GA-Transformer模型回归+SHAP分析+新数据预测+多输出!深度学习可解释分析(附MATLAB代码)
1. 研究背景
Transformer 模型在自然语言处理等领域表现优异,但其在结构化数据回归预测中的超参数(如自注意力头数)往往靠经验设定,难以保证最优性能。为此,引入遗传算法(GA)自动搜索最优头数,提升模型的预测精度与泛化能力。代码同时对比优化前后的效果,验证 GA 的有效性。
2. 主要功能
- 数据预处理:读取 Excel 数据,进行归一化,按比例划分训练集和测试集,并转换为序列格式。
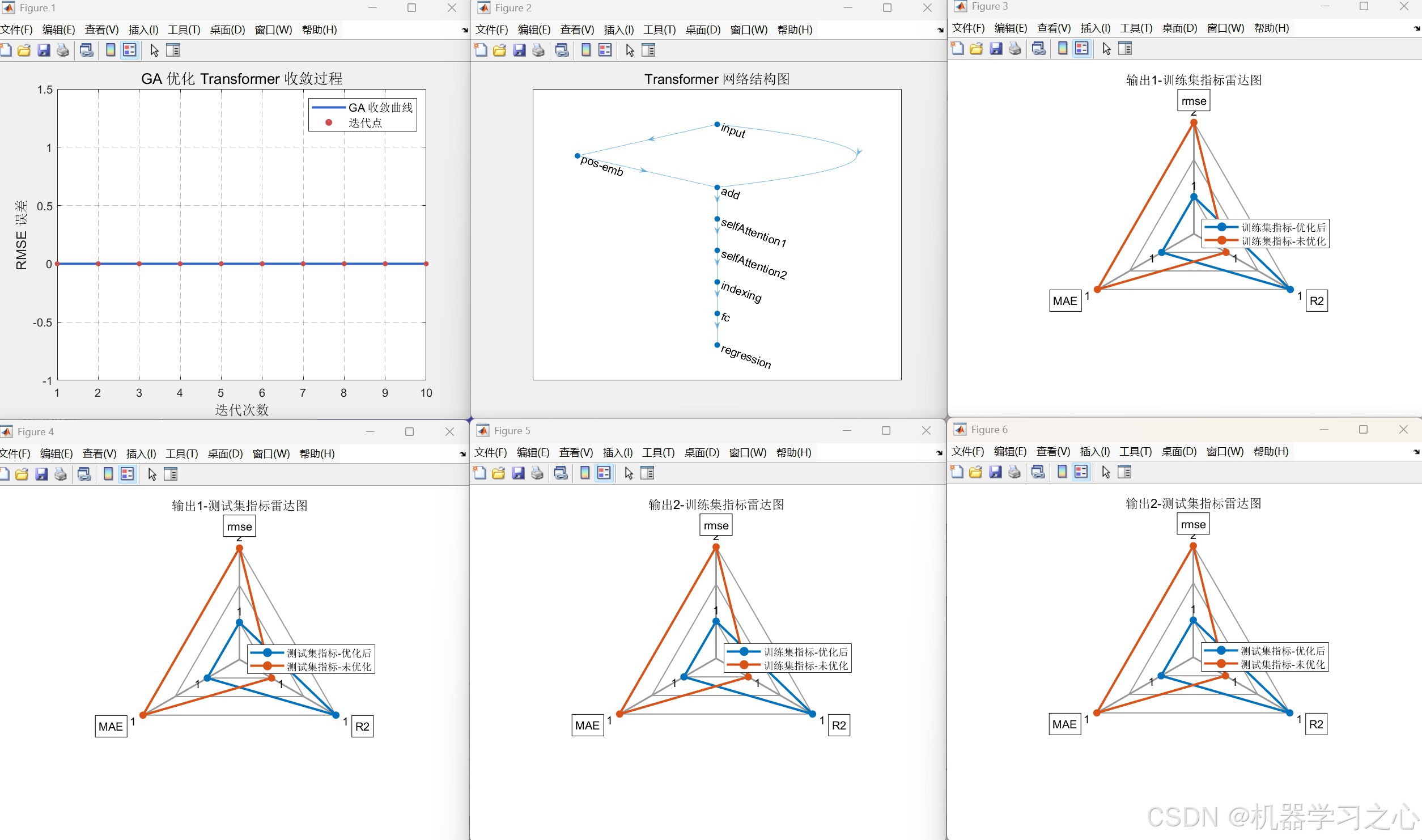
- GA 优化 Transformer:以注意力头数为决策变量,以测试集 RMSE 为目标函数,利用 GA 寻找使误差最小的头数。
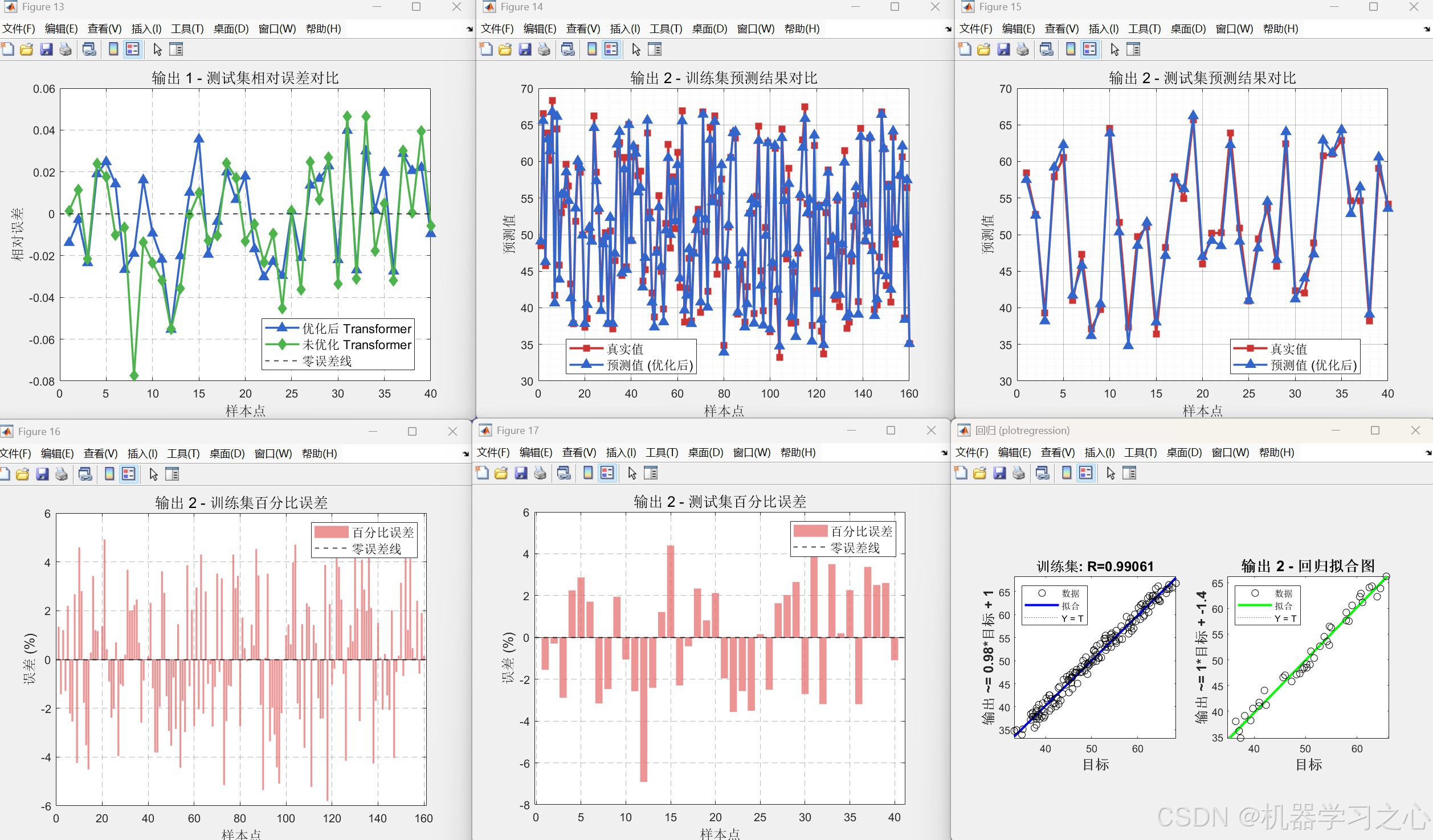
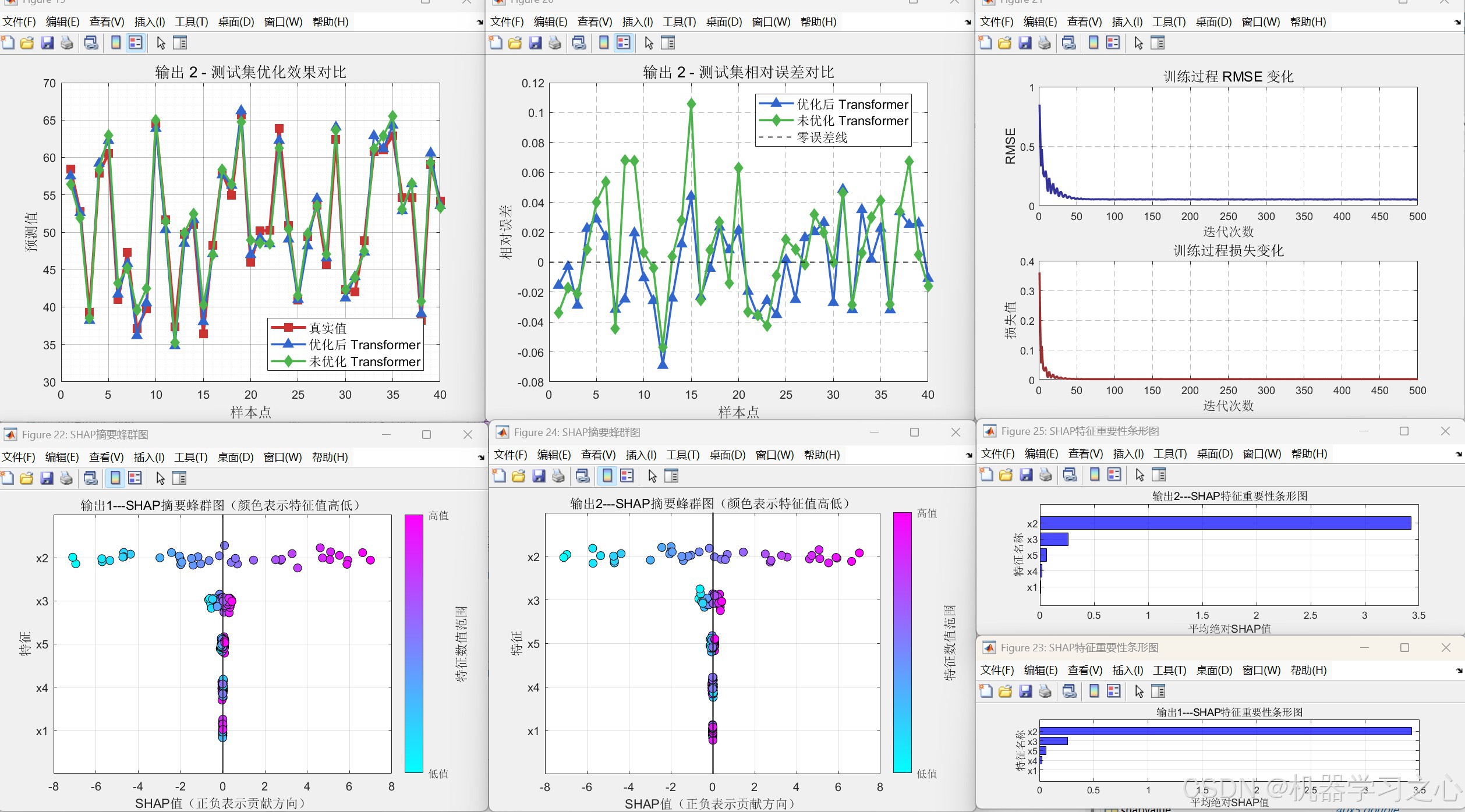
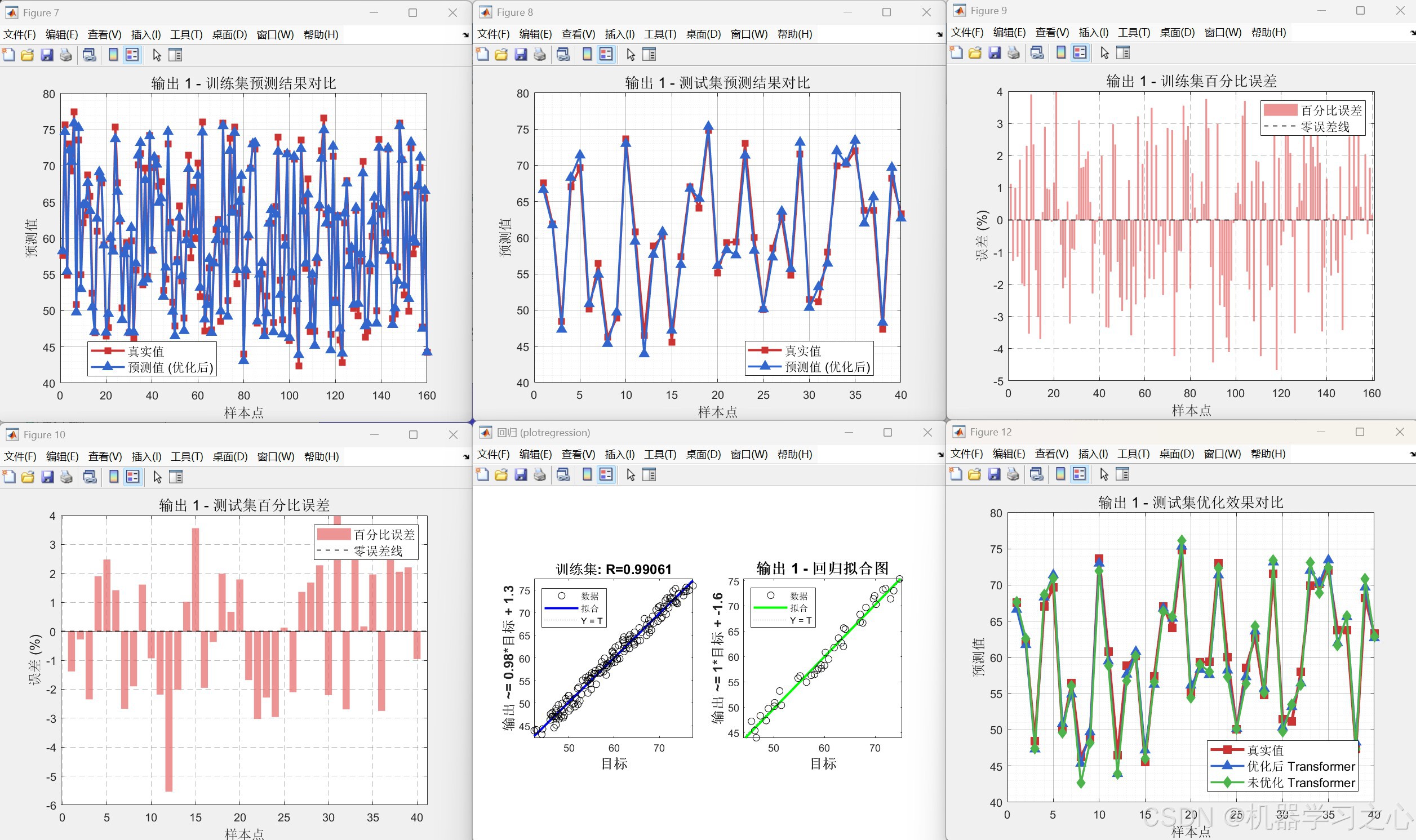
- 模型训练与评估:使用优化后的头数重新训练 Transformer,并与未优化模型(固定头数=1)进行对比,输出 RMSE、R²、MAE 等指标,以及预测曲线、误差图、雷达图等可视化结果。
