二、聊天模型核心能力
1. 定义聊天模型
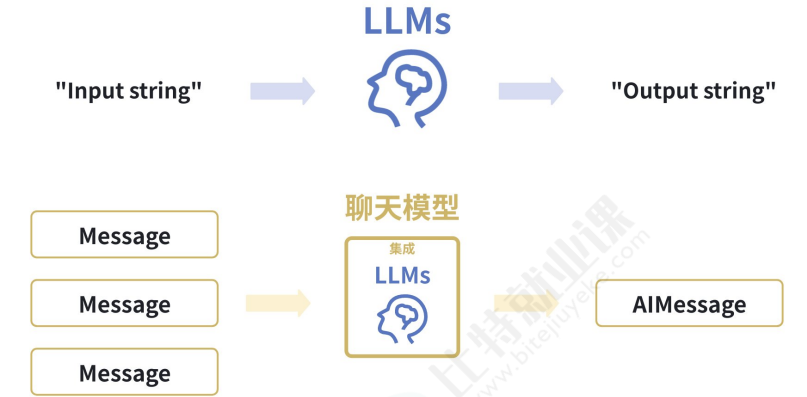
大语言模型 (LLM) 在各种与语言相关的任务(例如文本生成、翻译、摘要、问答等)中表现出色。 现代 LLM 通常通过聊天模型接口访问,该接口将消息列表作为输入,并返回消息作为输出,而不是使 用纯文本。
LLM 与 LangChain 中 聊天模型 的关系:
• 在 LangChain 的官方文档中,认为 LLM 大多数是纯文本补全模型。这些纯文本模型封装的 API 接 受一个字符串提示作为输入,并输出一个字符串补全结果(实际上 LLM 还包括多模态输入)。 OpenAI 的 GPT-5 就是作为 LLM 来实现的。
• LangChain 中的 聊天模型 通常由 LLM 提供支持,但经过专门调整以用于对话。关键在于,它们 不是接受单个字符串作为输入,而是接受聊天消息列表,并返回一条 AI 消息作为输出。
1.1 通过 API 定义聊天模型
1.1.1 方式1:ChatOpenAI
class langchain_openai.chat_models.base.ChatOpenAI 是 LangChain 为 OpenAI 的 聊天模型(如 gpt-5 , gpt-5-mini )提供的具体实现类。
其继承了 class langchain_openai.chat_models.base.BaseChatOpenAI ,且 BaseChatOpenAI 实现了标准的 Runnable 接口。
ChatOpenAI 常用初始化参数说明
| 参数名 | 参数描述 | 备注 |
|---|---|---|
| model | 要使用的 OpenAI 模型的名称(如 gpt-4, gpt-3.5-turbo等) |
核心参数,必须指定 |
| temperature | 采样温度,控制回答的随机性。值越高,回答越多样化、有创意;值越低,回答越稳定、保守。 | 常用范围是 0.0 ~ 1.0 |
| max_tokens | 要生成的最大令牌数(即回复的最大长度) | 用于控制生成长度 |
| timeout | 请求 API 的超时时间 | 网络控制参数 |
| max_retries | API 调用失败后的最大重试次数 | 网络控制参数 |
| openai_api_key / api_key | OpenAI API 密钥。用于身份验证。 | 如未传入,默认从环境变量 OPENAI_API_KEY中读取 |
| base_url | API 请求的基本 URL。 | 可用于配置代理或使用兼容 OpenAI 的第三方服务 |
| organization | OpenAI 组织 ID。 | 如未传入,默认从环境变量 OPENAI_ORG_ID中读取 |
代码里我们使用deepseek的,正好v4版本上线了
DeepSeek 常用参数表
| 参数名 | 作用 | 常用写法 / 推荐值 |
|---|---|---|
model |
指定模型 | deepseek-chat、deepseek-reasoner、deepseek-v4-flash、deepseek-v4-pro |
temperature |
控制随机性,越低越稳定,越高越发散 | 编程/数学:0;数据分析:1.0;聊天/翻译:1.3;创作:1.5。DeepSeek 默认是 1.0。 |
max_tokens |
限制最大输出 token 数 | 例如 1024、2048,不写就是让模型默认控制 |
timeout |
请求超时时间 | 例如 30,单位通常是秒 |
max_retries |
请求失败后的最大重试次数 | 例如 2、3 |
top_p |
另一种控制随机性的采样参数 | 默认 1,通常不要和 temperature 同时乱调 |
presence_penalty |
鼓励模型聊新内容 | 范围 -2 到 2,默认 0 |
frequency_penalty |
降低重复表达 | 范围 -2 到 2,默认 0 |
stream |
是否流式输出 | True / False |
stop |
遇到指定字符串停止生成 | 例如 ["\n\n"] |
response_format |
控制输出格式 | JSON 输出时用 {"type": "json_object"} |
tools |
函数调用 / 工具调用 | 用于让模型调用函数,DeepSeek 当前最多支持 128 个 functions。 |
api_key / DEEPSEEK_API_KEY |
API 密钥 | 推荐配置环境变量 DEEPSEEK_API_KEY |
python
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import Runnable, RunnableSequence
from langchain_deepseek import ChatDeepSeek
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
#1、定义模型
#api key默认从系统环境变量中读取()里的第二个参数也可以自己加上api_key=
model = ChatDeepSeek(
model="deepseek-v4-flash",
temperature=0.3,
max_tokens=200,
#.......
