目录
[2.虚拟地址与进程地址空间 3.是什么?例子](#2.虚拟地址与进程地址空间 3.是什么?例子)
1.引入新概念,直接解释上篇的答案
为什么父子进程输出地址是一致的,但是变量内容不一样?
首先这个并不是物理内存
1.1一个进程,一个虚拟地址空间
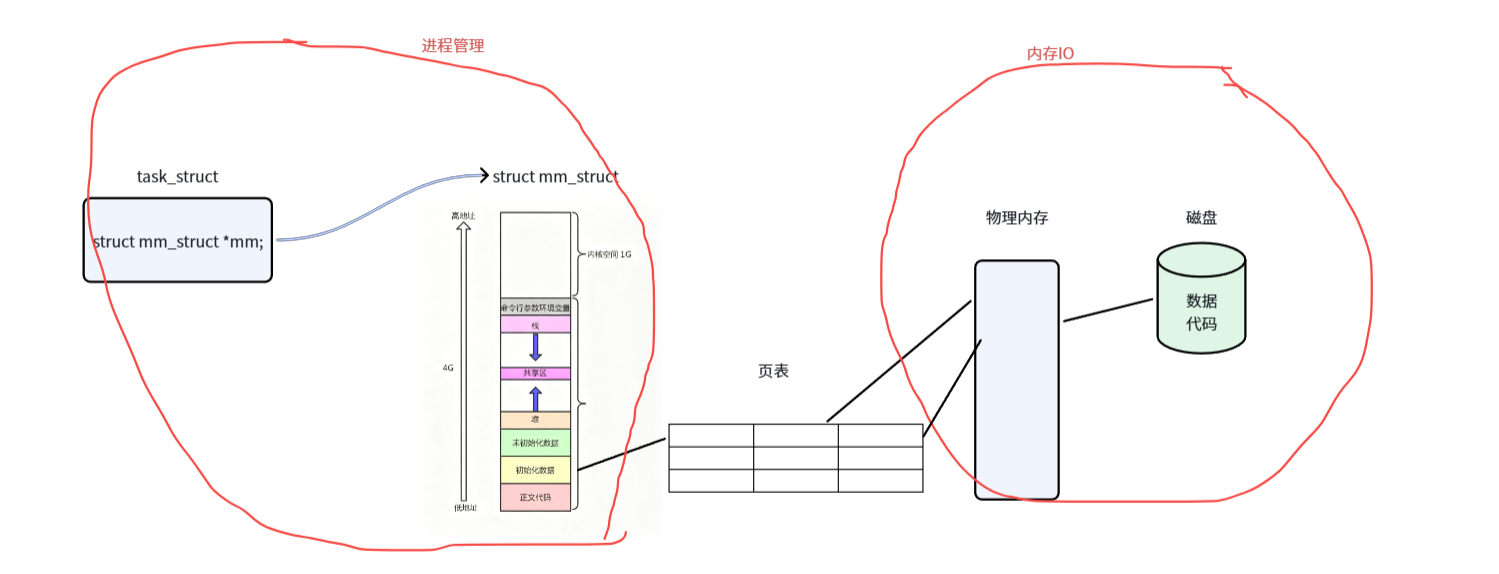
每一个进程创建时都有一个task_struct用来描述对应的进程,而每一个task_struct都对应一个虚拟地址空间的东西。
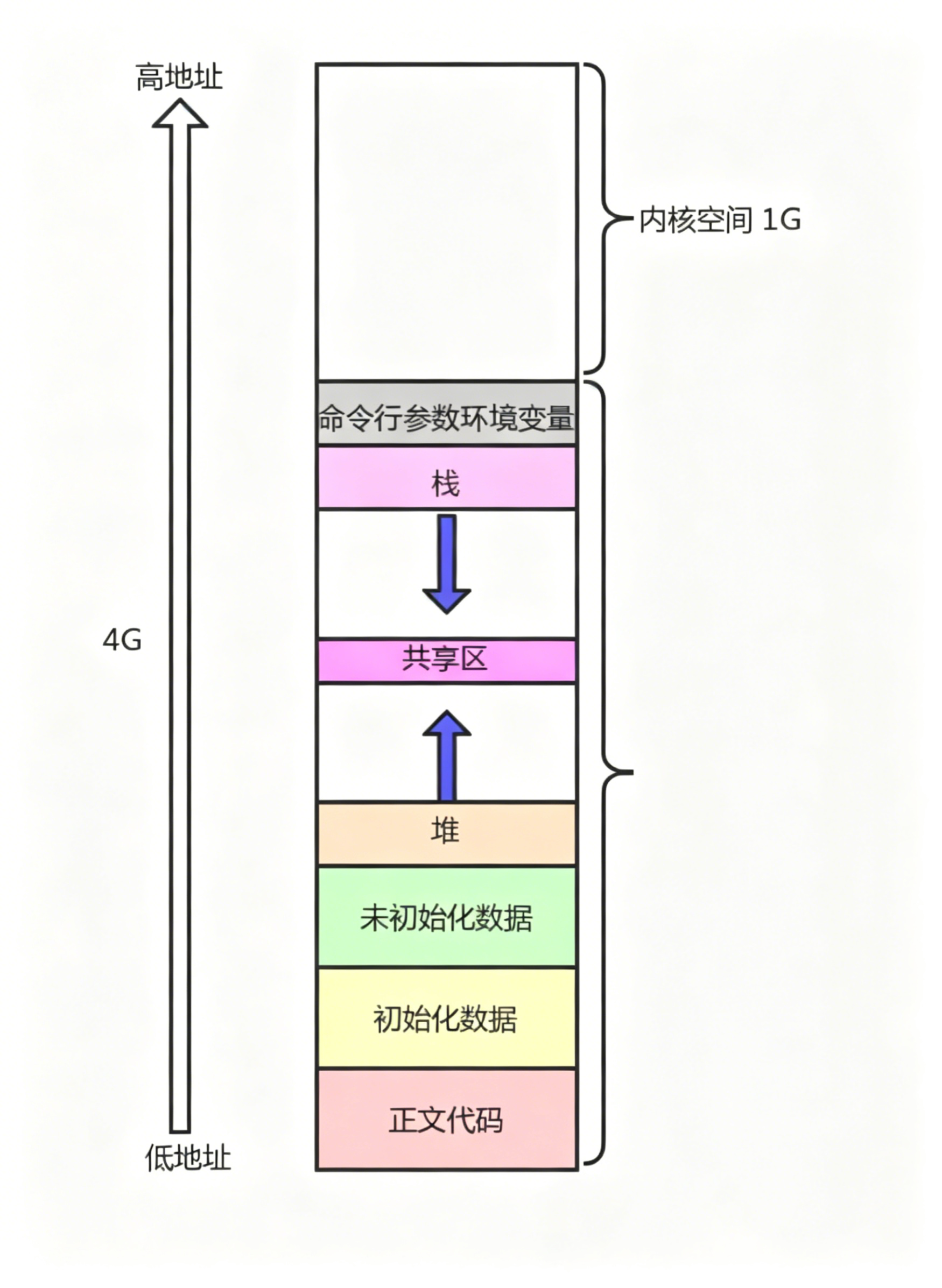
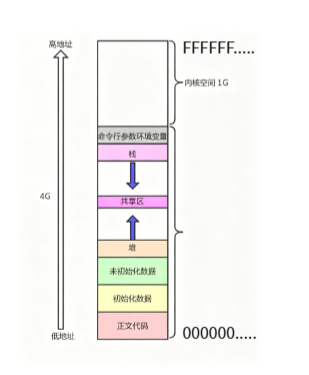
虚拟地址空间对应宽度单位是1字节
32位机器下-2^32个地址 = 4GB 一般以32位为例
64位机器下-2^64个地址
0-3GB 称为用户空间
3-4GB 称为内核空间
访问0-3GB上的,拿到其虚拟地址,就能直接访问
