神经网络基础
人工神经网络( Artificial Neural Network, 简写为ANN)也简称为神经网络(NN),是一种模仿生物神经网络结构和功能的计算模型。人脑可以看做是一个生物神经网络,由众多的神经元(基本单位)连接而成。
神经网络的灵感来源与基本概念
神经网络的概念最早源于对生物神经系统的研究。在大脑中,神经元通过树突接收信号,在细胞体内处理,若信号强度超过阈值,则通过轴突传递信号。受此启发,人工神经网络将这一过程抽象为数学模型,本质上是一个可以从数据中学习的复杂函数:
- 输入:如图像像素、文本向量等。
- 输出:如分类标签、预测值等。
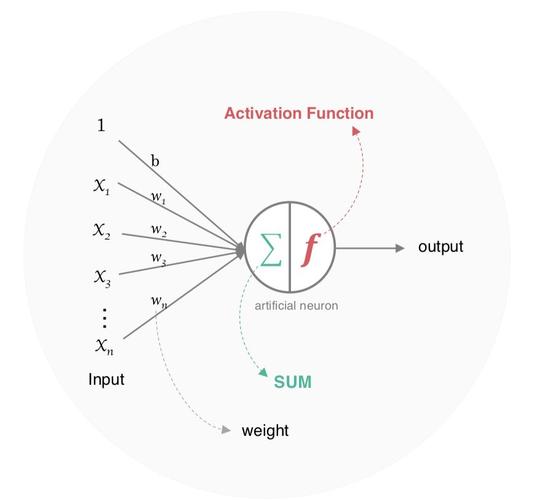
人工神经元(感知机)模型
人工神经元是神经网络的基本计算单元,其数学模型包括以下部分:
-
输入 : x1,x2,...,xnx_1,x_2,...,x_nx1,x2,...,xn
-
权重 : w1,w2,...,wnw_1,w_2,...,w_nw1,w2,...,wn(控制每个输入的重要性)
-
偏置 : bbb (调整激活阈值)
-
计算过程:
-
线性组合:
z=∑i=1mwixi+b=wTx+bz=\sum_{i=1}^{m}w_ix_i+b=w^Tx+bz=∑i=1mwixi+b=wTx+b
拟合直观的简单的因果关系
-
激活函数:
y=f(z)y=f(z)y=f(z)
引入非线性,使网络能拟合复杂、间接因果关系
-
这个过程就像,来源不同树突(树突都会有不同的权重)的信息, 进行的加权计算, 输入到细胞中做加和,再通过激活函数输出细胞值
从神经元到网络:线性层
多个神经元可组成一个"层"(Layer),形成线性层:
- 所有神经元接收相同输入。
- 每个神经元有独立的权重和偏置。
- 并行计算,输出一个向量。
矩阵表示:
- 输入向量:x∈Rnx \in \mathbb{R}^nx∈Rn
- 权重矩阵: W∈Rm×nW \in \mathbb{R}^{m×n}W∈Rm×n (mmm 为神经元数量)
- 偏置向量: b∈Rmb \in \mathbb{R}^mb∈Rm
- 输出: z=Wx+bz=Wx+bz=Wx+b
维度示例:
| 变量 | 维度 | 说明 |
|---|---|---|
| xxx | n×1n×1n×1 | 输入向量 |
| WWW | m×nm×nm×n | 权重矩阵 |
| bbb | m×1m×1m×1 | 偏置向量 |
| zzz | m×1m×1m×1 | 输出向量 |
🌰:输入为28×28图像(展平为784维),提取128个特征,则 WWW 为 128×784 。
神经网络图示:
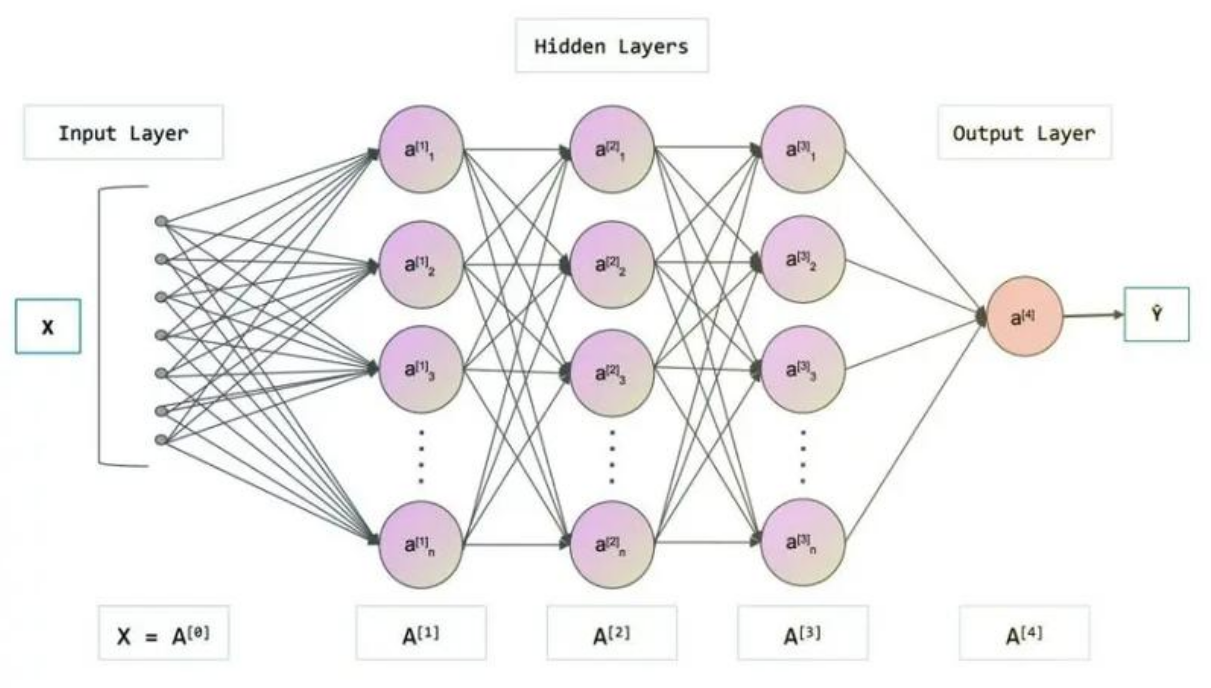
神经元对前一层每个神经元的信息进行进一步的整合归纳,将更高阶、更全局 的特征发送给后一层的每个神经元。神经元有几个,代表对前一层的信息浓缩了几份高阶特征。(每个神经元的权重(侧重点)互不相同。)
神经网络中信息只向一个方向移动,即从输入节点向前移动,通过隐藏节点,再向输出节点移动。其中的基本部分是:
- 输入层(Input Layer) : 即输入xxx的那一层(如图像、文本、声音等)。每个输入特征对应一个神经元。输入层将数据传递给下一层的神经元。
- 输出层(Output Layer) : 即输出yyy的那一层。输出层的神经元根据网络的任务(回归、分类等)生成最终的预测结果。
- 隐藏层(Hidden Layers): 输入层和输出层之间都是隐藏层,神经网络的"深度"通常由隐藏层的数量决定。隐藏层的神经元通过加权和激活函数处理输入,并将结果传递到下一层。
特点:
- 同一层的神经元之间没有连接
- 第 N 层的每个神经元和第 N-1层 的所有神经元相连(这就是fully connected的含义),这就是全连接神经网络
- 全连接神经网络接收的样本数据是二维的,数据在每一层之间需要以二维的形式传递, 输入和输出张量的维度是**( N , 特征数 )**
- 第N-1层神经元的输出就是第N层神经元的输入
- 每个连接都有一个权重值(www系数和bbb系数)
模型更宽 or 更深 ?
相同计算量下网络的深度与宽度的选择类似科技文明改良与传承
神经网络内部状态值和激活值
每一个神经元工作时,前向传播会产生两个值,内部状态值(加权求和值)和激活值 ;反向传播时会产生激活值梯度和内部状态值梯度。
内部状态值 : z=Wx+bz=Wx+bz=Wx+b
神经元或隐藏单元的内部存储值,它反映了当前神经元接收到的输入、历史信息以及网络内部的权重计算结果。
激活值 : a=f(z)a=f(z)a=f(z)
通过激活函数(如 ReLU、Sigmoid、Tanh)对内部状态值进行非线性变换后得到的结果。激活值决定了当前神经元的输出。
正向传播数据流
逆向传播的梯度流
激活函数:引入非线性
若仅使用线性层,多层网络仍等价于单层线性模型。因此需引入非线性激活函数,使网络能学习复杂模式。
常见激活函数对比:
| 函数名称 | 数学公式 | 导数公式 | 输出范围 | 优点 | 缺点 |
|---|---|---|---|---|---|
| Identity (线性函数) | f(x)=xf(x)=xf(x)=x | f′(x)=1f′(x)=1f′(x)=1 | (−∞,∞)(-\infty, \infty)(−∞,∞) | 简单直接,无饱和区 | 无法引入非线性,表达能力弱 |
| Binary Step (阶跃函数) | f(x)={0for x<01for x≥0f(x) = \begin{cases} 0 & \text{for } x < 0 \\ 1 & \text{for } x \ge 0 \end{cases}f(x)={01for x<0for x≥0 | f′(x)={0for x≠0?for x=0f'(x) = \begin{cases} 0 & \text{for } x \ne 0 \\ ? & \text{for } x = 0 \end{cases}f′(x)={0?for x=0for x=0 | {0,1}\{0, 1\}{0,1} | 简单,适合感知机 | 在 x=0x=0x=0 不可导,梯度几乎处处为0 |
| Sigmoid (Logistic) | f(x)=11+e−xf(x) = \frac{1}{1 + e^{-x}}f(x)=1+e−x1 | f′(x)=f(x)(1−f(x))f'(x) = f(x)(1 - f(x))f′(x)=f(x)(1−f(x)) | (0,1)(0, 1)(0,1) | 适合二分类输出;平滑可导 | 梯度消失(两端饱和);非零均值;计算涉及指数运算 |
| Tanh (双曲正切) | f(x)=tanh(x)=21+e−2x−1f(x) = \tanh(x) = \\ \frac{2}{1 + e^{-2x}} - 1f(x)=tanh(x)=1+e−2x2−1 | f′(x)=1−f(x)2f'(x) = 1 - f(x)^2f′(x)=1−f(x)2 | (−1,1)(-1, 1)(−1,1) | 零均值,收敛速度优于Sigmoid | 仍存在梯度消失问题 |
| ReLU (线性修正单元) | f(x)={0for x<0xfor x≥0f(x) = \begin{cases} 0 & \text{for } x < 0 \\ x & \text{for } x \ge 0 \end{cases}f(x)={0xfor x<0for x≥0 | f′(x)={0for x<01for x≥0f'(x) = \begin{cases} 0 & \text{for } x < 0 \\ 1 & \text{for } x \ge 0 \end{cases}f′(x)={01for x<0for x≥0 | [0,∞)[0, \infty)[0,∞) | 计算高效;有效缓解梯度消失;稀疏激活 | 存在"死亡ReLU"问题(负区间梯度为0导致神经元失活) |
| Leaky ReLU | f(x)={0.01xfor x<0xfor x≥0f(x) =\\ \begin{cases} 0.01x & \text{for } x < 0 \\ x & \text{for } x \ge 0 \end{cases}f(x)={0.01xxfor x<0for x≥0 | f′(x)={0.01for x<01for x≥0f'(x) = \\ \begin{cases} 0.01 & \text{for } x < 0 \\ 1 & \text{for } x \ge 0 \end{cases}f′(x)={0.011for x<0for x≥0 | (−∞,∞)(-\infty, \infty)(−∞,∞) | 解决"死亡ReLU"问题;保留ReLU优点 | 性能略逊于ReLU;负区间的斜率(0.01)是超参数,需人工设定 |
| PReLU (参数化ReLU) | f(α,x)={αxfor x<0xfor x≥0f(\alpha, x) =\\ \begin{cases} \alpha x & \text{for } x < 0 \\ x & \text{for } x \ge 0 \end{cases}f(α,x)={αxxfor x<0for x≥0 | f′(α,x)={αfor x<01for x≥0f'(\alpha, x) = \\ \begin{cases} \alpha & \text{for } x < 0 \\ 1 & \text{for } x \ge 0 \end{cases}f′(α,x)={α1for x<0for x≥0 | (−∞,∞)(-\infty, \infty)(−∞,∞) | 负区间的斜率 α\alphaα 可自动学习,更灵活 | 训练参数增加,可能导致过拟合风险 |
| RReLU (随机化ReLU) | f(α,x)={αxfor x<0xfor x≥0f(\alpha, x) =\\ \begin{cases} \alpha x & \text{for } x < 0 \\ x & \text{for } x \ge 0 \end{cases}f(α,x)={αxxfor x<0for x≥0 | f′(α,x)={αfor x<01for x≥0f'(\alpha, x) = \\ \begin{cases} \alpha & \text{for } x < 0 \\ 1 & \text{for } x \ge 0 \end{cases}f′(α,x)={α1for x<0for x≥0 | (−∞,∞)(-\infty, \infty)(−∞,∞) | 随机化的 α\alphaα 可以作为一种正则化手段 | 训练和推理时行为不一致,增加了不确定性 |
