一、分析1
一、模型设计目标
| 模型 | 设计目标 |
|---|---|
| CLIP | 图像与文本之间的对比学习,学习一个共享的嵌入空间,用于零样本分类、检索等任务。 |
| Qwen-VL | 多模态语言建模,基于解码器架构(如 Qwen3 LM Dense/MoE Decoder),支持图像、视频、文本的联合理解与生成。 |
二、架构组件对比
| 组件 | CLIP | Qwen-VL |
|---|---|---|
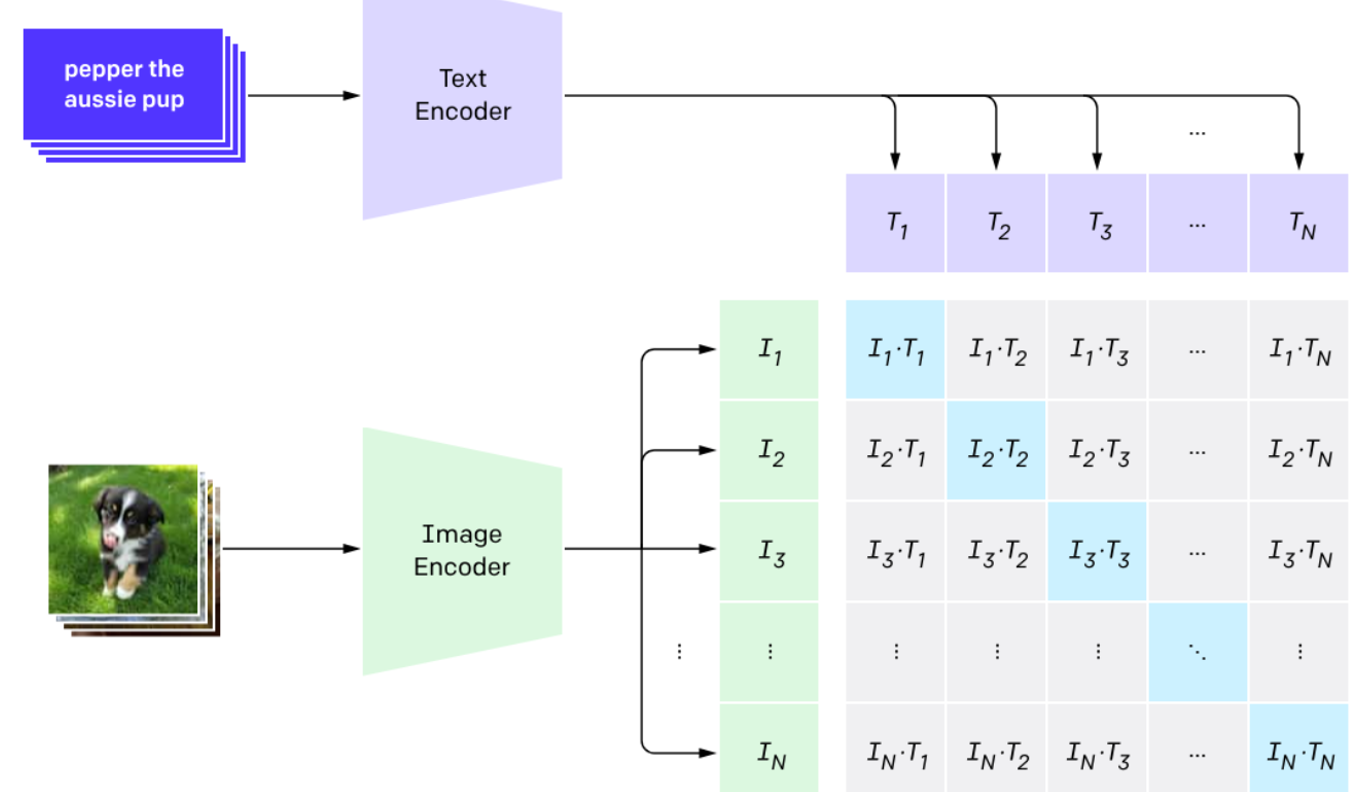
| 视觉编码器 | Image Encoder(如 ViT 或 CNN) | Vision Encoder(输出视觉 token) |
| 文本编码器 | Text Encoder(如 Transformer) | 文本作为输入的一部分,与视觉 token 一起送入 LM Decoder |
| 交互方式 | 双塔独立编码,最后通过点积计算相似度 | 视觉 token 与文本 token 拼接,统一输入到语言模型解码器 |
| 输出 | 图像与文本的相似度矩阵 | 文本生成(如描述、问答、对话等) |
三、训练目标
| 模型 | 训练目标 |
|---|---|
| CLIP | 对比学习:最大化匹配的(图像,文本)对之间的相似度,最小化不匹配对的相似度。使用交叉熵损失。 |
| Qwen-VL | 自回归语言建模:基于图像和文本前缀,预测下一个文本 token。 |
四、推理方式
| 模型 | 推理方式 |
|---|---|
| CLIP | 给定图像,计算其与所有类别文本的相似度,选择最相似的作为预测结果(零样本分类)。 |
| Qwen-VL | 给定图像和文本提示(如"描述这张图片"),生成对应的文本回答。 |
五、总结对比表
| 特性 | CLIP | Qwen-VL |
|---|---|---|
| 架构类型 | 双塔编码器 | 单塔解码器(LM) |
| 模态交互 | 仅在输出层(点积) | 在每一层(注意力机制) |
| 训练任务 | 对比学习 | 语言建模 |
| 是否生成文本 | 否 | 是 |
| 适用任务 | 检索、分类、匹配 | 对话、描述、VQA、推理 |
二、分析2
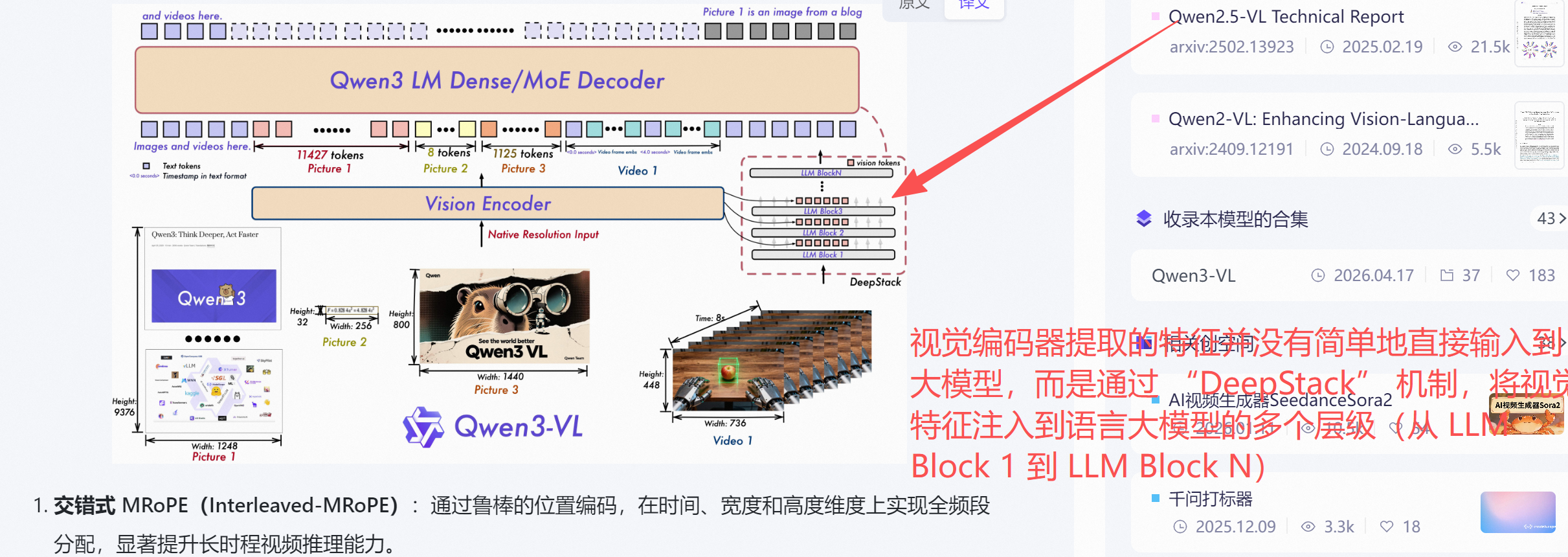
一、VL 模型的标准架构(以 Qwen-VL 为例)
一个典型的视觉语言模型由三部分构成:
1. 视觉编码器(Vision Encoder)
-
作用:将原始图像(或视频帧)转换为视觉特征序列(visual tokens)。
-
常用结构:ViT(Vision Transformer)、EVA、CLIP 的视觉编码器等。
-
输出:
[num_patches, hidden_dim]或经过池化后的[num_visual_tokens, d_model]。
2. 连接器(Connector / Adapter)
-
作用:将视觉编码器的输出对齐到大语言模型的输入空间(维度、序列长度、语义分布)。
-
常见实现:
-
线性投影:最简单的单层全连接。
