往期回顾
如何速成LLM以伪装成一个AI研究者(1)------循环,卷积,编解码器,注意力,Transformer
免责声明:作者也是伪装的,有错漏属于正常现象,欢迎评论指正。
更大更快更强的Transformer
今天我们要来读的是一篇2024年5月的技术报告,DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model (的第2章Architecture部分),以对比现代Transformer和17年提出的原始Transformer的区别。
DeepSeek 是一家成立于2023年7月17日的中国AI公司,由知名量化资管巨头幻方量化创立,总部位于浙江省杭州市,公司创始人梁文锋在量化投资和高性能计算领域拥有深厚背景。因为模型的出色表现和极低的推理成本,以及对开源社区的贡献而出名。
等一下------我们上次还在读2017年的论文,这次就直接跳到7年后了?
对,不然怎么叫速成嘛。
下图左边为上一期我们看过的,原始Transformer的架构,而右边为更现代的,DeepSeek-V2的架构。它主要有三个变化:(1)归一化层从Attention和FFN的后面变到了前面 (2)Attention层做了KV-Cache优化 (3)FFN层添加了MoE机制。
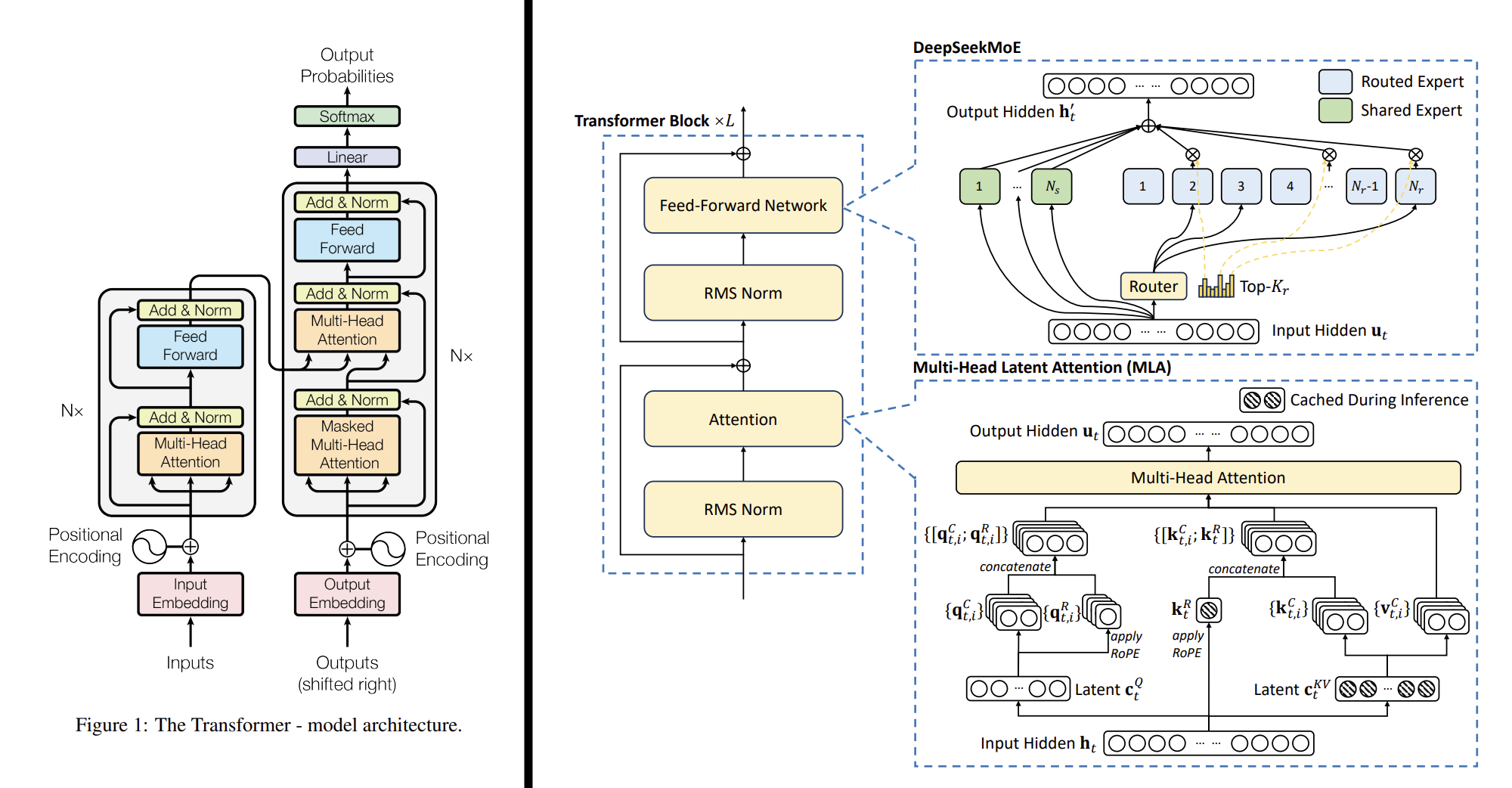
下面我们逐步拆解这三点。
Pre-LN vs Post-LN
对比两张图,你一定能发现的一个明显差异是,相比于原始的Transformer,现代网络的Norm层(也称为Layer Normalization,LN层)怎么挪到Attention和FFN前面去了?