| ELU (指数线性单元) | f(α,x)={α(ex−1)for x<0xfor x≥0f(\alpha, x) =\\ \begin{cases} \alpha(e^x - 1) & \text{for } x < 0 \\ x & \text{for } x \ge 0 \end{cases}f(α,x)={α(ex−1)xfor x<0for x≥0 | f′(α,x)={f(α,x)+αfor x<01for x≥0f'(\alpha, x) = \\ \begin{cases} f(\alpha, x) + \alpha & \text{for } x < 0 \\ 1 & \text{for } x \ge 0 \end{cases}f′(α,x)={f(α,x)+α1for x<0for x≥0 | (−α,∞)(-\alpha, \infty)(−α,∞) | 接近零均值;能缓解"死亡ReLU";负区间平滑性好 | 计算涉及指数运算,比ReLU慢;输出范围有界 |
ReLU是当前最常用激活函数,因其简单高效。
sigmoid 激活函数
f(x)=11+e−x f(x) = \frac{1}{1 + e^{-x}} f(x)=1+e−x1
sigmoid函数图像,导数图像:
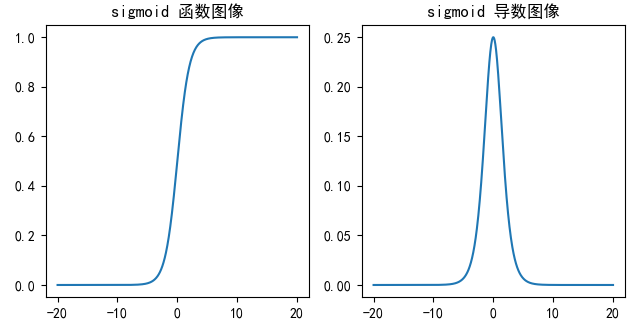
- 对于 sigmoid 函数而言,输入值在 -6, 6 之间输出值才会有明显差异,输入值在 -3, 3 之间才会有比较好的效果。
- 导数数值范围是 (0, 0.25) ,当输入 <-6 或者 >6 时,sigmoid 激活函数图像的导数接近为 0,此时网络参数将更新极其缓慢,或者无法更新(梯度消失)
- 一般来说, sigmoid 网络在 5 层之内就会产生梯度消失 现象。而且,该激活函数并不是以 0 为中心的,所以在实践中这种激活函数使用的很少。sigmoid函数一般只用于二分类的输出层。
python
import torch
import matplotlib.pyplot as plt
# 定义x张量作为x轴(定义1000个等距点作为横坐标)
x = torch.linspace(-20, 20, 1000)
# 创建一个包含所有激活函数的列表
# activations = [torch.relu, torch.sigmoid, torch.tanh, torch.softmax]
# 创建激活函数,求激活值
y = torch.sigmoid(x)
# 画图并展示
plt.plot(x, y)
# plt.show()
# 定义x张量,带导数,作为x轴(定义1000个等距点)
x = torch.linspace(-20, 20, 1000, requires_grad=True)
# 计算loss值,并反向传播
y = torch.sigmoid(x)
y.sum().backward() # 需要对向量张量y求和,使之变为标量张量,然后计算梯度。
plt.plot(x.detach(), x.grad)
plt.show()tanh 激活函数
f(x)=tanh(x)=21+e−2x−1 f(x) = \tanh(x) = \frac{2}{1 + e^{-2x}} - 1 f(x)=tanh(x)=1+e−2x2−1
tanh函数图像,导数图像:
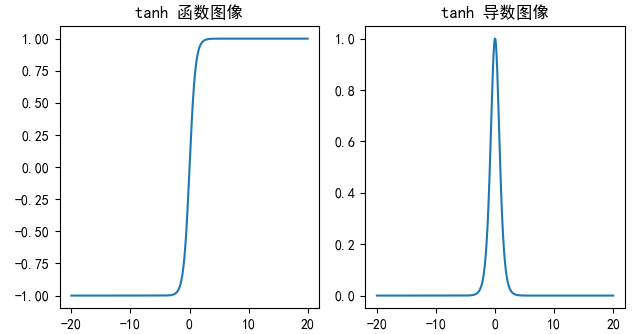
- Tanh 函数将输入映射到 (-1, 1) 之间 ,图像以 0 为中心,在 0 点对称,当输入 大概<-3 或者 >3 时将被映射为 -1 或者 1。其导数值范围 (0, 1),当输入的值大概 <-3 或者 > 3 时,其导数近似 0。
- 与 Sigmoid 相比,它是以 0 为中心的 ,且梯度相对于sigmoid大,使得其收敛速度要比 Sigmoid 快,减少迭代次数。然而,从图中可以看出,Tanh 两侧的导数也为 0,同样会造成梯度消失 (少于5层为佳)。
- 若使用时可在隐藏层使用tanh函数 ,在输出层使用sigmoid函数。
python
import torch
import matplotlib.pyplot as plt
# 定义x张量作为x轴(定义1000个等距点作为横坐标)
x = torch.linspace(-20, 20, 1000)
# 创建一个包含所有激活函数的列表
# activations = [torch.relu, torch.sigmoid, torch.tanh, torch.softmax]
# 创建激活函数,求激活值
y = torch.tanh(x)
# 画图并展示
plt.plot(x, y)
# plt.show()
# 定义x张量,带导数,作为x轴(定义1000个等距点)
x = torch.linspace(-20, 20, 1000, requires_grad=True)
# 计算loss值,并反向传播
y = torch.tanh(x)
y.sum().backward() # 需要对向量张量y求和,使之变为标量张量,然后计算梯度。
plt.plot(x.detach(), x.grad)
plt.show()ReLU 激活函数
f(x)={0for x<0xfor x≥0 f(x) = \begin{cases} 0 & \text{for } x < 0 \\ x & \text{for } x \ge 0 \end{cases} f(x)={0xfor x<0for x≥0
ReLU函数图像,导数图像:
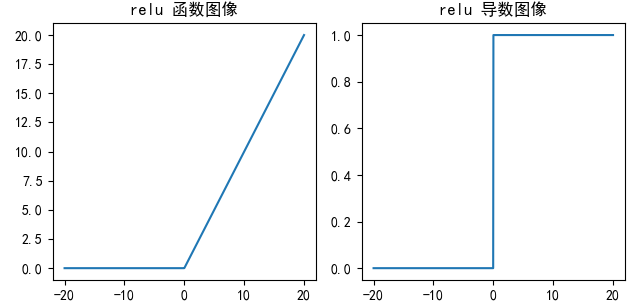
ReLU激活函数将小于 0 的值映射为 0,而大于 0 的值则保持不变,它更加重视正信号,而忽略负信号,这种激活函数运算更为简单,能够提高模型的训练效率。- 当x<0时,
ReLU导数为0,而当x>0时,则不存在饱和问题。所以,ReLU能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。然而,随着训练的推进,部分神经元的输入会落入小于0区域,导致对应的梯度是0,从而权重无法更新。这种现象被称为**"神经元死亡"** 。 ReLU是目前最常用的激活函数。与sigmoid相比,ReLU的优势是:- 采用sigmoid函数,计算量大(指数运算),反向传播求误差梯度时,计算量相对大,而采用
Relu激活函数,整个过程的计算量节省很多。 - sigmoid函数反向传播时,很容易就会出现梯度消失 的情况,从而无法完成深层网络的训练。
Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
- 采用sigmoid函数,计算量大(指数运算),反向传播求误差梯度时,计算量相对大,而采用
python
import torch
import matplotlib.pyplot as plt
# 定义x张量作为x轴(定义1000个等距点作为横坐标)
x = torch.linspace(-20, 20, 1000)
# 创建一个包含所有激活函数的列表
# activations = [torch.relu, torch.sigmoid, torch.tanh, torch.softmax]
# 创建激活函数,求激活值
y = torch.relu(x)
# 画图并展示
plt.plot(x, y)
# plt.show()
# 定义x张量,带导数,作为x轴(定义1000个等距点)
x = torch.linspace(-20, 20, 1000, requires_grad=True)
# 计算loss值,并反向传播
y = torch.relu(x)
y.sum().backward() # 需要对向量张量y求和,使之变为标量张量,然后计算梯度。
plt.plot(x.detach(), x.grad)
plt.show()SoftMax 激活函数
SoftMax 激活函数是深度学习中用于多分类任务的核心函数,它是二分类函数 Sigmoid 在多分类场景下的自然推广。其核心作用是将神经网络输出的原始值(logits)转换为一组概率分布,使得所有输出值都在 (0,1) 区间内,且总和为 1,从而可以被解释为每个类别的预测概率。
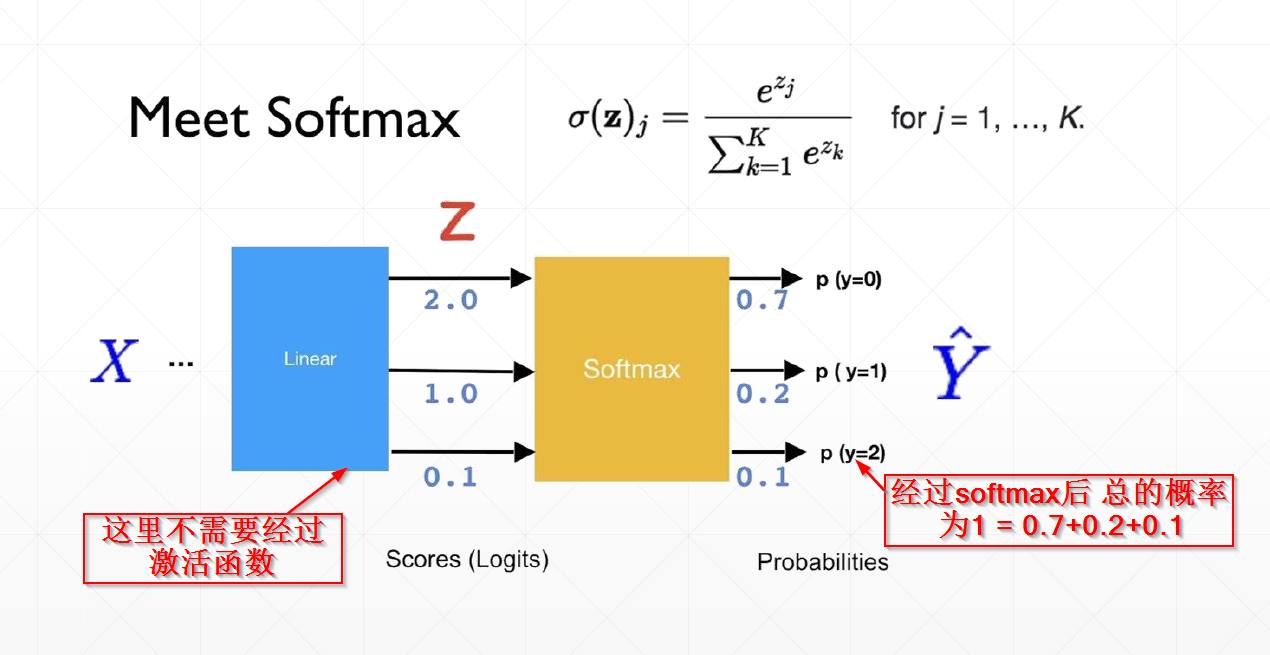
核心特性
- 概率归一化:输出值范围在 (0,1),且所有输出之和为 1,满足概率分布的基本性质。
- 强调最大值:指数运算会放大输入值之间的差异,使得最大值对应的概率显著高于其他值,有助于模型做出明确的分类决策。
- 可微性:SoftMax 是连续可微函数,便于在反向传播中计算梯度,是训练神经网络的关键。
PyTorch 实现示例
python
import torch
# 定义输入张量(logits)
scores = torch.tensor([0.2, 0.02, 0.15, 0.15, 1.3, 0.5, 0.06, 1.1, 0.06, 3.75])
# 应用 SoftMax 函数,dim=0 表示按行计算
probabilities = torch.softmax(scores, dim=0)
# 输出结果
print(probabilities)输出结果为:
tex
tensor([0.0212, 0.0177, 0.0202, 0.0202, 0.0638, 0.0287, 0.0185, 0.0522, 0.0183, 0.7392])最大的输入值 3.75 对应的概率为 0.7392,远高于其他值,这体现了 SoftMax 强调最大值的特性。
温度系数 τττ 的作用
softmax(zi)=eziτ∑jezjτ \text{softmax}(z_i) = \frac{e^{\frac{z_i}{\tau}}}{\sum_j e^{\frac{z_j}{\tau}}} softmax(zi)=∑jeτzjeτzi
- τ<1τ<1τ<1 (低温):分布更尖锐,放大差异,趋近于 one-hot 编码,适用于推理或决策场景。
- τ=1τ=1τ=1(常温):标准 SoftMax,保持原始概率分布,是默认设置。
- τ>1τ>1τ>1 (高温):分布更平滑,缩小差异,趋近于均匀分布,适用于知识蒸馏或探索性任务。
实现图示的 Softmax 温度系数( τττ )效果,代码:
python
import numpy as np
import matplotlib.pyplot as plt
# 设置全局字体为支持中文的字体,例如 'SimHei' (黑体)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号 '-' 显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
# 1. 定义输入数据(模拟图示的logits,共10个类别)
logits = np.array([0.2, 0.02, 0.15, 0.15, 1.3, 0.5, 0.06, 1.1, 0.06, 3.75])
# 2. 实现带温度系数的Softmax函数
def softmax_with_temperature(logits, tau):
"""
计算带温度系数tau的Softmax概率分布
参数:
logits: 输入的logits数组
tau: 温度系数(tau>0)
返回:
概率分布数组
"""
# 防止指数运算溢出(减去最大值)
z = logits / tau
z_max = np.max(z)
exp_z = np.exp(z - z_max) # 减去最大值防止溢出
return exp_z / np.sum(exp_z)
# 3. 定义温度系数和对应的描述
temperatures = [0.3, 0.5, 1.0, 2.0, 5.0, 10.0]
descriptions = [
"分布更尖锐", "分布更尖锐", "标准Softmax",
"分布更均匀", "分布更均匀", "分布更均匀"
]
# 4. 绘制子图(2行3列,共6个图)
plt.figure(figsize=(15, 10)) # 调整画布大小,方便显示
for i, (tau, desc) in enumerate(zip(temperatures, descriptions)):
# 计算当前温度下的概率分布
probs = softmax_with_temperature(logits, tau)
# 创建子图
plt.subplot(2, 3, i + 1) # 2行3列,第i+1个子图
plt.bar(range(len(logits)), probs, color='green', alpha=0.7) # 绘制柱状图
# 添加标题和描述
plt.title(f"温度系数 τ = {tau} ({desc})")
plt.xlabel("类别")
plt.ylabel("概率")
plt.ylim(0, 1) # 统一y轴范围(0到1)
# 在柱状图上显示概率值(可选,增强可读性)
for j, prob in enumerate(probs):
plt.text(j, prob + 0.02, f"{prob:.2f}", ha='center', fontsize=9)
# 调整子图间距
plt.tight_layout()
plt.show()激活函数的选择
1.根据网络层类型选择
隐藏层
-
首选
ReLU及其变体 :ReLU是目前深度学习中最常用的激活函数,因为它计算简单且能有效缓解梯度消失问题。如果你使用了
ReLU, 需要注意一下Dead ReLU问题, 避免出现0梯度从而导致过多的神经元死亡 -
少用使用sigmoid激活函数,可以尝试使用tanh激活函数
输出层
-
分类任务:
- 二分类 :使用 Sigmoid(输出单个概率值)。
- 多分类(互斥) :使用 Softmax(输出概率分布,总和为1)。
- 多分类(非互斥/多标签) :使用 Sigmoid(每个类别独立输出概率)。
-
回归任务 :使用 线性激活函数 (即不使用非线性激活,或显式使用 f(x)=xf(x)=xf(x)=x ),因为输出需要是任意范围的连续值。
f(x)=xf(x)=xf(x)=x也称为identity激活函数
Identity激活函数本质上就是"没有激活函数"。主要是为了代码的设计模式和灵活性(如占位符、统一接口)
2. 根据网络深度选择
- 浅层网络(< 5层):Sigmoid 和 Tanh 通常也能工作,但 ReLU 仍是更稳健的选择。
- 深层网络(> 10层) :必须 使用
ReLU、Leaky ReLU、ELU或 Swish。Sigmoid 和 Tanh 会导致严重的梯度消失,使得深层网络无法训练。
3. 常用激活函数对比表
| 激活函数 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|
| ReLU | 计算快,缓解梯度消失 | 存在"神经元死亡"问题(负输入时梯度为0) | 绝大多数隐藏层的首选 |
| Leaky ReLU | 解决了神经元死亡问题 | 效果不如 ReLU 稳定 | 当 ReLU 效果不佳时尝试 |
| Sigmoid | 输出范围 (0,1),适合概率 | 梯度消失严重,输出非零中心 | 仅用于二分类输出层 |
| Tanh | 输出范围 (-1,1),零中心 | 梯度消失严重 | 已基本被 ReLU 取代 |
| Softmax | 输出概率分布 | 仅用于分类输出层 | 多分类任务输出层 |
| Swish | 性能通常优于 ReLU | 计算稍复杂 | 高精度要求的图像、NLP任务 |
| GELU | 平滑,性能优异 | 计算复杂度高 | Transformer、大型模型 |
4. 选择流程图
你可以按照以下逻辑流程进行选择:
- 确定任务类型:
- 是分类 还是回归?
- 如果是分类,是二分类还是多分类?
- 确定输出层:
- 回归 → 线性。
- 二分类 → Sigmoid。
- 多分类 → Softmax。
- 确定隐藏层:
- 默认选择
ReLU。 - 如果发现训练停滞或大量神经元输出为0 → 尝试
Leaky ReLU或ELU。 - 如果追求极致精度且算力充足 → 尝试 Swish 或 GELU。
- 默认选择
- 测试与验证:
- 在小数据集上快速实验 2-3 种候选函数,观察收敛速度和最终准确率。
总结 :对于现代深度学习模型,隐藏层默认使用
ReLU,输出层根据任务选择Sigmoid/Softmax/线性。只有在遇到特定问题(如收敛困难、精度瓶颈)时,才考虑替换为更复杂的变体(如 Swish 或 Mish)。
参数初始化
🤔 为什么参数初始化如此重要?
如果把训练神经网络比作教一个机器人走路,那么参数初始化就是为它设定一个初始姿势。一个好的初始姿势能让它更快学会走路,而一个糟糕的姿势可能让它永远无法站立。
参数初始化的核心作用主要有三点:
- 打破对称性 (Break Symmetry)
这是必须要解决的问题。如果同一层的所有神经元权重都初始化为相同的值(例如全0或全1),那么在前向传播和反向传播过程中,它们会计算出完全相同的输出和梯度,并同步更新。这就像一群"复制人",永远学习相同的特征,导致网络的学习能力大打折扣。随机初始化是打破这种对称性的关键。 - 防止梯度消失或爆炸 (Prevent Vanishing/Exploding Gradients)
在深层网络中,梯度需要通过反向传播从输出层传递到输入层。如果初始权重值过大,梯度会在反向传播中指数级增大,导致梯度爆炸 ;如果初始权重值过小,梯度则会指数级缩小,最终趋近于零,导致梯度消失。这两种情况都会使网络难以有效训练。合理的初始化能让梯度和激活值在传播过程中保持稳定的尺度。 - 提高收敛速度 (Accelerate Convergence)
一个设计良好的初始化策略能让网络的激活值分布在一个合理的范围内,使得梯度能够更高效地流动和更新。这能让模型从一个更好的"起点"开始优化,从而大大加快训练收敛的速度。
常见的参数初始化方法
偏置(Bias)通常可以简单地初始化为0。而权重(Weight)的初始化则更为关键,以下是几种主流方法:
基础初始化方法
这些方法通常不推荐用于权重,但有助于理解初始化的重要性。
- 全0/全1/固定值初始化
- 做法:将所有权重设为同一个常数(如0、1或3)。
- 缺点 :无法打破对称性,导致网络无法学习。全1或过大的固定值还容易引发梯度爆炸。
- 适用场景:几乎只用于偏置项的初始化,或用于调试网络结构。
- 随机初始化 (均匀/正态分布)
- 做法:从一个简单的概率分布(如均值为0、标准差为1的正态分布,或(0,1)的均匀分布)中随机采样来初始化权重。
- 优点 :能够打破对称性。
- 缺点:如果分布的尺度(方差)选择不当,仍然可能导致梯度消失或爆炸,尤其是在深层网络中。
高级初始化方法
这些方法通过精心设计初始值的尺度,来解决深层网络的训练难题。
Xavier(泽维尔) 初始化 (也称 Glorot 初始化)
-
核心思想 :旨在保持前向传播时激活值的方差和反向传播时梯度的方差大致稳定。它根据当前层的输入神经元数量 (fan_in) 和输出神经元数量 (fan_out) 来动态调整初始权重的方差。
-
适用场景 :非常适合搭配 Sigmoid 或 Tanh 等饱和激活函数。
-
PyTorch实现:pythonimport torch.nn as nn import torch.nn.init as init layer = nn.Linear(256, 128) # 输入256,输出128 # 使用均匀分布的Xavier初始化 init.xavier_uniform_(layer.weight) # 或使用正态分布 # init.xavier_normal_(layer.weight)
Kaiming 初始化 (也称 He 初始化)
-
核心思想 :专门为 ReLU 及其变体激活函数设计。由于ReLU会将负值置零,它会改变信号的方差。Kaiming初始化在Xavier的基础上进行了修正,只考虑输入神经元数量 (fan_in),以补偿ReLU带来的方差变化。
-
适用场景 :是当前使用 ReLU、Leaky ReLU 等激活函数的深度网络的首选初始化方法。
-
PyTorch实现:pythonimport torch.nn as nn import torch.nn.init as init layer = nn.Linear(256, 128) # 使用均匀分布的Kaiming初始化,并指定激活函数为'relu' init.kaiming_uniform_(layer.weight, nonlinearity='relu') # 或使用正态分布 # init.kaiming_normal_(layer.weight, nonlinearity='relu')
如何选择?
