最近把 OpenAI 官方的 openai-agents-python 仓库从头翻了一遍,这个库并不大,src/agents/ 里撑起整个运行时的核心文件也就几十个,但你越读越能理解:它不是一个"LLM 调用封装器",也不是又一个"Agent 框架",它更像是 OpenAI 把自己在 Swarm、Responses API、Codex、Realtime 上踩过的坑重新收敛之后,画出来的一张 Agent 系统最小闭环图。
这篇文章不打算做 API 翻译,我想回答几个更本质的问题:
- 为什么
Agent这一个 dataclass 要塞那么多字段?每个字段在解决什么控制流问题? SandboxAgent为什么要单独拉出一条继承线?它和普通Agent的边界在哪?- Handoffs 和 Agents-as-tools 看起来都是"一个 Agent 调另一个 Agent",为什么 SDK 坚持把它们分成两种原语?
- Guardrails 为什么分 input / output / tool 三层,而不是一个通用的拦截器?
- Sessions、RunState、Tracing 这三套"状态系统"各自管什么?
- Realtime Agent 为什么不能直接复用普通 Agent 的那套东西?
把这些问题串起来之后,你会发现 Agents SDK 的核心设计哲学只有一句话:
把 Agent Loop 里每一个可能出错、可能被打断、可能需要人介入的点,都显式地建成一个 SDK 原语。
其他框架通常是"少数几个抽象 + 大量 prompt 拼接",而 Agents SDK 是"原语足够多但刻意克制 + 让 Python 自己把它们组合起来"。
官方在 docs/index.md 里写得很直白:
The SDK has two driving design principles:
- Enough features to be worth using, but few enough primitives to make it quick to learn.
- Works great out of the box, but you can customize exactly what happens.
下面进入正题。
1. 核心抽象地图:Agents SDK 到底有几块
先给一张全貌图,后面每一节对应图里的一块。
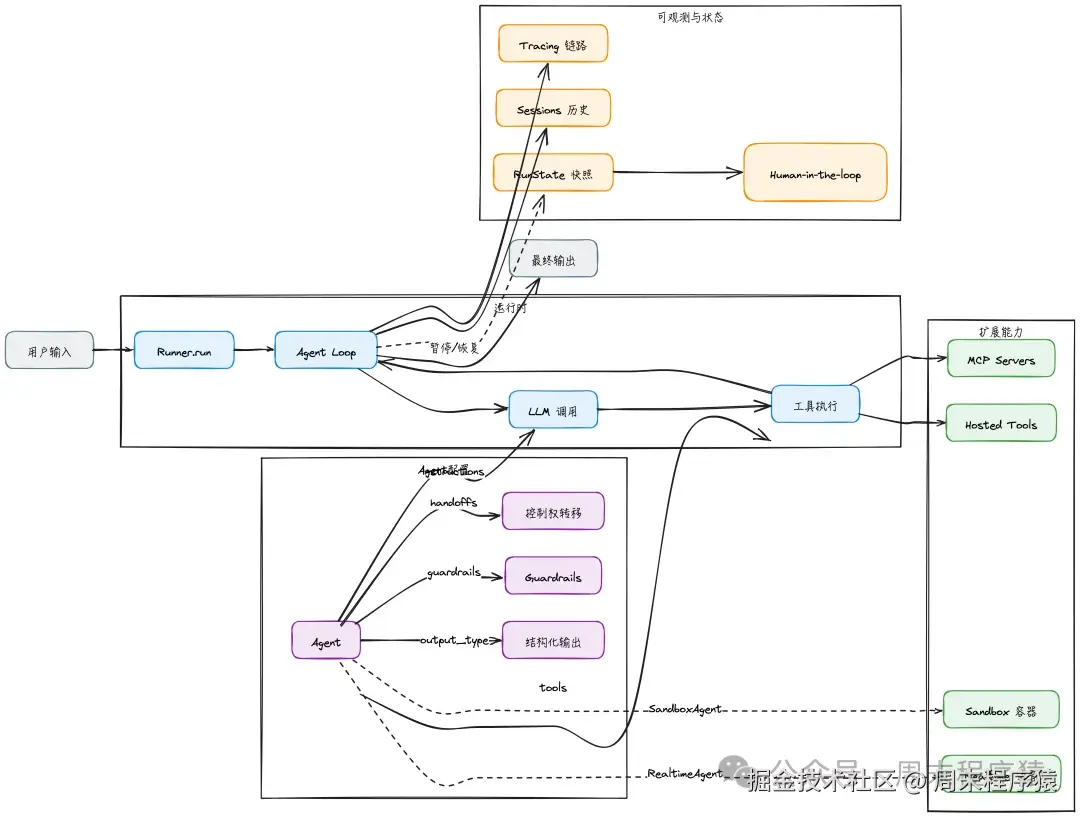
如果你之前用过 langgraph 之类的显式控制流框架,会发现 Agents SDK 走的是另一条路:它不把"节点 + 边"暴露给你写 ,而是把 Agent Loop 这个控制流当成一个黑盒内置在 Runner 里,让你通过配置 Agent 的字段和几类原语去影响它。
这是一种更偏"声明式"的风格,代价是你没法像 langgraph 那样随意重画拓扑,收益是心智负担小很多。
2. Agent:一个 dataclass 撑起整个 Loop
所有故事都从 src/agents/agent.py 里的 Agent 这个 dataclass 开始。
拆掉无关字段,它的骨架是这样的:
ini
@dataclass
class AgentBase(Generic[TContext]):
name: str
handoff_description: str | None = None
tools: list[Tool] = field(default_factory=list)
mcp_servers: list[MCPServer] = field(default_factory=list)
mcp_config: MCPConfig = field(default_factory=lambda: MCPConfig())
@dataclass
class Agent(AgentBase, Generic[TContext]):
instructions: str | Callable[..., MaybeAwaitable[str]] | None = None
prompt: Prompt | DynamicPromptFunction | None = None
handoffs: list[Agent[Any] | Handoff[TContext, Any]] = field(default_factory=list)
model: str | Model | None = None
model_settings: ModelSettings = field(default_factory=get_default_model_settings)
input_guardrails: list[InputGuardrail[TContext]] = field(default_factory=list)
output_guardrails: list[OutputGuardrail[TContext]] = field(default_factory=list)
output_type: type[Any] | AgentOutputSchemaBase | None = None
hooks: AgentHooks[TContext] | None = None
tool_use_behavior: ... = "run_llm_again"
reset_tool_choice: bool = True一个普通 Python dataclass,没有继承一堆抽象类,没有什么神秘的元类。