当然,DeepSeek-V2用的是RMS Norm 而不是 LN 。
LN 是什么:设输入向量为 v ⃗ \vec{v} v , L N ( v ⃗ ) = γ v ⃗ − μ σ + β LN(\vec{v})=\gamma \frac{\vec{v}-\mu}{\sigma}+\beta LN(v )=γσv −μ+β。其中, μ , σ \mu,\sigma μ,σ为 v ⃗ \vec{v} v 的平均值和方差(即 μ = 1 ∣ v ⃗ ∣ ∑ i = 0 ∣ v ⃗ ∣ v i \mu=\frac{1}{|\vec{v}|}\sum_{i=0}^{|\vec{v}|} v_i μ=∣v ∣1∑i=0∣v ∣vi, σ = 1 ∣ v ⃗ ∣ ∑ i = 0 ∣ v ⃗ ∣ ( v i − μ ) 2 \sigma=\frac{1}{|\vec{v}|}\sum_{i=0}^{|\vec{v}|}(v_i-\mu)^2 σ=∣v ∣1∑i=0∣v ∣(vi−μ)2),而 β , γ \beta,\gamma β,γ为可学习参数。这个过程可以看做,先把 v ⃗ \vec{v} v 的平均值、方差归一化到(0,1),然后缩放到 ( β , γ ) (\beta, \gamma) (β,γ)。当 ( β , γ ) = ( 0 , 1 ) (\beta, \gamma)=(0,1) (β,γ)=(0,1)时相当于制作归一化,而当 ( β , γ ) = ( μ , σ ) (\beta, \gamma)=(\mu,\sigma) (β,γ)=(μ,σ)时,相当于恒等变换------啥都没做。
RMS 是什么:它只缩放方差而不管平均值,也就是 R M S ( v ⃗ ) = γ v ⃗ σ RMS(\vec{v})=\gamma \frac{\vec{v}}{\sigma} RMS(v )=γσv它们的主要目的都是稳定梯度,防止梯度消失或者爆炸。在Transformer中,做LN的是每一个D维的特征向量。
由于它们区别其实不大,以下我们还是统称归一化层为LN。
这一个改动最大的区别就在于改变了残差连接和LN的组合顺序。假设 l l l层的输入是 l l l,输出是 F l ( x l ) F_l(x_l) Fl(xl):
- Post-LN (Attention is all you need 的原始设计): x l + 1 = L N ( x l + F l ( x l ) ) x_{l+1}=LN(x_l+F_l(x_l)) xl+1=LN(xl+Fl(xl))
- Pre-LN (现代主流设计): x l + 1 = x l + F l ( L N ( x l ) ) x_{l+1}=x_l +F_l(LN(x_l)) xl+1=xl+Fl(LN(xl))
残差连接(Residual Connection) 的感性理解
残差连接首创于CVPR2016的著名论文ResNet ( DeepResidual Learning for Image Recognition ),用于稳定深层网络的学习 。
假设我希望一层网络学习到一个函数 H ( x ) H(x) H(x),传统网络中,输入 x x x,会期望这层网络的输出是 H ( x ) H(x) H(x)。但事实往往不那么遵循美好的期望,尤其对于很深的网络来说,一旦一些早期的层学得不好、学歪了,就会非常影响整个模型的性能。
而ResNet期望这层网络的输出是 H ( x ) − x H(x)-x H(x)−x,即输入与输出的差值。在数学意义上这和直接学习 H ( x ) H(x) H(x)完全等价,但好处是,如果网络学不会, H ( x ) H(x) H(x)可以退化到近似为0,网络退化为恒等映射,而保证模型整体性能不会因为它这层没学会而下降,提供了一个保底。
