前言
2026 年 4 月 21 日 - 23 日,全球 PostgreSQL 生态顶级技术盛会 Postgres Conference 2026 在美国硅谷圣何塞圆满举办。本届大会以 "Energizing People with Data and Creativity" 为核心主题,汇聚了全球顶尖开发者与技术实践者,共探 PostgreSQL 在 AGI 时代作为核心数据基座的演进方向。作为深耕内核创新的技术厂商,YMatrix 受邀出席并发表了两场重磅技术演讲,展示了其在超融合架构下的最新突破。
01
盛况回顾,聚焦 AGI 时代,看全球 PostgreSQL 技术的演进风向

作为全球 PostgreSQL 技术的年度"风向标",本次大会的议程设计展现了数据库技术从"传统通用"向"全能专用"转型的清晰路径。在为期三天的分享中,现场讨论的焦点高度集中在以下三个关键的技术领域:
-
数据库与 AI Agent 的原生融合: 与往年单纯讨论存储不同,今年多场深度讲座聚焦于如何利用 PostgreSQL 作为 AI 智能体(Agent)的"长短期记忆"底座。特别是关于向量数据处理(Vector Processing)与大模型协议(MCP)的结合,成为了开发者最感兴趣的热点之一。
-
极致的性能榨取与内核优化: 会场中有大量篇幅讨论了如何通过修改内核执行器、利用 SIMD 指令集等底层手段,让 PostgreSQL 突破传统的性能天花板。这种对"毫秒级延迟"和"高吞吐量"的极致追求,反映了 AGI 时代对底层数据基座的严苛要求。
-
从"静态存储"转向"动态计算": 另一大显著趋势是关于库内流处理(In-Database Streaming)的探讨。开发者们不再满足于将数据库视为一个数据"仓库",而是希望它能直接演变成一个实时计算的"工厂",在数据进入的一瞬间即完成分析与响应。
02
YMatrix两大核心技术分享,重塑 PostgreSQL 性能底座
YMatrix 在本届大会的技术分享,分别针对 PostgreSQL 的分析性能瓶颈与传统流处理架构痛点,给出了轻量化、原生融合的解决方案,为大规模数据分析与实时计算提供了全新思路。
YMatrix vector
How to implement high performance pluggable vectorized executor