实际上在代码编译,编译结束大部分变量名不在了。会变成 内存地址(绝对或相对) 或寻址方式(如寄存器+偏移)。
假设在物理内存上有一个全局变量g_val其值为100,与此同时在虚拟地址空间上也要有一个四字节的全局变量。拿着g_val的起始虚拟地址假设0x111111。在操作系统内为每一个进程创建一个叫做页表的东西。
1.2一个进程,一套页表
页表 → 是内核管理的数据结构,它存放在物理内存 中。内核通过自己的虚拟地址空间(3--4 GB)中的一段映射来访问和修改页表。
页表可以通过虚拟地址空间找到对应的物理地址
页表左侧填充一个0x111111,右侧假设0x112233
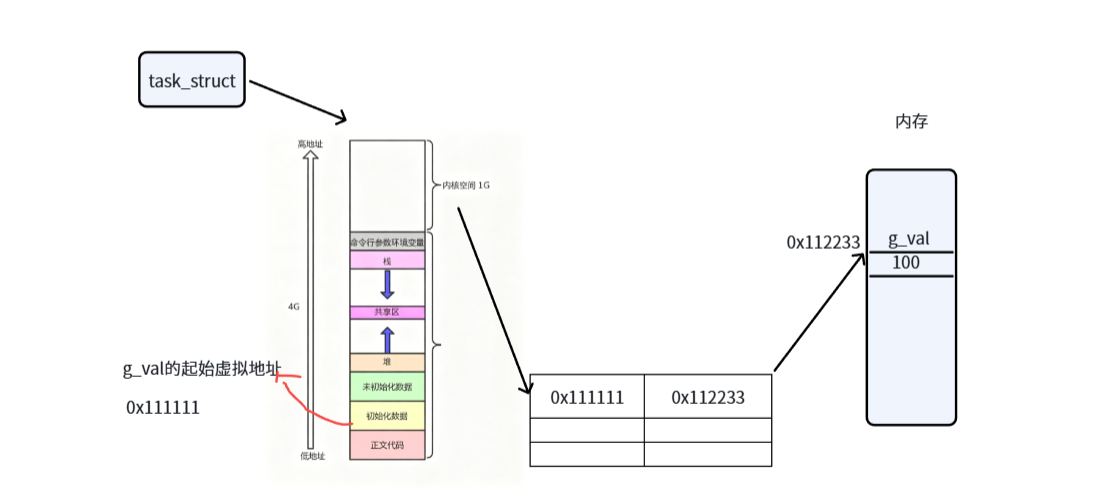
1.3页表是用来做虚拟地址和物理地址映射的
既然上面int g_val=100对应四个字节,虚拟地址宽度是一字节
所以理应无论是在虚拟地址还是物理地址都应该有四个地址啊,为什么只拿到了一个呢?
