MATLAB小tips:
fpga_complex_out'是复共轭转置
fpga_complex_out.':只转置
注意:
ready代表着下游收不收
仿真小tips:
"从 0 开始"
Restart:时间归0
可以在MATLAB中生成数据送入仿真中,看Vivado结果是不是和MATLAB的输出相同
知识小tips:
1,
always @(posedge clk ) begin
if (rst_n==1'b0) begin
tx_state <= state_idle;
cnt <= 0;
end
else if (sign_uw_ready || tx_state == state_idle) begin
tx_state <= tx_nextstate;
if (tx_state != tx_nextstate)
cnt <= 0; // 换状态时计数器清零
else if (tx_state != state_idle)
cnt <= cnt + 1;
end
end
当 posedge clk 触发的那个绝对瞬间,FPGA 会立刻举起相机,对所有的寄存器拍一张"快照"。
-
在这一拍,
state的值是旧的(比如还是ST_IDLE)。 -
而
next_state是通过上面那段组合逻辑刚算出来的新值(比如ST_HEAD_UW)。
在这个 always 块里的所有右边(等号右侧、if 括号里)的变量,全部强制使用这张快照里的旧值!
现在,系统开始一行一行看代码:
-
看到
state <= next_state;-
动作 :系统拿个小本本记下:"好,等会我要把
ST_HEAD_UW写进state里。" -
注意 :此时
state的物理电压根本没有变 ,它还是ST_IDLE!这就是"非阻塞"的含义------它不阻塞下面代码的运行。
-
-
看到
if (state != next_state)-
判定 :系统翻开刚才的快照一看,旧的
state是ST_IDLE,算出来的next_state是ST_HEAD_UW。 -
结果 :
ST_IDLE != ST_HEAD_UW,条件成立(True)!
-
-
看到
cnt <= 0;- 动作 :系统又拿小本本记下:"好,等会我要把
cnt清零。"
- 动作 :系统又拿小本本记下:"好,等会我要把
所有代码看完了,最后一步:同时放行! 系统根据小本本上的记录,在极短的延迟后,把物理大门统一打开:state 瞬间变成了 ST_HEAD_UW,同时 cnt 瞬间变成了 0。
在硬件里(<=):无论你写在前面还是后面,只要在一个 always 块里,等号左边的变量在这一瞬间绝对不会变,它要等到整个块结束时才集体突变!
2,
在 Verilog 里,只要是被放在 always 块里通过 = 或者 <= 赋值的信号,它的类型必须是 reg 。你定义成了 wire,编译器会直接报语法错误。
在always和initial块里的变量要用reg型变量
3,rom_addr分析
wire 6:0 rom_addr;
wire 6:0 next_rom_addr = sign_uw_ready ? (cnt6:0 + 1'b1): cnt6:0;
assign rom_addr = (tx_state == state_idle || tx_state == state_data) ? 7'd0 : next_rom_addr;
在真实的 FPGA 里,ROM(底层是 BRAM 物理硬核)有一个雷打不动的物理特性:1 拍读延迟 (1-Cycle Latency)。
这意味着:如果你在第N个时钟的上升沿给它地址 0,它要在第 N+1个时钟的上升沿,才能把第 0 号抽屉里的数据吐出来。
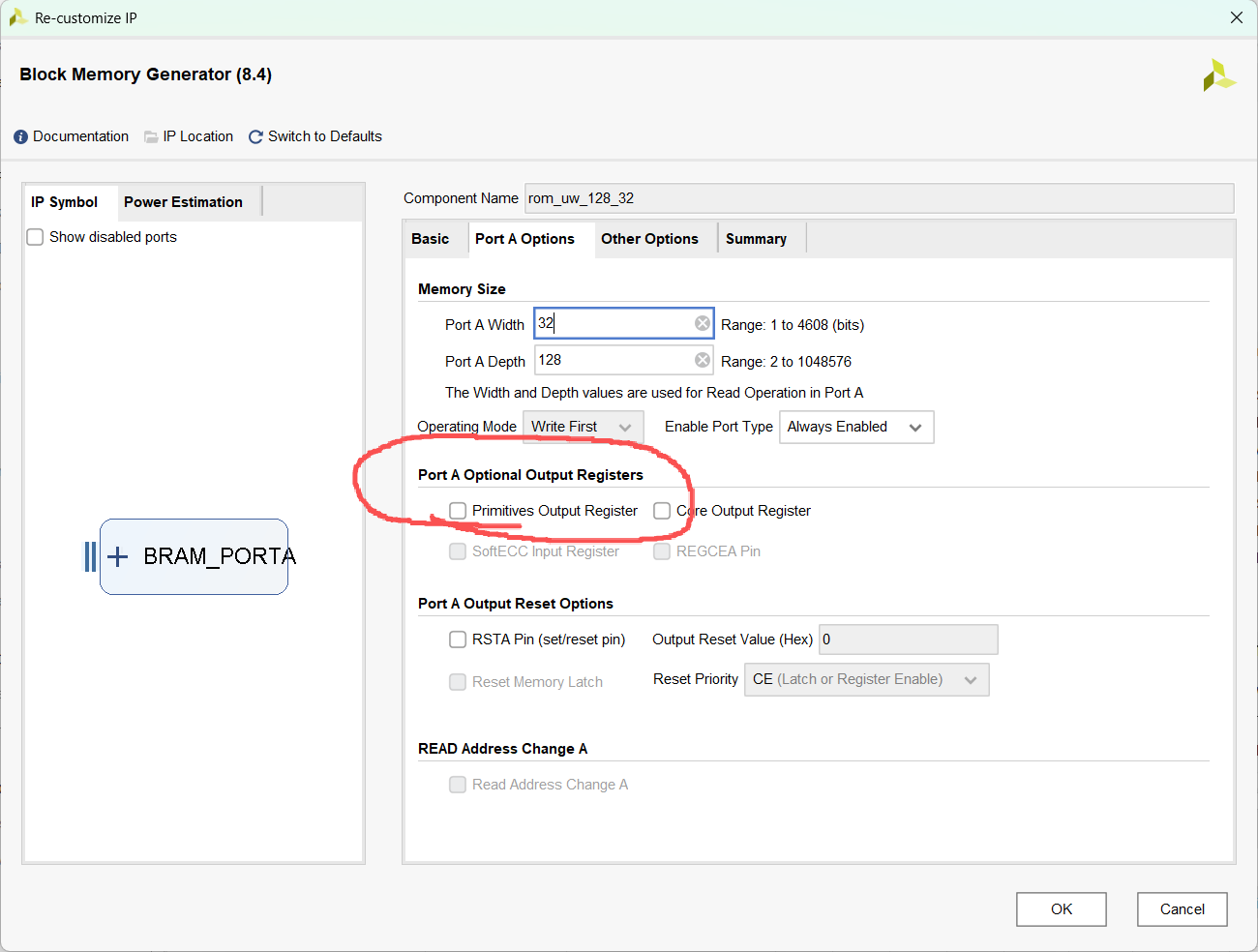
