单层神经网络
神经网络是深度学习的算法架构基础,其灵感来源于生物大脑的神经元结构。在算法中,我们将数据输入视为"电子信号"(特征 xxx),通过权重(www)和偏置(bbb)的线性计算处理后,再通过激活函数(Activation Function)输出最终结果。
从特征矩阵到输出结果的过程叫作正向传播
一. 单层回归网络:线性回归
1. 理论基础
最简单的神经网络就是单层回归神经网络(即线性回归)。它没有任何隐藏层,直接将输入特征通过加权求和得出连续的输出值。
单层神经网络:一个输入层+一个输出层(我们不算输入层,所以是一层)
数学公式:
z^i=b+w1xi1+w2xi2+⋯+wnxin\hat{z}i = b + w_1x{i1} + w_2x_{i2} + \dots + w_nx_{in}z^i=b+w1xi1+w2xi2+⋯+wnxin
矩阵表示:
z^=Xw\boldsymbol{\hat{z}} = \boldsymbol{Xw}z^=Xw
- z^\boldsymbol{\hat{z}}z^(预测结果列向量) :包含了所有 mmm 个样本预测结果的列向量,形状为 (m,1)(m, 1)(m,1)。
- bbb(偏置项/截距) :在数学公式中是常数。在矩阵表示 Xw\boldsymbol{Xw}Xw 中,它被作为第一个元素塞进了权重向量 w\boldsymbol{w}w 的最顶部或底部。
- w\boldsymbol{w}w(权重列向量) :由于吸收了 bbb,其长度从 nnn 膨胀为 n+1n+1n+1。它包含了截距和所有的特征权重,形状为 (n+1,1)(n+1, 1)(n+1,1)。
- X\boldsymbol{X}X(增广特征矩阵) :为了能和包含了 bbb 的权重向量顺利相乘,特征矩阵的最左侧或最右侧被人为追加了一列全为 111 的占位符。其形状从 (m,n)(m, n)(m,n) 膨胀为了 (m,n+1)(m, n+1)(m,n+1)。
符号规范:
在我们学习autograd的时候,我们说线性回归的方程是y^i=b+w1xi1+w2xi2+⋯+wnxin\hat{y}i = b + w_1x{i1} + w_2x_{i2} + \dots + w_nx_{in}y^i=b+w1xi1+w2xi2+⋯+wnxin,但在这里,为什么写做zzz呢?
首先,无论是回归问题还是分类问题,y永远表示标签(labels)。在回归问题中,y是连续型数字,在分类问题中,y是离散型的整数。
对于线性回归来说,线性方程的输出结果就是最终的标签。但对于整个深度学习体系而言,复杂神经网络的输出才是最后的标签。在我们单独对线性回归进行说明的时候,行业惯例就是使用zzz来表示线性回归的结果。
注意,我们通常使用粗体的小写字母来表示列向量,粗体的大写字母表示矩阵或者行列式。并且在机器学习中,我们默认所有的一维向量都是列向量。
如果考虑我们有m个样本,则回归结果可以被写作:
z^=b+w1x1+w2x2+⋯+wnxn \boldsymbol{\hat{z}} = b + w_1\boldsymbol{x}_1 + w_2\boldsymbol{x}_2 + \dots + w_n\boldsymbol{x}_n \quad z^=b+w1x1+w2x2+⋯+wnxn其中 z^\boldsymbol{\hat{z}}z^ 是包含了m个全部的样本的预测结果的列向量,带帽子的都是预测结果,不带的是真实结果。
我们可以使用矩阵来表示上面多个样本的回归结果的方程,其中 w\boldsymbol{w}w 可以被看做是一个结构为(n+1,1)的列矩阵(这里的n加上的1是我们的截距b),X\boldsymbol{X}X 是一个结构为(m,n+1)的特征矩阵(这里的n加上的1是为了与截距b相乘而留下的一列1,这列1有时也被称作 x0x_0x0 ),则有:
\\begin{bmatrix} \\hat{z}_1 \\ \\hat{z}_2 \\ \\hat{z}_3 \\ \\dots \\ \\hat{z}_m \\end{bmatrix} \\begin{bmatrix} 1 \& x_{11} \& x_{12} \& x_{13} \& \\dots \& x_{1n} \\ 1 \& x_{21} \& x_{22} \& x_{23} \& \\dots \& x_{2n} \\ 1 \& x_{31} \& x_{32} \& x_{33} \& \\dots \& x_{3n} \\ \\dots \& \\dots \& \\dots \& \\dots \& \\dots \& \\dots \\ 1 \& x_{m1} \& x_{m2} \& x_{m3} \& \\dots \& x_{mn} \\end{bmatrix} \* \\begin{bmatrix} b \\ w_1 \\ w_2 \\ \\dots \\ w_n \\end{bmatrix}
z^=Xw \boldsymbol{\hat{z}} = \boldsymbol{Xw} z^=Xw
如果在我们的方程里没有常量 bbb,我们则可以不写 X\boldsymbol{X}X 中的第一列以及 w\boldsymbol{w}w 中的第一行。
2. 补充方法(1和2不常用,了解就行)
(1).torch.set_printoptions - 全局打印格式设置
作用:
修改 PyTorch 在控制台打印张量时的默认显示行为。当你在调试大型张量,发现中间被省略号 ... 截断,或者浮点数小数点太多看得眼花缭乱时,可以通过这个方法进行全局设置。
python
torch.set_printoptions(precision=None, threshold=None, sci_mode=None, profile=None)参数:
- 浮点精度 (precision): 设置浮点数输出的小数位数(默认是 4,int)。
- 截断阈值 (threshold): 触发省略号
...截断的元素总数阈值(默认是 1000,int)。避坑提醒:如果你想强行打印整个超大张量不被截断,可以将其设为float('inf')(无穷大)。 - 科学计数 (sci_mode): 是否启用科学计数法 (bool)。设为
False可以强制显示完整数字。 - 配置模板 (profile): 快速应用预设格式,可选
'default','short','full'。
返回值:
- 成功: 无返回值 (
None)。这属于对全局环境状态的修改操作。
用完后恢复 PyTorch 的默认设置 (好习惯):torch.set_printoptions(profile="default")
示例:
python
# 创建一个 100x100 的大矩阵
big_tensor = torch.randn(100, 100)
# 1. 默认打印会显示省略号 ...
print("默认打印:\n", big_tensor)