-
MLP(2~3 层非线性映射)。
-
DeepStack(你提到的):多层特征融合,可保留更细粒度的视觉信息。
-
Q-Former(BLIP-2 风格):可学习的查询 token 压缩视觉特征。
-
-
输出:与文本 token 同一维度的视觉 token 序列(例如 256 个 token,每个 4096 维)。
3. 大语言模型底座(LLM Backbone)
-
作用:接受视觉 token + 文本 token 的混合序列,进行自回归生成。
-
常用模型:Qwen(稠密或 MoE)、LLaMA、ChatGLM 等。
-
关键点:LLM 的参数在训练中部分或全部更新,学会理解视觉 token 的含义并生成相关文本。
二、视觉 token 与文本 token 的拼接方式
你说的"文本作为输入的一部分,与视觉 token 一起送入 LM Decoder,视觉 token 与文本 token 拼接,统一输入到语言模型解码器"完全正确。具体过程如下:
-
图像 → 视觉编码器 → 连接器 → 得到
[v1, v2, ..., vm](m 个视觉 token) -
文本 (例如"请描述这张图片") → 分词器 → 得到
[t1, t2, ..., tn](n 个文本 token)v1, v2, ..., vm, t1, t2, ..., tn -
也可以把视觉 token 放在文本后面,或者交错放置(较少见)。
-
这个混合序列直接输入到 LLM 的解码器(自注意力机制会自然捕捉视觉 token 与文本 token 之间的交互)。
-
LLM 基于前缀(视觉 + 文本 prompt)生成后续文本。
注意:LLM 的注意力掩码通常允许所有 token 相互可见(双向注意力只在视觉 token 内部或文本内部?实际常用因果掩码,但视觉 token 之间可以双向,文本部分保持因果)。实现细节因模型而异。
三、为什么纯文本 LLM 在通用对话上效果更好?
你观察到的"Qwen LLM 纯文本模式下效果更好"和"VL 的通用对话能力不如纯文本大模型"是符合实践的,主要原因有:
1. 训练数据与目标不同
-
纯文本 LLM:海量高质量文本(书籍、网页、对话、代码),专注于语言理解与生成。
-
VL 模型:需要图文配对数据(例如 1~5 亿对),这类数据往往噪声大、描述简单,无法像纯文本那样学习复杂的推理、常识和丰富表达。
2. 视觉 token 压缩损失
-
图像被压缩成少量 token(例如 256 个),会丢失大量细节(纹理、小物体、文字等)。
-
当模型需要仅依赖文本回答问题时(比如对话中没有图片),这些视觉 token 实际上变成了无意义的干扰,模型不得不学会忽略它们,但这会浪费一部分容量。
3. 参数分配与训练难度
-
VL 模型需要在 LLM 内部同时学习语言能力和跨模态对齐,而纯文本 LLM 将所有参数都用于语言建模,更专注。
-
多模态训练容易出现模态不平衡(模型偏向文本,忽视图像),导致图像理解不深,同时也损害了纯文本能力。
4. 评测偏差
-
通用对话基准(如 MT-Bench、AlpacaEval)主要考察语言能力(推理、写作、知识),不包含图像理解任务。