)
#2、定义消息
#用户消息在langchain里被定义成HumanMessage
#系统提示消息SystemMessage 通常作为第一条消息传入
messages=[
SystemMessage(content="补全一个故事"),
HumanMessage(content="一只猫正在___")
]
#3、定义输出解析
parse=StrOutputParser()
# print(parse.invoke(result))
#5、定义链
#注意链的顺序不能错,因为它是按照顺序来执行每一个组件的
chain = model | parse
#执行链条
print(chain.invoke(messages))
1.1.3 方式2:init_chat_model
介绍该方法须先了解一下关于 Runnable 接口中的 .invoke() 调用。该方法是将单个输 入转换为对应的输出。例如对于聊天模型来说,就是根据用户的问题输入,输出相应的答案。
invoke() 方法定义:
abstractmethod invoke(
input: Input,
config: RunnableConfig | None = None,
**kwargs: Any,
) → Output
• input :输入一个 Runnable 实例
• config (默认空):用于 Runnable 的配置。
返回值: • 返回一个 Runnable 实例
class langchain_core.runnables.config.RunnableConfig 常用参数说明
| 参数名 | 参数描述 |
|---|---|
| configurable | 通过 .configurable_fields()在此 Runnable 或子 Runnable 上配置的属性的运行时值。 |
| run_id | 针对此调用运行的跟踪器的唯一标识符。如果未提供,将生成新的 UUID。 |
| run_name | 此调用的跟踪器运行的名称。默认为类的名称。 |
| metadata | 此次调用和任何子调用的元数据。键是字符串,值是 JSON。 类型:dict[str, Any] |
上面的 ChatOpenAI 用于明确创建 OpenAI 聊天模型的实例。而 init_chat_model() 是一个工 厂函数,它可以初始化多种支持的聊天模型(如 OpenAI、Anthropic、FireworksAI 等),不仅仅是 OpenAI 的聊天模型。
init_chat_model() 函数定义
python
langchain.chat_models.base.init_chat_model(
model: str,
*,
model_provider: str | None = None,
configurable_fields: Literal[None] = None,
