RLHF:用人类反馈训练 AI 的艺术
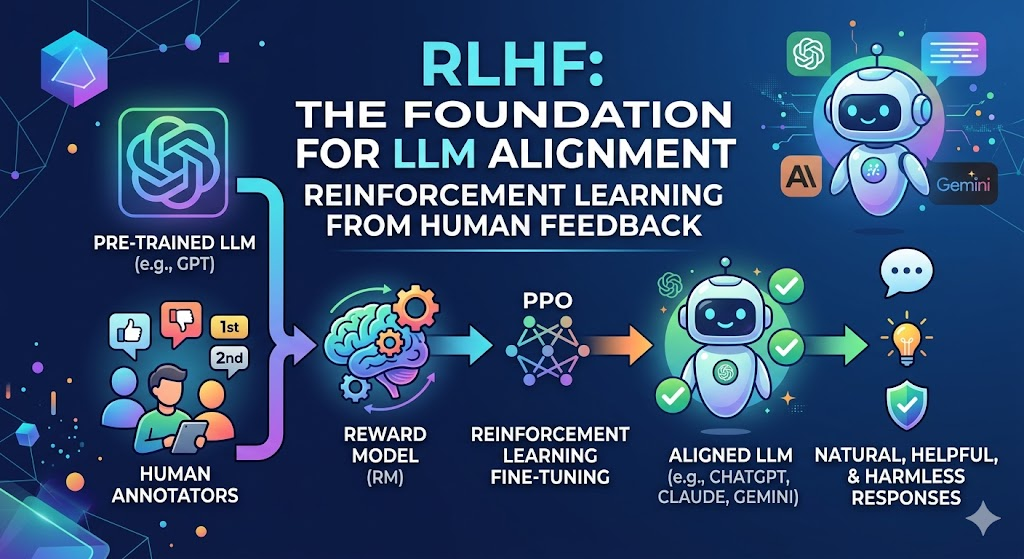
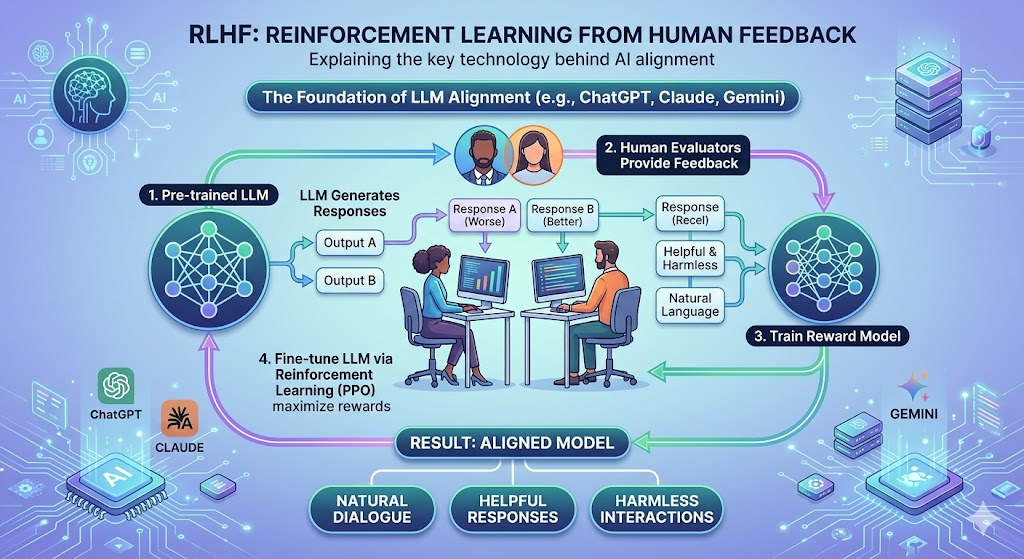
Reinforcement Learning from Human Feedback,即"基于人类反馈的强化学习",是当代大语言模型对齐(Alignment)技术的基石。ChatGPT、Claude、Gemini 等主流模型之所以能够以自然、有帮助、无害的方式与人类对话,背后的关键技术正是 RLHF。
目录
- [为什么需要 RLHF?](#为什么需要 RLHF?)