但这个字段清单值得逐条看,因为每个字段都在回答一个具体的控制流问题:
instructions/prompt:系统提示词。
允许传字符串也允许传函数,这样你就可以在运行时根据RunContextWrapper动态生成 system prompt。
这里区分instructions(Python 侧)和prompt(OpenAI 托管的 Prompt 对象)是刻意的------后者允许你不改代码就热更 prompt。tools+mcp_servers+mcp_config:两条工具来源。
一条是本地 Python 函数挂成的Tool,另一条是通过 MCP 协议拉过来的远端工具。
get_all_tools()会把两边合并。handoffs:能把控制权转交出去的目的地列表。
注意它是list[Agent | Handoff],不是dict------也就是说它不是"显式路由表",而是"候选专家池",路由由 LLM 自己用 function calling 决定。input_guardrails/output_guardrails/output_type:输入闸门、输出闸门、结构化输出 schema。
这三个放一起,就把 Agent 这一次调用的"形状"锁死了。tool_use_behavior:工具调用后的下一步策略。
有三种模式:-
"run_llm_again":默认,工具结果回传给 LLM 继续推理。"stop_on_first_tool":第一个工具结果直接当最终输出,不再过 LLM。StopAtTools({"stop_at_tool_names": [...]}):命中指定工具就停。- 也可以传一个函数,拿到所有工具结果后自己判断是不是收敛。
这四种模式实际上覆盖了 ReAct、Plan-and-Execute、Single-Shot-Tool 这些模式的停机条件。
把"什么时候停止 Agent Loop"从 prompt 里抠出来做成显式配置,是我觉得 Agents SDK 最务实的设计。
还有一个容易忽略的点------Agent 是泛型 Agent[TContext]。
这个 TContext 就是贯穿全链路的 RunContextWrapper.context,你的业务对象(用户 ID、租户 ID、DB 连接池)就放在这里。
它不会进 prompt,也不会被序列化进 session,但会被传到每一个工具函数、Guardrail、Handoff callback 里。
2.1 clone() 和 as_tool()
再看两个方法:
python
def clone(self, **kwargs: Any) -> Agent[TContext]:
return dataclasses.replace(self, **kwargs)clone() 就是 dataclasses.replace,浅拷贝。
文档里专门写了一句警告:tools 和 handoffs 是浅拷贝的,列表对象是新的,但里面的 tool / handoff 还是同一个引用。
想独立改,就传新的列表进去。
这种小地方能看出来维护者有工程洁癖。
as_tool() 的签名很长,关键点是它把一个 Agent 包装成一个 FunctionTool ,让它可以被挂到另一个 Agent 的 tools 里。
这就是所谓 "Agents as tools" 模式。
它和 handoffs 的本质区别我单独放一节讲。
3. SandboxAgent:把 Agent 拖进真实工作区
3.1 为什么要单独做一个 SandboxAgent
为什么还要拉一个 SandboxAgent 出来?我翻了一下 src/agents/sandbox/sandbox_agent.py:
python
@dataclass
class SandboxAgent(Agent[TContext]):
default_manifest: Manifest | None = None
base_instructions: str | Callable[...] | None = None
capabilities: Sequence[Capability] = field(default_factory=Capabilities.default)
run_as: User | str | None = None就多了四个字段,但背后的假设完全变了。
普通 Agent 的假设是:模型通过 prompt + tool call 跟世界交互 。
SandboxAgent 的假设是:模型有一个真实、持久、隔离的工作区,它能 ls、能读文件、能 apply_patch、能跑 shell,还能把状态保存下来下次接着用。
你可以把这看成是 OpenAI Codex 那套能力(代码库里有独立的 agent,可以跑编辑、执行、测试)被收进 SDK 之后的产物。
官方在 docs/sandbox_agents.md 里的一段话说得挺准:
The SDK gives you that execution harness without making you wire together file staging, filesystem tools, shell access, sandbox lifecycle, snapshots, and provider-specific glue yourself.
