论文信息
- 标题:End-to-End Object Detection with Transformers
- 会议:ECCV 2020
- 单位:Facebook AI
- 代码:https://github.com/facebookresearch/detr
- 论文:https://arxiv.org/pdf/2005.12872.pdf
前言
目标检测一直被锚框、候选框、NMS 等手工设计组件"绑架",流程繁琐且调参痛苦。DETR 直接把检测当成集合预测问题,用 CNN + Transformer 一套到底,彻底抛弃先验框与后处理,真正做到端到端。本文带你逐段精读、公式拆解、图表逐张分析,吃透这篇划时代工作。
一、核心思想总览
DETR 做了一件极简但颠覆性的事:
- 把目标检测定义为直接集合预测,输出一组框而非稠密预测
- 用二分图匹配(匈牙利算法) 强制一对一匹配,天然去重
- 用 Transformer 做全局关系建模,并行输出所有目标
- 结构极简,无需自定义层,几十行代码就能复现
二、整体架构与流程图详解
图 1:DETR 端到端检测流程

图 1:DETR 通过将通用卷积神经网络与变压器架构相结合,直接(并行)预测最终的检测集。在训练期间,二分匹配将预测与真实框唯一对应。未匹配的预测应产生"无对象"(ø)类别预测。
- 图片说明:输入图像 → CNN 提取特征 → Transformer 编码全局信息 → Transformer 解码输出固定数量预测 → 二分匹配损失监督。
- 深度解读 :
- 不再生成上千个锚框,只输出固定 100 个预测框
- 无 NMS,匹配损失自带"去重"属性
- 无锚框设计,框直接相对原图回归,更干净
图2:DETR 详细架构
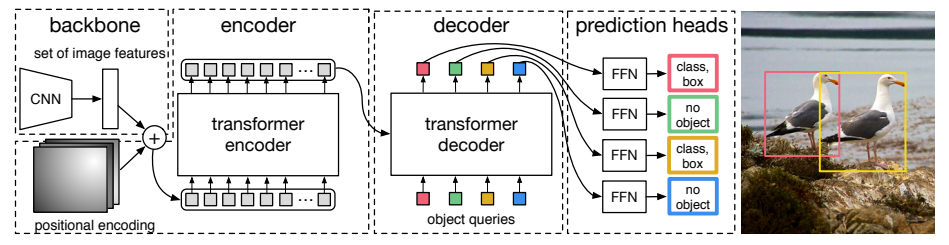
图 2:DETR 使用传统的卷积神经网络(CNN)骨干网络来学习输入图像的二维表示。模型将其展平,并添加位置编码,然后将其传递给一个变压器编码器。接着,一个变压器解码器将少量固定数量的学习位置嵌入作为输入,我们称其为对象查询,并且还关注编码器的输出。我们将解码器的每个输出嵌入传递给一个共享的前馈网络(FFN),该网络预测检测结果(类别和边界框)或"无对象"类别。
结构分为 4 个模块:
- CNN 主干:ResNet50/101 下采样 32 倍,提取 2048 维特征
- 1×1 卷积降维:把通道压到 d=256,拉直成序列送入 Transformer
- Transformer 编码器:全局自注意力,建模物体间关系
- Transformer 解码器:100 个**目标查询(object queries)**并行解码
- FFN 预测头:每个查询输出(类别+4维框)
- 通俗解释:编码器负责"看懂全局场景",解码器负责"找出所有物体",object query 相当于 100 个可学习的"查找模板"。
三、核心损失函数:匈牙利匹配 + 框损失
1)二分图匹配代价
Lmatch(yi,y^σ(i))=−1ci≠∅p^σ(i)(ci)+1ci≠∅Lbox(bi,b^σ(i))L_{match}(y_i,\hat{y}{\sigma(i)}) = -\mathbb{1}{c_i≠∅}\hat{p}{\sigma(i)}(c_i)+\mathbb{1}{c_i≠∅}L_{box}(b_i,\hat{b}_{\sigma(i)})Lmatch(yi,y^σ(i))=−1ci=∅p^σ(i)(ci)+1ci=∅Lbox(bi,b^σ(i))
