1.启动Hadoop集群
在完全分布模式下,必须同时启动所有虚拟机和Hadoop服务,集群才能正常工作。
Hadoop是一个"主从架构"的分布式系统,Master节点(NameNode, ResourceManager)本身不存储数据 ,也不执行计算任务。
-
数据不可见 :你的文件实际存储在
Slave1和Slave2的 DataNode 上。如果它们没启动,HDFS 里就是空的。 -
任务跑不动 :计算任务(MapReduce)是由
Slave1和Slave2上的 NodeManager 执行的。Master 只负责分配任务,没人干活程序就会报错。 -
缺少数据节点 :HDFS 默认通常有副本数(如
dfs.replication=2),如果活着的节点数量少于副本数,系统会认为集群异常。
正确启动与验证方式
请保持三台虚拟机同时运行 ,然后在 master 节点上执行:
注:不要只看 master,你需要确认三台机器都在正常工作。在 master 上执行以下命令检查所有节点:
bash
# 批量查看三台机器的进程
for host in master slave1 slave2; do
echo "========== $host =========="
ssh $host jps
done健康的输出应该是:
-
master :
NameNode,SecondaryNameNode,ResourceManager -
slave1 :
DataNode,NodeManager -
slave2 :
DataNode,NodeManager
实际操作输出(先启动Hadoop集群再操作下面的命令):
bash
[root@master /]# for host in master slave1 slave2; do
> echo "-------------- $host ----------------------"
> ssh $host jps
> done
-------------- master ----------------------
4449 Jps
3609 ResourceManager
3309 SecondaryNameNode
3087 NameNode
4015 JobHistoryServer
-------------- slave1 ----------------------
2919 DataNode
3035 NodeManager
3549 Jps
-------------- slave2 ----------------------
2881 DataNode
2997 NodeManager
3511 Jps| 符号/关键字 | 作用 | 是否必需 |
|---|---|---|
for |
循环开始关键字 | ✅ 必需 |
in |
指定要遍历的列表 | 可选(默认使用位置参数) |
; |
分隔同一行的多个命令 | ❌ 可换行代替 |
do |
标记循环体开始 | ✅ 必需 |
done |
标记循环体结束 | ✅ 必需 |
变量名 |
存储当前迭代的值 | ✅ 必需 |
https://chat.deepseek.com/share/eoycr52eo3t3d2se2z
-
浏览器验证
打开浏览器访问 Web 界面,确认 Live Nodes 数量显示为 2(代表两台从节点都在线)。
-
HDFS 界面:
http://master:9870 -
YARN 界面:
http://master:8088
-
-
1的前提要在master中关闭防火墙
bash
[root@master /]# systemctl status firewalld # 查看防火墙状态
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2026-04-23 07:45:12 CST; 48min ago
Docs: man:firewalld(1)
Main PID: 685 (firewalld)
CGroup: /system.slice/firewalld.service
└─685 /usr/bin/python2 -Es /usr/sbin/firewalld --nofork --nopid
Apr 23 07:45:12 master systemd[1]: Starting firewalld - dynamic firewall daemon...
Apr 23 07:45:12 master systemd[1]: Started firewalld - dynamic firewall daemon.
