redis环境配置
Redis是一种键值型的NoSql数据库,这里有两个关键字:
- 键值型
- NoSql
其中键值型,是指Redis中存储的数据都是以key、value对的形式存储,而value的形式多种多样,可以是字符串、数值、甚至json:
而NoSql则是相对于传统关系型数据库而言,有很大差异的一种数据库。
上面这种拆分了存的方式有点松散
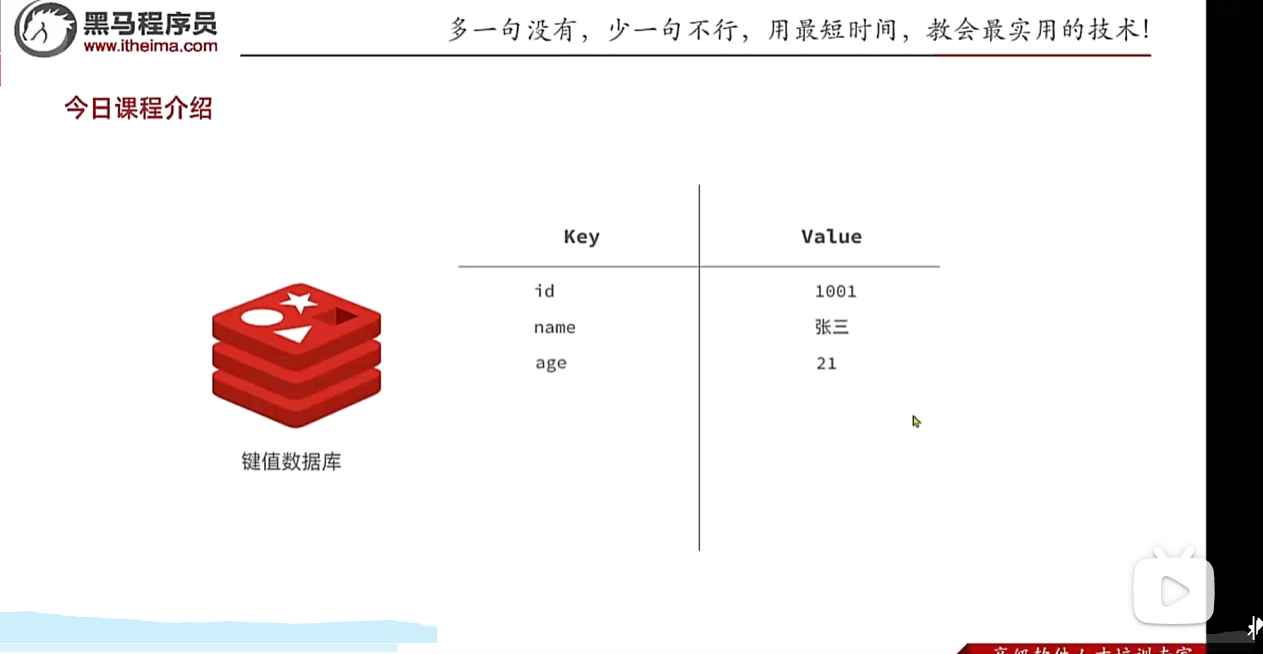
用这种方式就更加紧凑,这种方式也是key value 形式只不过value变成了更长的josn字符串
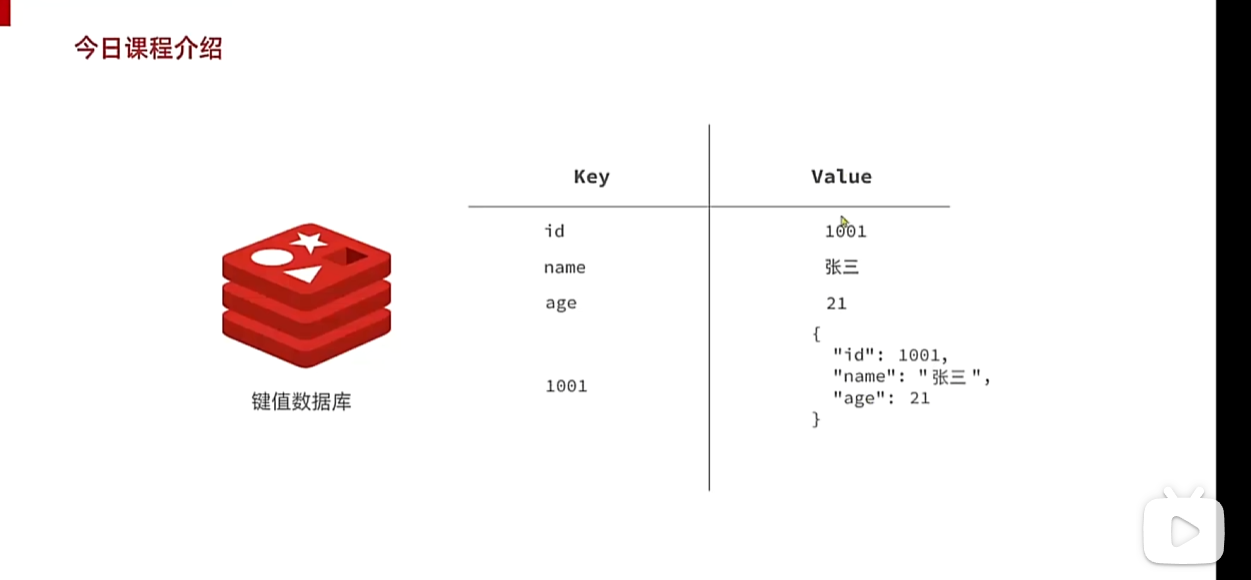
我们先来认识以下什么叫nosql

认识NoSQL
NoSql 可以翻译做Not Only Sql(不仅仅是SQL),或者是No Sql(非Sql的)数据库。是相对于传统关系型数据库而言,有很大差异的一种特殊的数据库,因此也称之为非关系型数据库。
1.1.1.结构化与非结构化
传统关系型数据库是结构化数据,每一张表都有严格的约束信息:字段名、字段数据类型、字段约束等等信息,插入的数据必须遵守这些约束:
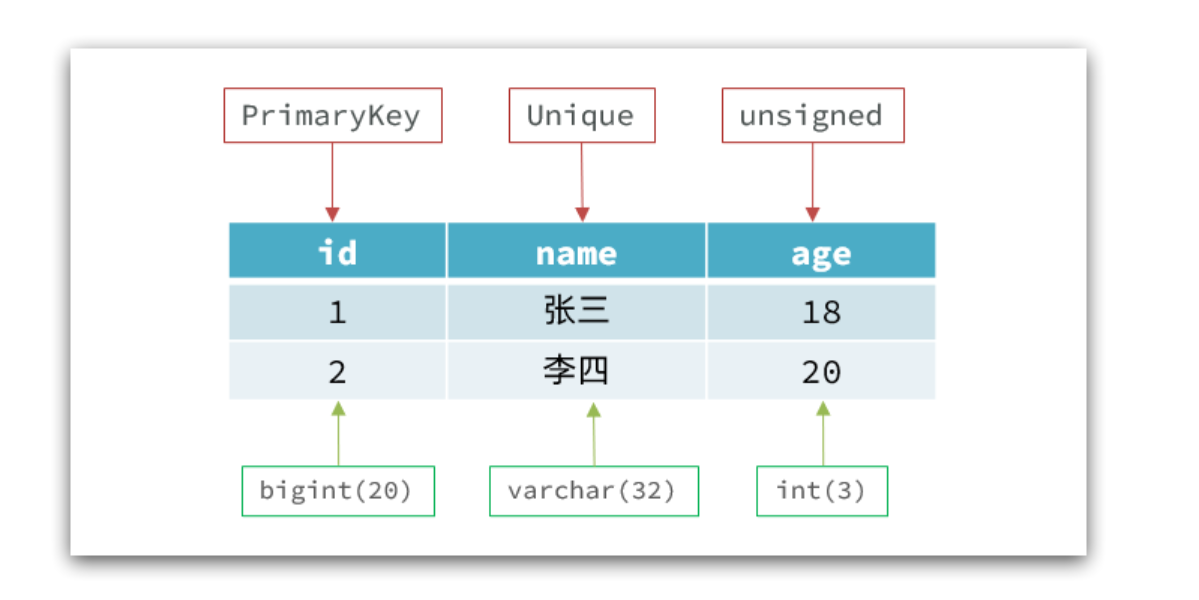
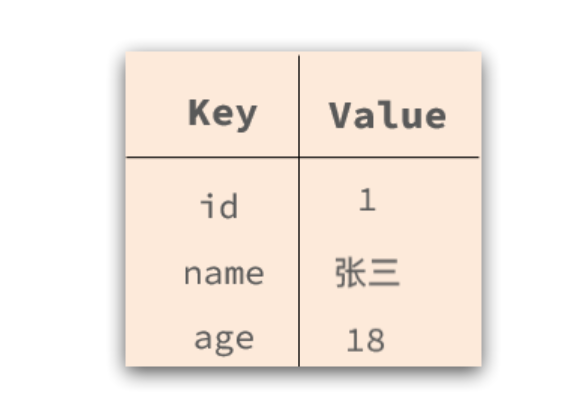
而NoSql则对数据库格式没有严格约束,往往形式松散,自由。
可以是键值型:
也可以是文档型:

甚至可以是图格式:
1.1.2.关联和非关联
传统数据库的表与表之间往往存在关联,例如外键:
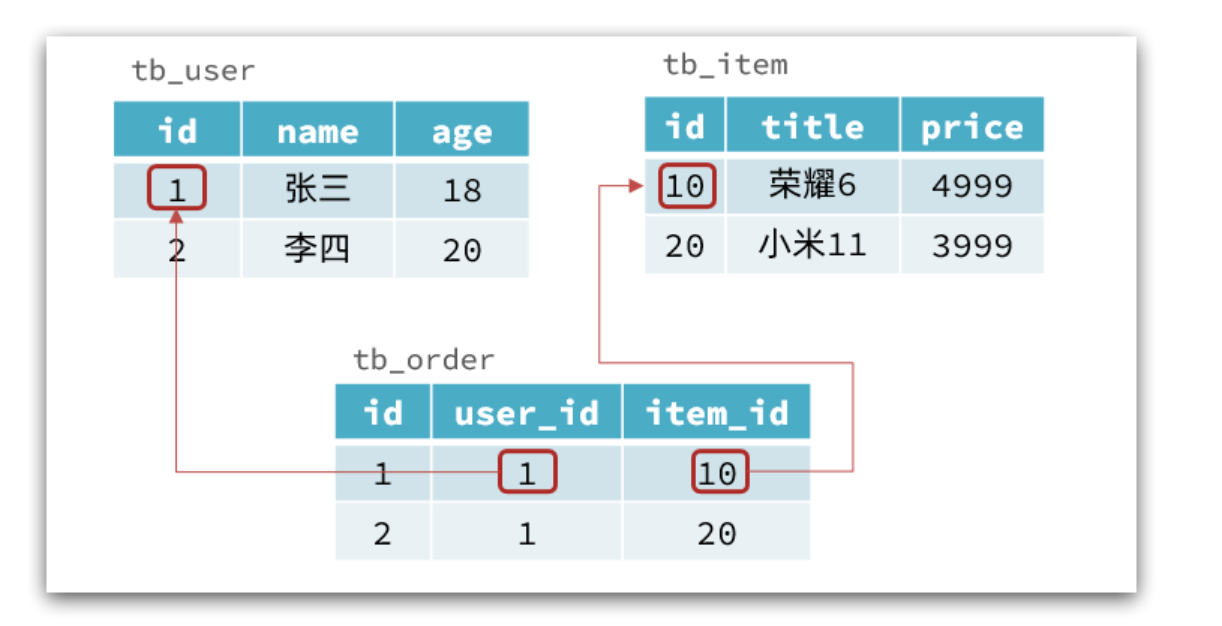
而非关系型数据库不存在关联关系,要维护关系要么靠代码中的业务逻辑,要么靠数据之间的耦合:
{
id: 1,
name: "张三",
orders: [
{
id: 1,
item: {
id: 10, title: "荣耀6", price: 4999
}
},
{
id: 2,
item: {
id: 20, title: "小米11", price: 3999
}
}
]
