我用最生活化的例子 ,把 QuadGraph 从 0 到 1 搭建出来,每一个节点、每一条边、每一个语义都写死,你直接能在组会演示。
场景
我们要存储以下知识:
- 实体:Apple Inc.(苹果公司)、iPhone 15(手机)
- 属性:iPhone 15 颜色:黑色;价格:5999 元
- 文档:《苹果 2024 秋季产品发布会文档》
- 社区:消费电子科技社区
第一步:填 T(节点类型,固定 4 种)
python
T = { attribute, entity, document, community }固定不变,所有知识都用这 4 类节点。
第二步:填 V(所有节点,列全所有点)
V 就是所有四层节点的列表:
python
V = [
# 1. Attribute Layer(属性节点)
"颜色_黑色",
"价格_5999元",
# 2. Knowledge Graph Layer(实体节点)
"实体_Apple Inc.",
"实体_iPhone 15",
# 3. Document Layer(文档节点)
"文档_苹果2024秋季产品发布会",
# 4. Community Layer(社区节点)
"社区_消费电子科技"
]第三步:填 R(所有关系类型,层内 + 层间)
python
R = [
# 层内关系(实体-实体)
"发布",
# 层间关系(跨四层的固定关系)
"has attribute(拥有属性)",
"included in(包含于/被文档包含)",
"belongs to(属于)"
]第四步:填 E(所有边,严格按公式 E={(v,r,v′)})
每条边都是 (起点节点,关系,终点节点)
python
E = [
# 1. 实体-实体 关系(知识图谱层内)
("实体_Apple Inc.", "发布", "实体_iPhone 15"),
# 2. 实体-属性 关系(层间:has attribute)
("实体_iPhone 15", "has attribute", "颜色_黑色"),
("实体_iPhone 15", "has attribute", "价格_5999元"),
# 3. 实体-文档 关系(层间:included in)
("实体_Apple Inc.", "included in", "文档_苹果2024秋季产品发布会"),
("实体_iPhone 15", "included in", "文档_苹果2024秋季产品发布会"),
# 4. 文档-社区 关系(层间:belongs to)
("文档_苹果2024秋季产品发布会", "belongs to", "社区_消费电子科技")
]第五步:填 S(节点语义特征,就是节点的文字内容)
S 存储每个节点的文本意思,让模型读懂文字:
python
S = {
# 属性语义
"颜色_黑色": "iPhone 15的颜色属性,取值为黑色",
"价格_5999元": "iPhone 15的价格属性,取值为5999元",
# 实体语义
"实体_Apple Inc.": "美国科技公司,总部位于库比蒂诺",
"实体_iPhone 15": "苹果公司2024年发布的智能手机",
# 文档语义
"文档_苹果2024秋季产品发布会": "2024年9月苹果召开发布会,发布iPhone 15系列产品,售价5999元起,颜色包含黑色...",
# 社区语义
"社区_消费电子科技": "包含手机、电脑、智能设备的科技产品主题社区"
}四、最终完整 QuadGraph 存储结构
python
G = (
# V 节点
["颜色_黑色","价格_5999元","实体_Apple Inc.","实体_iPhone 15","文档_苹果2024秋季产品发布会","社区_消费电子科技"],
# E 边
[
("实体_Apple Inc.","发布","实体_iPhone 15"),
("实体_iPhone 15","has attribute","颜色_黑色"),
("实体_iPhone 15","has attribute","价格_5999元"),
("实体_Apple Inc.","included in","文档_苹果2024秋季产品发布会"),
("实体_iPhone 15","included in","文档_苹果2024秋季产品发布会"),
("文档_苹果2024秋季产品发布会","belongs to","社区_消费电子科技")
],
# R 关系类型
["发布","has attribute","included in","belongs to"],
# T 节点类型
["attribute","entity","document","community"],
# S 语义特征
{
"颜色_黑色":"iPhone 15颜色属性黑色",
"价格_5999元":"iPhone 15价格5999元",
"实体_Apple Inc.":"美国科技公司",
"实体_iPhone 15":"2024苹果手机",
"文档_苹果2024秋季产品发布会":"发布会介绍iPhone15售价颜色",
"社区_消费电子科技":"消费电子主题社区"
}
)五、一句话总结
QuadGraph 用5 个元素 就把所有类型的知识统一存起来:
- V 存所有节点(属性、实体、文档、社区)
- E 存所有连线
- R 存连线的名字
- T 固定 4 类节点
- S 存每个节点的文字意思
不管是医疗、法律、百科知识,全都能按这个格式存,这就是它能通用的核心原因。
具体推理流程:
(1)编码(文本→向量)
- 第一步:把文字变成计算机能懂的向量节点文字(比如 "iPhone 15")→ 节点向量;关系文字(比如 "发布")→ 关系向量。
- 关键:所有向量在同一个空间计算机可以直接计算 "用户问题" 和 "节点" 的相似度。
通俗例子
用户问题:"iPhone15 价格是多少?"