config_prefix: str | None = None,
**kwargs: Any,
) → BaseChatModel| 参数类别 | 参数名 | 参数描述 |
|---|---|---|
| init_chat_model() 常用参数 | model | 要使用的模型的名称 |
| model_provider | 模型提供方。支持的model_provider值及对应集成包: - openai→ langchain-openai - anthropic→ langchain-anthropic - google_genai→ langchain-google-genai - ollama→ langchain-ollama - deepseek→ langchain-deepseek ... 未指定时,将尝试从模型名称推断 |
|
| configurable_fields | 设置可配置的模型参数范围: - None:无可用配置字段 - 'any':所有字段可配置(如api_key、base_url等运行时修改) - Union[List[str], Tuple[str,...]]:仅指定字段可配置 |
|
| config_prefix | 配置前缀规则: - 非空字符串:通过config["configurable"]["{config_prefix}_{param}"]读取配置 - 空字符串:通过config["configurable"]["param"]读取配置 |
|
| 其他模型参数设置 | temperature | 采样温度:值越高回答越天马行空,值越低越保守靠谱 |
| max_tokens | 生成内容的最大令牌数 | |
| timeout | 请求超时时间 | |
| max_retries | 最大重试次数 | |
| openai_api_key / api_key | OpenAI API密钥;未传入时,自动读取环境变量OPENAI_API_KEY |
|
| base_url | API请求的基础URL | |
| ...... | 其他扩展参数(如更多模型专属配置项) |
python
from langchain.chat_models import init_chat_model
from langchain_core.messages import SystemMessage, HumanMessage
#1、基本用法
#LangChain封装了更上层的方法,让我们初始化模型
deepseek_model = init_chat_model(
model="deepseek-v4-flash",
model_provider="deepseek",
temperature=0.3
)
result1 = deepseek_model.invoke("你是谁")
print(f"deepseek-v4-flash:{result1.content}")