- yiy_iyi:第 i 个真实目标,包含类别 cic_ici 和框 bib_ibi
- y^σ(i)\hat{y}_{\sigma(i)}y^σ(i):匹配到的第 σ(i) 个预测框
- ∅∅∅:无目标背景类
- 通俗解释:给每个预测框找唯一对应的真实框,兼顾分类置信度与框位置。
2)匈牙利损失
LHungarian(y,y^)=∑i=1N−logp\^σ\^(i)(ci)+1ci≠∅Lbox(bi,b\^σ\^(i))\mathcal{L}{Hungarian}(y,\hat{y})=\sum{i=1}^N\left-log\\hat{p}_{\\hat{\\sigma}(i)}(c_i)+\\mathbb{1}_{c_i≠∅}\\mathcal{L}_{box}(b_i,\\hat{b}_{\\hat{\\sigma}(i)})\\rightLHungarian(y,y^)=∑i=1N−logp\^σ\^(i)(ci)+1ci=∅Lbox(bi,b\^σ\^(i))
- 对匹配好的对计算:分类负对数似然 + 框回归损失
- 背景类损失降权 10 倍,缓解类别不平衡
3)框损失(L1 + GIoU)
Lbox(bi,b^i)=λiouLiou(bi,b^i)+λL1∣∣bi−b^i∣∣1\mathcal{L}{box}(b_i,\hat{b}i) = λ{iou}\mathcal{L}{iou}(b_i,\hat{b}i)+λ{L1}||b_i-\hat{b}_i||_1Lbox(bi,b^i)=λiouLiou(bi,b^i)+λL1∣∣bi−b^i∣∣1
- λL1=5,λiou=2λ_{L1}=5, λ_{iou}=2λL1=5,λiou=2
- GIoU 保证尺度不变,L1 保证偏移稳定
四、关键图表与实验深度解析
表1:DETR 与 Faster R-CNN 对比(来源:原论文 Table 1)
| 模型 | AP | APs | APl |
|---|---|---|---|
| Faster R-CNN-FPN+ | 42.0 | 26.6 | 53.4 |
| DETR | 42.0 | 20.5 | 61.1 |
- 表格分析:
- DETR 整体精度持平最强 Faster R-CNN
- 大物体 AP 狂涨 7.8,因为 Transformer 全局感受野
- 小物体弱 5.5,是早期 Transformer 通病
图3:编码器自注意力可视化

图 3:一组参考点的编码器自注意力。编码器能够区分各个实例。在验证集图像上使用基线 DETR 模型进行预测。
- 图中标记了三个参考点,颜色代表注意力权重
- 解读:编码器会自动区分不同实例,把注意力集中在对应物体上,帮解码器轻松定位。
图4:解码器层数与 AP 变化
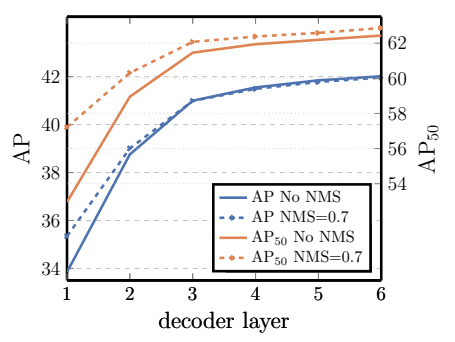
图 4:每个解码器层后的 AP 和 AP50 性能。对单个长计划基准模型进行了评估。DETR 从设计上就不需要 NMS,这一点从该图中得到了验证。NMS 会降低最后几层的 AP,从而剔除 TP 预测,但在第一个解码器层会提高 AP,剔除重复预测,因为第一层没有信息交流,并且略微提高了 AP50。
- 横轴:解码器层数;纵轴:AP/AP50
- 解读:
- 层数越深,AP 越高,从 34→42
- 浅层需要 NMS,深层完全不需要 NMS
- 证明自注意力能自己抑制重复框
图6:解码器注意力可视化

图 6:展示每个预测对象的解码器注意力(来自 COCO 验证集的图像)。预测是使用 DETR-DC5 模型完成的。注意力得分以不同颜色表示不同的对象。解码器通常会关注对象的边缘部分,如腿部和头部。请以彩色方式查看效果最佳。
- 不同颜色对应不同预测物体
- 解读:解码器注意力非常"局部",只盯着物体的关键点:头、脚、边缘,精准提取边界。
图7:100 个查询的预测分布
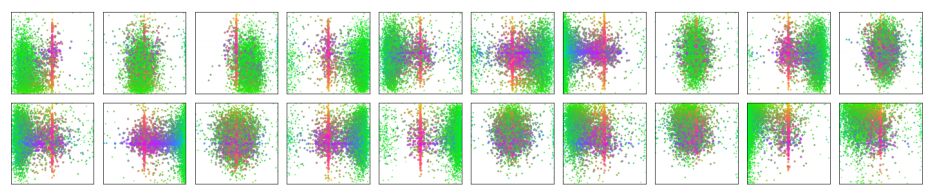
图 7:对 COCO 2017 验证集中的所有图像进行的所有框预测结果的可视化,展示了 DETR 解码器中总共 N = 100 个预测槽中的 20 个槽的预测结果。每个框预测都以其中心坐标在 1×1 的正方形中的形式表示,该坐标已根据每个图像的尺寸进行标准化。这些点采用颜色编码,绿色表示小框,红色表示大水平框,蓝色表示大垂直框。我们观察到每个槽都学会了专注于某些区域和特定的框尺寸,并且具有多种工作模式。我们注意到几乎所有的槽都有预测整个图像大框的模式,这在 COCO 数据集中很常见。
- 每个点是一个框的中心,颜色代表大小
- 解读:
- 100 个查询自动分工
- 有的专门测小物体,有的测大横框、大竖框
- 几乎所有 slot 都会预测大尺度框,适配 COCO 分布
图5:分布外泛化

图 5:罕见类别的分布外泛化。尽管训练集中没有一张图片中有超过 13 只长颈鹿,但 DETR 在泛化到相同类别的 24 只及以上实例时却毫无困难。
- 训练集最多 13 只长颈鹿,测试给 24 只
- 解读:DETR 没有为每个类别绑定查询,泛化极强,能处理从未见过的密集目标。
五、全景分割扩展
图8:全景分割头结构
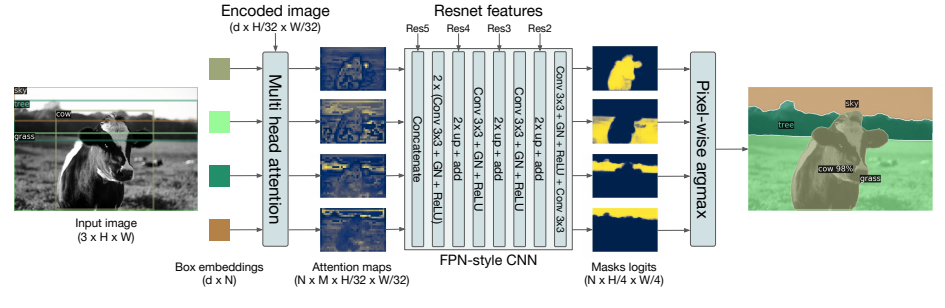
图 8:全景式头部的示意图。针对每个检测到的物体,都会同时生成一个二值掩码,然后通过像素级的"最大值"运算将这些掩码合并起来。
- 在解码器后加 mask head,用注意力生成掩码
- 逐像素 argmax 合并,掩码天然不重叠
图9:全景分割效果
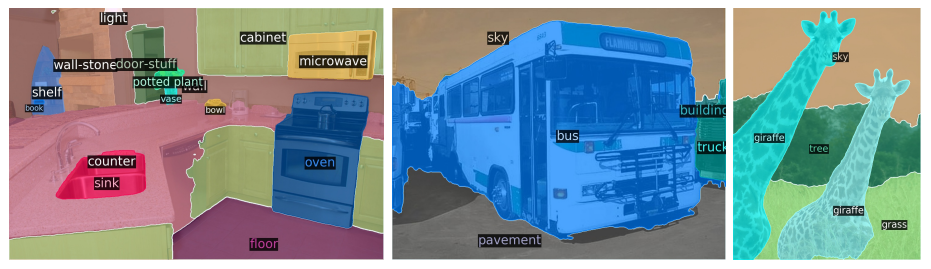
图 9:由 DETR-R101 生成的全景分割的定性结果。DETR 能以统一的方式为物体和物品生成对齐的掩码预测。
- 统一输出"可数物体(thing)"和"不可数区域(stuff)"
- 边界锐利,无重叠,效果干净
表5:全景分割结果对比(来源:原论文 Table 5)
| 模型 | PQ | PQth | PQst |
|---|---|---|---|
| PanopticFPN++ | 42.4 | 49.2 | 32.3 |
| DETR-R101 | 45.1 | 50.5 | 37.0 |
- 解读:DETR 在 stuff 类别大幅领先,因为全局注意力更适合大区域建模。
六、消融实验关键结论
表2:编码器层数影响
| 层数 | AP |
|---|---|
| 0 | 36.7 |
| 6 | 40.6 |
- 编码器很关键,全局推理提升明显
表3:位置编码影响
- 完全去掉空间编码:AP 掉 7.8
- 逐注意力层加入编码 > 只输一次
- 位置编码是 Transformer 看空间的"眼睛"