3.2 四个核心字段的分工
default_manifest: Manifest------声明这个沙盒初始状态里放什么。
你可以往 manifest 里塞GitRepo、LocalDir、LocalFile、Dir,runner 启动会话时会帮你把这些 entry 物化到沙盒文件系统里。
这个设计很像 Dockerfile 的COPY/ADD但更声明式。base_instructions------覆盖 SDK 默认的 sandbox 系统提示词 。
注意和instructions不同:instructions是附加的业务 prompt,base_instructions是替换 SDK 提供的沙盒基础 prompt(比如"你有 shell / apply_patch / read_file 可以用"这类),默认情况下你别碰,SDK 维护的那份已经经过反复调优了。capabilities------沙盒原生能力集合。
默认Capabilities.default()会给你一套 shell、apply_patch、文件读取等常用能力,你可以+ Skills(...)把额外的 Skill 绑进来。run_as------沙盒里以什么用户身份执行模型发起的命令。
这是权限边界的显式建模。
调用方式还是老一套 Runner.run(agent, input, run_config=...),区别是 run_config.sandbox=SandboxRunConfig(client=UnixLocalSandboxClient()) 告诉 runner:这一次要起一个沙盒会话,沙盒用的是本地 Unix。
你可以换成 Docker、换成托管方案,Agent 本身不用改。
ini
from agents import Runner
from agents.run import RunConfig
from agents.sandbox import Manifest, SandboxAgent, SandboxRunConfig
from agents.sandbox.entries import GitRepo
from agents.sandbox.sandboxes import UnixLocalSandboxClient
agent = SandboxAgent(
name="Workspace Assistant",
instructions="Inspect the sandbox workspace before answering.",
default_manifest=Manifest(
entries={"repo": GitRepo(repo="openai/openai-agents-python", ref="main")}
),
)
result = Runner.run_sync(
agent,
"Inspect the repo README and summarize what this project does.",
run_config=RunConfig(sandbox=SandboxRunConfig(client=UnixLocalSandboxClient())),
)这段代码背后发生的事情:SDK 启动一个 Unix local sandbox → 把 openai/openai-agents-python 拉到 repo/ → 把默认的 sandbox system prompt + 你的 instructions 合起来喂给模型 → 模型开始用 shell 读 README → apply_patch 或者直接回答 → 如果你配置了 SandboxRunConfig.session / session_state,这次执行的状态还能被保存、下次接着跑。
3.3 它和 Hosted Shell / CodeInterpreterTool 的区别
很多人刚看到会问:那我用 ShellTool 或者 CodeInterpreterTool 是不是就够了?我自己的判断是这样:
- 如果 shell 只是偶尔用一下的"工具之一",用
ShellTool(environment={"type": "container_auto", ...})就够,成本低、启动快。 - 如果任务本身就长在工作区里 ------跨多轮修改同一份代码、生成产物再基于产物继续推理、需要快照恢复------那就上
SandboxAgent。
换句话说,前者是"给 Agent 一把钥匙",后者是"把 Agent 关进房间里工作"。
这两个抽象并行存在,不冲突。
4. Handoffs vs Agents-as-tools:一个问题的两种答案
这是我觉得 SDK 里最容易搞混、但设计意图其实最清晰的一块。
两者都是"让一个 Agent 用上另一个 Agent 的能力",但语义完全不同:
| 维度 | Handoffs | Agents as tools |
|---|---|---|
| 本质 | 控制权转移 | 函数调用 |
| 触发形式 | 暴露成 transfer_to_<agent_name> 工具 |
暴露成一个普通 function tool |
| 转交后谁在说话 | 新 agent 接管,直接对用户输出 | 还是原 agent,拿到结果后继续自己说 |
| 新 agent 看到什么上下文 | 默认看到全部历史(可用 input_filter 过滤) |
只看到调用方构造的 input,不自动继承历史 |
| 适用场景 | 分流 / 分诊:一个总台 Agent 把工单交给专业 Agent | 主 manager 串起多个专家,自己汇总输出 |
官方在 docs/multi_agent.md 里把这两种模式叫做 "Handoffs" 和 "Agents as tools",并给出了直白的选择建议:
Use agents as tools when a specialist should help with a bounded subtask but should not take over the user-facing conversation. Use handoffs when routing itself is part of the workflow and you want the chosen specialist to own the next part of the interaction.
