化软件层;靠 C 语言结构体首地址对齐,实现基类指针管理子类对象,靠开头 16 位协议族字段做运行时类型区分,一套接口兼容全场景网络通信。
socket常见API
socket
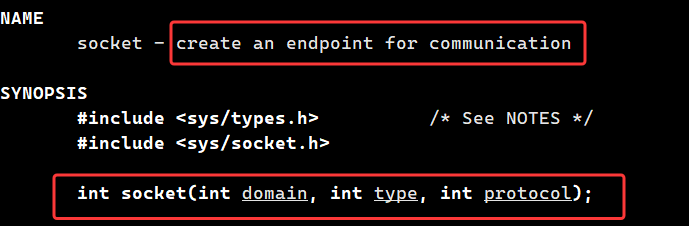
socket() 就是创建一个通信端点(endpoint)。它的作用是向内核申请一个通信对象。因为在 Linux 中一切皆文件。无论是磁盘上的普通文件、设备驱动,还是我们今天讲的网络套接字(Socket),在操作系统眼中都是一个个的"文件对象"。因此,socket() 系统调用在底层做的事情,本质上就是内核在内核空间申请一块内存,构建用于描述网络连接的 socket 结构体。在当前进程的文件描述符表(File Descriptor Table)中,为这个内核对象分配一个唯一的编号。将这个编号(文件描述符 FD)返回给用户。后续的 bind、listen、connect、send、recv 等所有操作,都是通过这个 FD 来定位内核中的。

成功返回一个非负整数,就是 socket 文件描述符 fd,一般从3开始。失败则返回 -1,错误信息存在 errno 里。

第一个参数 domain 表示是在通信域内,决定用哪种套接字模式,对应我们前面讲的三种套接字:
- (1) AF_INET:网络套接字(跨主机 TCP/UDP),最常用的
- (2) AF_UNIX:本地域套接字(本机进程通信)
- (3) AF_PACKET:原始套接字(直接操作网卡)

第二个参数 type 表示的是通信类型 :
- SOCK_STREAM:TCP 流式套接字(可靠、面向连接)
- SOCK_DGRAM:UDP 数据报套接字(无连接、不可靠)
第三个参数 protocol 表示具体协议,大部分场景下,前两个参数已经确定了协议,这里传 0 就行。
填充网络信息
调用 socket() 系统调用后,内核为我们创建了一个通信端点,并返回了一个文件描述符 fd。此时,我们手里只有一个 "空的账户"(fd),还不知道要连接哪台主机、用哪个端口。接下来的关键步骤,就是填充通信信息。
为了告诉内核 "我要连谁" 或 "我是谁",我们需要填充一个地址结构体。这个结构体就是 struct sockaddr。如下 :
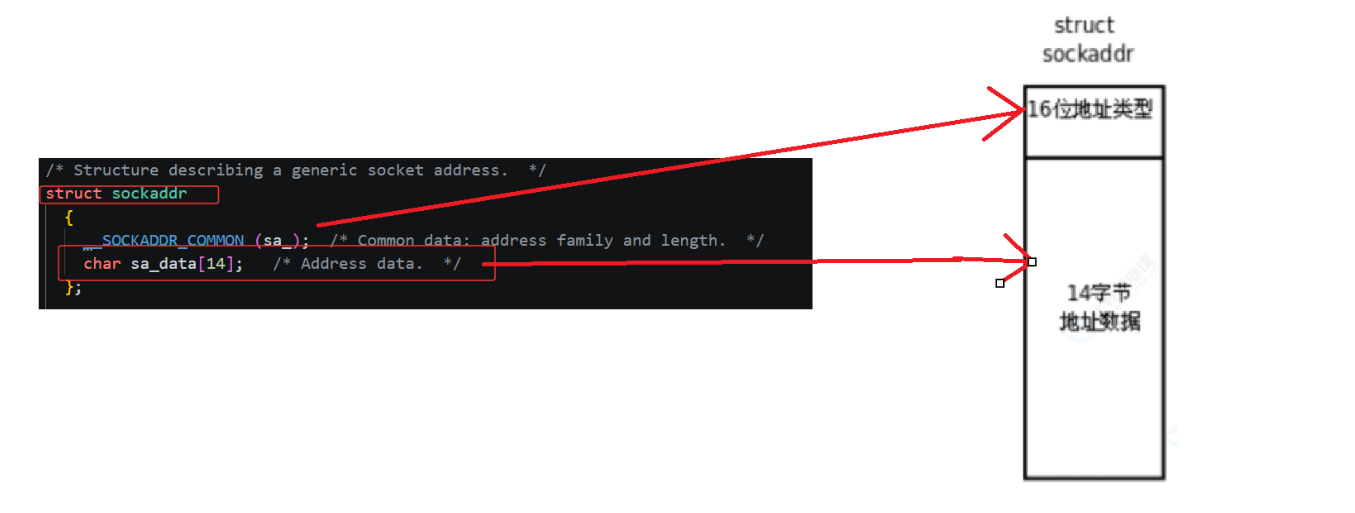
但是,直接操作 struct sockaddr 里面的 sa_data14 数组非常麻烦(需要手动拼凑 IP 和端口)。因此,实际开发中我们通常使用它的专用版本 ------struct sockaddr_in。如下 :
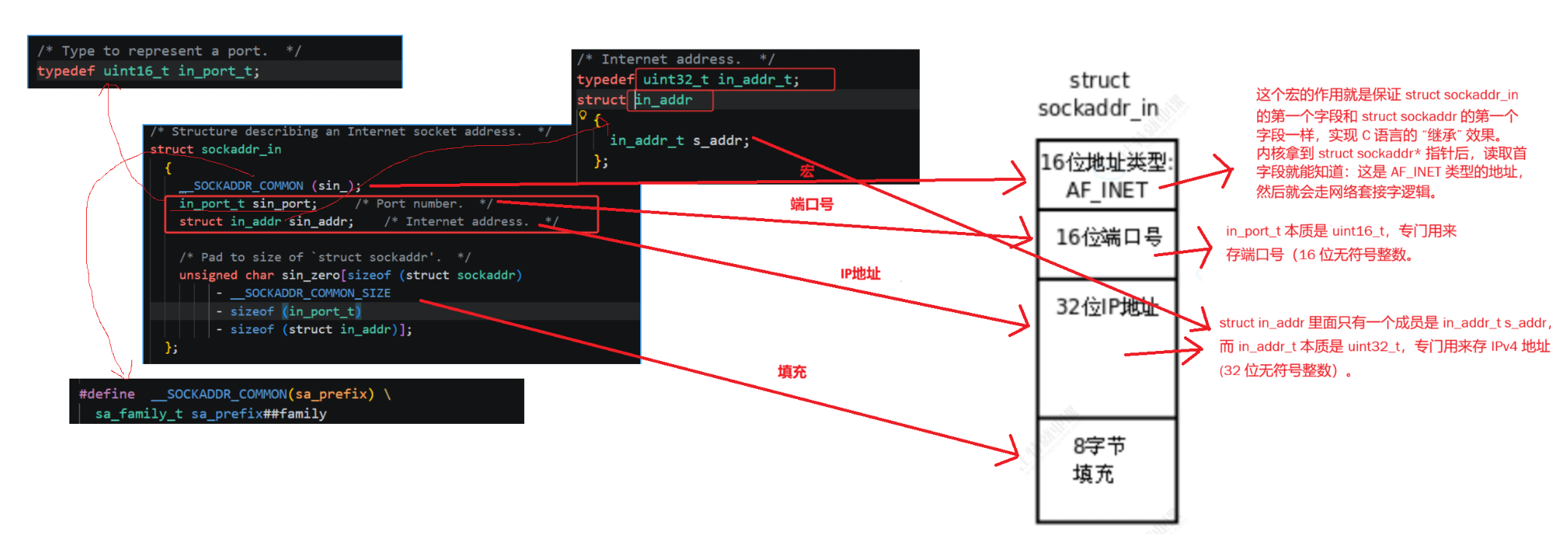
我们填充完 sockaddr_in 后,将其传给 bind 或 connect 时,必须强制类型转换为 struct sockaddr*。这也就是我们之前讨论的 "统一软件层" 和 "C 语言多态":系统调用接口只认通用的 struct sockaddr,但内核内部会通过读取结构体开头的 sa_family 字段,来识别这其实是一个 AF_INET 类型的网络地址,从而执行对应的网络协议栈逻辑。代码如下 :

