从0开始的机器学习之旅(二):监督学习,从线性回归说起
上一节我们介绍了机器学习的大致分类,这一节我们开始从监督学习开始,从回归说起,逐步深入了解监督学习
一、回归方程是什么
回归方程,顾名思义,就是用来回归的方程。回归方程的目的是找到一个函数,这个函数能够将输入的特征映射到输出的目标。举个例子,现在你有一组数据,数据中包含房屋的面积和价格,你想找到一个函数,这个函数能够将房屋的面积映射到价格,这个函数就是回归方程。
回归方程为什么属于监督学习?我们之前说到,监督学习需要有X->Y的映射数据,而我们的回归方程正好就属于这个范畴,比如就像是求解最简单的Y = wX + b,我们给出两个点(1,2)和(2,3),我们将这两个点(数据)代入到方程(学习)中,得到最满足方程的w和b(参数),这个过程就是监督学习。
当然,上述提到的Y = wX + b只是最简单的线性回归方程,实际中我们可能会遇到更复杂的回归方程,比如多项式回归、逻辑回归等等,这些都是监督学习中的回归问题。它们有一个更通用的形式,就是Y = f(X) + ε,其中f(X)是我们要学习的函数,ε是误差项,表示我们无法完全拟合数据的部分。
如图所示,这就是一个典型的用房屋面积来预测价格的回归数据,我们的目标就是找到一个Y = f(X) + ε函数,使其每一个点(面积X,价格Y)都能够尽可能接近这个真实的数据点。
二、代价函数
这里我们仍然沿用上述的房屋面积和价格关系的例子Y = wX + b
(一)、参数
回归方程中的参数就是我们要学习的函数中的未知数,比如在线性回归中,参数就是w和b,我们通过学习来找到最适合数据的w和b,这样我们的回归方程就能够更好地拟合数据。举个例子,如下图:
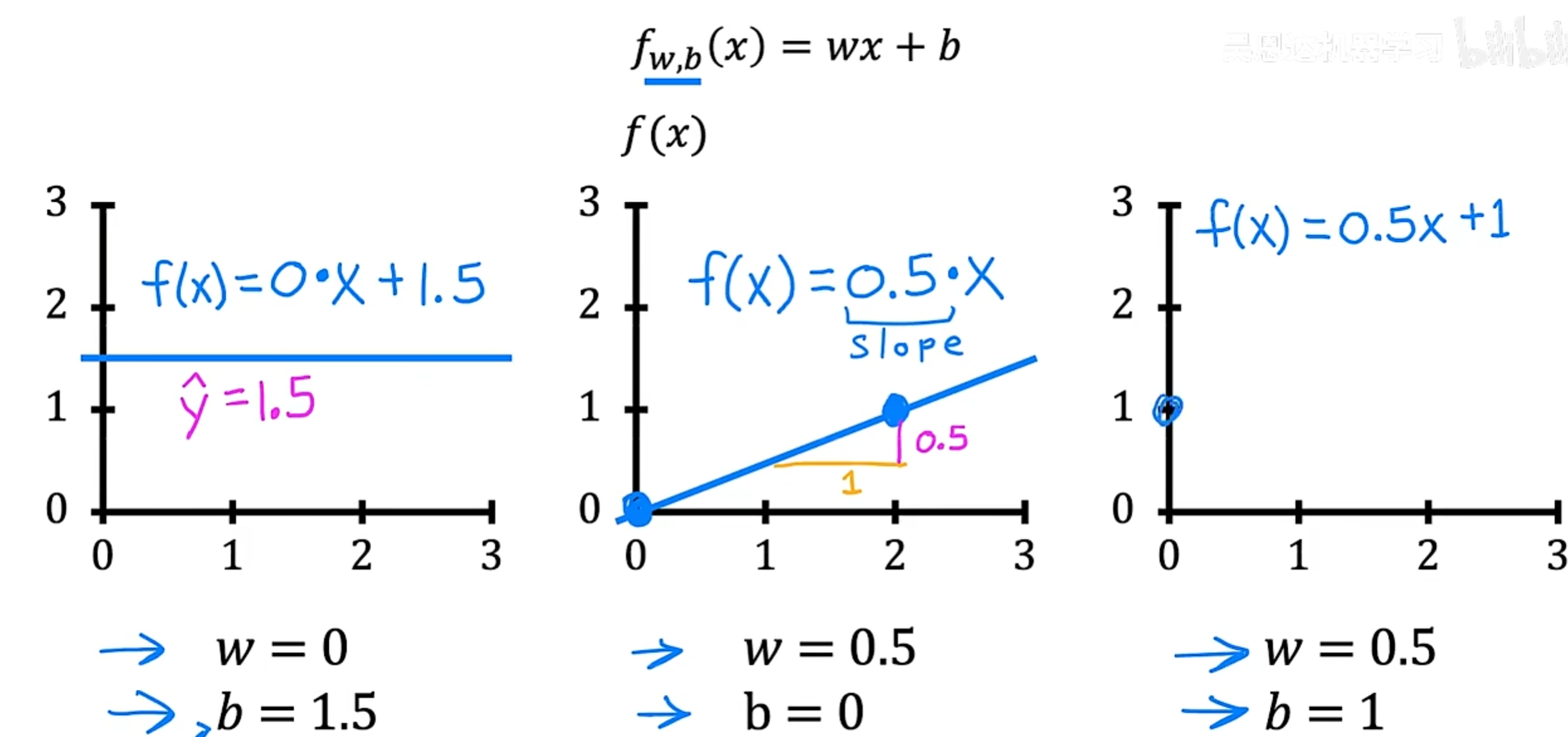
图中的w和b就是我们平时说的参数 ,w和b的不同直接影响到直线的形状,进而影响到回归方程的拟合程度。