# 默认打印:
# tensor([[-1.3840, -1.2492, 0.6762, ..., 1.5979, -1.7582, -0.2823],
# [ 0.4981, -1.1073, -0.9235, ..., -0.3036, 0.3311, 0.5786],
# [-0.9422, -0.2717, 2.1143, ..., -0.3625, -0.4068, -0.5136],
# ...,
# [ 1.1565, 0.5502, -0.7146, ..., -0.0374, 1.2774, 0.4224],
# [ 0.3920, 1.2613, -1.2283, ..., 0.4899, -0.7182, -0.0208],
# [-1.4335, -0.2543, -0.0262, ..., -1.0005, -0.2518, 0.2897]])
# 2. 强行改变打印规则:保留2位小数,且绝对不截断显示!
torch.set_printoptions(precision=2, threshold=float('inf'))
print("修改规则后打印:\n", big_tensor) # 此时会满屏打印所有 10000 个元素
# 修改规则后打印:
# tensor([[-1.38e+00, -1.25e+00, 6.76e-01, -3.80e-01, -5.23e-01, 1.97e+00,
# 3. 用完后恢复 PyTorch 的默认设置 (好习惯)
torch.set_printoptions(profile="default") (2) torch.allclose - 浮点数极小误差比较 (张量全等判断)
作用:
比较两个张量是否在数值上"近似相等"。==这是深度学习中极其重要的高级排错技巧!==因为计算机底层的浮点数(如 float32)在进行大量矩阵运算后,必然会产生微小的精度丢失。此时用普通的 == 比较几乎一定会返回 False,必须用 allclose 来判断两者的差异是否在允许的极小误差范围内。
python
torch.allclose(input, other, rtol=1e-05, atol=1e-08, equal_nan=False)参数:
- 输入张量 (input): 第一个要比较的目标张量 (Tensor)。
- 对比张量 (other): 第二个要比较的目标张量 (Tensor),形状需与
input一致。 - 相对误差容忍度 (rtol): Relative tolerance,默认
1e-05(float)。 - 绝对误差容忍度 (atol): Absolute tolerance,默认
1e-08(float)。
返回值:
- 成功: 返回一个布尔值标量 (
True或False)。只有当 ∣input−other∣≤atol+rtol×∣other∣|input - other| \le atol + rtol \times |other|∣input−other∣≤atol+rtol×∣other∣ 对所有元素都成立时,才返回True。
示例:
python
a = torch.tensor([0.1, 0.1, 0.1])
# b = 0.1 + 0.1 + 0.1
b = torch.tensor([0.1]) + torch.tensor([0.1]) + torch.tensor([0.1])
# 史诗级避坑:浮点数加法产生的微小精度误差
print("a 的值:", a) # 返回 tensor([0.1000, 0.1000, 0.1000])
print("b 的值:", b) # 返回 tensor([0.3000])
# 1. 错误做法:直接用普通等号比较
# 虽然数学上它们应该相等,但底层二进制表示有极小误差,结果是 False
print("直接用 == 比较:", (a.sum() == b).item()) # 返回 False
# 2. 正确做法:使用 allclose 允许微小容差
print("使用 allclose 比较:", torch.allclose(a.sum(), b)) # 返回 True(3) torch.manual_seed - 人为设置随机数种子
作用:
强制固定 PyTorch 全局的随机数生成器。在深度学习中,模型权重的初始化(如 nn.Linear 自动赋予的权重)、数据集的乱序抽取等都严重依赖于随机数。设置统一的随机种子,可以保证每次运行代码时生成的"随机"结果完全一致。这在排查 Bug、团队对齐算法结果以及发表论文要求模型可复现 (Reproducibility) 时极其重要!
(注:虽然全称是 torch.random.manual_seed(),但在工业界和官方文档中,最规范、最常用的简写是直接调用 torch.manual_seed()),是一个东西的不同别名。
python
torch.manual_seed(seed)参数:
- 随机种子 (seed): 任意一个整数 (int)。业界通常喜欢用特定的数字如
42、0、1234等。数字本身的大小没有特殊的数学意义,只要团队内部保持一致即可。
返回值:
- 成功: 返回一个 PyTorch 的随机数生成器对象 (
torch._C.Generator)。通常我们在代码中不需要接收或处理这个返回值。
示例与核心机制:
python
import torch
import torch.nn as nn
# 1. 核心操作:设置全局随机种子
torch.manual_seed(42)
# 设置种子后,紧跟着的随机操作的结果会被"永久固定"
print("设置种子后第一次生成:", torch.rand(2))
# 无论运行多少次代码,输出永远是: tensor([0.8823, 0.9150])
# 2. 史诗级避坑:种子的"消耗"特性
# 种子只会保证整个程序的"随机操作序列"一致。如果你再调用一次 rand,
# 结果会和上一次不同,但只要重启程序,这"第二次"的结果依然固若金汤。
print("设置种子后第二次生成:", torch.rand(2))
# 永远输出: tensor([0.3829, 0.9593])
# 3. 对 nn.Linear 的巨大影响
torch.manual_seed(42) # 重新设回 42,相当于"时光倒流"到初始状态
layer1 = nn.Linear(3, 1) # 此时底层自动生成的 W 和 b 每次都会一模一样!
print("\n固定种子后初始化的 Linear 权重:\n", layer1.weight)3. nn.Linear类 - 线性层(全连接层)
nn.Linear类是nn.Module类的子类
(1).nn.Linear类类型
作用:
nn.Linear 是 PyTorch 中构建神经网络最基础的模块,通常被称为"全连接层 (Fully Connected Layer)"或"稠密层 (Dense Layer)"。它的核心作用是对输入数据自动执行线性变换。使用这个类,我们不需要再手动给特征矩阵 XXX 拼接全为 1 的占位列,也不用手动创建和初始化权重张量,PyTorch 会在底层自动帮我们创建并管理权重矩阵 (WWW) 和偏置项 (bbb),且默认开启了自动求导 (requires_grad=True)。
python
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)核心参数:
- 输入特征数(in_features):对应单个样本的特征维度 (即前面数学公式里的x的下标 nnn)。比如我们有"花瓣长、花萼长、花瓣宽、花萼宽"4个特征,这里就填 4 (int)。
- 输出特征数(out_features):对应经过线性层后输出的维度。如果是我们前面讲的单目标线性回归,只输出一个预测值 z^\hat{z}z^,这里就填 1。如果是多目标回归或多分类,则填对应的类别数 (int)。
- 是否保留偏置 (bias):决定该层是否学习一个加法偏置项 bbb。默认为
True。如果设为False,则底层只计算 xATxA^TxAT,相当于强制让直线过原点 (bool)。
核心属性 (Attributes):
实例化 nn.Linear 后,可以通过以下属性直接访问底层的参数张量:
.weight:该层的可学习权重,它是一个二维张量 (ndim=2)。形状为(out_features, in_features)。.bias:该层的可学习偏置,它是一个一维张量(ndim=1)。形状为(out_features)。
理论与底层代码的对齐 (极其重要):
我们在理论推导时,为了消除加号,习惯把 bbb 塞进 www 里,算出增广矩阵乘法 z^=Xw\boldsymbol{\hat{z}} = \boldsymbol{Xw}z^=Xw。
但在 PyTorch 底层,为了显存分配的高效性和普适性,官方采用的是权重与偏置分离 的算法,并利用广播机制(Broadcasting)进行加法:
y=xWT+by = xW^T + by=xWT+b
(注:官方文档中的WWW是行向量,所以要转置一下,xxx 即为特征矩阵 XXX。)
补充:
权重矩阵的Shape看起来是反的,如:定义
linear1 = nn.Linear(in_features=20, out_features=13)时,直觉上权重矩阵应该是[20, 13]。但实际打印linear1.weight.shape时,输出的却是torch.Size([13, 20])(即[out_features, in_features])。这是因为:
nn.Linear绝对不会去转置你的输入数据矩阵 XXX(因为 XXX 通常包含着巨大的 Batch Size,转置极其消耗显存),它在底层自动转置的是它自己的"权重矩阵 WWW"。按照公式 y=xWT+by = xW^T + by=xWT+b 推演:
- 输入特征 xxx :你的输入形状是
[500, 20](500 个样本,20 个特征)。- 底层权重 WWW :底层实际存储的形状是
[13, 20]。- 计算时的自动转置 :在执行前向传播时,PyTorch 自动将 WWW 转置为 WTW^TWT,此时参与计算的矩阵形状变成了
[20, 13]。- 矩阵乘法完美闭环 :
[500, 20]×\times×[20, 13]=[500, 13]。完美得出了第一层需要的 13 个神经元输出!工业界设计考量:将权重按照
[out_features, in_features]存储,能够保证同一个输出神经元对应的所有输入权重在物理内存中是连续排列的。这极大地提升了 CPU/GPU 缓存的命中率,让底层的 C++/CUDA 矩阵乘法算子执行得飞快。
(2). call - 实例调用(执行前向传播)
作用:将输入数据喂给该层并执行前向传播计算。在PyTorch中,所有的 nn.Module 子类都重写了Python的魔法方法 __call__。因此,我们严禁直接调用 .forward(X),而是直接把实例对象当成函数来调用(例如 linear_layer(X))。因为 __call__ 内部不仅调用了正向传播逻辑,还负责管理和运行各种底层的钩子(hooks)机制。
python
# 实例化后,直接像调用函数一样调用该对象
linear_layer(input)参数:
- 输入张量 (input): 输入的特征张量 (Tensor),形状通常为
(m, in_features)(mmm 为样本量)。
返回值:
- 成功: 返回经过线性变换后的输出结果张量 (Tensor),形状为
(m, out_features)。
示例:
python
import torch
import torch.nn as nn
# 1. 准备假数据 (m=4 个样本,n=3 个特征)
# 注意:这里千万不需要再手动加一列 1 了!
X = torch.tensor([[1., 0., 0.],
[1., 1., 0.],
[1., 0., 1.],
[1., 1., 1.]])
