Multi-Agent 协作案例
核心目标
我的最终目的不是"堆很多智能体",而是为了把一个复杂问题拆成几个更稳定的职责单元:
- 用 Plan-Execute-Replan 做任务主循环(负责"任务推进")
- 用专职 Agent(多个子Agent:本地检索、外部研究、综合输出)补齐能力边界(负责"工具执行" ,执行具体任务)
除了多智能体主体外,还有几个概念:
-
在多agent主体外,包一层 Orchestrator,让它负责:
- 会话上下文装配
- 对话运行状态持久化
- 流式事件输出
- 中断恢复
- 失败后的兜底回答(失败时触发 fallback)
-
Checkpoint + Stream:支持中断恢复、澄清问题、实时流式输出
大致流程
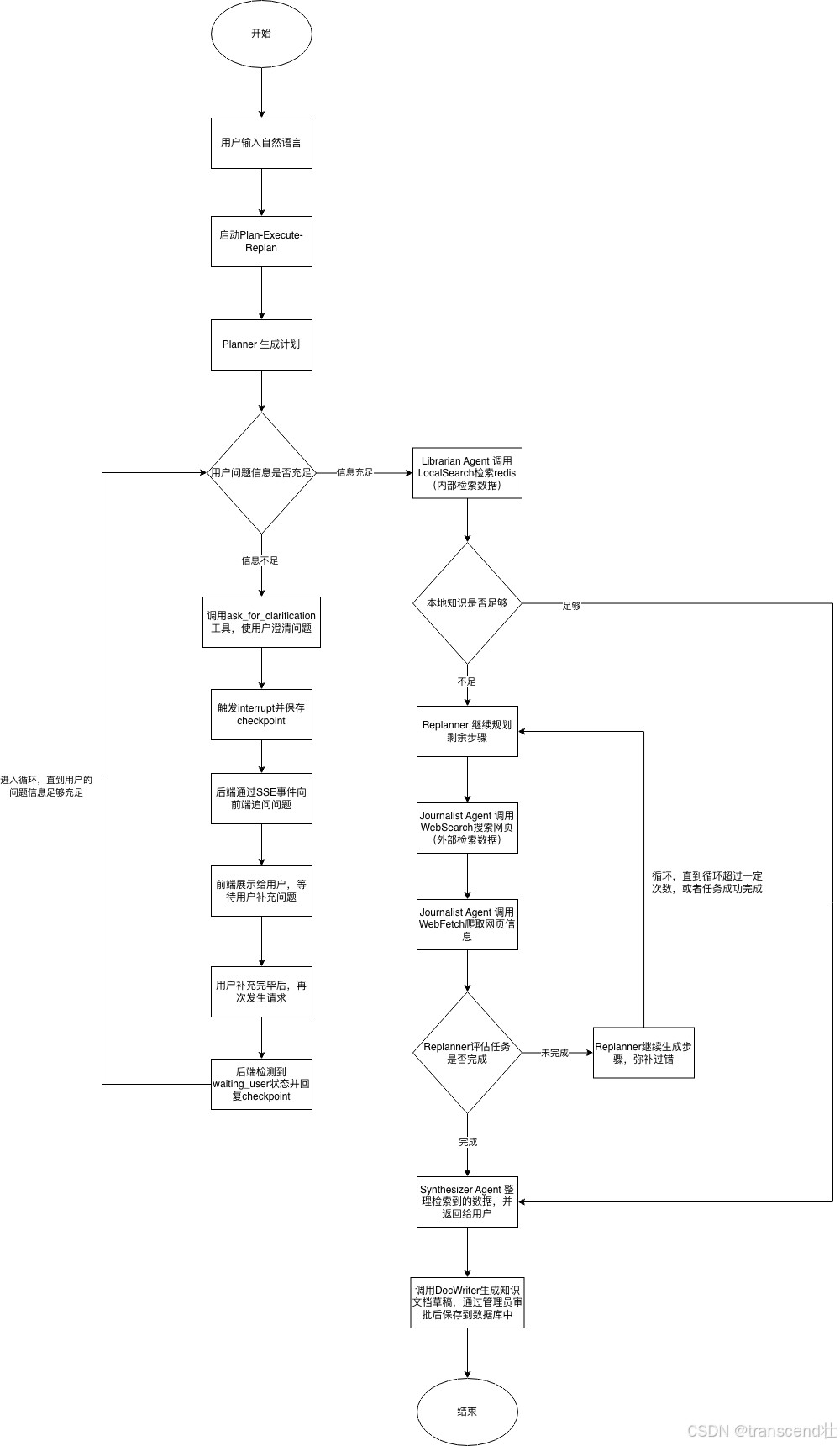
具体的角色
1. Planner / Executor / Replanner
这一层不是我自己手写一个 if-else planner,而是借助Eino框架 ADK 的 Plan-Execute-Replan 主循环。
它的职责不是直接生产最终答案,而是控制任务推进:
- Planner:先把用户问题拆成一组可执行步骤
- Executor :执行当前这一步,并调用合适的工具或能力 Agent
- 我的Executor中又包含了三个子Agent:Librarian、Journalist、Synthesizer,分别处理本地知识检索、外部研究、信息整合
- Replanner:根据执行结果判断是否继续、改计划,还是直接产出最终回答
这个结构的好处是,系统不会一开始就假设路径是固定的。 它会在执行过程中根据检索结果动态调整,而不是"先脑补完整路径,再硬着头皮走完"。