[root@master /]# # 临时关闭防火墙
[root@master /]# systemctl stop firewalld好了,下面是在master节点的操作
bash
[root@master ~]# cd /
[root@master /]# cd /opt/hadoop-3.1.4/sbin # 切换到这个目录下。Linux系统执行命令时,会按照PATH环境变量中定义的目录顺序去查找可执行文件,但我没有将Hadoop目录/opt/hadoop-3.1.4/sbin配置到PATH中,所以系统找不到start-dfs.sh等命令
[root@master sbin]# ls
distribute-exclude.sh hadoop-daemons.sh mr-jobhistory-daemon.sh start-all.sh start-dfs.sh start-yarn.sh stop-balancer.sh stop-secure-dns.sh workers.sh
FederationStateStore httpfs.sh refresh-namenodes.sh start-balancer.sh start-secure-dns.sh stop-all.cmd stop-dfs.cmd stop-yarn.cmd yarn-daemon.sh
hadoop-daemon.sh kms.sh start-all.cmd start-dfs.cmd start-yarn.cmd stop-all.sh stop-dfs.sh stop-yarn.sh yarn-daemons.sh
[root@master sbin]# start-dfs.sh # 启动HDFS(存储系统)
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [master]
Last login: Wed Apr 22 23:52:22 CST 2026 from 192.168.128.1 on pts/0
Starting datanodes
Last login: Wed Apr 22 23:55:00 CST 2026 on pts/0
Starting secondary namenodes [master]
Last login: Wed Apr 22 23:55:03 CST 2026 on pts/0
[root@master sbin]# start-yarn.sh # 启动YARN(资源管理器)
Starting resourcemanager
Last login: Wed Apr 22 23:55:07 CST 2026 on pts/0
Starting nodemanagers
Last login: Wed Apr 22 23:56:02 CST 2026 on pts/0
[root@master sbin]# mr-jobhistory-daemon.sh start historyserver # 启动Hadoop的JobHistory Server(历史服务器),它的核心功能是记录和展示已经运行完成的MapReduce作业的历史信息。 mr指的是MapReduce。daemon是魔鬼的意思,也有守护进程,后台程序,虚拟光驱的意思
WARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
[root@master sbin]# jps # 列出当前用户正在运行的Java进程及其主类名称
3024 Jps
2547 ResourceManager
2965 JobHistoryServer
2262 SecondaryNameNode
1996 NameNode由于我没有将Hadoop的目录配置到PATH环境变量中,所以我想要启动Hadoop集群的话,必须
- 要么进入该目录(/opt/hadoop-3.1.4/sbin)执行start-dfs.sh等命令
- 要么在任意目录下写完整路径:如/opt/hadoop-3.1.4/sbin/start-dfs.sh
1.配置Hadoop环境变量
如果想配置,可以:
方法一:编辑~/.bashrc(推荐)
bash
# 打开配置文件
vi ~/.bashrc
# 在文件末尾添加以下内容
export HADOOP_HOME=/opt/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 保存并生效
source ~/.bashrc方法二:编辑/etc/profile(对所有用户生效)
bash
# 打开系统配置文件
vi /etc/profile
# 在文件末尾添加
export HADOOP_HOME=/opt/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 保存并生效
source /etc/profile验证配置成功:
bash
# 1. 确认环境变量生效
echo $HADOOP_HOME
# 应输出:/opt/hadoop-3.1.4
# 2. 确认命令可用
which start-dfs.sh
# 应输出:/opt/hadoop-3.1.4/sbin/start-dfs.sh
# 3. 现在可以在任何目录执行
cd ~
start-dfs.sh2.jps