也就是说,假设 F l ( x ) F_l(x) Fl(x)是ResNet第 l l l层的输出,则 l l l层传递给第 l + 1 l+1 l+1层的输入为 F l ( x ) + x F_l(x)+x Fl(x)+x(也就是期望的 H ( x ) H(x) H(x))。通过 + x +x +x这个恒等变换,网络早期层的梯度被较好地保留,从而在增加深度的情况下不至于导致早期层梯度丢失。
直觉上,我们可以感觉这是给模型一个"训得不好也有的退路",避免因为短时期内的训练进展不顺,导致无法返回正轨,从而提高了训练的稳定性。
从公式可以看出,Pre-LN对残差连接保留得更好,从直觉上来说,它的梯度和训练效果应该更加稳定,实际上也确实如此。
post-LN 中, ∂ x l + 1 ∂ x l = ∂ L N ∂ ( x l + f l ( x l ) ) ( I + ∂ f l ∂ x l ) \frac{\partial x_{l+1}}{\partial x_l}=\frac{\partial LN}{\partial {(x_l+f_l(x_l))}}(I+\frac{\partial f_l}{\partial x_l}) ∂xl∂xl+1=∂(xl+fl(xl))∂LN(I+∂xl∂fl),其中,对于前一项, J L N ( x ) J_{LN}(x) JLN(x)(雅可比矩阵)的谱范数(最大奇异值)是 O ( 1 σ ) O(\frac{1}{\sigma}) O(σ1)的, σ \sigma σ为向量的方差值。 J f J_f Jf在标准初始化(Xavier 或 Kaiming,反正都是参数初始化方法)下,范数是 O ( 1 d ) < O ( 1 ) O(\frac{1}{\sqrt{d}})<O(1) O(d 1)<O(1)的(d是特征值维度),所以后一项 I + ∂ f l ∂ x l I+\frac{\partial f_l}{\partial x_l} I+∂xl∂fl,的谱范数是 ∼ O ( 1 ) \sim O(1) ∼O(1)的。综上,post-LN的梯度是 O ( 1 σ ) O(\frac{1}{\sigma}) O(σ1)的。
虽然 O ( 1 σ ) O(\frac{1}{\sigma}) O(σ1) 期望上 ∼ O ( 1 ) \sim O(1) ∼O(1) ,但是在训练初期或者数值不稳定时, σ \sigma σ可能非常小,导致整个链式求导的谱范数出现指数级增长。因此,Post-LN非常需要warm-up 过程,即训练初期先使用小学习率训练,让激活值保持合适的方差。
而pre-LN 中, ∂ x l + 1 ∂ x l = I + ∂ f l ∂ L N ( x l ) ∂ L N ∂ x l \frac{\partial x_{l+1}}{\partial x_l}=I+\frac{\partial f_l}{\partial LN(x_l)}\frac{\partial LN}{\partial x_l} ∂xl∂xl+1=I+∂LN(xl)∂fl∂xl∂LN,因此后一项 ∂ f l ∂ L N ( x l ) ∂ L N ∂ x l \frac{\partial f_l}{\partial LN(x_l)}\frac{\partial LN}{\partial x_l} ∂LN(xl)∂fl∂xl∂LN的谱范数 ∼ O ( 1 σ d ) \sim O(\frac{1}{\sigma \sqrt{d}}) ∼O(σd 1),这一项小于1,故谱范数可以更稳定地保持在 O ( 1 ) O(1) O(1)。