选择哪种初始化方法,主要取决于你使用的激活函数。
| 初始化方法 | 适用激活函数 | 核心优势 |
|---|---|---|
| Kaiming (He) 初始化 | ReLU、Leaky ReLU、PReLU | 专为ReLU系列设计,有效防止深层网络梯度消失 |
| Xavier (Glorot) 初始化 | Sigmoid、Tanh | 保持信号在S型函数中的方差稳定 |
| 随机初始化 | 浅层网络或简单任务 | 实现简单,能打破对称性 |
神经网络整体结构与训练流程
1. 三层架构:
- 输入层:接收原始数据。
- 隐藏层:多层堆叠,进行特征提取。
- 输出层:输出预测结果。
神经网络搭建
- 定义网络类 :创建一个类并继承自神经网络框架的基础类(如
nn.Module)。 - 初始化层 :在类的初始化方法(
__init__)中,定义网络包含的各个层,例如全连接层(nn.Linear)、卷积层(nn.Conv2d)等。 - 定义前向传播 :实现前向传播方法(
forward),定义数据如何依次通过你定义的各个层,最终得到输出。
python
import torch.nn as nn
import torch.nn.functional as F
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
# 定义层
self.fc1 = nn.Linear(10, 64)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(64, 2)
def forward(self, x):
# 定义前向传播
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
# 注意:通常不在这里写 softmax,损失函数会处理
return x
model = SimpleNN()
if torch.cuda.is_available():
model.to("cuda")参数计算详解
神经网络的参数主要指在训练过程中会被学习和更新的权重(Weights)和偏置(Biases)
核心计算公式
对于最常见的全连接层(Linear Layer),其参数量计算遵循一个通用公式:
参数量 = (输入维度 × 输出维度) + 输出维度这个公式可以拆解为两部分:
- 权重(Weights)数量 =
输入维度 × 输出维度 - 偏置(Biases)数量 =
输出维度(每个输出神经元对应一个偏置)
🌰假设我们搭建一个简单的神经网络,其结构如下:
- 隐藏层1 :
nn.Linear(3, 3)(输入3个特征,输出3个特征)- 隐藏层2 :
nn.Linear(3, 2)(输入3个特征,输出2个特征)- 输出层 :
nn.Linear(2, 2)(输入2个特征,输出2个特征)我们来逐层计算参数量:
- 隐藏层1 (nn.Linear(3, 3))
- 权重数量:
3 (输入) × 3 (输出) = 9- 偏置数量:
3 (输出)- 该层总参数量:9 + 3 = 12
- 隐藏层2 (nn.Linear(3, 2))
- 权重数量:
3 (输入) × 2 (输出) = 6- 偏置数量:
2 (输出)- 该层总参数量:6 + 2 = 8
- 输出层 (nn.Linear(2, 2))
- 权重数量:
2 (输入) × 2 (输出) = 4- 偏置数量:
2 (输出)- 该层总参数量:4 + 2 = 6
最后,将所有层的参数量相加,得到整个网络的总参数量:
总参数量 = 12 + 8 + 6 = 26
其他常见层的参数量计算
除了全连接层,了解其他层的计算方法也很有帮助:
| 层类型 | 参数量计算公式 | 示例 |
|---|---|---|
| 卷积层 (Conv2d) | (卷积核高 × 卷积核宽 × 输入通道数 × 输出通道数) + 输出通道数 |
nn.Conv2d(3, 64, 3) 的参数量为 (3×3×3×64) + 64 = 1792 |
| 批归一化层 (BatchNorm) | 2 × 特征维度 |
nn.BatchNorm1d(64) 的参数量为 2 × 64 = 128 (包含缩放γ和平移β参数) |
| 嵌入层 (Embedding) | 词汇表大小 × 嵌入维度 |
nn.Embedding(1000, 128) 的参数量为 1000 × 128 = 128000 |
神经网络的优缺点
优点
- 强大的特征学习能力
- 卓越的非线性建模能力
- 强大的泛化能力
- 广泛的适用性
- 支持并行计算
缺点
- "黑箱"性质,可解释性差
- 对数据量和质量的依赖性强
- 计算资源消耗巨大
- 存在过拟合风险
- 模型设计和调参复杂
2. 训练过程:
- 前向传播 :输入数据经各层计算,得到预测输出 y^\hat{y}y^。
- 计算损失:使用损失函数衡量预测与真实值的差距。
- 反向传播:通过链式法则计算梯度,从输出层反向传播误差。
- 参数更新:使用优化算法(如SGD、Adam)更新权重和偏置。
训练过程中的三个关键概念:
在模型训练中,有三个基础概念需要明确区分:
- Epoch :使用全部训练数据完成一次完整训练的过程。例如,数据集有 50,000 个样本,一个 Epoch 就是遍历这 50,000 个样本一次。
- Batch Size :每次训练时使用的小批量样本数量。例如,Batch Size = 256,表示每次更新参数时只用 256 个样本计算梯度。
- Iteration(Step):使用一个 Batch 数据完成一次参数更新的过程。例如,数据集 50,000 个样本,Batch Size = 256,则每个 Epoch 需要约 196 次 Iteration( 50,000/256≈195.350,000/256≈195.3 ,向上取整为 196)。
🔍 前向传播与反向传播
前向传播与反向传播是神经网络训练过程中两个核心且相互依存的阶段,它们共同构成了模型从输入到输出、再从误差到参数更新的完整闭环。
前向传播(Forward Propagation)
前向传播是数据从输入层经过隐藏层最终到达输出层的计算过程。在这个过程中,每一层的神经元接收上一层的输出作为输入,通过权重加权、偏置相加,再经过激活函数处理,生成本层的输出。
其数学表达为:
z(l)=W(l)a(l−1)+b(l)a(l)=σ(z(l))\begin{aligned} z^{(l)} &= W^{(l)} a^{(l-1)} + b^{(l)} \\ a^{(l)} &= \sigma(z^{(l)}) \end{aligned}z(l)a(l)=W(l)a(l−1)+b(l)=σ(z(l))
其中:
- z(l)z^{(l)}z(l)是第 lll 层的加权输入;
- W(l)W(l)W(l) 是第 lll 层的权重矩阵;
- a(l−1)a^{(l−1)}a(l−1) 是第 l−1l−1l−1 层的激活输出;
- b(l)b^{(l)}b(l) 是第 lll 层的偏置向量;
- σσσ 是激活函数,如
ReLU、Sigmoid 等。
前向传播的最终目的是计算模型的预测输出,并与真实标签一起用于计算损失函数 EEE ,为后续的反向传播提供误差信号。
反向传播(Backward Propagation)
反向传播是利用链式法则从输出层向输入层逐层计算梯度的过程。它的目标是计算损失函数对每一层参数(权重和偏置)的梯度,以便通过梯度下降法更新参数,使损失函数最小化。
其核心步骤为:
-
计算输出层误差:
δ(L)=∂E∂a(L)⊙σ′(z(L))\delta^{(L)} = \frac{\partial E}{\partial a^{(L)}} \odot \sigma'(z^{(L)})δ(L)=∂a(L)∂E⊙σ′(z(L))
其中 δ(L)δ(L)δ(L) 是输出层的误差项, ⊙\odot⊙ 表示逐元素相乘。
-
逐层反向传播误差:
δ(l)=((W(l+1))Tδ(l+1))⊙σ′(z(l))\delta^{(l)} = ((W^{(l+1)})^T \delta^{(l+1)}) \odot \sigma'(z^{(l)})δ(l)=((W(l+1))Tδ(l+1))⊙σ′(z(l))
-
计算参数梯度:
∂E∂W(l)=δ(l)(a(l−1))T\frac{\partial E}{\partial W^{(l)}} = \delta^{(l)} (a^{(l-1)})^T∂W(l)∂E=δ(l)(a(l−1))T
∂E∂b(l)=δ(l)\frac{\partial E}{\partial b^{(l)}} = \delta^{(l)}∂b(l)∂E=δ(l)
-
更新参数
W(l)=W(l)−η∂E∂W(l)W^{(l)} = W^{(l)} - \eta \frac{\partial E}{\partial W^{(l)}}W(l)=W(l)−η∂W(l)∂E
b(l)=b(l)−η∂E∂b(l)b^{(l)} = b^{(l)} - \eta \frac{\partial E}{\partial b^{(l)}}b(l)=b(l)−η∂b(l)∂E
其中 ηηη 是学习率,控制参数更新的步长。
两者关系与作用
前向传播负责"预测",反向传播负责"学习"。前向传播计算输出和损失,反向传播计算梯度并更新参数。两者交替进行,形成一个完整的训练迭代。通过不断重复这一过程,模型逐渐逼近最优参数,实现对数据的拟合与泛化。
3. 常见损失函数:
分类任务损失函数
多分类交叉熵损失函数
公式与符号说明
交叉熵损失函数的通用形式为:
L=−∑i=1nyilog(S(fθ(xi)))\mathcal{L} = - \sum_{i=1}^{n} y_i \log\left(S(f_\theta(\mathbf{x}_i))\right)L=−∑i=1nyilog(S(fθ(xi)))
其中:
- yiy_iyi :样本 xix_ixi 属于第 iii 类的真实概率(ground truth),在 one-hot 编码下非 0 即 1;
- fθ(xi)f_θ(x_i)fθ(xi) :神经网络对样本 xix_ixi 的原始输出(logits),即分类得分;
- S(⋅)S(⋅)S(⋅) :
softmax激活函数,将 logits 转换为概率分布,满足 ∑yi=1\sum y^i=1∑yi=1 且 y^i∈0,1\hat y_i∈0,1y^i∈0,1 ; - y^i=S(fθ(xi))\hat y_i=S(f_θ(x_i))y^i=S(fθ(xi)) :第 iii 类的预测概率;
- θθθ :神经网络参数;
- LLL :衡量真实值 yyy与预测值 \\hat y 之间差异性的损失结果,值越小表示预测越接近真实。
公式拆解步骤
-
输入样本 xix_ixi → 经神经网络模型 fθf_θfθ 输出原始得分(logits);
-
logits → 经
softmax函数SSS 转换为预测概率 y^i\hat y_iy^i ; -
计算损失 :对每个类别 iii ,计算 yilog(y^i)y_ilog(\hat y_i)yilog(y^i) ,再取负和,即:
L=−∑i=1nyilog(y^i)L=−\sum_{i=1}^ny_ilog(\hat y_i)L=−∑i=1nyilog(y^i)
由于 yiy_iyi 为 one-hot 编码,仅正确类别对应的 yi=1y_i=1yi=1 ,其余为 0,因此实际计算中只需对正确类别计算 −log(y^correct)−log(\hat y_{correct})−log(y^correct)。
二分类交叉熵作为特例
在二分类任务中,标签 yi∈0,1y_i∈{0,1}yi∈0,1 ,预测概率 pi=y^ip_i=\hat y_ipi=y^i,损失函数可写为:
Loss(L)=−∑i=1n(yilog(pi)+(1−yi)log(1−pi))Loss(L)=−\sum_{i=1}^n(y_ilog(p_i)+(1−y_i)log(1−p_i))Loss(L)=−∑i=1n(yilog(pi)+(1−yi)log(1−pi))
这与多分类公式在形式上一致,只是将 softmax 替换为 sigmoid,且仅需处理两个类别,因此是多分类交叉熵在 n=2n=2n=2 时的特例。
核心要点总结
- 多分类交叉熵适用于"类内互斥"场景(一个样本只能属于一个类别);
softmax函数确保输出为合法概率分布;- 损失值反映预测概率与真实标签的偏离程度,越小越好;
- 二分类交叉熵是其特例,适用于
only two classes的场景。
多分类任务
python
import torch
import torch.nn as nn
# 1. 定义交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 2. 模拟模型输出 (logits)
# 假设有一个批次,包含2个样本,共3个类别
# 形状为 [batch_size, num_classes]
logits = torch.tensor([[0.1, 0.8, 0.1], # 样本1的预测分数
[0.7, 0.2, 0.1]]) # 样本2的预测分数
# 3. 定义真实标签 (类别索引)
# 形状为 [batch_size]
# 表示样本1的真实类别是1,样本2的真实类别是0
targets = torch.tensor([1, 0])
# 4. 计算损失
loss = criterion(logits, targets)
print(f"多分类交叉熵损失: {loss.item()}")二分类任务
方法一: nn.BCEWithLogitsLoss (推荐)
这是最常用的方法,因为它将 Sigmoid 激活函数和 BCELoss 结合在一个类中,具有更好的数值稳定性。
关键特性:
- 输入 :接收模型输出的原始 logits。
- 标签 :标签
target是一个与 logits 形状相同的张量,值为 0.0 或 1.0。
python
import torch
import torch.nn as nn
# 1. 定义二分类交叉熵损失函数 (推荐)
criterion = nn.BCEWithLogitsLoss()
# 2. 模拟模型输出 (logits)
# 假设有一个批次,包含3个样本
logits = torch.tensor([2.0, -1.0, 1.0])
# 3. 定义真实标签
# 形状需与 logits 相同
targets = torch.tensor([1., 0., 1.])
# 4. 计算损失
loss = criterion(logits, targets)
print(f"二分类交叉熵损失 (BCEWithLogitsLoss): {loss.item()}")方法二:nn.BCELoss
如果你选择先手动对模型输出应用 Sigmoid 函数,则应使用 nn.BCELoss。
关键特性:
- 输入 :接收已经过 Sigmoid 函数处理后的概率值(范围在 0 到 1 之间)。
- 标签 :与
BCEWithLogitsLoss相同。
python
import torch
import torch.nn as nn
# 1. 定义二分类交叉熵损失函数
criterion = nn.BCELoss()
# 2. 模拟模型输出 (概率值)
# 注意:这里的输入必须是经过 Sigmoid 激活后的概率
probs = torch.tensor([0.9, 0.2, 0.8])
# 3. 定义真实标签
targets = torch.tensor([1., 0., 1.])
