二叉树
二叉树:每个结点最多两个孩子:左孩子、右孩子。
满二叉树:每一层结点全部长满,没有空缺。
完全二叉树:最后一层从左往右排,右边可以为空,左边不能缺。
斜树:全部只有在左/右孩子,最差的形态。
遍历
顺序是根据根的前后顺序定的,左右顺序永远不变。
- 前序
根->左->右
- 中序
左->根->右
- 后序
左->右->根
确认唯一二叉树:
- 前序+中序->唯一二叉树
- 后序+中序->唯一二叉树
- 前序+后续->不能确定唯一二叉树
计算公式
深度/层数:h(根是第一层)
结点总数:n
叶子结点树:n0
度1结点:n1
度2结点:n2
结点的度:该结点拥有的子节点个数。
度数公式
叶子结点数=度2节点树+1
结点总数
n= n0+ n1+ n2
二叉树层数结点范围
第k层最多结点数=2^(k-1)
深度为h的二叉树总结点最大值(满二叉树)=2^h-1
深度为h的二叉树总节点最小值=2^(h-1)
深度范围
n个结点的二叉树:
最小深度(完全二叉树)=(log2n)+1
最大深度(斜树)=n
完全二叉树专有公式
总结点为n,度1结点只有0或1个
编号规则(根=1,从上到下、从左到右):
- 结点i的左孩子=2i
- 结点i的右孩子=2i+1
- 结点i的双亲=i/2
线索二叉树
作用:利用空指针,保存前驱、后继,方便遍历。
N个结点二叉树,空链域数量=n+1
哈夫曼树(最优二叉树)
规则:每次选权值最小的两个结点合并,新的结点权值=两数之和。
特点:
- 没有度为1的节点
- 叶子数n0,总结点=2n0-1
- 带权路径长度WPL最小
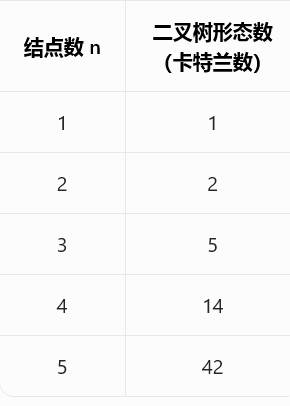
卡特兰数
卡特兰数:n个结点的二叉树的形态数。
公式: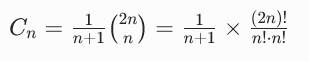
常见卡特兰数:
邻接表
邻接表:给每一个顶点开一个链表(或动态数组),只存它直接相连的点和边权。
邻接矩阵:行列数都为节点个数,如节点数为5,边为7,则为5*5的矩阵。
链表
循环链表:在单向链表(或双向链表)基础上,令表尾节点的指针指向表中的第一个节点,构成循环链表。特点是可以从表中任何节点可是遍历整个链表。
排序算法
各种排序算法的时间复杂度和空间复杂度:
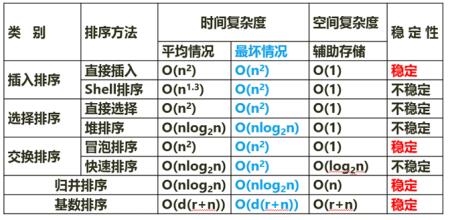
时间复杂度:衡量算法运行时间随着数据量n增长的变化趋势。平均情况,指的是随机数据下的表现。最坏情况,是指数据完全有序/逆序时的最差表现。O(1)=固定几次。O(n)=跟着数据量线性走。O(n2)=双层循环。O(nlogn)=分层+分治,每层n,层数logn。
空间复杂度:衡量算法额外需要的内存空间,重点看除了原数组外,额外开了多少空间。O(1)=原地排序,几乎不需要额外的空间。O(log2n)=递归栈的深度带来的额外空间。O(n)=需要额外开一个和原数组一样大的辅助数组。
- 稳定:相等元素相对位置不变。
- 不稳定:会乱序。
| 时间复杂度 | 排序算法 | 记忆 |
|---|---|---|
| O(n^2) | 冒泡排序 | 都是两层循环,一层遍历轮数,一层内部逐个对比,嵌套循环->n*n |
| O(n^2) | 插入排序 | 都是两层循环,一层遍历轮数,一层内部逐个对比,嵌套循环->n*n |
| O(n^2) | 选择排序 | 都是两层循环,一层遍历轮数,一层内部逐个对比,嵌套循环->n*n |
| O(nlogn) | 快速排序 | 都是分治思想,拆分logn层,每层干n次活 |
| O(nlogn) | 归并排序 | 都是分治思想,拆分logn层,每层干n次活 |
| O(nlogn) | 堆排序 | 都是分治思想,拆分logn层,每层干n次活 |
#include <iostream>
#include <vector>
using namespace std;
// 打印数组
void print(int arr[], int n)
{
for(int i = 0; i < n; i++)
cout << arr[i] << " ";
cout << endl;
}
int main()
{
int arr[] = {5,3,8,4,2};
//自动算数组长度,仅限普通静态数组,不能用在函数内部
int n = sizeof(arr) / sizeof(arr[0]);
return 0;
}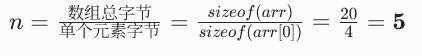