实际上我们拿到是四个地址中最小的那个也就是首地址,根据起始地址+偏移量就可以找到。
一个变量在内存中有一个物理地址,在虚拟地址空间还有一个虚拟地址
在操作系统内为每一个进程构建一套 页表
操作系统会通过页表,把虚拟地址转换为物理内存地址,进而访问指定变量
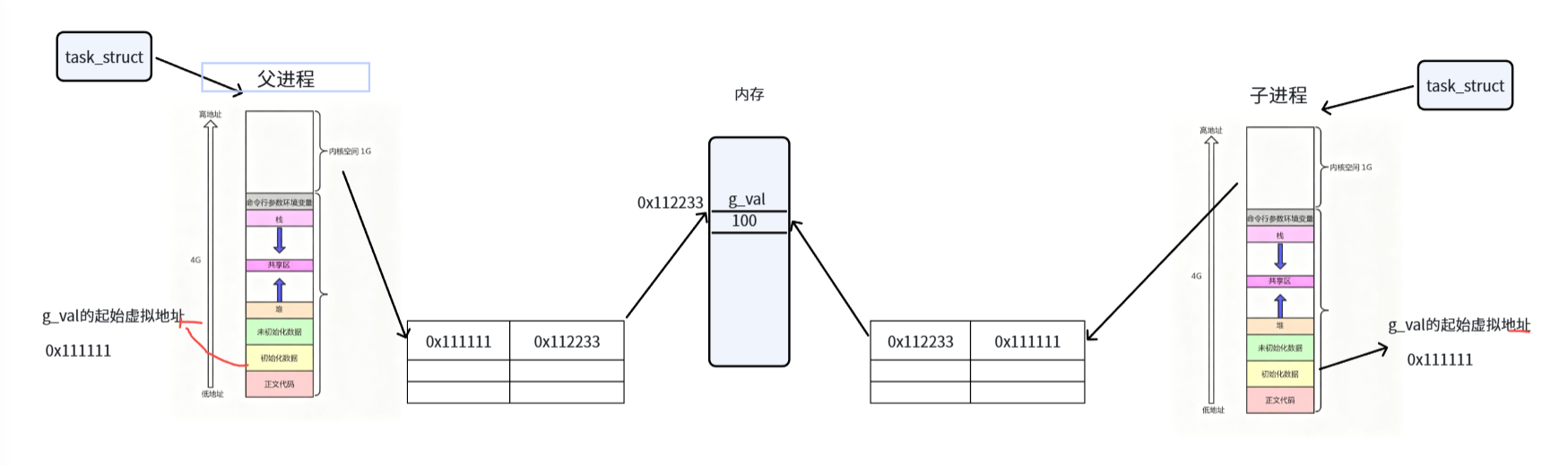
父子进程都有自己对应的一套页表,虚拟地址空间
子进程这个task_struct是拷贝自父进程的,地址空间、页表同样也是。同样的在子进程内也应该有一个全局变量g_val,这就发生浅拷贝了。父子的代码以及其他数据同样也是如此,这样父子在默认情况下就共享了。
浅拷贝
当子进程的g_val++,那么内存会重新开辟一个空间,把老变量里面的内容拷贝进来,此时就得到一个新的物理地址。从而构建一个新的映射关系
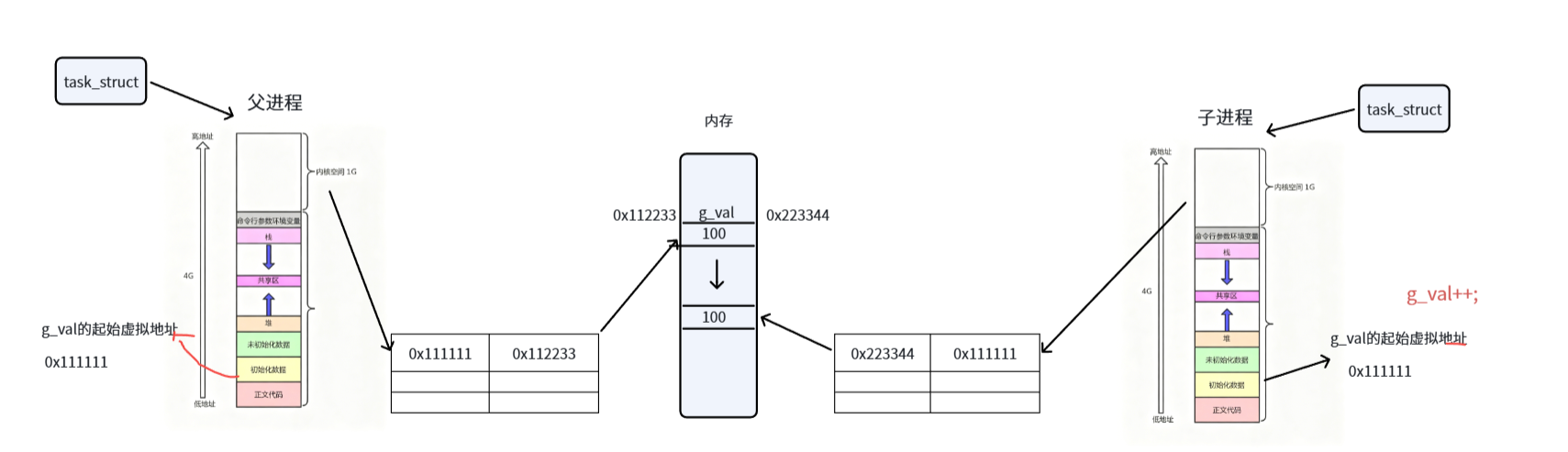
子进程对变量进行修改,构建全新的映射关系,虚拟内存不变,物理内存指向一个新的物理地址---这种机制称之为写时拷贝。这些都是操作系统自动做的。
由此可以解释上篇最后的那个地址是一致的,但是变量内容不一样。之前fork也是同样的原理。
进程具有独立性
用户看不到物理地址,操作系统把物理地址隐藏起来了,只能看到虚拟地址。
2.虚拟地址与进程地址空间 3.是什么?例子