- 问题→向量 h_q
- 节点 "价格_5999 元"→向量 h_v
- 计算机一算:两者很像,就判定这个节点相关。
- 公式 (3):初始化 把节点本身的信息 +用户问题的信息绑在一起。
- **公式 (4):消息传递(GNN 核心)**每个节点向邻居 "打听信息",把周围节点、关系的信息聚合过来。
- 公式 (5):输出分数 给每个节点打一个分:这个节点和用户问题有多相关。
2. 固定我们的「苹果场景」(全程用这个,不换)
- 用户查询 q:iPhone 15 的价格是多少?
- 查询向量 h_q:模型把这句话转成的计算机向量(理解用户要找「iPhone15」「价格」)
- 我们的 QuadGraph 关键节点 :
- v1:实体_Apple Inc.(实体类型)
- v2:实体_iPhone 15(实体类型)
- v3:属性_价格_5999 元(属性类型)
- v4:属性_颜色_黑色(属性类型)
- v5:文档_苹果 2024 秋季发布会(文档类型)
- 关键边(关系) :
- (v1, 发布,v2)
- (v2, has attribute, v3) → 核心!iPhone15 有价格属性
- (v2, has attribute, v4)
- 目标 :让 GFM 算出 → 节点 v3(价格 5999 元)和查询最相关
第一步:先把所有文字转成向量(模型的 "语言")
模型先用 Qwen3 嵌入模型,把所有东西转成向量:
- 查询向量:hq → 代表「iPhone15 价格」
- 节点向量:hv2(iPhone15)、hv3(价格 5999)、hv1(苹果公司)
- 关系向量:hr(has attribute)、hr(发布)
公式 (3):初始化节点向量 Init(给节点 "注入查询信息")
公式
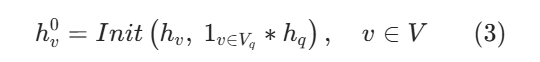

作用
把节点本身的信息 + 用户查询的信息 绑在一起,让节点 "知道用户在问什么"。
苹果例子讲解
- 系统先初步挑出和查询沾边的节点:Vq={v2(iPhone15),v3(价格)}
- 对这些节点,Init 函数把节点向量 + 查询向量 融合:
- hv20=Init(hv2,hq) → iPhone15 向量 +「iPhone15 价格」向量
- hv30=Init(hv3,hq) → 价格向量 +「iPhone15 价格」向量
- 不相关节点(苹果公司、黑色):只保留自己的向量,不加查询信息
大白话
初始化就是:给可能相关的节点,贴上用户问题的标签。
公式 (4):核心!消息传递 + 更新(GNN 每层干的事)
公式
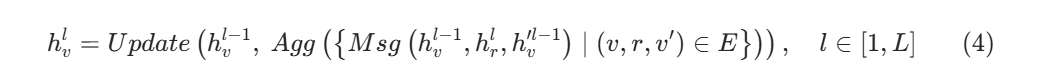

作用
每个节点向邻居打听消息 → 把邻居的信息收过来 → 更新自己的信息。我们以第 1 层(l=1) 、节点 v3(价格 5999) 为例讲解!
子步骤 1:Msg 生成消息(DistMult)
节点 v3 的邻居是v2(iPhone15) ,关系是has attribute。
- Msg 函数输入:h_v2_0(iPhone15 初始化向量)、h_r1(has attribute 向量)、h_v3_0(价格初始化向量)
- Msg 输出:iPhone15 传给价格节点的消息→
- 内容:"我是 iPhone15,你是我的价格属性,用户在问我的价格!"