插入排序类
直接插入排序
排序方式:把数组分为左边有序区+右边无序区,每次那一个无序区的第一个往前挨个比较,插到有序区的合适位置。
举例:5,3,8,4,2,设5为有序,3,8,4,2为无序
- 3,5,8,4,2,此时8,4,2为无序
3,5,8,4,2
3,4,5,8,2
2,3,4,5,8
时间复杂度:最好(完全有序)时,每个数只比一次O(n);平均/最坏时,每个元素都要往前挪、对比多次O(n^2)。
空间复杂度:仅临时变量存待插入值O(1)。
稳定性:稳定。
适用场景 :数据基本有序,小规模数据,希尔排序的底层基础。
- 优点:稳定、原地、简单;数据越有序,越快,最好O(n);不需要大量交换,只是后移。
- 缺点:最坏/平均O(n^2);大数据非常慢。
// 直接插入
void insertSort(int arr[], int n)
{
for(int i = 1; i < n; i++)
{
int temp = arr[i];
int j;
for(j = i - 1; j >= 0 && arr[j] > temp; j--)
{
arr[j+1] = arr[j];
}
arr[j+1] = temp;
}
}Shell排序(希尔排序,缩小增量插入)
排序方式:先取一个增量gap(gap=数组长度/2,向下取整),把数组按gap分组(按下标每隔一个gap取一个),每组内部做插入排序,不断缩小gap,直到gap=1退化为普通插入。大的数快速跳到后面,减少后期挪动次数。
举例:5,3,8,4,2,取gap=2->gap=1
- gap=2,分组为5,8,2、3,4,分别排序为2,5,8和3,4,填回原来的下标,合并数组2,3,5,4,8
- gap=1,退化为直接排序,得到2,3,4,5,8
时间复杂度:平均O(n^1.3),最坏O(n^2)。
空间复杂度:没有额外的数组O(1)。
稳定性:不稳定。
适用场景: 中等规模数据;嵌入式、简单工程轻量排序;不需要严格稳定的场景。
- 优点: 插入排序优化版,远远快于冒泡、插入、选择;平均O(n^1.3)。中等数量够用;原地排序O(1)。
- 缺点: 不稳定;增量规则不统一,数学逻辑复杂;最坏还是O(n^2)。
// 希尔
void shellSort(int arr[], int n)
{
int gap = n / 2;
while(gap > 0)
{
for(int i = gap; i < n; i++)
{
int temp = arr[i];
int j;
for(j = i - gap; j >= 0 && arr[j] > temp; j -= gap)
{
arr[j+gap] = arr[j];
}
arr[j+gap] = temp;
}
gap /= 2;
}
}选择排序类
直接选择排序(简单选择排序)
排序方式:每一轮在无序区找最小值,和无序区第一个位置交换,一轮锁定一个最左侧的有序数。
举例:5,3,8,4,2
- 找全局最小2,和第一位交换->2,3,8,4,5
- 在3,8,4,5里面找最小值3->2,3,8,4,5
2,3,4,8,5
2,3,4,5,8
时间复杂度:不管有序无序,每轮都要遍历找最小值,固定比较次数为n(n-1)/2,最好/最坏/平均时,O(n^2)。
空间复杂度:仅存最小值下标,O(1)。
稳定性:不稳定,远距离交换会打乱相等元素。
适用场景: 对交换次数有要求的场景;极小量数据,不在乎时间。
- 优点: 思路简单,交换次数少;原地排序O(1)。
- 缺点: 不稳定,不论是否有序,都要全遍历,固定O(n^2),效率差。
// 简单选择
void selectSort(int arr[], int n)
{
for(int i = 0; i < n; i++)
{
int minIdx = i;
for(int j = i + 1; j < n; j++)
{
if(arr[j] < arr[minIdx])
minIdx = j;
}
swap(arr[i], arr[minIdx]);
}
}堆排序
排序方式:把数组建立成大顶堆(父节点≥子节点),堆顶是最大值,交换到数组末尾(末尾有序),剩余元素重新调整为大顶堆,循环执行。
举例:5,3,8,4,2
- 建大顶堆8,4,5,3,2
- 堆顶最大值和最末尾值交换,保证最大值放末尾->2,4,5,3,8,调整剩余堆
- 堆顶5放在倒数第二->2,4,3,5,8
- ......
