场景
SpringBoot+LangChain4j+Ollama实现本地大模型语言LLM的搭建、集成和示例流程:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/160340066
在上面的基础上,学习RAG的使用。
一、为什么需要RAG?------ 大模型的局限性
大型语言模型(LLM)虽然强大,但存在两个核心痛点:
1、知识陈旧:
模型训练完成后知识就被"冻结",无法知道训练之后发生的新事件。
2、"幻觉"问题:
当模型不确定答案时,会"编造"看似合理但错误的信息,尤其在专业领域或企业私有数据上。
RAG(Retrieval-Augmented Generation,检索增强生成) 正是解决这些问题的核心技术。
它让模型在回答前,先从你的知识库(文档、数据库、网页)中检索相关信息,然后基于这些事实生成答案。
打个比方:
传统 LLM 像一个闭卷考试的考生,只能靠记忆;RAG 则给了他一套开卷的参考书,可以随时查阅。
二、RAG 核心流程(三步走)
RAG 分为两个阶段:
索引阶段(Indexing) 和 检索生成阶段(Retrieval & Generation)。
2.1 索引阶段(文档入库)
这一步将你的文档"加工"成可检索的格式,存入向量数据库。
原始文档 → 加载 → 解析 → 分块 → 向量化 → 存储
加载(Load):读取各种格式的文件(PDF、Word、TXT、网页等)。
解析(Parse):提取纯文本,去除格式、图片等无关信息。
分块(Split):将长文档切分成适合模型处理的短片段(chunk)。原因:模型上下文窗口有限,且细粒度检索更精准。
向量化(Embed):用嵌入模型(Embedding Model)将每个文本片段转换成高维向量(例如 768 维浮点数数组)。向量可以捕获语义信息。
存储(Store):将向量和原始文本存入向量数据库,便于后续相似度检索。
2.2 检索生成阶段(问答)
用户提问时,执行以下步骤:
用户问题 → 向量化 → 相似度检索 → 增强上下文 → 生成答案
查询向量化:用同一个嵌入模型将用户问题也转换成向量。
相似度检索:在向量数据库中寻找与问题向量最相似的 K 个文本片段(例如余弦相似度)。
增强上下文:将检索到的片段与原始问题组合成一个"增强提示"(Augmented Prompt)。
生成答案:把增强提示发给 LLM,让它基于提供的材料生成准确答案。
三、LangChain4j 中 RAG 的核心组件
Document 代表一个原始文档(包含文本、元数据)
DocumentParser 解析特定格式(PDF、DOCX等)
DocumentSplitter 将长文档切分成 TextSegment
TextSegment 一个文本片段(chunk)
EmbeddingModel 将文本转换为向量
EmbeddingStore 向量数据库的抽象接口
EmbeddingStoreIngestor 自动化管道:分块 → 向量化 → 入库
ContentRetriever 根据问题检索相关片段
RetrievalAugmentor 增强器,将检索结果注入到 AI 请求中
AiServices 构建 AI 服务,支持 RAG
注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
实现
四、代码详解:从零搭建一个 RAG 问答系统
前置:
拉取嵌入模型(用于向量化):
ollama pull nomic-embed-text4.1 添加依赖(pom.xml 关键部分)
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.5</version>
</parent>
<groupId>com.example</groupId>
<artifactId>spring-langchain4j-ollama-rag</artifactId>
<version>1.0</version>
<properties>
<java.version>17</java.version>
<langchain4j.version>1.0.0-beta4</langchain4j.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 核心:用于启用 @AiService 声明式 AI 服务 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
</dependency>
<!-- 具体模型:用于集成本地 Ollama 服务 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama-spring-boot-starter</artifactId>
</dependency>
<!-- 文档加载:支持 PDF、TXT、DOCX 等 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>${langchain4j.version}</version>
</dependency>
</dependencies>为什么不需要 langchain4j-embeddings-bge-small-en-v15?