这个选项(它通常默认是勾选的,这会在物理层面上多加一级 D 触发器,增加一拍延迟)。取消勾选它!确保 ROM 只有最基础的 1 拍读取延迟。
如果下游亮绿灯(ready == 1),我要的下一个地址就是 cnt + 1;如果下游亮红灯堵车了(ready == 0),我要的地址就保持在 cnt。
只要系统还在"空闲等待状态"或者正在"发业务数据状态",我就强行把 ROM 的地址按死在 0。一旦进入发 UW 的状态,我才把地址控制权交还给 next_rom_addr。
4,tb_sign_uw_inserter波形分析
注意:

大概有100ps的偏差,
既然你明确是在做"行为级仿真 (Behavioral Simulation)",理论上代码是 0 延迟的,那这个偏差是从哪来的?真相只有一个:这是 Xilinx 仿真库为了保护你,强行给你注入的"人工延迟"!
在数字电路中,时钟敲击触发器到数据输出,需要物理时间,这叫 T_{co}。在纯正的 IEEE Verilog 标准行为仿真里,T_{co} 是被当作 0 的。 但是,你现在的工程里混入了 Xilinx 的官方 IP(FIFO 和 ROM)!
当 Vivado 和 Questa 联调,并引入 Xilinx 底层库(unisims / xpm)时,Xilinx 的仿真引擎做了一个非常"鸡贼"但也极其聪明的操作: 它会在后台全局范围内,给所有的时序寄存器(包括你手写的 cnt 和 tx_state)强行加上一个极其微小的人工延迟(通常是 100ps 或者 1ns)。
为了让这种"自己写的纯 RTL"和"官方 IP 黑盒"在一起完美协同,工具故意让所有的寄存器输出在时钟沿之后**"稍微等一小会儿(产生这道缝隙)"**再变化。这样,下一个模块在时钟沿抓数据时,抓到的就绝对是稳如泰山的旧数据,彻底消灭了仿真层面的时序错乱。
为什么偏偏是 100ps?
在 Xilinx 的仿真世界里,为了防止我们手写的 Verilog 代码和他们封装好的硬核 IP(比如你的 FIFO 和 BRAM)在同一个绝对时钟沿发生"追尾相撞"(这在仿真学里叫 Delta Cycle 竞争冒险),Xilinx 设定了一个全局的保护规则:
它就像是交通规则里的"起步安全时间"。时钟上升沿就像是绿灯亮起,Xilinx 强制规定:所有底层触发器看到绿灯后,必须强制等待 100ps 才能踩油门让数据跳变。 这 100ps 的"微小延迟"起到了极其关键的作用:
-
它让下游模块在时钟边沿抓取数据时,抓到的绝对是上一拍稳如泰山的旧数据。
-
等下游模块抓完数据后(0ps 瞬间完成),上游的数据才在 100ps 后慢悠悠地更新。
-
这样就从根源上彻底消灭了仿真环境下的"保持时间违例(Hold Time Violation)"。

在黄线时钟上升沿这一刻,sign_symbmod_i输入为16'ha000,输入sign_symbmod_valid有效标志,并且只要FIFO内部现有数据量少于1500,输出sign_symbmod_ready也一直为1。
输出sign_uw_i还得等存进768个数据才开始输出,输出sign_uw_valid有效标志置0,输入sign_uw_ready一直为1,下游一直准备好。
"Write-to-Empty Deassertion Latency"(写数据到空标志撤销的延迟)。 手册里明确写着:对于基于 BRAM 的同步 FIFO,从你写入第一个数据(wr_en ,本代码中就是sign_symbmod_valid,拉高),到内部逻辑算完账、并且把出货口的 empty 信号拉低,固定需要经历 3 到 4 个时钟周期。
tx_state与tx_nextstate一开始都为1。
下一拍:
fifo_sign_count更新为1.