大富翁---操作系统
10亿 --物理内存
私生子--进程
大饼--虚拟地址空间
会让每个进程都认为自己有4GB的物理内存
或者,每一个进程都认为自己在独占物理内存
饼要不要管理?--要管理,怎么管理?---先描述,再组织!
虚拟地址空间本质:是一个数据结构!
mm_struct
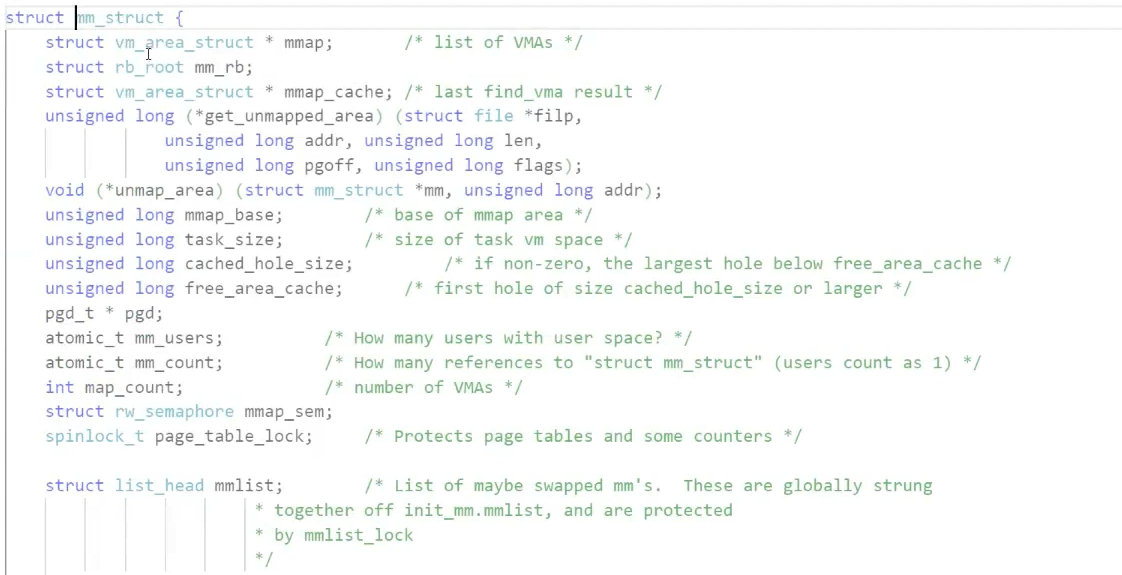
struct mm_struct
{
long code_start;
long code_end;
long init_start,init_end;
long unint_start,unint_end;
......
}
虚拟空间是一个在内核、操作系统中给进程创建的结构体对象
虚拟地址空间从全零到全F
4.怎么办?
》什么叫做区域划分?
例子:
100cm桌子 对桌子进行统一编址
桌子--地址空间
100cm--2^32个地址
刻度--地址空间上的地址
小女孩(李四)画38线本质是区域划分,现在用计算机量化一下
struct Destop{ struct Destop area={0,49,50,99}
int size;
int zs_start;
int zs_end;
int ls_start;
int ls_end;
}
区域划分只需要确认区域的开始和结束即可!
