论文信息
- 标题:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- 会议:ICML 2022
- 单位:Salesforce Research
- 代码:https://github.com/salesforce/BLIP
- 论文:https://arxiv.org/pdf/2201.12086.pdf
引言:多模态模型的"偏科"与"挑食"难题
想象一下,你有两个AI助手:一个能精准判断"这张图里有没有猫",但让它写一句描述图片的话就只会说"a cat";另一个能写出优美的图片描述,但让它从100张图里找出猫的图片就会频频出错。这就是2022年之前多模态预训练(VLP)模型的真实写照------要么擅长理解类任务(如CLIP、ALBEF),要么擅长生成类任务(如SimVLM),没有一个能做到全能。
更糟糕的是,这些模型都有严重的"挑食"问题:它们只能吃"干净"的人工标注数据,但人工标注太贵了,所以大家只能去网上爬海量的图文对。可这些网页数据就像路边摊的小吃,虽然量大但满是"地沟油"------很多文本根本不描述图片内容,比如一张风景图配文"今天心情真好"。之前的方法只能用简单的规则过滤掉最明显的垃圾,剩下的噪声还是会严重影响模型性能。
BLIP的作者们一次性解决了这两个难题:
- 提出了多模态混合编码器-解码器(MED)架构,让同一个模型既能做理解又能做生成,彻底告别偏科
- 发明了字幕生成与过滤(CapFilt)技术,能把网上的噪声数据"提纯"成高质量训练数据,让模型吃得香又长得壮
一、MED架构:一个模型打天下
BLIP的核心是多模态混合编码器-解码器(Multimodal Mixture of Encoder-Decoder, MED) ,它就像一个变形金刚,能根据不同任务切换成三种不同的工作模式。
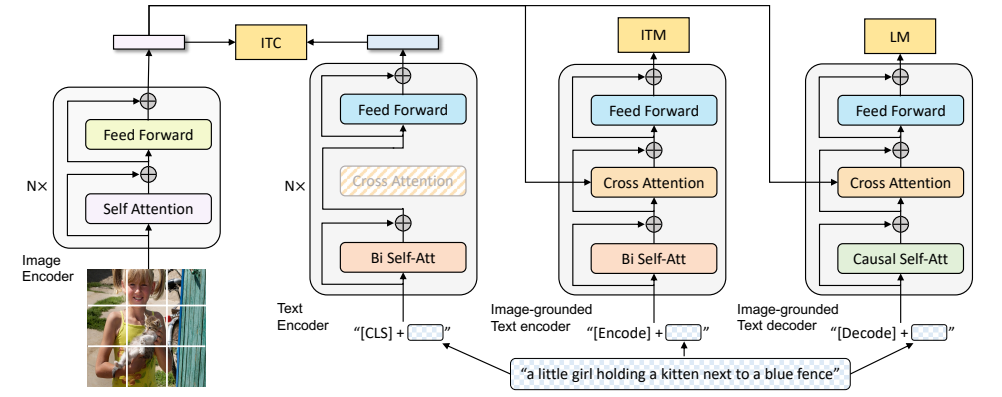
图片1:BLIP预训练架构与目标
出处:论文图2
1.1 三种工作模式
模式1:单模态编码器(Unimodal Encoder)
- 功能:分别编码图像和文本,让它们的特征空间对齐
- 输入 :图像 + 文本(开头加
[CLS]token) - 训练目标:图像-文本对比损失(ITC)
- 通俗解释:就像让两个说不同语言的人先学一些基础词汇,知道"cat"对应猫的图片,"dog"对应狗的图片
模式2:图像引导的文本编码器(Image-grounded Text Encoder)
- 功能:融合图像和文本信息,学习细粒度的跨模态交互
- 输入 :图像 + 文本(开头加
[Encode]token) - 特殊设计 :在文本编码器的每个Transformer块里加了一个交叉注意力层,让文本token能"看到"图像token
- 训练目标:图像-文本匹配损失(ITM)
- 通俗解释:就像让两个人坐下来聊天,不仅知道对方说的词是什么意思,还能理解整句话的含义
模式3:图像引导的文本解码器(Image-grounded Text Decoder)