4.1 Handoff 的有意思细节
Handoff 的实现方式挺巧的------它在底层就是一个 function tool,工具名默认叫 transfer_to_<agent_name>。
LLM 通过 function calling 来"选择"要 handoff 到谁。
这样就不需要单独发明一套 routing 语法,复用 function calling 就完了。
另外有几个细节值得拎出来:
input_type:让 LLM 在 handoff 时同时生成一段结构化 metadata,比如{"reason": "duplicate_charge", "priority": "high"}。
这不是"换 agent 时带的消息",而是"为什么换"。
这个信息会进on_handoffcallback,你可以拿去写日志、发告警、预取数据。input_filter:允许你改写交给新 agent 的历史。
SDK 内置的handoff_filters.remove_all_tools是最常用的一个,把之前的工具调用链剥掉,只留对话历史。
因为专家 agent 通常不关心前面分诊 agent 用过什么工具。nest_handoff_history(beta):这是一个挺新的能力。
开启后,SDK 会把前面整段对话压缩成一条 assistant summary,用<CONVERSATION HISTORY>包起来再给新 agent。
一轮 handoff 追加一段。
这种嵌套摘要对于多级分诊场景特别有用,否则每次 handoff 后半程都背着越来越长的前情。is_enabled:可以传 bool 或者函数,运行时动态决定某个 handoff 要不要出现在工具列表里。
鉴权、AB 实验都可以挂这里。
4.2 Agents-as-tools 的隐藏能力
Agent.as_tool(...) 这个方法签名长得吓人,但有几个参数你用过一次就离不开:
parameters:传一个 dataclass 或 pydantic Model,这样 LLM 调这个"agent 工具"时生成的是严格的结构化输入,而不是自由文本。
对于子任务参数明确的场景(比如"给我查一下 SKU=... 的库存")比让模型自由组 prompt 靠谱得多。input_builder:你自己拿到结构化参数后,再决定怎么拼成给子 agent 的 prompt。
SDK 不替你猜。custom_output_extractor:子 agent 跑完以后,默认拿final_output当工具返回值。
你可以自己写一个 extractor,比如只抽最后一条 assistant message。needs_approval:这个子 agent 的调用要不要走 HITL 审批流。
和下面要讲的人机回路是一套东西。on_stream:如果子 agent 开了 streaming,你可以拿到它的stream_events。
外层 runner 流式输出时,嵌套 agent 的增量也能透出来。
一句话总结:Handoffs 把模型放出去,Agents-as-tools 把模型包进来 。
真实系统里两者会同时出现。
一个 triage agent handoff 到 refund agent,refund agent 再用一个 pricing agent 的 as_tool 去算折扣。
5. Tools:函数、MCP、托管------三条路汇成一个 Tool
docs/tools.md 里列了五类工具,但本质上可以收敛成三条路径:
- Function tools :Python 函数挂成工具。
@function_tool装饰器自动从函数签名 + docstring 生成 JSON Schema,用 pydantic 做入参校验。
这条路最常用。 - Hosted tools :跑在 OpenAI 那边的工具,比如
WebSearchTool、FileSearchTool、CodeInterpreterTool、HostedMCPTool、ImageGenerationTool、ToolSearchTool。
你的代码不用出力,请求直接由 Responses API 代为执行。 - MCP servers :挂在
Agent.mcp_servers列表里,每次 run 开始时 SDK 会去list_tools()合并进最终工具集。
支持 stdio、HTTP+SSE、Streamable HTTP 三种 transport。
get_all_tools() 的实现值得瞄一眼:
python
async def get_all_tools(self, run_context: RunContextWrapper[TContext]) -> list[Tool]:
mcp_tools = await self.get_mcp_tools(run_context)
asyncdef _check_tool_enabled(tool: Tool) -> bool:
ifnot isinstance(tool, FunctionTool):
returnTrue
attr = tool.is_enabled
if isinstance(attr, bool):
return attr
res = attr(run_context, self)
if inspect.isawaitable(res):
return bool(await res)
return bool(res)
results = await asyncio.gather(*(_check_tool_enabled(t) for t in self.tools))
enabled: list[Tool] = [t for t, ok in zip(self.tools, results, strict=False) if ok]
all_tools: list[Tool] = prune_orphaned_tool_search_tools([*mcp_tools, *enabled])
return all_tools注意几个点:
- MCP tools 和本地 tools 合并。
模型拿到的是一个统一的工具集,它分不清也不用分清这个工具是本地函数还是远程 MCP。 is_enabled支持动态判断,每次 run 都会重新评估。
做 feature flag 很方便。prune_orphaned_tool_search_tools会把没配套的ToolSearchTool清掉------这是新的"按需加载工具"机制,后面单独讲。
5.1 新特性:Hosted Tool Search
这个东西在 docs/tools.md 里叫 "Hosted tool search",是 OpenAI Responses API 提供的新能力,用来解决"工具太多,schema token 炸了"的问题。
核心思路:
ini
from agents import Agent, Runner, ToolSearchTool, function_tool, tool_namespace
@function_tool(defer_loading=True)
def get_customer_profile(customer_id: str) -> str: ...
@function_tool(defer_loading=True)
def list_open_orders(customer_id: str) -> str: ...