图中的 fw,b(x)=wx+bf_{w,b}(x) = wx + bfw,b(x)=wx+b 就是我们通过学习得到的回归方程,而y^\hat{y}y^就是这个函数的输出,也就是我们预测的价格。
我们的目标就是,构造一个y^=fw,b(x)=wx+b\hat{y} = f_{w,b}(x) = wx + by^=fw,b(x)=wx+b,使y^−y\hat{y} - yy^−y的值最小。
(二)、代价函数
代价函数是用来衡量我们预测的结果和真实结果之间的差距 的函数,常用的代价函数有均方误差(MSE)和平均绝对误差(MAE)等。对于线性回归来说,最常用的代价函数是均方误差,它的定义如下:
J(w,b)=1m∑i=1m(fw,b(xi)−yi)2=1m∑i=1m(wxi+b−yi)2J(w,b) = \frac{1}{m} \sum_{i=1}^{m} (f_{w,b}(x_i) - y_i)^2 = \frac{1}{m} \sum_{i=1}^{m} (wx_i + b - y_i)^2J(w,b)=m1i=1∑m(fw,b(xi)−yi)2=m1i=1∑m(wxi+b−yi)2
也可以写成:
J(w,b)=1m∑i=1m(yi^−yi)2J(w,b) = \frac{1}{m} \sum_{i=1}^{m} (\hat{y_i} - y_i)^2J(w,b)=m1i=1∑m(yi^−yi)2
其中,m是样本的数量,fw,b(xi)f_{w,b}(x_i)fw,b(xi)是我们预测的值,yiy_iyi是真实的值。我们的目标就是最小化 这个损失函数,也就是说,我们要找到一组参数w和b,使得这个损失函数的值最小。
(三)、可视化代价函数
让我们来分析一下J(w,b)的函数图像
当b不变的时候,J(w,b)就是一个关于w的二次函数,而且由于w存在于(wx_i + b - y_i)^2中,所以这个函数是一个开口向上的抛物线。
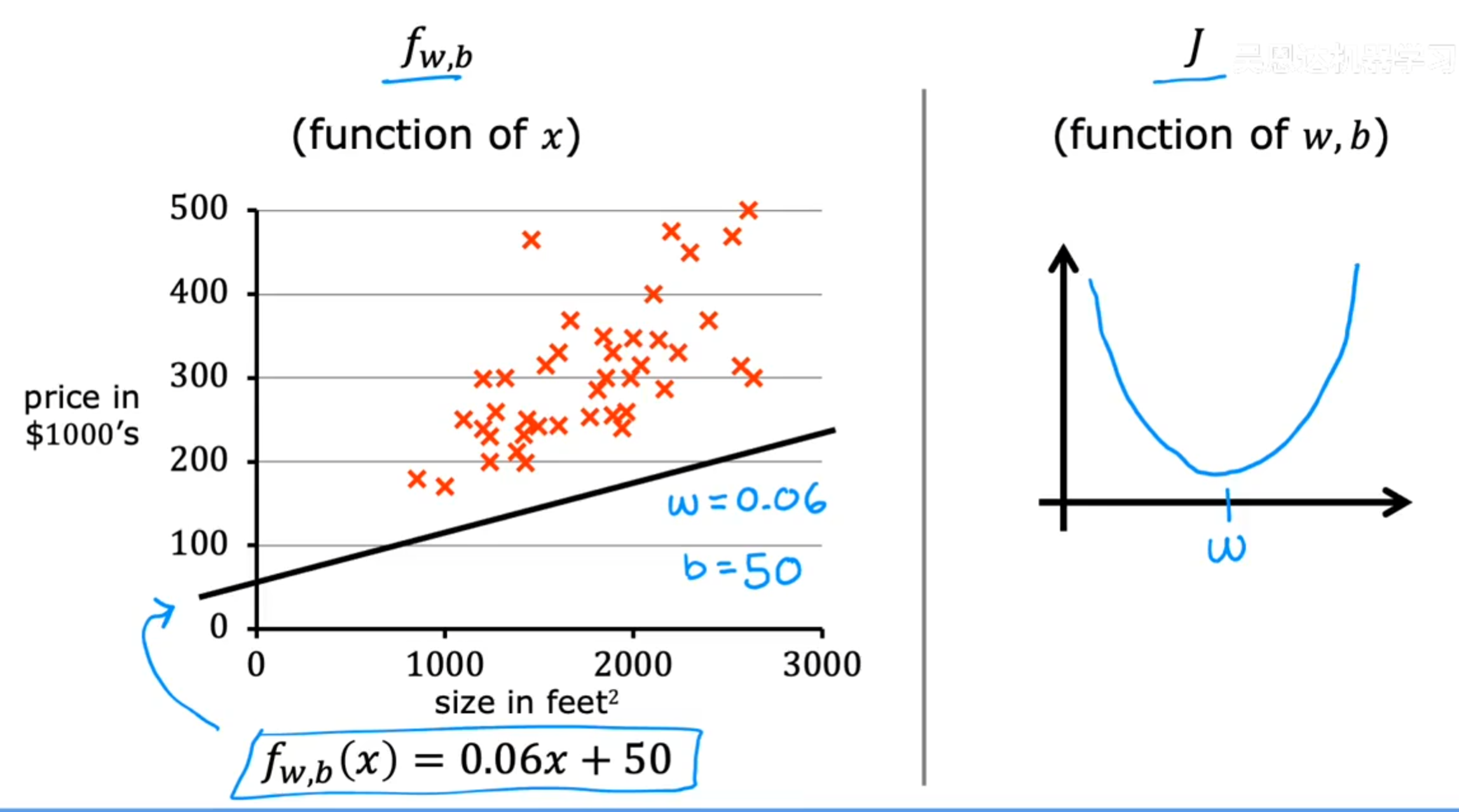