-
在这些任务上,VL 模型因为上述原因自然表现不如同规模纯文本 LLM。
四、VL 模型的核心价值在哪里?
尽管纯文本对话能力稍弱,VL 模型在以下任务上远远优于纯文本 LLM:
-
图像描述 / 视频摘要
-
视觉问答(VQA)
-
图文检索(给定图片找文字,或反过来)
-
文档图表理解(OCR + 布局 + 推理)
-
多模态对话(用户上传图片,模型基于图片回答问题)
如果你需要处理不含图像的对话任务,直接用纯文本 Qwen LLM 更合适;如果你的应用涉及图像/视频理解,VL 是必不可少的。
五、总结表
| 特性 | 纯文本 LLM | VL 模型(如 Qwen-VL) |
|---|---|---|
| 架构 | 仅 LM Decoder | Vision Encoder + Connector + LM Decoder |
| 输入 | 文本 token | 视觉 token + 文本 token(拼接) |
| 训练数据 | 纯文本 | 图文对 + 纯文本(混合) |
| 优势 | 通用对话、推理、写作 | 图像/视频理解、多模态问答 |
| 劣势 | 无法理解图像 | 纯文本对话能力略低于同规模 LLM |
三、分析3
Qwen-VL与CLIP是两种截然不同的多模态架构:CLIP是用于对齐图文特征的双塔模型 ,而Qwen-VL是基于大语言模型的生成式对话模型。
| 对比维度 | CLIP (Contrastive Language-Image Pre-training) | Qwen-VL |
|---|---|---|
| 架构设计 | 双塔模型 (Dual-Encoder):独立的图像编码器 (ViT) 和文本编码器 (Transformer)-。 | 大语言模型架构 (LLM-based):视觉编码器 + 位置感知适配器 (VL Adapter) + 大语言模型 (Qwen-7B)-。 |
| 核心任务 | 图文匹配/检索:将图像和文本映射到同一嵌入空间,通过计算相似度进行匹配-。 | 生成式理解:以图像和文本提示作为输入,自回归地生成文本回答(如描述、对话、问答)。 |
| 训练范式 | 对比学习:通过拉近匹配图文对、推远非匹配对来学习,最小化交叉熵损失-。 | 多阶段预训练 + 指令微调:1. 图文预训练;2. 多任务预训练;3. 指令微调,以最大化文本token的交叉熵为目标-。 |
| 处理方式 | 图像需缩放到固定分辨率(如224x224)。 | 第一、二阶段为固定分辨率(224x224 / 448x448),后续版本(如Qwen2-VL)支持原生动态分辨率-。 |
| 主要优势 | 检索与零样本分类:跨模态检索、高效匹配、零样本图像分类。 | 对话与复杂推理:视觉对话、图像描述、视觉问答 (VQA)、文字识别、定位等综合性任务。 |
核心架构与能力对比
Qwen-VL 的架构创新
-
强基座 (Strong LLM Backbone) :以强大的 Qwen-7B 大语言模型为基座,提供复杂的语言理解和生成能力-。
-