# 2. 实例化线性层
# in_features=3 (因为X有3列),out_features=1 (输出单个预测值)
linear_layer = nn.Linear(in_features=3, out_features=1)
# 3. 前向传播:直接把 X 喂给实例化后的对象
# 注意:这里触发了 __call__ 方法!
# 在底层,它自动执行了 X @ linear_layer.weight.T + linear_layer.bias
z_hat = linear_layer(X)
print("预测结果的形状:", z_hat.shape)
# 返回 torch.Size([4, 1])
print("\n系统自动初始化的权重 W:\n", linear_layer.weight)
# 形状是 (1, 3),并且自动带有 requires_grad=True
# 比如: tensor([[ 0.4312, -0.1583, 0.5101]], requires_grad=True)
print("\n系统自动初始化的偏置 b:\n", linear_layer.bias)
# 形状是 (1,),同样带有 requires_grad=True
# 比如: tensor([-0.3121], requires_grad=True)二. 二分类神经网络:逻辑回归
1. 理论基础
**线性回归是统计学经典算法,它能够拟合出一条直线来描述变量之间的线性关系。但在实际中,变量之间的关系通常都不是一条直线,而是呈现出某种曲线关系。在统计学的历史中,为了让统计学模型能够更好地拟合曲线,统计学家们在线性回归的方程两边引入了联系函数(link function),对线性回归的方程做出了各种各样的变化,并将这些变化后的方程称为"广义线性回归"。**其中比较著名的有等式两边同时取对数的对数函数回归、同时取指数的S形函数回归等。
y=ax+b→lny=ln(ax+b)y = ax + b \quad \rightarrow \quad \ln y = \ln(ax + b)y=ax+b→lny=ln(ax+b)
y=ax+b→ey=eax+by = ax + b \quad \rightarrow \quad e^y = e^{ax+b}y=ax+b→ey=eax+b
当我们需要模型输出"是"或"否"(例如判断图片是不是猫)时,连续的回归值 zzz 就不适用了。我们需要在回归网络的基础上,叠加一个激活函数(Activation Function) ,将输出结果压缩到 (0,1)(0, 1)(0,1) 的概率区间。
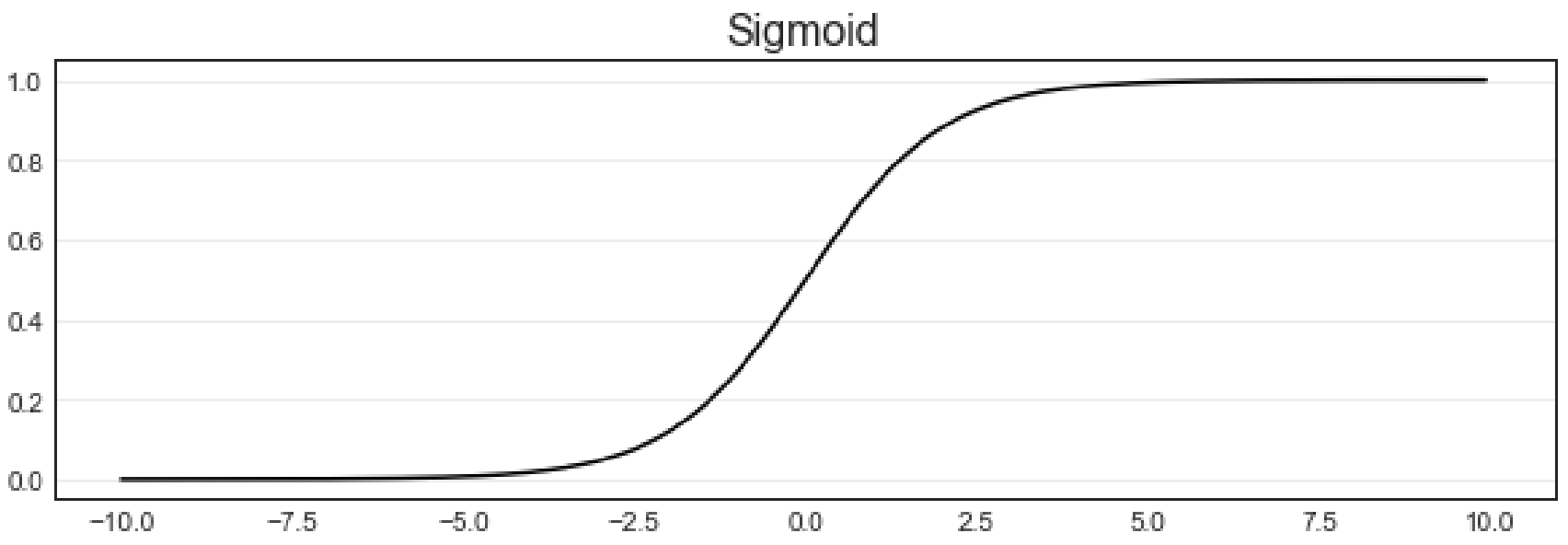
逻辑回归(Logistic Regression)本质上就是"单层线性回归 + Sigmoid 激活函数"构成的二分类神经网络。
2. 核心激活函数:Sigmoid
Sigmoid(又称 Logistic 函数)可以将任意实数映射到 0 到 1 之间,完美契合概率的定义。
- 数学公式 :
σ(z)=11+e−z\sigma(z) = \frac{1}{1 + e^{-z}}σ(z)=1+e−z1
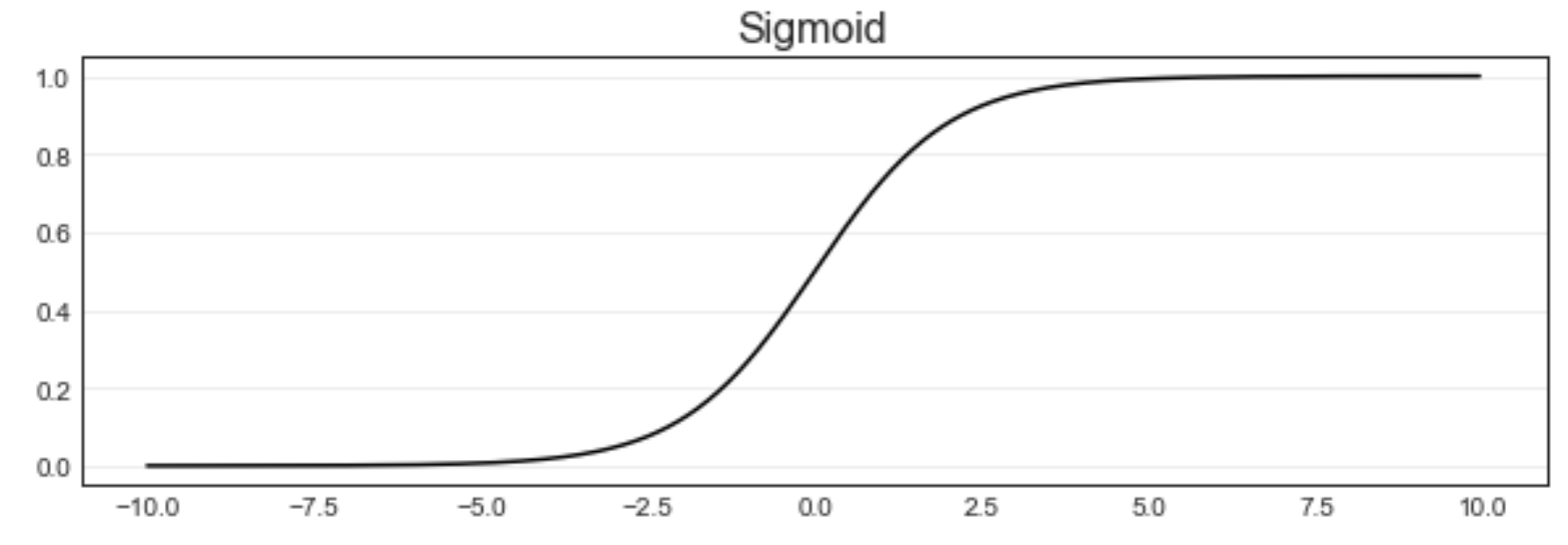
从图像上就可以看出,这个函数的性质相当特别。当自变量 zzz 趋近正无穷时,因变量 σ\sigmaσ 趋近于 111,而当 zzz 趋近负无穷时,σ\sigmaσ 趋近于 000,这使得 Sigmoid 函数能够将任何实数映射到 (0,1)(0,1)(0,1) 区间。同时,Sigmoid 的导数在 z=0z = 0z=0 点时最大(这一点的斜率最大),所以它可以快速将数据从 z=0z = 0z=0 的附近排开,让数据点到远离自变量取 000 的地方去。这样的性质,让 Sigmoid 函数拥有将连续性变量 zzz 转化为离散型变量 σ\sigmaσ 的力量,这也就是化回归算法为分类算法的力量。
补充:除了 Sigmoid,常用的激活函数还有阶跃函数 (Sign)、ReLU、Tanh 等,但在二分类的输出层,Sigmoid 是绝对的霸主。
更神奇的是,当我们对线性回归的结果取 Sigmoid 函数之后,只要再进行以下操作:
补充:只要形如σ1−σ\frac{\sigma}{1-\sigma}1−σσ,且1> σ\sigmaσ >0,σ1−σ\frac{\sigma}{1-\sigma}1−σσ就叫做几率。
- 将结果 σ\sigmaσ 以几率(σ1−σ\frac{\sigma}{1-\sigma}1−σσ)的形式展现。
- 在几率上取以 eee 为底的对数。
就很容易得到:
lnσ1−σ=ln(11+e−Xw1−11+e−Xw)=ln(11+e−Xwe−Xw1+e−Xw)=ln(1e−Xw)=ln(eXw)=Xw \begin{aligned} \ln \frac{\sigma}{1-\sigma} &= \ln \left( \frac{\frac{1}{1+e^{-Xw}}}{1 - \frac{1}{1+e^{-Xw}}} \right) \\ &= \ln \left( \frac{\frac{1}{1+e^{-Xw}}}{\frac{e^{-Xw}}{1+e^{-Xw}}} \right) \\ &= \ln \left( \frac{1}{e^{-Xw}} \right) \\ &= \ln(e^{Xw}) \\ &= Xw \end{aligned} ln1−σσ=ln(1−1+e−Xw11+e−Xw1)=ln(1+e−Xwe−Xw1+e−Xw1)=ln(e−Xw1)=ln(eXw)=Xw
**不难发现,让 σ\sigmaσ 取对数几率后所得到的值就是我们线性回归的 zzz!因为这个性质,在等号两边加 Sigmoid 的算法被称为"对数几率回归",在英文中就是 Logistic Regression,就是逻辑回归。**逻辑回归可能是广义线性回归中最为人知的算法,它是一个叫做"回归"实际上却总是被用来做分类的算法,对机器学习和深度学习都有重大的意义。
注:σ\sigmaσ 值的概率解释(了解即可)
