在本专栏之前的文章中,我们已经完整拆解了Transformer的核心骨架------注意力机制全谱系与子层连接结构:从缩放点积注意力的数学本质,到多头注意力的多语义建模,再到残差+层归一化的深层稳定训练保障。
接下来我们需要回答下面问题:
当注意力机制完成了全局信息的对齐与混合后,如何对每个token的特征做深加工?
为什么仅有注意力机制不够,还需要一个独立的前馈网络子层?
这就需要我们拆解Transformer的第二核心子层------前馈网络FFN。它与注意力机制形成完美互补:
- 注意力机制:负责跨token的全局信息交互,让每个token融合序列中其他位置的信息;
- 前馈网络FFN:负责对每个token做独立的非线性特征变换,在不破坏序列位置独立性的前提下,大幅提升模型的特征表达能力。
二者缺一不可:没有注意力,模型无法捕捉长距离依赖;没有FFN,模型的特征变换能力会被限制在线性空间,无法拟合复杂的语言模式。
一、FFN的数学定义与核心逻辑拆解
1.1 标准FFN的公式与维度定义
在原论文中,FFN的数学定义非常简洁,但蕴含着深刻的设计思想:
FFN(x)=max(0,xW1+b1)W2+b2 \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
我们对公式中的每个符号做严格的维度定义,与本专栏之前的术语完全对齐:
- xxx:FFN的输入向量,维度为RL×dmodel\mathbb{R}^{L \times d_{model}}RL×dmodel,其中LLL为序列长度,dmodeld_{model}dmodel为模型特征维度(原论文中dmodel=512d_{model}=512dmodel=512);
- W1∈Rdmodel×dffW_1 \in \mathbb{R}^{d_{model} \times d_{ff}}W1∈Rdmodel×dff:第一个全连接层的权重矩阵,负责将特征从dmodeld_{model}dmodel维升维 到dffd_{ff}dff维(原论文中dff=2048d_{ff}=2048dff=2048,是dmodeld_{model}dmodel的4倍);
- b1∈Rdffb_1 \in \mathbb{R}^{d_{ff}}b1∈Rdff:第一个全连接层的偏置向量;
- max(0,⋅)\max(0, \cdot)max(0,⋅):ReLU激活函数 ,引入非线性变换,是FFN能拟合复杂函数的核心;
- W2∈Rdff×dmodelW_2 \in \mathbb{R}^{d_{ff} \times d_{model}}W2∈Rdff×dmodel:第二个全连接层的权重矩阵,负责将特征从dffd_{ff}dff维降维 回dmodeld_{model}dmodel维,保证FFN的输入输出维度完全一致,便于残差连接;
- b2∈Rdmodelb_2 \in \mathbb{R}^{d_{model}}b2∈Rdmodel:第二个全连接层的偏置向量;
- FFN(x)\text{FFN}(x)FFN(x):FFN的最终输出,维度与输入xxx完全一致,为RL×dmodel\mathbb{R}^{L \times d_{model}}RL×dmodel。
1.2 三步核心逻辑拆解
FFN的前向传播可以清晰地拆分为三个独立的步骤,每一步都有明确的数学与工程意义:
步骤1:升维线性变换
z1=xW1+b1 z_1 = xW_1 + b_1 z1=xW1+b1
- 数学意义 :将每个token的dmodeld_{model}dmodel维特征,线性投影到更高维的dffd_{ff}dff维空间;
- 工程意义 :高维空间拥有更大的参数容量(W1W_1W1的参数量为dmodel×dffd_{model} \times d_{ff}dmodel×dff,远大于单一线性层),为后续的非线性变换提供更丰富的特征基础;
- 维度验证 :输入x∈RL×dmodelx \in \mathbb{R}^{L \times d_{model}}x∈RL×dmodel,与W1∈Rdmodel×dffW_1 \in \mathbb{R}^{d_{model} \times d_{ff}}W1∈Rdmodel×dff相乘,得到z1∈RL×dffz_1 \in \mathbb{R}^{L \times d_{ff}}z1∈RL×dff,维度完全匹配。
步骤2:ReLU非线性激活