- 功能:根据图像生成文本描述
- 输入 :图像 + 文本(开头加
[Decode]token) - 特殊设计 :把双向自注意力换成了因果自注意力(只能看到前面的token,不能看到后面的),这样才能自回归生成文本
- 训练目标:语言建模损失(LM)
- 通俗解释:就像让一个人看着图片讲故事,只能一个字一个字地说,不能提前剧透后面的内容
1.2 三大预训练目标
BLIP同时训练三个目标,总损失是三个损失的和:
L=Litc+Litm+Llm\mathcal{L} = \mathcal{L}{itc} + \mathcal{L}{itm} + \mathcal{L}_{lm}L=Litc+Litm+Llm
目标1:图像-文本对比损失(ITC)
ITC损失的目标是让匹配的图文对在特征空间里靠得更近,不匹配的离得更远。它借鉴了ALBEF的动量编码器思想,用动量模型生成软标签来处理潜在的正样本。
公式1:ITC损失
Litc=12E(I,T)∼DH(yi2t,pi2t)+H(yt2i,pt2i)\mathcal{L}{itc} = \frac{1}{2} \mathbb{E}{(I, T) \sim D} \left H(y\^{i2t}, p\^{i2t}) + H(y\^{t2i}, p\^{t2i}) \\rightLitc=21E(I,T)∼DH(yi2t,pi2t)+H(yt2i,pt2i)
- Litc\mathcal{L}_{itc}Litc:ITC总损失,是图像到文本和文本到图像损失的平均值
- HHH:交叉熵损失函数
- yi2ty^{i2t}yi2t:图像III对应的真实文本的one-hot标签
- pi2tp^{i2t}pi2t:模型预测的图像III对应各个文本的概率分布
- yt2iy^{t2i}yt2i:文本TTT对应的真实图像的one-hot标签
- pt2ip^{t2i}pt2i:模型预测的文本TTT对应各个图像的概率分布
目标2:图像-文本匹配损失(ITM)
ITM损失是一个二分类任务,让模型判断一个图文对是匹配的还是不匹配的。BLIP用了硬负样本挖掘策略:选择那些语义相似但不匹配的负样本,这样训练出来的模型更鲁棒。
公式2:ITM损失
Litm=E(I,T)∼DH(yitm,pitm(I,T))\mathcal{L}{itm} = \mathbb{E}{(I, T) \sim D} H(y^{itm}, p^{itm}(I, T))Litm=E(I,T)∼DH(yitm,pitm(I,T))
- Litm\mathcal{L}_{itm}Litm:ITM损失
- yitmy^{itm}yitm:图文对的真实标签(匹配为1,不匹配为0)
- pitm(I,T)p^{itm}(I, T)pitm(I,T):模型预测的图文对匹配的概率
目标3:语言建模损失(LM)
LM损失让模型学会根据图像生成文本描述。它优化的是交叉熵损失,训练模型最大化真实文本的似然概率。
公式3:LM损失