crm_tools = tool_namespace(
name="crm",
description="CRM tools for customer lookups.",
tools=[get_customer_profile, list_open_orders],
)
agent = Agent(
name="Operations assistant",
model="gpt-5.5",
instructions="Load the crm namespace before using CRM tools.",
tools=[*crm_tools, ToolSearchTool()],
)defer_loading=True 的工具默认不会把完整 schema 喂给模型,模型要用的时候通过 ToolSearchTool() 按需加载一个 namespace。
这个设计对"工具很多但每次只用少数几个"的 agent 很友好------比如运维机器人可能有 200 个工具,但一次对话里只涉及 5 个,没必要把 200 个 schema 全塞进 context。
这个能力目前只在 OpenAI Responses 模型上支持,要 openai>=2.25.0。
属于"新设计理念"的一部分:工具集本身变成了可动态加载的东西,而不是启动时就全部暴露。
5.2 MCP 是"AI 世界的 USB-C"
MCP(Model Context Protocol)这块值得单独一段,docs/mcp.md 里列了四种集成方式:
- Hosted MCP tools :
HostedMCPTool(tool_config={...}),整个 MCP 往返在 OpenAI 那边完成,你的 Python 进程都不用参与。 - Streamable HTTP :
MCPServerStreamableHttp,你自己启服务器(本地或远程),SDK 管连接。 - HTTP+SSE :
MCPServerSse,遗留方案,MCP 社区已经 deprecate,新集成别用。 - stdio :
MCPServerStdio,把 MCP server 当子进程起,走 stdin/stdout。
然后再加上 MCPServerManager 去管多台服务器的连接生命周期(自动重连、失败隔离、并发连接),一整套拼出来就是一个"通用外部工具接入层"。
对比一下:没有 MCP 之前,你接一个外部数据源得自己写 function tool;有了 MCP 之后,只要对方暴露了 MCP 接口,你 mcp_servers=[server] 挂上去就行,工具、提示词模板、资源都自动接入。
MCP 于 Agent,相当于 LSP 于 IDE。
它不解决"这个 agent 聪不聪明"的问题,而是解决"这个 agent 能不能跟别的系统对话"的问题。
6. Guardrails:输入、输出、工具三层闸门
docs/guardrails.md 里把 guardrail 分成三类,边界划得挺清楚:
- Input guardrail :跑在整条链路的第一个 agent 上。
- Output guardrail :跑在整条链路最后那个产出最终输出的 agent 上。
- Tool guardrail:每次 function tool 被调用时都会跑,分 input(调用前)和 output(调用后)两种。
为什么这么切?因为不同的风险在不同的位置。
"别让用户让我做数学作业"这种规则写在 input guardrail 里最高效------还没烧一个 token 就能拦掉。
"模型别把身份证号吐出去"这种规则写在 output guardrail 里最合适------只有最终输出才是真正发出去的东西。
而"调 delete_file 前得检查一下路径别是 /"这种规则就必须写在 tool guardrail 里,否则 agent 链路任何一环只要用了这个工具你都得防一手。
6.1 Tripwire 和 Execution Mode
Guardrail 的关键概念是 tripwire------触发了就立刻抛异常,停掉整个 run:
python
@input_guardrail
async def math_guardrail(
ctx: RunContextWrapper[None], agent: Agent, input: str | list[TResponseInputItem]
) -> GuardrailFunctionOutput:
result = await Runner.run(guardrail_agent, input, context=ctx.context)
return GuardrailFunctionOutput(
output_info=result.final_output,
tripwire_triggered=result.final_output.is_math_homework,
)这里有个很实用的新设计:run_in_parallel 参数。
默认 True,guardrail 和主 agent 并行启动,延迟最低,但代价是如果 guardrail 触发的时候主 agent 可能已经消耗了 token。
设 False 变成 blocking,guardrail 通过了主 agent 才开跑,延迟略高但安全。
工程上这就是典型的 安全-延迟 tradeoff ,SDK 把选择权留给了你。
默认给的是"低延迟 + 并行"的版本,因为对绝大多数轻量 guardrail 来说,代价可以忽略。
6.2 Tool Guardrail 才是真正的新花样
less
@tool_input_guardrail
def block_secrets(data):
args = json.loads(data.context.tool_arguments or "{}")
if "sk-" in json.dumps(args):
return ToolGuardrailFunctionOutput.reject_content(
"Remove secrets before calling this tool."
)
return ToolGuardrailFunctionOutput.allow()
@function_tool(tool_input_guardrails=[block_secrets])
def classify_text(text: str) -> str: ...它跟 input/output guardrail 不一样的地方在于:它挂在工具上 ,而不是挂在 agent 上。
这意味着无论哪个 agent(handoff 目标、嵌套 as_tool)调了这个工具,这个 guardrail 都会生效。
这解决了一个实际问题------当你有十几个 agent 共享同一批工具,你不想把同一份 guardrail 在十几个 agent 上贴十几遍。
另外它的返回值不止 allow / reject,还有 reject_content(...) 这种"把工具结果替换成一段消息"的模式。
你完全可以把敏感信息 redact 掉再让 agent 继续跑,而不是简单粗暴地掐掉整个 run。
7. Human-in-the-loop:pause / approve / resume 才是正确姿势
Agent 最危险的地方不是"答错题",而是"答对题但走错流程"。
比如 refund agent 决定要退一笔 10 万块的钱,你总得有个地方能截住。
Agents SDK 的 HITL 设计有几个关键点,我对着 docs/human_in_the_loop.md 梳理一下:
-
在工具层面标注
needs_approval:python@function_tool(needs_approval=True) async def cancel_order(order_id: int) -> str: ...或者传一个异步函数,根据参数动态判断这次要不要审批。
-
run 暂停,而不是阻塞 。
Agent Loop 走到需要审批的工具调用时,不会 block,也不会抛异常,而是把这一次 run 挂起 ,把未解决的审批项挂在
RunResult.interruptions里。 -
用
RunState把状态序列化出去 。这是 Agents SDK 里我个人觉得最扎实的一块:
ini
state = result.to_state()
STATE_PATH.write_text(state.to_string())
# ... 几小时后,可能换了一台机器
stored = json.loads(STATE_PATH.read_text())
state = await RunState.from_json(agent, stored)
state.approve(interruption)
result = await Runner.run(agent, state)RunState 不只是保存了 messages,还包括 approvals、usage、tool_input、nested agent-as-tool 的 resumption 点、trace metadata、server-managed conversation settings。