这个抛物线的最低点就是我们要找的最优参数w。同样的,当w不变的时候,J(w,b)也是一个关于b的二次函数,也是一个开口向上的抛物线,这个抛物线的最低点就是我们要找的最优参数b。
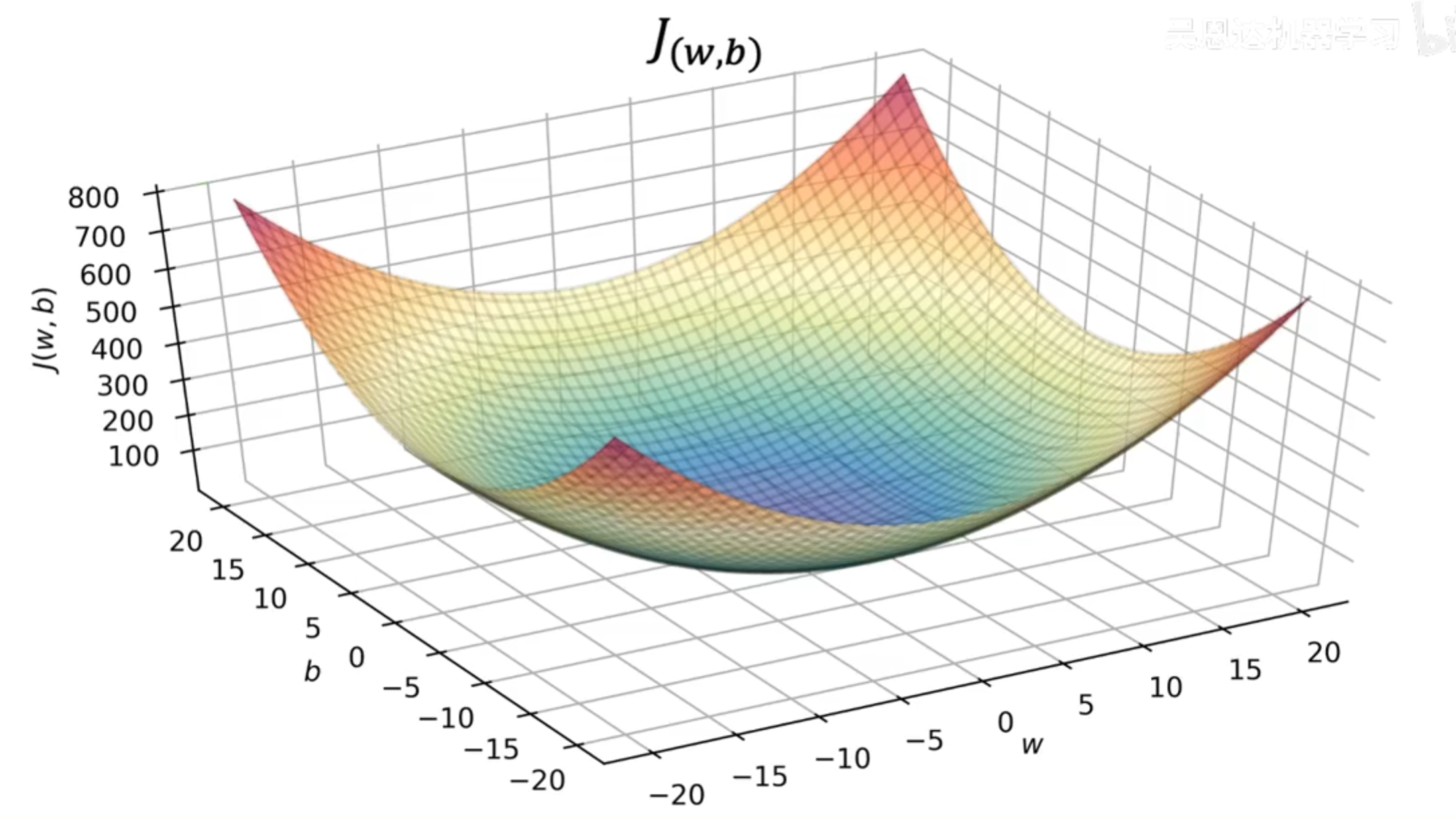
而当我们同时考虑w和b的时候,J(w,b)就是一个关于w和b的二次函数,这个函数的图像是一个三维的抛物面,这个抛物面的最低点就是我们要找的最优参数w和b。
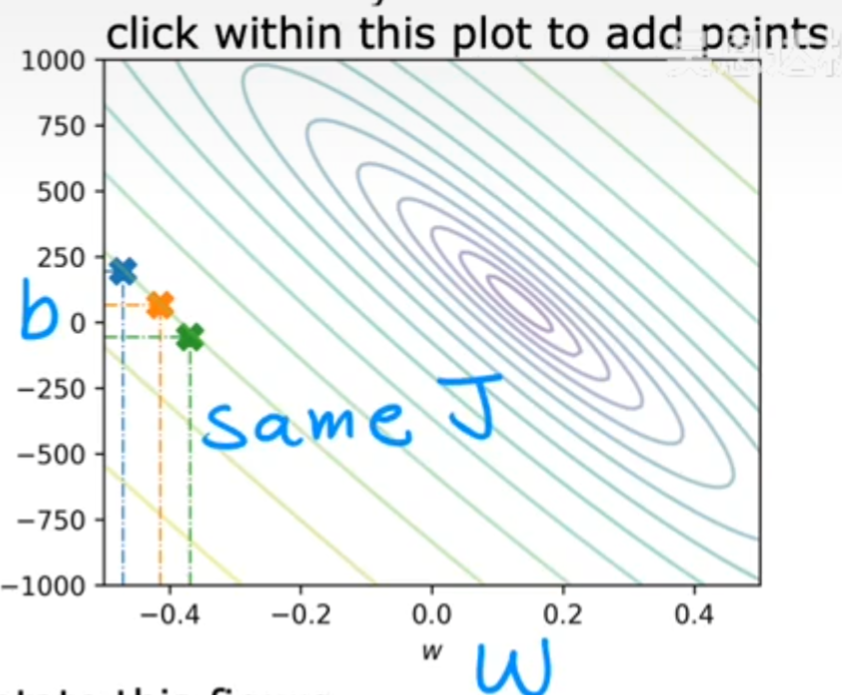
这种三维的图像可以通过类似于地理中的等高线来进行二维化,每一条闭合的等高线代表着J(w,b)的一个特定值,等高线越密集的地方,J(w,b)的值变化越快,而等高线越稀疏的地方,J(w,b)的值变化越慢。等高线的颜色用来代表J(w,b)的值。从下图可以看到,那一块紫色的区域就是J(w,b)的最低点,也就是我们要找的最优参数w和b所在的位置。
三、梯度下降,学习率
之前我们在尝试找出最佳的w和b的时候,我们都是在猜,那有没有一种方法能让我们更快地系统性 地找到最佳的w和b呢?答案是有的,这就是梯度下降算法 。
梯度下降算法不仅用在回归中,在机器学习中他无处不在,是很重要的一种学习算法
(一)、梯度下降算法
之前我们提到,我们学习的目的是找到一组值(w,b)来让代价函数J(w,b)最小,我们在高中就学过这种问题的直观解法:求导数,找到导数为0的点,这个点就是我们要找的最优参数w和b所在的位置。
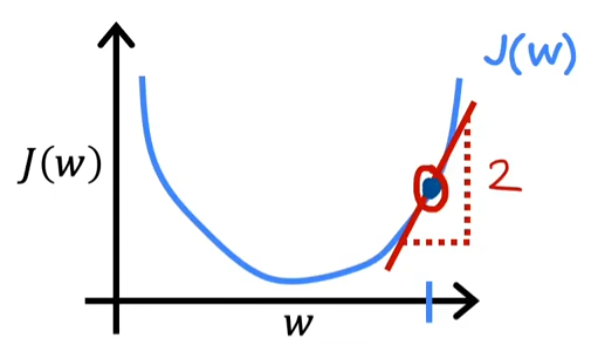
就像这张图一样,当导数为0的时候,便是最低点
先从简单的情况入手:当我们只考虑w的时候,我们的目标就是找到一个w,使得J(w)最小,我们可以通过求导数来找到这个w,具体的步骤如下:
-
