学完这节课后,你将能够:
-
了解什么是 RAG,以及它的实现原理
-
通过实践案例和动手实验,掌握 RAG 应用的构建方法
-
了解如何建立评测体系,驱动 RAG 应用持续改进
-
掌握 RAG 问题归因和效果改善的系统化思路
前言
你报名参与了导游志愿者活动,但对景点并不熟悉的你很难给出令游客满意的景点介绍。你意识到可以通过查询资料来帮助你完成导游工作,这时的你不再扮演知识的输出者,而是知识的总结者。同样地,给大模型配备知识库,也可以让它参考查询到的信息回答原本无法回答的问题 。这种结合了信息检索与文本生成的方法就是检索增强生成(RAG,Retrieval Augmented Generation)。
1 什么是 RAG
构建 RAG 应用是减少大模型幻觉、让其能回答私有领域知识的的有效手段。
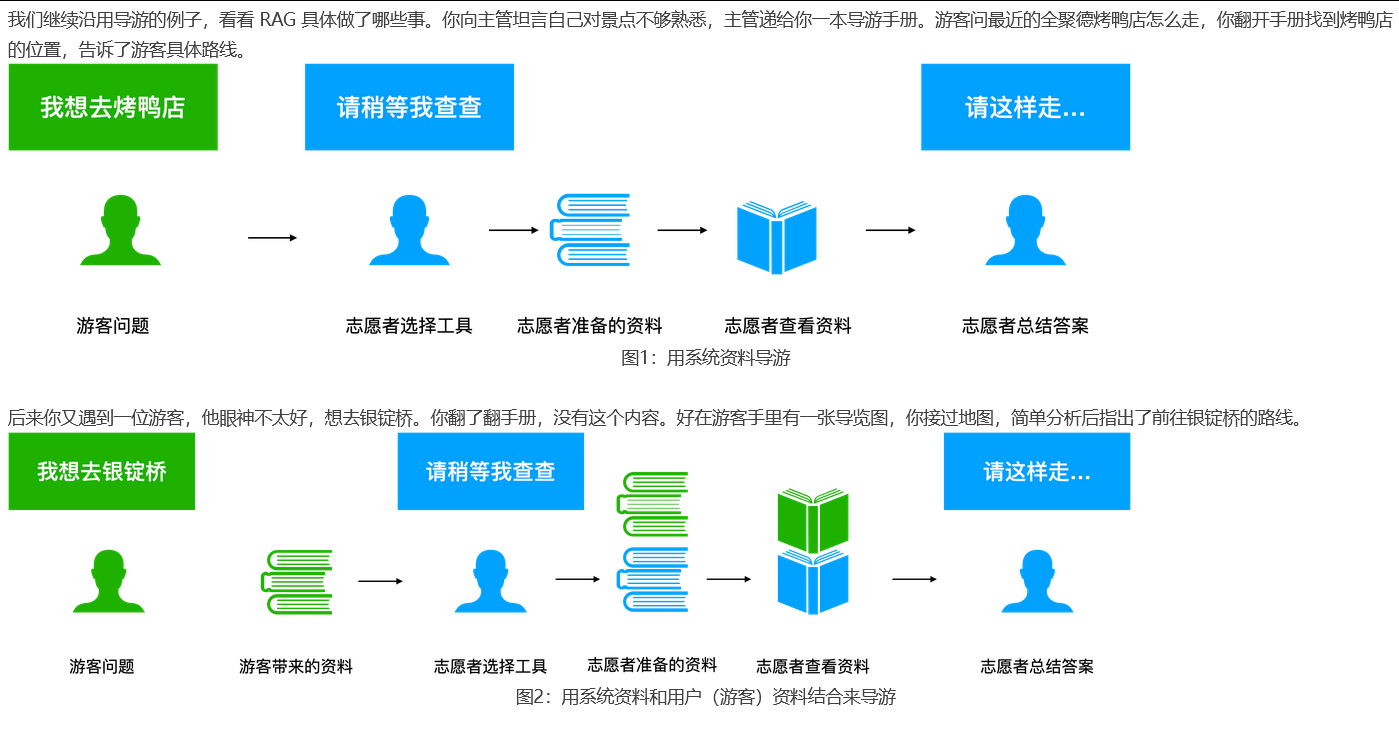
通过知识库增强大模型的能力,让它基于已有资料作答,而不是编造一个像模像样的地址。这就是检索增强生成(R etrievalA ugmented G eneration,简称 RAG)。
**RAG 包括三个步骤:建立索引、检索、生成。**准备「导游手册」的过程就是建立知识库索引;导游翻手册查资料就是检索知识库;导游基于检索到的资料充分思考并回答游客的问题就是生成答案。
2 RAG 的实现原理
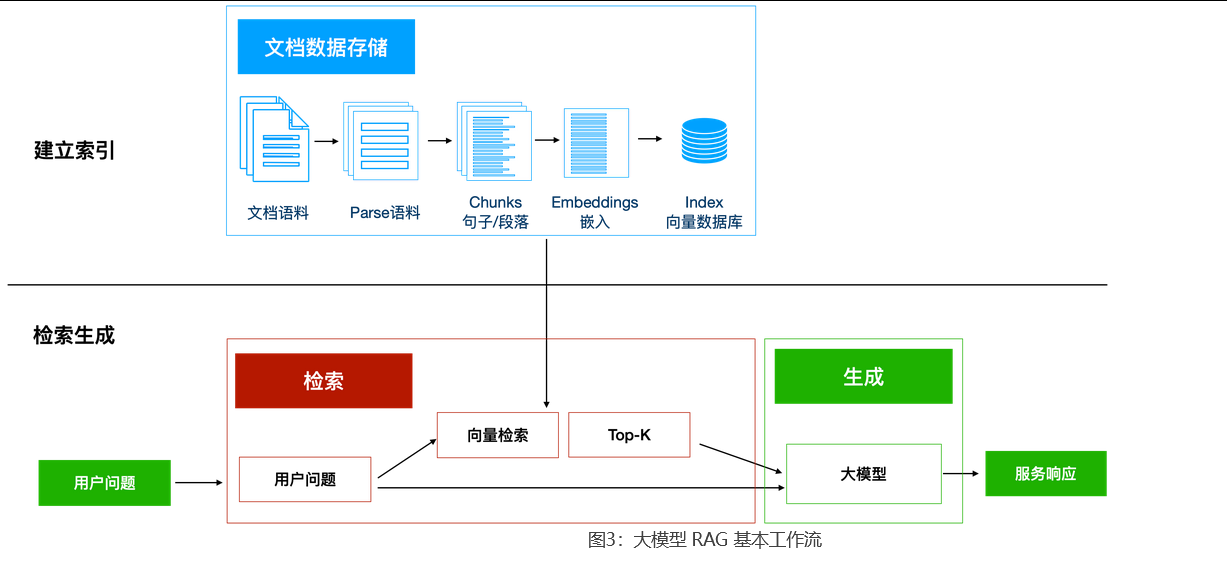
RAG 主要分两个阶段:
建立索引 :首先要清洗和提取原始数据,将 PDF、DOCX 等不同格式的文件解析为纯文本数据;然后将文本数据分割成更小的片段(chunk);最后将这些片段通过嵌入模型转换成向量数据 (此过程叫做 embedding ),并将原始语料块和嵌入向量以键值对形式存储 到向量数据库中,以便进行后续快速、高频的检索 。这就是建立索引的过程。
检索生成: 系统会获取到用户输入 ,随后计算出用户的问题 与向量数据库 中的文档块之间的相似度,选择相似度最高的 K 个文档块 (K 值可以自己设置)作为回答当前问题的知识。检索到的知识和你的问题会按一定格式组合 起来,作为提示词(就是你发给大模型的那段文字)提交给大模型,大模型给出回复。
3 RAG 应用案例:阿里云 AI 助理
以阿里云的客户服务场景为例。数百万企业客户每天会产生大量咨询需求。在高峰时段,人工客服处理咨询类工单可能需要约 1 小时,技术类工单可能需要更长时间。对于其中高频、重复、规则相对明确的咨询,如果全部依赖人工处理,不仅效率受限,也会占用客服处理复杂问题的时间。
为解决这一问题,阿里云推出了阿里云 AI 助理。它背后是基于千问大模型的 RAG 应用,知识库来自阿里云各产品的使用文档,能回答产品介绍、组合方案、迁移方案、权益查询、购买指引等问题。比如提问:
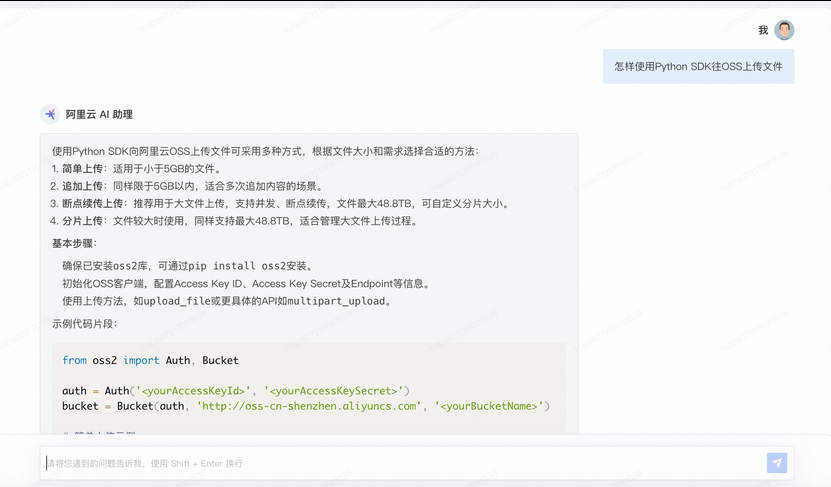
AI 助理会提供答案,并在回答最后附上它参考的文档链接,供你进一步校验。相比提工单等数小时,它平均 10 秒就能给出回答,超过 90% 的用户反馈 AI 助理「回答质量好」。
这类 RAG 应用在企业中随处可见:
-
内部知识库助手:帮员工快速检索公司制度、技术文档
-
电商导购助手:结合商品说明和用户评价,给出个性化选购建议