Plan-Execute-Replan:plan生成计划后,由execute执行任务,每轮只执行"下一个可执行步骤",然后由replan评估是否继续,replan评估通过后,再继续由execute执行任务,继续循环。
2. Librarian
Librarian 负责站内知识检索,也就是 RAG 这一层。它做的事情不是简单地从向量库捞几段文本,而是:
- 在本地知识范围内找最相关的文章或文档
- 给出一个本地知识摘要
- 判断当前知识覆盖是否已经足够
如果本地内容已经足够回答,就没有必要再触发外部研究;如果本地信息不足,再交给 Journalist 补齐。
3. Journalist
Journalist 负责外部研究。它的作用是把站内知识没有覆盖到的部分补上,尤其是:
- 实时信息
- 外部案例
- 行业资料
- 公开网页内容
它和 Librarian 的边界非常明确:
- Librarian 面向"内部知识"
- Journalist 面向"外部知识"
这让系统不会把 RAG 和联网搜索混成一个黑盒步骤,而是能明确知道"哪些结论来自站内,哪些来自外部"。
4. Synthesizer
Synthesizer 是结果整合器。前面的 Agent 解决的是"找到什么",它解决的是"怎么把已经找到的信息组织成用户真正想要的回答"。
它的输入通常包括:
- 用户原始问题
- 本地知识结果
- 外部研究结果
它负责把这些内容整合成:
- 可读的最终答案
- 更稳定的引用结构
- 用户可以直接消费的文字输出
可以把它理解为一个"回答编辑器",而不是"再查一次资料的人"。
编排层的作用
1. 上下文组装
用户问题进入后,系统不会只拿这句话直接去跑,而是先组装上下文:
- 当前 conversation