小男孩张三桌子上每一个刻度就相当于地址
张三就可以根据刻度随意访问,张三只要知道自己开始和结束的区域是什么,这范围内的刻度就可以随便用,每一个刻度不需要保存
整个桌子是100cm,而我们一旦有刻度就是0-99,这个过程就是对桌子进行统一编址。地址可以用int整数来保存
|--------------|--------------------------------------|
| 桌子上的刻度 | 虚拟地址(例如 0x0, 0x1, 0x2, ...) |
| 张三 | 一个进程(或者 CPU 执行的程序) |
| 知道自己开始和结束的区域 | 进程的虚拟地址空间范围(如 0~3GB,或由堆、栈、代码段组成的区间) |
| 范围内的刻度随便用 | 程序可以直接通过指针访问该范围内的任何虚拟地址(只要该地址已被合法映射) |
| 每一个刻度不需要保存 | 程序不需要显式为每个字节记录信息;只需要在需要时计算地址并访问 |
区域划分只需知道开始和结束:这就像内存分段(代码段、数据段、堆、栈),操作系统只需要记录每个段的基地址和长度(或结束地址),不需要为段内的每个字节单独做标记。
刻度就是地址,统一编址:整个虚拟地址空间(比如 0~3GB)如同一条从 0 到 99 的尺子,每个整数索引对应一个字节。这与计算机为每个字节分配一个唯一虚拟地址的做法一致。
地址可以用
int整数保存:在 32 位系统中,虚拟地址确实是一个 32 位无符号整数。指针本质上就是一个整数,只是编译器赋予了它类型语义。
有几个进程(小孩),操作系统就为每个进程分配一个独立的虚拟地址空间(桌子)。
每个进程都认为自己独占整个"桌子"(例如 32 位系统下的 0--3GB 用户空间)。
不同进程的"桌子"是相互隔离的------张三的刻度 0x10 和李四的刻度 0x10,虽然是相同的虚拟地址,但通过页表映射到不同的物理内存位置,因此互不干扰。
操作系统负责为每个进程维护各自的页表,从而实现这种隔离。
这就是进程地址空间独立性的核心:每个进程都有自己私有的虚拟地址空间,彼此看不见对方的内存。只有通过特定的进程间通信(共享内存、文件映射等)才能有控制地共享部分物理页面。
所以之前那个mm_struct里面应该有以下数据
struct mm_struct
{
long code_start;
long code_end;
long init_start,init_end;
long unint_start,unint_end;
......
}
所以地址空间是一个结构体,而它的结构体是每一个的开始虚拟地址和结束虚拟地址。这样往里面一填就把区域划分出来了.
小女孩把区域调整37分,这个就是调整区域
area.ls_start-=20;
area.zs_end-=20;
调整区域只需要对整数变量进行+-
源代码(部分)
进程

会存在一个mm_struct的结构

mm_struct就是当前进程对应的虚拟地址空间
| 字段 | 作用 | 普通进程 | 内核线程 |
|---|---|---|---|
mm |
指向进程自己的内存描述符,包含用户态地址空间(页表、VMA 等)。 | 非空,指向其内存描述符 | 为 NULL(内核线程没有用户地址空间) |
active_mm |
指向当前实际活跃的内存描述符(即 CPU 当前使用的页表所属的 mm)。 | 与 mm 相同 |
指向借用的 某个普通进程的 mm(因为内核线程运行时需要借用页表来访问内核空间) |
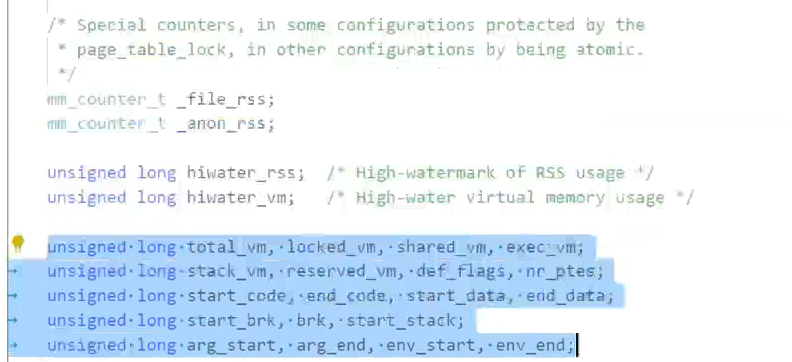
struct mm struct {
unsigned long total_vm, locked_vm, shared_vm, exec_vm;
unsigned long stack_vm, reserved_vm, def_flags, nr_ptes;
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
| 字段 | 说明 |
|---|---|
total_vm |
进程总共使用的虚拟内存页数(包括代码、数据、栈、共享库等) |
locked_vm |
被锁在内存中(不允许换出)的页数,例如通过 mlock() 锁定的内存 |
shared_vm |
与其他进程共享的页数(例如共享内存、动态库代码段) |
exec_vm |
可执行代码页数(一般是代码段 .text) |
stack_vm |
栈区域占用的页数 |
reserved_vm |
保留的页数(通常用于特殊映射,具体含义随内核版本变化) |
def_flags |
默认的页保护标志(如 VM_READ, VM_WRITE 等) |
nr_ptes |
该进程占用的页表项(PTE)数量(反映页表开销) |
start_code, end_code |
代码段的虚拟地址起始和结束位置 |
start_data, end_data |
数据段的虚拟地址起始和结束位置(包括初始化和未初始化数据) |
start_brk |
堆的起始地址(brk 的初始值) |
brk |
堆的当前结束地址(通过 sbrk/brk 系统调用调整) |
start_stack |
栈的起始地址(通常是用户栈的最高地址,向下增长) |
arg_start, arg_end |
命令行参数的起始和结束地址(位于栈顶附近) |
env_start, env_end |
环境变量的起始和结束地址 |
我们对应的代码和数据,是不是会随着应用程序的体积不同,正文部分和数据部分大小也不一样。
当我们的程序让它变成进程的时候,磁盘上的数据和代码是要加载到物理内存的。一旦加载到物理内存,代码占多少个物理内存那么就会同批次地在虚拟地址空间上相同大小,填充页表,虚拟跟物理就建立了联系
页表是通过 3--4GB 中的虚拟地址被内核访问和修改",这是正确的。但用户程序访问自己的变量时,并不需要通过 3--4GB 空间------用户程序直接使用 0--3GB 的虚拟地址,CPU 通过页表(由内核管理)自动完成地址转换。
mm_struct Linux 内核中管理进程虚拟地址空间的核心数据结构!