jps命令是Java Virtual Machine Process Status Tool(Java虚拟机进程状态工具)的命令行工具
核心作用:列出当前用户正在运行的Java进程及其主类名称
1.基本用法:
bash
[root@master sbin]# jps # 最简单的使用
3024 Jps
2547 ResourceManager
2965 JobHistoryServer
2262 SecondaryNameNode
1996 NameNode输出的含义:
| 列 | 内容 | 说明 |
|---|---|---|
| 第一列 | PID(进程ID) | 操作系统分配给进程的唯一编号 |
| 第二列 | 主类名或Jar包名 | 正在运行的Java程序名称 |
2.输出含义详解:
比如输出:
bash
[root@master ~]# jps
12345 NameNode
12346 SecondaryNameNode
12347 ResourceManager
12348 Jps| 数字(PID) | 进程名称 | 含义 |
|---|---|---|
| 12345 | NameNode | Hadoop 名称节点进程,ID 是 12345 |
| 12346 | SecondaryNameNode | 辅助名称节点,ID 是 12346 |
| 12347 | ResourceManager | 资源管理器,ID 是 12347 |
| 12348 | Jps | jps 命令本身,ID 是 12348 |
PID的作用:
1.查看进程详细信息
bash
# 查看某个进程的详细信息
ps -ef | grep 12345
# 查看进程打开的文件
lsof -p 12345
# 查看进程状态
cat /proc/12345/status2.终止进程
bash
# 优雅终止
kill 12345
# 强制终止
kill -9 123453.查看进程资源占用
bash
# 查看 CPU/内存使用情况
top -p 12345PID的特点:
| 特性 | 说明 |
|---|---|
| 唯一性 | 同一时间,每个 PID 只对应一个进程 |
| 可重用 | 进程结束后,PID 可以被新进程使用 |
| 从 1 开始 | PID 1 通常是 init/systemd 进程 |
| 上限 | Linux 默认最大 PID 为 32768(可调整) |
注:进程ID(PID)在每次Hadoop启动时可能会不同,PID由系统分配
PID 是操作系统动态分配的:
-
进程启动时,系统从可用的PID池中取一个
-
进程结束时,该PID被释放回池中
-
下次启动时,系统可能分配不同的PID
3.jps的常用参数:
| 参数 | 作用 | 示例输出 |
|---|---|---|
jps -l |
显示完整包名 | org.apache.hadoop.hdfs.server.namenode.NameNode |
jps -v |
显示JVM参数 | -Xmx1000m -Xms500m ... |
jps -m |
显示main方法参数 | -Dfs.namenode.rpc-address=... |
bash
[root@master sbin]# jps -l
4322 sun.tools.jps.Jps
2547 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
2965 org.apache.hadoop.mapreduce.v2.hs.JobHistoryServer
2262 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
1996 org.apache.hadoop.hdfs.server.namenode.NameNode4.jps的工作原理:
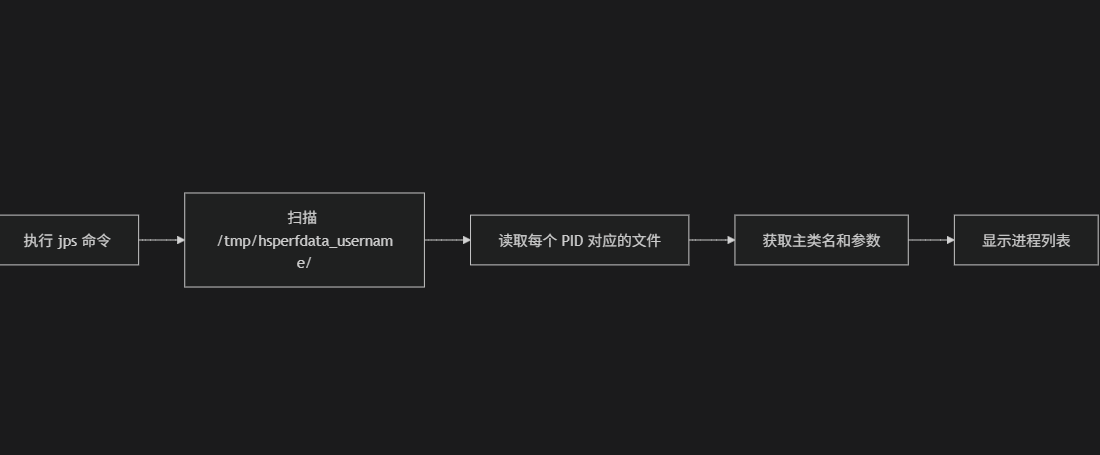
bash
[root@master sbin]# find / -name "jps"
/etc/alternatives/jps
/usr/bin/jps
/usr/java/jdk1.8.0_281-amd64/bin/jps以上输出说明系统中安装了3个jps命令,它们指向同一个JDK,是正常现象,不是错误。
输出解读:
bash
/etc/alternatives/jps # 软链接(符号链接)
/usr/bin/jps # 软链接(符号链接)
/usr/java/jdk1.8.0_281-amd64/bin/jps # 真实的 jps 程序文件这是 Linux alternatives 系统(多版本管理机制)造成的:
| 文件 | 类型 | 作用 |
|---|---|---|
/usr/java/jdk1.8.0_281-amd64/bin/jps |
真实文件 | JDK 实际安装位置 |
/etc/alternatives/jps |
软链接 | alternatives 系统的符号链接 |
/usr/bin/jps |
软链接 | 系统 PATH 中的命令入口 |
查看链接关系:
bash
[root@master sbin]# ls -l /usr/bin/jps
lrwxrwxrwx. 1 root root 21 Mar 26 08:36 /usr/bin/jps -> /etc/alternatives/jps执行jps命令时到底发生了什么?