下三拍:
sign_empty置为0,表示非空。送入的第一个数据a000b000挂靠在sign_fifo_dout上。

在黄线时钟上升沿的这一刻,前一红圈内的数据就是第768个数据,但是fifo_sign_count在下一时钟上升沿才更新为768。
在fifo_sign_count变为768的瞬间,
if (fifo_sign_count >= data_len) begin
tx_nextstate = state_head_uw;
end 下一状态更新为state_head_uw,2
下一拍:

在黄线时钟上升沿的那一刻,rom_addr采集到的依然是上一拍保持的地址00。ROM 内部的硬核收到指令:"收到!开始去第 00 号抽屉里抓取数据。"00号抽屉里面是00000000,所以直接输出就是。
因为sign_uw_ready为1,tx_state 更新为tx_nextstate 2。
并且同时检测到tx_state与tx_nextstate不等,cnt计数器清零。(只要sign_uw_ready为1,next_rom_addr的值就是计数器的值加1,黄线时刻的值就是01)
tx_state 更新为2了,赋值rom_addr为next_rom_addr,rom_addr的值为01了
tx_state 更新为2了,sign_uw_i的输出就是rom_data_out15:0,sign_uw_valid 赋为1'b1
再下一拍:
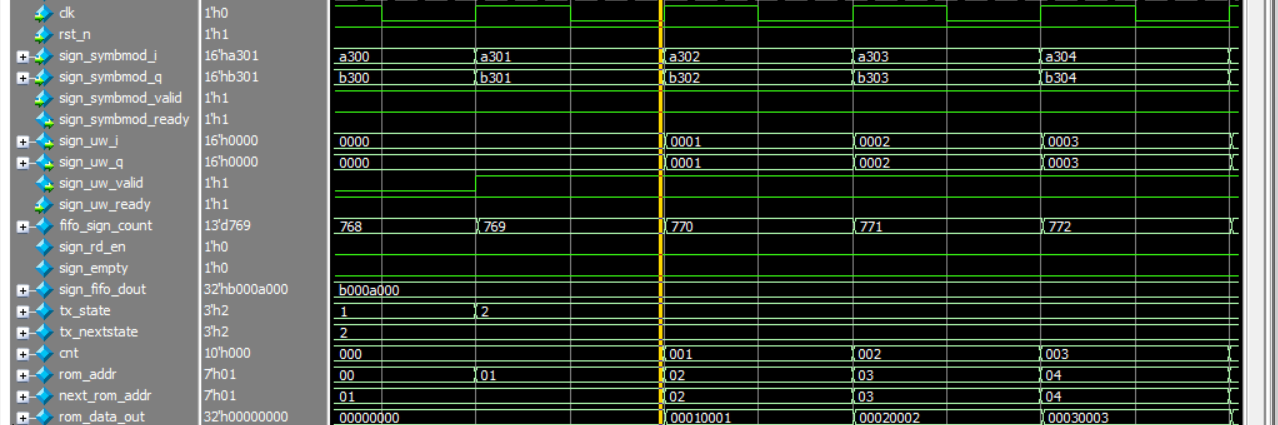
tx_state为2:
在时钟上升沿那一刻,cnt计数加1
next_rom_addr更新为2,赋给rom_addr为2
但是在黄线时钟上升沿的那一刻,rom_addr采集到的依然是上一拍保持的地址01,ROM 内部的硬核收到指令:"收到!开始去第 01 号抽屉里抓取数据。"01号抽屉里面是00010001,所以直接输出就是。
之后就一直这样,直到

在时钟上升沿那一刻,cnt计数加1,此时为07f(127)。判决符合条件,tx_nextstate更新为3。
在黄线时钟上升沿的那一刻,rom_addr采集到的依然是上一拍保持的地址7f(127),ROM 内部的硬核收到指令:"收到!开始去第 7f号抽屉里抓取数据。"7f号抽屉里面是007f007f,所以直接输出就是。
按理来说,此时next_rom_addr的值应为07f+1,但是这样就位宽溢出(Overflow / 回绕)。
执行加法 :下游亮绿灯,执行 + 1 的操作。 7'b111_1111 + 1 = 8'b1000_0000 (产生进位,变成了 8 位宽的值,十进制是 128)。
强行塞入结果 :但是!等号左边的 next_rom_addr 被你声明为 wire [6:0](只有 7 位宽)。 当把一个 8 位宽的 1000_0000 强行塞进 7 位宽的容器时,最高位(那个 1)会被硬件无情地切掉(丢弃) 。 剩下的低 7 位就是 000_0000 ,十六进制显示出来就是 00!
next_rom_addr赋值给rom_addr,也就变成了00.