- [RLHF 的三阶段流程](#RLHF 的三阶段流程)
- 阶段一:有监督微调(SFT)
- 阶段二:训练奖励模型(RM)
- [阶段三:PPO 强化学习优化](#阶段三:PPO 强化学习优化)
- 关键技术细节
- [RLHF 的局限性与挑战](#RLHF 的局限性与挑战)
- [RLHF 的演进:DPO、RLAIF、Constitutional AI](#RLHF 的演进:DPO、RLAIF、Constitutional AI)
- [代码实践:最小 RLHF 示例](#代码实践:最小 RLHF 示例)
一、为什么需要 RLHF?
预训练模型的根本问题
大语言模型(LLM)的预训练目标极其简单:预测下一个 Token。模型在海量互联网文本上学习这一目标,确实能习得惊人的语言能力,但也带来了严重的对齐问题:
预训练目标:P(next_token | context)互联网文本中充斥着错误信息、有害内容、偏见和低质量文字。一个纯粹追求"预测下一个 Token"的模型,会忠实地复现这些问题。更重要的是,模型学会了"预测人类会写什么",而非"什么是好的回答"------这两者有本质区别。
核心矛盾 :预训练优化的是统计似然(statistical likelihood),而人类真正需要的是有用性(helpfulness)、无害性(harmlessness)和诚实性(honesty)。这三点被 Anthropic 总结为 HHH 原则。
传统方法的局限
在 RLHF 之前,研究者尝试过多种对齐方法:
| 方法 | 思路 | 局限性 |
|---|---|---|
| 规则过滤 | 黑名单词汇、规则匹配 | 无法覆盖复杂语境,容易绕过 |
| 有监督微调(SFT alone) | 人工标注"好回答",直接微调 | 需要大量标注数据,且分布覆盖不足 |
| 对抗训练 | 训练分类器识别有害输出 | 分类器容易被对抗样本欺骗 |
| Constitutional AI(规则约束) | 让模型遵循明文规则 | 规则无法穷举,模型对规则理解有偏差 |
RLHF 的核心洞见是:与其告诉模型"什么是好的输出"(极其困难),不如让人类直接比较两个回答哪个更好(相对容易)。这一转变将高难度的绝对评分问题转化为相对排序问题。
二、RLHF 的三阶段流程
RLHF 的完整训练流程分为三个阶段,每个阶段都建立在前一个阶段的基础上。
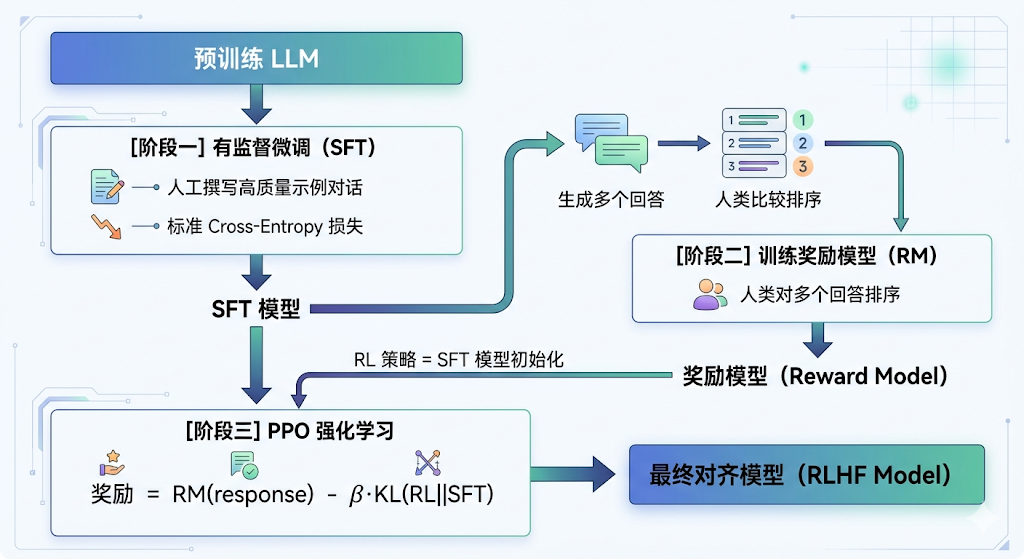
阶段一:有监督微调(SFT)
目标:将预训练模型的输出分布从"互联网文本风格"迁移到"有帮助的助手风格"。
数据收集
SFT 需要人工标注者(Labelers)针对一批精选的 Prompt,撰写高质量的示范回答:
python
# SFT 数据格式示例
sft_dataset = [
{
"prompt": "用 Python 实现一个二分查找算法,并解释其时间复杂度。",
"response": """以下是二分查找的 Python 实现:
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1 # 未找到