#2、定义可配置的模型(模型模拟器)
config_model=init_chat_model(temperature=0.3)
messages=[
SystemMessage(content="补全一个故事,一百字以内:"),
HumanMessage(content="一只猫正在__")
]
config={
"configurable":{
"model":"deepseek-v4-flash",
"model_provider":"deepseek"
}
}
#.invoke()的config参数才正真意义上定义了大模型
result2=config_model.invoke(input=messages,config=config)
print(f"config_model:{result2.content}")
#3、可配置的模型(默认参数)
model=init_chat_model(
model="deepseek-v4-flash",
model_provider="deepseek",
temperature=0.3,
max_tokens=1024
)
messages=[
SystemMessage(content="补全故事,100子以内"),
HumanMessage(content="一只狗正在__")
]
resullt=model.invoke(
input=messages,
config={
"configurable":{}
}
)1.2 通过本地部署的 LLM 定义聊天模型
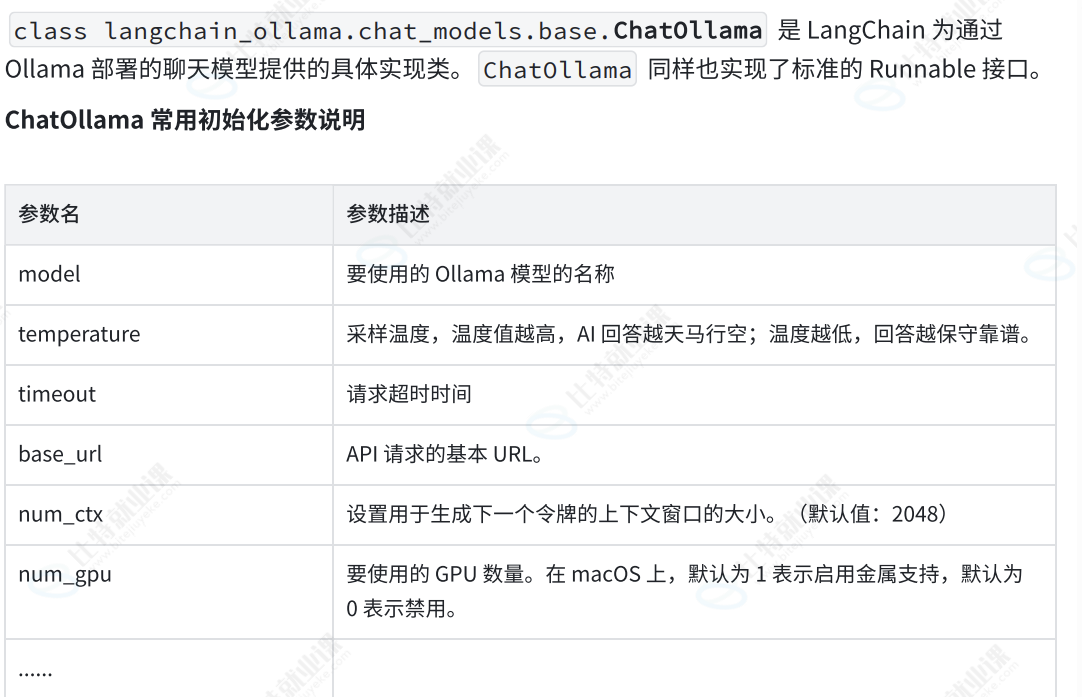
1.2.1 ChatOllama
若想使用 ChatOllama,需要先安装 Ollama 包:
pip install -U langchain_ollama
2. 聊天模型--调用工具
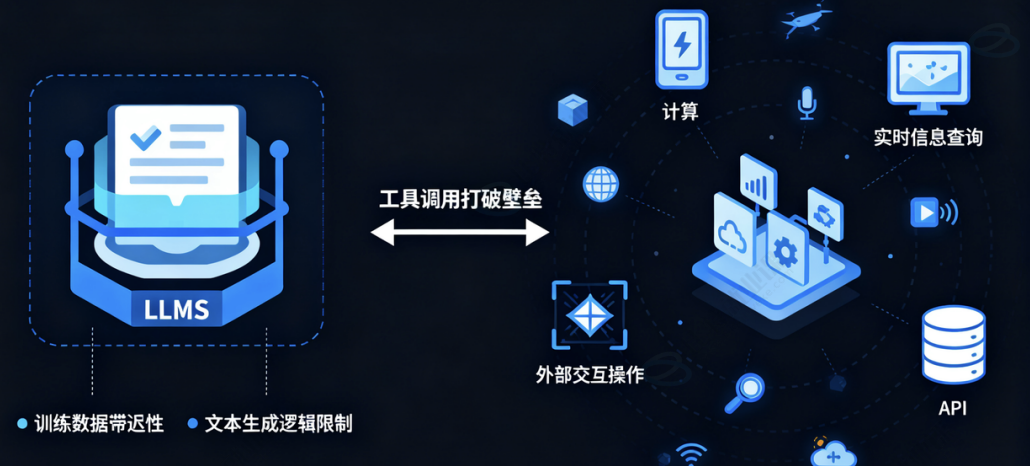
工具调用根本作用是让大语言模型(LLM)具备与外部世界交互的能力。
LLM 本身是一个封闭的知识系统,其能力受限于其训练数据(存在滞后性)和内在的文本生成逻辑。 它无法执行直接计算、查询实时信息、操作数据库或调用任何外部 API。工具调用打破了这层壁垒,其 作用具体体现在:
-
扩展能力边界:模型可以借助工具完成它自身无法完成的任务,如执行数学计算、搜索网络、查询 数据库等。
-
保证信息实时性:通过调用搜索工具或数据库查询工具,LLM 可以获取最新的、训练数据中不存在 的信息,避免回答过时或"一本正经地胡说八道"。
-
处理复杂任务:将一个复杂的用户请求(如"分析我上个月的消费趋势")分解成多个步骤,并依 次调用不同的工具(如"从数据库获取数据" -> "用 Python 进行数据分析" -> "生成图表") 来协同完成。协调这件事这更体现在 Agent 智能体上。
-