2,3,4,5,8
建堆规则:必须是完全二叉树,一层一层建满,不能空位置、不能跳格、不能随便挂节点。
下沉规则:只和左右两个孩子比,谁大和谁换。
顶尾交换规则:只和最大的孩子比,比如此时是第二轮,5的最大孩子是4,则和该分支最小的交换。
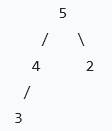
时间复杂度:建立堆O(n),每次调整堆O(logn)共n次,总的为O(nlogn)。
空间复杂度:原地在数组上建堆、调整,只用到临时变量,O(1)。
稳定性:不稳定。
适用场景: 内存受限、不能开额外数组;只需要找出最大/最小的前K个元素;操作系统、优先队列、任务调度。
- 优点: 稳定O(nlogn);原地排序O(1),不占额外内存;适合动态取最佳(优先队列)。
- 缺点:不稳定;缓存不友好,实际速度略慢于快排;建堆、下沉逻辑复杂。
// 下沉调整
void adjustHeap(int arr[], int idx, int len)
{
int temp = arr[idx];
// 左孩子
for(int i = idx * 2 + 1; i < len; i = i * 2 + 1)
{
// 找左右孩子最大
if(i+1 < len && arr[i+1] > arr[i])
i++;
if(arr[i] > temp)
{
arr[idx] = arr[i];
idx = i;
}
else break;
}
arr[idx] = temp;
}
// 堆排序
void heapSort(int arr[], int n)
{
// 初始建大顶堆:从最后一个非叶子结点往前
for(int i = n/2 - 1; i >= 0; i--)
adjustHeap(arr, i, n);
// 逐轮交换堆顶+末尾,再调整
for(int i = n - 1; i > 0; i--)
{
swap(arr[0], arr[i]);
adjustHeap(arr, 0, i);
}
}交换排序类
冒泡排序
排序方式:相邻两个元素两两相比,前面比后面大就交换,一轮下来最大的数沉到最后。
举例:5,3,8,4,2
3,5,8,4,2\]-\>\[3,5,4,8,2\]-\>\[3,5,4,2,8
3,4,5,2,8\]-\>\[3,4,2,5,8
3,2,4,5,8\]-\>\[2,3,4,5,8
时间复杂度:最好(本来就有序)时,加标记,只走一轮O(n);最坏(完全逆序)时,双层循环O(n^2);平均为O(n^2)。
空间复杂度:只用了临时变量交换、标记位,不开新数组、不递归,O(1)。
稳定性:稳定,相等值不交换。
适用场景:数据量很小、对效率无要求;基本有序的少量数据。
- 优点:逻辑简单、代码短;稳定排序;原地排序,空间O(1);数据接近有序时效率比较高。
- 缺点:时间复杂度高O(n^2);大量无效交换,效率低;不适合大量数据。
// 冒泡
void bubbleSort(int arr[], int n)
{
for(int i = 0; i < n - 1; i++)
{
for(int j = 0; j < n - 1 - i; j++)
{
if(arr[j] > arr[j+1])
swap(arr[j], arr[j+1]);
}
}
}快速排序
排序方式:分治+基准,选一个基准数,双指针(小的放左边,大的放右边),基准归位,左边右边递归重复。
基准归位:定义左右两个指针,L负责找比基准大的,R负责找比基准小的,两个指针分别往数组另一边走,找到比基准大/小的树,指针指着的两个数互换,直到左右指针碰面,一轮结束。左右指针碰面后,基准与当前数交换。基准选最左边,必须先动右指针R;基准选最右边,必须先动左指针L。
举例:5,3,8,4,2,选5为基准。
- 小于5的放左边,大于5的放右边,放完之后一趟就有2,3,4,5,8
时间复杂度:平均时,每次对半分,递归层数log2n,每一层一共处理n个数据,O(nlogn);最坏(完全有序/逆序)时,每次划分一边一个,一边n-1个,递归层数变成了n,O(n^2)。
空间复杂度:额外的空间用于递归调用栈。平均递归深度为log2n,O(logn);最坏深度n,O(n)。
稳定性:不稳定。
适用场景: 大数据量首选;日常开发、系统内置排序底层(C++/Java底层都是改良快排);不要求排序稳定的场景。
- 优点: 平均O(nlogn),所有排序中最快;常数时间小、实际运行效率极高;递归实现简洁。
- 缺点: 不稳定;最坏退化O(n^2);递归占用栈空间O(logn)。
// 快速排序