bash
# 你输入
[root@master ~]# jps
# 系统执行流程:
1. 在 PATH 中找到 /usr/bin/jps
2. 发现是软链接,读取内容:/etc/alternatives/jps
3. 访问 /etc/alternatives/jps
4. 发现也是软链接,读取内容:/usr/java/jdk1.8.0_281-amd64/bin/jps
5. 访问真实文件
6. 执行该文件(运行 jps 程序)3.补充知识:软链接
软链接是Linux中的一种特殊文件,它的内容是一个路径,指向另一个文件或目录。
命令输出解读:
bash
lrwxrwxrwx. 1 root root 21 Mar 26 08:36 /usr/bin/jps -> /etc/alternatives/jps| 字段 | 值 | 含义 |
|---|---|---|
| 第一个字符 | l |
这是一个软链接(l = link) |
| 权限 | rwxrwxrwx |
所有用户都有读写执行权限(指向的目标文件决定实际权限) |
| 链接数 | 1 |
只有这一个链接 |
| 所有者 | root |
属于 root 用户 |
| 大小 | 21 |
路径字符串的长度(21个字节) |
| 日期 | Mar 26 08:36 |
创建时间 |
| 文件名 | /usr/bin/jps |
链接文件本身 |
| 箭头 → | /etc/alternatives/jps |
指向的目标路径 |
bash
[root@master sbin]# ls -l /usr/bin/jps
lrwxrwxrwx. 1 root root 21 Mar 26 08:36 /usr/bin/jps -> /etc/alternatives/jps
[root@master sbin]# ls -l /etc/alternatives/jps
lrwxrwxrwx. 1 root root 36 Mar 26 08:36 /etc/alternatives/jps -> /usr/java/jdk1.8.0_281-amd64/bin/jps
[root@master sbin]# ls -l /usr/java/jdk1.8.0_281-amd64/bin/jps
-rwxr-xr-x. 1 root root 8832 Dec 9 2020 /usr/java/jdk1.8.0_281-amd64/bin/jps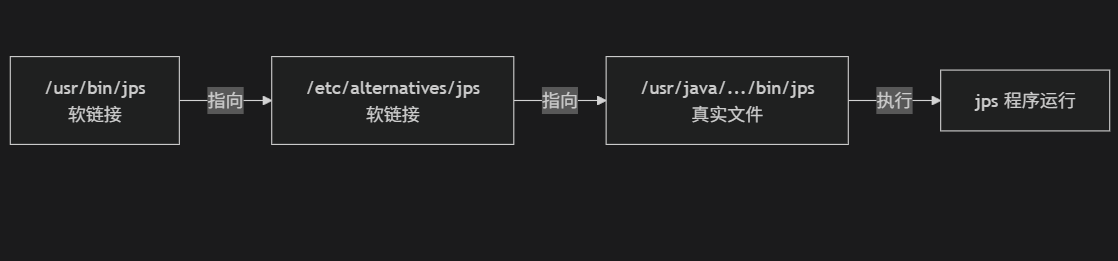
第一层:系统命令入口
bash
/usr/bin/jps -> /etc/alternatives/jps- 类型:软链接(l开头)
- 作用:让你在任何目录都能输入jps命令(系统会在PATH环境变量中找jps命令,而/usr/bin/jps在PATH中)
- 指向:/etc/alternatives/jps
第二层:alternatives管理链接
bash
/etc/alternatives/jps -> /usr/java/jdk1.8.0_281-amd64/bin/jps- 类型:软链接(l开头),就是说/etc/alternatives/jps这个文件是软链接,因为权限符前面的字母是l,l是link的缩写,表示软链接文件
- 作用:实现多版本JDK的切换管理
- 指向:具体的JDK版本中的jps
第三层:真实文件
bash
-rwxr-xr-x. 1 root root 8832 Dec 9 2020 /usr/java/jdk1.8.0_281-amd64/bin/jps- 类型:真实文件(第一个字符是-,不是l)
- 权限:rwxr-xr-x,即755,所有用户可读可执行
- 大小:8832字节(约8.6KB) 注:1字节=8比特,1KB=1024字节
- 本质:这是JDK自带的真正的jps程序
这种设计的优点:
1.灵活切换JDK版本
bash
# 假设你想切换到 JDK 11
# 只需修改一个软链接:
ln -sf /usr/java/jdk11/bin/jps /etc/alternatives/jps
# 所有使用 jps 的地方自动切换,无需修改系统配置2.统一路径命令
-
不管安装几个 JDK 版本
-