-
售后支持助手:对照产品手册和历史工单,快速响应售后咨询
4 持续改进 RAG 应用
构建 RAG 应用是减少大模型幻觉、让其能回答私有领域知识的的有效手段。
评测体系:建立持续优化的基础
1. 制作评测集
评测样本通常从线上用户的真实问答、工单和负反馈中随机抽取。业务专家拿到这些样本后,为每条问题写出标准答案。
用户的真实提问配上业务专家写的标准答案,就构成了评测集。评测集不是一次做完就不管了,因为用户需求会不断变化。上个月的热点(比如景区内一场已经结束的临时展览),这个月可能就没人问了。过期的问题要淘汰,新出现的问题类型要补充,不准确的标准答案要修正。建议每周从线上问答中随机抽样,只保留最近几个月(比如 3 个月)内的真实问答对,滚动维持 1000~3000 条评测样本。
2. 建立评测指标
有了评测集,还需要一套评测指标来衡量 RAG 系统的效果。
但问题是:业务关心的指标往往不能直接用来优化系统。比如景区主管关心「游客满意度有没有提升」「问题解决率有没有提升」,但这些指标只能告诉你「出问题了」,不能告诉你「问题出在哪」。技术指标才能定位系统的问题,把这些问题逐一优化后,RAG 系统的效果通常会随之改善。
因此,你要把业务指标拆解为具体的、可量化和可优化的技术指标。
怎么拆?可以像考核一名导游的讲解服务一样,先把「游客满意度」下钻到回答过程中的关键环节,比如是否听懂了游客的问题、有没有从手册中准确找到相关的资料等。对应到 RAG 系统中,这些环节可以映射为意图理解、知识检索、答案生成等模块。只有先定位到某个具体的模块,技术指标才有明确的评估对象。
-
检索模块:
-
**准确率(Precision):**检索到的文档有多少是真正相关的
-
**召回率(Recall):**相关文档有多少被检索到了
-
-
生成模块:
-
**相关性:**回答是否切题
-
**忠实度:**是否基于资料回答,没有编造
-
**完整性:**信息是否充分
-
**流畅性:**表达是否自然
-
这些技术指标怎么影响 RAG 系统的效果?举个例子:如果检索的召回率从 30% 提升到 70%,意味着系统多找回了 40 个百分点的相关信息。用户不用反复追问,一次就能拿到完整答案,满意度自然上升,工单量也会下降。
3.执行评测
每周,景区主管会从上周游客提出的问题中抽查一批,逐个看导游是怎么回答的。不只是看「答得好不好」,更重要的是看「哪里出了问题」。这就是专家评测。但专家评测很消耗人力,容易成为版本频繁迭代的瓶颈。对于需要日常批量评测的场景,可尝试用自动评测快速回归验证,判断新版本是否稳定变好。
专家评测
业务专家定期从线上用户的真实问答中抽样审查,让团队持续掌握用户满意度的变化。发现异常时,业务专家要及时分析原因(归因方法在第 6 节展开)。归因清楚后,按问题类型分派改进:
-
**技术团队:**负责优化意图理解、检索、生成等问题
-
**业务专家:**负责补充知识库内容、更新知识、修复错误
-
**产品团队:**负责处理业务规则类问题
同时,专家每次审查还会产出新的评测样本,从而覆盖更多场景,持续扩展下面将讲到的自动评测能力。
自动评测
专家评测发现问题后,团队会做相应修复,比如调整检索算法、优化系统提示词等。但修完之后,新问题来了:这次改动到底是改好了还是改坏了?核心技术指标有没有退化?如果每次改动后所有场景都要依赖业务专家重新人工做评测,专家就会成为系统迭代速度的瓶颈。
