目录
完整代码下载 :神经网络常见层Numpy封装参考 - 常见层
前置层
- 神经网络常见层Numpy封装参考(1):损失层
- 神经网络常见层Numpy封装参考(2):线性层
- 神经网络常见层Numpy封装参考(3):激活层
- 神经网络常见层Numpy封装参考(4):优化器
其他层
BatchNorm1d层
输入数据
X ( N × C ) = x 1 ( 1 ) x 1 ( 2 ) ⋯ x 1 ( C ) x 2 ( 1 ) x 2 ( 2 ) ⋯ x 2 ( C ) ⋯ ⋯ ⋯ ⋯ x N ( 1 ) x N ( 2 ) ⋯ x N ( C ) {{\bf{X}}_{(N \times C)}} = \left {\\begin{array}{c} {{x_1}\^{(1)}}\&{{x_1}\^{(2)}}\& \\cdots \&{{x_1}\^{(C)}}\\\\ {{x_2}\^{(1)}}\&{{x_2}\^{(2)}}\& \\cdots \&{{x_2}\^{(C)}}\\\\ \\cdots \& \\cdots \& \\cdots \& \\cdots \\\\ {{x_N}\^{(1)}}\&{{x_N}\^{(2)}}\& \\cdots \&{{x_N}\^{(C)}} \\end{array}} \\right X(N×C)= x1(1)x2(1)⋯xN(1)x1(2)x2(2)⋯xN(2)⋯⋯⋯⋯x1(C)x2(C)⋯xN(C)
从批次维度计算得到的均值和方差向量
μ ( 1 × C ) = ( X ^ ( N × C ) ) . m e a n ( a x i s = 0 ) v a r ( 1 × C ) = ( X ^ ( N × C ) ) . v a r ( a x i s = 0 ) \begin{array}{l} {{\bf{\mu }}{(1 \times C)}} = \left( {{{{\bf{\hat X}}}{(N \times C)}}} \right){\rm{.mean(axis = 0)}}\\ {\bf{va}}{{\bf{r}}{(1 \times C)}} = \left( {{{{\bf{\hat X}}}{(N \times C)}}} \right){\rm{.var(axis = 0)}} \end{array} μ(1×C)=(X^(N×C)).mean(axis=0)var(1×C)=(X^(N×C)).var(axis=0)
缩放与偏移学习参数,目标是寻找使损失最小化的最优数据分布均值和方差
γ ( 1 × C ) = γ ( 1 ) γ ( 2 ) ⋯ γ ( C ) β ( 1 × C ) = β ( 1 ) β ( 2 ) ⋯ β ( C ) \begin{array}{l} {{\bf{\gamma }}{(1 \times C)}} = \left {\\begin{array}{c} {{\\gamma \^{(1)}}}\&{{\\gamma \^{(2)}}}\& \\cdots \&{{\\gamma \^{(C)}}} \\end{array}} \\right\\ {{\bf{\beta }}{(1 \times C)}} = \left {\\begin{array}{c} {{\\beta \^{(1)}}}\&{{\\beta \^{(2)}}}\& \\cdots \&{{\\beta \^{(C)}}} \\end{array}} \\right \end{array} γ(1×C)=γ(1)γ(2)⋯γ(C)β(1×C)=β(1)β(2)⋯β(C)
训练模式前向传播
Y ( N × C ) = γ ( 1 × C ) × X ( N × C ) − μ ( 1 × C ) v a r ( 1 × C ) + ε + β ( 1 × C ) {{\bf{Y}}{(N \times C)}} = {{\bf{\gamma }}{(1 \times C)}} \times \frac{{{{\bf{X}}{(N \times C)}} - {{\bf{\mu }}{(1 \times C)}}}}{{\sqrt {{\bf{va}}{{\bf{r}}{(1 \times C)}} + \varepsilon } }} + {{\bf{\beta }}{(1 \times C)}} Y(N×C)=γ(1×C)×var(1×C)+ε X(N×C)−μ(1×C)+β(1×C)
评估模式前向传播