/usr/bin/jps永远指向"当前激活的版本" -
用户无需关心具体版本路径
3.符合Linux标准
-
FHS(文件系统层次结构标准)推荐这种设计
-
许多软件(Java、Python、Node.js)都采用类似方案
4.查看环境变量
bash
[root@master sbin]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/hadoop-3.1.4/bin:/opt/hadoop-3.1.4/sbin:/root/bin| 符号 | 名称 | 作用 |
|---|---|---|
PATH |
变量名 | 存储一系列目录路径 |
$ |
取值运算符 | 获取变量的值 |
输出结果解读:
bash
/usr/local/sbin
/usr/local/bin
/usr/sbin
/usr/bin
/opt/hadoop-3.1.4/bin # ✅ Hadoop 普通命令
/opt/hadoop-3.1.4/sbin # ✅ Hadoop 管理命令
/root/bin用 : 分隔的 7 个路径,系统会按顺序在这些目录中查找你输入的命令。
这表明其实PATH已配置Hadoop
验证:
bash
[root@master sbin]# which start-dfs.sh
/opt/hadoop-3.1.4/sbin/start-dfs.sh
[root@master sbin]# hadoop version
Hadoop 3.1.4
Source code repository https://github.com/apache/hadoop.git -r 1e877761e8dadd71effef30e592368f7fe66a61b
Compiled by gabota on 2020-07-21T08:05Z
Compiled with protoc 2.5.0
From source with checksum 38405c63945c88fdf7a6fe391494799b
This command was run using /opt/hadoop-3.1.4/share/hadoop/common/hadoop-common-3.1.4.jar
[root@master sbin]# hdfs dfs -ls / # 查看HDFS命令
Found 1 items
drwxrwx--- - root supergroup 0 2026-04-18 02:27 /tmp5.关闭防火墙的作用
防火墙(Firewall)是一种网络安全系统,主要的作用如下:
- 访问控制:根据预设规则,允许或拒绝网络流量进出计算机或网络;充当"门卫"的角色,决定哪些数据包可以通过。
- 网络隔离:将内部网络(如家庭/公司局域网)与外部网络(如互联网)分隔开;创建安全边界,防止外部威胁直接触及内部资源。
- 威胁防护:防止未授权访问(如阻挡黑客、恶意软件防止它们试图入侵你的设备);过滤恶意流量(识别并拦截可疑的数据传输);防止端口扫描(防止攻击者探测系统漏洞)
- 注:防火墙不能代替杀毒软件,它主要管"门"(网络通道),不管"屋里"(已经进入系统的恶意程序),所以最佳实践是防火墙+杀毒软件+安全意识的配合使用。
核心原因:Hadoop是分布式系统,依赖节点之间的直接通信
简单类比:
想象一下你在一个大办公室工作:
NameNode = 前台接待员:知道每个人的座位在哪(在Hadoop中知道各个节点的信息,但不传递文件)
DataNode = 普通员工:实际干活的(在Hadoop中负责实际存储和处理文件)
客户端(master节点) = 需要文件的人
工作流程:当你问前台"我要存一份文件",前台告诉你"去找员工A和员工B"(返回DataNode地址),你自己直接走到员工A和员工B的座位,把文件交给他们(客户端直连DataNode)
防火墙的作用:如果员工A和员工B的座位需要门禁卡(防火墙规则),而你没有,那么你就进不去(NoRouteToHostException),自然也就无法存文件。
6.HDFS的通信模式
HDFS(Hadoop Distributed File System)的通信模式主要涉及其客户端-服务器架构和内部节点间通信。核心包括以下几个层面:
1.NameNode <------> DataNode通信
心跳机制:DataNode每三秒向NameNode发送心跳包,表明自身存活状态
块报告:DataNode定期(默认6小时)向NameNode上报其存储的所有数据块列表
命令响应:NameNode通过心跳回复向DataNode发送指令(如复制、删除、恢复块等)
2.Client <------------> NameNode通信
元数据操作:客户端通过RPC(Remote Procedure Call)与NameNode交互。如:获取文件系统命名空间操作(创建、删除、重命名文件/目录)、获取数据块位置信息(getBlockLocations)、不涉及实际数据传输,仅传输元数据
3.Client <-----------> DataNode通信
数据读写:客户端直接与DataNode建立TCP连接进行数据传输。读取流程:客户端从NameNode获取块位置后,选择最近的DataNode直接读取。 写入流程:客户端将数据流式传输给第一个DataNode,该DataNode再级联转发给副本DataNode(Pipeline流水线模式)
7.如何关闭防火墙
1.查看防火墙的当前状态
bash
systemctl status firewalld # 查看防火墙的当前状态- system:系统。表示整个操作系统
- ctl:control控制的缩写。systemctl=控制系统
- status:状态
- firewall:防火墙,d:deamon(守护进程的缩写,表示一直在后台运行的程序)
- firewalld:防火墙后台服务
bash
[root@master ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2026-04-23 22:51:25 CST; 1h 58min ago
Docs: man:firewalld(1)
Main PID: 686 (firewalld)
CGroup: /system.slice/firewalld.service
└─686 /usr/bin/python2 -Es /usr/sbin/firewalld --nofork --nopid
Apr 23 22:51:24 master systemd[1]: Starting firewalld - dynamic firewall daemon...
Apr 23 22:51:25 master systemd[1]: Started firewalld - dynamic firewall daemon.关键信息:
-
Active: active (running)→ 防火墙开启中 -
Active: inactive (dead)→ 防火墙已关闭
2.关闭防火墙(临时)
bash
# 立即关闭
systemctl stop firewalld
# 验证是否关闭
systemctl status firewalld
# 显示 Active: inactive (dead)
bash
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Fri 2026-04-24 00:52:45 CST; 22s ago
Docs: man:firewalld(1)
Process: 686 ExecStart=/usr/sbin/firewalld --nofork --nopid $FIREWALLD_ARGS (code=exited, status=0/SUCCESS)
Main PID: 686 (code=exited, status=0/SUCCESS)
Apr 23 22:51:24 master systemd[1]: Starting firewalld - dynamic firewall daemon...
Apr 23 22:51:25 master systemd[1]: Started firewalld - dynamic firewall daemon.
Apr 24 00:52:45 master systemd[1]: Stopping firewalld - dynamic firewall daemon...