σ\sigmaσ 值代表了样本为某一类标签的概率
lnσ1−σ\ln \frac{\sigma}{1-\sigma}ln1−σσ 是形似对数几率的一种变化。而几率(odds)的本质其实是 p1−p\frac{p}{1-p}1−pp,其中 ppp 是事件 A 发生的概率,而 1−p1-p1−p 是事件 A 不会发生的概率,并且 p+(1−p)=1p+(1-p)=1p+(1−p)=1。因此,很多人在理解逻辑回归时,都对 σ\sigmaσ 做出如下的解释:
我们让线性回归结果逼近 0 和 1,此时 σ\sigmaσ 和 1−σ1-\sigma1−σ 之和为 1,因此它们可以被我们看作是一对正反例发生的概率,即 σ\sigmaσ 是某样本 iii 的标签被预测为 1 的概率 ,而 1−σ1-\sigma1−σ 是 iii 的标签被预测为 0 的概率 ,σ1−σ\frac{\sigma}{1-\sigma}1−σσ 就是样本 iii 的标签被预测为 1 的相对概率。基于这种理解,逻辑回归、即单层二分类神经网络返回的结果被当成概率来看待和使用(如果直接说它就是概率,或许不太严谨)。每当我们需要求解"样本 iii 的标签是 1 或是 0 的概率"时,我们就使用逻辑回归。
因此,当一个样本对应的 σi\sigma_iσi 越接近 1 或 0,我们就认为逻辑回归对这个样本的预测结果越肯定,样本被分类正确的可能性也越高。如果 σi\sigma_iσi 非常接近阈值(比如 0.5),就说明逻辑回归其实对这个样本究竟应该是哪一类别,不是非常肯定。
3. torch.sigmoid - Sigmoid 激活函数
torch.nn.functional做过一次瘦身,只有那些专门为了优化神经网络而被发明出来且往往带有超参数的函数,才有资格留在 torch.nn.functional 里。
注:torch.nn.functional.sigmoid 已经被官方弃用(Deprecated)了!
作用:
对输入张量执行逐元素的 Sigmoid 运算。它能将输入的所有实数(从负无穷到正无穷)映射到 (0,1)(0, 1)(0,1) 之间的开区间。在逻辑回归中,这个输出值通常被解释为"属于正类的概率"。当 z=0z=0z=0 时,输出正好为 0.50.50.5。
python
torch.sigmoid(input, *, out=None)数学公式:
outi=σ(inputi)=11+e−inputi\text{out}_i = \sigma(input_i) = \frac{1}{1 + e^{-input_i}}outi=σ(inputi)=1+e−inputi1
参数:
- 输入张量 (input): 需要执行激活计算的目标张量 (Tensor)。
- 输出张量 (out): 可选。指定存储结果的张量 (Tensor)。
返回值:
- 成功: 返回一个与输入形状完全相同、元素值均在 (0,1)(0, 1)(0,1) 之间的新张量 (Tensor)。
注:PyTorch张量也支持sigmoid()方法式调用或原地操作
python
z = torch.tensor([-100.0, -1.0, 0.0, 1.0, 100.0])
z.sigmoid() # 等价于 torch.sigmoid(z)
z.sigmoid_() # 原地修改z的值,节省显存 (In-place)*核心特性:
- 非线性转换 :将线性方程的输出 zzz 转变为概率,是神经网络具备复杂分类能力的关键。
- 梯度消失隐患:当输入值很大(如 10)或很小(如 -10)时,Sigmoid 函数的曲线会变得极其平缓。此时该处的导数(梯度)接近于 0,这在深层神经网络中会导致模型参数无法更新,即"梯度消失"现象。
示例:
python
# 1. 模拟线性回归的输出 z
z = torch.tensor([-100.0, -1.0, 0.0, 1.0, 100.0])
# 2. 执行 Sigmoid 转换
p = torch.sigmoid(z)
# 观察结果:
# - 极小值 (-100) 趋近于 0
# - 零值 (0) 对应 0.5
# - 极大值 (100) 趋近于 1
print("概率输出 p:\n", p)
# tensor([0.0000e+00, 2.6894e-01, 5.0000e-01, 7.3106e-01, 1.0000e+00])补充:在之后,如果你学习到 nn.Module 的构建,会发现 PyTorch 还提供了一个 nn.Sigmoid 类。
torch.sigmoid:是一个函数 (Functional),像加减乘除一样直接用,适合在forward函数里处理中间变量。nn.Sigmoid:是一个层(Layer/Module) ,它不存放参数,但可以像nn.Linear一样塞进nn.Sequential容器里,构建模型时代码结构感更强。
4. PyTorch实现
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# 0. 固定随机种子,保证每次运行生成的初始权重 W 和偏置 b 一致
torch.manual_seed(42)
# 第一部分:模拟真实的逻辑回归前向传播 (nn.Linear + Sigmoid)
# 1. 准备输入特征 X (m=2个样本, n=3个特征)
X = torch.tensor([[1., 0., 0.],
[1., 1., 0.]])
# 2. 实例化线性层 (in_features=3, out_features=1)
# 这一步自动创建了权重 W (1, 3) 和偏置 b (1,)
output_layer = nn.Linear(3, 1)
# 3. 计算线性组合 z (回归阶段)
# 底层执行: z = X @ W.T + b
z_hat = output_layer(X)
print("线性层输出 z_hat:\n", z_hat, "\n")