}此处要维护"张三"的订单与商品"荣耀"和"小米11"的关系,不得不冗余的将这两个商品保存在张三的订单文档中,不够优雅。还是建议用业务来维护关联关系。
1.1.3.查询方式
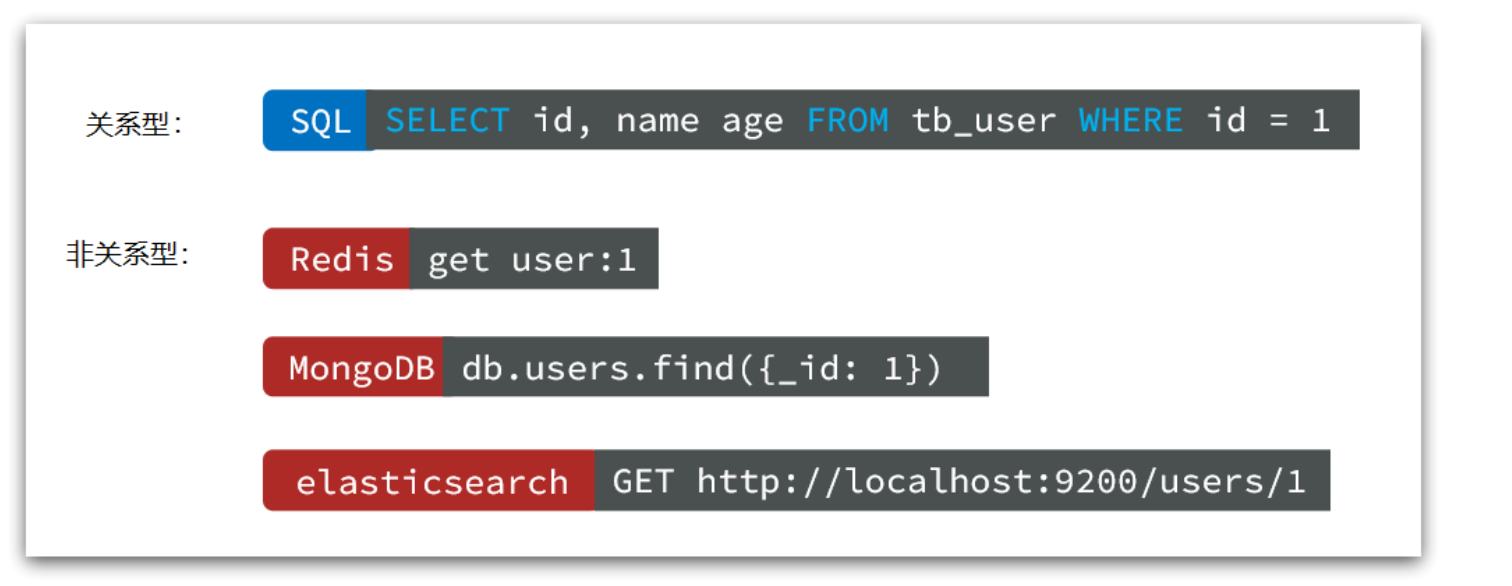
传统关系型数据库会基于Sql语句做查询,语法有统一标准;
而不同的非关系数据库查询语法差异极大,五花八门各种各样。
1.1.4.事务
传统关系型数据库能满足事务ACID的原则。
非关系型数据库往往不支持事务,或者不能严格保证ACID的特性,只能实现基本的一致性。
1.1.5.总结
除了上述四点以外,在存储方式、扩展性、查询性能上关系型与非关系型也都有着显著差异,总结如下:
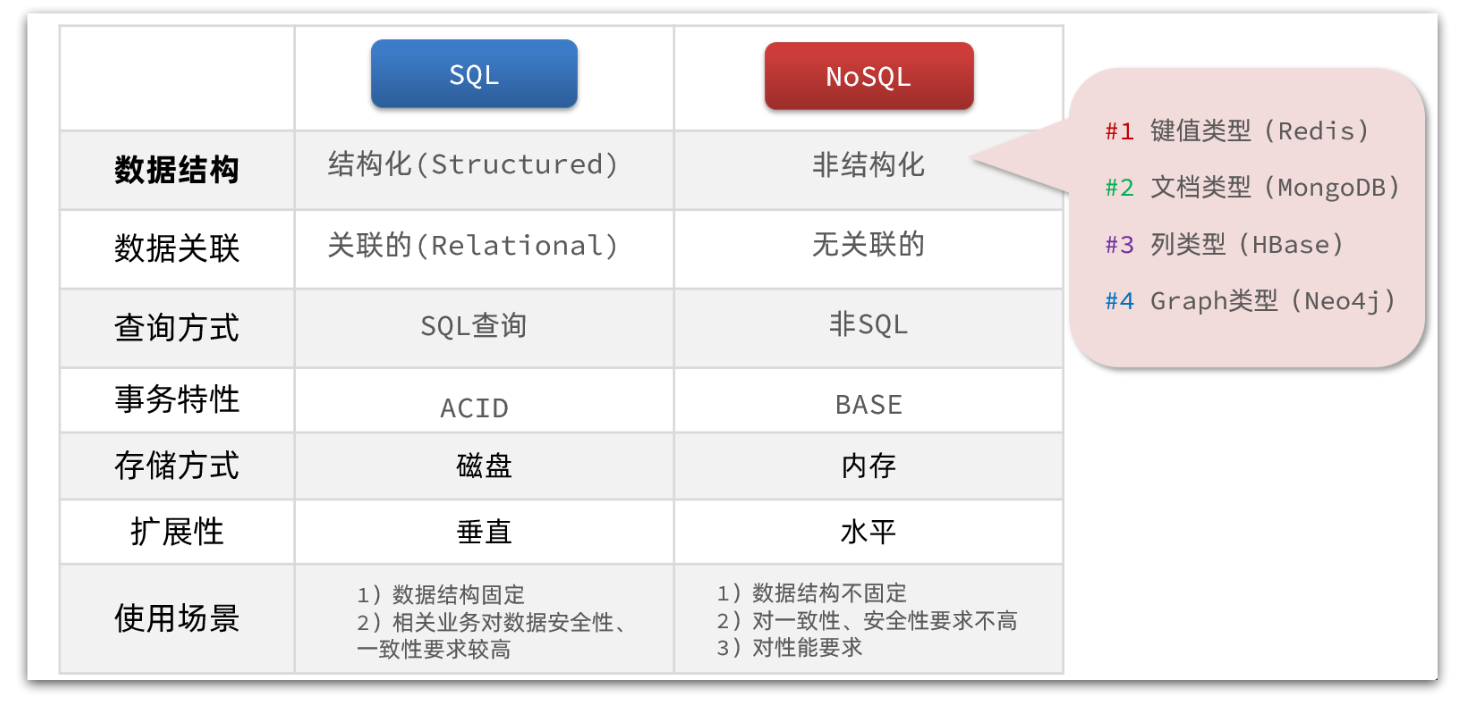
- 存储方式
-
- 关系型数据库基于磁盘进行存储,会有大量的磁盘IO,对性能有一定影响
- 非关系型数据库,他们的操作更多的是依赖于内存来操作,内存的读写速度会非常快,性能自然会好一些
- 扩展性
-
- 关系型数据库集群模式一般是主从,主从数据一致,起到数据备份的作用,称为垂直扩展。
- 非关系型数据库可以将数据拆分,存储在不同机器上,可以保存海量数据,解决内存大小有限的问题。称为水平扩展。
- 关系型数据库因为表之间存在关联关系,如果做水平扩展会给数据查询带来很多麻烦
安装redis 这里到了很关键的一点
之前我们在苍穹外卖学redis的时候用的是windows版的redis ,实际上redis官方只发布了linux版的,我们在这里使用的windows版的redis是微软自己写的,但是这个早就不维护了
所以如果我们想用linux版的redis 这里有几种解决方法
1.用虚拟机运行linux(这个也是黑马教程使用的方法,但是我实在不想,搞的电脑好卡)
2.购买linux云服务(在这里我将购买阿里云服务器,使用这种方式)强烈建议你选择 Ubuntu。
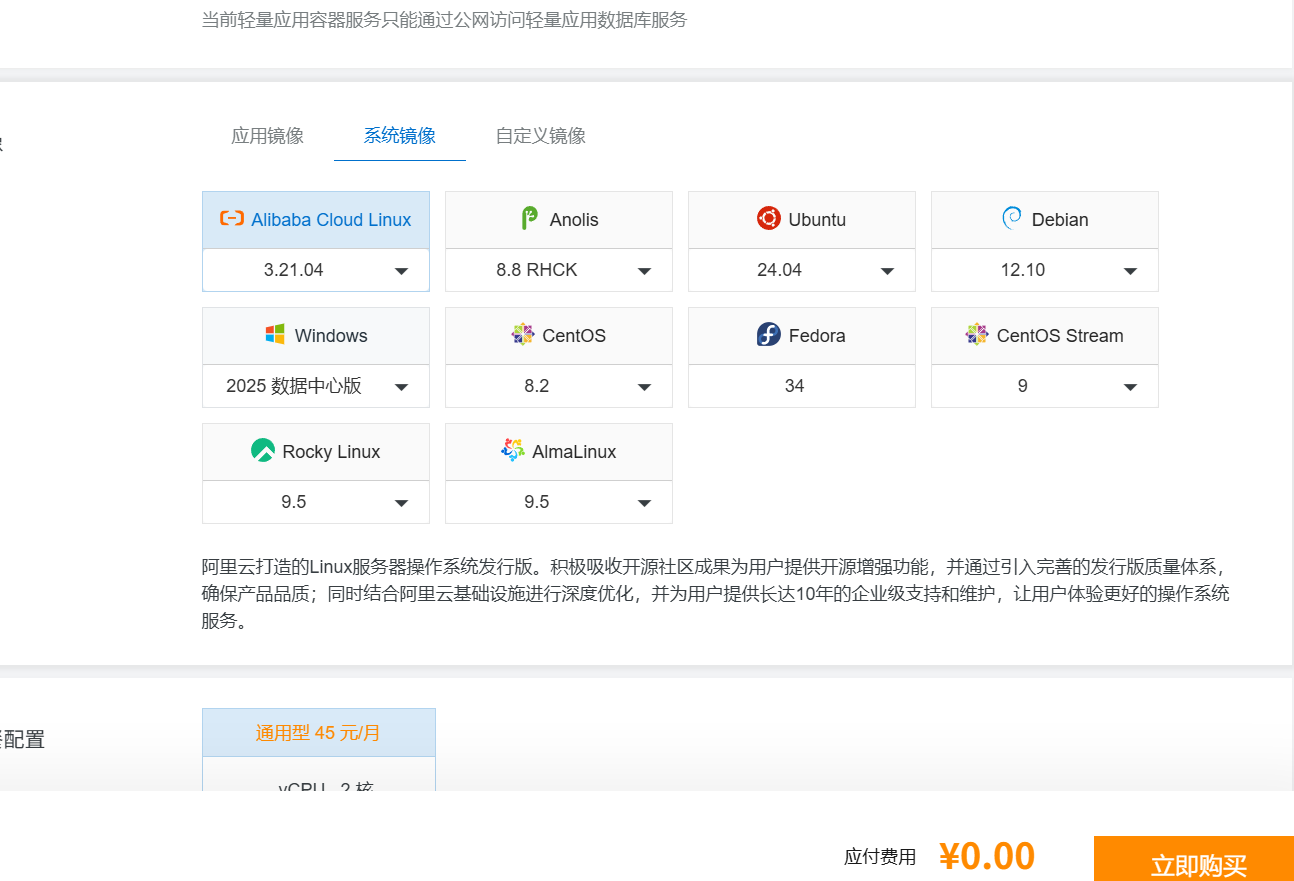
请点击右上角的 Ubuntu 图标,然后在下拉菜单中保持默认的 24.04 (或者如果你看到下拉框里有 22.04 ,选 22.04 也可以,都很稳定)。
为什么强烈推荐选 Ubuntu?