重新定义模型与损失函数模型预测值:y^i=wxi\hat{y}i = wx_iy^i=wxi均方误差损失函数:J=1N∑i=1N(y^i−yi)2=1N∑i=1N(wxi−yi)2J = \frac{1}{N} \sum{i=1}^{N} (\hat{y}i - y_i)^2 = \frac{1}{N} \sum{i=1}^{N} (wx_i - y_i)^2J=N1i=1∑N(y^i−yi)2=N1i=1∑N(wxi−yi)2
-
再对内层的 wxiwx_iwxi 求导产生 xix_ixi:dJdw=1N∑i=1N2(wxi−yi)⋅xi\frac{dJ}{dw} = \frac{1}{N} \sum_{i=1}^{N} 2(wx_i - y_i) \cdot x_idwdJ=N1i=1∑N2(wxi−yi)⋅xi提取常数项并化简后,形式与之前非常相似:dJdw=2N∑i=1N(y^i−yi)xi\frac{dJ}{dw} = \frac{2}{N} \sum_{i=1}^{N} (\hat{y}_i - y_i)x_idwdJ=N2i=1∑N(y^i−yi)xi
-
这里我们就得到了一个J关于w的导数,那在什么情况下能让J下降得最快呢?**那显然是顺着梯度的方向!**具体的更新公式如下:w=w−α⋅dJdww = w - \alpha \cdot \frac{dJ}{dw}w=w−α⋅dwdJ
其中,α\alphaα是学习率,表示我们每次更新w的步长。(后面再讲解)
那如果是同时考虑w和b呢?道理也是一样的,只是从求导变成了求偏导
梯度下降的核心是计算损失函数对参数的偏导数。根据微积分中的复合函数求导(链式法则),我们需要分别对权重 www 和偏置 bbb 求偏导。
对 www 求偏导数:∂J∂w=1N∑i=1N2(wxi+b−yi)⋅xi\frac{\partial J}{\partial w} = \frac{1}{N} \sum_{i=1}^{N} 2(wx_i + b - y_i) \cdot x_i∂w∂J=N1i=1∑N2(wxi+b−yi)⋅xi