我们改用 Ollama 的嵌入模型,避免了本地 DLL 加载问题,且与现有 Ollama 服务共享基础设施。
4.2 配置文件 application.yml
langchain4j:
ollama:
chat-model:
base-url: http://localhost:11434
model-name: qwen2:7b
temperature: 0.7
timeout: PT600S # 10 分钟
connect-timeout: PT300S # 5 分钟
read-timeout: PT300S # 5 分钟
log-requests: true
log-responses: true
embedding-model:
base-url: http://localhost:11434
model-name: nomic-embed-text
chat-model:用于最终生成答案的 LLM。
embedding-model:用于将文档片段和用户问题转换为向量。两者可以不同,且通常嵌入模型更轻量
4.3 文档索引服务:将文档入库
package com.badao.ai.service;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import jakarta.annotation.PostConstruct;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.ClassPathResource;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.nio.file.Path;
import java.util.List;
@Service
public class DocumentIndexingService {
@Autowired
private EmbeddingModel embeddingModel;
@Autowired
private EmbeddingStore<TextSegment> embeddingStore; // 注入 Spring 管理的 Bean
@PostConstruct
public void init() throws IOException {
ClassPathResource resource = new ClassPathResource("knowledge/knowledge.txt");
Path docPath = resource.getFile().toPath();
Document document = FileSystemDocumentLoader.loadDocument(docPath);
List<Document> documents = List.of(document);
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore) // 使用注入的存储
.build();
ingestor.ingest(documents);
System.out.println("文档已成功索引,共处理了 " + documents.size() + " 个文档。");
}
}解释:
TextSegment.from(document, 500, 50):将文档按 500 个字符切块,相邻块重叠 50 个字符(避免丢失边界信息)。
EmbeddingStoreIngestor:封装了"分块 → 向量化 → 存储"的完整流程。你也可以自定义分块策略。
@PostConstruct:Spring 容器启动后自动执行索引,确保知识库就绪
4.4构建带 RAG 能力的 AI 服务
package com.badao.ai.config;
import com.badao.ai.service.RAGAssistant;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.rag.DefaultRetrievalAugmentor;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.store.embedding.EmbeddingStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RagAiConfig {
@Bean