- 避开 CentOS 的"停更坑": 你学的《苍穹外卖》或其他老教程里,老师演示用的基本都是 CentOS 7。但现实情况是,CentOS 官方已经停止维护了。对于新手来说,现在装 CentOS 经常会遇到 yum****源失效、无法下载软件的报错,非常搞心态。
- 新手最友好,社区最庞大: Ubuntu 是目前全世界开发者用得最多的 Linux 系统。你在学习中遇到任何报错,去百度或 Google 搜索,出来的解决办法 90% 都是基于 Ubuntu 的,抄代码都能直接抄。
- 完美适配 Docker: Ubuntu 安装 Docker 的过程极其丝滑,官方支持得最好。
3.用本地用docker 装reidis的容器(这个也是大伙很推荐的一种方式)
4.用云服务器用docker安装redis的容器
因为我本人想玩云服务器 ,又想学习docker所以在这里我选择了第四种方式,而且最重要的是: 这正是目前企业里最主流、最标准的现代后端部署方案。
启动
redis的启动方式有很多种,例如:
- 默认启动
- 指定配置启动
- 开机自启
默认启动
安装完成后,在任意目录输入redis-server命令即可启动Redis:
redis-server
如图:
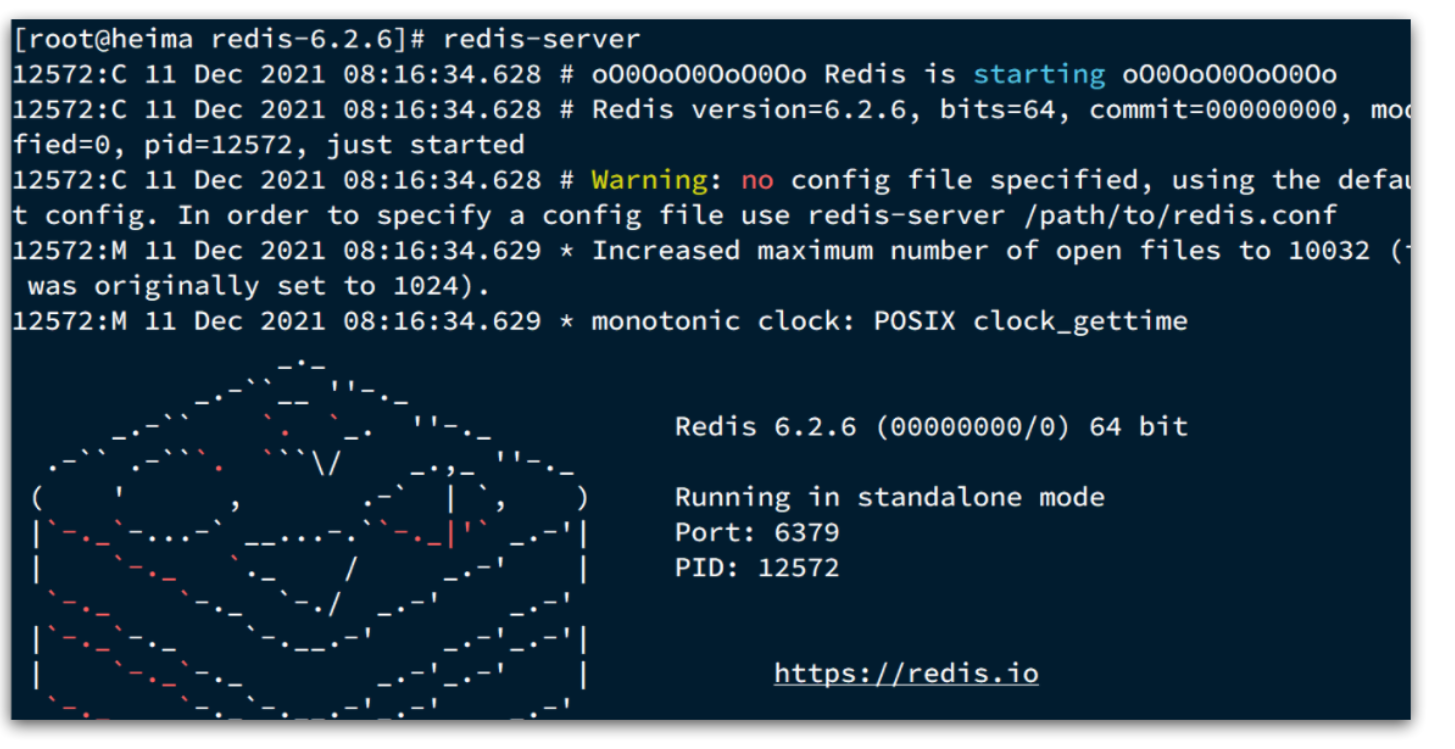
这种启动属于前台启动,会阻塞整个会话窗口,窗口关闭或者按下CTRL + C则Redis停止。不推荐使用。
之前我们在苍穹外卖用的就是这种方式
教程里面用的是指定配置启动 (好像是改了守护进程改成yes,意思就是可以让redis在后台运行)
其实这些我们都不用管了,现在是云服务器 + Docker 运行 Redis,不需要再单独管教程里那个 daemonize yes。docker run -d 已经起到了后台运行的作用。并且因为我们用的是用云服务器启动的,只要云服务器不关机,就一直会开着docker,和redis 不用我们手动去启动
我们第一次启动redis就是通过这条命令启动的
docker run --name my-redis -p 6379:6379 -d redis而docker是我们通过这条命令启动的
systemctl start docker并且我们的docker和reids都设置了开机自启
设置开机自启
怎么检查有没有开机自启
执行:
dockerinspect-f'{{.HostConfig.RestartPolicy.Name}}'my-redis
如果返回:
no
说明 没有 设置开机自启。
如果返回:
always
说明已经设置了。
怎么给 Docker 版 Redis 设置开机自启
如果容器已经创建好了,可以直接执行:
dockerupdate--restart=alwaysmy-redis
接下来黑马教程开启了日志,和修改了redis的密码,但是docker默认就是开启的状态
Docker 里通常默认就能看日志,但这不是"默认开启了 Redis 文件日志",而是 Docker 默认收集了 Redis 输出到控制台的日志。
所以我们只需要用
docker logs my-redis
去查看我们的日志
然后在这里我们修改密码采取这种方式
方式 2:推荐,重建容器并带密码启动
先停掉并删除当前容器:
docker stop my-redis
docker rm my-redis然后重新创建:
docker run -d --name my-redis --restart=always -p 6379:6379 redis redis-server --requirepass 123456这样意思是:
- 后台运行
- 容器名还是
my-redis - 开机自动恢复
- Redis 启动时直接带密码
以后连接时就要这样:
docker exec -it my-redis redis-cli -a 123456或者进交互后:
AUTH 123456改密码后怎么验证
1. 不带密码连
docker exec -it my-redisredis-cli
然后:
PING
如果提示需要认证,说明密码生效了。
2. 带密码连
docker exec-it my-redis redis-cli-a123456
然后:
PING
返回:
PONG
安装完成Redis,我们就可以操作Redis,实现数据的CRUD了。这需要用到Redis客户端,包括:
- 命令行客户端
- 图形化桌面客户端
- 编程客户端
Redis安装完成后就自带了命令行客户端:redis-cli,使用方式如下:
redis-cli options commonds
我们发现在docker里面是这样的,后面基本是一样的
docker exec -it my-redis redis-cli -a 123456这里我来解释一下
这多出来的 docker exec -it my-redis,其实就是 Docker 专属的**"开门进房"暗号**。
我们把它拆开来,一个词一个词给你翻译成大白话:
🔍 逐词拆解:
- docker exec
-
- 字面意思: 执行(execute)。
- 大白话: 它的意思是**"我要在一个正在运行的集装箱(容器)里面,执行一个动作"**。相当于你拿起了对讲机,准备对集装箱里面下达指令。
- -it (最关键,也是新手最迷惑的)
-
- 字面意思: 它是两个字母的缩写,
-i(interactive,保持交互) 和-t(tty,分配一个伪终端屏幕)。 - 大白话: 相当于**"给我接通视频通话,并且允许我持续讲话"**。
- 如果不加它会怎样? 如果你不加
-it,系统确实会把后面的指令传进容器,但容器执行完立刻就"挂断电话"了,你根本看不到反馈,也没法连续敲下一条命令。加上-it,你才能像面对面一样,看到那个熟悉的127.0.0.1:6379>交互界面。
- 字面意思: 它是两个字母的缩写,
- my-redis
-
- 字面意思: 容器名称。
- 大白话: 这是你给集装箱起的**"门牌号"**。因为服务器上可能同时跑着好几个 Redis、好几个 MySQL,你得明确告诉 Docker,你要进的是叫
my-redis的这个房间。
其中常见的options有:
-h 127.0.0.1:指定要连接的redis节点的IP地址,默认是127.0.0.1-p 6379:指定要连接的redis节点的端口,默认是6379-a 123321:指定redis的访问密码
其中的commonds就是Redis的操作命令,例如:
ping:与redis服务端做心跳测试,服务端正常会返回pong
不指定commond时,会进入redis-cli的交互控制台:
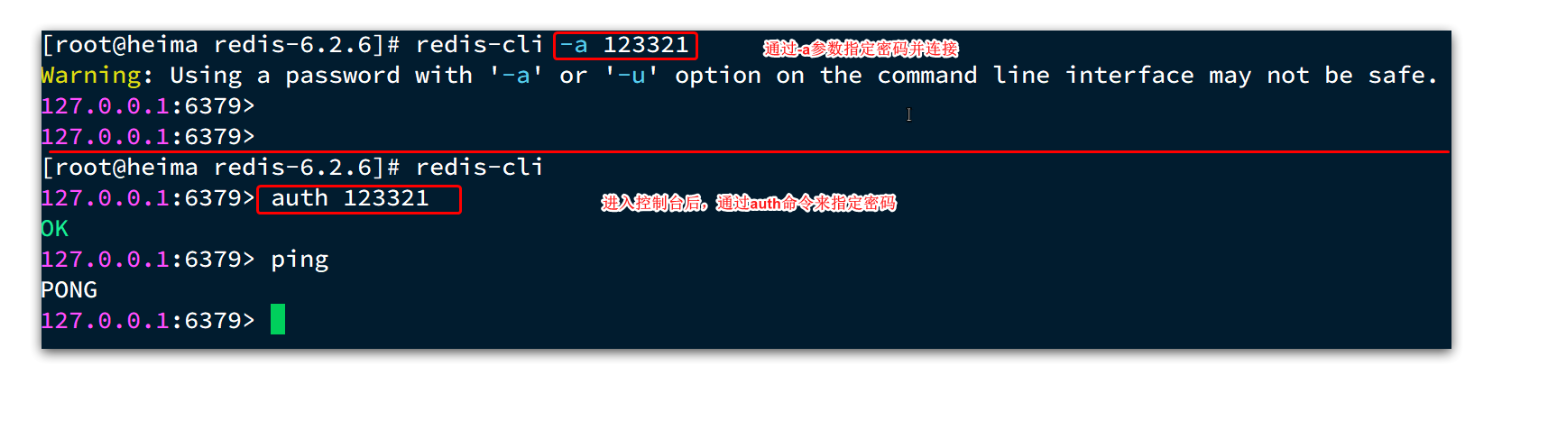
然后这里有一个易混淆的点
在你敲下 docker exec -it my-redis redis-cli****并且没指定 IP 的这种情况下,它连的是**「Docker 容器(玻璃房)内部专属的 127.0.0.1」**。