1》.在虚拟地址空间中申请指定大小的空间 调整区域划分!
2》.加载程序,申请物理空间
1<->2->页表进行映射!
物理地址转化为虚拟地址!---提供给上层用户
地址空间是个结构体变量mm_struct
1》开辟空间
2》初始化的值哪里来?---加载的时候,进行初始化!
虚拟地址转化成为物理地址
OS查找页表
5.为什么?
1》 这个可执行程序之后加载到物理内存哪个地方已经不重要了,不管加到什么地方都可以通过页表的映射关系,**将地址从无序变有序
2》**当用户拿着虚拟地址想要访问某个代码或者某个变量,需要把虚拟地址转化成物理地址,自动的地址转换的过程中,也可以对你的地址和操作进行合法性判定,进而保护物理内存
a.野指针b.char *str="helloworld";*str='H';运行崩溃,在字符常量区---查找页表的时候,权限拦截了!
字符串常量区在正文和初始化数据之间,只读权限,没有写的权限字符常量区不可修改
缺页中断
假设今天要访问代码部分,可是代码部分特别大。比如代码部分是2GB,物理内存可能只把代码四分之一加载进来了,直接把正文部分映射2GB,但只把500MB的虚拟地址和物理内存映射好,剩下有1.5GB没有加载进来。所以当我们操作系统在访问的时候,突然发现虚拟地址有,但物理内存并不在内存里。这个时候操作系统就可以继续实现,动态加载。也就是再拿500MB上物理内存然后对应地填页表,建立好映射关系,再让我们程序继续运行,这种形式我们叫做缺页中断
按需分配:物理内存按需分配,节省内存
3》让我们进程管理和内存管理,进行一定程度的解耦合!
一些问题:
1.我们可以不加载代码和数据,只有task_struct,mm_struct,页表
2.创建进程,先有task_struct,mm_struct等,还是先加载代码和数据?
先有内核数据结构,然后才有代码、数据
3.如何理解进程挂起?
先找到对应进程,内存空间严重不足,然后操作系统查页表。
把所有指定的代码数据,全部换出到swap分区里,只保留左半部分,右半部分换出,内存就清出来了