连接现有系统:可以将企业内部已有的系统、API 和数据库封装成工具,让 LLM 成为一个用自然语 言驱动的统一接口,极大地提升了自动化和集成能力。
在 LangChain 中,聊天模型提供了额外的功能:工具调用。它能使 LLM 与外部服务、API 和数据库进 行交互。工具调用还可用于从非结构化数据中提取结构化信息并执行各种其他任务。
当我们希望获取当前天气情况,由于 LLM 无法获取实时信息,此时我们就可以借助工具,通 过外部服务进行搜索完成查询:
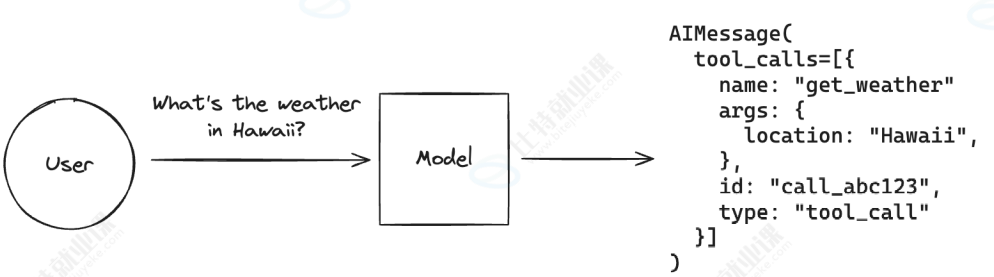
当我们希望获取数据库表中的数据时
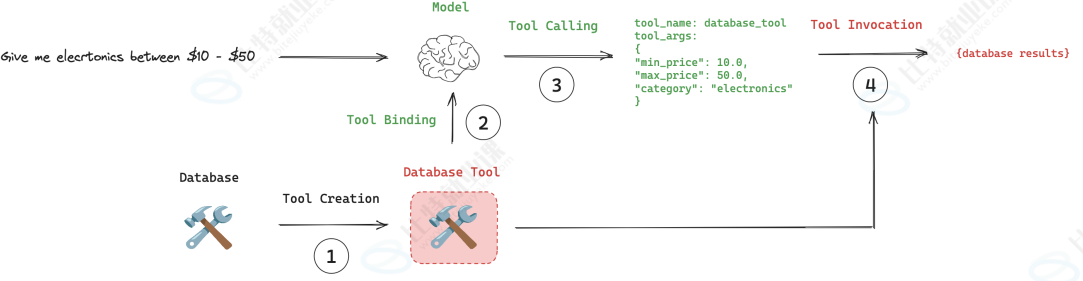
2.1 创建工具
关于工具schema
对于工具schema,它将从函数名 、类型提示 和文档字符串 中获取相关属性,以此 来声明一个工具,包括其名称、描述、输入参数、输出类型等等。这里需要说明的是,若是简单定义 工具,,工具 schema 需要解析 Google 风格的文档字符串去获取【参数描述】
schema 就是数据的"标准答案格式"。LangChain 里的 tool schema,就是告诉大模型这个工具叫什么、干什么、需要哪些参数、参数分别是什么类型。
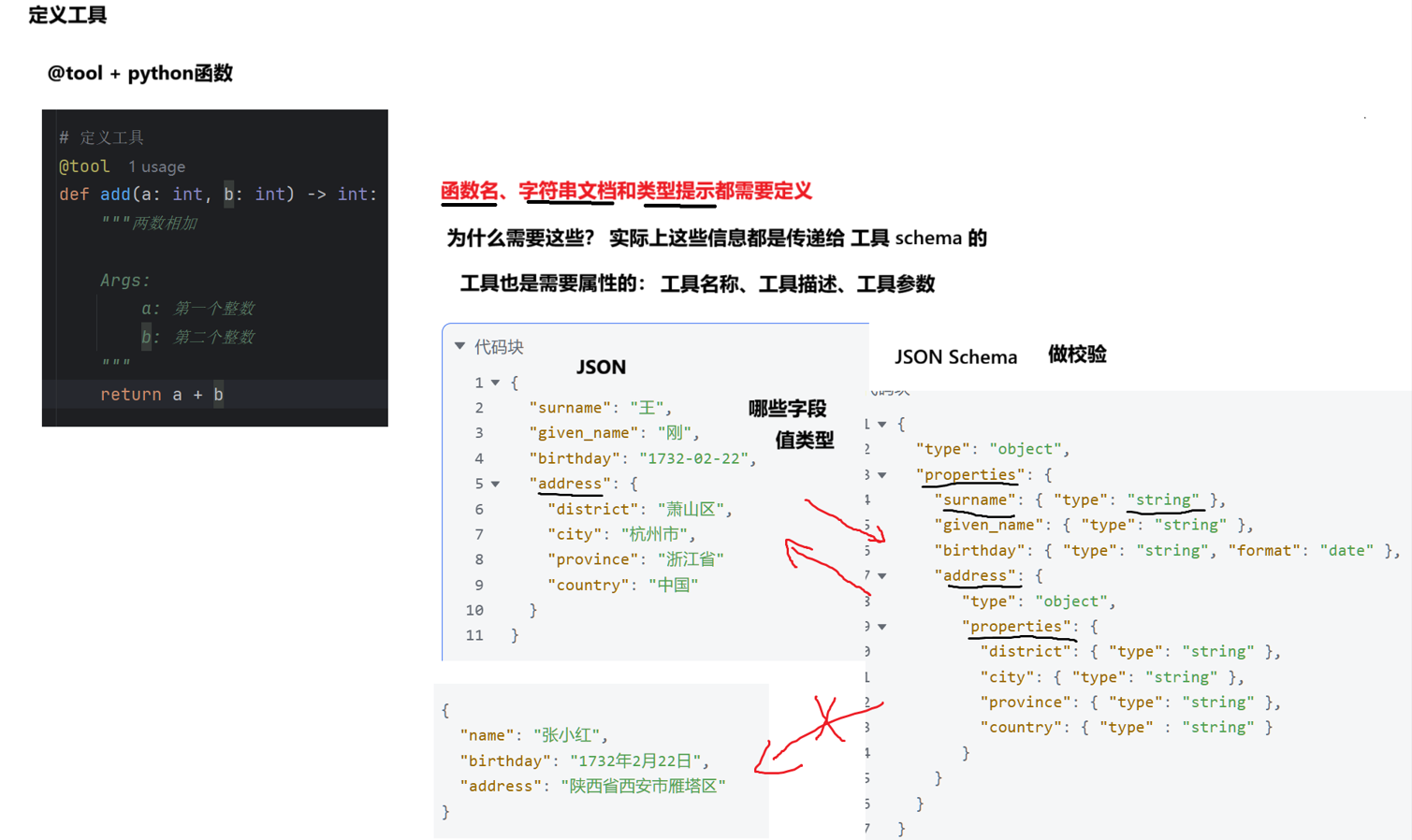
2.1.1 使用 @tool 装饰器创建工具
有三种方式创建工具
三种方式最终都会被 LangChain 封装成
BaseTool,区别只在于 参数描述(Schema)是如何生成的。
无论哪种写法,最终都会得到:
| 属性 | 作用 |
|---|---|
name |
工具名称(给 LLM 用) |
description |
工具用途说明 |
args_schema |
参数 JSON Schema |
invoke() |
执行工具 |
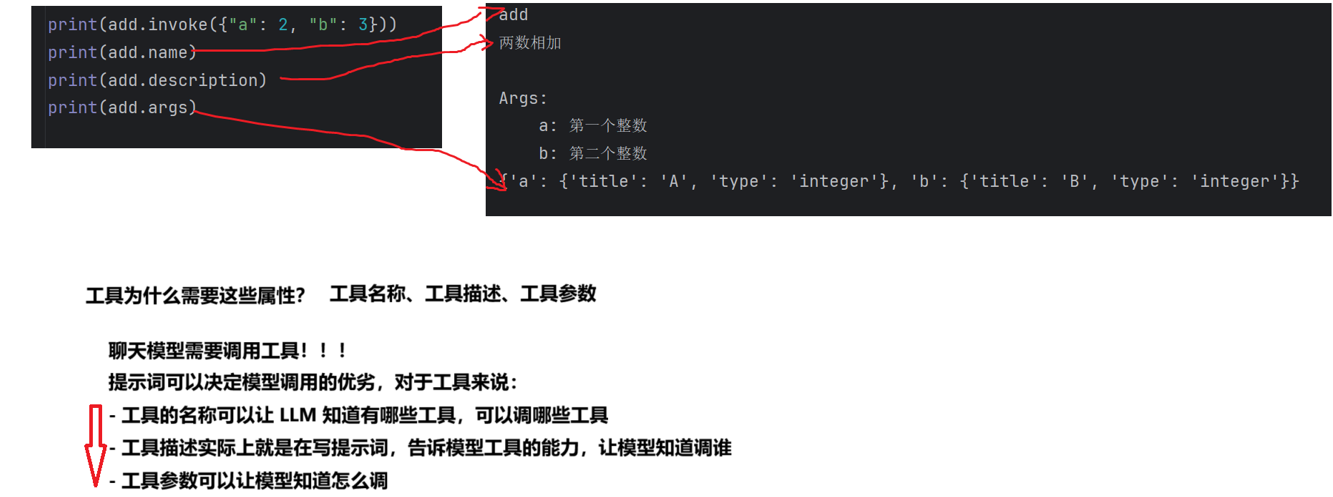
在 LangChain 中,实现了一个 @tool 装饰器来创建工具, @tool 装饰器是自定义工具的最简单方 法。
工作原理
LangChain 会:
-
用函数名 →
name -
用 docstring 第一行 →
description -
解析
Args:段落 → 参数描述 -
用 Python 类型注解 → 参数类型
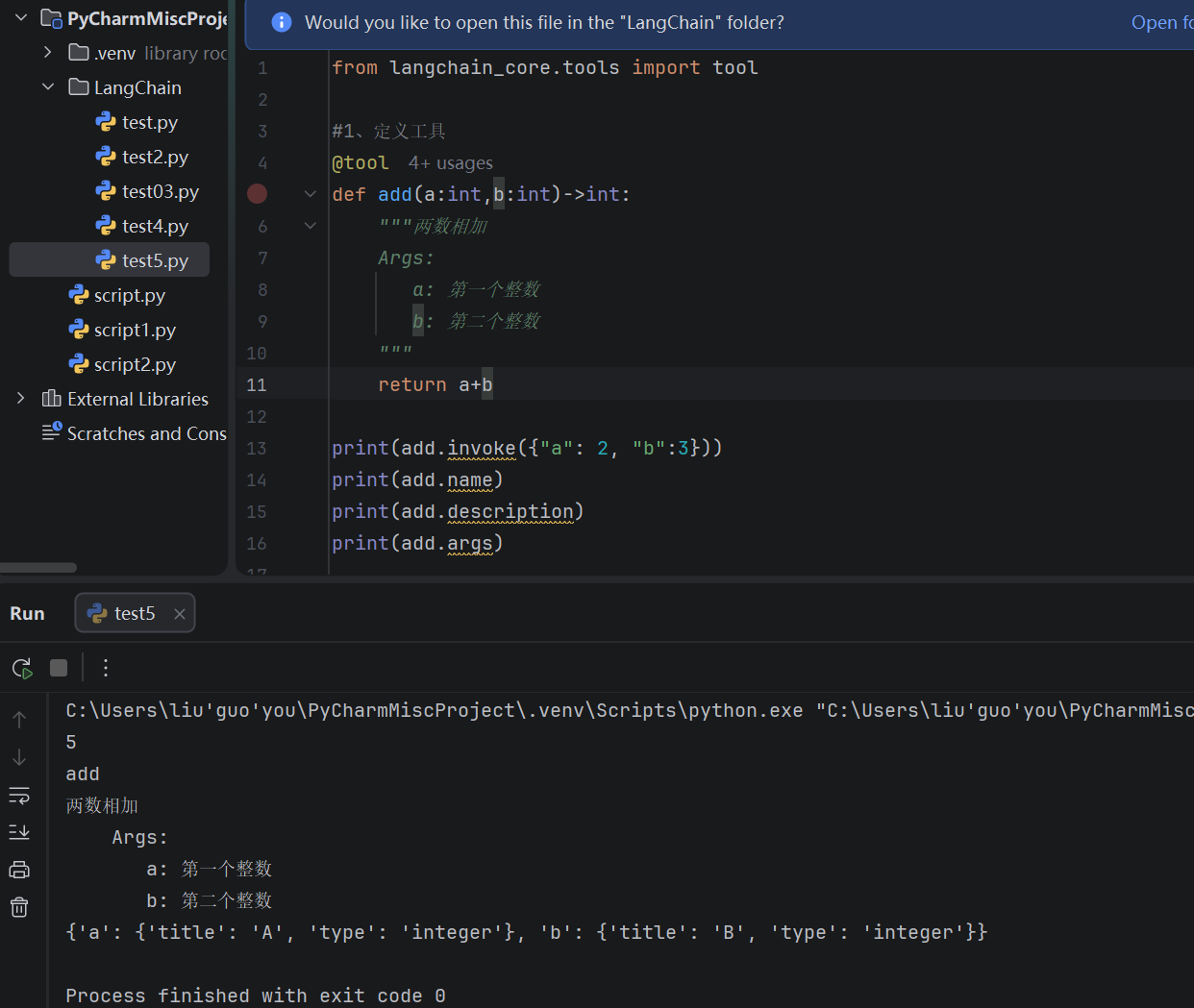
2.1.1.1 模式1:依赖 Pydantic 类
工作原理
-
完全由 Pydantic 接管参数定义
-
LangChain 直接读取:
-
model_json_schema() -
Field(description=...)
-
python
#方法二
class AddInput(BaseModel):
"""两数相加"""
a:int=Field(...,description="第一个整数")