这时,前期沉淀的高质量评测集就派上用场了。对于评测集已覆盖的场景,直接交给机器快速批量对比验证。
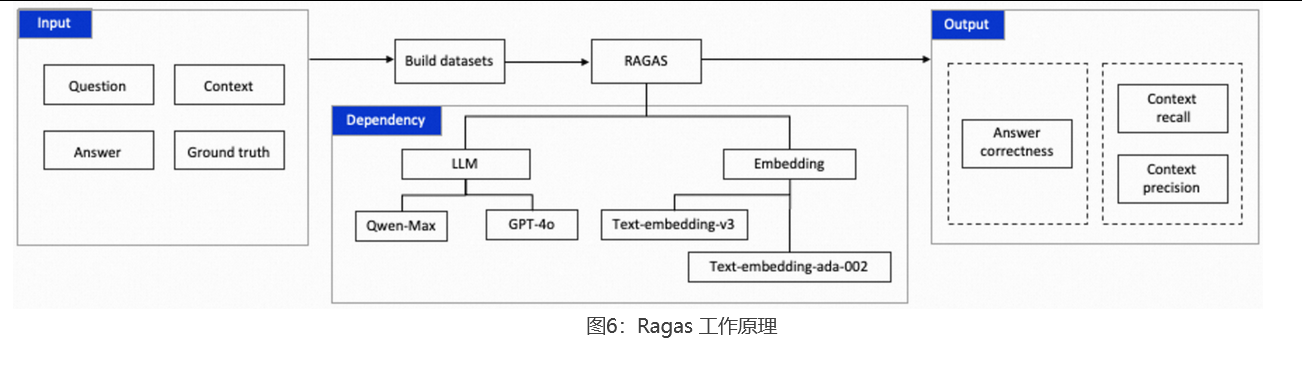
具体做法是:用前面提到的 Ragas 框架 ,基于同一套评测集,分别跑基线版本 和新版本,对比关键指标的变化。指标整体提升且核心指标没有退化,说明改动有正向收益;某些指标下降,也能帮助定位问题出在哪。
上线判断
上线判断不应只看技术指标。另一种做法是用 **GSB(Good / Same / Bad:新版更好、基本持平、新版更差)**对新旧版本在评测集上的表现进行逐条样本对比,再统计 Good / Same / Bad 三类结果的占比。一个可以参考的经验是:当超过 20% 的样本变好,且不超过 10% 的样本变差时,可以考虑上线。
总体来看,专家评测和自动评测应长期并行、相互补充。专家评测 适合关键场景和新场景的评测、掌握用户满意度和意图空间变化、发现异常、沉淀新的评测样本与指标;自动评测适合日常批量评测,用于版本迭代后的批量回归验证,判断新版本是否稳定变好,发现潜在退化,降低上线风险。
5、如何归因问题
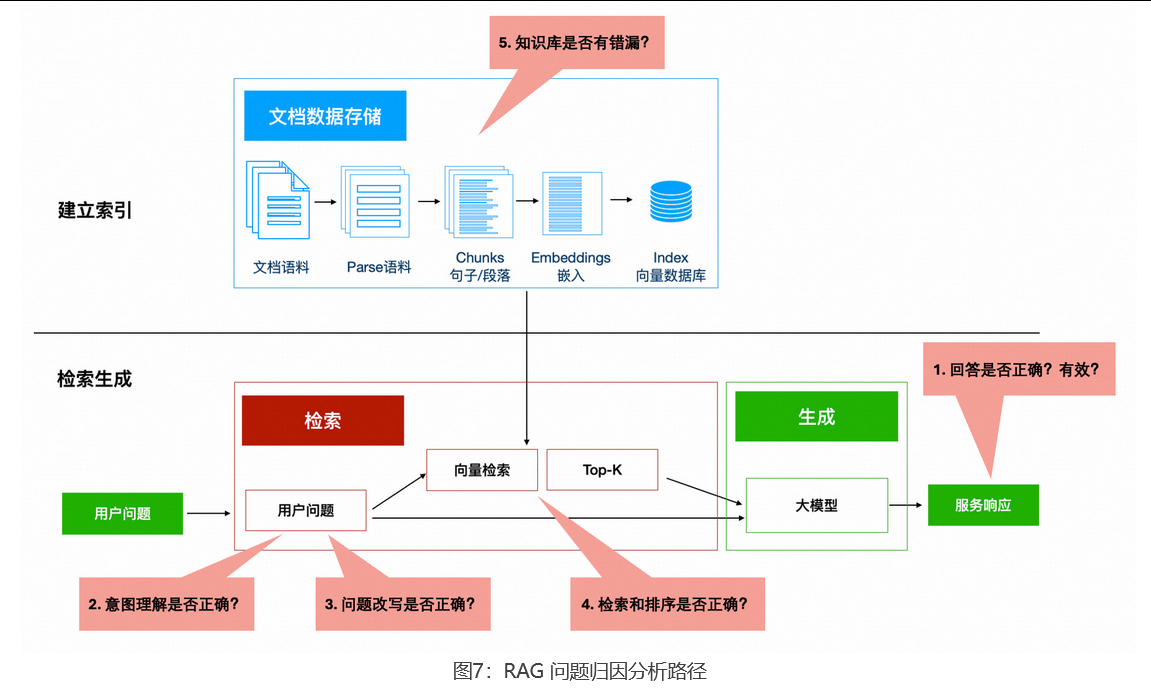
五步归因分析法
第 1 步:回答是否解决了问题?
游客问路,你的回答让他找到了目的地吗?如果游客走到湖边无路可走,说明回答完全不对。如果你讲了一大堆景点历史但没说怎么走,说明回答太啰嗦、没切中要点。
核心看两点:用户照着 RAG 系统的回答去做,能不能得到预期结果;RAG 系统的回答是否言简意赅。
第 2 步:系统理解对了吗?
如果系统回答不对,先看 RAG 系统有没有理解对用户的意图。游客问「兰州拉面去哪吃?」,导游需要判断:查手册(RAG)?掏手机搜索(上网搜)?还是转给其他导游(转人工)?如果判断错了方向,后面做得再好也没用。意图理解决定了 RAG 系统应该走哪条路径来回答问题。
关键点:第 1 步看结果,第 2 步看方向。一前一后,是把握回答正确性的关键。
第 3 步:问题改写跑偏了吗?
在确认系统没有误解用户意图后,下一步需要检查它拿去检索的内容是否合理 。有些 RAG 系统会先改写用户的问题,让它更适合检索,因为用户的输入往往信息不全、表达模糊。但如果改写时扭曲了原意就有问题了。比如用户问「附近有茶叶店吗」,改写成「附近有奶茶店吗」,导致后续检索方向跑偏。
第 4 步:检索和排序是否正确?
假设 RAG 系统判断需要查手册(走 RAG 路径),那就要看检索到的内容是否正确。在评测时,业务专家心里有标准答案,用标准答案对照系统检索出来的内容。看三个方面:
第一,找到的内容相不相关。翻到「兰州拉面的历史」明显不对,这是准确率的问题。
第二,专家知道应该有的内容有没有被遗漏。手册里记录了 8 家店只找出来 2 家,这是召回率的问题。
第三,排序对不对。找到了 10 条关于拉面的信息,但真正有用的「附近拉面店地址」排在第 8、9 条,前面全是烹饪方法和历史典故。**排序不好,大模型就要在一堆无关信息里大海捞针,反而容易被误导。**第 7 节会讲怎么用精排解决这个问题。
第 5 步:知识库本身有没有问题?
