本博客单纯作为我想面试大模型实习岗进行临时抱佛脚的学习,如果有错误欢迎在评论区指正,我会修改的。
引言:为什么推理优化是 LLM 时代的"黄金技能"?
大语言模型(LLM)的参数量动辄百亿、千亿。在学术界,我们关注如何把模型训练出来;但在工业界,真正的挑战在于如何把模型便宜、高效地部署上线。
当我们尝试运行一个 LLM 时,通常会遇到两座大山:
-
Memory Wall(内存墙):大模型的自回归生成特性产生了庞大的 KV Cache,极易导致显存溢出(OOM)。GPU 的高带宽内存(HBM)容量成为了最大瓶颈。
-
Compute-Bound vs. Memory-Bound:在 Prefill(预填充)阶段,计算是瓶颈;但在 Decode(解码)阶段,频繁的访存使得 GPU 的算力根本吃不满,沦为 Memory-Bound(访存瓶颈)。
核心技术一:显存优化(让 GPU 装下更多请求)
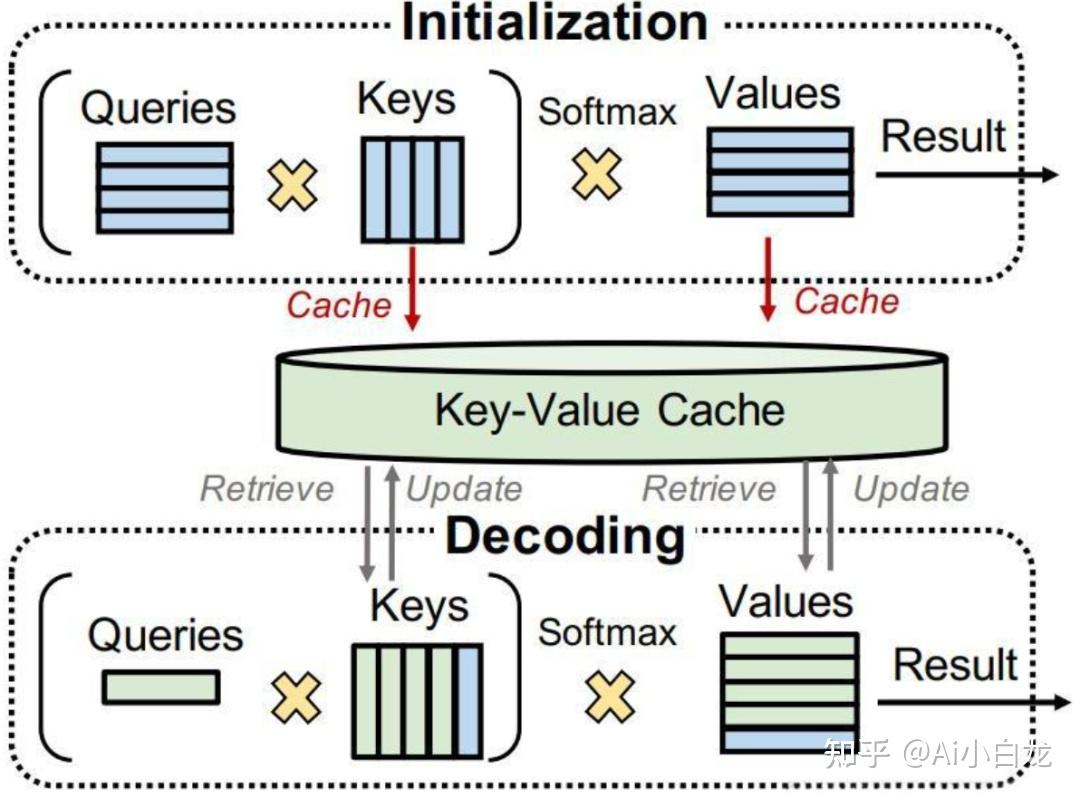
1. 空间换时间的艺术:KV Cache
LLM 生成文本是一个词一个词往外蹦的(Autoregressive)。为了生成第 N+1 个词,模型需要前面 N 个词的上下文。如果不做优化,每次生成新词都要把前面的词重新算一遍 Attention,计算复杂度是 O(N^2)。
KV Cache 的做法是:把历史 Token 的 Key 和 Value 矩阵缓存在显存中。新词只需要计算自己的 Query,并与缓存的 K、V 交互即可。计算复杂度瞬间降维到 O(N)。
痛点:算力省下来了,但随着并发请求增多,KV Cache 会占用海量显存。
2. 操作系统降维打击:PagedAttention (vLLM核心)
传统的 KV Cache 分配是连续的,假设系统预设最大长度为 2048,哪怕用户只生成了 10 个词,也会占用 2048 的显存空间,导致极大的内部碎片。
PagedAttention 巧妙地借用了操作系统中的"虚拟内存分页"思想:
-
将 KV Cache 切分成固定大小的 Block(块)。
-
逻辑上连续的 Cache,在物理显存上是不连续的。
-
按需分配:生成多少词,就分配几个 Block。
通过这种方式,显存浪费率被压缩到了极低的水平,极大地提升了并发上限。

核心技术二:计算与访存优化(打破 Memory Wall)
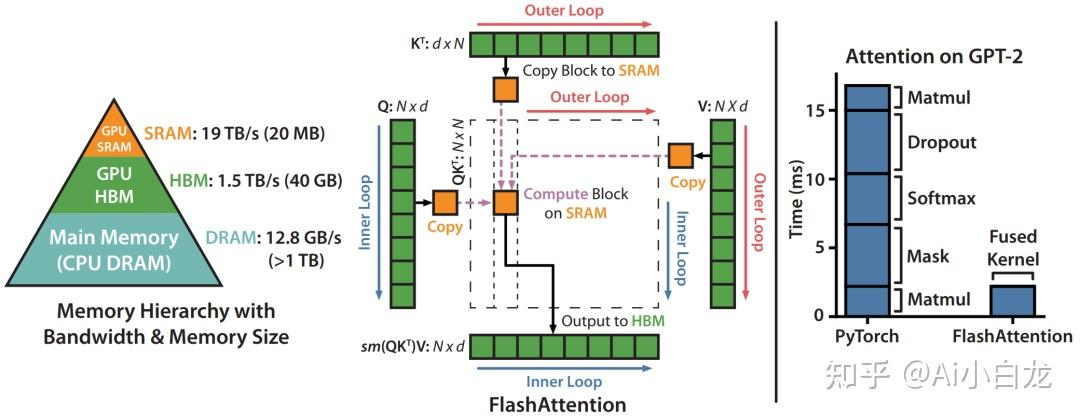
1. 硬件级榨干性能:FlashAttention
在标准的 Attention 计算中,中间产生的注意力分数矩阵(如 Q * K^T)需要被写入 GPU 的 HBM,然后再读出来做 Softmax。这种极其频繁的 I/O 操作严重拖慢了推理速度。
FlashAttention 的核心逻辑是 Tiling(分块计算)。它将矩阵分块读入到 GPU 中容量极小但速度极快的 SRAM 中,一次性完成 Attention 的全部计算,再将最终结果写回 HBM。
-
不保存庞大的中间注意力矩阵。
-
大幅减少了 HBM 的读写次数(Memory Accesses)。
2. 告别 GPU 闲置:Continuous Batching (动态批处理)
在传统的 Static Batching 中,必须等待同批次中"最长"的那个句子生成完毕,GPU 才能处理下一批任务,导致短句子的计算资源被白白闲置。
Continuous Batching(或 In-flight Batching) 实现了在单个迭代步(Iteration)级别的动态调度:只要某个请求生成结束,立刻将其移出 Batch,并塞入新的用户请求。让 GPU 始终处于满负荷运转状态,吞吐量成倍提升。
核心技术三:模型压缩与加速(算法工程师的内功)
除了系统层面的调度,直接从模型结构入手,降低参数量和计算量,是算法优化的另一条主线。