bind
我们填充一个地址结构体 struct sockaddr_in 后,这一步并没有真正进入内核,只是用户层的地址配置。真正让内核识别并绑定这个地址的,是 bind() 系统调用。当 bind() 被调用时,用户态数据被拷贝到内核空间,内核根据地址族识别出这是 AF_INET 网络套接字,并将 IP 和端口正式挂载到 socket 对象上,完成最终绑定。
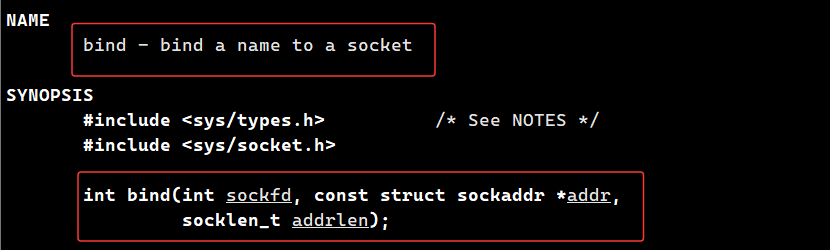
它的本质,就是把我们在用户态填充好的地址信息,真正挂载到内核的 socket 对象上。对服务器来说绑定 IP 和端口,是让客户端知道找谁连接。
第一个参数 sockfd 是 socket() 调用返回的文件描述符,用来定位内核中绑定的那个 socket 对象。
第二个参数 addr 是通用地址结构体指针 sockaddr*,我们之前填好的 sockaddr_in/sockaddr_un 都要强制转成这个类型。内核通过它开头的地址族字段,识别是哪种地址(网络 / 本地域)。
第三个参数 addrlen 是地址结构体的长度(比如 sizeof(struct sockaddr_in)),告诉内核要拷贝多少字节的地址数据。
返回值成功返回 0,失败返回 -1,错误码存在 errno 里。

六、总结
本文系统介绍了网络通信的基础概念与实现机制。首先阐述了端口号的作用,它是传输层标识主机内进程的关键标识,与IP地址共同构成网络通信的地址基础。接着深入分析了网络通信的本质是跨主机的进程间通信,而Socket作为操作系统提供的网络接口,屏蔽了底层细节,使进程能够便捷地进行网络数据传输。文章详细讲解了TCP和UDP协议的特点与适用场景,TCP提供可靠连接而UDP侧重高效传输。此外还介绍了网络字节序的重要性及转换方法,确保数据在不同主机间正确传输。最后详细解析了Socket编程的核心API,包括socket()创建通信端点、bind()绑定地址等,展示了Linux系统如何通过统一的接口设计支持多种网络通信场景。
谢谢大家的观看!