- 历史消息
- 对话记忆摘要
- 当前是否存在 pending run
也就是说,Multi-Agent 不是围绕"单条消息"工作的,而是围绕"一个正在持续推进的会话"工作的。
编排层负责决定什么时候带上记忆、把哪些上下文拼进当前问题。记忆模块负责真正管理短期记忆和长期记忆的生成、压缩、读取、更新。
2. 会话状态持久化
每次运行都会对应一个 conversation_run,里面会记录:
- 当前状态:
running / waiting_user / completed / failed - 当前阶段:例如
analyzing / web_research / integration - 原始问题
- 待补充问题
- 最近答案快照
- 上次心跳时间
这样系统就不只是"跑完就算",而是把一次长任务抽象成一个可以查询、恢复、追踪的运行实体。
3. 过程步骤记录
除了 run 级别的状态,还有 step 级别的过程日志:
- 当前是谁在工作、哪一个agent在工作
- 这一步在做什么
- 是否完成 / 失败
- 工具调用和返回的细节
前端能看到的"多 Agent 协作过程",其实就是这些 step 的流式投影,而不是前端临时拼的文案。
4. 失败兜底
真实系统里,ADK 并不一定每次都能完美通过 respond 工具产出最终答案。
所以编排层还做了一层 fallback:
- 如果主路径正常完成,就走标准最终回答
- 如果主路径没有完整产出,但已有足够检索结果,就根据本地摘要、外部研究摘要和来源生成兜底回答
5. 中断恢复
当系统需要用户补充条件时,它不会简单报错,而是把运行状态切到 waiting_user,保存 checkpoint,然后向前端发一个 question 事件。
