论文基础信息
- 标题:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- 会议:ECCV 2018
- 单位:Google Inc.
- 代码:github.com/tensorflow/models/tree/master/research/deeplab
- 论文:https://arxiv.org/pdf/1802.02611.pdf
一、论文核心总览
这篇论文把空间金字塔池化和编码器-解码器结构的优势焊死在一起 ,在DeepLabv3基础上加了极简解码器,同时用深度可分离卷积把速度和精度拉满,在PASCAL VOC 2012和Cityscapes两个数据集刷到SOTA,是语义分割领域兼顾精度与速度的里程碑工作。
一句话总结:DeepLabv3+ = 超强编码器(DeepLabv3+ASPP)+ 极简高效解码器 + 深度可分离空洞卷积。
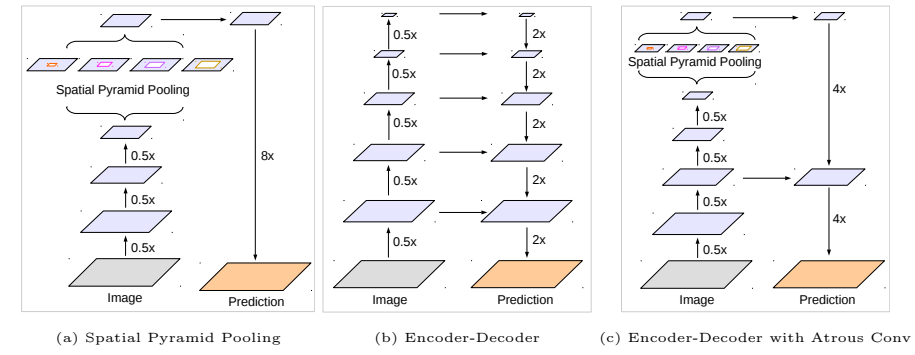
图 1.我们对 DeepLabv3 进行了改进,该模型采用了空间金字塔池化模块(a)以及编码器-解码器结构(b)。所提出的模型 DeepLabv3+ 从编码器模块中获取了丰富的语义信息,而详细的对象边界则通过简单但有效的解码器模块得以恢复。编码器模块允许我们通过应用空洞卷积在任意分辨率下提取特征。
二、核心创新点(人话版)
- 结构融合:把DeepLabv3的多尺度上下文捕获能力,和编码器-解码器的边界恢复能力结合
- 灵活分辨率:用空洞卷积任意控制编码器特征密度,平衡精度和算力
- 轻量化升级:改造Xception backbone,全链路用深度可分离卷积,更快更强
- 边界优化:专用解码器专门修复物体边缘,分割边界更锐利
三、核心技术详解(带公式+通俗解释)
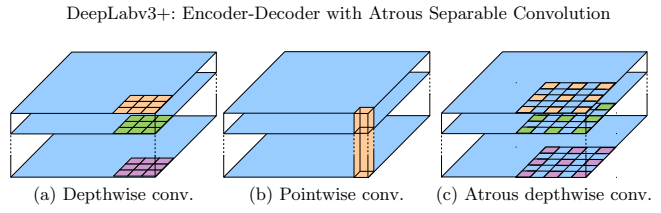
图 2. 3×3 深度分离卷积将标准卷积分解为(a)深度卷积(针对每个输入通道应用单一滤波器)和(b)点卷积(将深度卷积在不同通道中的输出进行组合)。在本研究中,我们探讨了空洞分离卷积,其中在深度卷积中采用了空洞卷积,如图(c)所示,其采样率为 2。
1. 空洞卷积(Atrous Convolution)
论文核心公式(公式1):
yi=∑kxi+r⋅kwkyi = \sum_k xi + r \\cdot kwkyi=k∑xi+r⋅kwk
字母逐词解释
- yiyiyi:输出特征图第iii个位置的像素值
- xxx:输入特征图
- rrr:空洞率(atrous rate),控制卷积核的孔洞大小,越大感受野越大
- kkk:卷积核内部元素的索引
- wkwkwk:卷积核第kkk个位置的权重参数
通俗解释
普通卷积是密集采样,空洞卷积就是在卷积核里插r−1r-1r−1个0,不增加参数就能扩大感受野,还能保持特征分辨率,解决分割任务下小物体丢失、边缘模糊的问题。
2. 深度可分离空洞卷积(Atrous Separable Convolution)
把标准卷积拆成两步:
- 深度卷积:每个通道单独卷积,不跨通道混合
- 逐点卷积 :1×1卷积融合通道信息
再把空洞卷积嵌入深度卷积,计算量砍半,精度不降反升。
通俗解释
相当于把卷积的「空间滤波」和「通道融合」分开做,再加上空洞扩大感受野,轻量+大感受野一举两得。
3. 编码器-解码器整体结构
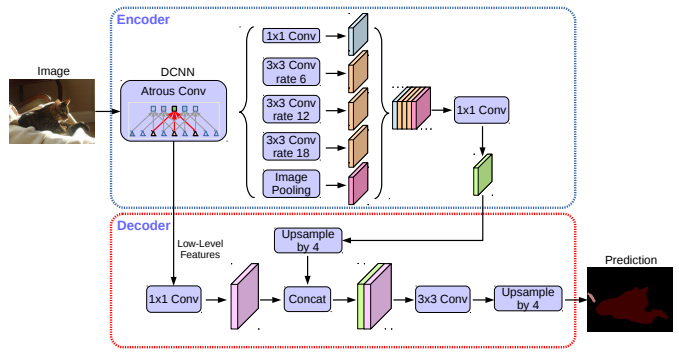
图 3. 我们提出的 DeepLabv3+ 通过采用编码器-解码器结构对 DeepLabv3 进行了扩展。编码器模块通过在多个尺度上应用空洞卷积来编码多尺度的上下文信息,而简单的但有效的解码器模块则沿着对象边界对分割结果进行细化。
结构拆解
- 编码器:DeepLabv3 backbone + ASPP模块,捕获多尺度语义信息
- 解码器 :
- 编码器输出上采样4倍
- 拼接主干网低层细粒度特征
- 两层3×3卷积细化特征
- 再上采样4倍得到最终分割图
通俗解释
编码器负责「看懂这是什么」,解码器负责「把边缘画精准」,两者结合既懂语义又抠细节。
4. ASPP模块(空洞空间金字塔池化)
并行4路不同空洞率的3×3卷积 + 1路全局池化,同时捕获小、中、大、全局尺度的上下文,解决多尺度物体分割难题。