堆区,不止一个吧!不止一个起始虚拟地址吧
地址空间扩展
struct mm_struct
{
struct vm_area_struct *mmap; /*指向虚拟区间(VMA)链表*/
struct rb_root mm_rb; /* red_black 树 */
unsigned long task_size;/*具有该结构体的进程的虚拟地址空间的⼤⼩*/
// 代码段、数据段、堆栈段、参数段及环境段的起始和结束地址。
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
}mm_struct会维护一张vm_area_struct的链表,以不连续的方式把起始记录下来,这样就可以把堆区管理起来
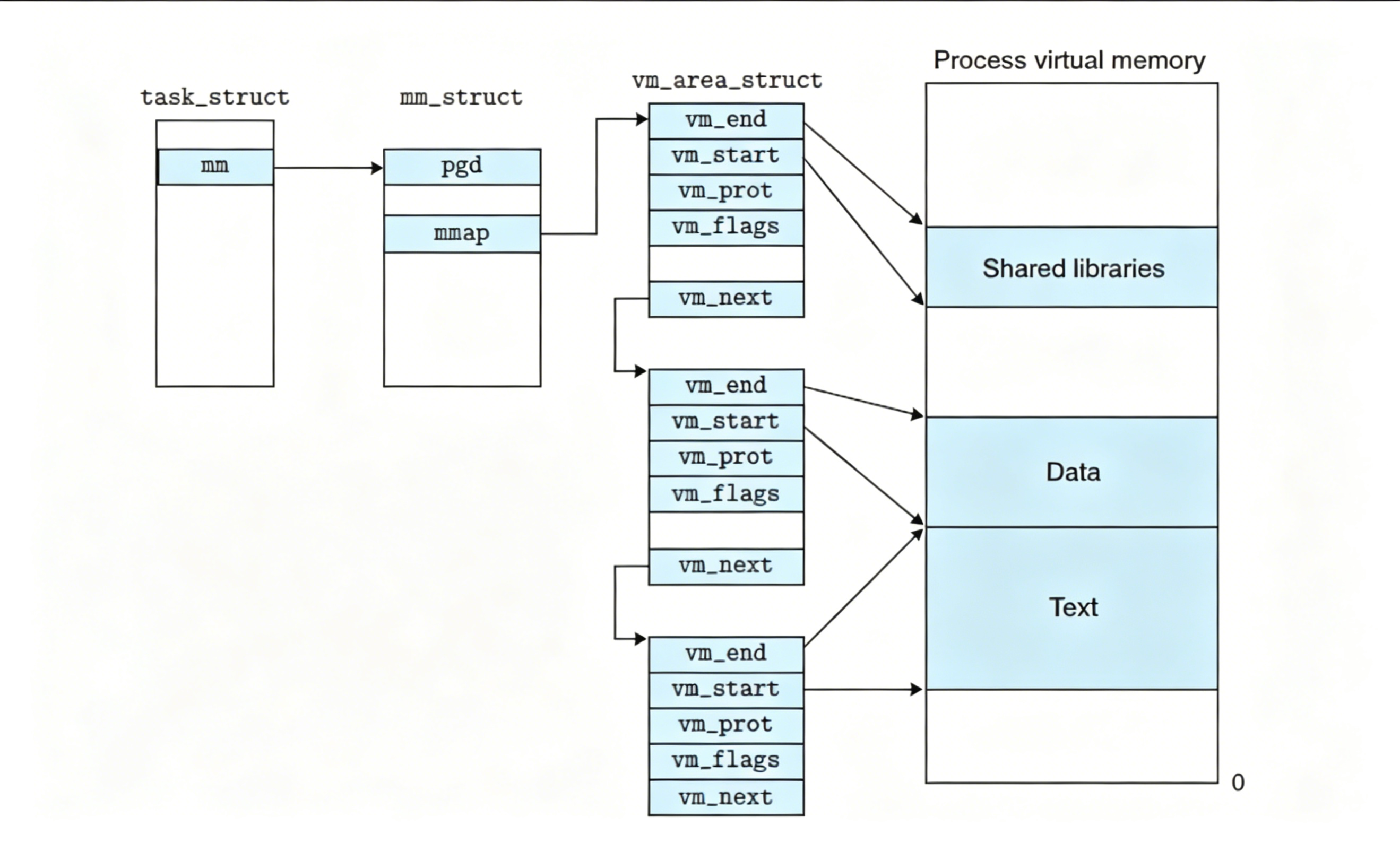
每个区域都会有一个vm_area_struct描述每个区域的开始和结束,然后mm_struct里是对整体的描述
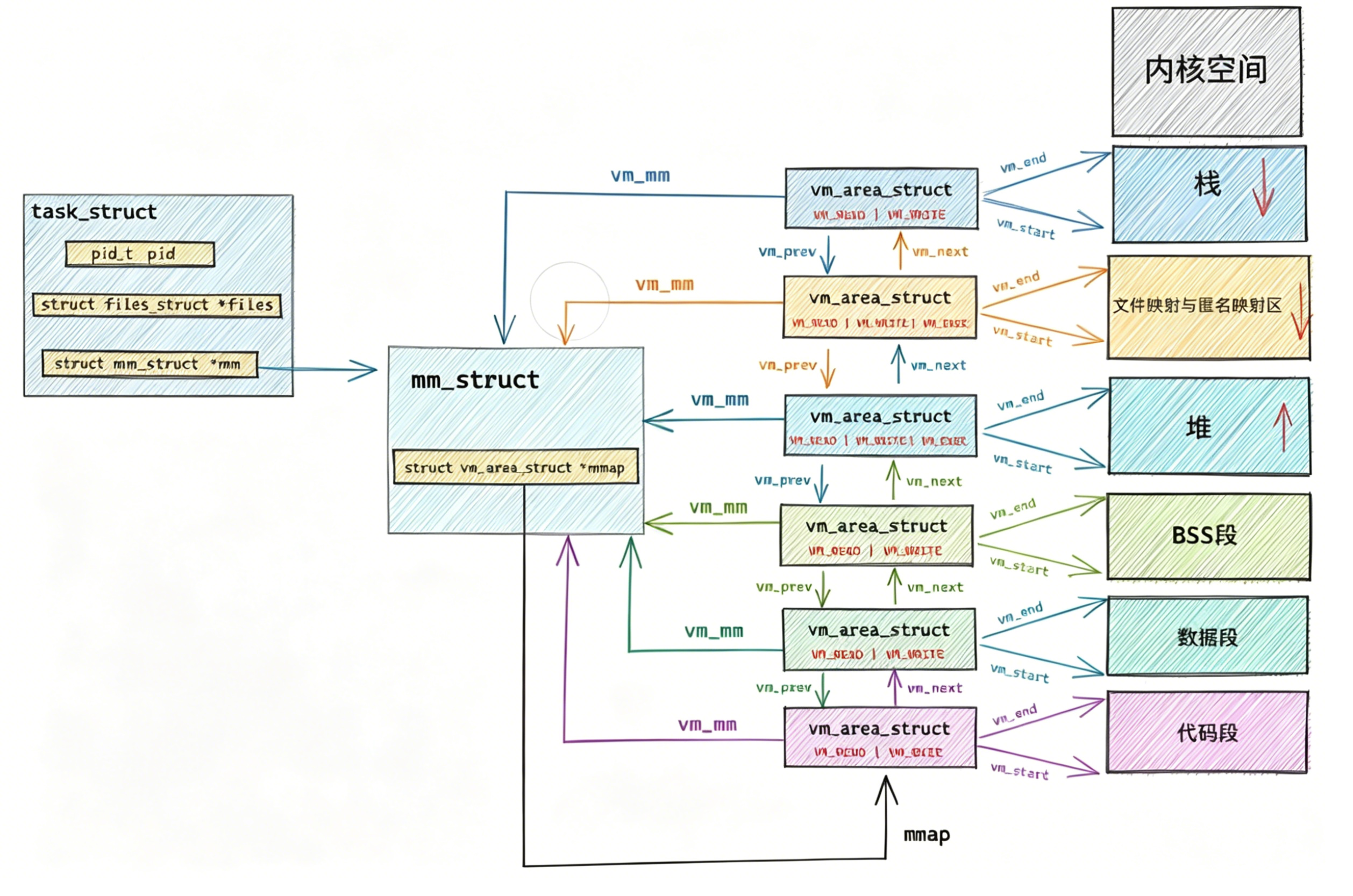
进程具有独立性:
1.内核数据结构独立
2.加载进入内存的代码和数据独立
6.为什么要有虚拟地址空间
这个问题其实可以转化为:如果程序直接可以操作物理内存会造成什么问题?
在早期的计算机中,要运行一个程序,会把这些程序全都装入内存,程序都是直接运行在内存上的, 也就是说程序中访问的内存地址都是实际的物理内存地址。当计算机同时运行多个程序时,必须保证 这些程序用到的内存总量要小于计算机实际物理内存的大小。
那当程序同时运行多个程序时,操作系统是如何为这些程序分配内存的呢?例如某台计算机总的内存 大小是128M,现在同时运行两个程序A和B,A需占用内存10M,B需占用内存110。计算机在给程序分 配内存时会采取这样的方法:先将内存中的前10M分配给程序A,接着再从内存中剩余的118M中划分 出110M分配给程序B。
这种分配方法可以保证程序A和程序B都能运行,但是这种简单的内存分配策略问题很多。
• 安全风险