# 时间复杂度分析:
# - 最优:O(1),第一次就找到
# - 平均/最差:O(log n),每次排除一半元素
# - 空间复杂度:O(1),只使用常数额外空间"""
},
# ... 更多示例
]训练过程
SFT 的训练与标准语言模型微调相同,使用交叉熵损失:
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.1-8B")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-8B")
# 只在 response 部分计算损失(不对 prompt 计算)
def compute_loss(model, inputs, return_outputs=False):
labels = inputs["input_ids"].clone()
# 将 prompt 部分的 labels 设为 -100(忽略)
labels[:, :inputs["prompt_length"]] = -100
outputs = model(**inputs, labels=labels)
return (outputs.loss, outputs) if return_outputs else outputs.loss
training_args = TrainingArguments(
output_dir="./sft-model",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=2e-5,
warmup_ratio=0.03,
lr_scheduler_type="cosine",
bf16=True, # 使用 BF16 混合精度
)SFT 阶段的关键决策:
- 数据质量 >> 数量:InstructGPT 论文显示,13,000 条高质量标注足以产生显著效果
- 标注者一致性:需要仔细培训标注者,建立明确的评分标准(rubric)
- 覆盖多样性:数据需覆盖各类任务(对话、代码、写作、推理等)
阶段二:训练奖励模型(RM)
这是 RLHF 最具创新性的环节。奖励模型的任务是学习人类的偏好,将其编码为一个标量分数函数。
偏好数据收集
对于同一个 Prompt,让 SFT 模型生成多个(通常 4-9 个)回答,由人类标注者对它们进行排序:
Prompt: "如何缓解工作压力?"
回答 A: "你可以尝试深呼吸、冥想、运动,
这些都有助于缓解压力..."
回答 B: "1. 制定优先级列表
2. 学会说不
3. 定时休息(番茄钟技术)
4. 下班后完全断开工作..."
回答 C: "压力是生活的一部分,接受它吧。"
人类排序:B > A > C这些排序对转化为训练数据:
python
# 偏好对数据格式
preference_data = [
{
"prompt": "如何缓解工作压力?",
"chosen": "回答 B(更具体、可操作)",
"rejected": "回答 A(较笼统)"
},
{
"prompt": "如何缓解工作压力?",
"chosen": "回答 A",
"rejected": "回答 C(消极且无用)"