视觉编码器 (Vision Encoder) :使用 ViT-bigG 架构,并用 OpenCLIP 的预训练权重初始化,确保强大的视觉特征提取能力。
-
VL Adapter :一个关键组件,通过单层交叉注意力机制将视觉特征序列压缩为固定长度(如256个token),解决了长序列带来的效率问题,实现了视觉与语言模型的高效连接。
-
多模态输入输出 :支持任意交错的图像-文本数据 作为输入,并能理解和生成用于定位的边界框 (Bounding Box),实现了从理解到定位的跨越。
CLIP 的架构特点
-
双塔独立性 :图像和文本编码器完全独立,最后通过计算嵌入向量的余弦相似度来判断图文是否匹配。
-
训练高效性 :训练目标简单直接,能利用海量图文对进行高效学习,因此零样本迁移能力极强。
-
缺乏生成能力:核心功能是检索和匹配,不具备根据图像生成描述性文本的能力。
训练策略:从对齐到生成
CLIP和Qwen-VL的训练目标和流程截然不同。
Qwen-VL的三阶段训练法
-
阶段一:图文预训练 (图文对齐)
-
数据 :使用约 14亿 清洗后的图文对,其中英文占77.3%,中文占22.7%-。
-
策略:冻结大语言模型,只训练视觉编码器和VL Adapter。目标是让模型初步理解图像和文字的对应关系。
-
-
阶段二:多任务预训练 (能力拓展)
-
数据 :引入分辨率更高(448x448)、质量更精细的数据,涵盖图像描述、视觉问答、文字识别、目标定位等7项任务。
-
策略:解冻全部参数,让模型在多个视觉语言任务上学习,极大拓宽了模型的能力边界。
-
-
阶段三:指令微调 (对齐与交互)
- 目标 :将预训练模型微调成交互式的 Qwen-VL-Chat 聊天机器人,使其能更好地遵循人类指令,进行多轮对话。
CLIP的单阶段训练
-
数据:使用了约4亿个从互联网收集的图文对。
-
策略:采用对比学习,模型需要从海量噪声数据中自动学习图文对应关系。
Qwen-VL 的核心优势
-
强大的视觉语言能力:在图像描述、视觉问答、文字识别和基于视觉的对话等任务上表现出色。
-
领先的基准性能:在多个视觉中心的理解基准上达到当时最先进的性能。
-
多语言支持 :原生支持英文和中文,这使其在处理中文场景和多语言指令时具有天然优势。
-
细粒度理解:通过高分辨率输入和高质量的训练数据,能更好地理解图像细节和进行文字阅读。
演进与后续发展
-
技术演进 :Qwen系列已演进至 Qwen3-VL 和 Qwen2.5-VL 。例如,Qwen2-VL引入了原生动态分辨率,能直接处理任意分辨率的图像,更接近人类的视觉感知-。Qwen2.5-VL在抽象概念理解上相比Qwen-VL有显著提升-。
-
性能表现 :后续的 Qwen3-VL 和 Qwen2.5-VL 模型在空间推理等复杂任务上表现出色,曾在 SpatialBench 榜单上领先于 Gemini 和 GPT 等模型-。
总结
简单来说,CLIP是一个优秀的"图文匹配器" ,为图像和文字建立了共同的"比较标准";而 Qwen-VL是一个强大的"视觉对话引擎",它不仅能"看懂"图像,还能像人一样围绕图像内容进行复杂的对话、解释和推理。