- 特征重要性分析:基于 Shapley 值的 SHAP 分析,量化各输入特征对模型输出的贡献。
- 新数据预测:支持载入新样本,自动归一化、预测并反归一化输出。
3. 算法步骤
- 加载数据与归一化 :读取
回归数据.xlsx,将输入特征 X(5 维)和输出 Y(2 维)分别归一化到 0,1。 - 划分数据集 :按 80% 比例随机或顺序拆分训练集和测试集,并转为
cell格式序列。 - 遗传算法优化 :
- 初始化种群(使用混沌映射增加多样性),编码注意力头数(整数,区间 2,20)。
- 适应度函数
fit.m:用当前头数构建 Transformer,训练 200 轮后计算测试集 RMSE 并返回。 - 执行选择、交叉、变异操作,迭代 10 代,输出最优头数
bestheads及收敛曲线。
- 构建优化模型 :用
bestheads构建与fit.m中类似但训练轮数更多(500 轮)的 Transformer。 - 训练与预测 :训练优化模型,对训练集、测试集进行预测并反归一化,同时调用
yuantrans.m得到未优化(heads=1)的对比结果。 - 性能评估与可视化:计算 RMSE、R²、MAE,绘制预测对比图、百分比误差柱状图、回归拟合图、雷达图等。
- SHAP 分析 :通过
shapley_function.m计算每个测试样本的 Shapley 值,生成蜂群图和条形图,揭示特征重要性。 - 新数据预测 :调用