官方 doc 里用了 "durable" 这个词,确实没毛病------你可以把 state 塞进数据库 / 队列,一周之后捞出来继续跑。
- 粘性决策 sticky decision 。
state.approve(interruption, always_approve=True)可以让当前 run 内以后对同一工具的调用都自动放行。
对于"我已经确认 A 工具可以随便调了"的场景很实用。 - 跨 handoff / as_tool 的 HITL 也能正常工作 。
哪怕是嵌套 agent 里的一个工具要审批,interruption 也会冒泡到最外层的 run state 上,你只需要在顶层处理就好。
这套设计的哲学挺清晰的:Agent 执行是一个可以被暂停、可以被 relocate、可以被恢复的过程,而不是一个必须跑完的事务 。
这跟传统 RPC/函数调用的模型完全不同。
对比一下其他框架:langgraph 也有 checkpoint 机制,但它更偏"保存每一步节点输出";Agents SDK 的 RunState 更偏"保存一个完整的 Agent Loop 执行快照"。
两条路都通,看你设计的 agent 是图结构还是 loop 结构。
8. Sessions:多轮对话的记忆层
Agent loop 里跑完一轮,下一轮怎么接上?Agents SDK 给了三条路(在 docs/running_agents.md 里有对比表格,这里挑重点):
- 手动
result.to_input_list():自己拿着 history 字符串/列表,下一轮再传进去。
provider-agnostic,但什么都得自己管。 session=...:用 SDK 内置的 Session 实现。
SDK 在每次 run 前session.get_items()拿历史,run 完session.add_items()存回去。- OpenAI server-managed :
conversation_id或者previous_response_id,历史存在 OpenAI 那边。
第二条是大多数人会选的,SDK 里 Session 本身是一个 Protocol:
python
class Session(Protocol):
session_id: str
session_settings: SessionSettings | None = None
async def get_items(self, limit: int | None = None) -> list[TResponseInputItem]: ...
async def add_items(self, items: list[TResponseInputItem]) -> None: ...
async def pop_item(self) -> TResponseInputItem | None: ...
async def clear_session(self) -> None: ...四个方法,没了。
实现的时候爱用 SQLite 用 SQLite,爱用 Redis 用 Redis,爱用 MongoDB 用 MongoDB。
官方已经内置了一堆:
| 实现 | 定位 |
|---|---|
SQLiteSession |
默认实现,本地开发够用 |
AsyncSQLiteSession |
用 aiosqlite 的异步版本 |
RedisSession |
多 worker 共享 |
SQLAlchemySession |
接公司已有的关系库 |
MongoDBSession |
文档库场景 |
DaprSession |
云原生 Dapr sidecar |
OpenAIConversationsSession |
存在 OpenAI 那边 |
OpenAIResponsesCompactionSession |
长对话自动压缩 |
AdvancedSQLiteSession |
带 branching / analytics |
EncryptedSession |
给任意 session 加密 + TTL |
这里有个 Compaction Session 值得单独说一下------它会在每轮结束后自动判断要不要调 Responses API 的 responses.compact 来压缩历史。
官方提到一个坑:默认情况下 compaction 会等完才让 run 结束,streaming 场景下最后的响应会"卡一下"。
所以重度流式场景建议关掉自动触发,自己在 idle 时主动 await session.run_compaction()。
8.1 为什么要有 Session 而不是直接用 conversation_id
你可能会想:既然 OpenAI 那边有 conversation_id,为啥 SDK 还自己搞一套?看看文档里怎么说的:
Sessions cannot be combined with
conversation_id,previous_response_id, orauto_previous_response_idin the same run. If you want OpenAI server-managed continuation instead, choose one of those mechanisms rather than layering a session on top.
它明确说了两条路不能混。
Session 是 client-side memory ,conversation_id 是 server-side memory 。
前者 provider-agnostic、可以自己选存储后端、可以自己做 encryption / TTL / branching;后者省事但绑定 OpenAI。
我自己的选择一般是:纯 OpenAI + 单机 = server-side,多 provider / 合规场景 = client-side session。
9. Tracing:运行追踪不是日志,是工作流的显微镜
默认情况下,你什么都不用做,整个 Runner.run(...) 就已经被 tracing 框起来了:
- 整个 run 被包在
trace()里 - 每个 agent 被包在
agent_span()里 - 每次 LLM 调用包在
generation_span()里 - 每次工具调用包在
function_span()里 - Guardrails、Handoffs、语音 STT/TTS 各自有自己的 span
docs/tracing.md 里给出了所有 span 类型,基本 cover 了 agent loop 的每个关键时刻。
你在 OpenAI 的 Traces Dashboard 能看到整个多 agent handoff 链的瀑布图。
9.1 几个容易踩的坑
- 默认是
BatchTraceProcessor,后台每几秒刷一次。
短生命周期的 worker(比如 Celery task、FastAPI background)最后要手动调flush_traces(),否则进程退出时可能还没导出。 OPENAI_AGENTS_TRACE_INCLUDE_SENSITIVE_DATA=false可以关掉 LLM input/output 和工具 input/output 的记录。
生产上如果 prompt 里带敏感信息你就得关。- 支持
add_trace_processor()加第二个导出目的地,或者set_trace_processors()完全替换默认的 OpenAI backend。
想接 Langfuse / Phoenix / Weights & Biases / Datadog 都是一行代码。 - Zero Data Retention 政策下的组织不能用默认 tracing,这个 docs 里明确写了。
9.2 为什么原生 tracing 比自己搭日志香
以前做多 agent 系统时,自己拿 OpenTelemetry 接 Jaeger 接了一套链路追踪。
能跑,但每新增一个 agent 就得记得补 span,每新增一个工具就得记得补属性。
Agents SDK 原生 tracing 的意义就在于:每个原语自带 span,你写 agent 本身就等于写可观测代码 。
这不是性能优化,是让 debug multi-agent workflow 从"读 log"升级成"读 trace"------多 agent handoff 是谁触发的、guardrail 为什么 tripwire、某个工具为什么返回了空结果,这些东西在 trace 里一眼就能看到。
10. Realtime Agents:为什么要单独拉一条继承线
src/agents/realtime/agent.py 里的 RealtimeAgent 是另一个挺有意思的设计:
python
@dataclass
class RealtimeAgent(AgentBase, Generic[TContext]):
instructions: ... = None
prompt: Prompt | None = None
handoffs: list[RealtimeAgent[Any] | Handoff[TContext, RealtimeAgent[Any]]] = ...