# 4. 计算损失
loss = criterion(probs, targets)
print(f"二分类交叉熵损失 (BCELoss): {loss.item()}")🔍 标签平滑(Label Smoothing)
在传统的分类任务中,我们通常使用 硬标签(Hard Labels) 。例如,一张猫的图片,其标签是 [0, 1, 0](假设类别为:飞机、猫、狗)。模型的目标是让预测概率无限接近 [0, 1, 0],这会导致模型对训练数据过度自信,甚至过拟合。
标签平滑 的思想是将硬标签转化为 软标签(Soft Labels)。它不把正确类别的概率设为 1,把错误类别的概率设为 0,而是给错误类别分配一个很小的非零概率,同时降低正确类别的概率。
具体来说,对于一个有 KKK 个类别的任务,标签平滑后的标签可以表示为:
yi′=(1−ϵ)yi+ϵKy_i' = (1 - \epsilon) y_i + \frac{\epsilon}{K}yi′=(1−ϵ)yi+Kϵ
其中:
- yiy_iyi 是原始的硬标签(0 或 1)。
- ϵϵϵ 是一个超参数,控制标签平滑的程度(通常取值在 0.1 左右)。
- KKK 是类别总数。
- yi′y_i'yi′是平滑后的软标签。
优点
- 防止过拟合:通过引入软标签,模型不会对训练数据过度自信,从而减少过拟合的风险。
- 提高泛化能力:软标签使得模型在训练过程中更加关注类间的关系,而不是仅仅记住训练数据的细节。
- 缓解对抗样本的影响:标签平滑可以使模型对输入的小扰动更加鲁棒,从而提高对抗样本的防御能力。
缺点
- 训练速度可能变慢:由于引入了软标签,模型需要更多的时间来收敛。
- 超参数选择 :需要选择合适的平滑参数 ϵϵϵ ,这可能需要通过实验来确定。
代码
在 PyTorch 中,可以使用 nn.CrossEntropyLoss 并设置 label_smoothing 参数来实现标签平滑
python
import torch
import torch.nn as nn
# 定义标签平滑的交叉熵损失函数
criterion = nn.CrossEntropyLoss(label_smoothing=0.1)
# 模拟模型输出和真实标签
logits = torch.tensor([[0.1, 0.8, 0.1], [0.7, 0.2, 0.1]])
targets = torch.tensor([1, 0])
# 计算损失
loss = criterion(logits, targets)
print(f"标签平滑后的交叉熵损失: {loss.item()}")回归任务损失函数
均方误差(MSE)
定义:MSE 计算的是预测值与真实值之间差值的平方的平均值。
公式:
MSE=1N∑i=1N(yi−yi^)2MSE=\frac{1}{N}\sum_{i=1}^N(y_i−\hat{y_i})^2MSE=N1∑i=1N(yi−yi^)2
其中, yiy_iyi 是真实值, y^i\hat y_iy^i 是预测值, NNN 是样本数量。
特点:
- 对异常值敏感:由于使用了平方项,较大的误差会被放大,导致模型对异常值非常敏感。
- 梯度计算 :梯度为 2(yi−y^i)2(y_i−\hat y_i)2(yi−y^i),随着误差减小,梯度也线性减小,有利于收敛。
- 平滑性:函数处处可导,优化过程相对稳定。
适用场景:数据中异常值较少,且希望模型对所有误差都敏感的情况。
平均绝对误差(MAE)
定义:MAE 计算的是预测值与真实值之间差值的绝对值的平均值。
公式:
MAE=1N∑i=1N∣yi−y^i∣MAE=\frac{1}{N}\sum_{i=1}^N\vert y_i−\hat y_i\vertMAE=N1∑i=1N∣yi−y^i∣
特点:
- 对异常值鲁棒:由于使用了绝对值,较大的误差不会被过度放大,因此对异常值不敏感。
- 梯度计算:梯度为常数(+1 或 -1),在误差较小时梯度不变,可能导致收敛速度变慢或在最优解附近震荡。
- 非平滑性:在误差为0处不可导,需要特殊处理。
适用场景:数据中存在较多异常值,希望模型对异常值不敏感的情况。
光滑L1损失(Smooth L1 Loss)
定义:Smooth L1 Loss 是 MSE 和 MAE 的结合体,它在误差较小时使用 MSE,在误差较大时使用 MAE。
公式:
Smooth L1(x)={0.5x2for ∣x∣<1∣x∣−0.5otherwise\text{Smooth L1}(x)=\begin{cases} 0.5x^2 & \text{for } \vert x \vert < 1 \\ \vert x \vert - 0.5 & \text{otherwise} \end{cases}Smooth L1(x)={0.5x2∣x∣−0.5for ∣x∣<1otherwise
其中, x=yi−y^ix=y_i−\hat y_ix=yi−y^i是误差。
特点:
- 结合优点:在误差较小时具有 MSE 的平滑性和快速收敛性,在误差较大时具有 MAE 的鲁棒性。
- 梯度计算:在误差较小时梯度线性减小,在误差较大时梯度为常数,平衡了收敛速度和鲁棒性。
- 平滑性:函数处处可导,优化过程稳定。
适用场景:目标检测中的边界框回归(如 Fast R-CNN、YOLO 等),以及其他需要平衡收敛速度和鲁棒性的回归任务。
总结与对比
| 损失函数 | 对异常值的敏感性 | 收敛速度 | 平滑性 | 适用场景 |
|---|---|---|---|---|
| MSE | 高 | 快(误差小时) | 高 | 异常值少的回归任务 |
| MAE | 低 | 慢(误差小时) | 低(在0处不可导) | 异常值多的回归任务 |
| Smooth L1 | 中等 | 平衡 | 高 | 目标检测、需要平衡收敛和鲁棒性的任务 |
代码
python
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# --- 1. 准备数据 ---
# 真实值 (Ground Truth)
y_true = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0])
# 预测值 (Predictions)
# 注意:最后一个值 10.0 是一个明显的异常值(预测偏差很大)
y_pred = torch.tensor([1.1, 2.2, 2.9, 4.1, 10.0])
# --- 2. 定义损失函数 ---
# reduction='mean' 表示计算平均值,这是最常用的方式
mse_loss_fn = nn.MSELoss(reduction='mean')
mae_loss_fn = nn.L1Loss(reduction='mean') # MAE 在 PyTorch 中通常对应 L1Loss
smooth_l1_loss_fn = nn.SmoothL1Loss(reduction='mean', beta=1.0) # beta 是阈值,默认为 1.0
# --- 3. 计算损失 ---
loss_mse = mse_loss_fn(y_pred, y_true)
loss_mae = mae_loss_fn(y_pred, y_true)
loss_smooth_l1 = smooth_l1_loss_fn(y_pred, y_true)
# --- 4. 输出结果 ---
print(f"真实值: {y_true}")
print(f"预测值: {y_pred} (注意最后一个值是异常值)")
print("-" * 30)
print(f"MSE Loss (均方误差): {loss_mse.item():.4f}")
print(f"MAE Loss (平均绝对误差): {loss_mae.item():.4f}")
print(f"Smooth L1 Loss: {loss_smooth_l1.item():.4f}")
# --- 5. 可视化理解 (可选) ---
# 绘制损失函数曲线,展示它们对误差的敏感度
x = torch.linspace(-5, 5, 100) # 误差范围从 -5 到 5
y_mse = x ** 2
y_mae = torch.abs(x)
# Smooth L1 实现逻辑: 0.5 * x^2 if |x| < 1 else |x| - 0.5
y_smooth_l1 = torch.where(torch.abs(x) < 1, 0.5 * x**2, torch.abs(x) - 0.5)
plt.figure(figsize=(10, 6))
plt.plot(x.numpy(), y_mse.numpy(), label='MSE (x^2)', linestyle='--')
plt.plot(x.numpy(), y_mae.numpy(), label='MAE (|x|)')
plt.plot(x.numpy(), y_smooth_l1.numpy(), label='Smooth L1', linewidth=2)
plt.title('Loss Functions Comparison')
plt.xlabel('Error (Prediction - Target)')
plt.ylabel('Loss Value')
plt.legend()
plt.grid(True)
plt.show()输出结果:
text
MSE Loss(均方误差):5.0140
MAE Loss(平均绝对误差):1.1000
Smooth L1 Loss(平滑L1损失):0.9070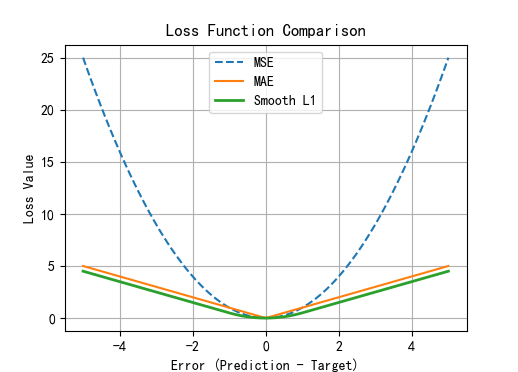
梯度特性(背后的原理)
虽然代码中只计算了 Loss 值,但
PyTorch的自动求导机制(Autograd)会根据这些 Loss 计算梯度:
- MSE 的梯度:与误差成正比。误差越大,梯度越大(容易导致梯度爆炸)。
- MAE 的梯度:恒定为 1 或 -1(在 0 处不可导)。无论误差多大,梯度都不变(收敛慢,但稳定)。
- Smooth L1 的梯度:
- 当误差 <1 时,梯度线性变化(类似 MSE,收敛快)。
- 当误差 >1 时,梯度固定为 1 或 -1(类似 MAE,防止梯度爆炸)。
4. 优化算法:
梯度下降(GD)优化方法
核心概念与参数更新
梯度下降是一种寻找损失函数最小值的优化方法。其核心思想是:梯度方向是函数增长最快的方向,因此梯度的反方向就是函数下降最快的方向。参数更新公式为:
wijnew=wijold−η∂E∂wijw_{ij}^{new}=w_{ij}^{old}−η\frac{∂E}{∂w_{ij}}wijnew=wijold−η∂wij∂E
其中:
- wijw_{ij}wij 是模型参数(如权重)。
- ηηη 是学习率(Learning Rate),控制每次更新的步长。
- ∂E∂wij\frac{∂E}{∂w_{ij}}∂wij∂E是损失函数 EEE 对参数 wijw_{ij}wij 的梯度。
学习率的选择至关重要:
- 太小:收敛速度慢,训练时间成本高。
- 太大 :可能跳过最优解,导致训练不稳定甚至发散。
因此,学习率通常需要随着训练过程动态调整。
三种梯度下降方式对比
深度学习中,梯度下降的几种方式的根本区别在于 Batch Size 的不同,具体如下:
| 梯度下降方式 | Training Set Size | Batch Size | Number of Batches | 特点 |
|---|---|---|---|---|
| BGD (Batch Gradient Descent) | NNN | NNN | 1 | 使用全部数据计算梯度,方向最准,但计算成本高、内存要求大,容易陷入局部极小值。 |
| SGD (Stochastic Gradient Descent) | NNN | 1 | NNN | 每次只用一个样本更新,计算快、内存小,但梯度噪声大,路径震荡,收敛慢。 |
| Mini-Batch (Mini-Batch Gradient Descent) | NNN | BBB | N/B+1N/B + 1N/B+1(未整除时 | 折中方案,兼顾效率与稳定性,是目前最常用的方式。 |
指数加权移动平均值( Exponential Moving Average )
一种在时间序列分析和深度学习优化中广泛应用的平滑技术,它通过赋予近期数据更高的权重,使模型或预测结果能更快响应最新变化,同时保留历史趋势的稳定性。
EMA的核心思想是"越近越重要",其计算公式为:
- 当 t=0t=0t=0时, St=Y0S_t=Y_0St=Y0
- 当 t>0t>0t>0 时, St=β⋅St−1+(1−β)⋅YtS_t=β⋅S_{t−1}+(1−β)⋅Y_tSt=β⋅St−1+(1−β)⋅Yt
其中:
- StS_tSt 表示第 ttt 时刻的指数加权平均值;
- YtY_tYt 表示第 ttt 时刻的实际观测值;
- βββ 是平滑系数,通常取值0.9,控制历史数据的衰减速度。
在实际应用中,EMA常用于:
- 梯度下降优化:平滑损失函数波动,加速收敛;
- 气温预测、金融走势分析等时间序列场景:过滤噪声,突出趋势;
- PyTorch等框架中,用于模型参数的移动平均,提升泛化能力。
通过调节 βββ 值,可以控制平滑程度:
- βββ 越大(如0.9),曲线越平缓,对当前值依赖越低,更适合长期趋势分析;
- βββ 越小(如0.5),曲线更贴近原始数据,响应更快,但波动也更大。
示例代码
python
import torch
import matplotlib.pyplot as plt
# 设置绘图风格
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# ==========================================
# 1. 参数设置与数据生成 (对应图2)
# ==========================================
ELEMENT_NUMBER = 30 # 模拟30天的数据
def test01():
# 固定随机种子,保证结果可复现
torch.manual_seed(0)
# 生成30天的随机气温数据 (均值为0,标准差为1,乘以10模拟气温波动)
temperature = torch.randn(size=[ELEMENT_NUMBER]) * 10
print("原始气温数据:", temperature.numpy())
# 绘制原始数据
days = torch.arange(1, ELEMENT_NUMBER + 1)
plt.figure(figsize=(10, 6))
plt.plot(days, temperature, color='r', label='原始气温')
plt.scatter(days, temperature, color='b', label='每日数据点')
plt.title(f"30天气温变化 (原始数据)")
plt.xlabel("天数")
plt.ylabel("气温")
plt.legend()
plt.grid(True)
plt.show()
# ==========================================
# 2. 指数加权平均计算 (对应图3)
# ==========================================
def test02(beta=0.9):
"""
计算指数加权移动平均
:param beta: 平滑系数 (通常取0.9)
"""
torch.manual_seed(0) # 保持数据与test01一致
temperature = torch.randn(size=[ELEMENT_NUMBER]) * 10
exp_weight_avg = []
# 遍历每一天的气温数据
for idx, temp in enumerate(temperature, 1): # idx从1开始计数
if idx == 1:
# 第一天的EMA值等于当天的实际值
exp_weight_avg.append(temp)
continue
# 计算EMA: S_t = beta * S_{t-1} + (1 - beta) * Y_t
# 注意:idx-2 是因为列表索引从0开始,且我们要取上一个EMA值
new_ema = exp_weight_avg[idx - 2] * beta + (1 - beta) * temp
exp_weight_avg.append(new_ema)
# 转换为Tensor方便绘图
exp_weight_avg = torch.tensor(exp_weight_avg)
# 绘制对比图
days = torch.arange(1, ELEMENT_NUMBER + 1)
plt.figure(figsize=(10, 6))
# 绘制原始数据 (散点)
plt.scatter(days, temperature, color='b', alpha=0.5, label='原始气温')
# 绘制EMA曲线
plt.plot(days, exp_weight_avg, color='r', linewidth=2, label=f'EMA (β={beta})')
plt.title(f"指数加权平均效果对比 (β={beta})")
plt.xlabel("天数")
plt.ylabel("数值")
plt.legend()
plt.grid(True)
plt.show()
# ==========================================
# 3. 运行演示
# ==========================================
# 运行 test01 查看原始数据
# test01()
# 运行 test02 查看 β=0.9 的效果 (通常情况)
print("正在绘制 β=0.9 的EMA曲线...")