Llm=E(I,T)∼DH(ylm,plm(I,T))\mathcal{L}{lm} = \mathbb{E}{(I, T) \sim D} H(y^{lm}, p^{lm}(I, T))Llm=E(I,T)∼DH(ylm,plm(I,T))
- Llm\mathcal{L}_{lm}Llm:LM损失
- ylmy^{lm}ylm:真实文本的token序列
- plm(I,T)p^{lm}(I, T)plm(I,T):模型自回归生成的token概率分布
1.3 参数共享策略
为了提高训练效率,BLIP的文本编码器和解码器共享除了自注意力层之外的所有参数:
- 共享的参数:嵌入层、交叉注意力层、前馈网络
- 不共享的参数:自注意力层(编码器用双向,解码器用因果)
作者们通过实验证明,这种共享策略既能减少模型参数(从361M降到224M),又能提高性能。如果连自注意力层都共享,模型会因为编码和解码任务的冲突而性能下降。
二、CapFilt:把噪声数据变成黄金
网上爬来的图文对虽然量大,但质量参差不齐。BLIP的作者们发明了字幕生成与过滤 (Captioning and Filtering, CapFilt)技术,能把这些噪声数据"提纯"成高质量的训练数据。
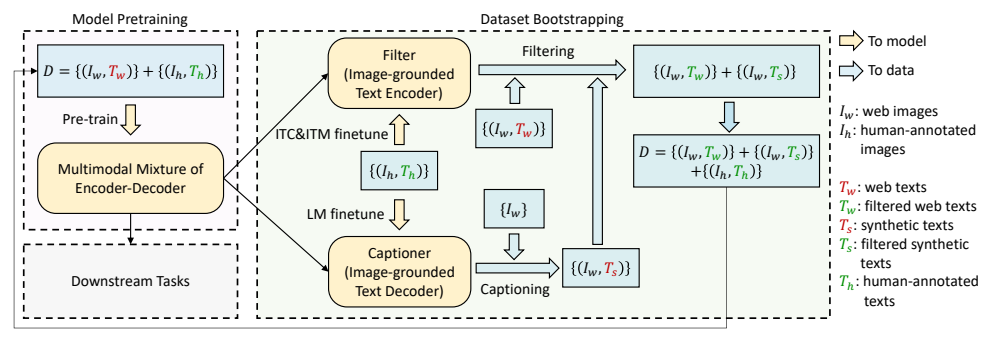
图片2:CapFilt整体流程
出处:论文图3
2.1 CapFilt的工作流程
CapFilt分为三个步骤:
- 预训练基础模型:用原始的噪声图文对预训练一个MED模型
- 微调两个专家 :
- Captioner(字幕生成器):用LM损失在高质量人工标注数据集(如COCO)上微调,学会给图片生成准确的描述
- Filter(过滤器):用ITC和ITM损失在COCO上微调,学会判断一个文本是否准确描述了图片
- 提纯数据集 :
- 用Captioner给所有网页图片生成合成字幕TsT_sTs
- 用Filter过滤掉原始网页字幕TwT_wTw和合成字幕TsT_sTs中的噪声(ITM头预测为不匹配的)
- 把过滤后的干净字幕和人工标注字幕合并,得到新的训练数据集
- 重新训练模型:用提纯后的数据集重新预训练一个MED模型,得到最终的BLIP模型
2.2 多样性比准确性更重要
在生成合成字幕时,作者们发现核采样(Nucleus Sampling)比束搜索(Beam Search)效果更好,尽管核采样生成的字幕噪声更多。
表格1:生成方法对比
| 生成方法 | 噪声比例 | Retrieval-FT (COCO) TR@1 | Caption-FT (COCO) CIDEr |
|---|---|---|---|
| Beam | 19% | 79.6 | 127.8 |
| Nucleus | 25% | 80.6 | 129.7 |
| 出处:论文表2 |
分析:核采样生成的字幕更多样化,包含了更多新的语义信息,而束搜索倾向于生成安全、常见的字幕。就像老师教学生,不仅要教标准答案,还要教不同的解题思路,这样学生才能举一反三。