化简后为:∂J∂w=2N∑i=1N(y^i−yi)xi\frac{\partial J}{\partial w} = \frac{2}{N} \sum_{i=1}^{N} (\hat{y}_i - y_i)x_i∂w∂J=N2i=1∑N(y^i−yi)xi
对 bbb 求偏导数:∂J∂b=1N∑i=1N2(wxi+b−yi)⋅1\frac{\partial J}{\partial b} = \frac{1}{N} \sum_{i=1}^{N} 2(wx_i + b - y_i) \cdot 1∂b∂J=N1i=1∑N2(wxi+b−yi)⋅1
化简后为:∂J∂b=2N∑i=1N(y^i−yi)\frac{\partial J}{\partial b} = \frac{2}{N} \sum_{i=1}^{N} (\hat{y}_i - y_i)∂b∂J=N2i=1∑N(y^i−yi)
w:=w−α∂J∂ww := w - \alpha \frac{\partial J}{\partial w}w:=w−α∂w∂Jb:=b−α∂J∂bb := b - \alpha \frac{\partial J}{\partial b}b:=b−α∂b∂J
其中,α\alphaα 表示学习率(Learning Rate),它控制着每次参数更新的步长大小。(后面再讲解)
(二)、可视化看梯度下降
我们可以通过可视化来更直观地理解梯度下降算法。现在假如我们的参数空间是二维的,也就是只有w和b两个参数,那么我们的代价函数J(w,b)就是一个三维的面,且很复杂,如下图所示:
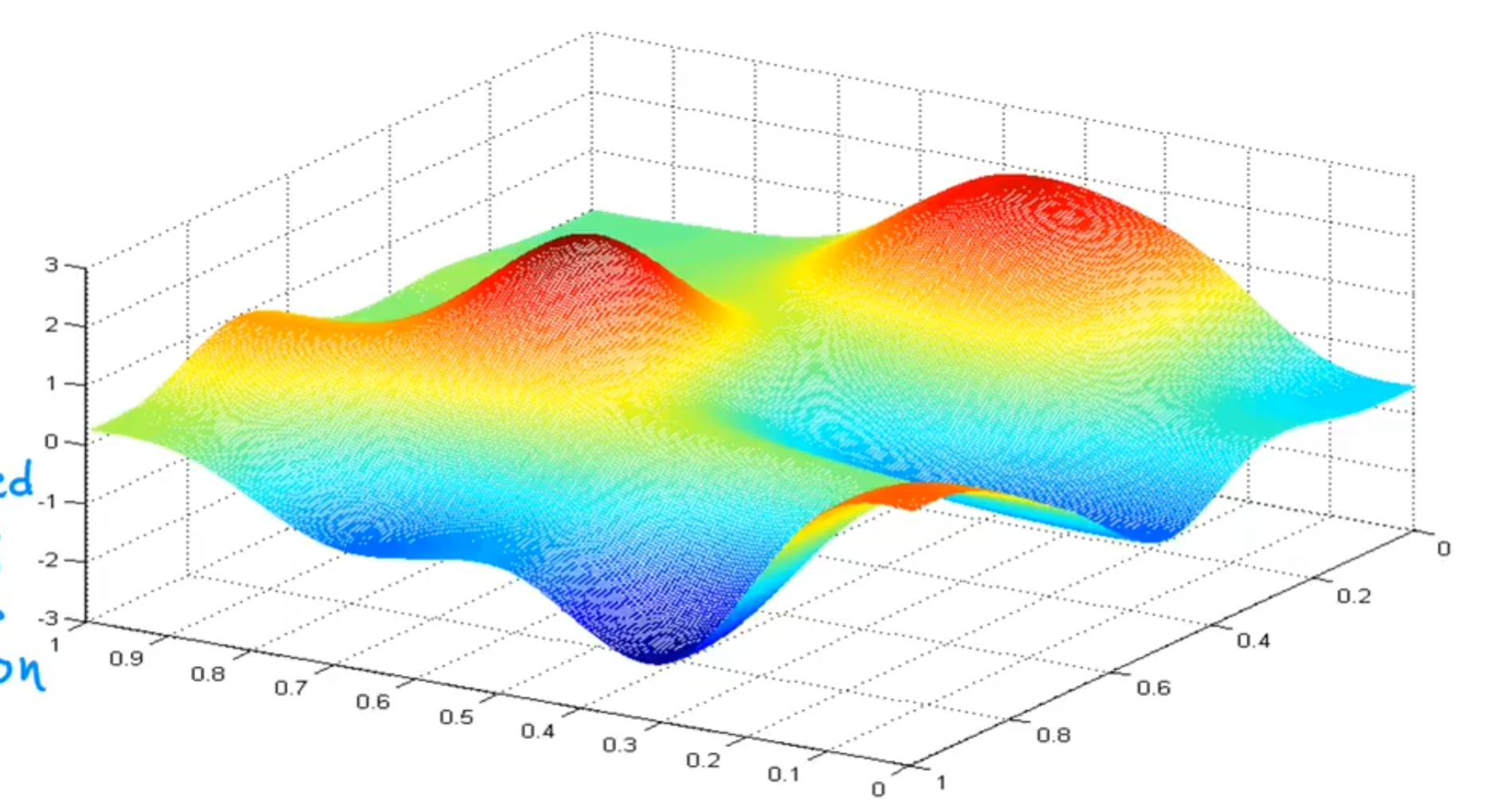
假如我们在其中的某一个点开始,想找到一个最低点,那么我们应该怎么做呢?就像我们之前说的那样,顺着梯度走,也就是沿着最陡的地方走,像爬山一样,如图
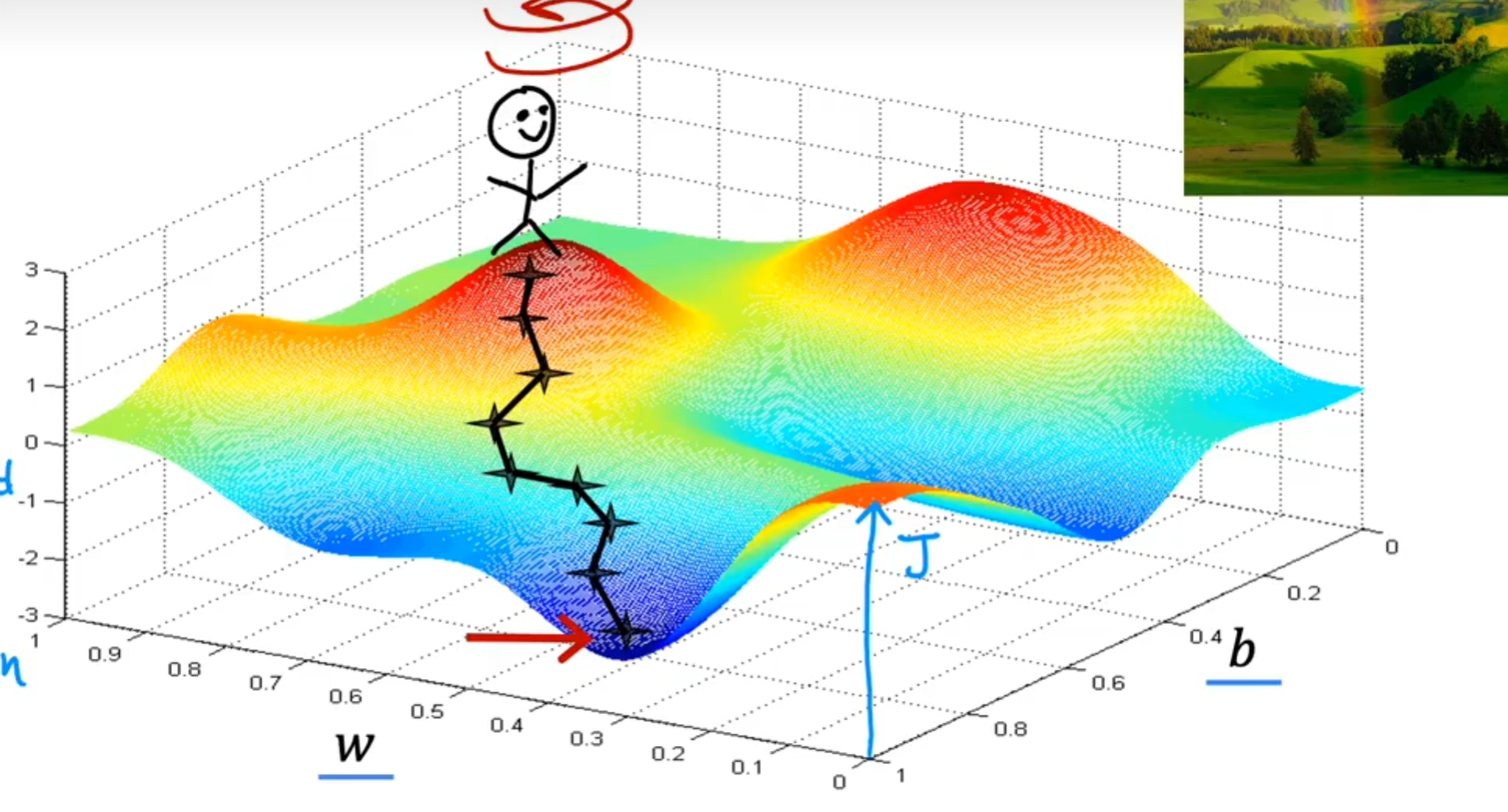
这样我们就能够一步步地接近最低点,最终找到**"最优"**的参数w和b。
真的最优吗?