还有一种可能:手册里根本没记录这家店,或者记录的地址是错的。这时要检查知识库内容是否有缺失、是否准确。
构建业务需要的 RAG 系统
总体来看,构建业务需要的 RAG 系统,核心是持续对齐「意图空间」 和**「知识空间」的过程。**
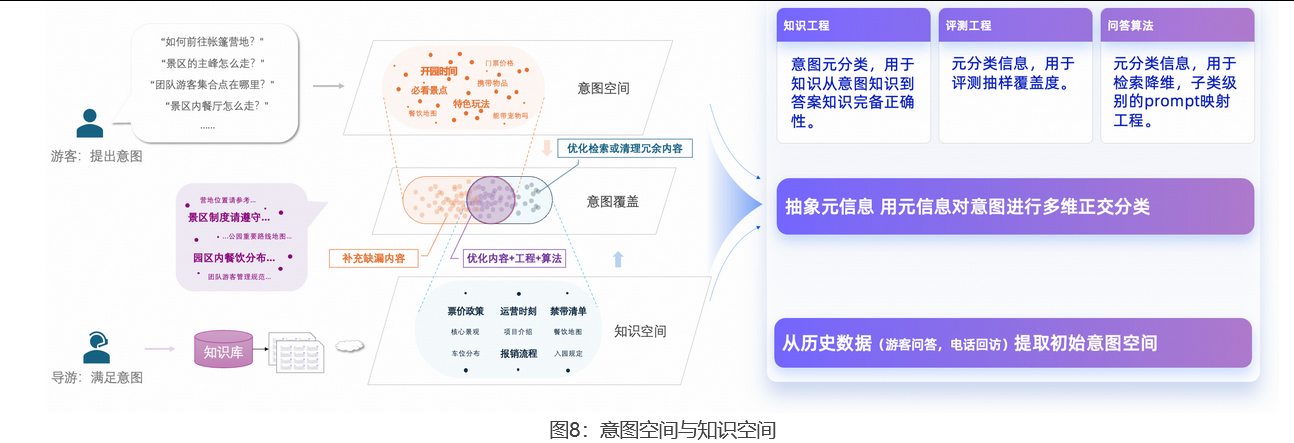
如上图所示,把用户可能问的问题 (意图空间)和 RAG 系统存的文档、规则、业务知识(知识空间)在元信息层面进行多维正交投影:
-
针对意图空间没有被知识空间覆盖的部分 ,需要业务专家补文档、更新规则,让知识跟上用户需求的变化。
-
针对知识空间中过期、重复或低质量内容的部分 ,会干扰检索和生成 ,需要业务专家和技术团队一起清理。
-
只有在知识空间和意图空间交叠的部分,才能通过工程和算法优化来持续迭代提升效果。
6、如何改善 RAG 效果
当一个 RAG 系统的知识问答不准确时,你可以从多个角度做改进:提升知识库质量、提升意图识别准确率、选择合适的信息来源、优化检索方式、精选送入大模型的内容、升级基座模型。
1 、提升知识库质量
知识库从原始文档 变成可检索的内容 需要经历一系列步骤,其中有解析 和切分两个环节。这两个环节的质量直接影响后续检索效果。
①提升文档解析效果
知识入库前首先要进行文档解析,从 PDF、Word、图片等原始资料中提取文字和结构,是内容提取的核心。
解析质量直接决定知识库最终能留住多少内容,以及这些内容是否完整、准确。尤其是表格、图片和复杂排版,一旦解析时丢了结构,后续检索就很难拼出完整答案。
来看一个具体场景:你上传了一份关键人员联系信息汇总 PDF,里面有一张人员信息表。系统解析后,你发现表格变成了零碎的文字,一些重要信息被跳过。你问「王芳的联系方式是什么?」,大模型答不上来,因为它压根没完整看到那张表。
为什么会这样?传统做法用 OCR(Optical Character Recognition,光学字符识别)等规则化工具提取文字。OCR 能识别标准文字,但它只认字不认结构,遇到表格、图注、复杂排版时,内容之间的层级和关联关系就丢了。
业界更优的做法是用 AI 驱动的智能文档解析,比如阿里云的文档智能。这类工具不只识别文字,还能理解文档的结构,区分标题、表格、图注,保留层级和关联关系。
目前前沿方向之一的 Visual RAG,可直接把图片或者图表作为检索对象,用视觉语言模型理解图片内容,再基于检索到的视觉证据回答问题。
②优化文档切分方式
文档解析更好了,下一步是切分 :把整份文档切成许多片段,再放进知识库 ,这样大模型在回答问题时能更精准地找到相关内容。
你可能会问:主流大模型已经支持很长的上下文,直接把整篇文档塞进去,回答不是更全面吗?
但大模型并不会「均匀地注意」 一篇超长文本中的所有信息。实际测试发现:它对开头和结尾关注多,位于中间的内容则容易被忽略 。这个现象叫 Lost in the Middle。上下文越长,大模型可能遗漏的细节就越多,甚至会给出看起来完整、实际却不可用的回答。