并不是我服务器的公网IP
接下来我们要去看看redis图形化客户端,这个并不是由官方编写的,而是由一位GitHub大神编写的,现在已经开源了
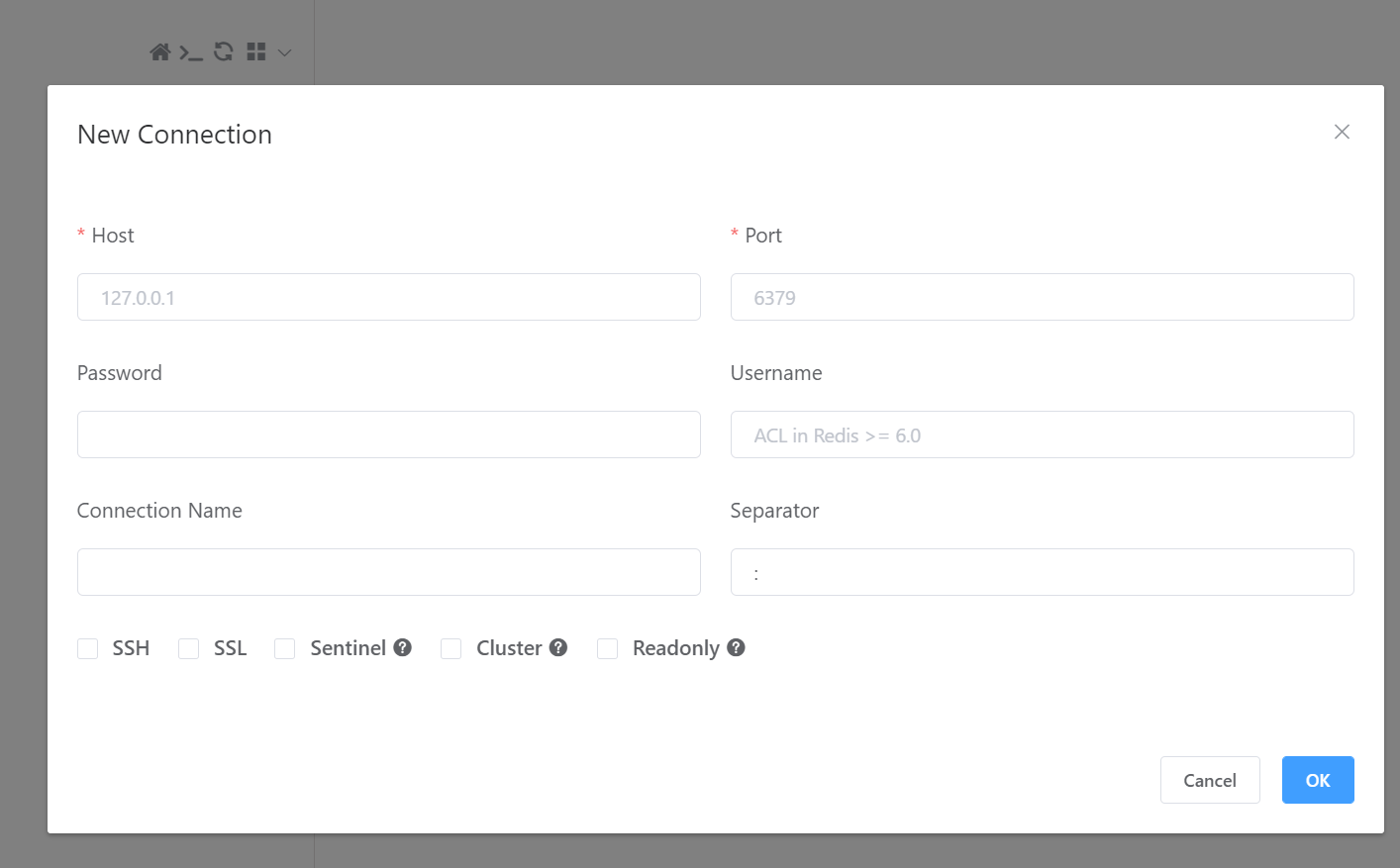
其实之前苍穹外卖也用到了这个
这个我们准备连接到我们云服务器里面的redis
- Host: 你的云服务器公网IP
- Port: 6379
- Password: 你的密码
- Username:留空
- Connection Name: my-redis
- Separator: :
但是这里有一个点要注意
我们要去服务器开放这个6379端口
但是有一个疑惑,之前不是通过ssh访问到redis了吗
但这不等于"你的本地电脑也能直接连 Redis"
因为你现在成功的链路其实是:
你的电脑 -> SSH -> 云服务器 -> Redis
其实就相当于我们在云服务器本身连 redis了
这只能证明放行了22端口
而不是:
你的电脑 -> 直接连 Redis 的 6379 端口
这两件事不是一回事。
我们来到阿里云的防火墙模板,准备放行这个
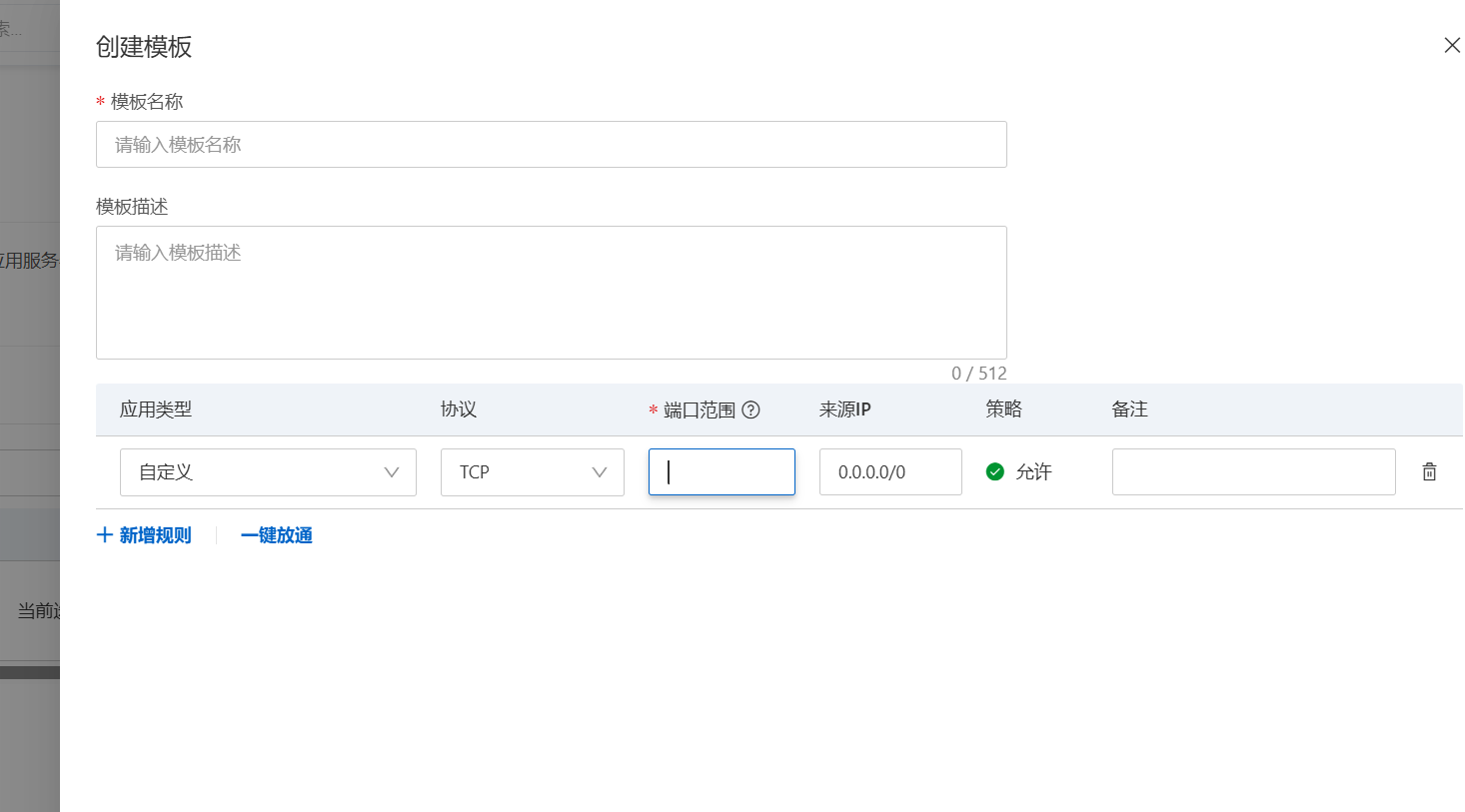
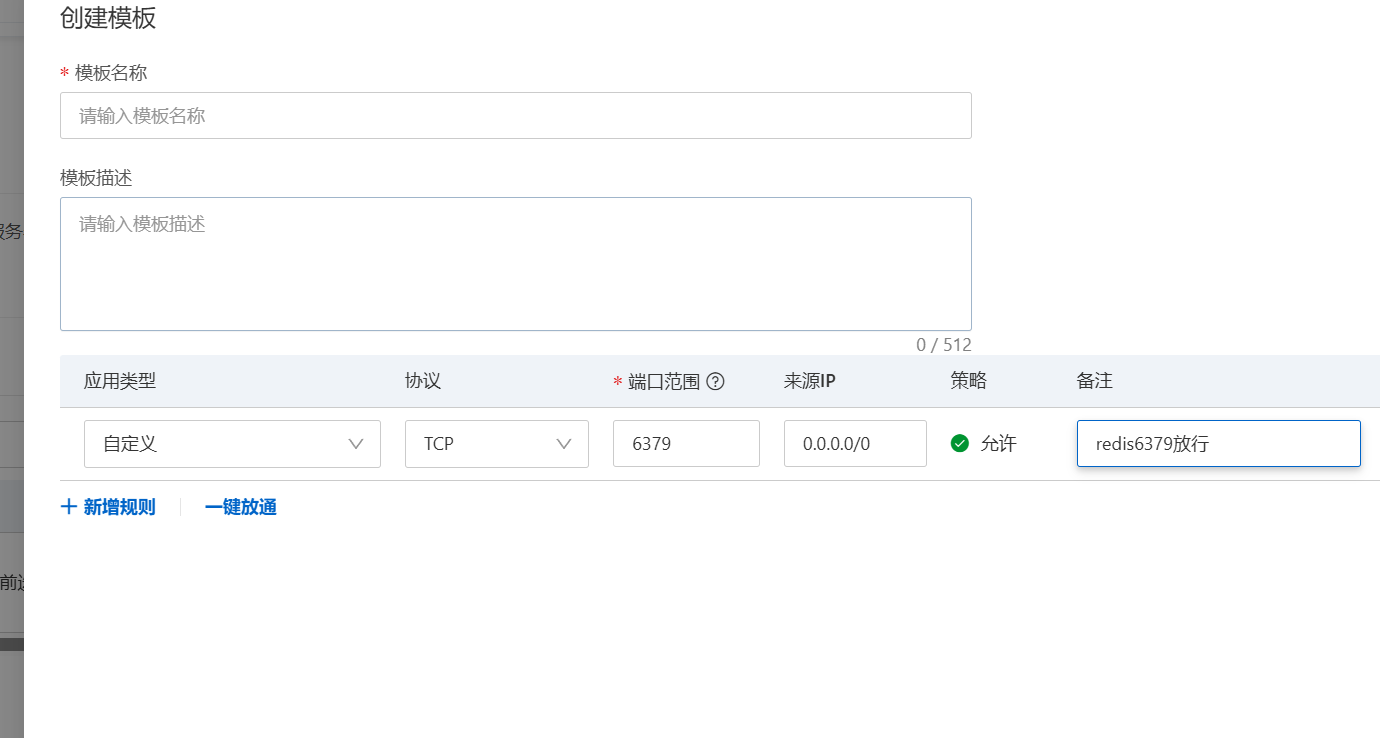
这样填写 0.0.0.0意思就是放行所有ip
创建之后应用至示例就可以了
简单来说,你的公网 IP 能连上 Docker 里的 Redis,是因为你在启动容器时那句神奇的 -p 6379:6379。
为什么能连上?(核心逻辑)
我们可以把这个过程想象成一个**"转接电话"**的过程:
- 公网 IP 是你的"大门": 当你在桌面端输入公网 IP 时,你的请求实际上是发送到了 云服务器的网卡 上。
- 宿主机(服务器)是"接线员": 云服务器收到 6379 端口的请求后,它并不知道怎么处理,但它查了一下自己的"转接表"。
- 端口映射是"转接规则": 因为你运行了 -p 6379:6379**,这就相当于告诉服务器:"只要有人在大门口找 6379 分机,你就把电话直接转接到 Docker 内部那个叫** my-redis****的房间的 6379 端口去。"
- Docker 内部的 127.0.0.1: Redis 确实在它自己的小房间里听着 127.0.0.1:6379**,但因为它接到了宿主机转接过来的"电话",连接就建立成功了。**
关键点:网络隔离
- 容器视角: Redis 认为自己运行在本地( 127.0.0.1**),它是安全的、隔离的。**
- 宿主机视角: 宿主机(你的 Ubuntu)在 6379 端口开启了一个"监听员",专门负责把流量往容器里搬。
- 外部视角: 你只需要知道服务器的公网 IP 即可,Docker 的内部细节对你来说是透明的。
当时就是这条命令设置的转接表
docker run --name my-redis -p 6379:6379 -d redis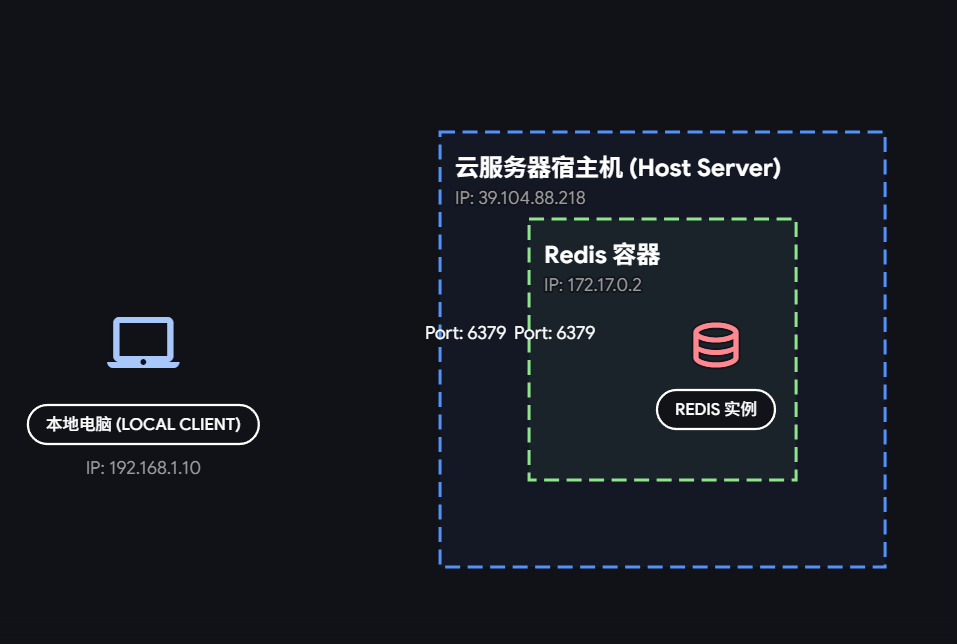
这些redis环境配置就大功告成了
接下来来到命令学习
Redis常见命令

下面三种特殊类型,其实本质上也是字符串,所以为什么叫基本类型
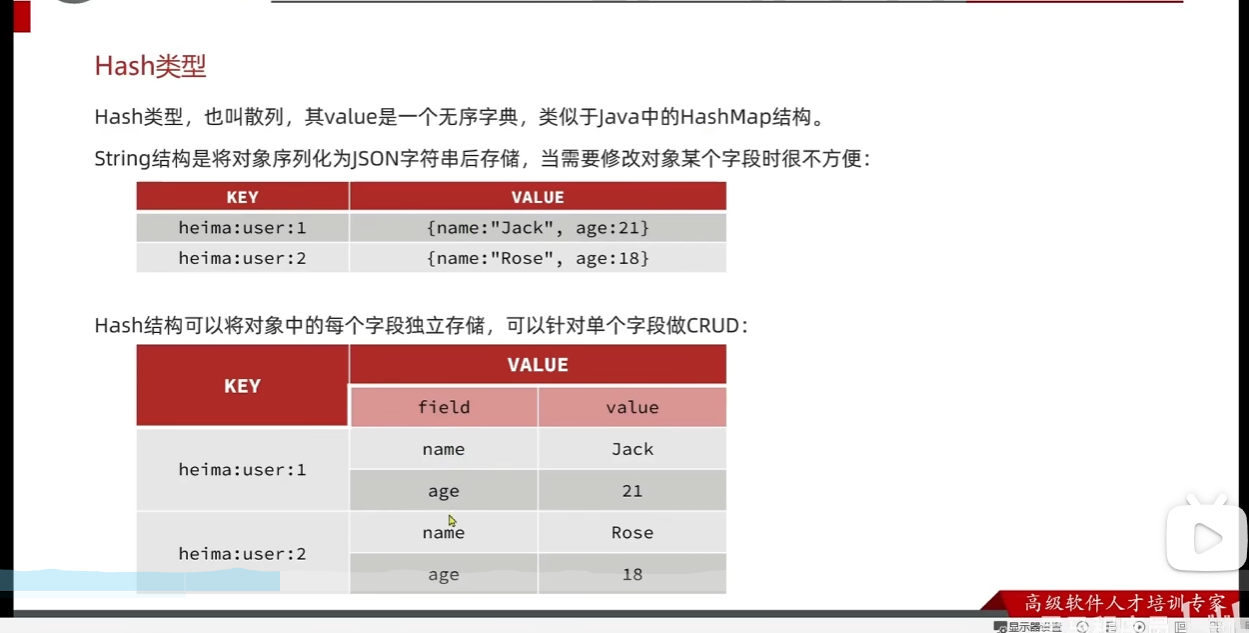
然后这里的Hash 见的比较少它是一个键值对的集合(field-value mapping)。
这些命令我们可以在官方文档 https://redis.io/docs/latest/commands/
通过组来查询
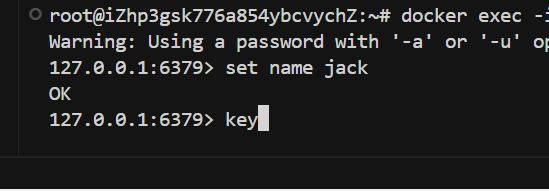
当我们输入一个key然后按tab键 它是会自动补全的
之前好像苍穹外面redis也接触过这个
String结构

keys是模糊查询,而且redis是单线程的,如果没有设置主从节点,在主节点上跑会直接卡死必须得查完才能进行接下来操作,所以在生产上不建议使用这个keys
String类型,也就是字符串类型,是Redis中最简单的存储类型。
其value是字符串,不过根据字符串的格式不同,又可以分为3类:
- string:普通字符串
- int:整数类型,可以做自增.自减操作
- float:浮点类型,可以做自增.自减操作


需要注意的是这里面的mget返回的应该是一个数组 在redis 里面数组就是这样1),2)这种方式这样展示出来
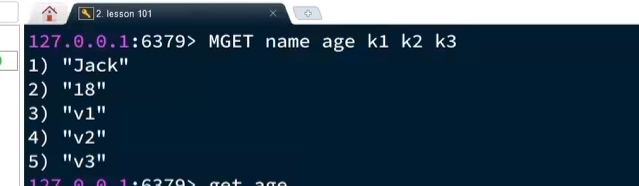
现在有一个这个问题


我们发现这个和hash其实非常像,但是并不是hash
1. Hash 图里的大括号:只是为了给人类看的(视觉伪装)
看你发的这张图,Hash 后面跟着 {name: "Jack", age: 21}。 真相是:在 Redis 的底层 Hash 结构中,根本不存在大括号 {和 **}**,也不存在冒号 :****! PPT 之所以这么画,仅仅是为了用一种程序员熟悉的格式(伪代码)告诉你:"这是一个包含多个属性的对象"。
如果你真要往 Hash 里存这个数据,你敲的真实命令是这样的:
Plaintext
HSET user:1 name "Jack" age 21看!完全没有大括号! Redis 会在内部建一个小表格,左边是 name,右边是 Jack。
2. String 里的 JSON 大括号:是实打实的真实字符
回到你上一个问题(图2),如果你把 Java 对象变成 JSON 字符串存进 String 里,你敲的命令是这样的:
Plaintext
SET user:1 "{\"id\":1, \"name\":\"Jack\", \"age\":21}"在这里,大括号 {****、双引号 "****、冒号 :****,统统都是真实的文字字符! 它们实实在在地占据着内存。Redis 根本不认识里面的 name 和 age,它只觉得这是一个总长度为 37 个字符的"长句子"。
这里有两种写法第一种是教程里面的写法
穿法一:外层穿"单引号"(你的写法,强推! 🌟 )
-
Plaintext
SET heima:user:1 '{"id":1, "name":"Jack", "age": 21}'
因为外层是单引号 ',内层是双引号 ",两者长得不一样,不会打架。所以完全不需要加 \ 去转义。非常清爽!在 Redis 命令行(CLI)里测试时,我们都这么干。
穿法二:外层穿"双引号"(我刚才的写法,看起来很乱)
加\是因为两个双引号,里面双引号需要 \作为转义字符
-
Plaintext
SET heima:user:1 "{"id":1, "name":"Jack", "age": 21}"
Hash结构

List结构



为什么用 BLPOP**/** BRPOP****就可以?