test02(beta=0.9)
# 可选:运行 test02 查看 β=0.5 的效果 (对比)
# print("正在绘制 β=0.5 的EMA曲线...")
# test02(beta=0.5)动量算法Momentum
核心思想与数学表达
动量算法在标准梯度下降基础上引入一个速度变量 vtv_tvt ,用于累积历史梯度方向。其更新公式为:
{vt=γvt−1+η∇θJ(θt)θt+1=θt−vt\begin{cases} v_t = \gamma v_{t-1} + \eta \nabla_\theta J(\theta_t) \\ \theta_{t+1} = \theta_t - v_t \end{cases}{vt=γvt−1+η∇θJ(θt)θt+1=θt−vt
其中:
- vtv_tvt:当前时刻的速度(动量项),表示参数更新的累积方向;
- γγγ :动量系数,通常取值 0.9 左右,控制历史梯度的衰减程度;
- ηηη :学习率,控制更新步长;
- ∇θJ(θt)\nabla_\theta J(\theta_t)∇θJ(θt):当前参数 θtθ_tθt 处的梯度;
- θt+1θ_{t+1}θt+1 :更新后的参数。
动量算法的优势
- 加速收敛:在梯度方向一致的区域,动量会不断累积,使更新步长变大,从而加快收敛速度。
- 抑制震荡:在梯度方向频繁变化的区域(如狭长山谷),动量会平滑更新路径,减少来回摆动,提高稳定性。
- 跳出局部极小值:由于动量具有"惯性",它可能帮助优化过程越过一些浅的局部极小值或鞍点。
与指数加权移动平均(EMA)的关系
动量算法中的速度更新公式与 EMA 非常相似。实际上,动量项 vtv_tvt 就是梯度的指数加权移动平均:
vt=γvt−1+(1−γ)⋅(η1−γ∇θJ(θt))v_t = \gamma v_{t-1} + (1 - \gamma) \cdot \left( \frac{\eta}{1 - \gamma} \nabla_\theta J(\theta_t) \right)vt=γvt−1+(1−γ)⋅(1−γη∇θJ(θt))
这表明动量算法本质上是对历史梯度进行加权平均,权重随时间指数衰减。这也解释了为什么动量算法能平滑梯度噪声,提升优化稳定性。
它与指数加权移动平均在数学形式上高度相关,都是通过加权历史信息来平滑当前更新方向
代码
动量算法(Momentum) 通常作为优化器(Optimizer)的一部分直接使用,无需手动编写更新循环。PyTorch 的 torch.optim.SGD 支持通过设置 momentum 参数来启用动量
python
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
# 设置全局字体为支持中文的字体,例如 'SimHei' (黑体)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号 '-' 显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
# 设置随机种子以保证结果可复现
torch.manual_seed(42)
# ==========================================
# 1. 构建一个简单的线性模型(模拟训练过程)
# ==========================================
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.linear = nn.Linear(1, 1, bias=False) # 单参数模型,便于可视化
def forward(self, x):
return self.linear(x)
# 初始化模型
model = SimpleModel()
print("初始参数权重:", model.linear.weight.item())
# ==========================================
# 2. 准备模拟数据(拟合 y = 2x)
# ==========================================
x = torch.tensor([[1.0], [2.0], [3.0], [4.0]])
y = torch.tensor([[2.0], [4.0], [6.0], [8.0]])
# ==========================================
# 3. 定义损失函数和优化器
# ==========================================
criterion = nn.MSELoss()
# 情况 A:普通 SGD(无动量)
optimizer_sgd = optim.SGD(model.parameters(), lr=0.01, momentum=0)
# 情况 B:SGD + Momentum(动量系数 0.9)
model_m = SimpleModel() # 重新初始化模型以对比
optimizer_momentum = optim.SGD(model_m.parameters(), lr=0.01, momentum=0.9)
# ==========================================
# 4. 训练循环(记录参数更新轨迹)
# ==========================================
steps = 50
weights_sgd = []
weights_m = []
for i in range(steps):
# 普通 SGD 训练
optimizer_sgd.zero_grad()
output = model(x)
loss = criterion(output, y)
loss.backward()
optimizer_sgd.step()
weights_sgd.append(model.linear.weight.item())
# Momentum 训练
optimizer_momentum.zero_grad()
output_m = model_m(x)
loss_m = criterion(output_m, y)
loss_m.backward()
optimizer_momentum.step()
weights_m.append(model_m.linear.weight.item())
# ==========================================
# 5. 可视化参数更新路径
# ==========================================
plt.figure(figsize=(10, 6))
plt.plot(range(steps), weights_sgd, label='SGD (无动量)', color='red', linewidth=2)
plt.plot(range(steps), weights_m, label='SGD + Momentum (β=0.9)', color='blue', linewidth=2)
plt.axhline(y=2.0, color='green', linestyle='--', label='目标权重 (2.0)')
plt.xlabel('训练步数')
plt.ylabel('模型权重值')
plt.title('SGD 与 Momentum 优化器参数更新对比')
plt.legend()
plt.grid(True)
plt.show()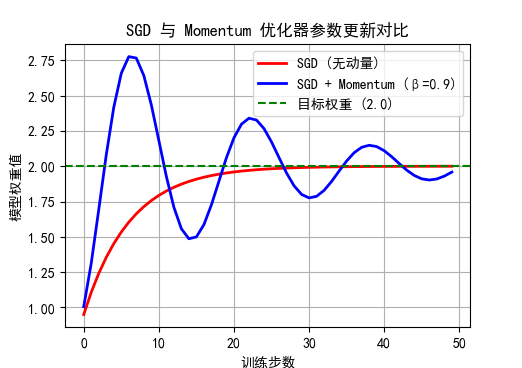
图中的蓝色线震荡更大,是因为动量赋予了它"惯性",让它在优化过程中冲得更猛 。这种震荡在优化初期是正常的,甚至是必要的,因为它帮助算法跳过了局部的微小起伏,更快地找到了下降方向。
AdaGrad 优化算法
AdaGrad (Adaptive Gradient) 是一种自适应学习率的优化算法。它的核心思想是:"历史梯度越大的参数,学习率越小;历史梯度越小的参数,学习率越大。"
这解决了传统SGD中所有参数使用统一学习率的痛点,特别适合处理稀疏数据(如NLP、推荐系统)。
核心思想:
在深度学习中,不同参数的梯度大小差异很大。有些参数可能每轮都更新(梯度大),有些参数可能很久才更新一次(梯度小)。
- 如果统一使用大学习率 → 梯度大的参数会震荡甚至发散;
- 如果统一使用小学习率 → 梯度小的参数几乎不更新,训练极慢。
AdaGrad 的解决方案 :
为每个参数独立维护一个学习率,该学习率随着训练进行自适应衰减,依据是该参数历史梯度的平方和。
参数更新公式:
θt+1=θt−ηGt+ϵ⊙gt\theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{G_t + \epsilon}} \odot g_tθt+1=θt−Gt+ϵ η⊙gt
其中:
- θt\theta_tθt:第 ttt 步的参数。
- gt=∇θJ(θt)g_t = \nabla_\theta J(\theta_t)gt=∇θJ(θt):当前时刻的梯度。
- η\etaη:全局初始学习率(超参数)。
- GtG_tGt:从第 1 步到第 ttt 步所有梯度的平方和(累积历史梯度)。
- ϵ\epsilonϵ:极小值(通常取 10−810^{-8}10−8),防止分母为 0。
- ⊙\odot⊙:表示逐元素相乘(Hadamard product)。
累积梯度计算:
Gt=∑τ=1tgτ2G_t = \sum_{\tau=1}^{t} g_\tau^2Gt=∑τ=1tgτ2
注意 :GtG_tGt 是一个对角矩阵,对每个参数独立计算历史梯度平方和。
优缺点分析:
| 特性 | 描述 |
|---|---|
| 优点:自适应 | 自动为不同参数分配不同学习率,无需手动精细调参。 |
| 优点:稀疏数据 | 对稀疏特征(如 NLP 中的低频词)非常友好,因为它们的 GtG_tGt 小,学习率大,更新快。 |
| 缺点:学习率骤降 | GtG_tGt 是单调递增的,导致分母越来越大,学习率会迅速衰减至 0,导致训练过早停止。 |
| 适用场景 | 凸优化问题、稀疏数据(文本分类、推荐系统)。不推荐用于深层神经网络的长期训练。 |
PyTorch 代码实现:
python
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 定义模型
model = nn.Linear(10, 1)
# 2. 定义损失函数
criterion = nn.MSELoss()
# 3. 定义 AdaGrad 优化器
# lr: 初始学习率 (通常可以设得稍大一点,如 0.01)
# lr_decay: 学习率衰减系数 (默认 0)
# eps: 防止除零的常数
optimizer = optim.Adagrad(model.parameters(), lr=0.01, eps=1e-8)
# 4. 训练循环模拟
for epoch in range(100):
optimizer.zero_grad()
# 前向传播
x = torch.randn(32, 10)
y = torch.randn(32, 1)
output = model(x)
# 计算损失
loss = criterion(output, y)
# 反向传播
loss.backward()
# 参数更新 (AdaGrad 自动处理学习率衰减)
optimizer.step()
if epoch % 10 == 0:
print(f'Epoch {epoch}, Loss: {loss.item():.4f}')
AdaGrad是第一个自适应学习率优化器,它让"梯度小的参数学得快,梯度大的参数学得慢",但因学习率衰减过快,逐渐被RMSProp和Adam取代。
RMSProp优化算法
RMSProp 的核心思想是:"关注近期,遗忘过去"。它通过计算梯度平方的指数加权移动平均来动态调整每个参数的学习率,使得训练过程更加稳定和高效。
🤔 为什么需要 RMSProp?
AdaGrad的问题 :AdaGrad会累积所有历史梯度的平方。随着训练的进行,这个累积值会越来越大,导致学习率(作为分母的一部分)单调递减,最终变得过小,使得模型在训练后期几乎停止学习。这对于非平稳目标(如 RNN)或需要长期训练的深度网络来说是个致命缺陷。RMSProp的解决方案 :RMSProp摒弃了"全部累积"的策略,转而采用指数加权移动平均 (EWMA)。这意味着它给予近期的梯度更高的权重,而让早期梯度的影响指数级衰减,仿佛被"遗忘"了。这样,学习率就不会无限制地减小,模型可以持续学习。
核心数学原理:
RMSProp 通过维护一个梯度平方的移动平均值来调整学习率。
st=γst−1+(1−γ)gt2θt+1=θt−ηst+ϵ⊙gt \begin{aligned} s_t &= \gamma s_{t-1} + (1 - \gamma) g_t^2 \\ \theta_{t+1} &= \theta_t - \frac{\eta}{\sqrt{s_t + \epsilon}} \odot g_t \end{aligned} stθt+1=γst−1+(1−γ)gt2=θt−st+ϵ η⊙gt
其中:
- θt\theta_tθt:第 ttt 步的参数。
- gt=∇θJ(θt)g_t = \nabla_\theta J(\theta_t)gt=∇θJ(θt):当前时刻的梯度。
- sts_tst:梯度平方的指数加权移动平均值,是 RMSProp 的关键。
- γ\gammaγ (gamma):衰减率,通常设为 0.9。它控制着对历史信息的"记忆"程度。
- η\etaη (eta):全局初始学习率(例如 0.001)。
- ϵ\epsilonϵ (epsilon):一个极小的常数(如 10−810^{-8}10−8),用于保证数值稳定性,防止分母为零。
- ⊙\odot⊙:表示逐元素相乘。
直观理解:
可以将 RMSProp 的工作方式想象成开车下坡:
- 坡度陡峭(梯度大) :
RMSProp会自动"踩刹车"(减小学习率),防止冲过头导致震荡。 - 坡度平缓(梯度小) :
RMSProp会自动"加速"(增大学习率),加快前进速度,提升收敛效率。
这种自适应机制使得 RMSProp 在处理不同方向的梯度时非常有效,尤其适合那些损失函数曲面呈狭长"山谷"状的场景。
优缺点分析:
| 特性 | 描述 |
|---|---|
优点:解决 AdaGrad 缺陷 |
通过指数衰减机制,避免了学习率单调递减至零的问题,使训练可以持续进行。 |
| 优点:自适应学习率 | 为每个参数动态调整学习率,对梯度大的方向抑制震荡,对梯度小的方向加速收敛。 |
| 优点:适合非平稳目标 | 特别适合处理循环神经网络(RNN)等目标函数会随时间变化的场景。 |
| 缺点:依赖超参数 | 衰减率 γ\gammaγ 和初始学习率 η\etaη 需要手动调整,对最终性能有影响。 |
| 缺点:可能陷入局部最优 | 和许多优化器一样,它仍有可能收敛到非凸函数的局部最优解。 |
PyTorch 代码实现:
在 PyTorch 中,可以非常方便地使用 torch.optim.RMSprop。
python
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 定义一个简单的模型
model = nn.Sequential(
nn.Linear(10, 5),
nn.ReLU(),
nn.Linear(5, 1)
)
# 2. 定义损失函数
criterion = nn.MSELoss()
# 3. 定义 RMSProp 优化器
# model.parameters(): 模型待优化的参数
# lr: 初始学习率,通常设为 0.001 或 0.01
# alpha: 平滑常数 (即公式中的 gamma),默认 0.99
# eps: 防止除零的常数,默认 1e-8
optimizer = optim.RMSprop(model.parameters(), lr=0.001, alpha=0.99, eps=1e-8)
# 4. 训练循环示例
for epoch in range(100):
optimizer.zero_grad() # 清零梯度
# 模拟数据
x = torch.randn(32, 10)
y = torch.randn(32, 1)
# 前向传播
output = model(x)
loss = criterion(output, y)
# 反向传播
loss.backward()
# 参数更新 (RMSProp 自动调整每个参数的学习率)
optimizer.step()
if epoch % 10 == 0:
print(f'Epoch {epoch}, Loss: {loss.item():.4f}')Adam优化算法
结合了 动量法 (Momentum) 和 RMSProp 的优点,既能利用历史梯度加速收敛,又能为每个参数自适应地调整学习率,目前最常用。
Adam 就像是给模型训练装上了一个"智能导航系统":
- 动量 (Momentum) 负责"惯性":让模型在正确的方向上加速,减少震荡。
- 自适应学习率 (
RMSProp) 负责"刹车与油门":在陡峭的地方减速(防止冲过头),在平缓的地方加速(提高效率)。
核心原理:双重矩估计
Adam 通过计算梯度的一阶矩(均值)和二阶矩(未中心化的方差)来更新参数。
mt=β1mt−1+(1−β1)gt(一阶矩:动量)vt=β2vt−1+(1−β2)gt2(二阶矩:自适应学习率)m^t=mt1−β1t(一阶矩偏差校正)v^t=vt1−β2t(二阶矩偏差校正)θt+1=θt−ηv^t+ϵ⊙m^t(参数更新) \begin{aligned} m_t &= \beta_1 m_{t-1} + (1 - \beta_1) g_t \quad &\text{(一阶矩:动量)} \\ v_t &= \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 \quad &\text{(二阶矩:自适应学习率)} \\ \hat{m}_t &= \frac{m_t}{1 - \beta_1^t} \quad &\text{(一阶矩偏差校正)} \\ \hat{v}t &= \frac{v_t}{1 - \beta_2^t} \quad &\text{(二阶矩偏差校正)} \\ \theta{t+1} &= \theta_t - \frac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \odot \hat{m}_t \quad &\text{(参数更新)} \end{aligned} mtvtm^tv^tθt+1=β1mt−1+(1−β1)gt=β2vt−1+(1−β2)gt2=1−β1tmt=1−β2tvt=θt−v^t +ϵη⊙m^t(一阶矩:动量)(二阶矩:自适应学习率)(一阶矩偏差校正)(二阶矩偏差校正)(参数更新)
符号说明:
- gtg_tgt:当前时刻的梯度。
- mtm_tmt:梯度的指数加权移动平均(类似动量)。
- vtv_tvt:梯度平方的指数加权移动平均(类似 RMSProp)。
- β1,β2\beta_1, \beta_2β1,β2:衰减率,通常分别设为 0.9 和 0.999。
- η\etaη:学习率,默认通常为 0.001。
- ϵ\epsilonϵ:防止除零的小常数,通常为 1e-8。
- m^t,v^t\hat{m}_t, \hat{v}_tm^t,v^t:偏差校正后的矩估计。
为什么要进行"偏差校正"?