# 线性层输出 z_hat:
# tensor([[0.9718],
# [1.4510]], grad_fn=<AddmmBackward0>)
# 4. 通过 Sigmoid 激活函数将其转化为概率(分类阶段)
# 推荐使用torch.sigmoid();因为torch.nn.functional.sigmoid已经被官方弃用(Deprecated)了!
prob = torch.sigmoid(z_hat)
print("经过Sigmoid后的概率输出 prob:", prob)
# prob中的值代表样本属于类别'1'的概率(0到1之间)
# 经过Sigmoid后的概率输出 prob: tensor([[0.7255],
# [0.8101]], grad_fn=<SigmoidBackward0>)5. 符号函数sign
(1).定义
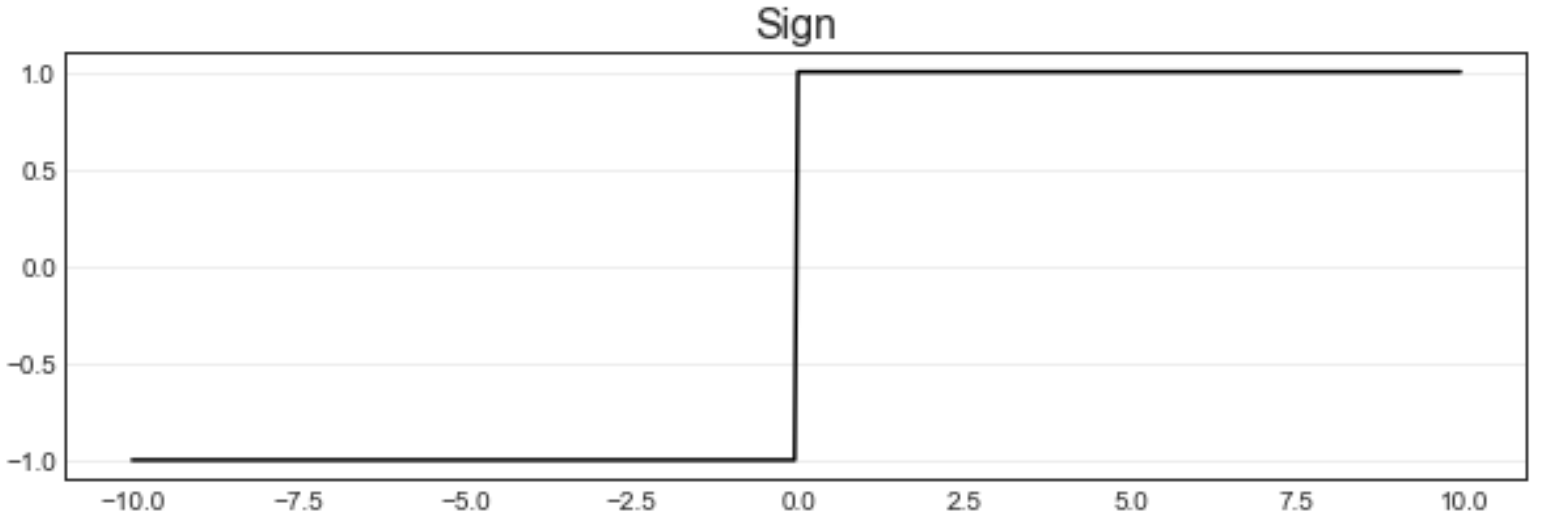
符号函数是图像如下所示的函数。
我们可以使用以下表达式来表示它:
y={1if z>00if z=0−1if z<0 y = \begin{cases} 1 & if \ z > 0 \\ 0 & if \ z = 0 \\ -1 & if \ z < 0 \end{cases} \quad y=⎩ ⎨ ⎧10−1if z>0if z=0if z<0
由于函数的取值是间断的,符号函数也被称为"阶跃函数" ,表示在0的两端,函数的结果y是从-1直接阶跃到了1。在这里,我们使用y而不是σ\sigmaσ来表示输出的结果,是因为输出结果直接是0、1、-1这样的类别,就相当于标签了。对于sigmoid函数而言,σ\sigmaσ返回的是0~1之间的概率值,如果我们希望获取最终预测出的类别,还需要将概率转变成0或1这样的数字才可以。但符号函数可以直接返回类别,因此我们可以认为符号函数输出的结果就是最终的预测结果y。在二分类中,符号函数也可以忽略中间z=0z = 0z=0的时候,直接分为0和1两类,用如下式子表示:
y={1if z>00if z≤0 y = \begin{cases} 1 & if \ z > 0 \\ 0 & if \ z \le 0 \end{cases} \quad y={10if z>0if z≤0
等号被并在上方或下方都可以。这个式子可以很容易被转化为下面的式子:
∵z=w1x1+w2x2+b \because z = w_1x_1 + w_2x_2 + b ∵z=w1x1+w2x2+b
∴y={1if w1x1+w2x2+b>00if w1x1+w2x2+b≤0 \therefore y = \begin{cases} 1 & if \ w_1x_1 + w_2x_2 + b > 0 \\ 0 & if \ w_1x_1 + w_2x_2 + b \le 0 \end{cases} ∴y={10if w1x1+w2x2+b>0if w1x1+w2x2+b≤0
∴y={1if w1x1+w2x2>−b0if w1x1+w2x2≤−b \therefore y = \begin{cases} 1 & if \ w_1x_1 + w_2x_2 > -b \\ 0 & if \ w_1x_1 + w_2x_2 \le -b \end{cases} ∴y={10if w1x1+w2x2>−bif w1x1+w2x2≤−b
此时,−b-b−b就是一个阈值,我们可以使用任意字母来替代它,比较常见的是字母θ\thetaθ。当然,不把它当做阈值,依然保留w1x1+w2x2+bw_1x_1 + w_2x_2 + bw1x1+w2x2+b与0进行比较的关系也没有任何问题。和sigmoid一样,我们也可以使用阶跃函数来处理数据:
python
X = torch.tensor([[1,0,0],
[1,1,0],
[1,0,1],
[1,1,1]], dtype = torch.float32)
andgate = torch.tensor([[0],
[0],
[0],
[1]], dtype = torch.float32)
w = torch.tensor([-0.2,0.15, 0.15], dtype = torch.float32)
def LinearRwithsign(X,w):
zhat = X@w
#注:矩阵×向量:(m,n)@(n)结果是1D的(m),w传的是1D的所以andhat是1维张量
andhat = torch.tensor([int(x) for x in zhat >= 0], dtype = torch.float32)
#注:列表推导式返回列表,所以andhat是1维张量
return zhat, andhat
LinearRwithsign(X,w)