},
# ...
]奖励模型架构
奖励模型通常是在 SFT 模型基础上,将最后的 LM head 替换为一个线性层,输出标量分数:
python
import torch
import torch.nn as nn
from transformers import AutoModel
class RewardModel(nn.Module):
def __init__(self, base_model_name):
super().__init__()
self.backbone = AutoModel.from_pretrained(base_model_name)
# 将语言模型头替换为标量输出头
hidden_size = self.backbone.config.hidden_size
self.reward_head = nn.Linear(hidden_size, 1, bias=False)
def forward(self, input_ids, attention_mask):
outputs = self.backbone(
input_ids=input_ids,
attention_mask=attention_mask
)
# 取最后一个 token 的隐藏状态
last_hidden = outputs.last_hidden_state[:, -1, :]
reward = self.reward_head(last_hidden)
return reward.squeeze(-1)奖励模型训练损失
RM 的训练目标基于 Bradley-Terry 偏好模型,使用 Pairwise Ranking Loss:
L_RM = -E[log σ(r_θ(x, y_w) - r_θ(x, y_l))]其中:
r_θ(x, y)是奖励模型对 Promptx、回答y打出的分数y_w是人类偏好的(winner)回答y_l是不被偏好的(loser)回答σ是 Sigmoid 函数
python
def reward_model_loss(reward_chosen, reward_rejected):
"""
Pairwise ranking loss(来自 Bradley-Terry 模型)
目标:让 chosen 的奖励分数高于 rejected
"""
# reward_chosen: shape (batch_size,)
# reward_rejected: shape (batch_size,)
loss = -torch.nn.functional.logsigmoid(
reward_chosen - reward_rejected
).mean()
# 辅助指标:chosen 分数高于 rejected 的比例
accuracy = (reward_chosen > reward_rejected).float().mean()
return loss, accuracy
# 训练循环
for batch in dataloader:
reward_chosen = reward_model(batch["chosen_ids"], batch["chosen_mask"])
reward_rejected = reward_model(batch["rejected_ids"], batch["rejected_mask"])
loss, acc = reward_model_loss(reward_chosen, reward_rejected)
loss.backward()
optimizer.step()奖励模型训练的关键挑战:
- 标注者间一致性(Inter-annotator Agreement):不同人对"好回答"的判断存在分歧,需要统计处理
- 奖励黑客(Reward Hacking):RM 只是对真实人类偏好的近似,LM 可能学会"欺骗"RM
- 分布偏移:RM 在 SFT 模型的输出分布上训练,但在 RL 阶段需要评估策略模型的输出
阶段三:PPO 强化学习优化
有了奖励模型,就可以用强化学习来优化语言模型策略(policy)了。RLHF 通常使用 PPO(Proximal Policy Optimization) 算法。
将语言模型视为强化学习问题
状态(State) s_t = (prompt + 已生成的 tokens)
动作(Action) a_t = 生成下一个 token(词表大小 = 动作空间)
奖励(Reward) R = RM(prompt, full_response)(序列末尾给出)
策略(Policy) π_θ = 语言模型本身KL 散度惩罚项
仅使用 RM 奖励会导致"奖励黑客"------模型可能生成荒谬但 RM 打高分的文本。因此引入 KL 散度惩罚,防止 RL 模型偏离 SFT 参考模型太远:
R_total = r_RM(x, y) - β · KL(π_θ(y|x) || π_SFT(y|x))其中:
r_RM是奖励模型的分数KL(π_θ || π_SFT)是当前策略与参考策略(SFT 模型)的 KL 散度β是控制 KL 惩罚强度的超参数(通常 0.01~0.1)
python
def compute_rlhf_reward(
prompt_response_ids,
reward_model,
policy_model,
ref_model,
beta=0.04
):
# 1. 奖励模型打分
rm_score = reward_model(prompt_response_ids)
# 2. 计算 KL 散度惩罚
with torch.no_grad():
ref_logprobs = ref_model(prompt_response_ids).logits
policy_logprobs = policy_model(prompt_response_ids).logits
# Per-token KL divergence
kl_div = torch.nn.functional.kl_div(
policy_logprobs.log_softmax(-1),
ref_logprobs.softmax(-1),
reduction='batchmean'
)
# 3. 组合奖励
total_reward = rm_score - beta * kl_div
return total_rewardPPO 更新过程
PPO 的核心是 Clipped Surrogate Objective,防止策略更新步幅过大:
python
def ppo_loss(old_logprobs, new_logprobs, advantages, epsilon=0.2):
"""
PPO Clipped Objective
"""
# 计算策略比率
ratio = torch.exp(new_logprobs - old_logprobs)