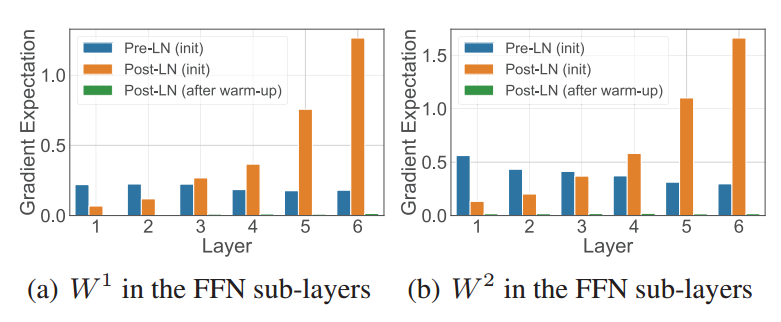
在On Layer Normalization in the Transformaer Architecture论文的实验中,测量了不同层数的参数矩阵的梯度范数,结果如下。可以看到Post-LN不做warm-up的情况下是很爆炸的,而Pre-LN相对更稳定:
这篇论文还证明了理论上pre-LN不需要warm-up,不过实操中,因为存在更多复杂的因素影响梯度,即使用的是pre-LN,一般也是需要进行warm-up来提升稳定性的。
KV-Cache优化
使用Transformer的时候,每生成一个新的token,就需要使用之前所有token的 K K K值和 V V V值来计算注意力分数,对这些KV值的缓存就叫KV-Cache。
KV-Cache成为了大模型计算的一个瓶颈问题。你可能会问,Attention的计算复杂度是 O ( N 2 D ) O(N^2D) O(N2D)的,而KV-Cache是 O ( N D ) O(ND) O(ND)的,为什么KV-Cache问题更大?这是因为,推理时,大模型是一个token接一个token生成的。如果只考虑单个token生成过程,此时只有一个查询( N Q = 1 N_Q=1 NQ=1),矩阵乘法的复杂度是 O ( N Q D K N K ) = O ( N D ) O(N_QD_KN_K)=O(ND) O(NQDKNK)=O(ND),而在这个过程中也需要读取整个 O ( N D ) O(ND) O(ND)的KV-Cache。
而现代GPU的算力与显存带宽的比值是多少?以 NVIDIA H100 为例,它的算力是约2000 T FLOPS(Floating Point Operations per Second,每秒浮点计算数),而显存带宽是3.35 TB/s。一个FP16是2字节,也就是它每秒只能读取约1.675 TB的浮点数。二者的比值约为1200!这意味着GPU 在等待数据从显存送过来的时间里,计算单元绝大部分时间是空闲的。显然,KV-Cache是一个比算力更严重的问题。
因此,工程师们想了各种策略来优化这个瓶颈。
那么Attention的 O ( N 2 D ) O(N^2D) O(N2D)计算复杂度问题怎么办?
工程上主要靠 提高硬件利用率 和 降低计算常数 的方式解决,此外也可能使用滑动窗口 之类的方法限定上下文长度。不要觉得降常数听起来没有降低复杂度炫酷,假如常数降低到原来的1/4,那么同计算量下,可以处理的序列长度 N N N就可以扩展到2倍了。想想看,让你用人类智慧把你的论文篇幅变成原来的2倍是多费劲的一件事!
有兴趣的话,可以关注FlashAttention系列,看看工程优化是如何实现的,我看不明白就先不看了:
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
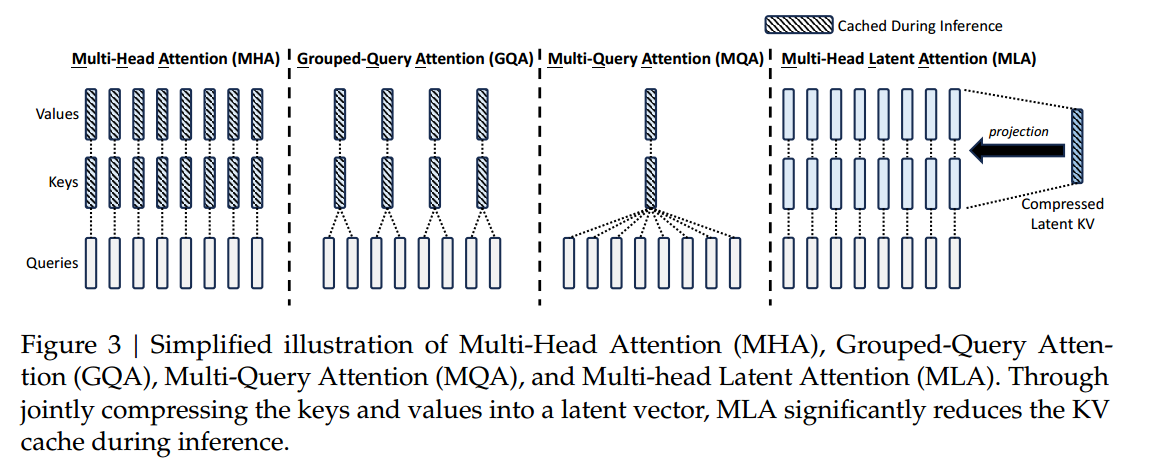
那要怎么减少KV-Cache使用呢?一个简单粗暴的思路是:减少K和V就可以了。因此人们开始使用 MQA(Multi-Qurey Attention,上图3) 。Attention有 h h h个头(上图为8),就有 h h h个Q,但是让它们共用一个K和V(长度还是 d / h d/h d/h, d d d为特征维度),这不就把Cache缩小到原来的 1 / h 1/h 1/h了?