下一拍:
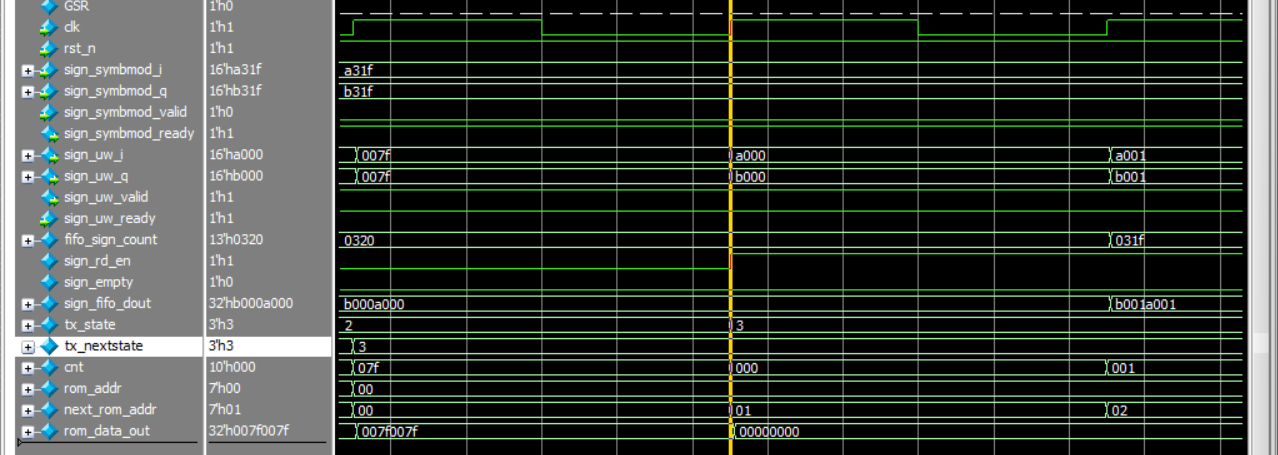
因为sign_uw_ready为1,tx_state 更新为tx_nextstate 3。
并且同时检测到tx_state与tx_nextstate不等,cnt计数器清零 。(只要sign_uw_ready为1,next_rom_addr的值就是计数器的值加1,黄线时刻的值就是01)但是后面暂时不会用到这了。
很早之前送入的第一个数据a000b000就挂靠在sign_fifo_dout上了,
因为assign sign_rd_en = (tx_state == state_data) & sign_uw_ready;此时sign_rd_en就为1了。但是在黄线时钟上升沿的那一刻,模块检测到的依旧是sign_rd_en为0,
第一个数据a000b000依旧挂靠在sign_fifo_dout上,之后赋给sign_uw_i。
下一拍:
在时钟上升沿那一刻,计数器cnt加1。
模块检测到sign_rd_en为1,第二个数据a001b001推到sign_fifo_dout上,fifo_sign_count减1,之后赋给sign_uw_i。
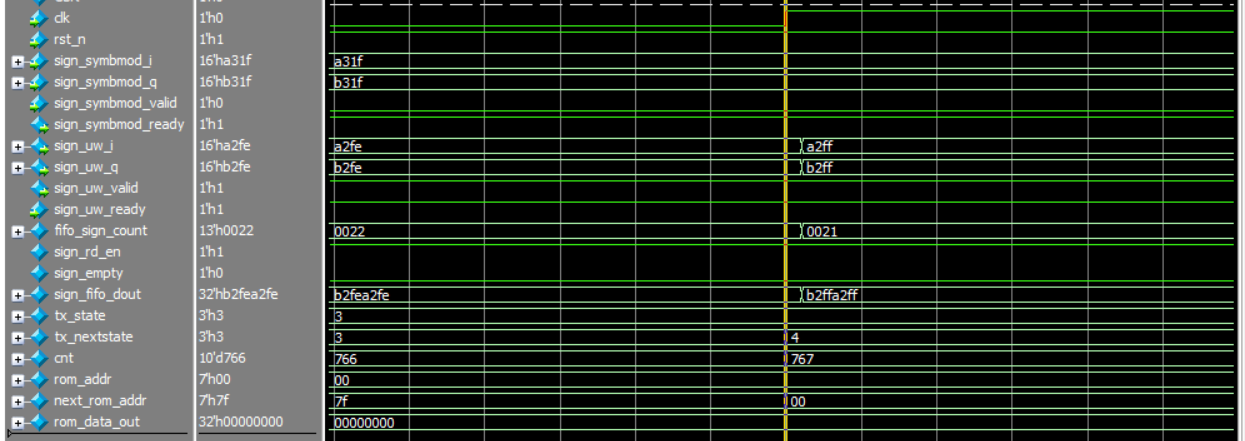
在黄线时钟上升沿那一刻,cnt计数器+1为767,检测到cnt为768并且sign_uw_ready为1,tx_nextstate更新为4,2ff(767)
7'b111_1111 + 1 = 8'b1000_0000 (产生进位,变成了 8 位宽的值,十进制是 128)。位宽溢出了,next_rom_addr变为了00,因为tx_state此时还是3,所以rom_addr依旧是0,rom_data_out上挂靠着00000000。
下一拍:
因为sign_uw_ready为1,tx_state 更新为tx_nextstate 4。sign_rd_en变为0
并且同时检测到tx_state与tx_nextstate不等,cnt计数器清零。
tx_state更新为4之后,sign_uw_i的输出就是rom_data_out15:0,sign_uw_valid 赋为1'b1。
next_rom_addr:计数器+1=01,赋值给rom_addr
第二帧(第二个1024):
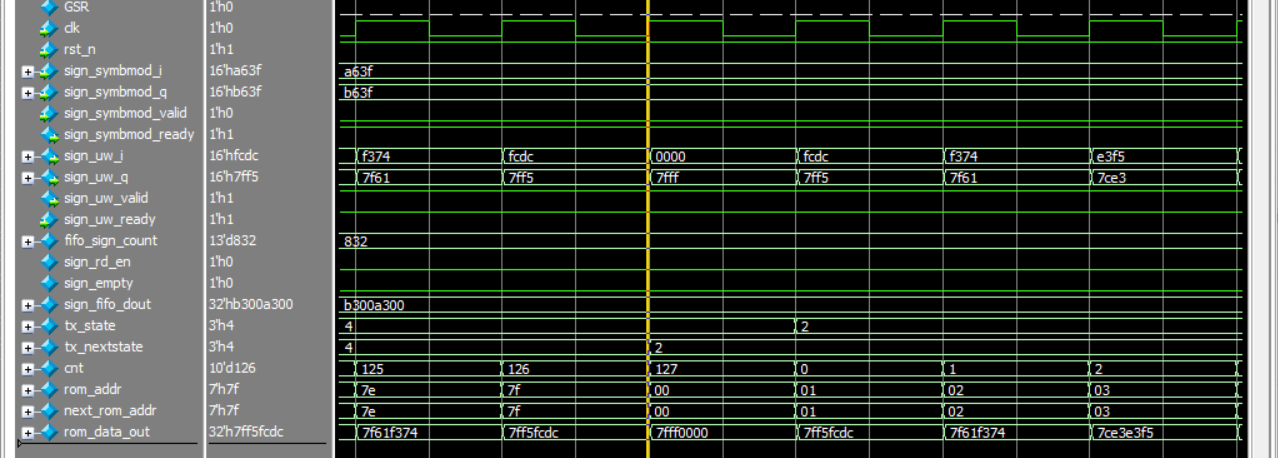
在黄线时钟上升沿的那一刻,因为计数器cnt达到了127但是fifo_sign_count >= data_len,所以tx_nextstate更新为2。
此时在黄线时钟上升沿的那一刻,模块检测到的rom_addr依旧是7f,所以rom_data_out的输出是7FFF0000
5,加装MATLAB生成数据
reg 31:0 payload_mem 0:767;
这是你在仿真器内存里强行开辟的一块二维虚拟阵列(你可以把它想象成一个拥有 768 个抽屉的药柜)。
-