output_guardrails: list[OutputGuardrail[TContext]] = ...
hooks: RealtimeAgentHooks | None = None对比一下 Agent 和 RealtimeAgent,你会发现 RealtimeAgent少了一堆字段:
- 没有
model:因为一个RealtimeSession里所有 agent 共享一个 realtime 模型。 - 没有
model_settings:同理。 - 没有
output_type:realtime 不支持结构化输出,本质上它是语音/增量对话流。 - 没有
tool_use_behavior:同样由 session 统一控制。 - 没有
input_guardrails:语音输入没有"完整输入"这个概念,guardrail 模型不适用。
这种"刻意阉割"的继承线比"全都继承过来再往里塞 realtime 特殊 field"要干净得多。
一个 RealtimeAgent 知道自己的能力边界,用户也知道。
它适合的场景就一种------低延迟的服务端语音 agent :WebSocket transport、gpt-realtime-1.5、自动打断检测、SIP/电话接入。
这东西已经不是"把文本 agent 挂个 TTS"了,而是整条链路都在语音域里。
Realtime 目前还是 beta,但它的存在本身就说明一件事:Agents SDK 不打算只做"文本 agent",它想做"所有模态下的 agent 运行时"。
11. 其他值得注意的新理念
前面 10 节覆盖了核心模块。
最后再扫几个 0.14 系列新增或强化的设计点。
11.1 Provider 无关,不强绑 OpenAI
默认是 OpenAI Responses API,但 SDK 通过 extensions.models.any_llm_model.AnyLLMModel 和 litellm_model.LitellmModel 支持 100+ LLM,包括本地模型。
你换 provider 只要改 Agent(model=...),其他代码一行不动。
Tracing 也不强绑 OpenAI backend。
你可以只用 tracing 的 API key 把 trace 发到 OpenAI dashboard,LLM 本身走别的 provider。
这种"能力分离"对想用本地模型但想蹭 OpenAI observability 的场景很友好。
11.2 RunContextWrapper:类型化依赖注入
ini
agent = Agent[MyAppContext](
name="...",
tools=[my_tool], # my_tool 的签名可以是 (ctx: RunContextWrapper[MyAppContext], ...) -> ...
)
result = await Runner.run(agent, "...", context=MyAppContext(db=..., user_id=...))context 是一个泛型参数,不会进 prompt,但会被传到每个工具 / guardrail / handoff callback。
相当于一个 类型安全的依赖注入容器 。
我觉得这比 LangChain 那种把一切都塞进 dict 的风格优雅很多。
11.3 Streaming 和 Interruption 的统一
Runner.run_streamed(...) 返回 RunResultStreaming,你 async for event in result.stream_events() 拿增量。
关键点在于:streaming 和 HITL interruption 可以叠加使用 。
流式跑到一半需要审批,SDK 会让流先"正常结束",然后 result.interruptions 里挂着要解决的项。
你处理完再 Runner.run_streamed(agent, state) 继续流式输出。
对话型 UI 做这种"流到一半弹个确认对话框,点了继续"的交互就挺自然。
11.4 原语少但组合方式敞开
把前面列的所有原语放一起:Agent、SandboxAgent、RealtimeAgent、Handoff、Agent.as_tool、FunctionTool、HostedMCPTool、MCPServer、InputGuardrail、OutputGuardrail、ToolGuardrail、RunState、Session、Tracing、RunContextWrapper。
你能搭出什么?