5. Modified Aligned Xception
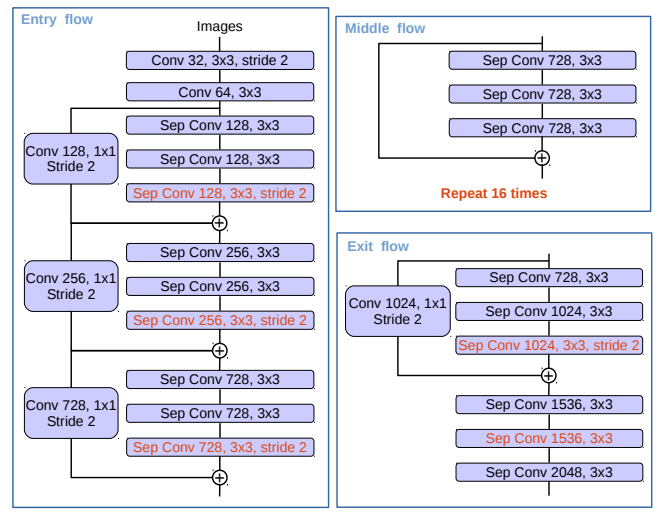
图 4. 我们对 Xception 进行了如下修改:(1)增加层数(与 MSRA 的修改相同,但入口流程有所变化),(2)将所有的最大池化操作替换为具有步长的深度可分离卷积,(3)在每个 3×3 深度卷积之后添加额外的批量归一化和 ReLU 操作,类似于 MobileNet。
论文对Xception做了3点改造:
- 加深网络,保留Entry Flow结构保证速度
- 最大池化全部替换为带步幅的深度可分离卷积
- 每个3×3深度卷积后加BN和ReLU
通俗解释
把Xception改成全卷积、可空洞、更稳定的分割专用backbone。
四、实验结果与分析(带表格+解读)
实验表格总览
出处:DeepLabv3+论文表1、表2、表6
1. 解码器1×1卷积通道数实验(表1)
| Channels | 8 | 16 | 32 | 48 | 64 |
|---|---|---|---|---|---|
| mIOU | 77.61% | 77.92% | 78.16% | 78.21% | 77.94% |
分析
- 通道数48时mIOU达到峰值78.21%
- 通道太少特征不足,太多引入冗余噪声
- 论文最终选用48通道作为低层特征压缩维度
2. 解码器结构设计实验(表2)
| 结构方案 | mIOU |
|---|---|
| 两层3×3卷积(256通道) | 78.85% |
| 一层3×3卷积 | 78.21% |
| 三层3×3卷积 | 78.02% |
分析
- 两层3×3卷积效果最优,过多卷积导致过拟合
- 仅用Conv2低层特征比叠加Conv3更高效
- 证明论文解码器简单但极其有效
3. SOTA对比实验(表6)
| 模型 | mIOU |
|---|---|
| DeepLabv3 | 85.7% |
| DeepLabv3+(Xception) | 87.8% |
| DeepLabv3+(Xception-JFT) | 89.0% |
分析
- 相比DeepLabv3提升3.3%
- 加入JFT预训练再提1.2%
- 无任何后处理刷到VOC 2012测试集89.0%,登顶SOTA
4. 边界精度实验
论文用trimap实验验证边界效果:
- 窄边界区域mIOU提升4.8%~5.4%
- 解码器对边缘细节的修复能力显著优于单纯双线性上采样
五、核心代码实现(TensorFlow2)
python
import tensorflow as tf
from tensorflow.keras import layers, Model
# 空洞卷积(论文核心算子)
def atrous_conv2d(x, filters, kernel_size, rate=1, **kwargs):
"""
空洞卷积:扩大感受野,不损失分辨率
:param rate: 空洞率r,对应论文公式中的r
"""
return layers.Conv2D(
filters, kernel_size,
dilation_rate=rate,
padding='same',
**kwargs
)(x)
# 深度可分离空洞卷积(DeepLabv3+专属)
def atrous_sep_conv2d(x, filters, kernel_size, rate=1, **kwargs):
x = layers.DepthwiseConv2D(
kernel_size, padding='same',
dilation_rate=rate, **kwargs
)(x)
x = layers.Conv2D(filters, 1, padding='same')(x)
return x
# ASPP模块(空洞空间金字塔池化)
def ASPP(x, output_stride=16):
shape = x.shape.as_list()
conv1x1 = layers.Conv2D(256, 1, padding='same')(x)
rate = 6 if output_stride == 16 else 12