[31:0](抽屉的宽度):规定了每个抽屉里能放 32 比特的数据(刚好装下我们 MATLAB 里拼好的 16 位 I + 16 位 Q)。 -
[0:767](抽屉的数量):规定了这个药柜一共有 768 个抽屉(对应你 768 长度的业务数据 Payload)。 -
⚠️ 架构师注 :这种写法在 Testbench 里极其常见,但它绝对不能被综合到真正的 FPGA 芯片里!因为真实的硬件需要用 BRAM 或分布式 RAM 来存储,而这里只是靠电脑内存虚拟出来的。
integer f_out;
在 Verilog 中,integer 是一个 32 位的有符号整数。这里的 f_out 是一个**"文件句柄(File Handle)"**。 你可以把它理解为操作系统发给仿真器的一张"通行证"。后面仿真器要想往 Windows/Linux 的硬盘里写文件,就必须出示这个 f_out 编号。
initial begin
// 1. 把 MATLAB 的 txt 读入到内存数组中
$readmemh("sim_input_payload.txt", payload_mem);
这是大名鼎鼎的十六进制内存读取函数,h 代表 Hexadecimal(十六进制)。 它就像一个极其高效的搬运工,在仿真的第 0 皮秒瞬间完成以下动作:
-
在 Vivado 的仿真运行目录下去寻找
sim_input_payload.txt这个文件。 -
打开文件,读取第一行的 32 位 16 进制数据(比如
40000000)。 -
把它塞进
payload_mem[0](第 0 号抽屉)。 -
读取第二行,塞进
payload_mem[1]。 -
......直到塞满全部 768 个抽屉,或者文件读到末尾。
有了这一步,你后面在时钟节拍里,只需要用 sign_symbmod_i = payload_mem[i][31:16];,就能像在内存里取变量一样,以极快的速度把 MATLAB 生成的真实信号一拍一拍地喂给下游逻辑了。
// 2. 创建一个输出文件,准备记录 FPGA 吐出的拼装帧
f_out = $fopen("sim_output_verilog.txt", "w");
这是在为后续的"记录得分"做铺垫。
-
$fopen:调用操作系统的功能,在硬盘上创建一个名为sim_output_verilog.txt的空文件。 -
"w"(Write 模式):告诉系统我要往里写东西。如果之前有同名文件,它会毫不留情地把它清空覆盖。 -
交接句柄 :文件创建好之后,系统会返回一个唯一的整数 ID,存到了我们刚才定义的
f_out里面。
在后续的代码里,只要你的 FPGA 吐出了有效数据(valid == 1),你就可以通过调用 $fdisplay(f_out, "%h", data); 这样的语句,向这出示 f_out 通行证,把数据一行一行地印在这个文本文件里。
end
// --- 新增:上帝视角的"自动计分板 (Scoreboard)" ---
// 只要有有效数据输出,就立刻写进 txt 文件!