可以看出,我们每一步的步长貌似也是一个变量?所有步骤的最优不一定代表全局的最优,就像贪心算法一样,为了更好的理解,我们看下一个路径
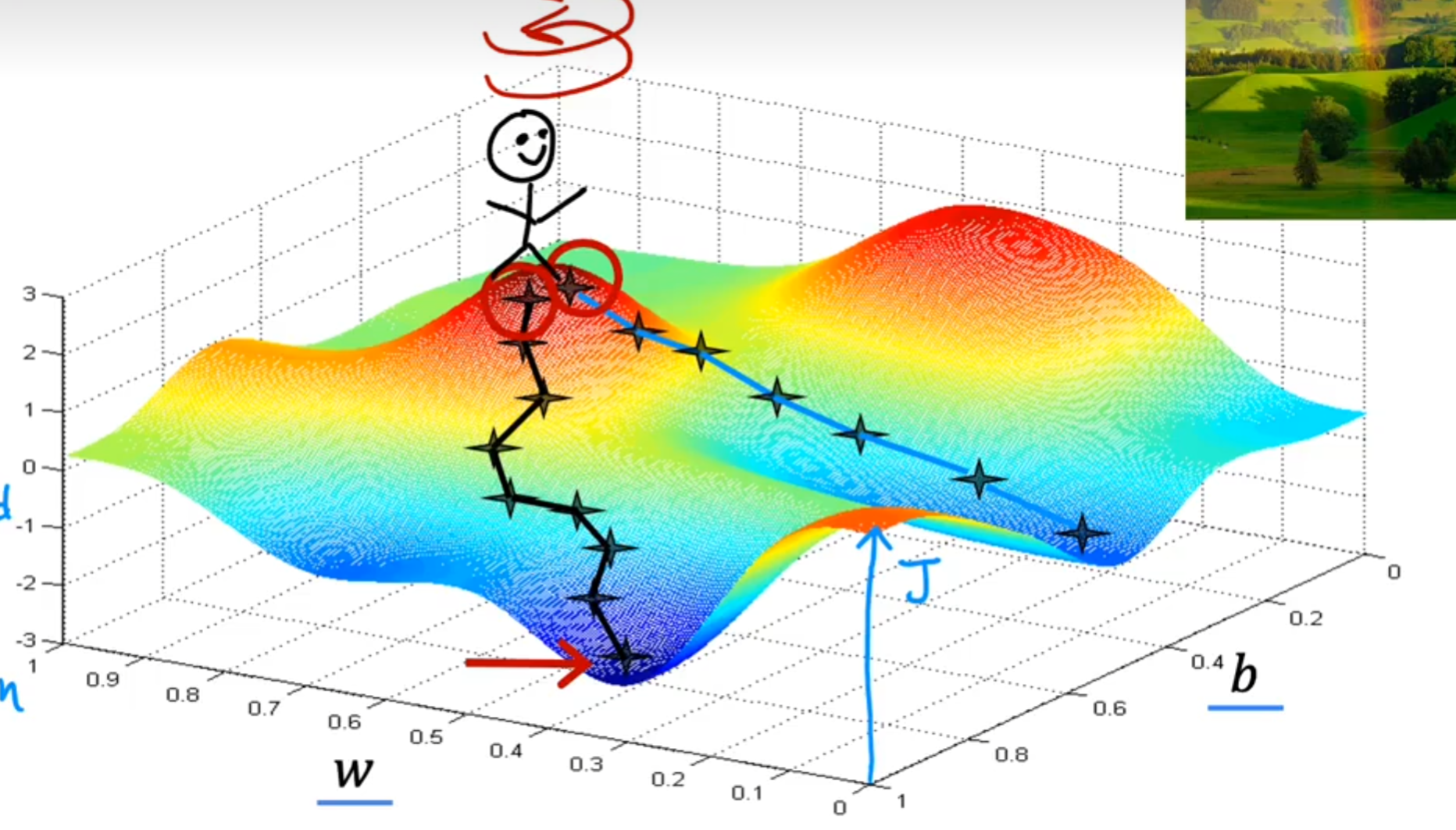
你看,这个路径的步长不同于上一条路径,它却到达了一条新的谷低!这就是步长不同导致的,梯度下降算法不一定能够找到全局最优的参数w和b,步长是其中一个重要的因素,在机器学习中,他有一个更专业的名字,叫做学习率(Learning Rate)。
(三)、学习率
学习率会对学习的结果和效率产生极其重要的影响,简单来说,学习率过大会导致我们错过最优点,甚至发散;学习率过小则会导致收敛速度过慢,甚至陷入局部最优。
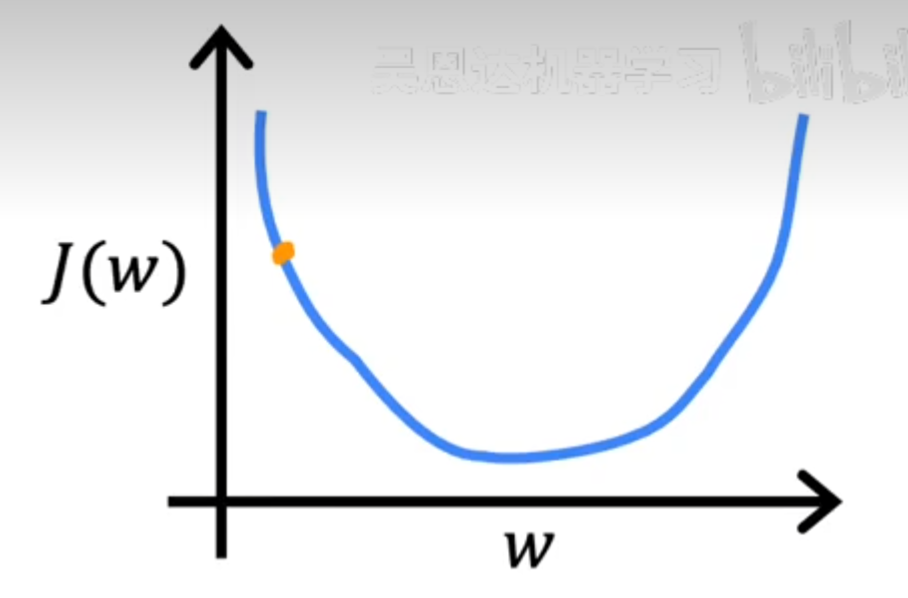
举个例子,比如下面这个图
根据上文的推理,我们可以得到
w=w−αddwJ(w)w = w - \alpha \frac{d}{dw}J(w)w=w−αdwdJ(w)
当α\alphaα很小的时候,具体的路径如下:

这里走了很多步才到达最低点,效率很低
但实际上效率低还不是最糟糕的点,当图像出现了类似"鞍"的情况时,学习率过小就会导致我们陷入局部最优,无法找到全局最优的参数w和b,如下图所示:
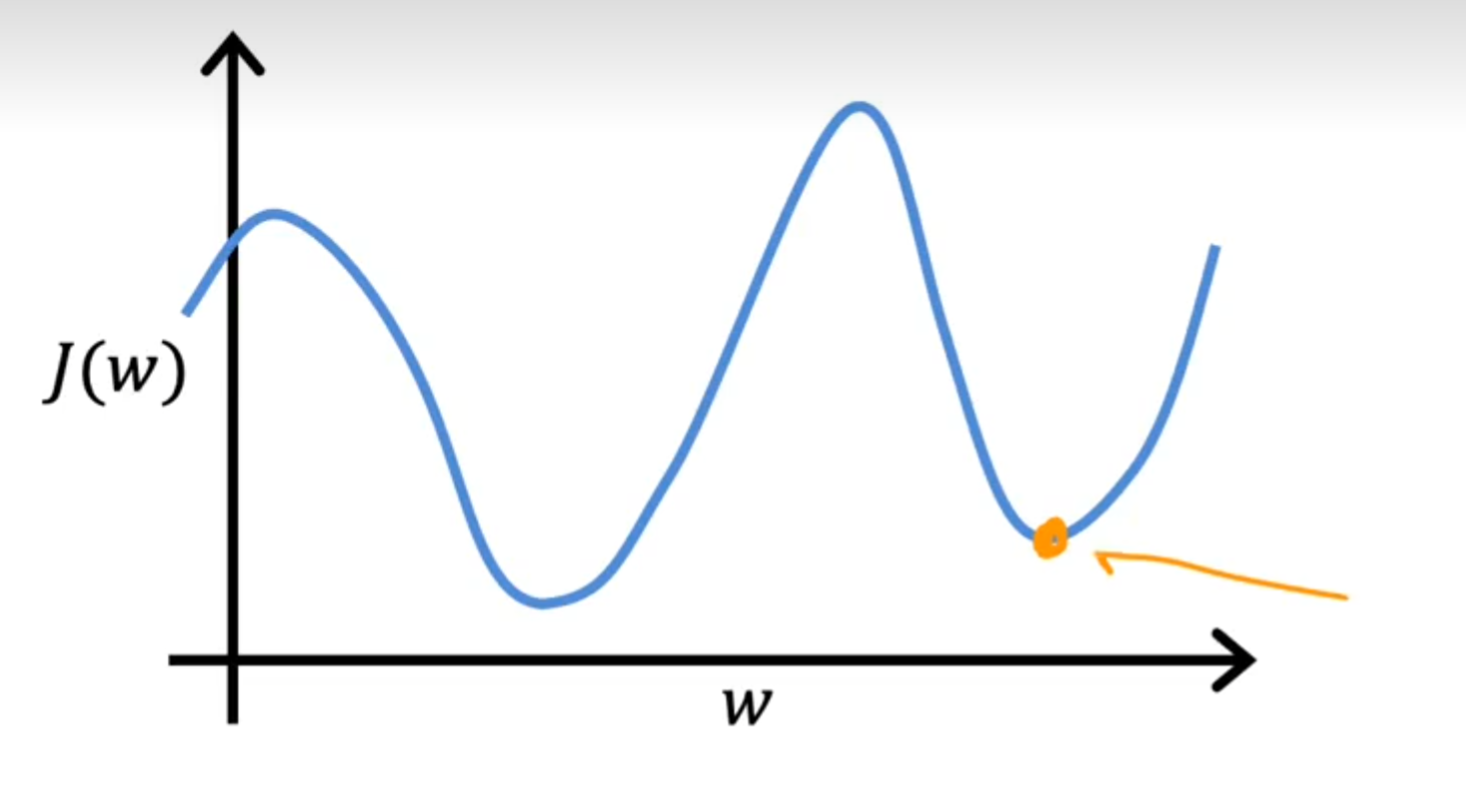