- Manager-worker :一个
Agent+ 多个Agent.as_tool() - Triage + Specialist :一个 triage
Agent+ 多个handoffs - Parallel ensemble :
asyncio.gather同时跑多个Runner.run(...) - Verifier loop :一个生成 agent + 一个 verifier agent(as_tool),外加
tool_use_behavior的停机条件 - Long-running sandbox coding :
SandboxAgent+SandboxRunConfig.session断点续跑 - Voice frontdesk :
RealtimeAgent负责语音接待,需要专业能力时 handoff 到 textAgent - HITL 工单审批 :多个
function_tool(needs_approval=...)+RunState持久化
这里头没有"新概念",全是上面那些原语的组合。
这就是 Agents SDK 最让我舒服的地方------它让你用 Python 本身去写控制流 ,而不是学一个新的 DSL。
你想用 asyncio.gather 并发就并发,想用 while 循环就循环,想搞 pytest 单测就单测,不需要先过"框架学习曲线"这一关。
12. 一个最小可运行示例:串起所有关键原语
我拿前面讲过的概念拼一个示例,你可以当成"Agents SDK Hello World Plus":
python
import asyncio
from pydantic import BaseModel
from agents import (
Agent, Runner, SQLiteSession, function_tool,
input_guardrail, RunContextWrapper, GuardrailFunctionOutput,
InputGuardrailTripwireTriggered, handoff, trace,
)
from agents.extensions.handoff_prompt import RECOMMENDED_PROMPT_PREFIX
class AppContext(BaseModel):
user_id: str
tenant: str
class Config: arbitrary_types_allowed = True
# --- 工具:需要人工审批才能真的发邮件 ---
@function_tool(needs_approval=True)
asyncdef send_email(subject: str, body: str) -> str:
returnf"sent: {subject}"
@function_tool
asyncdef lookup_order(order_id: str) -> str:
returnf"order {order_id}: status=shipped"
# --- Input guardrail:别让 agent 被用来写数学作业 ---
class IsMathHomework(BaseModel):
is_math_homework: bool
guardrail_agent = Agent(
name="Math homework detector",
instructions="Check if the user is asking you to do their math homework.",
output_type=IsMathHomework,
)
@input_guardrail
asyncdef block_math_homework(
ctx: RunContextWrapper[AppContext], agent: Agent, input
) -> GuardrailFunctionOutput:
res = await Runner.run(guardrail_agent, input, context=ctx.context)
return GuardrailFunctionOutput(
output_info=res.final_output,
tripwire_triggered=res.final_output.is_math_homework,
)
# --- 专业 agent:退款专员 ---
refund_agent = Agent[AppContext](
name="Refund Agent",
handoff_description="Handles refund approvals and processing.",
instructions=f"{RECOMMENDED_PROMPT_PREFIX}\nProcess refund requests carefully.",
tools=[send_email],
)
# --- 入口 agent:分诊 + 自带订单查询工具 ---
triage_agent = Agent[AppContext](
name="Triage",
instructions=f"{RECOMMENDED_PROMPT_PREFIX}\nRoute the user to the right specialist. Use lookup_order when needed.",
tools=[lookup_order],
handoffs=[handoff(refund_agent)],
input_guardrails=[block_math_homework],
)
asyncdef main() -> None:
session = SQLiteSession("support_user_123")
ctx = AppContext(user_id="u_123", tenant="acme")
with trace("support_workflow"):
try:
result = await Runner.run(
triage_agent,
"Order #ORD-42 arrived damaged, I want a refund and want you to email me a confirmation.",
context=ctx,
session=session,
)
while result.interruptions:
state = result.to_state()
for interruption in result.interruptions:
# 真实环境里这里接一个审批服务 / UI
print(f"Approval needed: {interruption.name} args={interruption.arguments}")
state.approve(interruption)
result = await Runner.run(triage_agent, state, session=session)
print("Final:", result.final_output)
print("Last agent:", result.last_agent.name)
except InputGuardrailTripwireTriggered:
print("Blocked: looks like a math homework request.")
if __name__ == "__main__":
asyncio.run(main())这段代码 80 行左右,但它同时用了:
- 类型化的
RunContextWrapper[AppContext] - Session 持久化对话历史
- Input guardrail + tripwire
- Function tool +
needs_approval触发 HITL handoff()转接到专家 agentRunState暂停 → 审批 → 恢复循环- 显式
trace()把整个工作流包成一条可观测的 trace
你可以把这个例子看成 Agents SDK 的"最小完整形态"。
大多数生产 agent 系统都是这个骨架的扩充。
13. 小结:Agents SDK 真正换掉的是什么
写到这儿我想回头回答开头那个问题:OpenAI 这一版 Agents SDK 的"最新设计理念"到底是什么。
我觉得是三件事:
第一,把 Agent 从"prompt + 循环"变成"可配置的运行时对象"。 以前我们说 agent = prompt + tools,现在 agent = prompt + tools + guardrails + handoffs + output schema + tool_use_behavior + context type + hooks + session + tracing。
多出来的每一项都是在解决"只有 prompt 和 tools 时会出问题的某个场景"。
第二,把"长任务"和"人参与"做成一等公民。 SandboxAgent 解决长时间在文件系统里搞事的需求;RunState + HITL 解决中途需要暂停、审批、换机器继续跑的需求;Session 解决跨轮记忆的需求。
这些在传统 chatbot 里都是"写在业务代码里"的东西,现在是 SDK 原语。
第三,把可观测性和 provider 抽象当作底座。 Tracing 默认开、无侵入;模型层通过 Model interface 和 any_llm / LiteLLM 适配器支持 100+ provider;MCP 作为通用外部能力协议已经深入到 Agent 的 get_all_tools() 里。
整个 SDK 有一种很克制的美感:原语不多(认真数一下也就十几个),但每一个都在干实事;每一个都能单独用,也都能组合起来。
Agents SDK 不是在和 LangChain、LlamaIndex 抢 "framework" 这个位置,它更像是在定义 "Agent 运行时"这一层到底应该长什么样子。