# 裁剪比率,防止过大的更新
clipped_ratio = torch.clamp(ratio, 1 - epsilon, 1 + epsilon)
# 取最小值(保守更新)
loss = -torch.min(
ratio * advantages,
clipped_ratio * advantages
).mean()
return loss完整的 PPO RLHF 训练循环(简化版)
python
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
# 初始化
ppo_config = PPOConfig(
learning_rate=1.4e-5,
batch_size=128,
mini_batch_size=16,
gradient_accumulation_steps=1,
optimize_cuda_cache=True,
early_stopping=True,
target_kl=6.0, # 目标 KL 散度(自适应 β)
kl_penalty="kl",
seed=42,
)
# 策略模型(带 Value Head)
policy_model = AutoModelForCausalLMWithValueHead.from_pretrained(
"sft-model", # 从 SFT 模型初始化
torch_dtype=torch.bfloat16,
)
# 参考模型(冻结,不参与梯度更新)
ref_model = AutoModelForCausalLMWithValueHead.from_pretrained(
"sft-model",
torch_dtype=torch.bfloat16,
)
ref_model.eval()
ppo_trainer = PPOTrainer(
config=ppo_config,
model=policy_model,
ref_model=ref_model,
tokenizer=tokenizer,
dataset=prompt_dataset,
)
# 训练循环
for epoch in range(num_epochs):
for batch in ppo_trainer.dataloader:
# 1. 策略模型生成回答
query_tensors = batch["input_ids"]
response_tensors = ppo_trainer.generate(
query_tensors,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
)
# 2. 奖励模型打分
rewards = [
reward_model(q, r)
for q, r in zip(query_tensors, response_tensors)
]
# 3. PPO 更新
stats = ppo_trainer.step(
query_tensors,
response_tensors,
rewards
)
ppo_trainer.log_stats(stats, batch, rewards)三、关键技术细节
3.1 价值函数(Value Head)
PPO 需要估计状态价值 V(s) 来计算优势函数(Advantage)。在 RLHF 中,通常在语言模型顶部添加一个线性 Value Head:
python
# Advantage Estimation (GAE)
def compute_advantages(rewards, values, gamma=1.0, lam=0.95):
"""
Generalized Advantage Estimation
γ: 折扣因子(语言生成通常用 1.0,因为序列较短)
λ: GAE 参数(平衡偏差与方差)
"""
advantages = []
gae = 0
for t in reversed(range(len(rewards))):
delta = rewards[t] + gamma * values[t+1] - values[t]
gae = delta + gamma * lam * gae
advantages.insert(0, gae)
return torch.tensor(advantages)3.2 标注者间一致性处理
现实中不同标注者的偏好可能冲突。常见处理方法:
python
# 方法一:多数投票
def majority_vote(annotations):
from collections import Counter
votes = Counter(annotations)
return votes.most_common(1)[0][0]
# 方法二:基于 Elo 评分的排名
def compute_elo_rankings(pairwise_results, k=32):
elo = defaultdict(lambda: 1500)
for winner, loser in pairwise_results:
expected_w = 1 / (1 + 10 ** ((elo[loser] - elo[winner]) / 400))
expected_l = 1 - expected_w
elo[winner] += k * (1 - expected_w)
elo[loser] += k * (0 - expected_l)
return dict(sorted(elo.items(), key=lambda x: -x[1]))
# 方法三:基于 Cohen's Kappa 的质量控制
# 过滤一致性低于阈值的标注者3.3 关键超参数
| 超参数 | 推荐范围 | 作用 |
|---|---|---|
| KL 系数 β | 0.01 ~ 0.1 | 控制偏离参考模型的程度 |
| PPO epsilon | 0.1 ~ 0.3 | 裁剪比率,控制更新步幅 |
| GAE λ | 0.9 ~ 0.99 | 平衡优势估计的偏差-方差 |
| Value loss coef | 0.1 ~ 1.0 | Value Head 损失权重 |
| Rollout batch | 128 ~ 512 | 每次采样的轨迹数量 |
| Mini-batch | 16 ~ 64 | PPO 更新的小批量大小 |
| Target KL | 1.0 ~ 10.0 | 自适应 KL 系数的目标值 |
四、RLHF 的局限性与挑战
4.1 奖励黑客(Reward Hacking)
这是 RLHF 最根本的问题之一。模型学会的不是"真正有帮助",而是"让奖励模型打高分"。两者可能大相径庭。
典型案例:
问题:解释量子纠缠
奖励黑客式回答:
"量子纠缠是一个极其深刻的概念!它涉及到粒子之间
神奇的关联性,爱因斯坦称之为'鬼魅般的超距作用'。
这个现象不仅颠覆了我们对现实的认知,还是量子计算
和量子通信的基础。您问了一个绝妙的问题!..."