也许你会问------那这样不会降低模型性能吗?那是当然会了,所以这是一种权衡的艺术。所以 GQA(Grouped-Query Attention,上图2) 就出现了,GQA的作者把它描述为 an interpolation(插值) between multi-head and multi-query attention 。具体地,GQA将查询头分为 g g g个组(上图为4组),每个组共用一组 K K K和 V V V,KV-Cache减少到原来的 g / h g/h g/h,性能牺牲也会相对更少。
而MLA(Multi-Head Latent Attention,上图4) ,则没有减少 K K K和 V V V的头数,而是在 K K K和 V V V的来源上做文章。具体地,它定义了一个"低秩联合压缩"(low-rank joint compression for keys and values ) C C C。其中 C C C的维度 d c < < d d_c << d dc<<d。原始的MHA,令 K t = W K t X , V t = W V t X K_t=W_{Kt}X,V_t=W_{Vt}X Kt=WKtX,Vt=WVtX,而MLA的思想是计算出 C = W C X C=W_C X C=WCX( d d d维降至 d c d_c dc维),它的K和V来自 K t = W K t C , V t = W V t C K_t=W_{Kt}C,V_t=W_{Vt}C Kt=WKtC,Vt=WVtC( d c d_c dc维到 d / h d/h d/h维),但是------ 它们不需要被显式计算出来。
一旦显式计算K和V,就又陷入了"要么做重复计算K和V牺牲计算量,要么缓存计算后的K和V牺牲KV-Cache"的圈套,和优化KV-Cache的初衷不符。好在, Q T K = X T W Q T W K C Q^TK=X^TW_Q^TW_KC QTK=XTWQTWKC,也即 W Q T W K W_Q^TW_K WQTWK可以视作一个矩阵(它们都是要学习的,并且永远一起出现,那么 W Q W_Q WQ和 W K W_K WK的具体值就不重要了,只有它们的乘积重要,可以说 " W K W_K WK被 W Q W_Q WQ吸收了" )。而 W V W_V WV的值也会被后续对Attention做的线性变换矩阵吸收,所以K和V都不需要被显式的计算出来,只有 C C C需要。