这是 Adam 区别于其他算法的一个重要细节。
由于 m0m_0m0 和 v0v_0v0 初始化为 0,且 β1,β2\beta_1, \beta_2β1,β2 接近 1,导致训练初期的 mtm_tmt 和 vtv_tvt 会偏向于 0(尤其是 mtm_tmt)。
通过除以 1−βt1 - \beta^t1−βt,可以将初始阶段的估计值"放大",使其更接近真实的梯度矩,从而保证训练初期的稳定性。
优缺点分析:
| 特性 | 描述 |
|---|---|
| 优点:收敛极快 | 结合了动量和自适应学习率,通常在训练初期就能快速下降。 |
| 优点:省心(默认参数好用) | 大多数情况下,使用默认参数 (η=0.001,β1=0.9,β2=0.999\eta=0.001, \beta_1=0.9, \beta_2=0.999η=0.001,β1=0.9,β2=0.999) 就能获得很好的结果,无需精细调参。 |
| 优点:适合稀疏数据 | 和 RMSProp 一样,能很好地处理 NLP 等稀疏梯度场景。 |
| 缺点:泛化能力争议 | 有研究发现,在某些图像分类任务中,Adam 收敛到的解可能不如 SGD + Momentum 泛化能力强(即测试集准确率略低)。 |
| 缺点:权重衰减问题 | 标准 Adam 中的 L2 正则化实现存在缺陷(与自适应学习率耦合),导致权重衰减不准确。AdamW 修复了这个问题,因此在现代大模型训练中更推荐使用 AdamW。 |
PyTorch 代码实现
python
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 定义模型
model = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
# 2. 定义损失函数
criterion = nn.CrossEntropyLoss()
# 3. 定义 Adam 优化器
# lr: 学习率,默认 1e-3 (0.001)
# betas: (beta1, beta2),默认 (0.9, 0.999)
# eps: 数值稳定性,默认 1e-8
# weight_decay: 权重衰减 (L2正则),但在 Adam 中建议使用 AdamW 代替
optimizer = optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-8)
# 4. 训练循环
for epoch in range(10):
for x_batch, y_batch in dataloader: # 假设有数据加载器
optimizer.zero_grad() # 清零梯度
output = model(x_batch) # 前向传播
loss = criterion(output, y_batch) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 参数更新 (Adam 自动处理)
print(f'Epoch {epoch}, Loss: {loss.item():.4f}')总结与演进
Adam 是深度学习优化器的集大成者,它的出现极大地降低了训练深度神经网络的门槛。
- SGD + Momentum:快,但需要手动调学习率。
- AdaGrad:自适应,但学习率下降太快。
- RMSProp:解决了 AdaGrad 的问题,但缺乏动量。
- Adam = Momentum + RMSProp + 偏差校正。
AdamW= Adam + 解耦的权重衰减(目前训练 Transformer/BERT/GPT 等模型的首选)。
🔍学习率优化
学习率(Learning Rate)可以说是深度学习训练中最重要 的超参数。如果把模型训练比作"下山找最低点(最优解)",那么梯度 决定了你往哪个方向走,而学习率 则决定了你每一步迈多大。学习率优化不仅仅是设定一个初始值,更是一门关于**"动态平衡"**的艺术。
为什么需要优化学习率?
固定学习率(例如全程使用 0.01)通常不是最优解,因为训练的不同阶段对步长的需求是不同的:
| 学习率状态 | 表现症状 | 形象比喻 |
|---|---|---|
| 太大 (Too High) | 损失函数剧烈震荡,甚至变成 NaN(发散)。 | 步子太大,直接跨过山谷撞到了对面的山上。 |
| 太小 (Too Low) | 损失下降极慢,像"乌龟爬",容易陷入局部最优。 | 小心翼翼地挪动,还没走到山脚天就黑了(训练结束)。 |
| 刚刚好 (Just Right) | 损失平滑下降,前期快,后期稳。 | 下山时,远处大步跑,近处小步走,精准到达谷底。 |
动态调整策略
1. 学习率预热
适用场景: Transformer (BERT, GPT)、大模型训练。
原理: 在训练刚开始时,参数是随机初始化的,梯度可能很不稳定。如果直接用大学习率,模型容易"崩"。
做法: 在前几个 Epoch(或 Step)内,将学习率从极小值(如 1e-7)线性增加到预设值(如 0.001)。这相当于让车先挂一档起步,热车后再挂五档飞驰。
2. 学习率衰减
这是最常用的策略,目的是在训练后期进行精细微调。
-
等间隔衰减 (Step Decay): 每隔固定的轮数(如 30 个 Epoch),将学习率除以 10。简单粗暴,效果稳定。
- 特点:呈现"阶梯状"下降。
-
指定间隔衰减(Multi-Step Decay):等间隔衰减的升级版,允许你手动指定在哪些具体的 Epoch 进行衰减,而不需要间隔均匀
- 特点:灵活,完全由你掌控"关键时刻"。
-
指数衰减(Exponential Decay)
- 特点:平滑下降,没有突变。
-
余弦退火 (Cosine Annealing):让学习率按照余弦函数的曲线下降。
- 特点: 下降过程更平滑,且可以在后期配合"重启"(SGDR),跳出局部最优解。
-
自适应衰减 (
ReduceLROnPlateau): 监控验证集的指标(如 Loss 或 Accuracy)。如果连续 N 个 Epoch 没有提升,就自动降低学习率。这是最"智能"的策略之一。
🤔 如何寻找最佳初始学习率?
不要盲目猜测,可以使用 学习率范围测试。
操作步骤:
- 将学习率设为极小值(如
1e-7)。 - 跑几个 batch,每跑一个 batch 稍微增加一点学习率(指数增长)。
- 记录每个学习率对应的 Loss。
- 画图: 横轴是学习率(对数坐标),纵轴是 Loss。
如何看图:
- 最佳点:Loss 下降最快(斜率最大)处对应的学习率。
- 安全上限:Loss 开始剧烈震荡或上升前的那个点。
PyTorch 代码
在 PyTorch 中,我们通过 torch.optim.lr_scheduler 来实现这些策略。
python
import torch
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR, ReduceLROnPlateau, CosineAnnealingWarmRestarts
# 假设 model 和 optimizer 已经定义
optimizer = optim.Adam(model.parameters(), lr=0.001)
# --- 策略 1: 等间隔衰减 ---
# 每 30 个 epoch,学习率变为原来的 0.1 倍
scheduler_step = StepLR(optimizer, step_size=30, gamma=0.1)
# --- 策略 2: 指定间隔衰减 ---
# milestones=[50, 125, 160]: 在这三个特定的epoch结束后衰减
# gamma=0.5: 每次减半
scheduler_multi_step = MultiStepLR(optimizer, milestones=[50, 125, 160], gamma=0.5)
# --- 策略 3: 指数衰减 ---
# gamma=0.95: 每个 epoch 学习率都变为上一轮的 0.95 倍
# 这是一个平滑的过程
scheduler_exponential = ExponentialLR(optimizer, gamma=0.95)
# --- 策略 4: 自适应衰减 ---
# 当验证集 Loss 连续 10 个 epoch 没下降时,学习率减半
scheduler_plateau = ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=10)
# --- 策略 5: 余弦退火 (带重启) ---
# T_0=10 表示第一个周期为 10 个 epoch,T_mult=2 表示后续周期翻倍
scheduler_cosine = CosineAnnealingWarmRestarts(optimizer, T_0=10, T_mult=2)
# --- 训练循环 ---
for epoch in range(100):
train_loss = train_one_epoch(model, optimizer)
val_loss = validate(model)
# 选择不同的调度器进行更新
scheduler_step.step() # 等间隔
# scheduler_multi_step.step() # 指定间隔
# scheduler_exponential.step() # 指数
# scheduler_plateau.step(val_loss) # 自适应式 (需要传入指标)
# scheduler_cosine.step() # 余弦退火
print(f'Epoch {epoch}, LR: {optimizer.param_groups[0]["lr"]}')总结
学习率优化没有"银弹",但遵循以下流程通常能获得不错的效果:
- 先用 范围测试 找到一个大致的最佳初始值。
- 对于 CNN 任务,尝试 Adam (lr=3e-4) 或 SGD + 阶梯衰减。
- 对于 Transformer 任务,使用 AdamW + Warmup + 线性/余弦衰减。
- 如果训练后期 Loss 不下降,检查是否衰减过快,或者尝试
ReduceLROnPlateau。
正则化方法
- 在设计机器学习算法时希望在新样本上的泛化能力强 。许多机器学习算法都采用相关的策略来减小测试误差,这些策略被统称为正则化。
- 神经网络强大的表示能力经常遇到过拟合,所以需要使用不同形式的正则化策略。
- 目前在深度学习中使用较多的策略有范数惩罚 ,
DropOut,标准化层等,接下来我们对其进行详细的介绍。
Dropout 随机失活
如果把神经网络比作一个团队,Dropout 的核心思想就是:在训练过程中,随机让一部分员工"休假"(失活),强迫剩下的员工独立工作并分担更多责任,从而防止团队过度依赖某几个"明星员工"。
核心原理:为什么要"随机失活"?