针对 PostgreSQL 标准执行器在 OLAP 场景下因"一次一元组"迭代模式带来的 CPU 重复开销,YMatrix 技术专家熊灿灿详细拆解了 mxvector 向量化执行引擎。
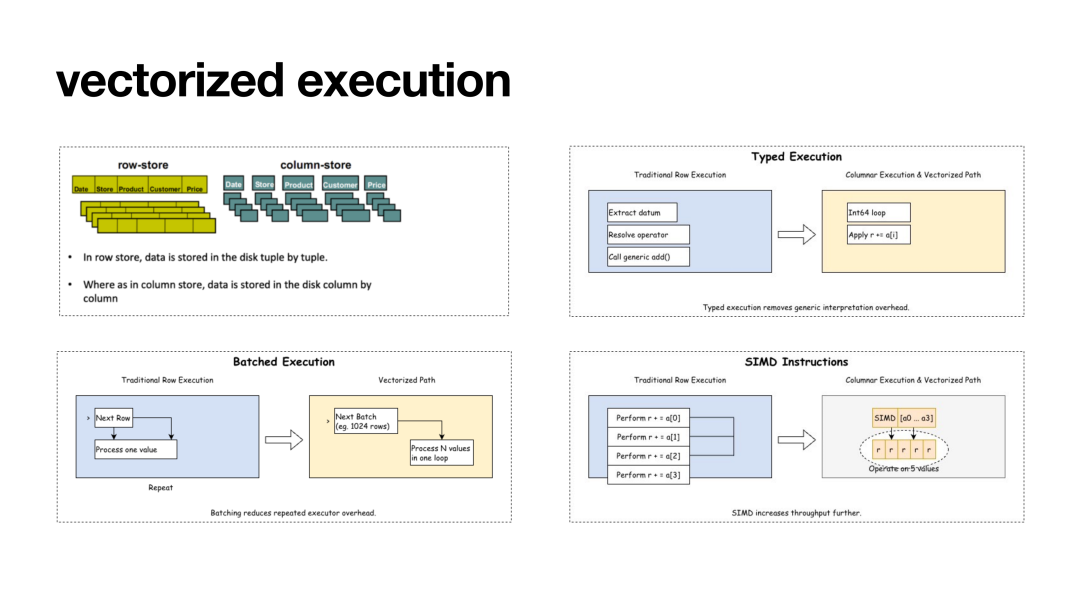
该引擎的核心在于其极致的可插拔特性:利用 PostgreSQL 原生的 Hook、Custom Scan 与 Table Access Method 等扩展机制,mxvector 实现了在不侵入内核代码的前提下,与标准执行路径的平滑共存。通过引入 VSlot 零拷贝技术将标量运算转化为批量向量化处理,并深度适配 SIMD 指令集优化,mxvector 大幅削减了函数调用与条件分支开销,使 PostgreSQL 在维持强劲 OLTP 能力的同时,具备了工业级的实时分析效能。
PostgreSQL Streaming Model: From Implicit to Explicit
How Domino Unlocks Continuous Computing
在关于流计算的分享中,YMatrix 技术专家熊灿灿深度解读了 Domino 流计算引擎。
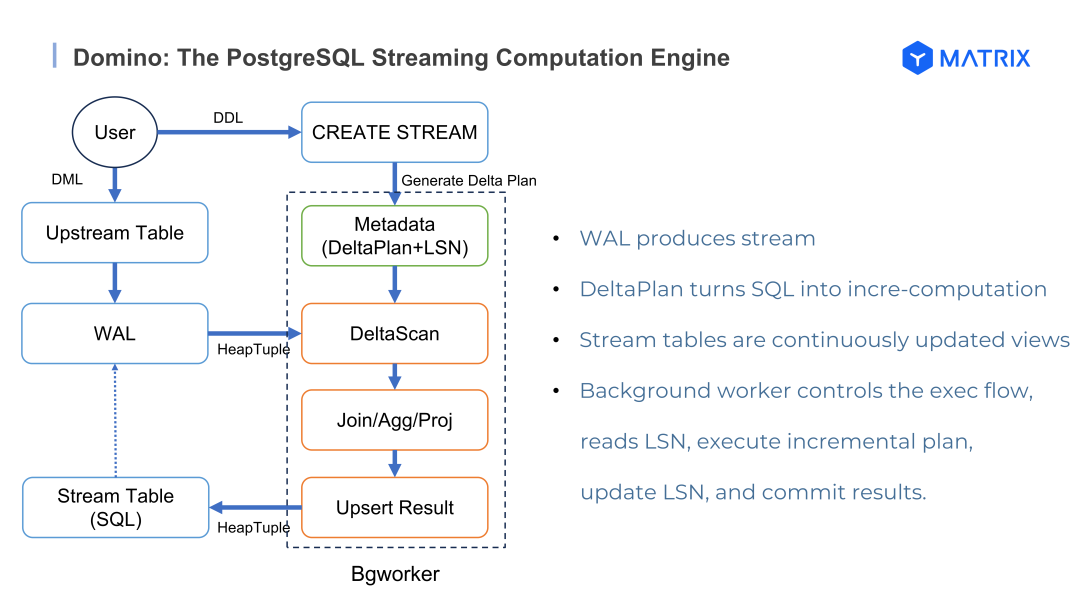
针对传统流处理链路(如 Kafka+Flink+DB)架构臃肿、数据冗余流转及维护成本高昂等痛点,YMatrix 创新的 Domino 引擎 通过充分挖掘 PostgreSQL 内核能力,实现了从"批处理"向"流式反应"模式的范式升级。
Domino 将流处理逻辑深度嵌入数据库内核,原生支持标准 SQL 扩展,在严格保证 Exactly-Once (精确一次) 一致性语义的基础上,实现极低的全链路延迟。实测中,在数亿行规模的复杂业务负载下,端到端全链路延迟低于 20 秒,性能显著优于传统方案。
03
持续深耕内核生态,赋能AI时代数据底座
本次在Postgres Conference 2026的亮相,不仅是 YMatrix 向全球展示其"超融合"技术理念的窗口,更是中国数据库创新力量与全球开源生态的一次深度共振。随着超融合架构的不断演进,PostgreSQL 正在从单一的关系型数据库演变为全能型的 AI 数据底座。
未来,YMatrix 将持续创新,推动数据库技术向更简单、更高效、更智能的方向演进。后续我们将针对 mxvector 向量化执行引擎与 Domino 流处理引擎的分享内容,分享更详尽的技术解读,欢迎持续关注YMatrix的官方动态!