2.3 为什么要解耦Captioner和Filter
作者们还发现,Captioner和Filter不能共享参数,否则会出现"确认偏差"------Captioner生成的噪声字幕会被Filter错误地保留下来。
表格2:参数共享对比
| Captioner & Filter | 噪声比例 | Retrieval-FT (COCO) TR@1 |
|---|---|---|
| 共享参数 | 8% | 79.8 |
| 解耦 | 25% | 80.6 |
| 出处:论文表4 |
分析:解耦后,Filter能更客观地评价Captioner生成的字幕,就像审稿人不能是作者本人一样,这样才能保证评审的公正性。
三、实验结果:用数据说话
BLIP在多个下游任务上都取得了state-of-the-art的结果,而且只用了比之前模型少得多的数据。
3.1 CapFilt真的有用吗?
表格3:CapFilt效果对比
| C | F | 预训练数据集 | Retrieval-FT (COCO) TR@1 | Caption-FT (COCO) CIDEr |
|---|---|---|---|---|
| ❌ | ❌ | 原始14M | 78.4 | 127.8 |
| ✅ | ❌ | 原始+合成 | 79.1 | 128.2 |
| ❌ | ✅ | 过滤后原始 | 79.7 | 128.9 |
| ✅ | ✅ | 提纯后14M | 80.6 | 129.7 |
| 出处:论文表1 |
分析:
- 只用Captioner(生成合成字幕),性能提升0.7%
- 只用Filter(过滤原始字幕),性能提升1.3%
- 两者一起用,性能提升2.2%
- 当预训练数据增加到129M时,性能还能进一步提升到81.9%
这说明CapFilt的两个模块是互补的,生成和过滤缺一不可。
3.2 图文检索:用1/30的数据超越CLIP
表格4:零样本图文检索结果(Flickr30K)
| Method | 预训练图片数 | TR R@1 | IR R@1 |
|---|---|---|---|
| CLIP | 400M | 88.0 | 68.7 |
| ALIGN | 1.8B | 88.6 | 75.7 |
| ALBEF | 14M | 94.1 | 82.8 |
| BLIP | 14M | 94.8 | 84.9 |
| BLIP | 129M | 96.0 | 85.0 |
| 出处:论文表6 |
分析:BLIP只用了14M预训练图片,就超过了用400M图片训练的CLIP和用1.8B图片训练的ALIGN!这说明BLIP的学习效率比之前的模型高得多,CapFilt功不可没。
3.3 其他下游任务:全面领先
表格5:VQA和NLVR2结果对比
| Method | 预训练图片数 | VQA test-std | NLVR2 test-P |
|---|---|---|---|
| ALBEF | 14M | 76.04 | 83.14 |
| BLIP | 14M | 77.62 | 82.30 |
| BLIP | 129M | 78.17 | 83.08 |
| 出处:论文表8 |
分析:在需要复杂推理的VQA和NLVR2任务上,BLIP也全面超越了之前的state-of-the-art方法ALBEF。而且BLIP不需要目标检测器,推理速度比需要检测器的方法快10倍以上。
3.4 零样本视频任务:惊人的泛化能力
BLIP不仅在图像任务上表现出色,还能直接零样本迁移到视频任务上!
表格6:零样本文本到视频检索结果(MSRVTT)
| Method | R@1 | R@5 | R@10 |
|---|---|---|---|
| VideoCLIP | 8.7 | 22.2 | 30.0 |
| MIL-NCE | 10.4 | 23.0 | 32.4 |
| BLIP (零样本) | 19.2 | 43.3 | 51.6 |
| ClipBERT (微调) | 22.0 | 46.8 | 59.9 |
| 出处:论文表10 |
分析:BLIP只用了图像数据预训练,零样本迁移到视频任务上就超过了很多专门在视频上微调的模型!这说明BLIP学到的视觉语言表征具有很强的泛化能力。
四、核心代码实现
下面是BLIP核心部分的代码实现,包括MED架构和三个预训练损失:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import BertModel, BertTokenizer, ViTModel, ViTFeatureExtractor
class BLIP(nn.Module):
def __init__(self, vit_name='google/vit-base-patch16-224', bert_name='bert-base-uncased', embed_dim=256):
super().__init__()
# 图像编码器
self.vision_encoder = ViTModel.from_pretrained(vit_name)
# 文本编码器/解码器(共享参数)
self.text_encoder = BertModel.from_pretrained(bert_name, add_pooling_layer=False)
self.text_decoder = BertModel.from_pretrained(bert_name, add_pooling_layer=False)
# 投影层,用于对比学习
self.vision_proj = nn.Linear(self.vision_encoder.config.hidden_size, embed_dim)
self.text_proj = nn.Linear(self.text_encoder.config.hidden_size, embed_dim)
# ITM分类头
self.itm_head = nn.Linear(self.text_encoder.config.hidden_size, 2)
# LM头
self.lm_head = nn.Linear(self.text_decoder.config.hidden_size, self.text_decoder.config.vocab_size)