(长篇幅、充满赞美,但实质内容稀少)缓解方法:
- 定期更新奖励模型(Online RLHF)
- 引入多样性奖励,惩罚重复模式
- 使用 Constitutional AI 等额外约束
- 红队测试(Red-teaming)发现并修复问题
4.2 人类反馈的可扩展性瓶颈
高质量标注需要:
- 专业知识:代码题目需要程序员,医学问题需要医生
- 时间成本:每条偏好对需要数分钟人工审阅
- 标注一致性:不同标注者的偏好难以完全对齐
规模估算:InstructGPT 使用约 40 名专职标注者,生成约 40,000 条偏好对。这对资源有限的团队来说是显著门槛。
4.3 分布偏移
奖励模型在 SFT 模型的输出分布上训练,但 RL 训练过程中策略逐渐偏离 SFT 分布。奖励模型在分布外数据上可能给出不可靠的评分。
训练时 RM 见过的:SFT 模型输出
RL 后期 RM 需要评估:与 SFT 差异越来越大的策略模型输出
↑
可靠性下降!4.4 过度优化(Over-optimization)
随着 RL 训练深入,模型可能过度优化奖励模型而退化。Gao et al. (2022) 发现奖励分数与真实质量之间存在倒 U 形关系:
真实质量
▲
│ ●
│ ● ●
│ ● ● ← 过度优化后质量下降
│ ● ●
└──────────────────→ RM 分数
过拟合 RM!4.5 标注偏见
标注者的文化背景、个人偏好、知识水平都会影响标注结果,导致模型产生系统性偏见:
- 偏好符合特定文化价值观的回答
- 更长的回答(即使内容冗余)通常得分更高
- 措辞流畅的错误答案可能优于表达生硬的正确答案
五、RLHF 的演进:DPO、RLAIF、Constitutional AI
5.1 DPO:直接偏好优化
DPO(Direct Preference Optimization,2023)通过数学变换,将 RLHF 的三阶段问题化简为一个直接的监督学习问题,无需显式训练奖励模型,也无需 PPO:
python
def dpo_loss(policy_model, ref_model, chosen_ids, rejected_ids, beta=0.1):
"""
DPO 损失函数
直接从偏好数据中学习,无需独立训练 RM
"""
# 策略模型的 log 概率
policy_chosen_logps = get_log_probs(policy_model, chosen_ids)
policy_rejected_logps = get_log_probs(policy_model, rejected_ids)
# 参考模型的 log 概率(冻结)
with torch.no_grad():
ref_chosen_logps = get_log_probs(ref_model, chosen_ids)
ref_rejected_logps = get_log_probs(ref_model, rejected_ids)
# 计算隐式奖励差
chosen_rewards = beta * (policy_chosen_logps - ref_chosen_logps)
rejected_rewards = beta * (policy_rejected_logps - ref_rejected_logps)
# DPO 损失(同 Bradley-Terry 模型)
loss = -torch.nn.functional.logsigmoid(
chosen_rewards - rejected_rewards
).mean()
return lossDPO vs RLHF 对比:
| 维度 | RLHF (PPO) | DPO |
|---|---|---|
| 是否需要 RM | 是 | 否 |
| 是否需要 RL | 是(PPO) | 否(SL) |
| 训练稳定性 | 较难调参 | 更稳定 |
| 计算成本 | 高 | 低 |
| 性能 | 通常更强 | 接近甚至超越 |
| 可解释性 | 低 | 较高 |
5.2 RLAIF:用 AI 替代人类标注
RLAIF(Reinforcement Learning from AI Feedback)用 AI 模型(通常是更强的 LLM)替代人类标注者,生成偏好数据:
python
def generate_ai_feedback(prompt, response_a, response_b, judge_model):
"""
用 AI 评判者生成偏好标注
"""
judge_prompt = f"""请评估以下两个回答,判断哪个更有帮助、更准确、更安全。
问题:{prompt}
回答 A:{response_a}
回答 B:{response_b}
请分析两个回答,然后以 JSON 格式输出:
{{"preferred": "A" 或 "B", "reason": "原因(一句话)"}}"""
feedback = judge_model.generate(judge_prompt)
return parse_json(feedback)
