一、绝对位置编码
正弦位置编码
含义:位置编码加到词嵌入上,让模型感知 token 的位置信息。向量的每一维都由不同频率的正弦或余弦波决定。
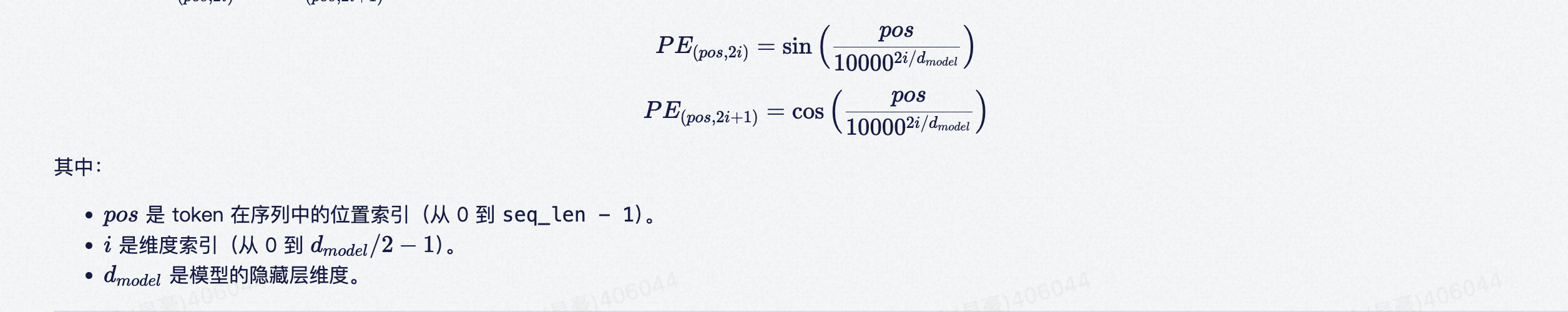
python
def sinusoidal_pe(seq_len, d_model):
pos = torch.arange(seq_len).float().unsqueeze(1)
dim = torch.arange(0, d_model, 2).float()
freqs = 1.0 / (10000.0 ** (dim / d_model))
angles = pos * freqs
pe = torch.zeros(seq_len, d_model)
pe[:, 0::2] = torch.sin(angles)
pe[:, 1::2] = torch.cos(angles)
return pe注意:
1、分母随着 i增大而指数级增长。低维度(如 i=0):频率高 → 变化快 → 捕捉局部细节。高维度:频率低 → 变化慢 → 捕捉全局结构。
2、计算快,不需要训练
3、不擅长外推到更长的序列
4、位置感知弱,只能表达"绝对"位置,无法直接编码词与词之间的相对距离
二、相对位置编码
ALiBi
含义:用固定线性偏置替代位置嵌入,直接加到注意力分数上。每个头有不同的斜率 m_h,对远距离 token 的注意力施加惩罚。
python
def alibi_attention(Q, K, V, num_heads):
B, S, D = Q.shape
d_h = D // num_heads
# Compute slopes: m_h = 1/2^(8h/H) for h=1..H
h_idx = torch.arange(1, num_heads + 1, dtype=torch.float32, device=Q.device)
slopes = 1.0 / (2.0 ** (8.0 * h_idx / num_heads)) # (H,)
# Distance matrix |i - j|, shape (S, S)
pos = torch.arange(S, device=Q.device).float()
dist = (pos.unsqueeze(0) - pos.unsqueeze(1)).abs() # (S, S)
# ALiBi bias: (H, S, S)
bias = -slopes.view(num_heads, 1, 1) * dist.unsqueeze(0)
# Split into heads: (B, H, S, d_h)
Qh = Q.view(B, S, num_heads, d_h).transpose(1, 2)
Kh = K.view(B, S, num_heads, d_h).transpose(1, 2)
Vh = V.view(B, S, num_heads, d_h).transpose(1, 2)
scores = (Qh @ Kh.transpose(-2, -1)) / (d_h ** 0.5) + bias.unsqueeze(0)
attn = torch.softmax(scores, dim=-1)
out = (attn @ Vh).transpose(1, 2).reshape(B, S, D)
return out注意:
1、越靠后的头(higher index),斜率越小,意味着它对远距离 token 的惩罚更轻,关注更全局的信息;前面的头斜率大,更关注局部信息。
2、位置信息加在attention scores 上,而不是embedding 上
3、外推能力好