# 温度参数
self.logit_scale = nn.Parameter(torch.ones([]) * torch.log(torch.tensor(1.0 / 0.07)))
# 初始化解码器参数(共享除了自注意力之外的层)
self._init_decoder()
def _init_decoder(self):
"""初始化解码器,共享除了自注意力之外的参数"""
for name, param in self.text_encoder.named_parameters():
if 'attention.self' not in name:
self.text_decoder.state_dict()[name].copy_(param.data)
# 冻结共享参数的梯度
for name, param in self.text_decoder.named_parameters():
if 'attention.self' not in name:
param.requires_grad = False
def forward_vision(self, images):
"""编码图像"""
vision_outputs = self.vision_encoder(images)
vision_embeds = vision_outputs.last_hidden_state
vision_cls = vision_embeds[:, 0, :]
return vision_embeds, vision_cls
def forward_text_encoder(self, input_ids, attention_mask, vision_embeds):
"""图像引导的文本编码器"""
# 文本自注意力
text_outputs = self.text_encoder(
input_ids=input_ids,
attention_mask=attention_mask,
output_hidden_states=True
)
text_embeds = text_outputs.last_hidden_state
# 交叉注意力(简化版,实际实现需要更复杂的交叉注意力层)
cross_attn_output = torch.bmm(text_embeds, vision_embeds.transpose(1, 2))
cross_attn_output = F.softmax(cross_attn_output, dim=-1)
cross_attn_output = torch.bmm(cross_attn_output, vision_embeds)
text_embeds = text_embeds + cross_attn_output
return text_embeds
def forward_text_decoder(self, input_ids, attention_mask, vision_embeds):
"""图像引导的文本解码器(因果自注意力)"""
# 因果自注意力掩码
seq_length = input_ids.size(1)
causal_mask = torch.tril(torch.ones((seq_length, seq_length), device=input_ids.device))
causal_mask = causal_mask.unsqueeze(0).unsqueeze(0)
# 文本因果自注意力
text_outputs = self.text_decoder(
input_ids=input_ids,
attention_mask=causal_mask,
output_hidden_states=True
)
text_embeds = text_outputs.last_hidden_state
# 交叉注意力
cross_attn_output = torch.bmm(text_embeds, vision_embeds.transpose(1, 2))
cross_attn_output = F.softmax(cross_attn_output, dim=-1)
cross_attn_output = torch.bmm(cross_attn_output, vision_embeds)
text_embeds = text_embeds + cross_attn_output
return text_embeds
def forward(self, images, input_ids, attention_mask, labels=None):
# 编码图像
vision_embeds, vision_cls = self.forward_vision(images)
vision_proj = F.normalize(self.vision_proj(vision_cls), dim=-1)
# 编码文本(单模态)
text_outputs = self.text_encoder(input_ids=input_ids, attention_mask=attention_mask)
text_cls = text_outputs.last_hidden_state[:, 0, :]
text_proj = F.normalize(self.text_proj(text_cls), dim=-1)
# 计算ITC损失
loss_itc = self.itc_loss(vision_proj, text_proj)
# 计算ITM损失
loss_itm = self.itm_loss(vision_embeds, input_ids, attention_mask)
# 计算LM损失
loss_lm = 0.0
if labels is not None:
decoder_embeds = self.forward_text_decoder(input_ids, attention_mask, vision_embeds)
logits = self.lm_head(decoder_embeds)