在考虑给 Q Q Q和 K K K加上位置编码的情况下,吸收性可能会失效。因此DeepSeek-V2的报告提到,他们使用了两套Attention:一套为内容分数,和位置编码无关。一套为位置分数,单独创建一套维度很低的、跨所有头共享的Key和Query,专门用来应用位置编码。
MoE
MoE(Mixture of Experts) 替代的是原始Transformer中的FFN部分。原始Transformer的FFN存在信息稀疏的问题,可能只有少数参数是有效的。并且,规模扩张的成本较大。
而MoE的主要思路是:将原本的一个整体的FFN,拆分成一个门控系统+多个专家网络。对于每一个新到的token,由门控网络将其分配给特定的几个专家进行处理+结果聚合。感性地理解,就好像做一个翻译任务,专家1特别擅长医学术语,专家2特别擅长法律术语。如果到来的token和医学有关,就可以将其分配给专家1,如果和法律有关,则交由专家2处理。
这只是个比方,实际上训出来的MoE有没有这样直观的分工效果,属于可解释性范畴。
因此,使用MoE的模型,拥有大量的参数存储,但只有少量在推理时处于活跃状态。比如kimi-2.6模型,有1T参数存储,但是激活只有32B。
1T= 10 1 2 10^12 1012,1B= 10 9 10^9 109
Google团队在2020年发表的论文GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding,通过MoE将模型扩展到了600B。论文中关于MoE的示意图如下:
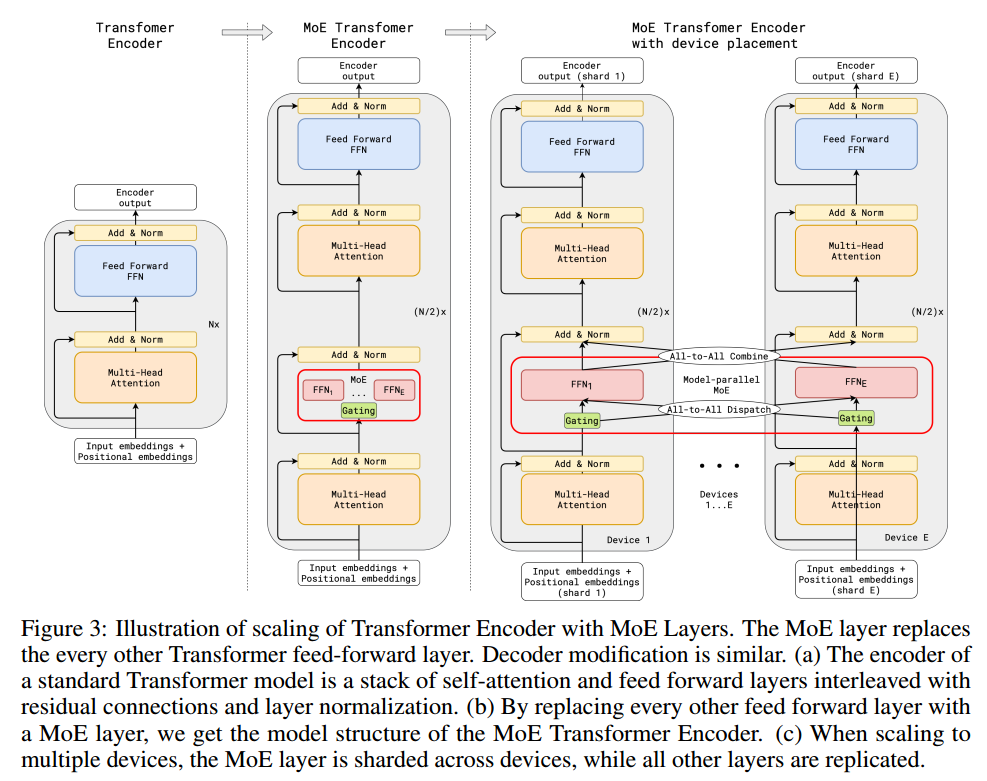
假设有 E E E个专家,则MoE有 E E E个独立的FFN网络和一个负责专家分配的Gating。如上图所示,不同的专家可以被部署在不同的设备,完全独立,无需彼此拷贝,这样能大大增加训练过程中的并发性。
不过,从直观上也很容易意识到一个问题:各个专家之间的"工作量"是不是均等的呢?会不会出现其实只有某几个专家在猛猛干活,其他专家都在旁边叉腰看戏的情况呢?