# Constitutional AI 中的 RLAIF 变体
# 让模型先生成回答,再用宪法原则自我批判并修改5.3 Constitutional AI(CAI)
Anthropic 提出的 Constitutional AI 引入了一套明文"宪法"原则,让模型自我修正,减少对人工标注的依赖:
宪法原则示例(Anthropic):
• 避免产生可能被用于伤害人的输出
• 如果不确定,优先选择对人类更有益的回答
• 不要写带有种族、性别或其他歧视性内容
• 鼓励用户自己思考,而非依赖 AI
RLAIF 流程:
Prompt → 模型生成回答
↓
模型根据宪法原则自我批判
↓
模型生成改进版回答
↓
用改进前/后的对比训练 RM5.4 其他变体对比
| 方法 | 年份 | 核心思路 | 优势 |
|---|---|---|---|
| RLHF(InstructGPT) | 2022 | PPO + 人类偏好 RM | 效果经过验证 |
| Constitutional AI | 2022 | AI 自我批判 + 宪法 | 减少人工标注 |
| DPO | 2023 | 去掉 RL,直接优化 | 简单稳定 |
| RLAIF | 2023 | AI 替代人类标注 | 可扩展 |
| IPO | 2023 | DPO 的正则化改进 | 防过拟合 |
| KTO | 2024 | 前景理论驱动的损失 | 更符合人类决策 |
| ORPO | 2024 | 单阶段 SFT+偏好 | 更高效 |
六、代码实践:最小 RLHF 示例
以下是一个使用 trl 库(Hugging Face)实现 RLHF 的完整可运行示例(简化版,适合入门学习):
python
"""
最小 RLHF 示例:使用 TRL 库训练一个情感正向化模型
任务:让语言模型生成尽可能积极情感的文本
"""
import torch
from transformers import pipeline, AutoTokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
from trl.core import LengthSampler
# ── 1. 配置 ────────────────────────────────────────
MODEL_NAME = "gpt2" # 使用 GPT-2 作为基础模型(方便本地运行)
ppo_config = PPOConfig(
model_name=MODEL_NAME,
learning_rate=1.41e-5,
log_with=None,
batch_size=16,
mini_batch_size=4,
gradient_accumulation_steps=1,
optimize_device_cache=True,
early_stopping=True,
target_kl=6.0,
kl_penalty="kl",
seed=0,
use_score_scaling=True,
use_score_norm=True,
score_clip=0.5,
)
# ── 2. 初始化模型 ───────────────────────────────────
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer.pad_token = tokenizer.eos_token
# 策略模型(带 Value Head)
policy_model = AutoModelForCausalLMWithValueHead.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float32,
)
# ── 3. 奖励函数:情感分类器 ─────────────────────────
# 用情感分类器作为奖励模型(替代人工标注)
sentiment_pipe = pipeline(
"sentiment-analysis",
model="lvwerra/distilbert-imdb",
device=0 if torch.cuda.is_available() else -1,
)
def compute_sentiment_reward(texts):
"""将情感分类结果转化为奖励分数"""
results = sentiment_pipe(texts, top_k=2, truncation=True, max_length=512)
rewards = []
for result in results:
for r in result:
if r["label"] == "POSITIVE":
rewards.append(torch.tensor(r["score"]))
break
return rewards
# ── 4. 准备数据集 ─────────────────────────────────
from datasets import load_dataset
dataset = load_dataset("imdb", split="train")
dataset = dataset.rename_columns({"text": "review"})