在 Redis 中,LPOP 和 RPOP 是普通的出队命令(从左边/右边弹出数据)。如果 List 为空,它们会立刻返回 nil(空)。 如果在实际开发中,你的程序想第一时间处理队列里的新消息,使用普通的 RPOP,你的代码就必须写成一个死循环(轮询),不断地去问 Redis:"有新数据了吗?"
- 弊端: 这种不断发问的方式极其浪费网络资源和 CPU 性能。
BLPOP**(Blocking Left POP) 和** BRPOP**(Blocking Right POP) 则是带有"阻塞"特性的命令。** 当使用 BRPOP 去读取一个空的 List 时,Redis 不会立刻返回空,而是会把这个客户端的连接挂起(进入休眠状态)。这也就是图片中提到"出队时采用 BLPOP 或 BRPOP"就能模拟阻塞队列的原因。
timeout****参数设置的是"最长等待时间",而不是"固定等待时间"。
1. 设置 5 秒:数据来了会立即返回吗?
会,而且是秒回。 如果你执行 BLPOP queue 5:
- 如果数据在第 0.1 秒就来了: 消费者会立即带着数据返回,整个过程只耗时 0.1 秒。它绝不会傻等够 5 秒才出来。
- 如果这 5 秒内一直没数据: 它才会一直等到第 5 秒结束,然后两手空空地返回一个
nil。
所以,这个 5 秒的意思是:"我最多等你 5 秒,这期间你只要敢出现,我立刻抓着你走。"
2. 设置 0 秒:数据来了不管吗?
完全相反,设置 0 秒是为了"哪怕等一辈子也要等到你"。 在 Redis 中,timeout 为 0 表示无限期阻塞:
- 只要队列里没有数据,消费者就永远停在那行代码不动,不消耗 CPU,也不返回结果。
- 但是 ,一旦有任何数据进入队列,消费者会瞬间被唤醒并立即弹出数据。
所以,设置 0 秒的意思是:"我会一直等下去,直到你出现的那一刻,我第一时间处理。"
它在这里会一直等待
1. 超时后数据才来,会立即 Pop 吗?
不会。
2. 如果用普通的 RPOP****会怎么样?
对比之下,普通的 RPOP****甚至连那 5 秒钟都不会等:
- 瞬间失败: 当你执行 RPOP****的那一刻,如果队列里没数据,它在 0.001 秒内就直接返回 nil****了。
- 擦肩而过: 如果数据在第 0.1 秒来了,普通 RPOP****也拿不到,因为它早在 0.1 秒之前就执行完毕并离开了。
两者的本质区别:
- 普通 RPOP**:** 是"快照查询"。它只看执行那一瞬间队列有没有东西,没有就撤。
- BLPOP 5**: 是"持续监听"。它会像开了一个限时的捕捉网,在 5 秒内任何时刻进来的数据都会被网住;但网一旦时间到了收回来,之后进来的鱼就只能留在池子里了。**
这个阻塞是对于消费者而言的
3. 一个绝对清晰的比喻:回转寿司店
把 Redis 队列 想象成寿司店里的 传送带 。 把 消费者(你的代码) 想象成 吃货顾客 。 把 生产者 想象成 后厨师傅 。
- 普通出队(RPOP): 顾客走到传送带前,看了一眼,没有三文鱼寿司。顾客立刻转身走出店门,去干别的事了。( 不阻塞 )
- 阻塞出队(BLPOP 5秒): 顾客走到传送带前,没有三文鱼。顾客没有走,而是拉了个板凳坐在传送带旁边,死死盯着出菜口等 5 分钟。(顾客被阻塞了! 这 5 分钟里他什么也干不了)
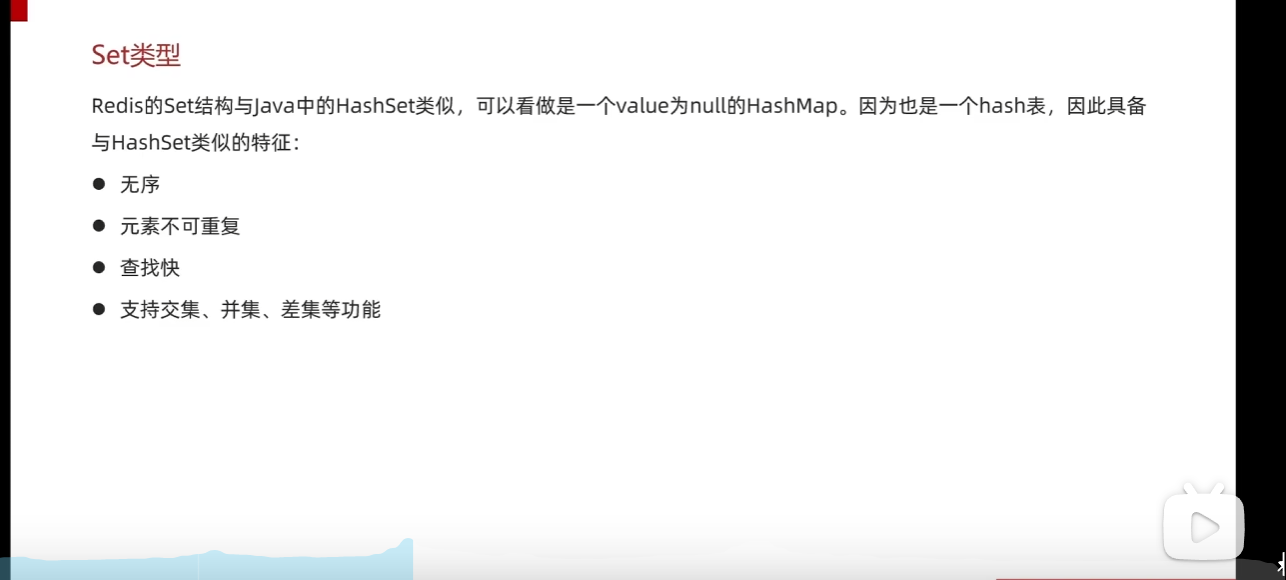
set类型
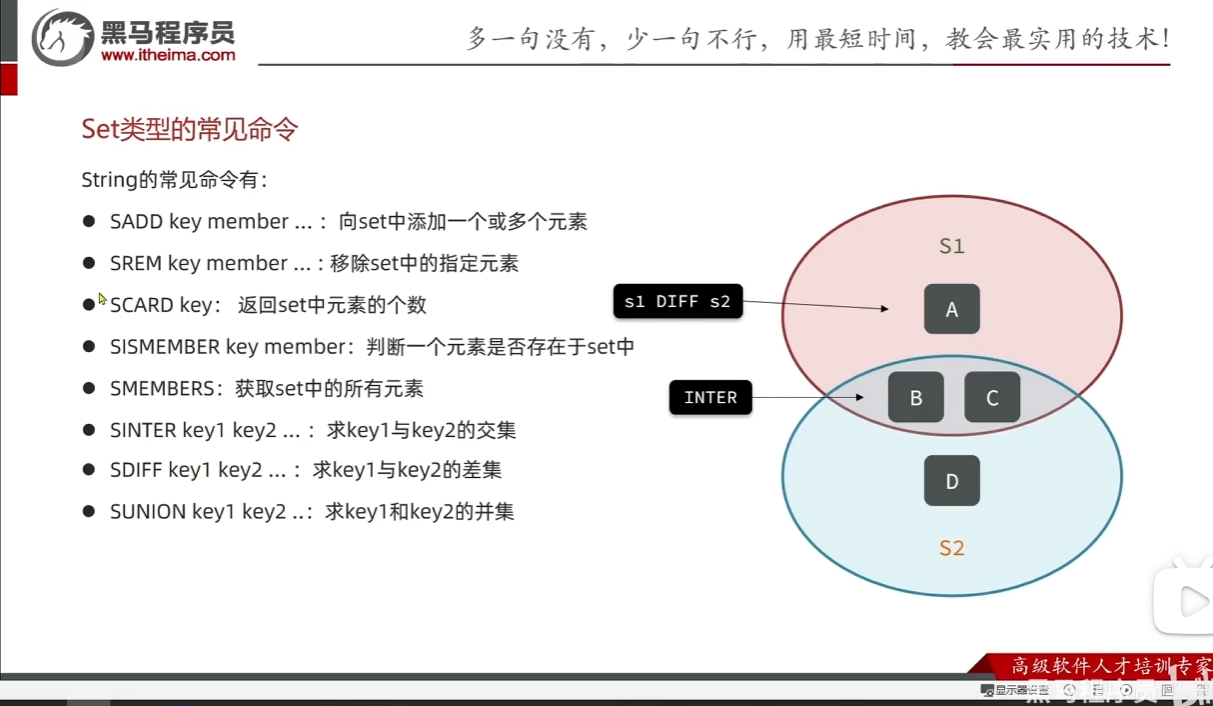
sortedset类型

这个经常用来被执行排行榜功能,之前苍穹外卖用的就是这个

Redis Java客户端
下面是官方文档推荐的redis客户端
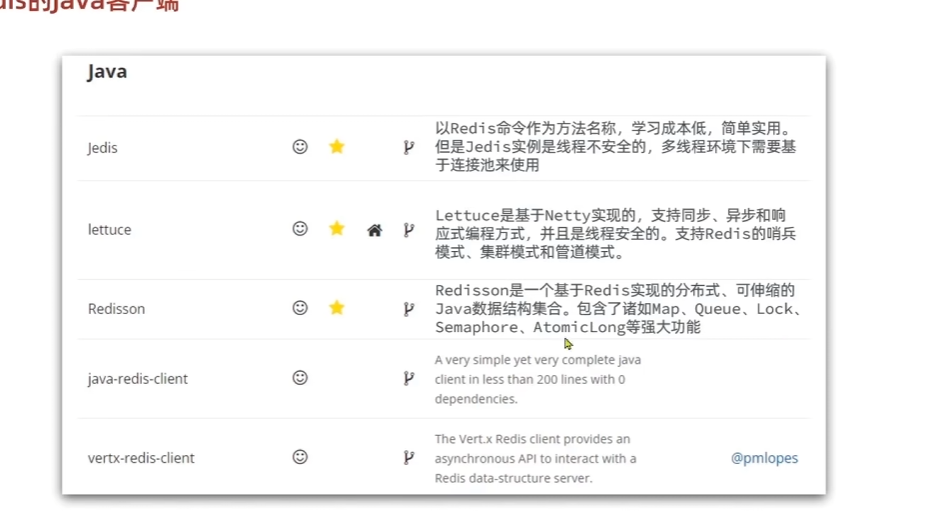
我们不用一个去学习这三个java客户端,因为spring data 可以整合、,学习了它等于两个都会了
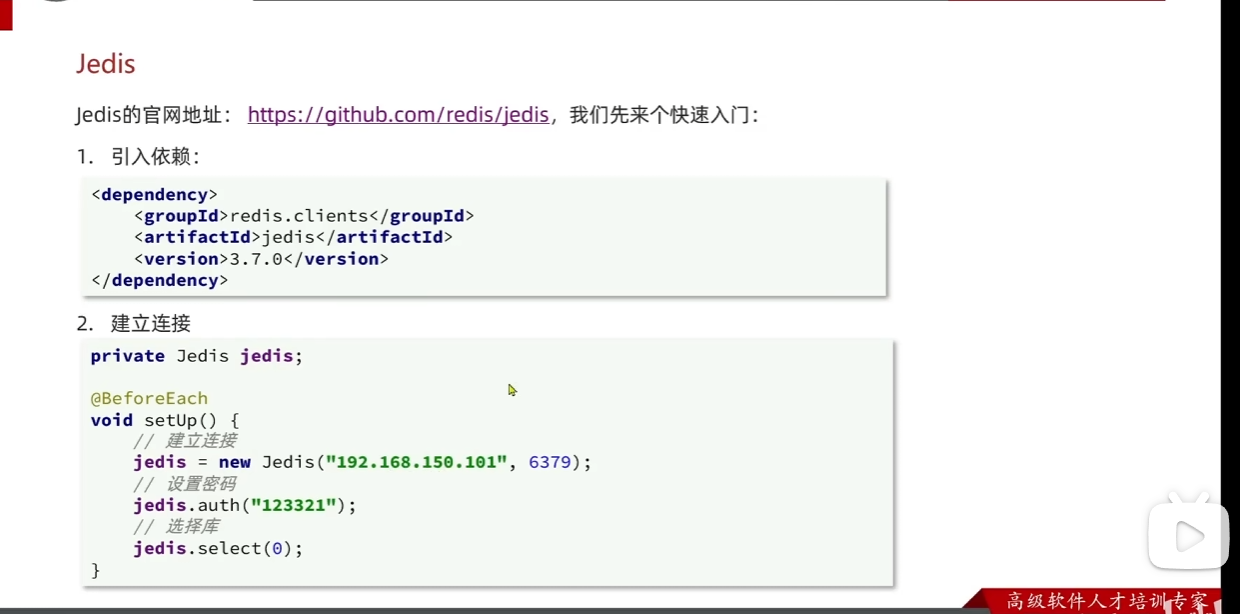
我们发现这里有一个我们从来没有见过的注解@ before each
它是 JUnit 5(Java 常用的单元测试框架)中的一个核心注解。它的主要作用是:
在当前测试类中的每一个 @Test****测试方法执行之前,都会先自动执行一次被它修饰的方法。
在你这张代码截图中的具体作用:
被 @BeforeEach 修饰的 setUp() 方法在这里被用来初始化测试环境。具体的好处如下:
-
避免代码重复: 之后你肯定会在这个测试类里编写多个测试方法(比如测试 Redis 的读数据、写数据、删除数据等操作)。如果没有这个注解,你需要在每一个测试方法开头都写一遍"建立连接"、"验证密码"和"选择库"的代码。
-
因为你但凡执行任何操作之前都得先建立连接
-
如果不使用
@BeforeEach注解,你必须在每一个测试方法里手动编写连接 Redis 的代码。假设我们要写两个测试:一个测试存数据,一个测试取数据,代码看起来就会像这样:package com.heima.test;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;public class JedisTest {
@Test void testSaveData() { // 【重复代码开始】每次都要手动建立连接 Jedis jedis = new Jedis("192.168.150.101", 6379); jedis.auth("123321"); jedis.select(0); // 【重复代码结束】 // 真正的测试逻辑 jedis.set("name", "Gemini"); System.out.println("数据保存成功"); // 用完还得记得关 jedis.close(); } @Test void testGetData() { // 【重复代码开始】换个测试方法,还得再写一遍一模一样的连接代码 Jedis jedis = new Jedis("192.168.150.101", 6379); jedis.auth("123321"); jedis.select(0); // 【重复代码结束】 // 真正的测试逻辑 String name = jedis.get("name"); System.out.println("获取到的名字是: " + name); // 用完还得记得关 jedis.close(); }}
这里select(0)是选择redis的一个库,然后过程有点像之前命令 redis cli那个命令

@AfterEach****的核心作用
在当前测试类中的每一个 @Test 测试方法执行完毕之后,都会自动执行一次被它修饰的方法。
它的主要使用场景是资源释放与清理,比如:
- 关闭连接: 关闭数据库连接、Redis 连接、网络连接等(防止连接池占满)。