# (tensor([-0.2000, -0.0500, -0.0500, 0.1000]), tensor([0., 0., 0., 1.]))阶跃函数和sigmoid都可以完成二分类的任务。在神经网络的二分类中,σ\sigmaσ的默认取值一般都是sigmoid函数,少用阶跃函数,这是由神经网络的解法决定的,我们后面详细讲解。
(2).torch.sign - 符号函数(阶跃函数)
没有torch.nn.functional.sign这个方法
作用:
对输入张量执行逐元素的符号提取运算。它能将输入的所有实数瞬间"阶跃"为三个极简的离散值:大于 0 返回 1,等于 0 返回 0,小于 0 返回 -1。在最基础的二分类(如感知机、逻辑与门)中,它可以直接抛弃概率,强行输出最终的类别标签。
python
torch.sign(input, *, out=None)数学公式:
outi={1(inputi>0)0(inputi=0)−1(inputi<0) \text{out}_i = \begin{cases} 1 & (input_i > 0) \\ 0 & (input_i = 0) \\ -1 & (input_i < 0) \end{cases} outi=⎩ ⎨ ⎧10−1(inputi>0)(inputi=0)(inputi<0)
参数:
- 输入张量 (input): 需要执行提取目标符号的张量 (Tensor)。
- 输出张量 (out): 可选。指定存储结果的张量 (Tensor)。
返回值:
- 成功: 返回一个与输入形状完全相同、元素值仅包含 {−1,0,1}\{-1, 0, 1\}{−1,0,1} 的新张量 (Tensor)。
注:PyTorch张量也支持sign()方法式调用或原地操作
python
z = torch.tensor([-100.0, -1.0, 0.0, 1.0, 100.0])
z.sign() # 等价于 torch.sign(z)
z.sign_() # 原地修改z的值,节省显存 (In-place)核心特性 (致命缺陷):
- 直接输出标签:它拥有化连续为离散的力量,是最纯粹的分类器函数。
- 不可导 (梯度阻断) :这是它在现代深度学习中被抛弃的根本原因 。在 z=0z=0z=0 处不可导,而在其他所有地方导数均为 000。如果在深层网络中使用它,反向传播时的梯度会瞬间变为 0,导致网络参数完全无法更新。
示例:
python
import torch
z = torch.tensor([-100.0, -0.5, 0.0, 0.5, 100.0])
y = torch.sign(z)
print("阶跃输出 y:\n", y)
# tensor([-1., -1., 0., 1., 1.])补充: ==因为它无法参与梯度的反向传播计算,所以 PyTorch 官方没有提供对应的 nn.Sign 类。==它通常只用于数据预处理或指标评估,绝不用于深层网络的隐层激活。
6.ReLU
(1).定义
**ReLU(Rectified Linear Unit)函数又名整流线性单元函数,英文发音为/rel-you/,是现在神经网络领域中的宠儿,应用甚至比sigmoid更广泛。ReLU提供了一个很简单的非线性变换:当输入的自变量大于0时,直接输出该值,当输入的自变量小于等于0时,输出0。**这个过程可以用以下公式表示出来:
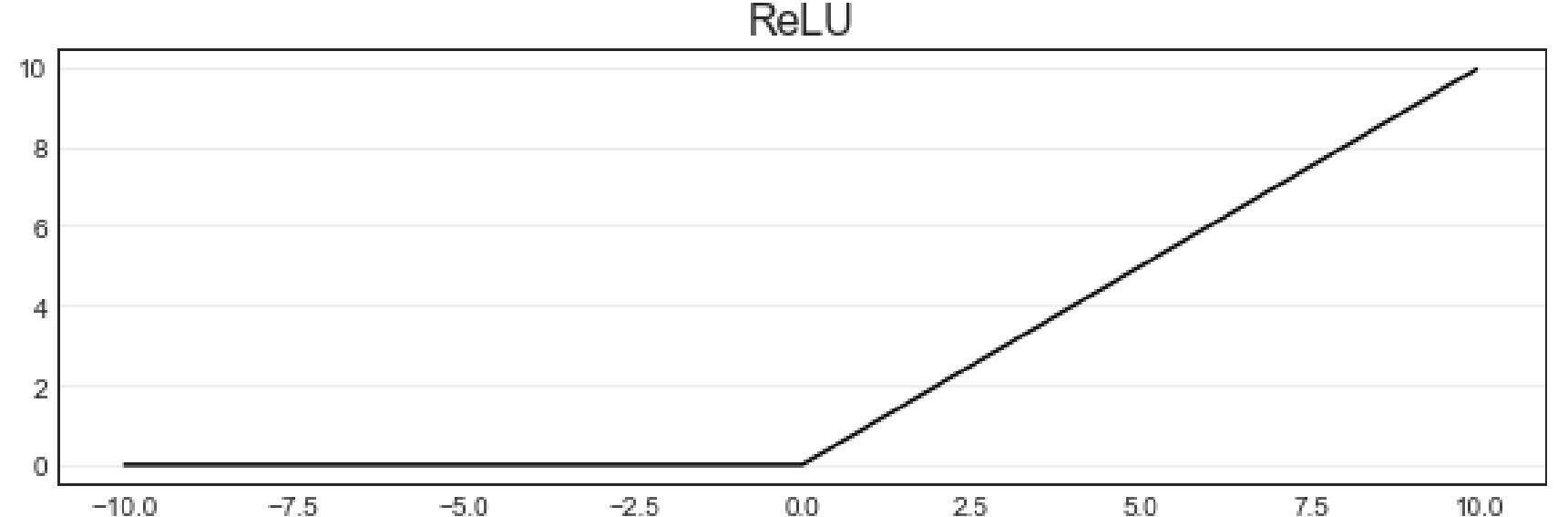
ReLU:σ={z(z>0)0(z≤0) ReLU: \sigma = \begin{cases} z & (z > 0) \\ 0 & (z \le 0) \end{cases} ReLU:σ={z0(z>0)(z≤0)
ReLU函数是一个非常简单的函数,本质就是max(0,z)\max(0,z)max(0,z)。max函数会从输入的数值中选择较大的那个值进行输出,以达到保留正数元素,将负元素清零的作用。ReLU的图像如下所示:
相对的,ReLU函数导数的图像如下:
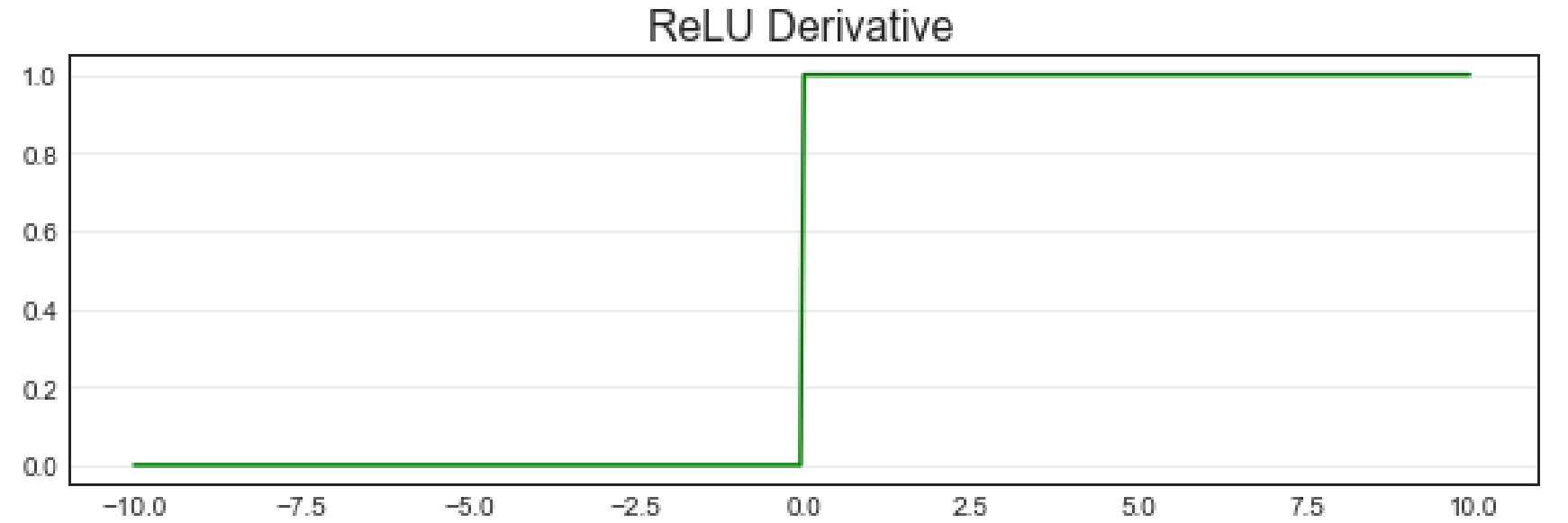
当输入 zzz 为正数时,ReLU函数的导数为1,当 zzz 为负数时,ReLU函数的导数为0,当输入为0时,ReLU函数不可导。因此,ReLU函数的导数图像看起来就是阶跃函数,这是一个美好的巧合。
(2).torch.relu & torch.nn.functional.relu - ReLU激活函数
作用:
对输入张量执行逐元素的 ReLU 运算,本质就是 max(0,z)\max(0, z)max(0,z)。它保留所有正数,并将所有负数强制清零。ReLU 是现代深度学习领域绝对的"宠儿",在多层感知机 (MLP) 和卷积神经网络 (CNN) 中的应用远超 Sigmoid。