◦ 每个进程都可以访问任意的内存空间,这也就意味着任意一个进程都能够去读写系统相关内 存区域,如果是一个木马病毒,那么他就能随意的修改内存空间,让设备直接瘫痪。
• 地址不确定
◦ 众所周知,编译完成后的程序是存放在硬盘上的,当运行的时候,需要将程序搬到内存当中 去运行,如果直接使用物理地址的话,我们无法确定内存现在使用到哪里了,也就是说拷贝 的实际内存地址每一次运行都是不确定的,比如:第一次执行a.out时候,内存当中一个进程 都没有运行,所以搬移到内存地址是0x00000000,但是第二次的时候,内存已经有10个进程 在运行了,那执行a.out的时候,内存地址就不一定了
• 效率低下
◦ 如果直接使用物理内存的话,一个进程就是作为一个整体(内存块)操作的,如果出现物理 内存不够用的时候,我们一般的办法是将不常用的进程拷贝到磁盘的交换分区中,好腾出内 存,但是如果是物理地址的话,就需要将整个进程一起拷走,这样,在内存和磁盘之间拷贝 时间太长,效率较低。
存在这么多问题,有了虚拟地址空间和分页机制就能解决了吗?当然!
• 地址空间和页表是OS创建并维护的!是不是也就意味着,凡是想使用地址空间和页表进行映射,也⼀定要在OS的监管之下来进行访问!!
也顺便保护了物理内存中的所有的合法数据,包括各个进程以及内核的相关有效数据!
• 因为有地址空间的存在和页表的映射的存在,我们的物理内存中可以对未来的数据进行任意位置的加载!物理内存的分配和进程的管理就可以做到没有关系,进程管理模块和内存管理模块就完成了解耦合
• 因为有地址空间的存在,所以我们在C、C++语言上new,malloc空间的时候,其实是在地址
空间上申请的,物理内存可以甚至⼀个字节都不给你。而当你真正进行对物理地址空间访问
的时候,才执行内存的相关管理算法,帮你申请内存,构建页表映射关系(延迟分配),这
是由操作系统自动完成,用户包括进程完全0感知!!
• 因为页表的映射的存在,程序在物理内存中理论上就可以任意位置加载。它可以将地址空间上的虚拟地址和物理地址进行映射,在进程视角所有的内存分布都可以是有序的。
感谢你的观看,期待我们下次再见。