在训练深层网络时,神经元之间容易产生共适应性(Co-adaptation)。也就是说,某些神经元可能会过度依赖特定的邻居来修正错误或提取特征。这会导致模型在训练集上表现极好,但在测试集(新数据)上泛化能力差(过拟合)。
Dropout 通过以下机制解决这个问题:
- 打破依赖:在每次训练迭代(Batch)中,随机将一部分神经元的输出置为 0。这意味着神经元不能依赖特定的上游节点,必须学习到更鲁棒的特征。
- 模型集成(Ensemble) :每次随机丢弃不同的神经元,相当于在训练成千上万个不同的"子网络"。测试时,所有神经元都参与计算,这相当于对这些子网络的结果进行了平均,从而极大地提升了泛化能力。
工作机制与数学公式
Dropout 在训练阶段 和测试阶段的行为是完全不同的。
1. 训练阶段
对于每一层的输出 hhh ,我们生成一个随机的"掩码"(Mask),以概率 ppp (丢弃率)将神经元置零,以概率 1−p1−p1−p 保留神经元。
为了保持输出数值的期望不变,保留下来的神经元数值需要放大,除以保留概率 (1−p)(1−p)(1−p)。这被称为 Inverted Dropout(反向 Dropout) ,是现代框架(如 PyTorch, TensorFlow)的标准实现。
公式如下:
h′=h⊙M1−ph' = \frac {h \odot M}{1-p}h′=1−ph⊙M
其中:
- ppp :丢弃概率(Dropout Rate),例如 0.5。
- MMM :伯努利随机变量生成的掩码矩阵,取值为 0 或 1。
- ⊙\odot⊙ :逐元素相乘。
- 除以(1−p)(1−p)(1−p) 是为了缩放(Scaling),保证训练时的期望输出与测试时一致。
2. 测试/推理阶段
在测试时,我们希望利用整个网络的全部知识,因此不进行随机丢弃 ,所有神经元都参与计算,且不需要做任何缩放(因为训练时已经缩放过)。
h′=hh′=hh′=h
PyTorch 代码实现
在 PyTorch 中使用 Dropout 非常简单,通常放在全连接层的激活函数之后。
python
import torch
import torch.nn as nn
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.relu = nn.ReLU()
# p=0.5 表示 50% 的概率丢弃神经元
self.dropout = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
# 训练时自动失活,测试时自动关闭
x = self.dropout(x)
x = self.fc2(x)
return x
# 模拟输入
input_data = torch.randn(32, 784)
model = SimpleNet()
# 1. 训练模式
model.train()
output_train = model(input_data)
# 此时部分神经元输出为 0,其余数值被放大
# 2. 测试模式
model.eval()
output_test = model(input_data)
# 此时所有神经元都工作,且数值未被缩放优缺点
| 特性 | 描述 |
|---|---|
| 优点:防止过拟合 | 极其有效,特别是当训练数据较少或网络过大时。 |
| 优点:计算高效 | 相比于模型集成(训练多个模型),Dropout 只需训练一个模型就能达到类似集成的效果。 |
| 优点:通用性 | 几乎可以插入到任何全连接网络结构中。 |
| 缺点:训练变慢 | 由于每次只更新部分参数,收敛速度通常会变慢,需要更多的 Epoch。 |
| 缺点:随机性 | 引入了噪声,可能导致训练 Loss 曲线震荡。 |
总结
Dropout 就像是神经网络的"防作弊机制"。它通过强制网络在训练时"由于残缺而更加健壮",确保了模型学到的是通用的特征,而不是死记硬背训练数据中的噪声。虽然现在的 Transformer 架构(如 BERT, GPT)更多使用残差连接和层归一化,但在传统的全连接网络和 CNN 中,Dropout 依然是不可或缺的神器。
批量归一化(Batch Normalization)
批量归一化(Batch Normalization,简称 BN) 是深度学习领域里程碑式的技术,如果说 Dropout 是为了防止过拟合,那么 BN 就是为了解决深层网络难以训练 的问题。它就像是给神经网络装上了一个"数据校准器",强行把每一层的输入数据拉回到标准的分布范围内,让网络学得更稳、更快。
核心原理:为什么要用 BN?
在深层网络中,随着前面层参数的不断更新,后面层接收到的输入数据分布会一直发生变化。这种现象被称为内部协变量偏移(Internal Covariate Shift, ICS)。
这就好比你在射击,但靶子一直在左右晃动,你很难瞄准。BN 的作用就是固定靶子,让每一层的输入分布保持稳定(通常是均值为 0,方差为 1 的标准正态分布)。
BN 带来的三大好处:
- 加速收敛:不再需要小心翼翼地调整参数,训练速度大幅提升。
- 允许更大的学习率:不用担心梯度爆炸或发散,可以使用比普通网络高 10-100 倍的学习率。
- 轻微的正则化效果:由于使用了 Mini-batch 的统计量(带有噪声),BN 在一定程度上能防止过拟合,有时甚至可以替代 Dropout。
工作机制与数学公式
BN 层通常放置在卷积/全连接层之后,激活函数之前。它的计算过程分为四步:
1. 训练阶段(Training)
BN 是基于 Mini-batch 进行计算的。假设一个批次有 mmm 个样本,对于某一个特征维度:
-
计算均值和方差:
μB=1m∑i=1mxiμ_B=\frac1m \sum_{i=1}^mx_iμB=m1∑i=1mxi
σB2=1m∑i=1m(xi−μB)2σ_B^2=\frac1m\sum_{i=1}^m(x_i−μ_B)2σB2=m1∑i=1m(xi−μB)2
-
标准化(归一化):
x^i=xi−μBσB2+ϵ\hat x_i=\frac {x_i−μ_B}{\sqrt {σ_B^2+ϵ}}x^i=σB2+ϵ xi−μB
注: ϵ\epsilonϵ 是一个极小值(如 10−510^{-5}10−5 ),防止分母为 0。
-
缩放与偏移(关键步骤) :
如果直接标准化,可能会破坏原本特征的表达能力(比如原本的数据分布是非线性的,强行拉成标准正态分布可能不好)。因此,BN 引入了两个可学习参数 γγγ (缩放)和 βββ (偏移),让网络自己决定是否需要恢复原来的分布。
yi=γx^i+βy_i=γ\hat x_i+βyi=γx^i+β
γ\gammaγ 和 β\betaβ 是通过反向传播训练出来的。
如果网络觉得标准化不好,它可以学出 γ=σ,β=μ\gamma=\sigma, \beta=\muγ=σ,β=μ 来恢复原状。
2. 推理阶段(Inference)
在测试或部署时,通常是一个样本一个样本地预测,无法计算 Batch 的均值和方差。
- 解决方案 :使用训练阶段累积的全局移动平均(Running Mean)和移动方差(Running Variance)。
- 这些统计量在训练时通过动量(Momentum)不断更新,推理时直接作为固定值使用。
核心计算公式:
在训练的每一个步骤(Step)中,BN 层不仅会计算当前批次的均值μBμ_BμB 和方差 σB2σ_B^2σB2 ,还会利用它们来更新全局的 running_mean 和 running_var。
更新采用的是**指数移动平均(Exponential Moving Average, EMA)**算法:
-
全局均值更新公式:
running_meant=(1−m)⋅running_meant−1+m⋅μB\text {running\_mean}_t=(1−m)⋅\text {running\mean}{t−1}+m⋅μ_Brunning_meant=(1−m)⋅running_meant−1+m⋅μB
-
全局方差更新公式:
running_vart=(1−m)⋅running_vart−1+m⋅σB2\text{running\_var}_t=(1−m)⋅\text{running\var}{t−1}+m⋅σ_B^2running_vart=(1−m)⋅running_vart−1+m⋅σB2
符号说明:
- running_meant/running_vart\text {running\_mean}_t / \text{running\_var}_trunning_meant/running_vart :当前步骤更新后的全局统计量。
- running_meant−1/running_vart−1\text {running\mean}{t-1} / \text{running\var}{t-1}running_meant−1/running_vart−1 :上一步保存的全局统计量。
- μB/σB2μ_B / σ_B^2μB/σB2 :当前 Mini-batch 计算出的均值和方差。
- mmm :动量(Momentum)参数。
它决定了当前批次的数据对全局统计量的影响权重。
注意 :在
PyTorch中,momentum参数默认值为 0.1。这意味着全局统计量主要保留历史记忆(90%),当前批次只贡献 10% 的新信息。注:有些文献或框架(如 TensorFlow 早期版本)可能使用 \\alpha 表示保留比例(如 0.999),公式会写成 \\alpha \\cdot \\text{old} + (1-\\alpha) \\cdot \\text{new} ,本质是一样的。
推理阶段的应用公式:
当模型训练完成,进入推理(测试/部署)阶段时,running_mean 和 running_var 将被固定下来,不再更新。
此时,对于任意输入 xxx (无论 Batch Size 是多少),归一化公式变为:
x^=x−running_meanrunning_var+ϵ\hat x=\frac {x−\text{running\_mean}}{\sqrt {\text {running\_var}+ϵ}}x^=running_var+ϵ x−running_mean
y=γx^+βy=γ\hat x+βy=γx^+β
关键点:
- 不再使用当前输入数据的均值和方差。
- 直接使用训练好的
running_mean和running_var。 - γγγ (缩放)和 βββ (偏移)也是使用训练好的固定值。
代码中的体现(PyTorch)
python
# 定义 BN 层,momentum=0.1 是默认值
bn = nn.BatchNorm2d(num_features=64, momentum=0.1)
# --- 训练阶段 ---
model.train()
# 1. 计算当前 batch 的 mean/var
# 2. 用它们归一化数据
# 3. 更新 running_mean 和 running_var (通过 EMA 公式)
output = bn(input)
# --- 推理阶段 ---
model.eval()
# 1. 忽略当前 input 的统计特征
# 2. 直接使用累积好的 running_mean 和 running_var
# 3. 输出确定的结果
output = bn(input) PyTorch 代码
在 PyTorch 中,BN 有针对全连接层(BatchNorm1d)和卷积层(BatchNorm2d)的不同实现。
python
import torch
import torch.nn as nn
class NetWithBN(nn.Module):
def __init__(self):
super(NetWithBN, self).__init__()
# 卷积层
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
# BN层:参数是通道数
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU()
# 全连接层
self.fc1 = nn.Linear(100, 50)
# BN层:参数是特征维度
self.bn2 = nn.BatchNorm1d(50)
def forward(self, x):
# 卷积 -> BN -> 激活 (经典顺序)
x = self.conv1(x)
x = self.bn1(x) # 自动判断是训练模式还是评估模式
x = self.relu(x)
# ... 后续操作
return x
# 使用示例
model = NetWithBN()
input_data = torch.randn(32, 3, 224, 224) # Batch=32
# 1. 训练模式
model.train()
output_train = model(input_data)
# 此时 BN 计算当前 Batch 的均值方差,并更新全局移动平均
# 2. 推理模式
model.eval()
output_test = model(input_data)
# 此时 BN 使用训练时累积的全局移动均值和方差优缺点分析
| 特性 | 描述 |
|---|---|
| 优点:训练极快 | 大幅减少训练所需的 Epoch 数量。 |
| 优点:降低调参难度 | 对权重初始化的敏感度大大降低,不再需要精心的初始化策略。 |
| 优点:允许高学习率 | 梯度流动更顺畅,不易出现梯度消失/爆炸。 |
| 缺点:依赖 Batch Size | 如果 Batch Size 太小(如 < 8),统计量计算不准,BN 效果会变差甚至导致训练失败。 |
| 缺点:推理行为差异 | 训练和推理的计算逻辑不同,如果忘记切换 model.eval(),结果会完全错误。 |
总结与对比
- 与 Dropout 对比 :
- Dropout 是做"减法",随机扔掉神经元,防止过拟合。
- BN 是做"除法"和"加法"(标准化+缩放),稳定数据分布,加速训练。
- 两者可以结合使用,但通常 BN 放在 Dropout 之前(或者在卷积网络中只用 BN 不用 Dropout)。
- 与其他归一化对比 :
- Batch Norm :统计量基于 Batch(适合 CNN,依赖 Batch Size)。
- Layer Norm :统计量基于 单个样本的所有特征(适合 RNN/Transformer,不依赖 Batch Size)。
- Instance Norm :统计量基于 单张图的单通道(适合风格迁移)。
BN 是现代卷积神经网络(CNN)的标配组件,它通过标准化层输入解决了深层网络训练难的痛点,是让你能训练出 100 层甚至更深网络的关键技术之一。
主流神经网络类型对比
| 网络类型 | 核心结构 | 适用数据 | 优势 | 劣势 |
|---|---|---|---|---|
| CNN | 卷积层、池化层 | 图像、网格数据 | 提取局部特征、参数共享 | 难以建模长距离依赖 |
| RNN | 循环连接、隐藏状态 | 序列数据(文本、时间序列) | 保留历史信息、处理顺序 | 串行计算、梯度消失 |
| Transformer | 自注意力机制、位置编码 | 序列、多模态 | 并行计算、建模全局依赖 | 计算复杂度高 |
关键差异总结:
- 并行性:CNN 和 Transformer 支持并行,RNN 为串行。
- 长距离依赖:Transformer 最优,RNN 次之(LSTM/GRU改善),CNN 最弱。
- 适用场景:CNN 用于图像,RNN 用于短序列,Transformer 用于长序列和跨模态任务。
深度学习 vs 传统机器学习
| 维度 | 传统机器学习 | 深度学习 |
|---|---|---|
| 特征工程 | 依赖人工设计(如SIFT、HOG) | 自动学习特征 |
| 数据需求 | 小数据即可(百/千级) | 需海量数据(万/亿级) |
| 计算资源 | CPU 即可 | 依赖 GPU/TPU |
| 可解释性 | 较强(如决策树) | 较弱(黑盒模型) |
| 复杂任务 | 难以处理高维数据 | 擅长图像、语音等 |
总结
神经网络是一个"可微函数 + 梯度优化"的统一框架。其核心在于:
- 通过多层非线性变换提取特征。
- 利用反向传播和优化算法自动学习参数。
- 不同结构(CNN、RNN、Transformer)适应不同数据类型。