void quickSort(int arr[], int left, int right)
{
if(left >= right)
return;
int i = left, j = right;
int pivot = arr[left];
while(i < j)
{
// 右指针找 小于pivot
while(i < j && arr[j] >= pivot)
j--;
// 左指针找 大于pivot
while(i < j && arr[i] <= pivot)
i++;
if(i < j)
swap(arr[i], arr[j]);
}
// 指针相遇,交换基准
arr[left] = arr[i];
arr[i] = pivot;
quickSort(arr, left, i - 1);
quickSort(arr, i + 1, right);
}归并排序
排序方式:分治+合并,不断把数组对半劈开,直到每组只有一个元素(天然有序),开一个辅助数组,把两个有序的小数组,按大小合并成大且有序的数组。
举例:5,3,8,4,2
- 拆分:5,3,8、4,2
- 继续拆:5,3、8、4、2
- 继续拆:5、3、8、4、2
- 合并:3,5、2,4
3,5,8\]、\[2,4\],合并\[2,3,4,5,8
时间复杂度:拆分层数为log2n,每层合并总要处理n个元素,最好/最坏/平均都为O(nlogn)。
空间复杂度:合并时必须单独开一个辅助数组,和原数组大小一样,固定的额外空间为O(n)。
稳定性:稳定。
适用场景 : ++必须保证排序稳定++;海量数据、磁盘外排序;大数据且不缺内存的场景。
- 优点: 时间绝对稳定O(nlogn);稳定排序,相等元素位置不变;适合外排序,数据太大放不了内存。
- 缺点: 需要额外辅助数组,空间O(n);常数开销大,实际速度比快排慢。
// 合并
void merge(int arr[], int temp[], int left, int mid, int right)
{
int i = left, j = mid + 1, k = left;
while(i <= mid && j <= right)
{
if(arr[i] <= arr[j])
temp[k++] = arr[i++];
else
temp[k++] = arr[j++];
}
while(i <= mid)
temp[k++] = arr[i++];
while(j <= right)
temp[k++] = arr[j++];
for(int p = left; p <= right; p++)
arr[p] = temp[p];
}
// 归并递归拆分
void mergeSort(int arr[], int temp[], int left, int right)
{
if(left >= right)
return;
int mid = (left + right) / 2;
mergeSort(arr, temp, left, mid);
mergeSort(arr, temp, mid+1, right);
merge(arr, temp, left, mid, right);
}
// 统一调用入口
void mergeSort(int arr[], int n)
{
int* temp = new int[n];
mergeSort(arr, temp, 0, n-1);
delete[] temp;
}基数排序
排序方式:不是比大小,而是按每一位排序,比如个位、十位、百位......依次桶排序。
时间复杂度:d为位数,r为基数,O(d*(n+r))。
空间复杂度:需要桶容器O(n+r)。
适用场景: 大量整数、手机号、学号、身份证等;位数不多的批量数据。
- 优点: 时间线性O(d*(r+n)),数据极大时碾压比较排序;稳定。
- 缺点: 只能排整数、字符串这类固定位数数据;额外空间大;不能通用所有数据。
查找算法
查找分类:
- 静态查找:数据不变(顺序、二分、分块)。
- 动态查找:数据频繁增删(哈希、二叉树排序)。
- 有序查找、无序查找
顺序查找(线性查找)
查找原理:不管数组有序无序,从第一个元素挨个往后对比,找到就返回下标,遍历完没找到就返回-1。
复杂度:最好O(1),第一个就是;最坏/平均O(n)。
适用场景:数据量很小,数据无序,没法二分。
- 优点:简单、支持无序数组、链表也能用。
- 缺点:数据量大极慢。
折半查找(二分查找)
查找原理:数组必须提前升序/降序有序,取中间mid,目标<mid,去左边找,否则去右边找。
时间复杂度:O(log2n)极快