b:int=Field(...,description="第二个整数")
@tool(args_schema=AddInput)
def add(a:int,b:int)->int:
return a+b
print(add.invoke({"a": 2, "b":3}))
print(add.name)
print(add.description)
print(add.args)2.1.1.2 模式2:依赖 Annotated
在 LangChain 中,可以依赖 Annotated 和文档字符串传递给工具 Schema 。
底层机制
-
LangChain 使用 类型提取器
-
自动生成等价 Pydantic Schema
-
不需要你手写
BaseModel
python
#方法三
@tool
def add(
a : Annotated[int, ..., "第一个整数"],
b : Annotated[int, ..., "第二个整数"],
)->int:
"""两数相加
Args:
a:第一个整数
b:第二个整数
"""
return a + b
print(add.invoke({"a": 2, "b":3}))
print(add.name)
print(add.description)
print(add.args)2.1.2 使用 StructuredTool 类提供的函数创建工具
class langchain_core.tools.structured.StructuredTool 类用来初始化工具,其中 from_function 类方法通过给定的函数来创建并返回一个工具。 from_function 类方法定义如 下:
python
classmethod from_function(
func: Callable | None = None,
coroutine: Callable[[...], Awaitable[Any]] | None = None,
name: str | None = None,
description: str | None = None,
return_direct: bool = False,
args_schema: type[BaseModel] | dict[str, Any] | None = None,
infer_schema: bool = True,
*,
response_format: Literal['content', 'content_and_artifact'] = 'content',
parse_docstring: bool = False,
error_on_invalid_docstring: bool = False,
**kwargs: Any,
) → StructuredTool关键参数说明:
• func:要设置的工具函数