μ r u n i n g ( 1 × C ) ← ( 1 − m o m e n t u m ) × μ r u n i n g ( 1 × C ) + m o m e n t u m × μ ( 1 × C ) v a r r u n i n g ( 1 × C ) ← ( 1 − m o m e n t u m ) × v a r r u n i n g ( 1 × C ) + m o m e n t u m × v a r ( 1 × C ) Y ( N × C ) = γ ( 1 × C ) × X ( N × C ) − μ r u n i n g ( 1 × C ) v a r r u n i n g ( 1 × C ) + ε + β ( 1 × C ) \begin{array}{l} \mathop {{{\bf{\mu }}{{\rm{runing}}}}}\limits^{(1 \times C)} \leftarrow \left( {1 - {\rm{momentum}}} \right) \times \mathop {{{\bf{\mu }}{{\rm{runing}}}}}\limits^{(1 \times C)} + {\rm{momentum}} \times {{\bf{\mu }}{(1 \times C)}}\\ \mathop {{\bf{va}}{{\bf{r}}{{\rm{runing}}}}}\limits^{(1 \times C)} \leftarrow \left( {1 - {\rm{momentum}}} \right) \times \mathop {{\bf{va}}{{\bf{r}}{{\rm{runing}}}}}\limits^{(1 \times C)} + {\rm{momentum}} \times {\bf{va}}{{\bf{r}}{(1 \times C)}}\\ {{\bf{Y}}{(N \times C)}} = {{\bf{\gamma }}{(1 \times C)}} \times \frac{{{{\bf{X}}{(N \times C)}} - \mathop {{{\bf{\mu }}{{\rm{runing}}}}}\limits^{(1 \times C)} }}{{\sqrt {\mathop {{\bf{va}}{{\bf{r}}{{\rm{runing}}}}}\limits^{(1 \times C)} + \varepsilon } }} + {{\bf{\beta }}{(1 \times C)}} \end{array} μruning(1×C)←(1−momentum)×μruning(1×C)+momentum×μ(1×C)varruning(1×C)←(1−momentum)×varruning(1×C)+momentum×var(1×C)Y(N×C)=γ(1×C)×varruning(1×C)+ε X(N×C)−μruning(1×C)+β(1×C)
层梯度
G R A D ( N × C ) = γ ( 1 × C ) v a r ( 1 × C ) + ε × ( g r a d ( N × C ) − 1 N ⋅ g r a d . s u m ( a x i s = 0 ) ( 1 × C ) − 1 N ⋅ X ^ ( N × C ) × ( g r a d ( N × C ) × X ^ ( N × C ) ) . s u m ( a x i s = 0 ) ( 1 × C ) ) {\bf{GRA}}{{\bf{D}}{(N \times C)}} = \frac{{{{\bf{\gamma }}{(1 \times C)}}}}{{\sqrt {{\bf{va}}{{\bf{r}}{(1 \times C)}} + \varepsilon } }} \times \left( {{\bf{gra}}{{\bf{d}}{(N \times C)}} - \frac{1}{N} \cdot \mathop {{\bf{grad}}{\rm{.sum(axis = 0)}}}\limits^{(1 \times C)} - \frac{1}{N} \cdot {{{\bf{\hat X}}}{(N \times C)}} \times \left( {{\bf{gra}}{{\bf{d}}{(N \times C)}} \times {{{\bf{\hat X}}}_{(N \times C)}}} \right)\mathop {{\rm{.sum(axis = 0)}}}\limits^{(1 \times C)} } \right) GRAD(N×C)=var(1×C)+ε γ(1×C)×(grad(N×C)−N1⋅grad.sum(axis=0)(1×C)−N1⋅X^(N×C)×(grad(N×C)×X^(N×C)).sum(axis=0)(1×C))
可学习参数梯度