大白话
Msg 就是:邻居通过关系,给你发一条专属消息。
子步骤 2:Agg 聚合消息(sum 求和)
节点 v3 只有 1 条消息(来自 iPhone15),直接把这条消息求和 / 收起来。
大白话
Agg 就是:把所有邻居发的消息,打包汇总。
子步骤 3:Update 更新节点向量
Update 函数把:
- 节点 v3 上一层的向量hv30
- 聚合后的消息 用 MLP 融合,得到第 1 层更新后的向量h_v3_1
大白话
Update 就是:把自己的旧信息 + 邻居的新信息,合成新的自己。
多层运行(L 层)
模型会跑 6 层(论文里 L=6),每一层都重复:打听消息→收消息→更新自己 最后得到节点的最终向量h_v3_L。
最终效果
节点 v3(价格 5999)的向量里,融合了:
- 自己的价格信息
- iPhone15 的信息
- 用户查询的信息→ 变成了 "和查询高度相关" 的向量
公式 (5):预测相关性分数 Predictor
公式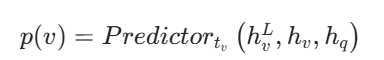
作用
按节点类型,给每个节点打一个0~1 的分数:分数越高 → 越和用户查询相关。
苹果例子讲解
- 对属性节点 v3(价格 5999) :Predictor 输入:最终向量hv3L + 原始向量hv3 + 查询向量hq输出分数:0.98(极高分)
- 对实体节点 v2(iPhone15):输出分数:0.85
- 对属性节点 v4(黑色):输出分数:0.05(极低分)
- 对实体节点 v1(苹果公司):输出分数:0.1
最终结果
GFM 告诉 LLM:最相关的节点是:属性_价格_5999 元!
全程大白话总结(组会这么说,所有人都懂)
用户问:iPhone15 的价格是多少?
- 初始化:给 iPhone15、价格节点,贴上用户问题的标签;
- 消息传递:iPhone15 节点给价格节点发消息:"我是 iPhone15,你是我的价格,用户在问我价格!"价格节点收下消息,更新自己的信息;
- 预测:模型给价格节点打高分,判断它和查询最相关;
- 输出:把价格节点的信息喂给 LLM,LLM 直接回答:5999 元!
最后把专业名词对应到例子里
表格
| 专业名词 | 苹果例子里的意思 |
|---|---|
| Msg(DistMult) | iPhone15 给价格节点发的消息 |
| Agg(sum) | 把邻居消息收起来 |
| Update | 价格节点更新自己的信息 |
| Predictor | 给节点打 "是否相关" 的分数 |
| query-dependent GNN | 带着用户问题去看图推理 |
初始化时判断 "相关节点 V_q" → 就是靠【文本向量余弦相似度】粗筛!
具体规则(超简单)
- 先把所有节点的原始文本向量 h_v 算出来
- 把用户查询向量 h_q 算出来
- 对每个节点,计算 h_v 和 h_q 的余弦相似度
- 取相似度最高的前 K 个节点 → 这就是
V_q(相关节点) - 只有这些节点,初始化时会注入查询向量 h_q
最后预测打分 p (v) → 绝对不是单纯看相似度!是【图结构 + 文本语义 + 查询信息】联合推理的综合分数!
Predictor 就是个「简单神经网络」
Predictor_{t_v} = 按节点类型的 MLP 二分类器
它就干一件事:输入 3 个向量 → 输出 1 个 0~1 的数(相关概率)
图拓扑结构 + 多层消息传递 + 文本语义 + 查询
图推理
输出精准相关性概率
第一步:向量拼接(最关键!把 3 个信息揉成一个)
把图推理结果 、节点文本 、查询文本 ,头尾接成一个长向量。
第二步:送入 MLP 神经网络(模型学出来的权重)
看这个拼接后的长向量,判断 "像不像是和查询相关的节点"
第三步:Sigmoid 压缩到 0~1(变成概率)
神经网络算出一个原始分数,再用 sigmoid 函数 压缩到 0~1 之间,就是最终的 p(v)。
三、对应到苹果例子,最终分数怎么来的?
节点 v3(价格 5999):
- 拼接向量里 = 图推理(和 iPhone15 相连)+ 文本(价格)+ 查询(iPhone15 价格)
- MLP 识别到:这是高度相关的组合
- Sigmoid 输出 → 0.98
节点 v4(颜色黑色):
- 拼接向量里 = 图相连但文本不匹配
- MLP 识别到:无关
- 输出 → 0.05
四、你最关心的:到底「根据什么」打分?
我给你总结成3 句人话:
- 不是算相似度,不是向量点积,不是余弦距离;
- 不是人工规则,不是谁定义的;
- 是神经网络根据 "拼接后的特征",用训练学到的模式,判断相关性强弱。
五、和 "单纯相似度" 的本质区别(你一定要分清)
- 相似度:只看两个向量像不像
- Predictor 打分 :看图结构推理结果 + 节点文本 + 查询文本 三者组合起来像不像 "相关节点"