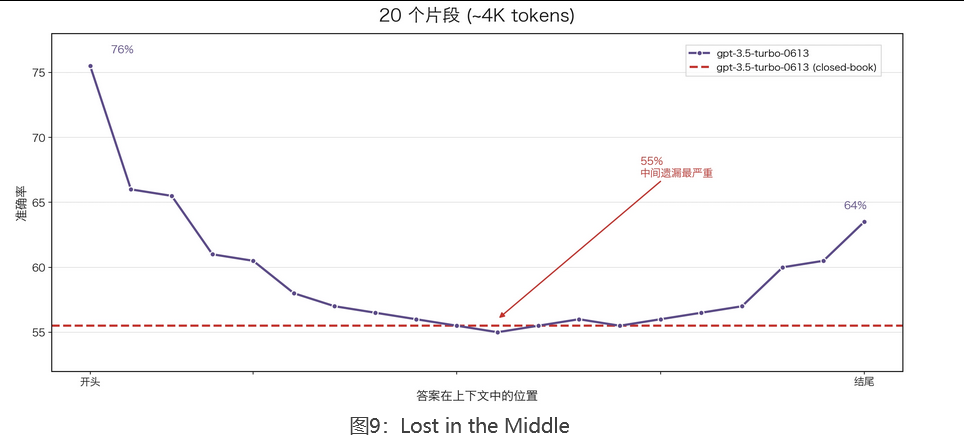
所以 RAG 的策略是先把文档切成小片段,只挑最相关的几段送进大模型,切分质量会直接影响检索效果。
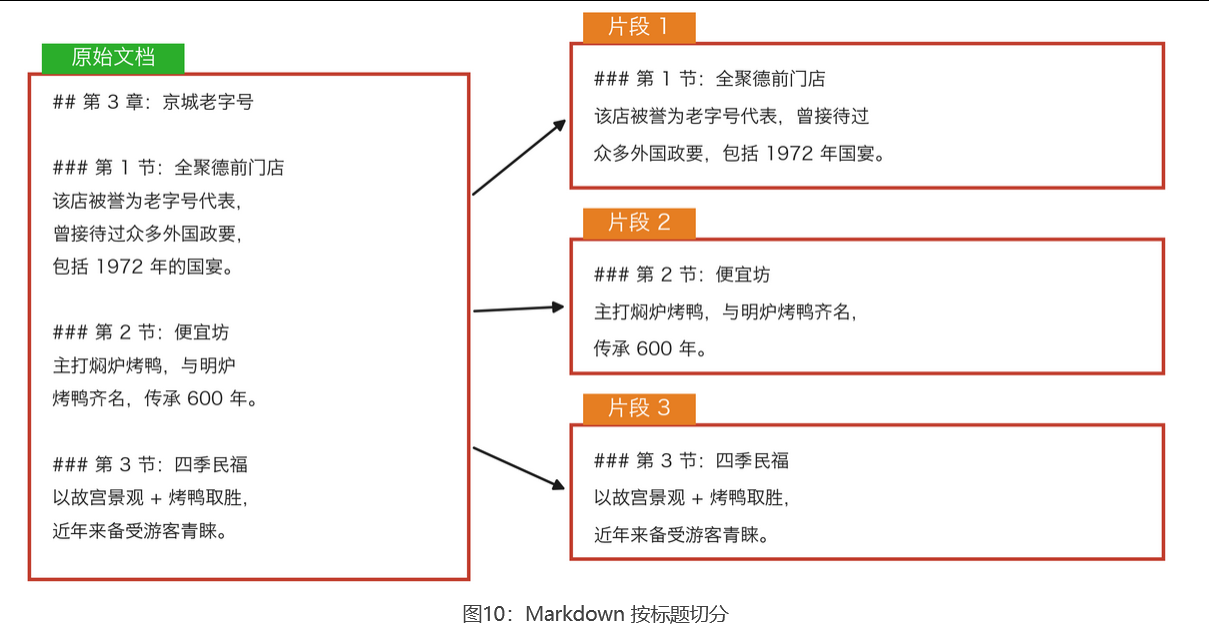
基于结构切分(Structure-Based Chunking): 像 HTML、Markdown、LaTeX、代码、Excel 等文件自身携带结构信息,切分时 应优先利用这些结构,使每个片段保留标题、层级、段落关系、注释、公式等上下文,而非简单按固定字数截断。
-
**HTML:**HTML 的标签天然标记了文档结构,比如 <h> 标识标题层级、<p> 标识段落。切分时可依据这些标签识别结构边界,避免将一个完整的小节或段落截断。
-
**Markdown:**Markdown 的语法(标题、列表、代码块等)可直接作为切分依据。推荐的做法是先按标题层级划分内容,再在过长的章节内部进一步拆分,保证每个片段的语义完整。
-
**LaTeX:**LaTeX 通过 \section、\subsection 等命令组织内容。切分时可沿这些结构边界划分,并将公式与其前后的解释文本保留在同一片段中,避免丢失关键上下文。
-
**代码文件:**代码的切分不应按行数机械截断,而应基于函数、类或 AST(抽象语法树)结构进行。这样可以保证每个片段在语法上完整,同时保留调用关系和实现意图,便于后续 RAG 系统理解。
-
**Excel:**Excel 文件的首行通常是表头(字段名),后续各行是数据记录。如果将每行数据切为独立片段,模型看到的只是「张三, 28, 上海」这样的裸数据,后续在检索时 RAG 系统无法判断各列的含义。推荐的做法是将表头拼接到每个数据行,比如「姓名:张三,年龄:28, 城市:上海」,让每个片段都携带完整表头。
-
语义切分(Semantic Chunking): 不按字数也不按标题,而是按含义自动找切分点。即使没有明显结构,也能把语义完整的段落保留在一起。但切分边界处的信息难免会出现丢失。
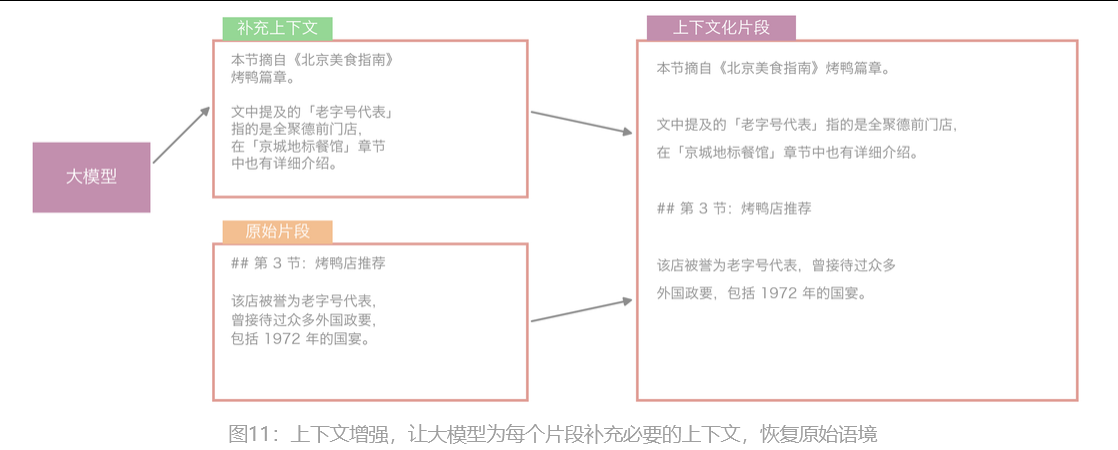
上下文增强(Contextual Retrieval)
切分之后,每个片段脱离了原文,导致 RAG 的检索系统无从判断片段原先属于文档哪个部分、与其他部分什么关联。这个问题的解决思路是,在切分后再补一步上下文增强(Contextual Retrieval): 给每个片段前都补充一段「背景上下文说明」,比如「本节摘自北京美食指南......」,让片段即使脱离原文,也能保留必要背景。这是目前的前沿方向之一。
2 提升意图识别准确率
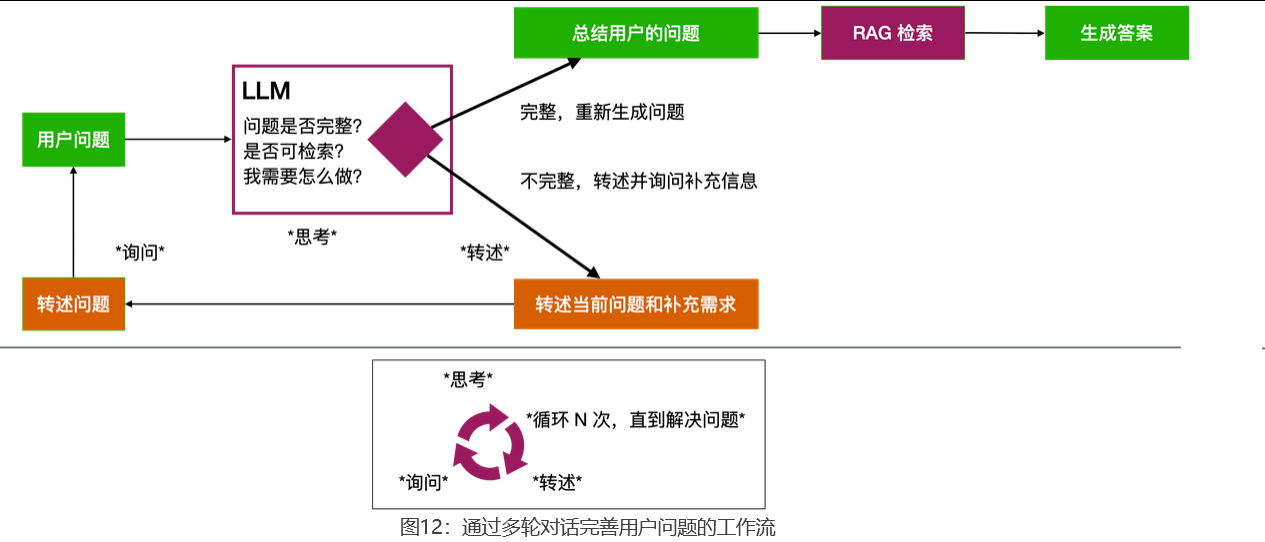
游客说话往往口语化、不够精确。比如,游客说「我想吃烤鸭」,新手导游直接翻手册查找「烤鸭」两个字,找到几家店,随便挑一家回答。游客不满意:「我想找一家老字号,人均消费要在 200 以内。」