d γ ( 1 × C ) = ( g r a d ( N × C ) × X n o r m ( N × C ) ) . s u m ( a x i s = 0 ) d β ( 1 × C ) = ( g r a d ( N × C ) ) . s u m ( a x i s = 0 ) \begin{array}{l} {\bf{d}}{{\bf{\gamma }}{(1 \times C)}} = \left( {{\bf{gra}}{{\bf{d}}{(N \times C)}} \times \mathop {{{\bf{X}}{{\bf{norm}}}}}\limits^{(N \times C)} } \right).sum(axis = 0)\\ {\bf{d}}{{\bf{\beta }}{(1 \times C)}} = \left( {{\bf{gra}}{{\bf{d}}_{(N \times C)}}} \right){\rm{.sum(axis = 0)}} \end{array} dγ(1×C)=(grad(N×C)×Xnorm(N×C)).sum(axis=0)dβ(1×C)=(grad(N×C)).sum(axis=0)
推导过程参考:神经网络批归一化层梯度公式推导
封装
python
class BatchNorm1d(Module):
def __init__(self, num_features, eps=1e-5, momentum=0.1):
"""
参数:
num_features: 输入特征的数量 (C)
eps: 数值稳定性常数
momentum: 移动平均的动量
"""
super().__init__()
self.eps = eps
self.momentum = momentum
self.num_features = num_features
# 可训练参数(需要更新)
self.gamma = Parameter(np.ones((1, num_features)), requires_grad=True) # 缩放参数
self.beta = Parameter(np.zeros((1, num_features)), requires_grad=True) # 平移参数
# 移动平均参数(评估时使用)
self.running_mean = np.zeros((1, num_features))
self.running_var = np.ones((1, num_features))
# 缓存中间变量(用于反向传播)
self.cache = {}
def forward(self, x):
"""
Args:
x: 输入数据,形状可以是 (N, C) 或 (N, C, L)
"""
# 保存输入形状,用于恢复
input_shape = x.shape
# 处理不同维度的输入
if len(input_shape) == 3: # (N, C, L)
N, C, L = input_shape
# 重排为 (N*L, C) 方便计算
x = x.transpose(0, 2, 1).reshape(-1, C)
self.cache['input_shape'] = input_shape
self.cache['N'] = N
self.cache['C'] = C
self.cache['L'] = L
else: # (N, C)
N, C = input_shape
self.cache['input_shape'] = input_shape
self.cache['N'] = N
self.cache['C'] = C
self.cache['L'] = 1
if self.training:
# 计算当前批次的均值和方差
batch_mean = np.mean(x, axis=0, keepdims=True)
batch_var = np.var(x, axis=0, keepdims=True)
# 更新移动平均
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * batch_mean
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * batch_var
# 归一化
x_norm = (x - batch_mean) / np.sqrt(batch_var + self.eps)
# 缓存中间变量用于反向传播
self.cache['batch_mean'] = batch_mean
self.cache['batch_var'] = batch_var
self.cache['x_norm'] = x_norm
else:
# 评估模式:使用移动平均
x_norm = (x - self.running_mean) / np.sqrt(self.running_var + self.eps)
# 缩放和平移
out = self.gamma.data * x_norm + self.beta.data