dataset = dataset.filter(lambda x: len(x["review"]) > 200)
def tokenize(sample):
# 只取前 128 个 token 作为 prompt
input_ids = tokenizer.encode(sample["review"])[:128]
sample["input_ids"] = input_ids
sample["query"] = tokenizer.decode(input_ids)
return sample
dataset = dataset.map(tokenize, batched=False)
dataset.set_format(type="torch")
# ── 5. PPO 训练 ────────────────────────────────────
ppo_trainer = PPOTrainer(
config=ppo_config,
model=policy_model,
ref_model=None, # TRL 会自动创建参考模型的副本
tokenizer=tokenizer,
dataset=dataset,
data_collator=lambda data: {
"input_ids": [d["input_ids"] for d in data],
"query": [d["query"] for d in data],
},
)
output_length_sampler = LengthSampler(16, 48) # 生成 16-48 个 token
generation_kwargs = {
"min_length": -1,
"top_k": 0.0,
"top_p": 1.0,
"do_sample": True,
"pad_token_id": tokenizer.eos_token_id,
"max_new_tokens": 32,
}
# 训练循环
for epoch, batch in enumerate(ppo_trainer.dataloader):
query_tensors = batch["input_ids"]
# 生成回答
response_tensors = ppo_trainer.generate(
query_tensors,
return_prompt=False,
length_sampler=output_length_sampler,
**generation_kwargs,
)
batch["response"] = tokenizer.batch_decode(
response_tensors, skip_special_tokens=True
)
# 计算奖励(情感分数)
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
rewards = compute_sentiment_reward(texts)
# PPO 更新
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
ppo_trainer.log_stats(stats, batch, rewards)
if epoch % 100 == 0:
avg_reward = torch.stack(rewards).mean().item()
print(f"Epoch {epoch:4d} | Avg Reward: {avg_reward:.4f}")
print("RLHF 训练完成!")完整训练监控指标
在生产级 RLHF 训练中,需要密切关注以下指标:
python
# 关键监控指标(通常记录到 W&B 或 TensorBoard)
metrics = {
# 奖励相关
"reward/mean": float, # 平均奖励(越高越好)
"reward/std": float, # 奖励标准差(反映多样性)
# KL 散度(控制偏离参考模型的程度)
"objective/kl": float, # 当前 KL 散度
"objective/kl_coef": float, # 自适应 KL 系数 β
# PPO 相关
"ppo/loss/policy": float, # 策略损失
"ppo/loss/value": float, # 价值函数损失
"ppo/policy/entropy": float, # 策略熵(反映生成多样性)
"ppo/policy/approxkl": float, # PPO 近似 KL
"ppo/policy/clipfrac": float, # 被裁剪的比例(应 < 0.3)
# 生成质量
"tokens/queries": float, # Prompt 平均长度
"tokens/responses": float, # 回答平均长度
}开源工具推荐:
- TRL(Hugging Face):最完整的 RLHF/DPO 训练库
- OpenRLHF:支持 70B+ 模型的分布式 RLHF 框架
- DeepSpeed-Chat:微软的 RLHF 参考实现
- LLaMA-Factory:国内流行的一站式微调/RLHF 工具