问题出在哪?游客起初提供的信息太少,而他的需求不只「烤鸭」两个字,还有「老字号」「人均消费」等隐含条件。新手导游没法准确地理解用户真正想问什么,自然找不到最合适的结果。解决办法:先追问。「您想去老字号还是新派?预算多少?」把模糊需求补全再去查,命中率高得多。这种策略叫追问补全(Query Enrichment)。
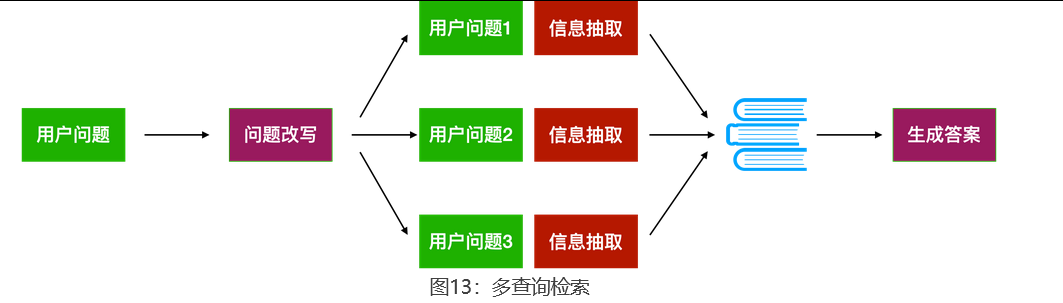
但如果游客自己也说不清楚,此时追问也问不出更多信息。怎么办?不要只从一个方向查。同时想到「适合游客的北京烤鸭餐厅推荐」、「北京老字号烤鸭店有哪些」、「人均消费低的北京网红烤鸭」,针对每种理解方向去查一遍手册,再综合所有结果给出答案 。这种策略叫多查询检索(Multi-Query Retrieval)。
还有一种方式:导游听到「推荐个烤鸭店」,脑子里先浮现出一个答案轮廓,「全聚德应该不错」,然后他翻手册找到全聚德的详细信息(地址、营业时间、特色菜),再把完整资料告诉游客。用「第一印象」来引导查找方向。这种策略叫假设答案(HyDE Hypothetical Document Embeddings):让大模型先根据用户的问题生成一段假设答案 ,然后用这段假设的答案作为新的问题去文档库里匹配新的文档块,再进行总结,生成最终答案。 
有时候游客的问题太长太杂,核心不明确。比如游客说了一大段话,又是描述位置又是讲个人偏好。这时可以先后退一步,让大模型提炼核心意图:「大体上看,这是什么类型的问题?」抓住主线后再去检索,比直接拿原文搜更准。这种策略叫问题摘要(Step Back)。
与之相反,有些问题不是太杂而是太大。游客问「怎么去长城并在那里玩一天」,你可以拆解成几个小问题:怎么去?门票多少?有什么景点?午饭在哪吃?逐个查手册再整合成完整攻略。这种策略叫问题分解(Decomposition)。
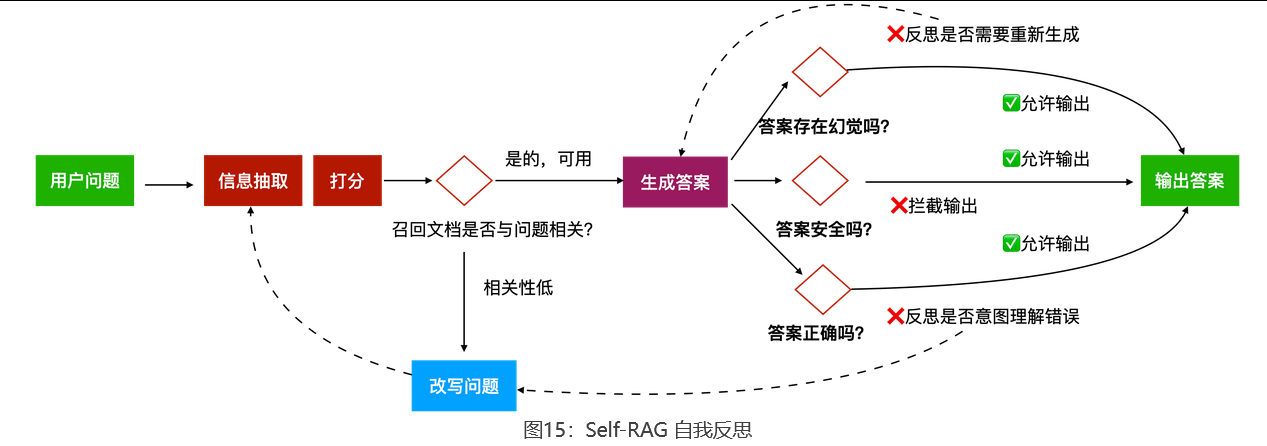
还有一种提升回答质量的策略是自我反思(Self-RAG) 。导游回答完游客之后,心里默默问自己三个问题:我翻的手册页和游客的问题相关吗?我说的都是手册上写的,还是我自己猜的?游客的问题真的被回答了吗?如果任何一个答案是「不确定」,就重新查一遍再回答。这种「自我审查」机制能有效减少错误和幻觉。
上面讲的这些策略,每一条都只对特定类型的问题奏效。传统 RAG 的做法是开发者提前选定一条策略,所有问题都走同一条路:简单问题被过度处理,复杂问题又只得到浅层答案
目前主流的 Agentic RAG 已经可以自己判断:这个问题需不需要检索?需要的话,信息够不够?不够就追问或换个策略继续搜。
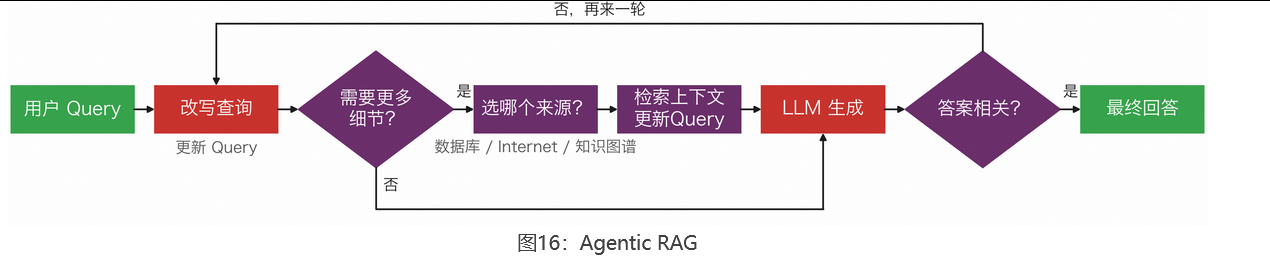
它靠一个**「思考→行动→观察→决策」** 的**推理循环(ReAct 模式)**实现自主决策:每执行一步,都会检查当前结果够不够好,不够就调整策略再来一轮。