conv3x3_r6 = atrous_sep_conv2d(x, 256, 3, rate=rate)
conv3x3_r12 = atrous_sep_conv2d(x, 256, 3, rate=rate*2)
conv3x3_r18 = atrous_sep_conv2d(x, 256, 3, rate=rate*3)
# 图像级全局特征
image_pool = layers.GlobalAveragePooling2D()(x)
image_pool = layers.Reshape((1, 1, shape[-1]))(image_pool)
image_pool = layers.Conv2D(256, 1, padding='same')(image_pool)
image_pool = layers.UpSampling2D((shape[1], shape[2]))(image_pool)
# 拼接融合
x = layers.Concatenate()([conv1x1, conv3x3_r6, conv3x3_r12, conv3x3_r18, image_pool])
x = layers.Conv2D(256, 1, padding='same')(x)
return x
# 解码器模块(论文核心创新)
def decoder_module(encoder_out, low_level_features):
# 4倍上采样
x = layers.UpSampling2D((4, 4))(encoder_out)
# 低层特征通道压缩
low_level_features = layers.Conv2D(48, 1, padding='same')(low_level_features)
# 特征拼接
x = layers.Concatenate()([x, low_level_features])
# 边界细化
x = atrous_sep_conv2d(x, 256, 3)
x = atrous_sep_conv2d(x, 256, 3)
# 最终4倍上采样
x = layers.UpSampling2D((4, 4))(x)
return x
# DeepLabv3+完整模型
def DeepLabv3Plus(input_shape=(512,512,3), num_classes=21):
inputs = layers.Input(input_shape)
# 加载ResNet101 backbone
backbone = tf.keras.applications.ResNet101(
weights='imagenet', include_top=False, input_tensor=inputs
)
low_level_features = backbone.get_layer('conv2_block3_out').output
# 编码器
encoder_out = ASPP(backbone.output)
# 解码器
decoder_out = decoder_module(encoder_out, low_level_features)
# 像素分类
outputs = layers.Conv2D(num_classes, 1, activation='softmax')(decoder_out)
return Model(inputs, outputs)完整可运行代码:sandbox://tos-cn-i-ik7evvg4ik/ci/38422596160947970_1776741507562/deeplabv3+_core_code.py
六、全文精读总结
1. 核心贡献
- 提出编码器-解码器+ASPP的混合结构,兼顾上下文与边界
- 设计极简高效解码器,专门修复分割边缘
- 改造Xception+深度可分离空洞卷积,实现速度精度双提升
- 在两大分割数据集刷到SOTA,无后处理VOC 2012达89.0%
2. 适用场景
- 城市景观分割(Cityscapes)
- 通用物体语义分割(PASCAL VOC)
- 移动端/边缘端部署(轻量化优势)
3. 行业影响
DeepLabv3+成为工业界最常用的语义分割基线模型,后续大量分割算法都基于它改进,是从学术到落地的经典之作。