这样用户不是看到"失败",而是看到:
- 当前任务暂停了
- 为什么暂停
- 需要补充什么信息
- 补充后还能继续同一次运行
Checkpoint 是多 Agent 编排过程中用于保存中间执行状态的断点机制。当系统因用户输入信息不足而无法继续执行时,会触发中断并保存当前运行上下文,包括计划、已执行步骤、工具调用状态和消息历史等信息。待用户补充信息后,系统可基于 checkpoint 恢复原任务执行,而无需从头重新规划与检索,从而提升多轮交互的连续性与执行效率。
断线重连机制
有一个问题很现实: 如果用户在 AI 正在回答时关闭页面、刷新页面,或者网络短暂中断,之前那种纯前端内存态的实现会直接丢掉这次会话中的运行状态。
要解决这个问题,核心不是"前端记住一点文本",而是把一次回答真正建模成 可恢复的运行对象。
1. 为什么之前会丢
之前的问题本质上有两个:
- 前端聊天状态保存在
zustand内存里,页面刷新就没了 - 后端的 SSE 是一次性连接,没有"重新接回同一条运行"的协议
所以页面回来后,前端只能重新拉历史消息,但不知道:
- 当前是不是还有一个 run 在执行
- 这次执行做到哪一步了
- 现在最新答案快照是什么
- 是否还能继续接回实时流
2. 运行快照
为了解决这个问题,我把 conversation_run 扩展成了运行快照。
当前会保存:
statuscurrent_stagepending_questionlast_answerheartbeat_at
这意味着前端重新进入页面时,不需要盲猜当前状态,而是可以直接通过会话详情拿到:
- 当前有没有活跃 run
- 当前 run 是
running还是waiting_user - 当前已经生成到哪一段回答