always @(posedge clk) begin
if (sign_uw_valid && sign_uw_ready) begin
// 按照 16进制格式记录 FPGA 的输出
$fdisplay(f_out, "%h %h", sign_uw_i, sign_uw_q);
end
end
注意:
%h:自动十六进制,位数不固定,不补零%04x:固定4 位十六进制 ,不足 4 位前面补 0
6,定点量化
6.1,为什么需要定点量化?(浮点vs定点)
在 MATLAB 里,你随便写一个 sin(x),它默认是用 64位双精度浮点数(Double) 来存储的。 浮点数就像科学记数法(比如 1.234*10^{-5}),它有一个"尾数"和一个"指数"。小数点是可以到处"浮动"的,所以它的精度极高,动态范围极大。
但是,FPGA 极其讨厌浮点数! 要在 FPGA 里用硬件电路实现一个浮点数加法器或乘法器,需要消耗海量的逻辑门(LUTs)和 DSP 资源,而且运算极慢、极其费电。对于动辄几百兆采样率的基带通信系统(比如你的 SC-FDE),用浮点数来实时处理信号简直是灾难。
因此,工业界采用了"定点数(Fixed-Point)": 我们硬性规定小数点的位置永远固定死**在某两位之间。既然小数点不动了,硬件就不需要去计算和对齐指数了,所有的加减乘除直接变成了最简单的二进制整数运算,速度起飞,资源极省!
6.2,核心奥秘:Q格式(Q-Format)
既然小数点固定了,那到底固定在哪里?这就引出了定点量化的行话:Q 格式 。 一个位宽为 N的有符号定点数,通常记为 Qm.n:
-
1 位符号位(最高位)。
-
m位整数位(决定了你能表示的最大数值范围,即"动态范围")。
-
n位小数位(决定了你能表示的最小刻度,即"精度")。
-
总位宽 N = 1 + m + n。
你的 UW 数据是复平面上的点,实部和虚部的值都在 -1.0, 1.0之间。你需要用 16 位寄存器(reg signed [15:0])来存它。
因为数值没有超过 1,所以我们不需要整数位(m=0)。我们把除了符号位之外的 15 位,全部用来当小数位。
这就构成了通信基带中最经典的 Q15 格式(或者叫 Q0.15)。
在 Q15格式下:
-
最小值代表:-1.0 (0x8<1000>000)
-
最大值代表:1.0 - 2^{-15} 0x1.111 1111 1111 1111
-
最小物理刻度(分辨率)是:2^{-15} =0.0000305
6.3,定点量化的三大"物理阵痛"
当你把浮点数转化为定点数时,就像把一张高清照片压缩成马赛克,必须经历三个粗暴的步骤(也就是你 MATLAB 代码里做的事情):
第一痛:缩放 (Scaling) ------ 匹配画布大小
硬件不认识小数,只认识整数。为了利用那 15 位小数位,我们必须把原数据放大 2^{15} 倍(也就是乘以 32768 ,为了防溢出通常用 32767)。
- 公式:
理论值 * 放大倍数。比如 0.5 * 32767 = 16383.5。
第二痛:截断与四舍五入 (Rounding) ------ 抹杀零头
FPGA 连半个比特都存不下,所以 16383.5 必须变成纯整数。
-
如果你直接丢弃小数(Floor),会引入固定的直流偏置误差。
-
所以你用了
round()(四舍五入),变成了 16384。 -
架构师注 :那个被抹掉的 0.5,就变成了永恒的量化噪声(Quantization Noise)。
第三痛:饱和与溢出 (Saturation & Overflow) ------ 打破天花板
如果你的理论值算出来是 1.1,乘以 32767 后变成了 36043。这超出了 16 位有符号数的极限(32767),最高位的符号位会被强行翻转,导致一个正的大数瞬间变成了一个极小的负数(波形上出现可怕的倒刺)。
- 在严谨的通信系统里,量化时必须加上饱和截幅逻辑:只要超过 32767,就强行按在 32767;低于 -32768,就死死按在 -32768。
6.4,架构师的铁律:6dB 法则
既然量化会引入噪声,那我们需要多少位宽才够用? 在数字信号处理中,有一条被供上神坛的经验公式:每增加 1 个比特的位宽,系统的信噪比(SNR)大约提升 6dB。

6.5,Q3.12 格式
"1位符号位 + 3位整数位 + 12位小数位"
架构师的底层剖析:为什么是乘以 2^{12} (4096)?