表4:损失函数影响
- 只 L1:AP 35.8(很差)
- 只 GIoU:AP 39.9
- L1+GIoU:AP 40.6
- 结论:必须联合使用
七、核心 PyTorch 代码(可直接运行)
python
import torch
import torch.nn as nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes=91, hidden_dim=256, nheads=8,
num_encoder_layers=6, num_decoder_layers=6):
super().__init__()
# CNN 主干
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
# Transformer
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers, num_decoder_layers)
# 预测头
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.bbox_embed = nn.Linear(hidden_dim, 4)
# 位置编码
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim//2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim//2))
def forward(self, x):
x = self.backbone(x)
h = self.conv(x)
H, W = h.shape[-2:]
# 构造2D位置编码
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H,1,1),
self.row_embed[:H].unsqueeze(1).repeat(1,W,1),
], dim=-1).flatten(0,1).unsqueeze(1)
# 送入Transformer
h = h.flatten(2).permute(2,0,1)
h = self.transformer(pos + h, self.query_pos.unsqueeze(1))
# 输出类别与框
return self.class_embed(h), self.bbox_embed(h).sigmoid()
# 测试
model = DETR()
x = torch.randn(1,3,800,1200)
cls, box = model(x)
print(cls.shape, box.shape)八、全文总结
核心创新
- 集合预测 + 匈牙利损失:彻底去掉锚框、NMS
- Transformer 全局建模:大物体精度大幅提升
- 结构极简:纯 CNN+Transformer,无自定义算子
- 极易扩展:一键扩展到全景分割,效果SOTA
优点
- 端到端、后处理少、设计优雅
- 大目标精度高
- 泛化强,能处理密集目标
- 全景分割统一框架
缺点
- 小物体精度弱
- 训练极长(500epoch)
- 收敛慢
DETR 真正开启了Transformer 目标检测时代,后续 Deformable DETR、YOLOv8-DETR 等都延续了这套范式。