• coroutine:协程函数,要设置的异步工具函数
• name:工具名称。默认为函数名称。
• description:工具描述。默认为函数文档字符串。
• args_schema:工具输入参数的schema。默认为 None。
• response_format:工具响应格式。默认为"content"。 ◦ 如果配置为 "content" ,则工具的输出为 ToolMessage 的 content 属性。
▪ 对于 HumanMessage 、 AIMessage 已经见过,分别表示 用户消息 和 AI消息响应 , 对于 ToolMessage ,它表示对应工具角色所发出的消息。 ◦ 如果配置为 "content_and_artifact" ,则输出应是与 ToolMessage 的 content 属性 与 artifact 属性相对应的二元组。(用法见下面的 示例3 )
• 该类方法全部参数及含义见这里from_function | langchain_core | LangChain Reference。
2.1.2.1 示例1:常规用法
对于用该类方法创建的工具,同样函数名、类型提示和文档字符串也都是传递给工具 Schema 的一部 分,不可缺失。
python
from langchain_core.tools import StructuredTool
#方式一
def add(a:int,b:int)->int:
"""两数相加"""
return a+b
add_tool=StructuredTool.from_function(add)
print(add_tool.invoke({"a": 1, "b": 2}))
print(add_tool.name)
print(add_tool.description)
print(add_tool.args)2.1.2.2 示例2:加入配置,依赖 Pydantic 类
同样的,让工具函数不提供描述、文档字符串等需要传递给工具 Schema 的内容,如下所示:
此时可以: 1. 使用 args_schema 参数,依赖 Pydantic 类定义并提供工具输入参数的 schema 属性。
- 使用 description 参数,替代文档字符串中对于工具描述的 schema 属性。
python
#方法二
class AddInput(BaseModel):
a:int=Field(description="第一个整数")
b:int=Field(description="第二个整数")
def add(a:int,b:int)->int:
return a+b
add_tool=StructuredTool.from_function(
func=add,
name="ADD", #工具名
description="两数相加",#工具描述
args_schema=AddInput,#工具参数
)