1. 结构化剪枝 (Structural Pruning)
非结构化剪枝(把权重随机置零)对硬件加速非常不友好。在工业界,更倾向于结构化剪枝。
例如,我们可以参考类似 Sheared-LLaMA 的方案,直接对庞大的预训练模型进行层数(Depth)或隐藏层维度(Width)的物理裁剪。裁剪后,利用高质量的开源数据集(例如 RedPajama)进行持续预训练(Continual Pre-training),以此来恢复模型的生成能力。这种物理瘦身能带来最直接的推理加速。
2. 模型量化 (Quantization)
将模型原本的 FP16(16位浮点数)权重,压缩为 INT8 甚至 INT4(4位整数)。常见的方案如 PTQ(训练后量化)、AWQ(激活感知权重压缩)等。不仅大幅降低了模型加载的显存门槛,还能利用 Tensor Core 的整数运算单元加速计算。
Python 实战:纯手工撸一个极简版 KV Cache 管理器
为了加深理解,我们用纯 Python + PyTorch 实现一个极其简化的 KV Cache 缓存更新逻辑。
python
import torch # 导入 PyTorch 核心库
import torch.nn as nn # 导入 PyTorch 的神经网络模块
class MinimalKVCache(nn.Module): # 继承 nn.Module,定义一个极简版的 KV Cache 模块
def __init__(self, max_batch, max_seq_length, hidden_dimension): # 初始化函数,需要预设最大批次大小、最大序列长度和隐藏层维度
super().__init__() # 调用父类的初始化方法
# 【核心技巧】使用 register_buffer 在 GPU 上预先分配一块固定大小的静态显存。
# 为什么要这么做?因为如果在每次生成新词时都使用 torch.cat 动态拼接张量,
# 会不断触发底层的显存分配和释放,带来极大的推理延迟(Overhead)。
self.register_buffer(
"k_cache", # 注册名为 k_cache 的显存块
# 初始化一个形状为 [批大小, 序列长度, 隐藏维度] 的全零张量
# 指定数据类型为 FP16(半精度浮点数)以节省显存,并直接将其加载到 GPU (.cuda())
torch.zeros(max_batch, max_seq_length, hidden_dimension, dtype=torch.float16).cuda()
)
self.register_buffer(
"v_cache", # 注册名为 v_cache 的显存块
# 同理,为 Value 矩阵初始化对应形状的全零 FP16 张量并放入 GPU
torch.zeros(max_batch, max_seq_length, hidden_dimension, dtype=torch.float16).cuda()
)
self.current_length = 0 # 初始化当前已缓存的序列长度指针,起步为 0
def update_and_retrieve(self, new_k, new_v): # 定义更新缓存并获取完整历史记录的方法,传入新生成的 K 和 V
"""
将最新生成的 Key/Value 状态追加写入到预先分配好的显存池中,
并返回截至当前所有的上下文历史记录,供 Attention 计算使用。
"""
batch_sz, seq_len, dim = new_k.shape # 获取新传入的 K 矩阵的形状:当前批次大小,新增词的长度,隐藏层维度
start_pos = self.current_length # 确定本次写入的起始位置(即上一次写到了哪里)