定点数里的小数点,其实根本不存在于物理硅片上,它纯粹存在于我们工程师的脑子里。
在 Q3.12 格式下,最低的一位(第 0 位)代表的物理权重是 2^{-12}。
我们要把数学上的小数 1.0 塞进这个格式里,就等于问:"1.0 里面包含了多少个 2^{-12}?"
答案显然是:1.0 /2^{-12} = 2^{12} = 4096。
所以,经过修改后的代码:
-
如果你的实部是
1.0乘以 4096 存进内存的是4096。转化为 16 进制就是1000。 -
如果你的实部是
0.5乘以 4096 存进内存的是2048。转化为 16 进制就是0800。
你得到了什么?(更大的整数天花板)
Q3.12 格式有 3 个整数位,加上 1 个符号位。这意味着你的系统现在能够不溢出地表示 **-8.0, 7.99975**之间的庞大数值!
这在 SC-FDE 系统中极其关键。因为你的基带信号后续可能要经过 IFFT/FFT 模块,或者经历多径信道的叠加,信号的幅度很容易突破 1.0 的限制。留出 3 位整数位作为"裕量(Headroom)",能完美防止 FFT 运算时的溢出灾难。
你付出了什么?(量化噪声的增加)
你的 Chu 序列最大值也就是 1.0。在 Q3.12 格式下,1.0 对应的物理寄存器数值只有 4096。
而 16 位有符号寄存器的物理极限是 32767。这意味着,你的 UW 数据在寄存器里只占用了低 13 位的空间,最高位的 3 根物理导线永远是和符号位相同的延伸(无效浪费)。
相比于原来的 Q15 格式,你损失了 3 个比特的精度(大约增加了 18dB 的量化底噪)。
7,动态背压测试
在理想状态下,我们写Testbench喜欢把下游的ready信号永远拉高(ready=1),这个叫下游无限吞吐量。但在真实的芯片世界,下游可能是一个运算很慢的FFT模块,或者是一个刚好快满的异步FIFO,它们随时可能向你亮起红灯(ready=0),要求你暂停你发送。
考验一:状态机会不会"跑飞"?