4、较强的先验假设,即注意力随距离单调递减
5、ALiBi会直接影响Softmax的输入分布
6、计算复杂度高
三、旋转编码
RoPE
含义:不再加上位置向量,而是通过向量旋转方式,将位置信息编码进向量之间的点积中。
python
def apply_rope(q, k):
B, S, D = q.shape
pos = torch.arange(S, device=q.device).unsqueeze(1).float()
dim = torch.arange(0, D, 2, device=q.device).float()
freqs = 1.0 / (10000.0 ** (dim / D))
angles = pos * freqs
cos_a = torch.cos(angles)
sin_a = torch.sin(angles)
def rotate(x):
x1, x2 = x[..., 0::2], x[..., 1::2]
return torch.stack([x1 * cos_a - x2 * sin_a,
x1 * sin_a + x2 * cos_a], dim=-1).flatten(-2)
return rotate(q), rotate(k)注意:
1、分母随着 i增大而指数级增长。低维度(如 i=0):频率高 → 变化快 → 捕捉局部细节。高维度:频率低 → 变化慢 → 捕捉全局结构。
2、旋转是线性操作,可以无缝集成到现有的 Transformer 架构中,无需修改注意力机制的核心计算
3、两个向量的点积只依赖于它们的相对位置,而不是绝对位置。这使得模型能够更好地泛化到不同长度的序列。
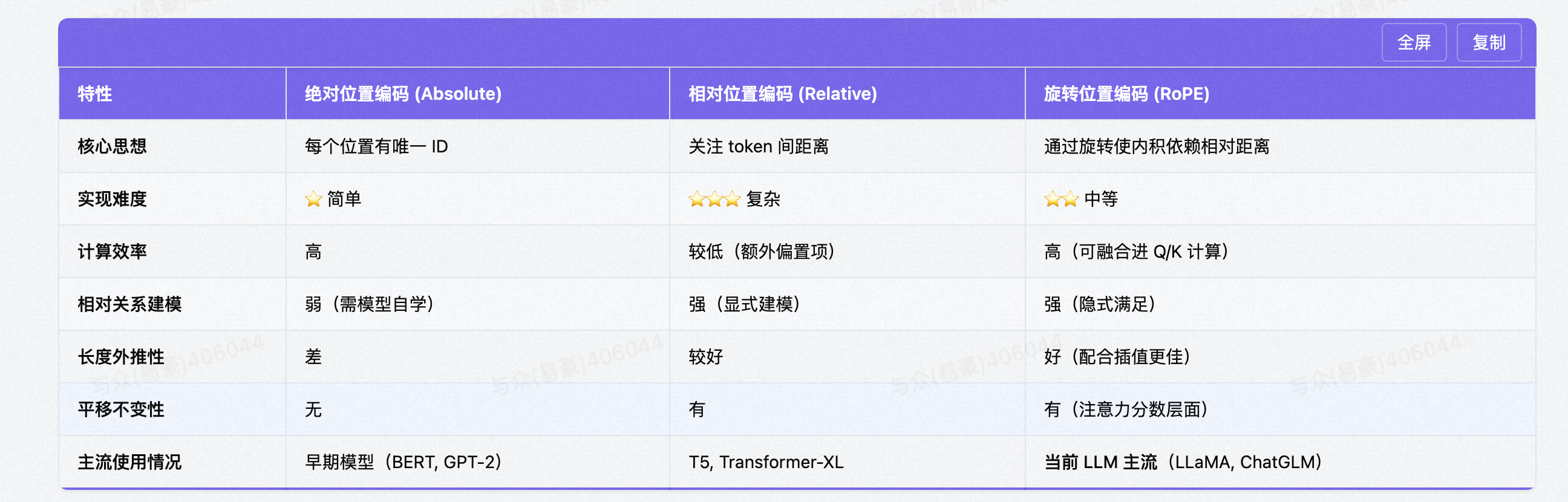
四、总结
五、位置外推
按比例缩放PI
含义:训练长度如果是n,但推理文本长度是4n,则直接按比例缩放,将所有文本位置都➗4。
注意:
1、这导致特征的高频维度(捕获局部信息)和低频维度(捕获全局信息)都被➗4
2、对于低频维度,本身数值较小,可以在长程依赖上表现不错
3、对于高频维度,本来两个token隔了4个距离,等比例缩放之后,导致局部区分度下降严重
NTK-aware RoPE 缩放
含义:标准 RoPE 在超过训练上下文长度的序列上性能下降。NTK-aware 缩放调整基础频率,保留高频维度同时拉伸低频维度,无需微调即可外推。
python
def ntk_rope(q, k, scale):
B, S, D = q.shape
new_base = 10000.0 * (scale ** (D / (D - 2)))
pos = torch.arange(S, device=q.device).float().unsqueeze(1)
dim = torch.arange(0, D, 2, device=q.device).float()
freqs = 1.0 / (new_base ** (dim / D))
angles = pos * freqs
cos_a = torch.cos(angles)
sin_a = torch.sin(angles)
def rotate(x):
x1, x2 = x[..., 0::2], x[..., 1::2]
return torch.stack([x1 * cos_a - x2 * sin_a,
x1 * sin_a + x2 * cos_a], dim=-1).flatten(-2)
return rotate(q), rotate(k)注意:
1、调整整个频谱的分布,使得在扩展后的长度下,高频部分仍然保持足够的振荡频率,从而保留对局部细节的敏感度。
2、让高频维度保持不变,只通过增大 base 来拉伸低频维度。