3、 选择合适的信息来源
不同类型的问题,要去不同的地方(信息源)找答案。
-
「我腿脚不好,景区里建议走哪条路?」------手册里有答案
-
「明天下午景区天气怎么样,游船会开吗?」------得上网查实时天气预报
-
「现在景区的停车场还有空位吗?」------得查景区内部系统(数据库)
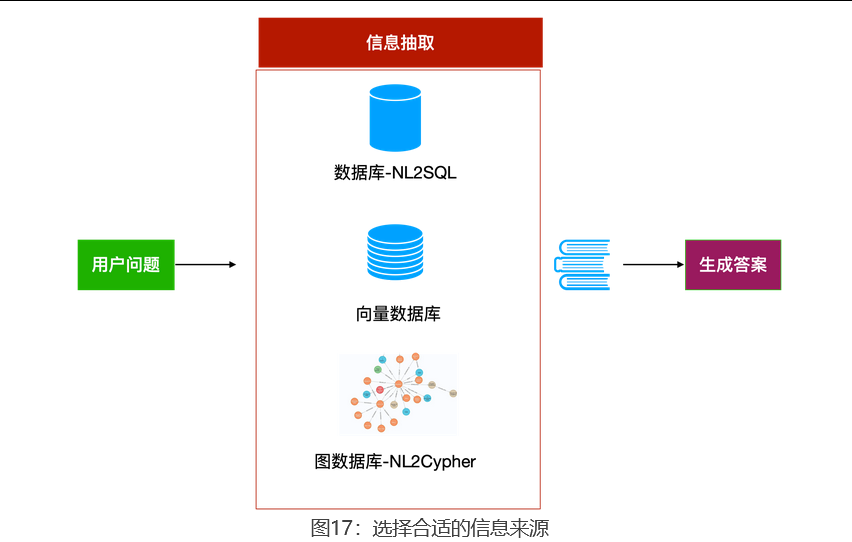
需要找含义相近的内容,可以用向量检索。 把文档切成多个片段之后,RAG 的下一步是从中找出与用户问题相关的片段。这本质上是一个搜索问题,难点在于:用户问题和手册写法可能不同,但含义相近。比如游客问「我腿脚不好,景区里建议走哪条路?」,手册里写的是「无障碍通道」和「平坦步道推荐」。关键词对不上,但说的是同一件事。
为了解决这个问题,大多数 RAG 系统会把片段转换成向量 。你可以把向量理解为文字在语义空间里的坐标:意思越接近,坐标通常也越接近。系统会把原文片段及其向量存入向量数据库。检索时,再把用户问题也转成向量,比较它与片段向量之间的坐标距离,从而找出语义相近的内容。
需要实时信息,可以上网搜索。 许多主流大模型(Qwen、GPT、Claude 等)的智能体产品已经支持联网搜索,常见形式包括 Web Search(调搜索 API)、Web Fetch(抓取网页内容)、Browser Use(操作浏览器)三档。不过要注意,有些网站会限制 AI 抓取,需要登录才能获取页面内容。
需要内部业务数据,可以从数据库查数据。 像「去年收入是多少」这类问题,答案往往存在内部数据库或 BI 系统。如果你要查询这类数据,常见做法是让大模型把自然语言问题转换成 SQL ,这类技术叫 NL2SQL 。该技术降低了查数门槛,但不能默认其结果一定可靠:真实业务往往库表结构复杂、指标口径不统一,另外还要处理权限控制。如果直接面向客户或用于关键决策,建议配合 SQL 校验、权限限制和结果复核。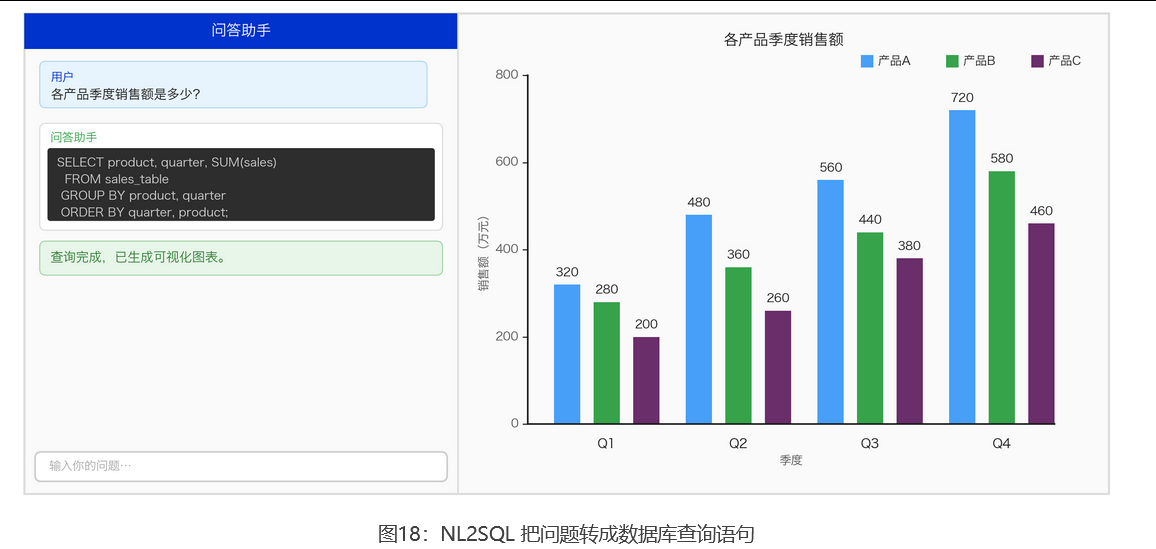
要实体之间的关系,就从知识图谱挖关系。 游客问「故宫和颐和园有什么历史渊源?」------系统从知识图谱里查找两个景点的关联节点,发现都和清朝皇室有关,挖掘出隐藏的关联信息。代表方案是微软的 GraphRAG,以及更轻量、构建更快的 LightRAG。
4、优化向量检索
接下来优化最常用的信息来源:向量数据库。向量检索(语义检索) 擅长找到表达相近的内容,但遇到编号、名称、专有名词这类适合精确匹配的信息,容易漏掉。所以更常见的做法是为其再加上一路关键词检索 :编号、名称、专有名词交给关键词检索;语义相近、表达变化交给向量检索 。两路结果分别召回,再合并排序,这就是混合检索(Hybrid Search)。
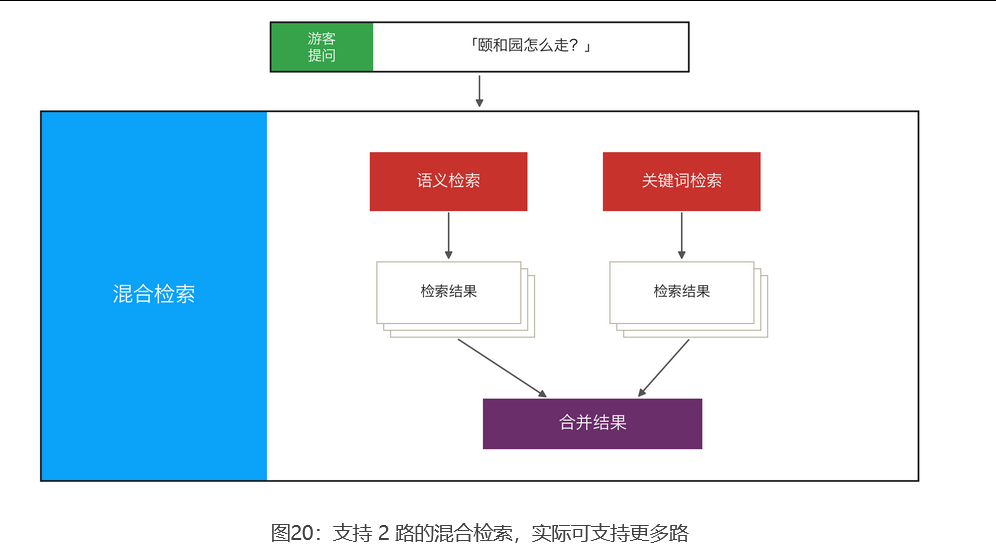
多路结果怎么合并?