print(add_tool.invoke({"a": 1, "b": 2}))
print(add_tool.name)
print(add_tool.description)
print(add_tool.args)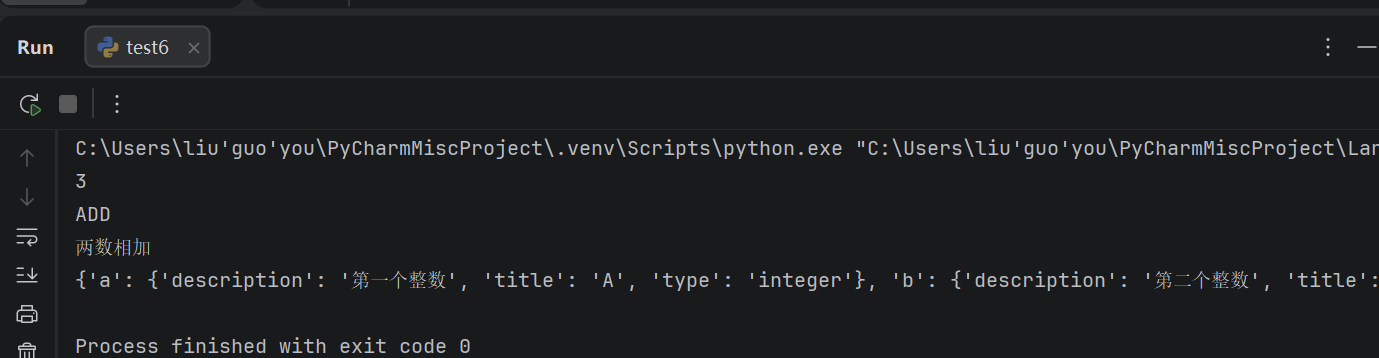
2.1.2.3 示例3:加入 response_format 配置
如果希望我们的工具区分消息内容(content)和其他工件(artifact),让大模型读取 content , 而一些用来构造 content 的原始数据保存下来,若后续有一些记录、分析的步骤,就可以派上用场 了,这就是 artifact 。 artifact 通常需要使用字典 Dict 或列表 List 保存。我们今后做日志记录、分析,或自定义后续的处理都很方便。
接下来举个例子再来理解下。例如我们定义了一个搜索天气的 tool ,若使用搜索引擎工具询问 "今 天的天气如何?" 时:
• content 可能是: "根据最新搜索结果,今天北京晴,气温在25°C到32°C之间。建议穿短袖衣 物。"
• artifact 可能是某搜索引擎 API 返回的完整 JSON 响应,其中包含多个搜索结果条目、每个条 目的标题、链接、摘要、排名等元数据。
python
#方法三
class AddInput(BaseModel):
a:int=Field(description="第一个整数")
b:int=Field(description="第二个整数")
def add(a:int,b:int)->Tuple[str,List[int]]:
nums=[a,b]
content=f"{nums}相加的结果是{a+b}"
return nums,content
add_tool=StructuredTool.from_function(
func=add,
name="ADD", #工具名
description="两数相加",#工具描述
args_schema=AddInput,#工具参数
response_format="content_and_artifact"
)
#模拟大模型调用的姿势
print(add_tool.invoke(
{"name": "ADD",
"args": {"a": 1, "b": 2},
"type": "tool_call", # 必填
"id": "111", # 必填
}))
小结一下,由于 LLM 大多理解文本,所以工具的主要输出 content 必须是结构良好、简洁的文本, 以便模型能够轻松理解和基于它进行推理、生成下一步的指令。
在链(Chain)中,工具调用之后的其他组件或函数,可能需要工具的原始且结构化数据(即 artifact )来执行特定操作。这些数据可能是庞大的、且非文本的。这些数据不适合直接塞给模 型。因此, artifact 其实是为了给链中后续的组件或函数使用的,不被大模型所直接使用!!