public RAGAssistant ragAssistant(ChatModel chatModel,
EmbeddingStore<TextSegment> embeddingStore,
EmbeddingModel embeddingModel) {
// 1. 创建内容检索器:从向量存储中检索相关片段
var contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3) // 最多返回 3 个相关片段
.minScore(0.7) // 最低相似度分数
.build();
// 2. 创建检索增强器
var retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.contentRetriever(contentRetriever)
.build();
// 3. 构建 AI 服务
return AiServices.builder(RAGAssistant.class)
.chatModel(chatModel)
.retrievalAugmentor(retrievalAugmentor)
.build();
}
}关键组件:
EmbeddingStoreContentRetriever:根据用户问题在向量库中检索相似片段。
DefaultRetrievalAugmentor:将检索到的内容自动插入到用户消息之前,构造增强提示。
AiServices.retrievalAugmentor():将增强器绑定到 AI 服务。
4.5 Assistant 接口定义
package com.badao.ai.service;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
public interface RAGAssistant {
@SystemMessage("你是一个知识库助手,请基于提供的上下文信息回答问题。如果无法从上下文中找到答案,请如实告知。")
String chat(@UserMessage String userMessage);
}4.6 Controller 暴露接口
package com.badao.ai.controller;
import com.badao.ai.service.RAGAssistant;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/rag")
public class RAGController {
private final RAGAssistant ragAssistant;
public RAGController(RAGAssistant ragAssistant) {
this.ragAssistant = ragAssistant;
}
@GetMapping("/ask")
public String ask(@RequestParam String question) {
return ragAssistant.chat(question);
}
}4.7 测试验证
准备一个测试文档 knowledge.txt,放在src-resource下knowledge下,内容:
公司内部规定:员工每天工作时间为 9:00 - 18:00,午休一小时。
年假规则:入职满一年后享有 5 天年假,满三年后享有 10 天年假。
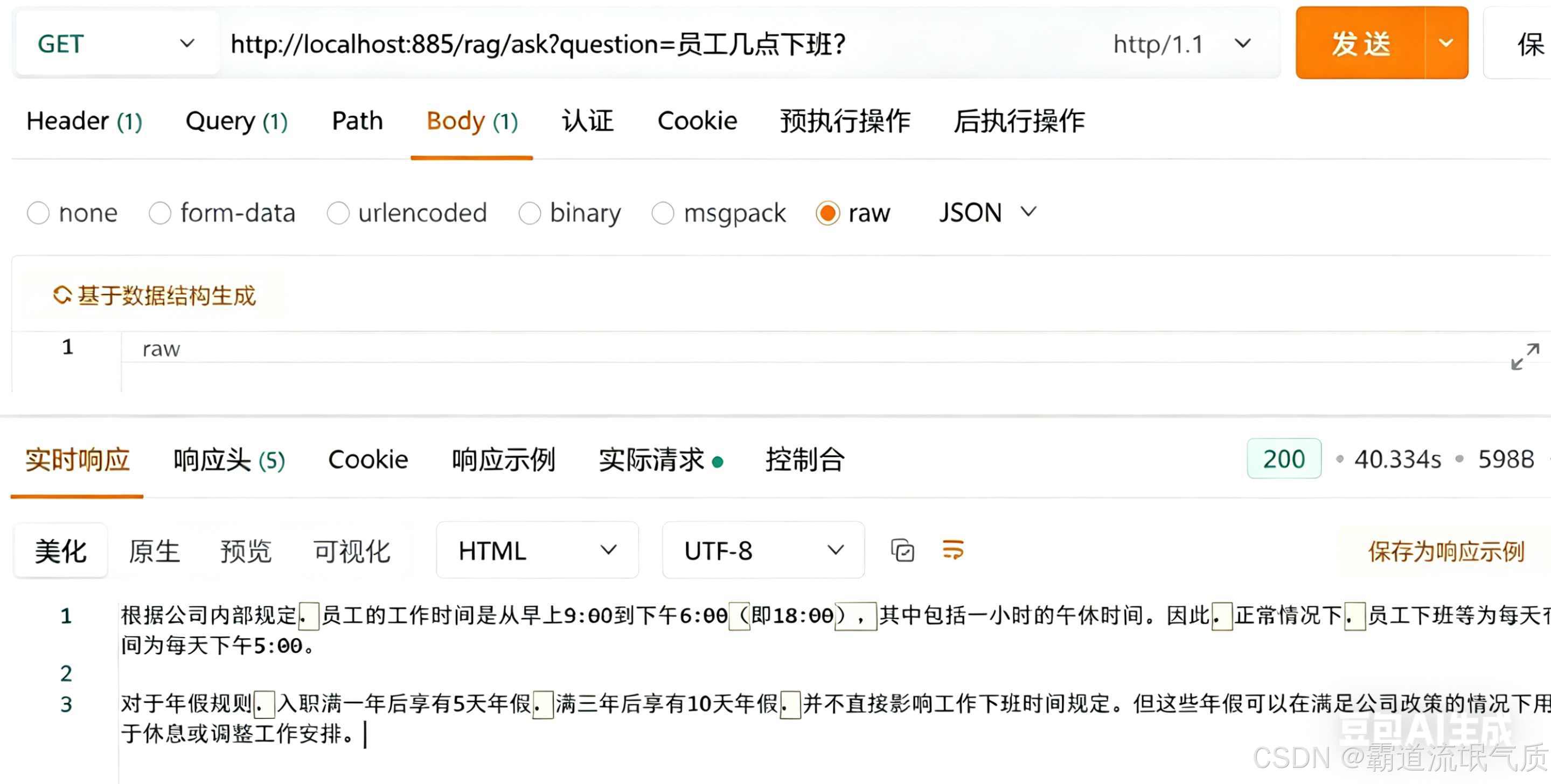
启动应用,访问测试接口
http://localhost:885/rag/ask?question= 员工几点下班?
常见问题与解决方案
1、本地嵌入模型加载失败(AccessDeniedException)
DJL 库在 Windows 上解压 DLL 失败 改用 Ollama 的嵌入模型(如 nomic-embed-text)
2、检索结果不相关 分块太大/太小,或嵌入模型不适合领域 调整分块大小;
尝试其他嵌入模型(bge-m3、all-MiniLM-L6-v2)
3、模型不遵循检索内容 系统提示词未强调"基于资料"
在 @SystemMessage 中加入明确指令
4、响应慢 向量检索或 LLM 推理慢
使用更快的嵌入模型(如 nomic-embed-text)、开启 GPU、缓存常见检索结果
5、重启后数据丢失
使用内存存储 改用持久化向量数据库(Redis、Chroma)