答案是------当然是会的!(图源知乎)

Gating一般来说是通过Sigmoid,就token和每个专家的相关性计算出一个概率分数,然后选择最大的一个或多个专家进行分配。这其实天然导致一个问题:训练阶段一开始被训得能力比较强的专家,会不断不断地被派新活,而起跑落后的专家则压根没怎么得到训练!因此,Gating的设计至关重要,它就是MoE的大老板,决定了对员工的工作安排是否科学合理。

以上是GShard的gating算法,它的大致思路是:
- 通过 g S , E = s o f t m a x ( W g x S ) g_{S,E}=softmax(W_g x_S) gS,E=softmax(WgxS)计算初始专家分配分数。
- 通过专家容量(expert capacity)设置专家被分配的token上限,缓解分配不均的问题。
- 通过auxillary loss的反向传播和梯度下降来优化Gating。
- 每个token最多路由给两个专家。
上文的代码很长,主要是因为每个token最多路由给两个专家这件事。我们先考虑只能路由给一个专家的情况。
假设一组有 S S S个token,输入记作 x S x_S xS。需要得到的输出,是auxillary loss,和最终的路由向量 G \mathcal G G( M o E ( x S ) = ∑ e = 1 E G S , e F F N e ( x S ) MoE(x_S)=\sum_{e=1}^{E} \mathcal G_{S,e}FFN_e(x_S) MoE(xS)=∑e=1EGS,eFFNe(xS))。并且它还设置了一个 O ( S / E ) O(S/E) O(S/E)级别的容量 C C C,即每个专家最终被分配的token数上限。
首先, g S , E = s o f t m a x ( W g x S ) g_{S,E}=softmax(W_g x_S) gS,E=softmax(WgxS)计算出初始专家分数后,对于每一个token s s s,我们选出 g s , e g_{s,e} gs,e值最高的专家 e = e 1 e=e_1 e=e1。假设 e 1 e_1 e1被分配的token数不足 C C C,则 G s , e 1 + = 1 \mathcal G_{s,e_1}+=1 Gs,e1+=1,否则, G s \mathcal G_s Gs退化为0向量,这个token会经残差连接直接传递到下一层。
接下来进行auxillary loss的计算。设 c e c_e ce表示专家 e e e被"试图"分配的token数(即以它作为 g g g分数最高的专家的token数,这个值可以超过 C C C)。已知 ∑ e = 1 E c e S = 1 \sum_{e=1}^{E}\frac{c_e}{S}=1 ∑e=1ESce=1,且我们希望 c e S \frac{c_e}{S} Sce越相近越好。根据高中学的均值不等式 ,可以想到将 1 E ∑ e = 1 E ( c e S ) 2 \frac{1}{E} \sum_{e=1}^E (\frac{c_e}{S})^2 E1∑e=1E(Sce)2优化为最小值是一个好思路。不过这有一个问题: c e c_e ce的计算方式是求top-k,top-k这个函数不可微,求不了导,也没法做反向传播。
一个解决方案是,令 m e = 1 S ∑ s = 1 S g s , e m_e=\frac{1}{S}\sum_{s=1}^S g_{s,e} me=S1∑s=1Sgs,e,然后用 ∑ e = 1 E ( c e S ) m e \sum_{e=1}^E (\frac{c_e}{S})m_e ∑e=1E(Sce)me做loss值(其中 c e c_e ce视作常数,不参与反向传播)。由于 g g g是完全用softmax计算得出的,所以 m e m_e me是可以求导的。通过优化这个loss,可以让"专家分配"变得平均。
最后,再把分配从top-1扩展到top-k(GShard里k=2)。除了top-1以外的分配不参与auxillary loss的构建,故主要变化就是, G s , e 1 \mathcal G_{s,e_1} Gs,e1增加的值从1变成了 g 1 g 1 + g 2 \frac{g_1}{g_1+g_2} g1+g2g1。此外,因为有时 g 2 g_2 g2的值太小了,分配给 e 2 e_2 e2这个行为显得不是很有必要,故算法里添加了一个取uniform(0,1)的随机数 r n d rnd rnd,只有在 2 g 2 > r n d 2g_2>rnd 2g2>rnd的情况下才进行第二次路由,否则只进行一次路由这样的操作。
那么这些就是GShard的gating过程啦。它对专家分配不均的过程做了一些考虑,但是并没有完美的解决。如何让专家工作量均衡,至今也是MoE相关优化中的重点讨论问题。
而DeepSeek-v2提出的DeepSeekMoE,相较于GShard这样的框架主要做了如下改进:
- 细粒度专家分割(Fine-Grained Expert Segmentation):在总参数量不变的情况下增加了专家的数量。
- 共享专家隔离(Shared Expert Isolation):设置一部分专家作为总是被激活的"共享专家",就好像翻译问题除了领域专业词汇知识,还有很多通用知识一样。共享专家减少了专家之间的知识冗余,使得非共享专家(称为路由专家)可以专注于更特定的领域。
总结
本文通过DeepSeek-V2的技术报告,探讨了现代LLM架构和传统Transformer的区别。下一期还是没想好写什么,不过应该会开始涉及训练相关。