假如从最右边开始,随着一步步的挪移,它到达了第一个最低点,但这是一个局部最低,左边的最低点才是全局最低点,但由于其学习率过低,会直接停在这个局部最优,拒绝前行
那么如果学习率过大呢?我们可以想象一下,如果学习率过大,我们每次更新参数w和b的步长就会很大,这样就可能会直接跳过最低点,甚至在参数空间中来回震荡,无法收敛到最低点,如下图所示:
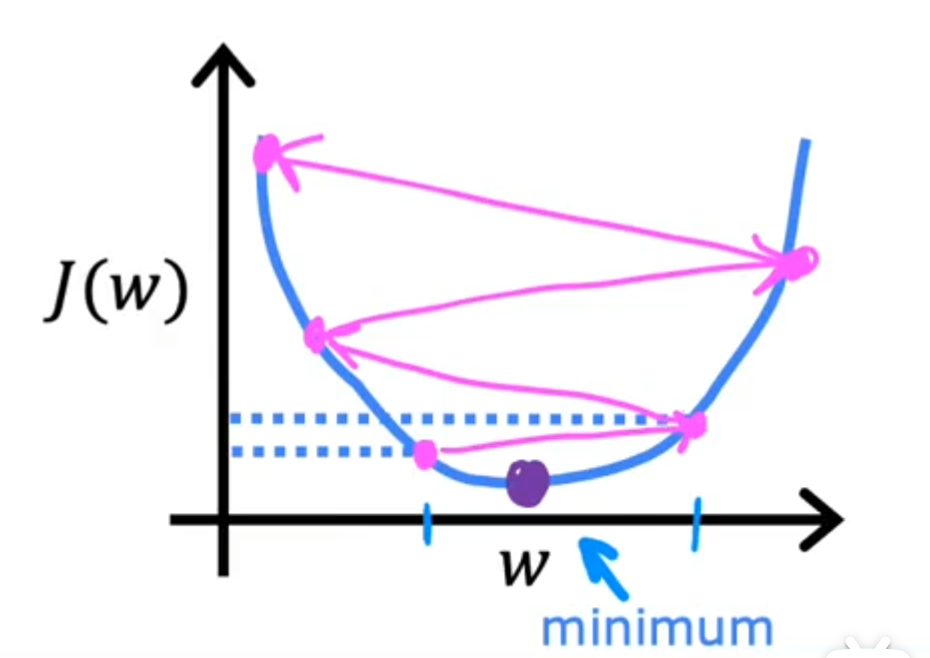
总的来说,学习率的设定是非常重要的,选择一个合适的学习率可以帮助我们更快地找到最优参数w和b,而选择一个不合适的学习率则可能会导致我们无法找到最优参数,甚至无法收敛。实际上,学习率在大多数情况下都不会是一个固定的值,通常我们会使用一些策略来动态调整学习率,比如学习率衰减、学习率预热等方法,以帮助模型更好地收敛。
四、梯度下降的优化
也许你看到这,会感觉梯度下降非常鸡肋,容易陷入局部最优,效率也不高,那么有没有什么方法能够改进梯度下降算法呢?答案是有的。
(一)、动量法(Momentum)
动量法是一种改进梯度下降算法的方法,它通过引入一个动量项来加速梯度下降的收敛速度,并且能够帮助模型跳出局部最优。动量法的核心思想是,在更新参数的时候,不仅考虑当前的梯度,还考虑之前的梯度,这样就能够在一定程度上抵消掉一些噪声,帮助模型更快地收敛。