- 当前最近的步骤列表是什么
3. 会话详情里的 active_run
现在 GET /api/chat/conversations/:id 不只返回历史消息和历史步骤,还会返回:
active_runactive_steps
其中 active_run 里会告诉前端:
- 当前运行 id
- 当前状态
- 当前阶段
- 最近答案快照
- 是否允许恢复
这样前端进入页面后就能先恢复 UI 状态,再决定是否继续发起恢复流。
4. 恢复流接口
我新增了一个接口:
POST /api/ai/chat/stream/resume
请求体会带:
conversation_idrun_id
后端收到后会做几件事:
- 校验当前 run 是否属于这个用户和这个会话
- 先推送一份当前快照
- 如果 run 还在
running,就把新连接重新挂到这个 run 的实时广播上 - 如果 run 已经是
waiting_user,就重新把补充问题发给前端 - 如果 run 已完成,就直接补发最终快照和完成事件
这里的关键点是:恢复不是重新发起一次新问题,而是重新订阅同一个运行中的对象。
5. run_hub
为了让"同一个运行可以被重新订阅",服务端增加了一个运行期广播中心 run_hub。
它不是长期存储,而是一个运行期内存中心,负责:
- 保存当前 run 的最新快照
- 维护这个 run 的订阅者
- 在
stage / step / chunk / question / done到来时同步更新快照并广播 - 在 run 结束后保留一个短暂窗口,方便页面回来时还能恢复
可以把它理解成:
- 数据库里的
conversation_run负责长期状态 run_hub负责运行期实时同步