多路召回会得到多份候选结果,但每一路的评分尺度可能完全不同:语义检索打 0.82 分,关键词检索打 15.3 分。就像一个学生数学考了 85 分(150 分制),物理考了 82 分(100 分制),无法直接比较哪个成绩更好(分制不同)。例如图中:
-
语义检索认为:片段 2 排第 1,片段 7 排第 2,片段 6 排第 3
-
关键词检索认为:片段 6 排第 1,片段 2 排第 2,片段 7 排第 3
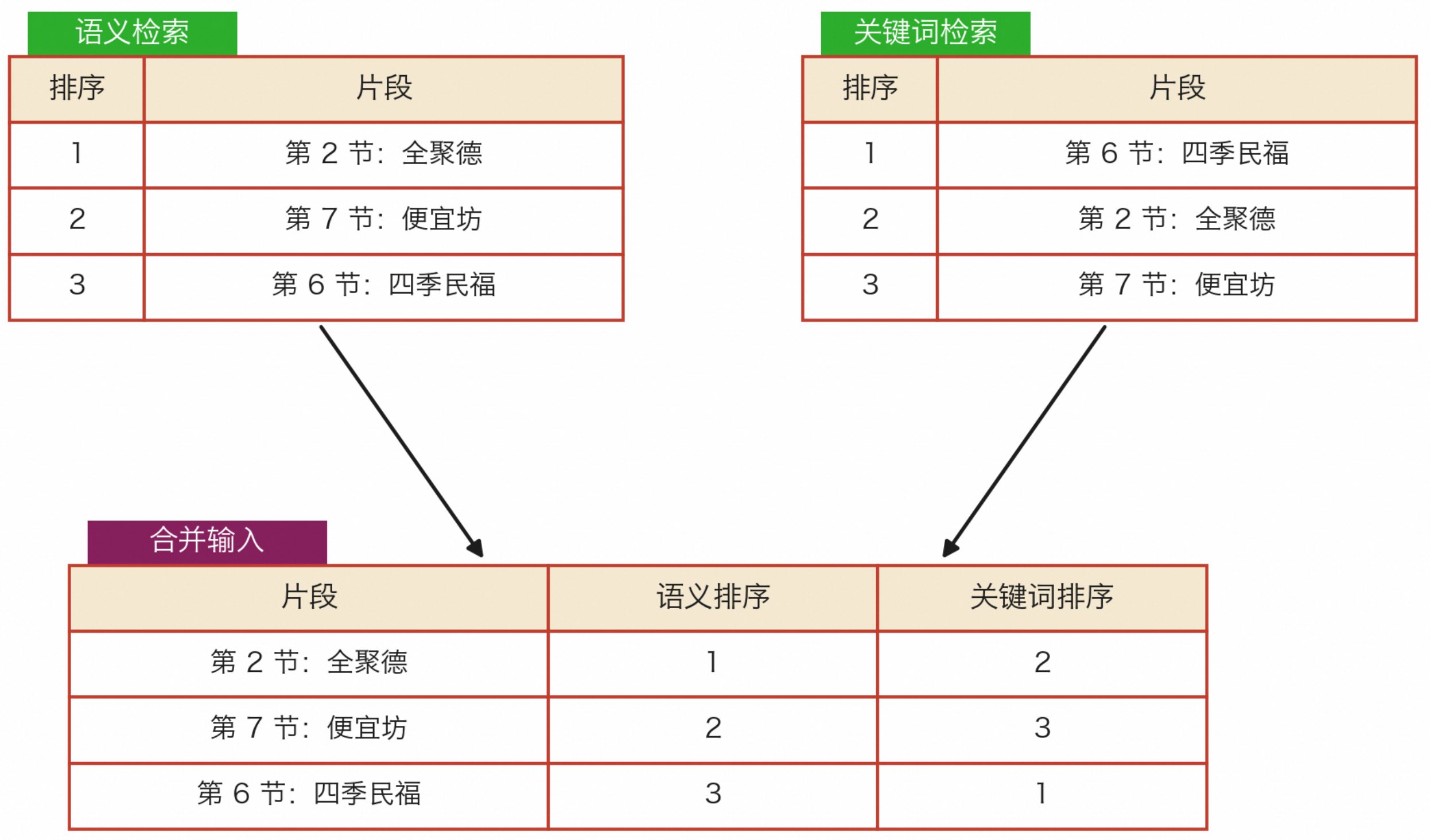
解决方案是通过 RRF (Reciprocal Rank Fusion,倒数排名融合) 对各片段在不同召回结果中的排名进行打分(RRF Score),再合并成一份统一的候选列表。
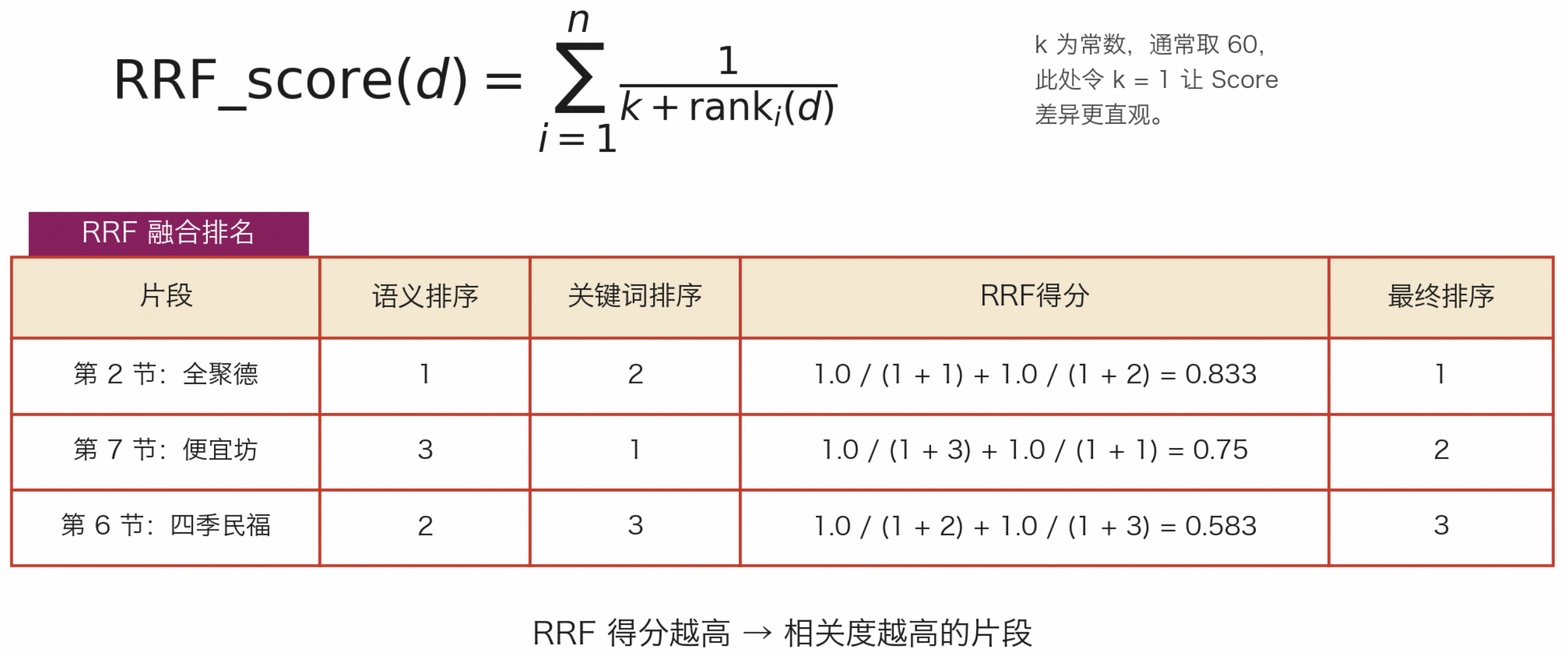
图22:RRF 计算每个片段的得分,rank_i(d)是片段在第 i 路召回结果里的排名
多路召回找到了一堆资料。但全部塞给大模型,它真的能用好吗?
5 、精选送入大模型的内容
前面提到,大模型在处理长文本时,并不会均匀关注所有信息,尤其容易忽略位于中间的内容。而检索返回的结果中,往往只有少部分真正相关,大量无关信息反而会进一步干扰大模型判断 (Context Rot 现象)。
所以解决思路是:用精排(ReRank)精选最相关的几条,提高送入大模型的有效信息浓度。
前面的 RRF 是粗排:速度快,目标是尽量不漏掉可能相关的内容。精排则会把用户问题和候选片段放在一起理解,判断它们是否真的匹配。 比如游客问「全聚德人均消费多少」,粗排觉得「全聚德的百年历史」很相关(都提到了全聚德),但精排会发现这篇讲的是历史不是价格,相关度不高。精排后只保留最相关的 top K 个片段(K 可配置)送给大模型。
6 、升级基座模型
当有更强大的大模型发布时,可以将其纳入候选并评测,看能否进一步提升 RAG 效果。建议先用自动评测从多个候选大模型中快速筛选出在当前场景下表现最优的,再让业务专家抽样对比大模型输出,重点关注文字组织、伦理合规等方面的细微差异。