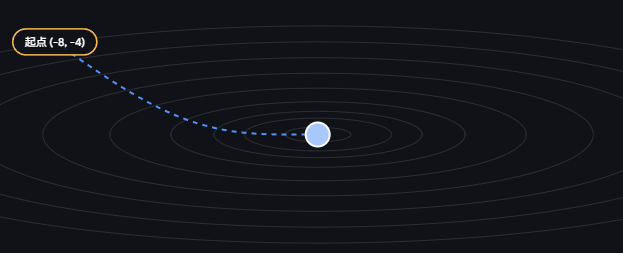
可以参考下图:
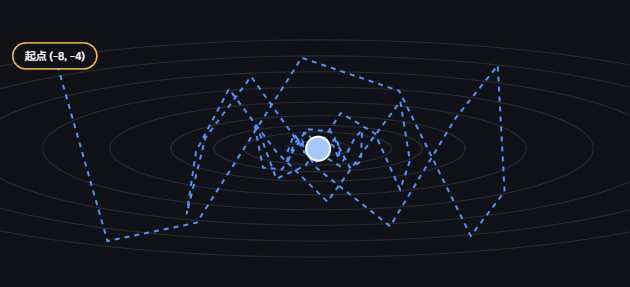
虽然这是一个典型的漏斗状数据,但由于动量法的引入,模型并不是慢慢"滑入"漏斗底,而是在漏斗周围转来转去再触底,这在一定程度上能帮助模型跨过鞍点,跳出局部最优。
(二)、自适应学习率(Adaptive Learning Rate)
这里其实之前就提到过,学习率不应该是一成不变的,应该随着训练的进行而动态调整,目前运用最广的是 RMSprop
原理可以简单的理解为,其会维护一个滑动时间窗口,不断计算参数过去梯度的平方和,更新的时候会把学习率不断除以这个平方和的平方根,这样就实现:变化快的参数会快速下降,变化慢的参数会下降缓慢,有效的避免了学习率过大导致的震荡问题,同时也能加快收敛速度。
(三)、Adam优化器
既然"动量"能加速收敛,"自适应学习率"能因材施教,那能不能把它们结合起来?这就诞生了 Adam。
其原理较为复杂,可以简单的理解为将两者结合,并发挥各自的长处,在现代的训练中,比如Transformer中,AdamW被大量使用
五、总结
这一节我们介绍了监督学习中的回归问题,算是入了监督学习的门,接下来一节我们会进入机器学习最具特色的向量与特征的领域中
Good Good Study, Day Day Up!