loss_lm = F.cross_entropy(logits.view(-1, logits.size(-1)), labels.view(-1))
# 总损失
loss = loss_itc + loss_itm + loss_lm
return loss
def itc_loss(self, vision_proj, text_proj):
"""计算图像-文本对比损失"""
logits_i2t = vision_proj @ text_proj.T * self.logit_scale.exp()
logits_t2i = text_proj @ vision_proj.T * self.logit_scale.exp()
labels = torch.arange(logits_i2t.size(0), device=logits_i2t.device)
loss_i2t = F.cross_entropy(logits_i2t, labels)
loss_t2i = F.cross_entropy(logits_t2i, labels)
return (loss_i2t + loss_t2i) / 2
def itm_loss(self, vision_embeds, input_ids, attention_mask):
"""计算图像-文本匹配损失(带硬负样本挖掘)"""
batch_size = input_ids.size(0)
# 生成硬负样本
with torch.no_grad():
vision_proj = F.normalize(self.vision_proj(vision_embeds[:, 0, :]), dim=-1)
text_proj = F.normalize(self.text_proj(self.text_encoder(input_ids, attention_mask).last_hidden_state[:, 0, :]), dim=-1)
sim_i2t = vision_proj @ text_proj.T
sim_t2i = text_proj @ vision_proj.T
# 为每个图像选择一个硬负文本
weights_i2t = F.softmax(sim_i2t, dim=1)
weights_i2t.fill_diagonal_(0)
neg_text_ids = torch.multinomial(weights_i2t, 1).squeeze()
# 为每个文本选择一个硬负图像
weights_t2i = F.softmax(sim_t2i, dim=1)
weights_t2i.fill_diagonal_(0)
neg_image_ids = torch.multinomial(weights_t2i, 1).squeeze()
# 构造正负样本
pos_vision_embeds = vision_embeds
neg_vision_embeds = vision_embeds[neg_image_ids]
all_vision_embeds = torch.cat([pos_vision_embeds, neg_vision_embeds], dim=0)
pos_input_ids = input_ids
neg_input_ids = input_ids[neg_text_ids]
all_input_ids = torch.cat([pos_input_ids, neg_input_ids], dim=0)
pos_attention_mask = attention_mask
neg_attention_mask = attention_mask[neg_text_ids]
all_attention_mask = torch.cat([pos_attention_mask, neg_attention_mask], dim=0)
# 编码
text_embeds = self.forward_text_encoder(all_input_ids, all_attention_mask, all_vision_embeds)
cls_embeds = text_embeds[:, 0, :]
# 预测
logits = self.itm_head(cls_embeds)
labels = torch.cat([torch.ones(batch_size), torch.zeros(batch_size)], dim=0).long().to(input_ids.device)
return F.cross_entropy(logits, labels)五、可视化:看看模型学到了什么

图片3:CapFilt示例
出处:论文图4
从图3可以看到:
- 原始网页字幕TwT_wTw(红色)大多是噪声,比如"from bridge near my house"根本不描述图片内容
- Captioner生成的合成字幕TsT_sTs(绿色)都准确描述了图片内容,比如"a flock of birds flying over a lake at sunset"
- Filter成功过滤掉了所有噪声字幕,只保留了干净的合成字幕
这说明CapFilt确实能有效提纯噪声数据,让模型学到更准确的视觉语言对应关系。
六、总结与未来方向
BLIP是多模态预训练领域的一个里程碑式的工作,它的主要贡献有三点:
- 统一架构:提出了MED架构,让同一个模型既能做理解又能做生成,打破了之前模型的偏科问题
- 数据提纯:发明了CapFilt技术,能把网上的噪声数据变成高质量训练数据,大大提高了数据利用效率
- 全面领先:在多个下游任务上取得了state-of-the-art的结果,而且具有惊人的零样本泛化能力
未来的研究方向包括:
- 多轮CapFilt:多次迭代提纯数据集,进一步提高数据质量
- 多字幕生成:为每张图片生成多个不同的合成字幕,扩大训练语料
- 模型集成:训练多个不同的Captioner和Filter,组合它们的力量
BLIP的思想影响了后来的很多多模态模型,比如BLIP-2、InstructBLIP等,它证明了好的数据和高效的架构同样重要,为多模态预训练指明了新的方向。