self.cache['out'] = out
# 恢复原始形状
if (len(input_shape) == 3):
out = out.reshape(N, L, C).transpose(0, 2, 1)
return out
def backward(self, grad):
# 处理不同维度的输入
if len(self.cache['input_shape']) == 3:
N, C, L = self.cache['input_shape']
# 将梯度重排为 (N*L, C)
grad = grad.transpose(0, 2, 1).reshape(-1, C)
else:
N, C = self.cache['input_shape']
# 获取缓存的中间变量
batch_mean = self.cache['batch_mean']
batch_var = self.cache['batch_var']
x_norm = self.cache['x_norm']
# 计算 gamma 和 beta 的梯度
self.gamma.grad += np.sum(grad * x_norm, axis=0, keepdims=True)
self.beta.grad += np.sum(grad, axis=0, keepdims=True)
# 层梯度
dx = self.gamma.data / np.sqrt(batch_var + self.eps) * (grad - grad.sum(axis=0, keepdims=True) / N - x_norm * (grad * x_norm).sum(axis=0, keepdims=True) / N)
# 恢复原始形状
if len(self.cache['input_shape']) == 3:
dx = dx.reshape(N, L, C).transpose(0, 2, 1)
return dx
def __call__(self, x):
return self.forward(x)
def __repr__(self):
return self.__class__.__name__ + f'(num_features={self.num_features}, eps={self.eps}, momentum={self.momentum})'测试
python
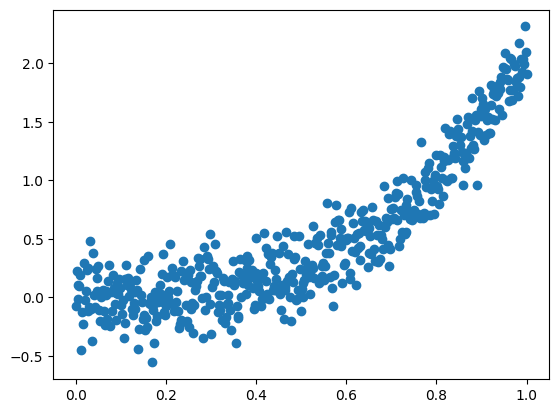
%matplotlib inline
# 数据点满足非线性关系
x = np.linspace(0, 1, 500).reshape(-1, 1)
y = 2 * x**3 + 0.2* np.random.randn(500).reshape(-1, 1)
plt.scatter(x, y)
plt.show()
python
# 定义模型和损失函数
model = Sequential(
Linear(1, 15),
Tanh(),
BatchNorm1d(15),
Linear(15, 1),
)
criterion = MSELoss()
python
optimizer = Adam(params=model.parameters(), lr=1e-2)
python
model.train()
# 训练流程
for epoch in range(200):
y_pred = model(x)
loss, grad = criterion(y_pred, y)
model.backward(grad)
optimizer.step()
optimizer.zero_grad()
if(epoch % 200 == 0):
print(loss)0.6625318142073177
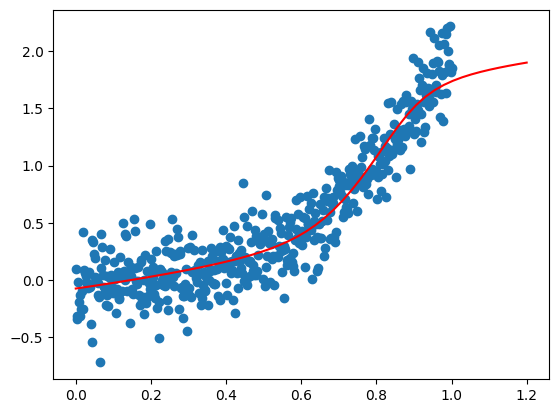
python
%matplotlib inline
model.eval()
# 检验拟合效果
x_plot = np.linspace(0, 1.2, 50).reshape(-1, 1)
plt.plot(x_plot, model(x_plot), c='r')
plt.scatter(x, y)
plt.show()
BatchNorm2d层
如果输入数据为批处理图像,即具有 N × C × H × W N \times C \times H \times W N×C×H×W形状的数据,那么只需将最后两个维度展平,然后传入BatchNorm1d层处理即可。
封装
python
class BatchNorm2d(BatchNorm1d):
def __init__(self, num_features, eps=1e-5, momentum=0.1):
"""
参数:
num_features: 输入特征的数量 (C)