python
torch.relu(input)
# 或者在底层常写为:
torch.nn.functional.relu(input, inplace=False)数学公式:
outi={inputi(inputi>0)0(inputi≤0) \text{out}_i = \begin{cases} input_i & (input_i > 0) \\ 0 & (input_i \le 0) \end{cases} outi={inputi0(inputi>0)(inputi≤0)
参数:
- 输入张量 (input): 需要执行激活计算的目标张量 (Tensor)。
- 原地操作标志 (inplace): 决定是否直接在原内存地址上修改数据。默认为
False。如果设为True,底层将不会为输出结果分配新的显存空间,而是直接覆盖原有的input张量。
返回值:
- 成功: 返回一个与输入形状完全相同,将负数截断为 0 的新张量 (Tensor)。
注:PyTorch张量也支持relu()方法式调用或原地操作
python
import torch
import torch.nn.functional as F
z = torch.tensor([-100.0, -1.0, 0.0, 1.0, 100.0])
z.relu() # 等价于 torch.relu(z)
z.relu_() # 原地修改z的值,节省显存 (In-place)
# 使用 functional 接口
F.relu(z) # 默认 inplace=False,不修改原张量
F.relu(z, inplace=True) # 原地修改(等价于 z.relu_())核心特性:
- 极速计算 :没有任何指数运算 (exe^xex),只有极其底层的比大小指令,在 CPU/GPU 上执行速度奇快。
- 缓解梯度消失 :当 z>0z > 0z>0 时,其导数永远恒定为 111。这使得无论神经网络有多深,正向信号的梯度都能毫无衰减地反向传播回去。
- Dying ReLU (神经元死亡隐患) :当 z<0z < 0z<0 时,输出为 0,且导数也为 0。如果学习率设置过大,导致某次更新后偏置 bbb 变成一个很大的负数,这个神经元可能以后永远只能输出 0,彻底"死掉"。
示例:
python
z = torch.tensor([-100.0, -1.0, 0.0, 1.0, 100.0])
p = torch.relu(z)
print("ReLU 输出 p:\n", p)
# tensor([ 0., 0., 0., 1., 100.])补充:torch.relu vs nn.ReLU
torch.relu:是函数,直接调用。nn.ReLU(inplace=False):是层(Module) 。在工业界,构建网络极其常用nn.Sequential(nn.Linear(2, 4), nn.ReLU(), nn.Linear(4, 1))这样的组合。你可以通过设置inplace=True让它在原地修改数据,进一步榨干显存。
7.tanh
(1).定义
tanh (hyperbolic tangent) 是双曲正切函数,英文发音/tæntʃ/或者/θæn/。双曲正切函数的性质与sigmoid相似,它能够将数值压缩到(-1,1)区间内。
tanh:σ=e2z−1e2z+1(10) tanh: \sigma = \frac{e^{2z} - 1}{e^{2z} + 1} \quad (10) tanh:σ=e2z+1e2z−1(10)
而双曲正切函数的图像如下:
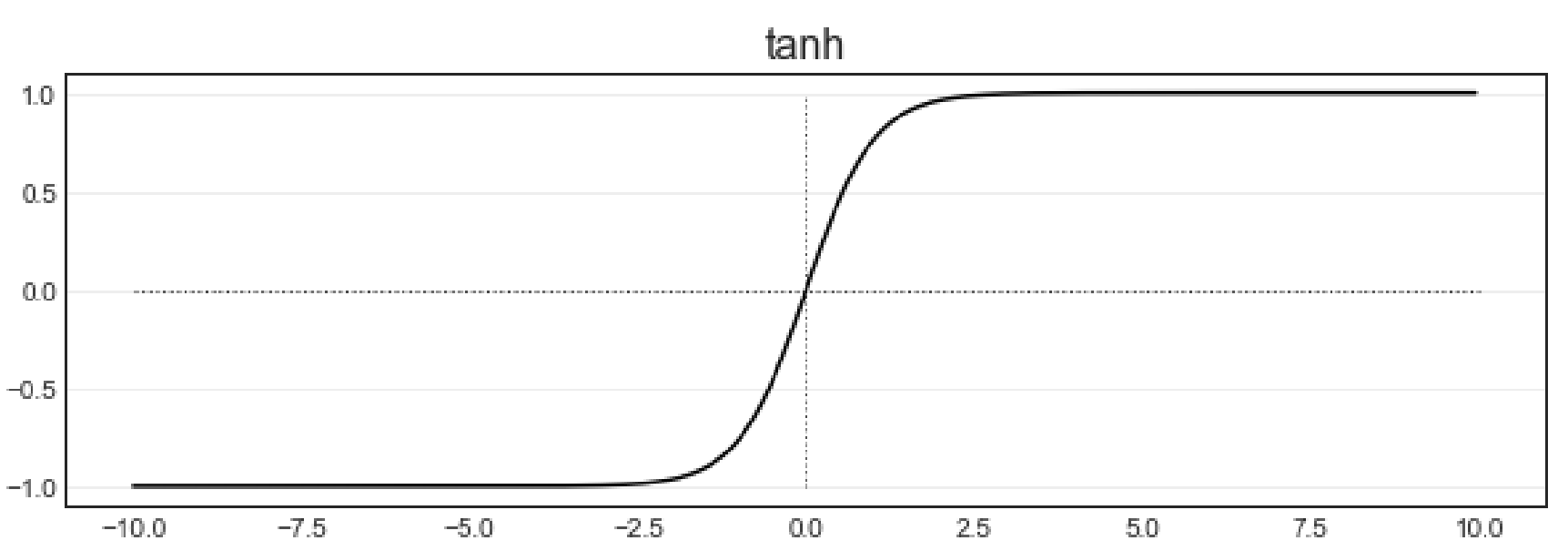
可以看出,tanh的图像和sigmoid函数很像,不过sigmoid函数的范围是在(0,1)之间,tanh却是在坐标系的原点(0,0)点上中心对称。
对tanh求导后可以得到如下公式和导数图像:
tanh′(z)=1−tanh2(z)(11) tanh'(z) = 1 - tanh^2(z) \quad (11) tanh′(z)=1−tanh2(z)(11)
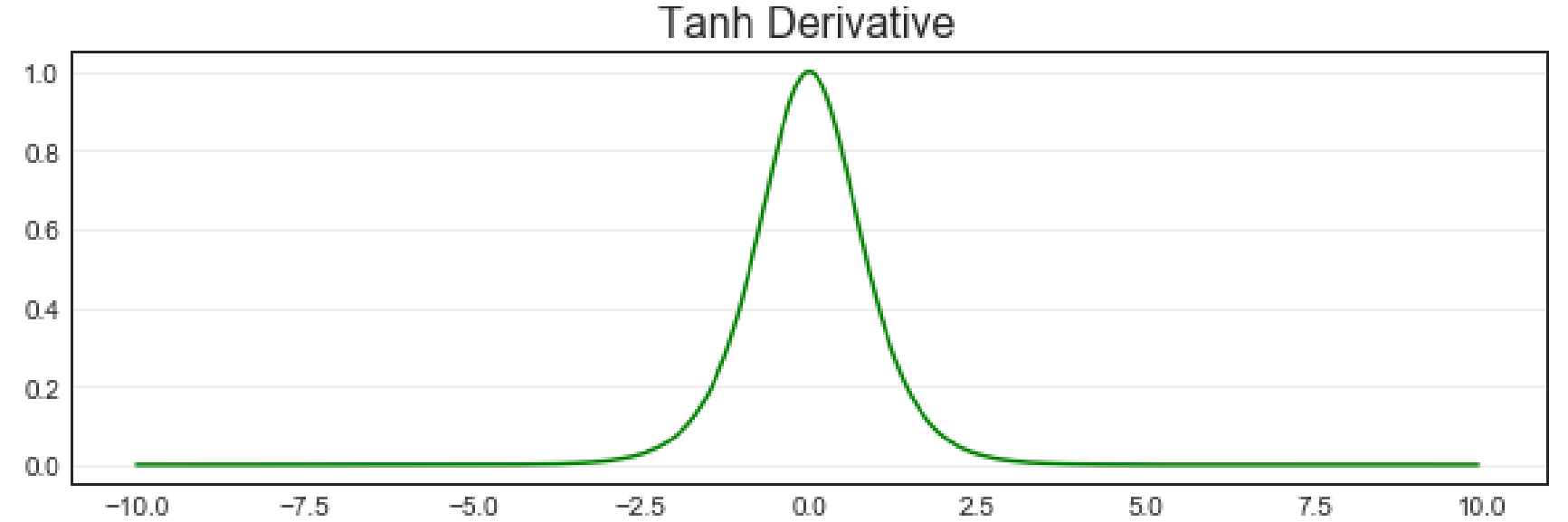
可以看出,当输入的 zzz 约接近于0,tanh函数导数也越接近最大值1,当输入越偏离0时,tanh函数的导数越接近于0。这些函数是最常见的二分类转化函数,他们在神经网络的结构中有着不可替代的作用。在单层神经网络中,这种作用是无法被体现的,因此关于这一点,我们可以之后再进行说明。到这里,我们只需要知道这些函数都可以将连续型数据转化为二分类就足够了。
(2).torch.tanh - 双曲正切激活函数
注:torch.nn.functional.tanh 已经被官方弃用(Deprecated)了!