newpre.m读取新的多输入.xlsx,进行归一化、预测、反归一化并保存结果。
4. 技术路线
数据层面 :多维输入 → 归一化 → 序列化 → 训练/测试划分
优化层面 :GA 种群初始化(混沌映射) → 适应度评价(Transformer 训练+测试) → 选择/交叉/变异 → 迭代寻优
模型层面 :序列输入 → 位置编码 → 加法融合 → 两个自注意力层(一个因果掩码,一个无掩码)→ 提取最后一个时间步 → 全连接 → 回归输出
分析层面:指标对比(优化 vs 未优化)→ 可视化(预测曲线、雷达图、误差分布)→ SHAP 特征重要性解释
5. 公式原理
- 归一化 :
mapminmax将数据线性映射到 0,1。 - 遗传算法 :
- 适应度函数:
fitness = sqrt(mean(sum(re - y_test))^2),本质是 RMSE(但注意公式有误,应为sqrt(mean((re - y_test).^2, 'all')))。 - 轮盘赌选择、实数交叉和变异(非均匀变异),保证子代在边界内。
- 适应度函数:
- Transformer 核心 :
- 自注意力机制:Attention(Q,K,V)=softmax(QKTdk+mask)V\text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + \text{mask}\right)VAttention(Q,K,V)=softmax(dk QKT+mask)V,其中因果掩码屏蔽未来信息,标准自注意力无掩码。
- 位置编码:
positionEmbeddingLayer使用可学习的位置向量叠加在输入序列上。 - 对于回归任务,最终输出层为全连接 + 回归层(MSE 损失)。
- 评价指标 :
- RMSE:1n∑i=1n(yi−y^i)2\sqrt{\frac{1}{n}\sum_{i=1}^n (y_i - \hat{y}_i)^2}n1∑i=1n(yi−y^i)2
- R²:1−∑(yi−y^i)2∑(yi−yˉ)21 - \frac{\sum (y_i - \hat{y}_i)^2}{\sum (y_i - \bar{y})^2}1−∑(yi−yˉ)2∑(yi−y^i)2
- MAE:1n∑∣yi−y^i∣\frac{1}{n}\sum |y_i - \hat{y}_i|n1∑∣yi−y^i∣
- SHAP 值:基于 Shapley 值的精确计算,枚举所有特征子集,计算边际贡献的加权平均。
6. 参数设定
| 参数 | 值 | 说明 |
|---|---|---|
种群规模 pop |
10 | 遗传算法个体数 |