end_pos = start_pos + seq_len # 确定本次写入的结束位置
# 【原位更新】将新生成的 K 和 V 状态,直接通过索引切片赋值,塞进我们预先分配好的显存块中
self.k_cache[:batch_sz, start_pos:end_pos, :] = new_k # 把新的 K 贴进去
self.v_cache[:batch_sz, start_pos:end_pos, :] = new_v # 把新的 V 贴进去
# 更新当前序列长度的指针,向前推进 seq_len 个位置
self.current_length += seq_len
# 切片提取并返回从索引 0 到当前最新长度 (current_length) 的完整上下文
# 这里的提取操作并不会发生物理显存的拷贝,只是创建了一个逻辑视图(View),非常高效
return self.k_cache[:batch_sz, :self.current_length, :], \
self.v_cache[:batch_sz, :self.current_length, :]大厂实习面试高频 Q&A (这是我让AI生成的)
面试官考察 LLM 优化,往往是从基础概念切入,逐步深挖到底层数据结构。以下是几个经典连环问:
Q1: 为什么 LLM 推理需要 KV Cache?如果不加会怎么样?
答: 因为大模型的生成是自回归的。如果不使用 KV Cache,每次生成第 N 个词时,前面的 N-1 个词都要重新参与计算 Attention。这会导致时间复杂度随着序列长度的增加呈 O(N^2) 爆炸。加上 KV Cache 后,我们缓存了历史的 K 和 V 矩阵,每次只需计算当前新词的 Q,时间复杂度退化为 O(N)。
Q2: 既然 KV Cache 这么好,那它有什么缺点?如何解决?
答: 缺点是极度消耗显存。随着 Batch Size 和上下文长度增加,KV Cache 会占用几十 GB 甚至更多的显存,导致模型哪怕能算得过来,也存不下数据(Out of Memory)。
解决思路主要有:
-
系统层面:使用 PagedAttention,将 KV Cache 存放在非连续的显存块中,消除显存碎片。
-
算法层面:使用 MQA (Multi-Query Attention) 或 GQA (Grouped-Query Attention),让多个 Query 共享同一组 K 和 V,从物理上缩小 KV Cache 的体积。
Q3: FlashAttention 优化了时间复杂度还是空间复杂度?
答:这是一个常见的陷阱题。 FlashAttention 并没有改变标准 Attention 的数学计算逻辑,所以它的计算时间复杂度依然是 O(N^2),并没有减少乘加操作的数量。
它的核心是降低了空间复杂度 (从 O(N^2) 降到了 O(N),无需实例化庞大的中间分数矩阵),并且通过 Tiling 技术大幅减少了 GPU SRAM 与 HBM 之间的内存读写次数(IO 复杂度),从而打破了访存瓶颈,实现了物理时间上的加速。
Q4: 在做模型压缩(比如结构化剪枝或蒸馏)时,你是如何评估优化效果的?
答: 在工业界做模型级优化时,不能单纯只看某一项特定任务的准确率,更应避免使用局限性较强的指标(例如 TPR 或 FPR 等分类指标),因为这无法反映大模型的泛化能力。
我们会更多地考察跨领域的通用评估指标(Cross-domain indicators)。具体包括:
-
生成质量:在不同领域(代码、数学、通识)的数据集上测量困惑度(Perplexity, PPL)的变化。
-
系统效率:测量优化前后的吞吐量(Throughput, Tokens/s)以及显存占用效率(Memory Efficiency),这才是衡量工程落地价值的硬核标准。