- 清理测试数据: 如果你的测试往数据库里写入了脏数据,可以在这里删掉,保证不影响别人。
- 关闭文件流: 释放被占用的文件句柄。

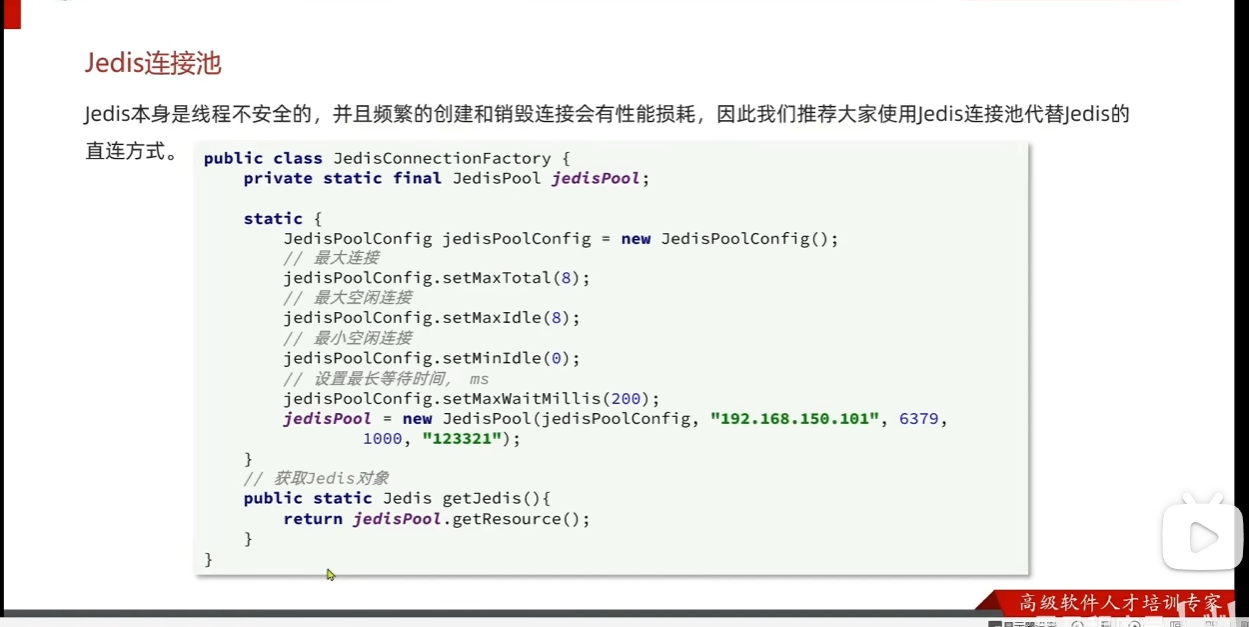
为什么jedis 需要连接池就可以解决线程安全的问题
因为连接池不是让同一个 Jedis 对象变成线程安全,而是避免多个线程共享同一个 Jedis 对象。
Jedis 本身可以理解为一个 Redis 连接对象,内部维护着 socket、输入输出流、请求响应状态等。如果多个线程同时用同一个 Jedis 实例,可能出现这种问题:
// 线程 A
jedis.set("name", "Tom");
// 线程 B
jedis.get("age");两个线程同时往同一个连接里写命令、读响应,可能导致命令和响应错乱。例如线程 A 发了 SET,线程 B 发了 GET,结果线程 A 读到了线程 B 的响应,线程 B 又读到了别的响应,这就是线程不安全。
连接池的做法是:
Jedis jedis = jedisPool.getResource();每个线程需要操作 Redis 时,从池子里借一个 Jedis****连接。用完之后关闭:
需要用的时候就给你
前面这些其实稍微看看就行,真正需要我们学的是这个SpringDataRedis ,现在它来了
SpringDataRedis
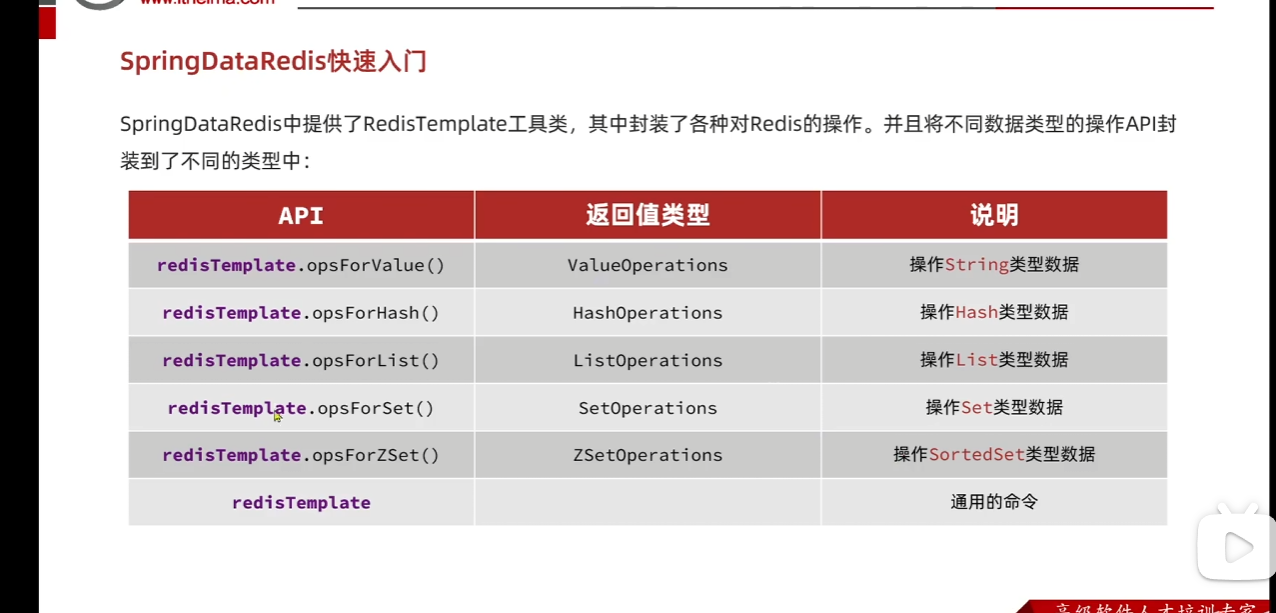
6.1.快速入门
SpringBoot已经提供了对SpringDataRedis的支持,使用非常简单:
6.1.1.导入pom坐标
<!--common-pool-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>6.1.2 .配置文件
spring:
redis:
host: 192.168.150.101
port: 6379
password: 123321
lettuce:
pool:
max-active: 8 #最大连接
max-idle: 8 #最大空闲连接
min-idle: 0 #最小空闲连接
max-wait: 100ms #连接等待时间我们看到这里有一个 lecttuce pool其实就是配置lecttuce 连接池
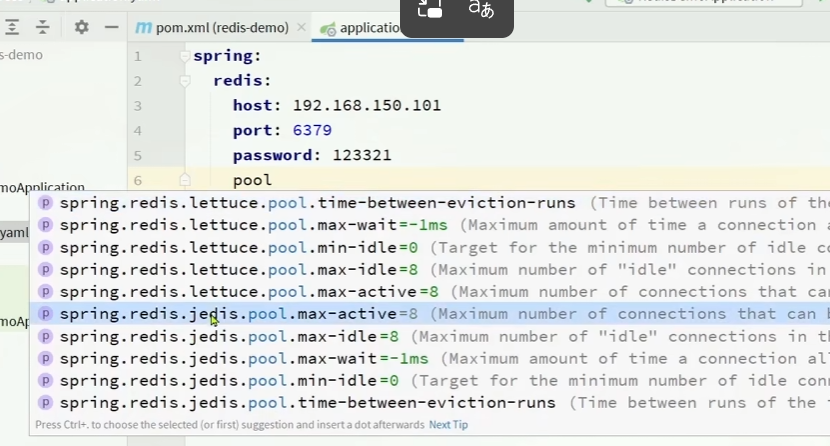
在这里连接池里面有两套,可以选择是否是lecttuce连接池,还是jedis连接池,spring默认使用的是lecttuce连接池,如果你想要选择jedis的依赖的话,还得在pom 文件另外在引入jedis的依赖
|-------------------|---------------------------------------------------------------|
| 参数 | 含义 |
| max-active: 8 | 连接池最多能同时创建 8 个 Redis 连接。如果同时有很多线程访问 Redis,最多只能有 8 个连接被使用。 |
| max-idle: 8 | 连接池中最多保留 8 个空闲连接。用完的连接不会马上销毁,会先放回池里复用,但最多保留 8 个。 |
| min-idle: 0 | 连接池中最少保留 0 个空闲连接。也就是空闲时可以不提前准备连接。 |
| max-wait: 100ms | 当连接池里的连接都被占用时,新的请求最多等待 100 毫秒。超过还拿不到连接,就会报错。 |
6.1.3.测试代码
@SpringBootTest
class RedisDemoApplicationTests {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Test
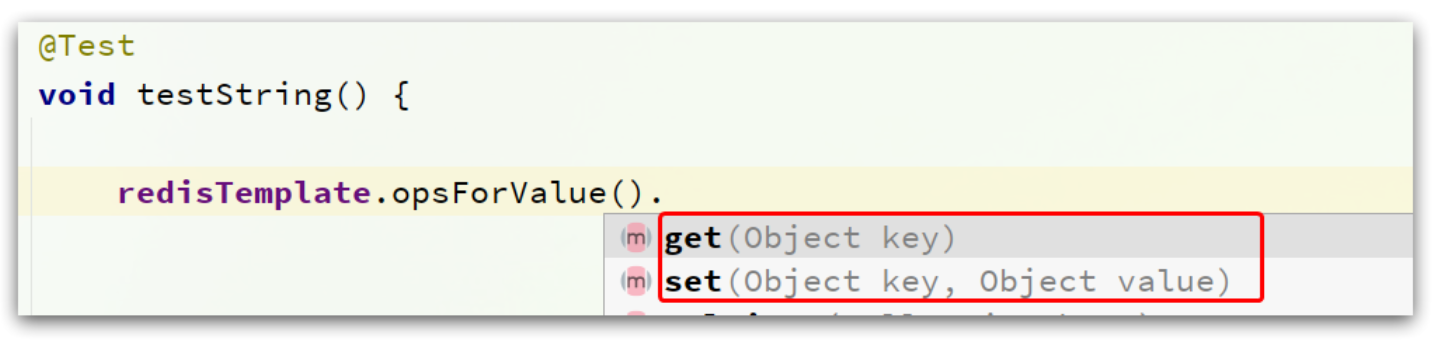
void testString() {
// 写入一条String数据
redisTemplate.opsForValue().set("name", "虎哥");
// 获取string数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
}贴心小提示:SpringDataJpa使用起来非常简单,记住如下几个步骤即可
SpringDataRedis的使用步骤:
- 引入spring-boot-starter-data-redis依赖
- 在application.yml配置Redis信息
- 注入RedisTemplate
6.2 .数据序列化器
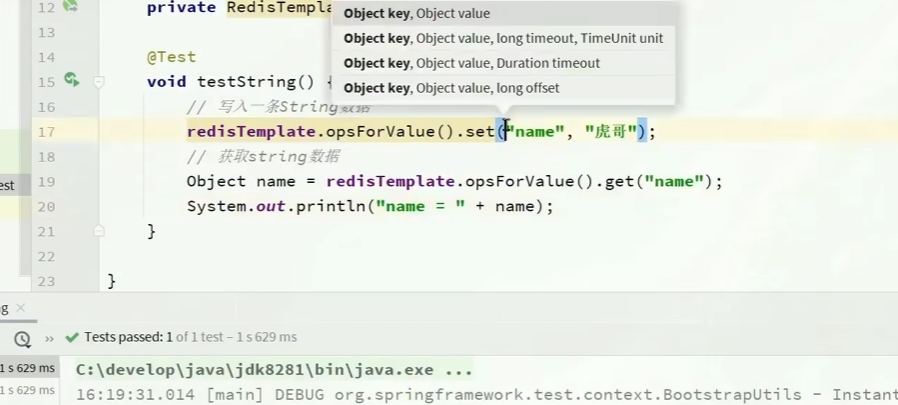
你如果像代码这样去存,你get最后还是会拿到虎哥,但是
其实在redis里面 其实存进去的东西已经被序列号剁碎了,
Java里的字符串 "虎哥"
↓ 序列化
Redis中保存的数据如果你使用原生的话reids中保存的数据就是一串乱码
\xac\xed\x00\x05t\x00\x06虎哥
但是只要序列化规则不变,我们可以把这串乱码拿回到java对象输出序列化之前的"虎哥"
Redis中保存的数据
↓ 反序列化
Java里的对象 "虎哥"RedisTemplate可以接收任意Object作为值写入Redis:
只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:
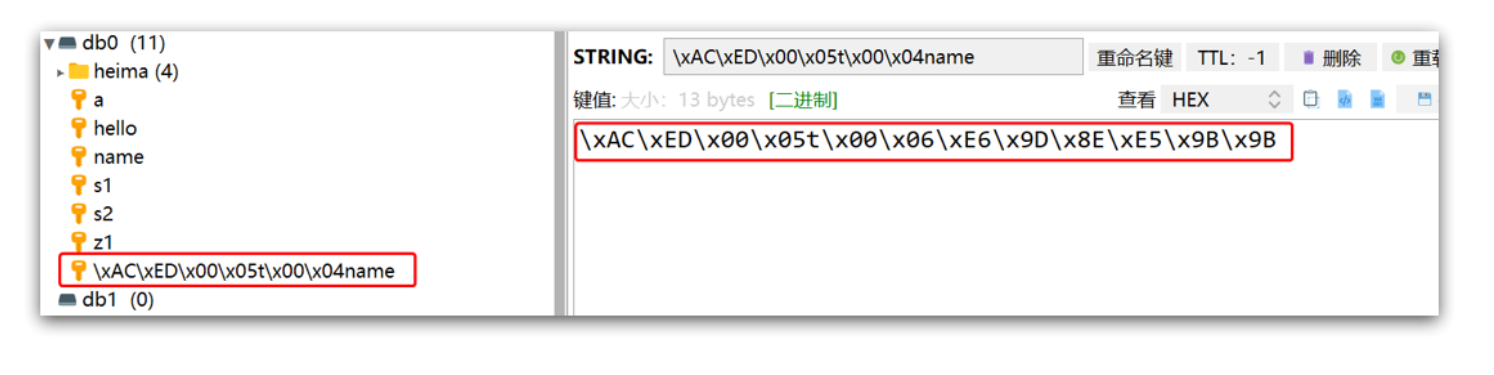
缺点:
- 可读性差
- 内存占用较大
我们可以自定义RedisTemplate的序列化方式,代码如下:
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){
// 创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 设置连接工厂
template.setConnectionFactory(connectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer =
new GenericJackson2JsonRedisSerializer();
// 设置Key的序列化
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 设置Value的序列化
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
// 返回
return template;
}
}以后用这个 RedisTemplate<String, Object> 存 value 的时候:
redisTemplate.opsForValue().set("user:1", user);会发生:
Java 对象 user
↓
GenericJackson2JsonRedisSerializer