最大迭代 Max_iter |
10 | GA 进化代数 |
| 注意力头数范围 | 2, 20 | 整数搜索空间 |
交叉概率 pc |
0.8 | GA 交叉率 |
变异概率 pm |
0.05 | GA 变异率 |
混沌映射类型 label |
1 | Tent 映射初始化种群 |
| 优化阶段训练轮数 | 200 | 适应度函数中的 MaxEpochs |
| 最终模型训练轮数 | 500 | 优化后网络的训练轮数 |
| 初始学习率 | 0.01 | Adam 优化器学习率 |
| 学习率衰减 | piecewise,每 200 轮(优化)/ 150 轮(GA 内)乘 0.1 | |
| 序列最大长度 | 128 | maxPosition |
| 通道数 | 头数 × 4 | |
| 数据集划分 | 训练 80%,测试 20% |
7. 运行环境
- MATLAB2024b
- 数据文件:
回归数据.xlsx、新的多输入.xlsx必须存在。
8. 应用场景
适用于多输入多输出回归预测任务,特别是:
- 工业过程建模:如化工、电力负荷、污染物浓度预测;
- 金融经济:多变量时间序列预测;
- 环境科学:水质、空气质量多指标预测;
- 工程优化:传感器信号映射、参数反演等。
因其同时具备特征重要性分析功能,也适合需要模型可解释性的研究场景。