Apr 24 00:52:45 master systemd[1]: Stopped firewalld - dynamic firewall daemon.3.开启防火墙(临时)
bash
# 立即开启
systemctl start firewalld
# 验证是否开启
systemctl status firewalld
# 显示 Active: active (running)4.永久关闭防火墙(开机不自启)
bash
# 停止防火墙 + 禁用开机启动
systemctl stop firewalld
systemctl disable firewalld
# 验证
systemctl status firewalld # 显示 inactive
systemctl is-enabled firewalld # 显示 disabled5.永久开启防火墙(开启自启)
bash
# 开启防火墙 + 设置开机启动
systemctl start firewalld
systemctl enable firewalld
# 验证
systemctl status firewalld # 显示 active
systemctl is-enabled firewalld # 显示 enabled2.启动后的基础操作
bash
[root@master current]# systemctl stop firewalld
bash
[root@slave1 current]# systemctl stop firewalld
bash
[root@slave2 current]# systemctl stop firewalld
bash
[root@master current]# echo "Hello HDFS" > ~/test.txt # 创建一个测试文件
[root@master current]# ls ~
anaconda-ks.cfg hadoop-3.1.4.tar.gz test.txt 文件.txt
[root@master current]# cat ~/test.txt
Hello HDFS
bash
[root@master current]# timeout 2 bash -c "echo > /dev/tcp/192.168.128.131/9866" && echo "端口9866可达" || echo "端口9866不可达"
端口9866可达
[root@master current]# hdfs dfs -ls /
Found 1 items
drwxrwx--- - root supergroup 0 2026-04-18 02:27 /tmp
[root@master current]# hdfs dfs -put ~/test.txt /test.txt # 上传到HDFS
[root@master current]# hdfs dfs -ls /
Found 2 items
-rw-r--r-- 2 root supergroup 11 2026-04-23 09:38 /test.txt
drwxrwx--- - root supergroup 0 2026-04-18 02:27 /tmp3.关闭Hadoop集群
推荐的关闭顺序:
注:这是在/opt/hadoop-3.1.4/sbin目录下的操作命令
bash
# 1. 先关闭 YARN(资源管理器)
./stop-yarn.sh
# 2. 再关闭 HDFS(存储系统)
./stop-dfs.sh
# 3. 最后关闭历史服务器(可选)
./mr-jobhistory-daemon.sh stop historyserver| 关闭顺序 | 结果 | 说明 |
|---|---|---|
| 先关 YARN,后关 HDFS | ✅ 正常 | YARN 上的任务先结束,然后 HDFS 安全关闭 |
| 先关 HDFS,后关 YARN | ⚠️ 可能有问题 | HDFS 关闭时,YARN 上的任务还在读写数据,会报错 |
具体原因:
-
YARN 依赖 HDFS
-
YARN 上的 MapReduce 任务需要从 HDFS 读取数据
-
任务执行结果也要写入 HDFS
-
如果先关 HDFS,YARN 任务会立即报错:
java.io.IOException: No FileSystem for scheme: hdfs
-
-
优雅关闭 vs 强制中断
-
先关 YARN:YARN 会等待当前任务完成,或优雅地终止它们
-
先关 HDFS:正在读写数据的任务会突然断开连接,可能造成数据不一致
-
检查是否关闭成功:
关闭后,用 jps 验证所有节点上都没有 Hadoop 进程了:
如:
bash
[root@master sbin]# cd ..
[root@master hadoop-3.1.4]# cd /
[root@master /]# stop-yarn.sh
Stopping nodemanagers
Last login: Wed Apr 22 23:56:04 CST 2026 on pts/0
Stopping resourcemanager
Last login: Thu Apr 23 01:14:42 CST 2026 on pts/0
[root@master /]# stop-dfs.sh
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Stopping namenodes on [master]
Last login: Thu Apr 23 01:14:43 CST 2026 on pts/0
Stopping datanodes
Last login: Thu Apr 23 01:15:01 CST 2026 on pts/0
Stopping secondary namenodes [master]
Last login: Thu Apr 23 01:15:02 CST 2026 on pts/0
[root@master /]# mr-jobhistory-daemon.sh stop historyserver
WARNING: Use of this script to stop the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon stop" instead.
[root@master /]# jps
8092 Jps