↓
JSON 格式的数据
↓
存入 Redis取的时候:
Object obj = redisTemplate.opsForValue().get("user:1");会发生:
Redis 里的 JSON 数据
↓
GenericJackson2JsonRedisSerializer
↓
Java 对象所以整体就是:
存:Java 对象 -> JSON
取:JSON -> Java 对象这里采用了JSON序列化来代替默认的JDK序列化方式。最终结果如图:
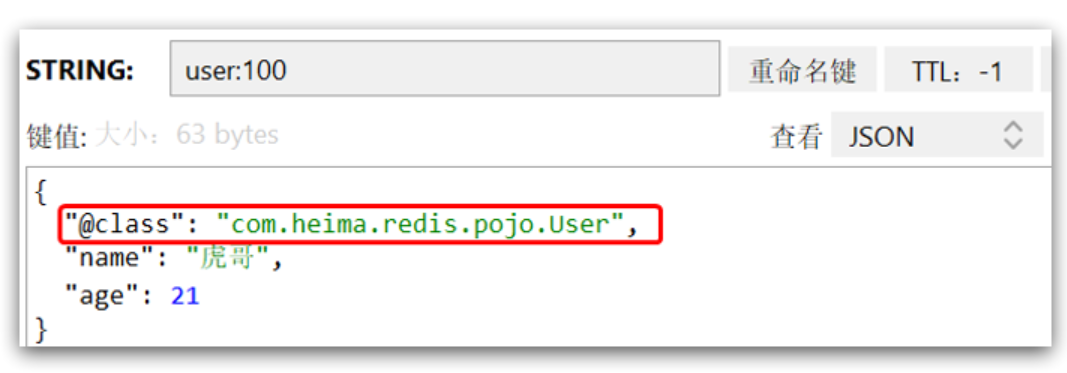
整体可读性有了很大提升,并且能将Java对象自动的序列化为JSON字符串,并且查询时能自动把JSON反序列化为Java对象。不过,其中记录了序列化时对应的class名称,目的是为了查询时实现自动反序列化。这会带来额外的内存开销。
6.3 StringRedisTemplate
尽管JSON的序列化方式可以满足我们的需求,但依然存在一些问题,如图:
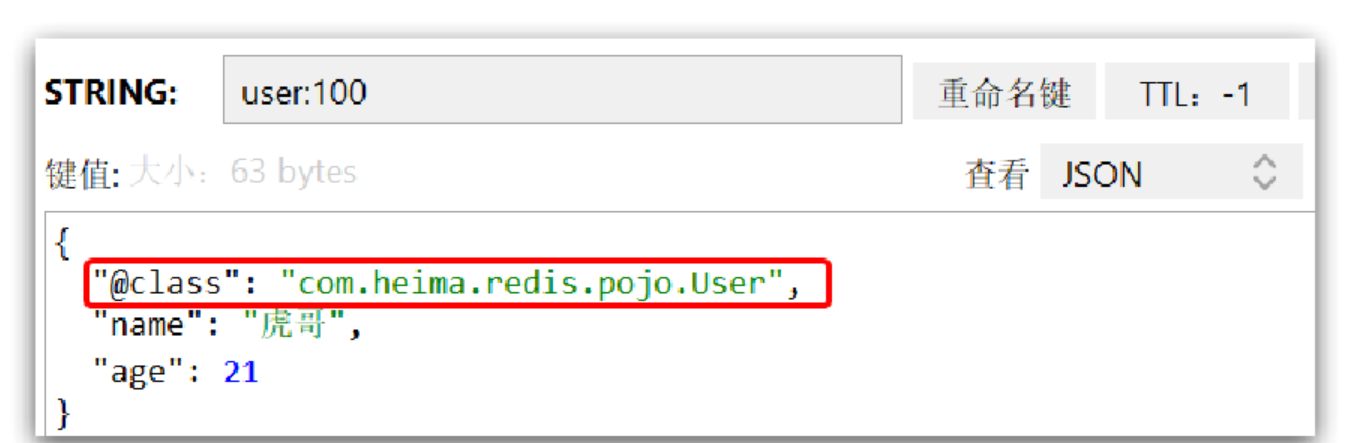
为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销。
为了减少内存的消耗,我们可以采用手动序列化的方式,换句话说,就是不借助默认的序列化器,而是我们自己来控制序列化的动作,同时,我们只采用String的序列化器,这样,在存储value时,我们就不需要在内存中就不用多存储数据,从而节约我们的内存空间
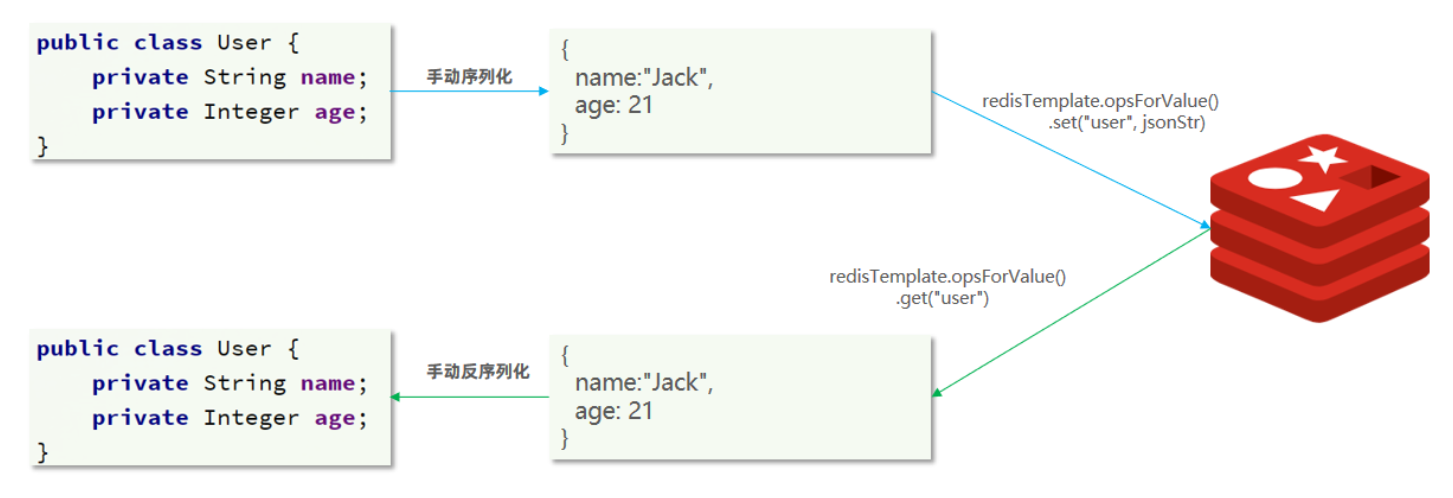
这种用法比较普遍,因此SpringDataRedis就提供了RedisTemplate的子类:StringRedisTemplate,它的key和value的序列化方式默认就是String方式。
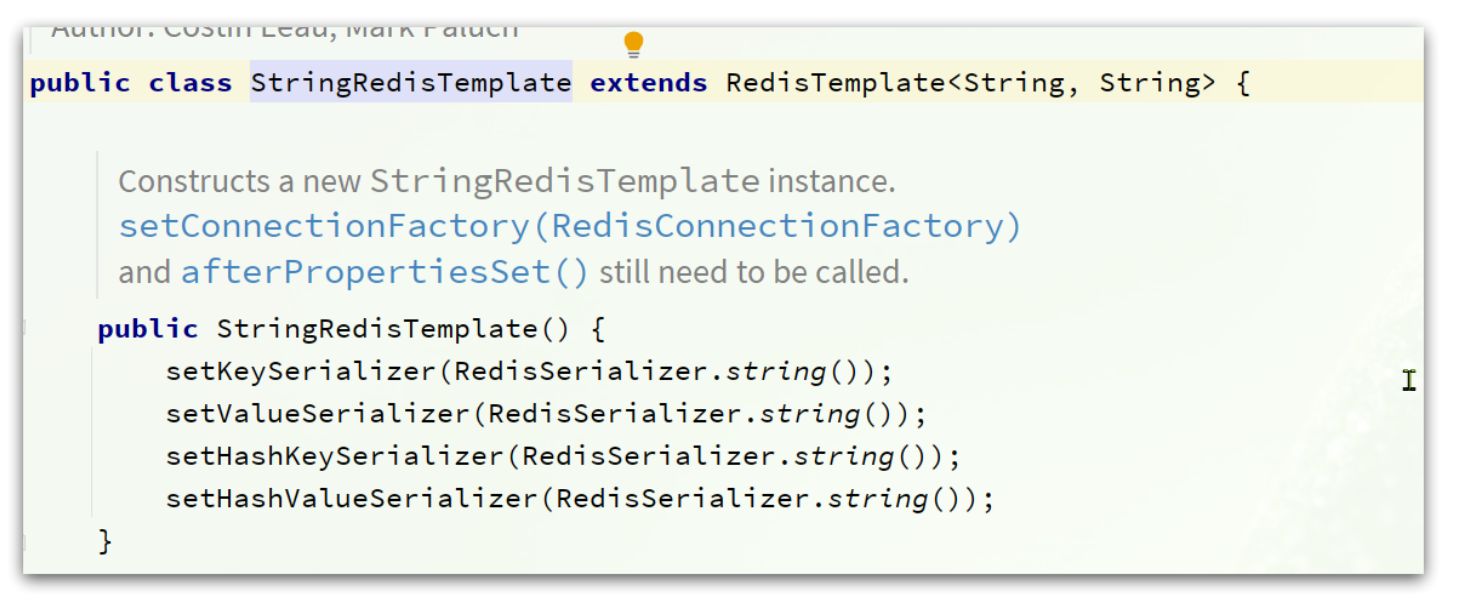
省去了我们自定义RedisTemplate的序列化方式的步骤,而是直接使用:
@SpringBootTest
class RedisStringTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
void testString() {
// 写入一条String数据
stringRedisTemplate.opsForValue().set("verify:phone:13600527634", "124143");
// 获取string数据
Object name = stringRedisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
private static final ObjectMapper mapper = new ObjectMapper();
@Test
void testSaveUser() throws JsonProcessingException {
// 创建对象
User user = new User("虎哥", 21);
// 手动序列化
String json = mapper.writeValueAsString(user);
// 写入数据
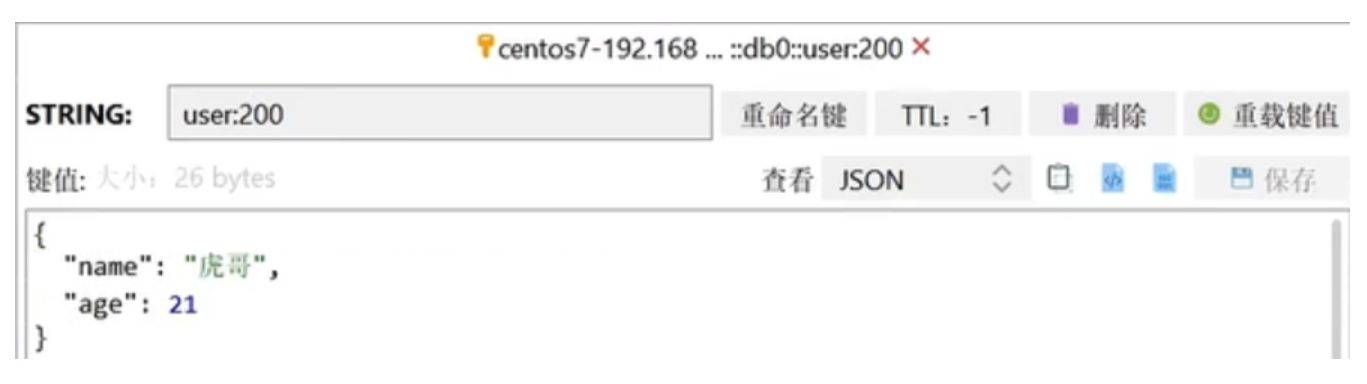
stringRedisTemplate.opsForValue().set("user:200", json);
// 获取数据
String jsonUser = stringRedisTemplate.opsForValue().get("user:200");
// 手动反序列化
User user1 = mapper.readValue(jsonUser, User.class);
System.out.println("user1 = " + user1);
}
}但是这个手动转换String对象,和手动把String 对象 转换成java对象这个过程还是不能省略
这里用到了一个工具mapper就可进行手动转换,然后这个工具其实和我们之前学过fastjosn是一样的
此时我们再来看一看存储的数据,小伙伴们就会发现那个class数据已经不在了,节约了我们的空间~
最后小总结:
RedisTemplate的两种序列化实践方案:

6.4 Hash结构操作
在基础篇的最后,咱们对Hash结构操作一下,收一个小尾巴,这个代码咱们就不再解释啦
马上就开始新的篇章~~~进入到我们的Redis实战篇
@SpringBootTest
class RedisStringTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
void testHash() {
stringRedisTemplate.opsForHash().put("user:400", "name", "虎哥");
stringRedisTemplate.opsForHash().put("user:400", "age", "21");
Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:400");
System.out.println("entries = " + entries);
}
}小技巧
选中按ctrl + H 有哪些实现
1. 普通 String(随便写的字)
如果你在这张白纸上随便写一句:"今天天气真不错,验证码是 123456"。
- 这张纸就是
String。 - 内容没有任何严格的格式,人类能看懂,但机器很难从里面准确抠出"验证码"这三个字。
2. JSON(画好的表格)
如果你在同样的一张白纸上,用尺子画了一个严格的表格:
JSON
{
"天气": "不错",
"验证码": "123456"
}- 这张纸依然是 String(数据类型没变,还是纸)。
- 但是,你赋予了这张纸严格的语法格式 (大括号、双引号、冒号),这就是
JSON。
JSON 不是一种独立于 String 之外的全新数据类型,JSON 仅仅是"一种按照特定标点符号规则写出来的、长得很特殊的 String"。 这就好比"诗歌"和"汉字"的关系。诗歌(JSON)和日常大白话(普通 String)读起来感觉完全不一样,但它们本质上都是由汉字(String)组成的。
|---------------------|------------------------------------------------------------------------|--------------------------------------------------------|---------------------------------------------------------|