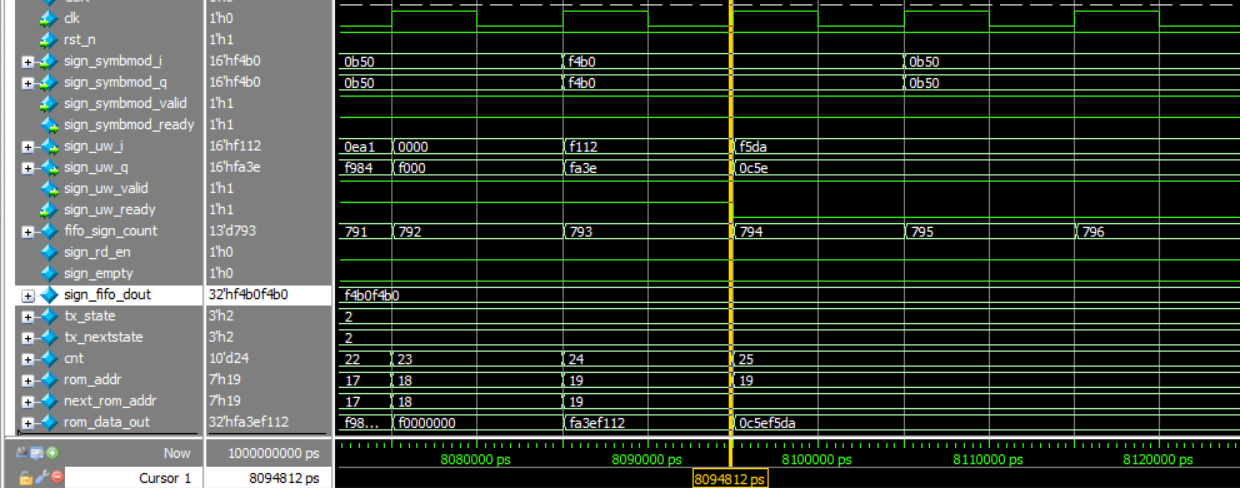
当我的状态机在发送128UW时,当发送到第25个点,下游突然亮起红灯(ready变0持续50拍)。
优秀的模块:状态机会立刻冻结在当前状态,计数器cnt停止加1,死死咬住第25个数据不放。
糟糕的模块:状态机没管下游,自己继续往下数,结果中间的 50 个 UW 数据被抛弃到了虚空中,导致接收端解调彻底失败。
在黄线时钟上升沿的那一刻,计数器cnt加1,变成25。
next_rom_addr检测到sign_uw_ready变为0,取当前的cnt值;rom_addr就等于next_rom_addr。
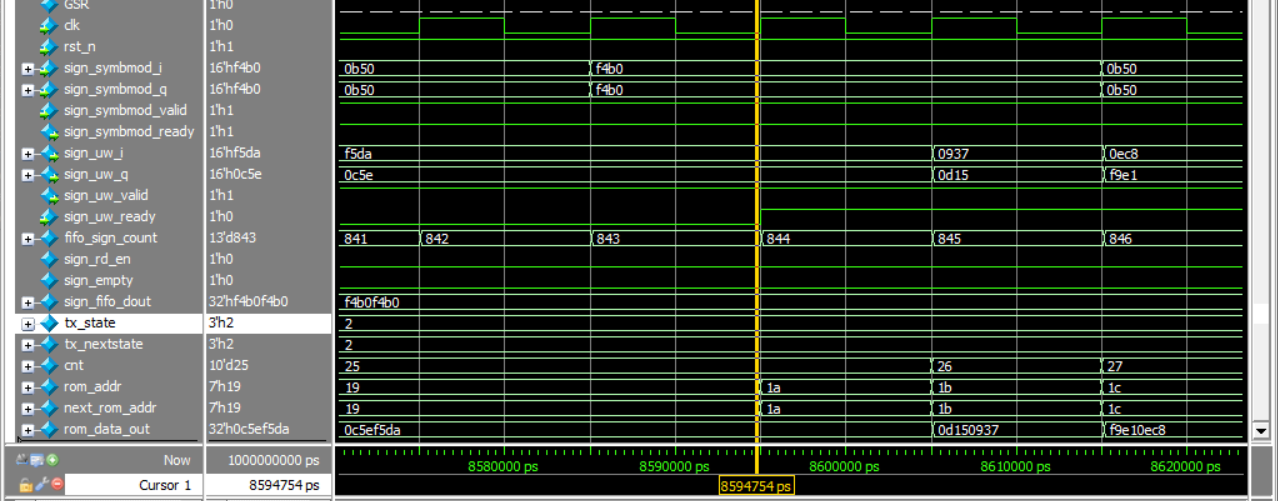
在黄线时钟上升沿的那一刻,rom_addr检测到还是19,rom_data_out还是挂靠着0c5ef5da,sign_uw_i/q输出就是这。但是此刻检测到的sign_uw_ready是0,没达成握手,所以此时的sign_uw_i/q不会导出。
并且此刻检测到的sign_uw_ready是0,计数器也不会加1。
那一刻之后sign_uw_ready变1,next_rom_addr赋值计数器cnt加1,变成1a;随后rom_addr也赋值为1a。
考验二:FIFO的数据会不会"漏水"?
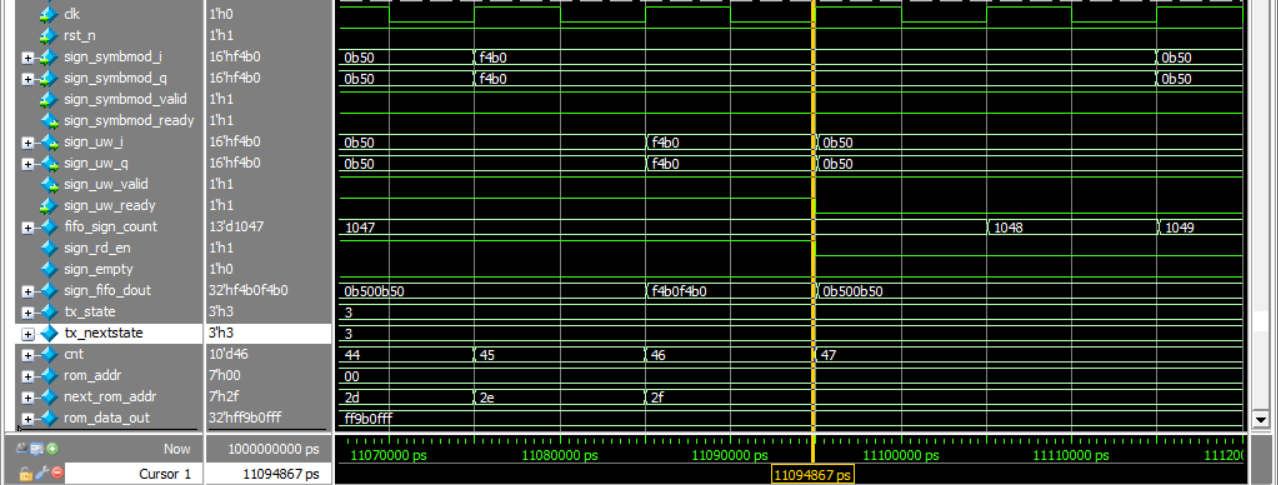
在发业务数据(Payload)时,如果下游红灯亮起。你的 data_rd_en(FIFO 读使能)必须立刻跟随 ready 拉低。如果晚了一拍,FIFO 里的宝贵业务数据就会被强行读出并丢弃,出现致命的**"丢包"**
考验三:出站数据的"有效性"保障
在这个红绿灯机制下,你在波形图上会观察到极其漂亮的一幕:你的 sign_uw_valid 输出信号,会像镜像一样 完美跟随这个 50 拍的 ready 信号上下跳动。只有在 valid == 1 且 ready == 1 的瞬间,数据才算真正完成了交接(这就是 AXI-Stream 握手协议的灵魂)。