eps: 数值稳定性常数
momentum: 移动平均的动量
"""
super().__init__(num_features, eps, momentum)
self.input_shape = None
def forward(self, x):
"""
Args:
x: 输入数据,形状为 (N, C, H, W)
"""
# 保存输入形状,用于恢复
self.input_shape = x.shape
# 四个维度分别为批次数、通道数、图像高度、图像宽度
N, C, H, W = self.input_shape
# 展平后两个维度
x = x.reshape(N, C, H*W)
# 传入父类前向传播
out = super().forward(x)
# 还原形状
return out.reshape(N, C, H, W)
def backward(self, grad):
# 接收输入形状
N, C, H, W = self.input_shape
# 展平后两个维度
grad = grad.reshape(N, C, H*W)
# 传入父类反向传播
grad = super().backward(grad)
# 还原形状
return grad.reshape(N, C, H, W)Dropout层
封装
python
class Dropout(Module):
def __init__(self, p=0.5):
"""
Args:
p: 神经元被置零的概率
"""
super().__init__()
self.p = p
self.mask = None
def forward(self, x):
# 评估模式不使用Dropout
if not self.training or self.p == 0:
return x
# 生成掩码,保留概率为1 - p
keep_prob = 1 - self.p
self.mask = np.random.binomial(1, keep_prob, size=x.shape) / keep_prob
return x * self.mask
def backward(self, grad):
# 评估模式不使用Dropout
if not self.training or self.p == 0:
return grad
# 反向传播时,梯度通过相同的掩码
return grad * self.mask
def __call__(self, x):
return self.forward(x)
def __repr__(self):
return self.__class__.__name__ + f"(p={self.p})"测试
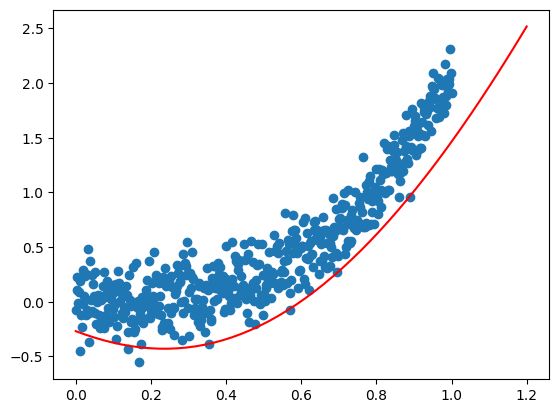
python
%matplotlib inline
# 数据点满足非线性关系
x = np.linspace(0, 1, 500).reshape(-1, 1)
y = 2 * x**3 + 0.2* np.random.randn(500).reshape(-1, 1)
plt.scatter(x, y)
plt.show()
python
# 定义模型和损失函数
model = Sequential(
Linear(1, 30),
Tanh(),
Dropout(p=0.2),
Linear(30, 15),
Tanh(),
Dropout(p=0.2),
Linear(15, 1),
)
criterion = MSELoss()
python
optimizer = Adam(params=model.parameters(), lr=1e-2)
python
model.train()
# 训练流程
for epoch in range(1000):
y_pred = model(x)
loss, grad = criterion(y_pred, y)
model.backward(grad)
optimizer.step()
optimizer.zero_grad()
if(epoch % 200 == 0):
print(loss)0.05895352855605514
0.05955724161945543
0.05435588561688262
0.05203513368390939
0.052702349514423374
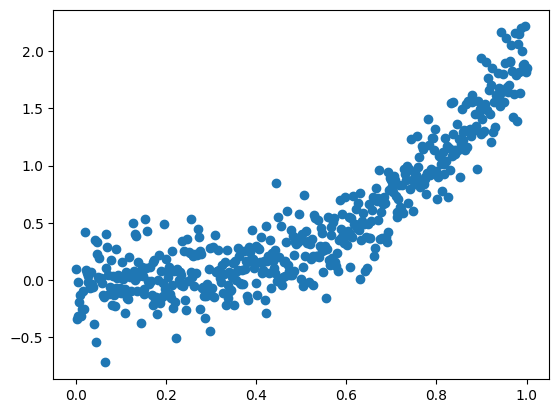
python
%matplotlib inline
model.eval()
# 检验拟合效果
x_plot = np.linspace(0, 1.2, 50).reshape(-1, 1)
plt.plot(x_plot, model(x_plot), c='r')
plt.scatter(x, y)
plt.show()