| 阶段 / 步骤 | 方案 A:老做法RedisTemplate<String, Object> | 方案 B:当前推荐做法StringRedisTemplate | 核心区别点 |
| 1. 初始形态 (Java 内存中) | Java 对象 立体结构:User | Java 对象 立体结构:User | 完全一样。此时它们存在于 Java 虚拟机中,Redis 看不懂。 |
| 2. 触发动作 (谁负责转换) | 隐式/自动 调用 set() 时,底层的 GenericJackson2JsonRedisSerializer 偷偷接手。 | 显式/手动 你在代码里自己写了 mapper.writeValueAsString(user)。 | 方案 A 是框架帮你干; 方案 B 是你自己亲手干。 |
| 3. 转换结果的 Java 类型 | java.lang.String | java.lang.String | 重点! 无论谁去转,在 Java 里生成的都是一个普通的 String 变量。 |
| 4. 转换结果的 具体内容 (格式) | 带赘肉的 JSON 格式: '{"@class":"com.xxx.User", "name":"虎哥", "age":21}' | 纯净的 JSON 格式: '{"name":"虎哥", "age":21}' | 虽然都是 String,也符合 JSON 语法,但 方案 A 强行塞入了长长的一段 Java 类路径。 |
| 5. 存入 Redis (传输动作) | 将上面的长 String 发给 Redis。 | 将上面的短 String 发给 Redis。 | StringRedisTemplate 直接放行短 String,不加任何干预。 |
| 6. 最终归宿 (Redis 仓库中) | Redis String 类型 占用内存较大。 | Redis String 类型 占用内存极小。 | Redis 根本不知道什么是 JSON,它只负责把这一长串字符当做 String 数据结构存盘。 |
此外**'{"@class":"com.xxx.User", "name":"虎哥", "age":21}'**
这个既是string 也是josn
1. 从"物理外壳"来看:它是绝对的 String(字符串)
不管这段文字长得多么有规律,只要它被引号包起来(单引号或双引号),在 Java 虚拟机和 Redis 的底层看来,它就是一串 纯文本字符 。
- 计算机不会管里面写的是"虎哥"还是 @class**,它只知道这里有 50 个字符,需要占用一点内存空间。**
- 它的 数据类型 就是 java.lang.String**。**
2. 从"内部灵魂"来看:它是完美的 JSON(格式规范)
虽然它的外壳是字符串,但它的内容并没有乱写,而是 严格遵守了 JSON 的国际通用语法规则 :
- 最外层有大括号 **{}**包裹。
- 里面的属性名(如 "name"****、 "age"****)都加了双引号。
- 属性名和属性值之间用冒号 **:**隔开。
- 不同的属性之间用逗号 **,**隔开。
再比如
template.setHashKeySerializer(RedisSerializer.string());
// 设置Value的序列化
template.setValueSerializer(jsonRedisSerializer);
这连个其实都是转string,后面一个也是转string 只不过是josn 格式的string 前面一个是纯string 不带josn格式的吗
实验:把 Java 字符串 **"hello"**存进 Redis
1. 交给 RedisSerializer.string()****(专门处理 Key 的)
- 它的性格:极度耿直,原样输出。
- 处理过程 :它看到你传进来一个字符串
"hello",它什么废话都不加。
最终发给 Redis 的底层文本:
-
Plaintext
hello
-
结果 :非常干净!在 Redis 里,这个 Key 的名字就叫
hello。
1. 定义时的双引号 = 快递包装盒
当你在 IDEA 里敲下这行代码:
Java
String str = "hello";这里的双引号 "" 根本不是数据的一部分,它是 Java 语言规定的语法记号(快递包装盒)。
- 为什么需要这个包装盒? 因为 Java 编译器(那个负责检查你代码有没有错的监工)是个死脑筋。如果代码里写的是:
String str = hello;(没加引号),编译器就会到处找:"有没有一个叫hello的变量啊?有没有叫hello的类啊?" 找不到它就会报错! - 所以,你加上双引号,就是明确告诉编译器:"大哥,这是一个纯文本,不是代码指令,你别管它什么意思,直接打包收下就行!"
2. 传进内存后 = 拆快递把包装扔了
当你的程序跑起来,编译器把你的代码翻译成了计算机能懂的机器码,并把这个字符串真正存进内存(RAM)时,它会把作为记号的双引号(包装盒)直接扔掉!
计算机内存里,真正存下来的只有"货物本身",也就是 h``e``l``l``o 这 5 个字母。
2. 交给 jsonRedisSerializer**(专门处理 Value 的)**
- 它的性格:职业病严重,万物皆 JSON。
- 处理过程 :它看到你传进来一个字符串
"hello"。它心想:"我的职责是把一切变成标准 JSON。标准的 JSON 字符串,外层必须有双引号包围!"
最终发给 Redis 的底层文本:
-
Plaintext
"hello"
JSON 官方支持的 6 种基本类型
根据国际通用标准,一个合法的 JSON 字符串,它的最外层可以是以下 6 种情况中的任何一种:
- 对象 (Object):也就是你最熟悉的带有大括号的。
-
- 举例:
{"name": "虎哥"} - 对应 Java:普通的实体类(如
User对象、Map)。
- 举例:
- 数组 (Array):带有中括号的。
-
- 举例:
["苹果", "香蕉"]或者[{"name":"张三"}, {"name":"李四"}] - 对应 Java:
List、Set、数组。
- 举例:
- 字符串 (String) :带有双引号的纯文本。( 👉 也就是我们上一回合聊的情况)
-
- 举例:
"hello" - 对应 Java:
String。
- 举例:
- 数字 (Number):光秃秃的数字。
-
- 举例:
21或者3.14 - 对应 Java:
int,Integer,Double等。
- 举例:
- 布尔值 (Boolean):
-
- 举例:
true或者false - 对应 Java:
boolean,Boolean。
- 举例:
- 空值 (Null):
-
- 举例:
null - 对应 Java:
null。
- 举例:
之后我们会做我们的第二个项目黑马点评项目
这个会单独开一个文档记录