这两层结合起来,才能同时满足"可靠落库"和"实时恢复"。
前端恢复策略
前端这边也不是简单地"掉了就重连",而是有一套状态恢复逻辑。
进入聊天页面后会做:
- 先加载会话列表
- 再加载当前会话详情
- 如果详情里有
active_run.can_resume = true - 先用
last_answer和active_steps恢复当前界面 - 再自动请求
/chat/stream/resume接回实时流
这样做的好处是:
- 页面一打开就能马上看到当前快照
- 不需要等恢复流连上之后才显示内容
- 即使恢复连接失败,用户也不会看到一片空白
另外,前端还会记住当前激活的 conversation。所以刷新页面时,不只是"重新进聊天页",而是会尽量回到刚才正在看的那条会话,并继续恢复它的运行状态。
效果展示
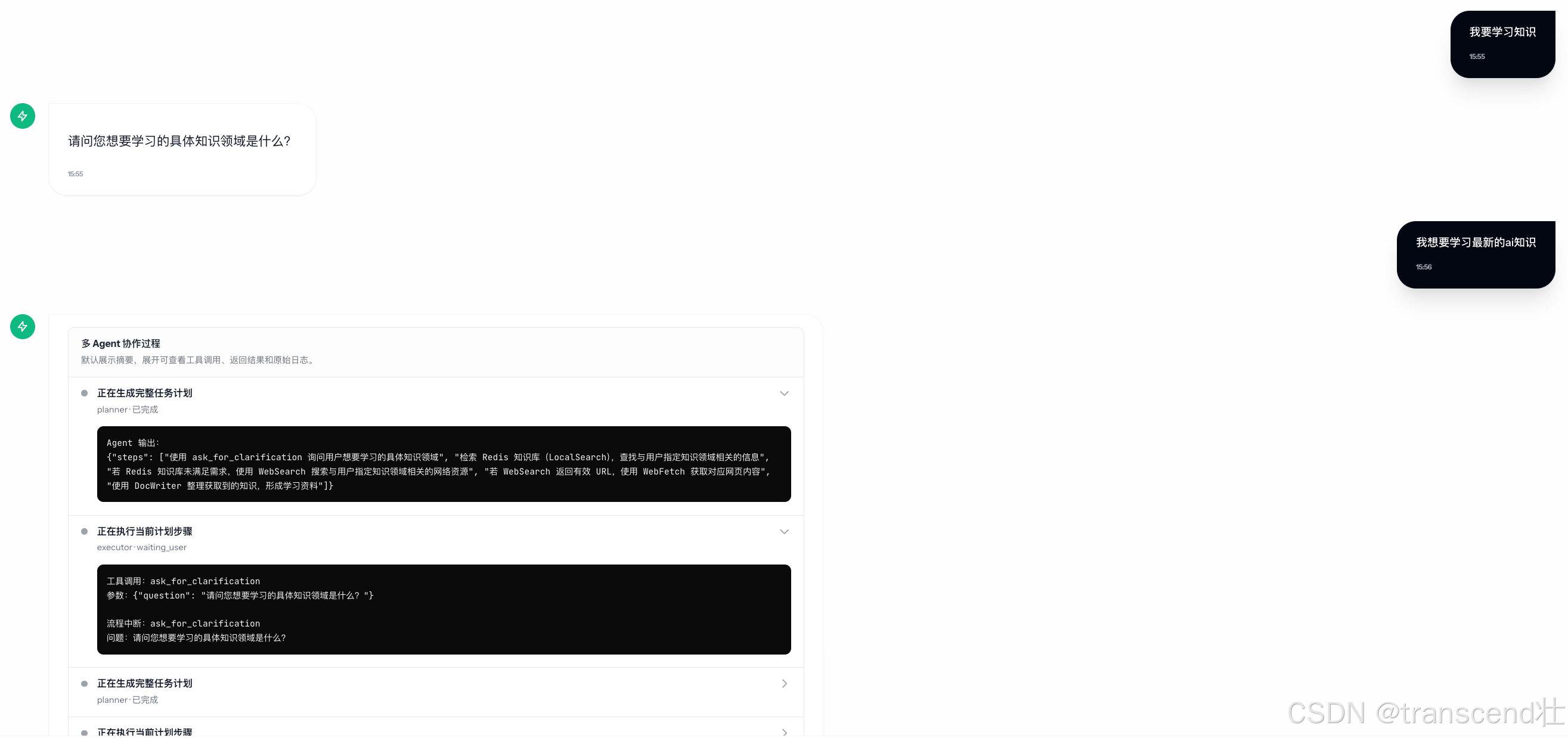
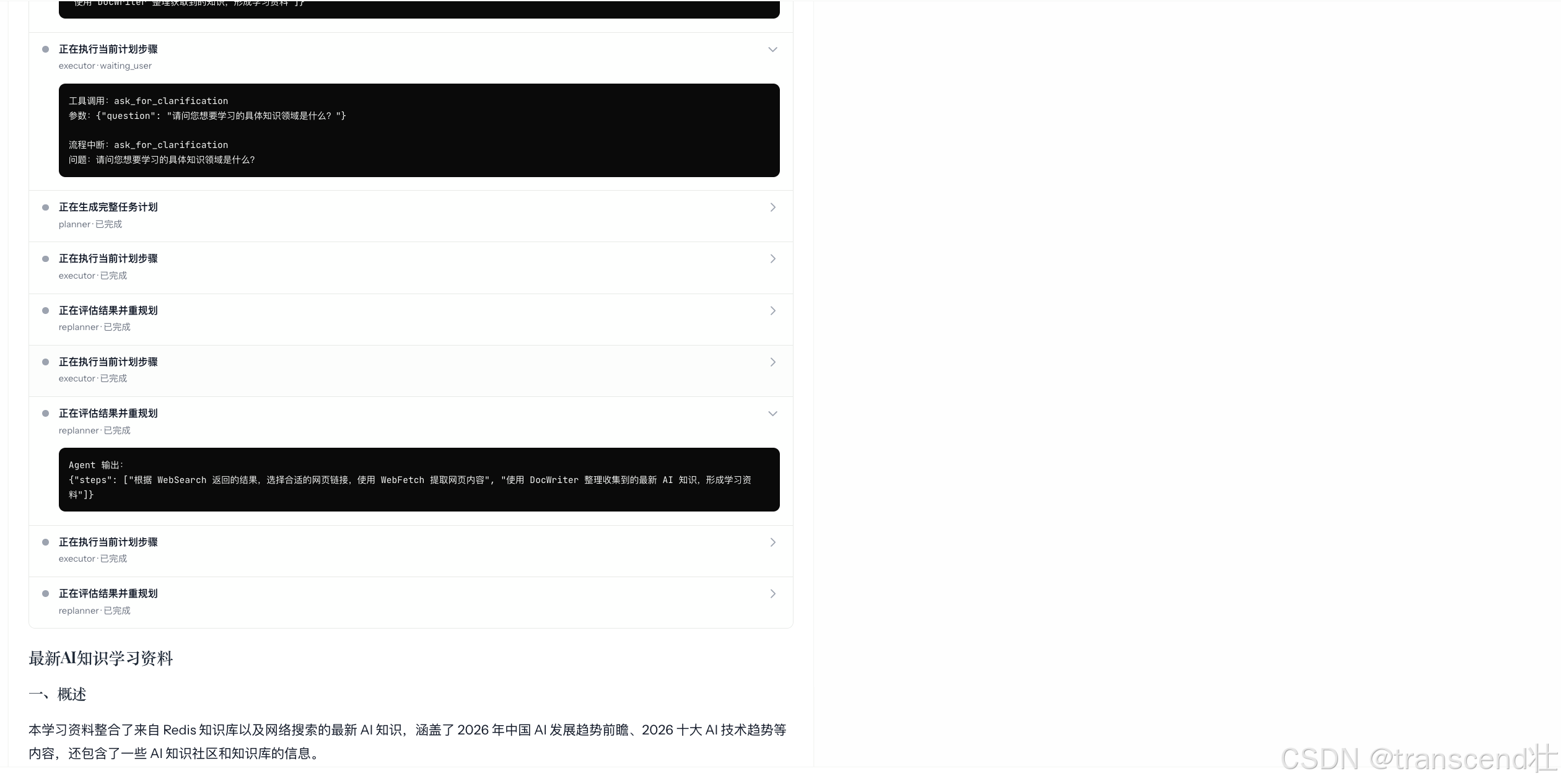
可以从展示的日志中看到详细的流程:调用了 ask_for_clarification 向用户询问不清晰的问题,以及多Agent之间的协作。

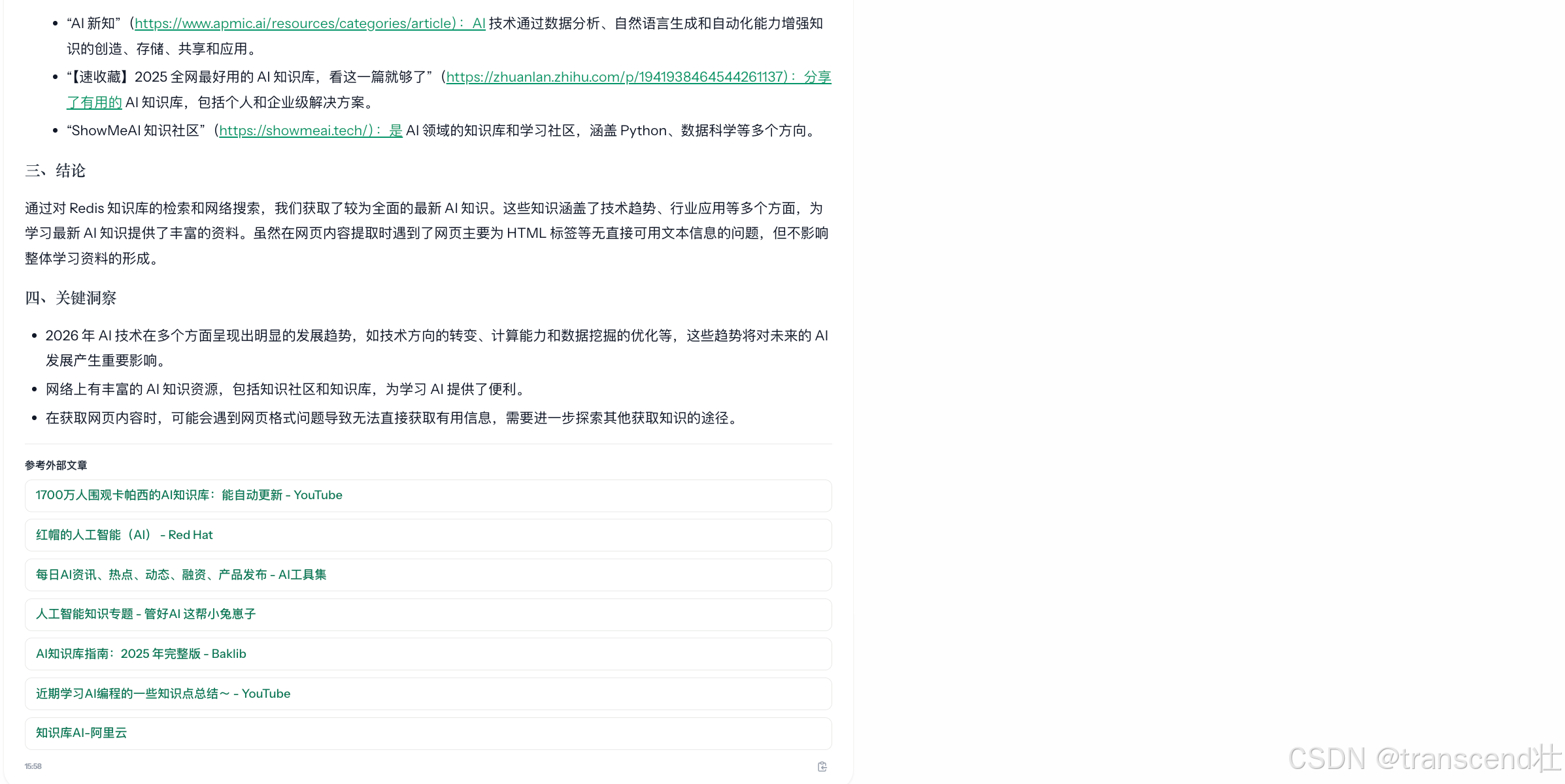
生成的回答末尾会标注参考文章的来源,确保回答是有事实可依据的,减少AI幻觉的产生。
总结
我更倾向于把 Multi-Agent 当成一个"有状态的协作系统",而不是一个"模型套模型"的技巧。
真正有价值的部分,不只是多了几个 Agent,而是这几件事一起成立:
- 主循环有清晰边界
- 能力角色有明确分工
- 编排层接住所有状态变化
- 流式链路不仅能输出,还能恢复
- 用户侧能感知系统在做什么,并且在断线后继续回来