空间复杂度:O(1)
适用场景:有序静态数组;频繁查找、很少修改。
- 优点:效率高、大数据首选。
- 缺点:必须有序;插入删除麻烦,要重排。
// 二分查找 非递归
int binarySearch(int arr[], int n, int key)
{
int left = 0;
int right = n - 1;
while(left <= right)
{
int mid = (left + right) / 2;
if(arr[mid] == key)
return mid;
else if(key < arr[mid])
right = mid - 1; // 左半区
else
left = mid + 1; // 右半区
}
return -1;
}
或递归二分:
int binarySearchRec(int arr[], int l, int r, int key)
{
if(l > r)
return -1;
int mid = (l + r) / 2;
if(arr[mid] == key)
return mid;
else if(key < arr[mid])
return binarySearchRec(arr, l, mid-1, key);
else
return binarySearchRec(arr, mid+1, r, key);
}分块查找
查找原理:把数组分为若干块,建立索引表,记录每块最大值、块起始位置,先查索引确定目标在哪一块,再在块内顺序查找。
复杂度:平均O(√n),介于顺序O(n)和二分O(logn)中间。
适用场景:数据量大、局部有序、整体难排序;介于顺序和二分之间的折中场景。
- 优点:不用全局有序;增删比二分方便。
- 缺点:需要额外的索引空间;效率不如二分。
二叉排序树查找
二叉排序树的定义规则:左子树所有节点值<根节点值;右子树所有节点值>根节点值;左右子树同样满足上面要求。
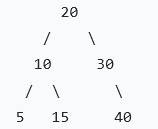
查找原理:从根节点开始,目标值更小->走左子树,否则走右子树;相等则查找成功;走到空结点则查找失败。
时间复杂度:树比较平衡,理想情况O(logn);最坏(斜树/单链)时,数据有序插入,树退化成一条直线O(n);平均O(logn)。
空间复杂度:非递归查找O(1);递归查找O(logn)~O(n)。
适用场景:
- 动态数据场景,频繁查找、插入、删除;
- 不需要严格平衡、追求实现简单;
- 数据库、索引、容器底层基础结构;
- 适合频繁修改的数据集,不适合固定静态有序数组。
- 优点:支持动态数据;理想平衡状态下,查找效率接近二分查找O(logn);不需要整片连续有序数组,存储空间灵活;天然自带大小顺序,方便范围查询。
- 缺点:数据有序插入时,容易变成斜树,效率退化到O(n);树结构复杂,实现、维护比数组麻烦;查询效率极度依赖树的平衡;不适合静态、固定不变的海量数据。
// 二叉排序树查找,非递归
TreeNode* BST_Search(TreeNode* root, int key)
{
TreeNode* p = root;
while(p != nullptr)
{
if(key == p->val)
return p; // 找到
else if(key < p->val)
p = p->left; // 小走左
else
p = p->right; // 大走右
}
return nullptr; // 没找到
}
// 二叉排序树查找,递归
TreeNode* BST_Search_Rec(TreeNode* root, int key)
{
if(root == nullptr)
return nullptr;
if(key == root->val)
return root;
else if(key < root->val)
return BST_Search_Rec(root->left, key);
else
return BST_Search_Rec(root->right, key);
}哈希查找(散列查找)
查找原理:通过哈希函数,直接算出存放的下标,一步定位。
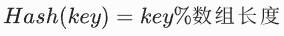
哈希冲突:两个不同的key,算出了同一个下标。比如哈希数组长度为5,数字7和12算出来下标都为2。
复杂度:理想无冲突O(1);最坏O(n)。
适用场景:
- 高频增删改;
- 海量数据缓存、集合、map底层。
- 优点:查找、插入、删除都极快。
- 缺点:有哈希冲突;无序、不能范围查找。