作用:
对输入张量执行逐元素的双曲正切运算。它能将输入的实数压缩到 (−1,1)(-1, 1)(−1,1) 之间。你可以把它看作是"加强版"且"向下平移"过的 Sigmoid 函数。
python
torch.tanh(input, *, out=None)数学公式:
outi=tanh(inputi)=e2inputi−1e2inputi+1\text{out}_i = \tanh(input_i) = \frac{e^{2input_i} - 1}{e^{2input_i} + 1}outi=tanh(inputi)=e2inputi+1e2inputi−1
参数:
- 输入张量 (input): 需要执行激活计算的目标张量 (Tensor)。
- 输出张量 (out): 可选。指定存储结果的张量 (Tensor)。
返回值:
- 成功: 返回一个与输入形状完全相同、元素值均在 (−1,1)(-1, 1)(−1,1) 之间的新张量 (Tensor)。
注:PyTorch张量也支持tanh()方法式调用或原地操作
python
z = torch.tensor([-100.0, -1.0, 0.0, 1.0, 100.0])
z.tanh() # 等价于 torch.tanh(z)
z.tanh_() # 原地修改z的值,节省显存 (In-place)核心特性:
- 零中心化 (Zero-centered) :与 Sigmoid (输出恒为正) 不同,Tanh 的输出是关于坐标原点 (0,0)(0,0)(0,0) 对称的。在数学上,零中心化的输出能使下一层网络权重的更新方向更均匀,收敛速度通常远快于 Sigmoid。
- 梯度消失 :虽然收敛更快,但它在两端的曲线依然非常平缓(当 zzz 很大或很小时,导数趋近于 0),依然无法解决极深网络中的梯度消失问题。
示例:
python
z = torch.tensor([-100.0, -1.0, 0.0, 1.0, 100.0])
p = torch.tanh(z)
# 观察结果:
# - 极小值趋近于 -1
# - 零值精确对应 0
# - 极大值趋近于 1
print("Tanh 输出 p:\n", p)
# tensor([-1.0000, -0.7616, 0.0000, 0.7616, 1.0000])补充:torch.tanh vs nn.Tanh
torch.tanh:是函数,常用于公式推导计算中(例如 RNN 循环神经网络底层的隐状态更新)。nn.Tanh():是层(Module) ,可以直接放入nn.Sequential容器中。
三. 多分类神经网络:Softmax 回归
1. 理论基础
当我们需要对样本进行多类别分类(如区分猫、狗、猪)时,输出层需要有多个神经元(每个神经元代表一个类别的得分)。为了让这些得分转化为合乎逻辑的概率(即所有类别的概率加起来必须等于 1),我们需要使用 Softmax 函数。
-
数学公式:
Softmax(zk)=ezk∑i=1KeziSoftmax(z_k) = \frac{e^{z_k}}{\sum_{i=1}^K e^{z_i}}Softmax(zk)=∑i=1Keziezk
(其中 KKK 是总类别数,zkz_kzk 是第 kkk 个类别的线性得分)
2. 避坑提醒:Softmax 的指数爆炸(溢出)问题
因为 Softmax 公式中涉及 eze^zez 的计算,当输入的 zzz 值很大(例如 z=1000z=1000z=1000)时,e1000e^{1000}e1000 会产生极其庞大的数值,导致计算机底层发生溢出(Overflow),返回 nan (Not a Number)。
解决方案:在计算 eze^zez 之前,将所有 zzz 值减去它们当中的最大值 CCC(即 z′=z−Cz' = z - Cz′=z−C)。这在数学上等价,但在计算机计算中完美规避了溢出问题。(注:PyTorch 底层的 softmax 已经内置了此防溢出机制,无需手动实现,但必须懂其原理!)
3. torch.softmax / F.softmax - Softmax 激活函数
注:在多维张量中使用 Softmax 时,强烈建议(有时是强制要求)显式指定 dim 参数,否则极易导致维度计算错位!
作用:
对输入张量的指定维度执行 Softmax 运算。它能将一组实数(通常是神经网络最后一层输出的原始得分 Logits)映射为取值在 (0,1)(0, 1)(0,1) 之间、且总和严格为 111 的概率分布。在多分类问题(如判断图片是猫、狗还是猪)中,输出值代表样本属于各个类别的相对概率。
python
import torch.nn.functional as F
# 两种写法在底层是完全等价的
F.softmax(input, dim=None, dtype=None)
torch.softmax(input, dim=None, dtype=None)数学公式:
对于输入向量 z\boldsymbol{z}z 中的第 iii 个元素,其 Softmax 值为:
Softmax(zi)=ezi∑j=1Kezj\text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}}Softmax(zi)=∑j=1Kezjezi
(其中 KKK 是该维度上元素的总个数。分子是当前元素的指数,分母是所有元素指数的总和)
参数:
-
输入张量 (input): 需要执行概率映射的目标张量 (Tensor)。
-
计算维度 (dim): 整数 (int)。必填!核心参数!指定在哪个维度上计算 Softmax(即让哪个维度上的元素加起来等于 1)。
填你希望进行softmax运算的那个维度的索引;
例如,对于形状为
(m个样本, n个类别)的张量,必须设dim=1表示按行计算,dim=0表示的是样本个数 。 -
数据类型 (dtype): 可选。指定返回张量的数据类型。
返回值:
- 成功: 返回一个与输入形状完全相同的新张量 (Tensor),其在指定维度上的元素值均在 (0,1)(0, 1)(0,1) 之间,且求和为 111。
示例:
python
import torch
import torch.nn.functional as F
# 1. 模拟神经网络对 2 个样本的 3 分类原始输出 (Logits)
# 形状为 (2, 3),代表 2 个样本,每个样本的 3 个类别得分
logits = torch.tensor([[1.0, 2.0, 3.0], # 样本1得分接近
[100.0, 10.0, -10.0]]) # 样本2得分差距极大
# 2. 执行 Softmax 转换,必须指定 dim=1 (按行计算各个样本的概率)
p = F.softmax(logits, dim=1)
print("概率输出 p:\n", p)
# 观察结果:
# 样本1:[0.0900, 0.2447, 0.6652] (得分 3 抢走了近 66% 的概率)
# 样本2:[1.0000, 0.0000, 0.0000] (由于100比10大太多,指数级拉开差距,模型近乎100%肯定它是第一类)
# 3. 验证数学特性:每行的概率和必须为 1
print("\n每行的概率和:\n", p.sum(dim=1))
# tensor([1., 1.])补充:F.softmax vs nn.Softmax
F.softmax(z, dim=1)/torch.softmax(z, dim=1):是函数 ,适合在forward函数里灵活调用,处理中间流转的张量。nn.Softmax(dim=1):是层(Layer/Module) 。它没有参数,但在实例化时就必须把dim绑定好。你可以把它塞进nn.Sequential容器里,例如nn.Sequential(nn.Linear(10, 3), nn.Softmax(dim=1)),这样构建的预测模型代码会极其清爽。
4. PyTorch 实现
python
# 假设我们要分3类,输入特征数为2
import torch
from torch.nn import functional as F
X = torch.tensor([[0,0],[1,0],[0,1],[1,1]], dtype = torch.float32) ## 4个样本
torch.random.manual_seed(420)
# 输出层需要3个神经元 (out_features=3)
dense = torch.nn.Linear(2,3)
# 1.计算原始得分zhat(形状为4x3)
zhat = dense(X)
# tensor([[ 0.5453, 0.2653, -0.3527],
# [ 0.9772, 0.9382, -0.5684],
# [ 0.1197, -0.2964, -0.8400],
# [ 0.5516, 0.3765, -1.0557]], grad_fn=<AddmmBackward0>)
# 每一行代表一个样本,每一个列代表输出层每一神经元对应的初始得分。
# 2.沿类别维度(dim=1)执行Softmax
# dim=1表示对每一行(每个样本的3个类别得分)进行概率归一化,此时需要进行加和的维度是1
sigma = F.softmax(zhat,dim=1)
# tensor([[0.4623, 0.3494, 0.1883],
# [0.4598, 0.4422, 0.0980],
# [0.4896, 0.3229, 0.1875],
# [0.4902, 0.4115, 0.0983]], grad_fn=<SoftmaxBackward0>)
# 每一行代表一个样本,每一个列代表输出层每一神经元对应的类别的概率。
sigma.shape #这里应当返回的正确结构是(4,3),4个样本,每个样本都有自己的3个类别对应的3个概率
#---------------------------------------补充------------------------------------
print(dense.weight)
# Parameter containing:
# tensor([[ 0.4318, -0.4256],
# [ 0.6730, -0.5617],
# [-0.2157, -0.4873]], requires_grad=True)
# 每一行对应一个输出层的神经元,每一个列代表一个特征参数w
print(dense.bias)
# Parameter containing:
# tensor([ 0.5453, 0.2653, -0.3527], requires_grad=True)
# 同理,三个数分别对应一个输出层的神经元的一个特征参数b四. 核心结构对比总结
无论任务如何变化,单层神经网络的本质都是 z=XwT+bz = Xw^T + bz=XwT+b。区别仅仅在于输出层神经元的个数以及所使用的激活函数。
| 网络类型 | 适用任务 | 输出神经元个数 | 激活函数 (处理 z) | 输出结果含义 |
|---|---|---|---|---|
| 线性回归 | 连续值预测 (房价、温度) | 1 | 无 (直接输出) | 具体的连续数值 |
| 逻辑回归 | 二分类 (是/否) | 1 | Sigmoid | 属于某一类的概率 (0~1) |
| Softmax回归 | 多分类 (A类, B类, C类...) | K (类别数) | Softmax | 属于各类的概率分布 (和为1) |