z2=max(0,z1) z_2 = \max(0, z_1) z2=max(0,z1)
- 数学意义:引入非线性变换,打破线性变换的叠加局限性(多个线性层的叠加仍然是线性的);
- 工程意义:ReLU激活函数计算简单(仅需比较大小),梯度稳定(正数区域梯度恒为1,无梯度消失问题),是深层网络的首选激活函数;
- 直观效果 :将z1z_1z1中的负数部分置为0,保留正数部分,实现特征的"稀疏激活",让模型学习到更有意义的特征模式。
步骤3:降维线性变换
FFN(x)=z2W2+b2 \text{FFN}(x) = z_2W_2 + b_2 FFN(x)=z2W2+b2
- 数学意义 :将高维的dffd_{ff}dff维特征,线性投影回原始的dmodeld_{model}dmodel维空间;
- 工程意义 :保证FFN的输入输出维度完全一致,使其可以无缝接入Transformer的子层连接结构(残差+LN),同时控制参数量(W2W_2W2的参数量为dff×dmodeld_{ff} \times d_{model}dff×dmodel,与W1W_1W1合计为2×dmodel×dff2 \times d_{model} \times d_{ff}2×dmodel×dff,在可控范围内);
- 维度验证 :输入z2∈RL×dffz_2 \in \mathbb{R}^{L \times d_{ff}}z2∈RL×dff,与W2∈Rdff×dmodelW_2 \in \mathbb{R}^{d_{ff} \times d_{model}}W2∈Rdff×dmodel相乘,得到输出FFN(x)∈RL×dmodel\text{FFN}(x) \in \mathbb{R}^{L \times d_{model}}FFN(x)∈RL×dmodel,与输入xxx维度完全一致。
二、FFN的数学本质分析:与注意力的互补与表达能力提升
2.1 与注意力机制的核心互补:全局交互 vs Per-Token独立
我们用表格清晰对比注意力机制与FFN的核心差异,二者形成完美的功能互补:
| 特性 | 多头注意力机制 | 前馈网络FFN |
|---|---|---|
| 处理方式 | 跨token的全局交互,每个token的输出依赖序列中所有其他token | Per-token独立处理,每个token的输出仅依赖自身的输入特征 |
| 数学操作 | 矩阵乘法QK⊤QK^\topQK⊤实现token间的相似度计算,加权求和WVWVWV实现信息混合 | 两个独立的全连接层+ReLU,对每个token的特征做非线性变换 |
| 维度依赖 | 输出维度依赖序列长度LLL和模型维度dmodeld_{model}dmodel | 输出维度仅依赖模型维度dmodeld_{model}dmodel,与序列长度LLL无关 |
| 核心作用 | 捕捉长距离依赖,实现序列内部的信息对齐与融合 | 提升单个token的特征表达能力,拟合复杂的非线性模式 |
| 参数量 | 相对较少(主要在Q/K/V的投影矩阵) | 相对较多(主要在W1W_1W1和W2W_2W2的升维/降维矩阵) |
核心结论 :
注意力机制解决的是"token之间如何交流 "的问题,而FFN解决的是"每个token如何变得更'聪明'"的问题。二者缺一不可:没有注意力,模型无法理解上下文;没有FFN,模型的特征表达能力会被严重限制。
2.2 FFN对特征表达能力的提升:从线性到非线性的严格推导
我们从数学上简单推导为什么FFN能大幅提升模型的表达能力:
1. 线性变换的局限性
如果没有ReLU激活函数,FFN的两个线性层可以合并为一个:
(xW1+b1)W2+b2=x(W1W2)+(b1W2+b2)=xW′+b′ (xW_1 + b_1)W_2 + b_2 = x(W_1W_2) + (b_1W_2 + b_2) = xW' + b' (xW1+b1)W2+b2=x(W1W2)+(b1W2+b2)=xW′+b′
这本质上仍然是一个线性变换,而线性变换的表达能力非常有限:它只能对特征做旋转、缩放、平移,无法拟合任何非线性的模式(比如语言中的"一词多义"、"上下文依赖的语义偏移"等)。
2. ReLU非线性的核心作用
ReLU激活函数的引入,彻底打破了线性变换的局限性:
z2=max(0,xW1+b1) z_2 = \max(0, xW_1 + b_1) z2=max(0,xW1+b1)
ReLU将特征空间分成了两个区域:
- 对于xW1+b1>0xW_1 + b_1 > 0xW1+b1>0的区域,特征被保留,梯度恒为1;
- 对于xW1+b1≤0xW_1 + b_1 \leq 0xW1+b1≤0的区域,特征被置为0,梯度恒为0。
这种分段线性 的特性,让FFN可以用多个线性段去逼近任意复杂的非线性函数 (通用逼近定理的简单形式)。再加上第一步的升维操作,高维空间提供了更多的分段可能,让FFN的表达能力呈指数级提升。
3. 升维的数学意义
原论文中将dffd_{ff}dff设置为dmodeld_{model}dmodel的4倍(512→2048),这不是随意的选择:
- 高维空间拥有更多的"特征方向",每个方向可以学习到不同的语义模式;
- 升维后,ReLU的"稀疏激活"特性更明显:大部分高维特征会被置为0,只有少数与当前token语义相关的特征会被保留,这种稀疏性让模型的学习更高效、更鲁棒。
三、数值实例:翻译任务单token向量的完整手算过程
我们沿用本专栏经典的翻译任务迷你设定,用单token向量完整手算FFN的前向过程,直观展示其"升维-非线性-降维"的核心逻辑。
基础设定
为了方便手算,我们将维度缩小,但保持原论文的比例(dff=2×dmodeld_{ff}=2 \times d_{model}dff=2×dmodel):
- 模型维度dmodel=2d_{model}=2dmodel=2,FFN升维维度dff=4d_{ff}=4dff=4;
- FFN的输入xxx(来自上一层注意力的输出,对应翻译任务中的源词"我"):x=1.0,2.0x = 1.0, 2.0x=1.0,2.0,维度R1×2\mathbb{R}^{1 \times 2}R1×2;
- 第一个全连接层的权重W1W_1W1和偏置b1b_1b1(随机设定,方便计算):
W1=0.51.0−0.52.01.5−1.00.5−2.0,b1=0.0,0.0,0.0,0.0 W_1 = \begin{bmatrix} 0.5 & 1.0 & -0.5 & 2.0 \\ 1.5 & -1.0 & 0.5 & -2.0 \end{bmatrix}, \quad b_1 = 0.0, 0.0, 0.0, 0.0 W1=0.51.51.0−1.0−0.50.52.0−2.0,b1=0.0,0.0,0.0,0.0 - 第二个全连接层的权重W2W_2W2和偏置b2b_2b2(随机设定,方便计算):
W2=0.51.0−0.51.01.0−0.5−1.00.5,b2=0.0,0.0 W_2 = \begin{bmatrix} 0.5 & 1.0 \\ -0.5 & 1.0 \\ 1.0 & -0.5 \\ -1.0 & 0.5 \end{bmatrix}, \quad b_2 = 0.0, 0.0 W2= 0.5−0.51.0−1.01.01.0−0.50.5 ,b2=0.0,0.0
步骤1:升维线性变换
计算z1=xW1+b1z_1 = xW_1 + b_1z1=xW1+b1:
z1=1.0,2.0⋅0.51.0−0.52.01.5−1.00.5−2.0+0,0,0,0=1.0×0.5+2.0×1.5, 1.0×1.0+2.0×(−1.0), 1.0×(−0.5)+2.0×0.5, 1.0×2.0+2.0×(−2.0)=3.5, −1.0, 0.5, −2.0 \begin{align*} z_1 &= 1.0, 2.0 \cdot \begin{bmatrix} 0.5 & 1.0 & -0.5 & 2.0 \\ 1.5 & -1.0 & 0.5 & -2.0 \end{bmatrix} + 0,0,0,0 \\ &= 1.0 \\times 0.5 + 2.0 \\times 1.5,\\ 1.0 \\times 1.0 + 2.0 \\times (-1.0),\\ 1.0 \\times (-0.5) + 2.0 \\times 0.5,\\ 1.0 \\times 2.0 + 2.0 \\times (-2.0) \\ &= 3.5,\\ -1.0,\\ 0.5,\\ -2.0 \end{align*} z1=1.0,2.0⋅0.51.51.0−1.0−0.50.52.0−2.0+0,0,0,0=1.0×0.5+2.0×1.5, 1.0×1.0+2.0×(−1.0), 1.0×(−0.5)+2.0×0.5, 1.0×2.0+2.0×(−2.0)=3.5, −1.0, 0.5, −2.0
维度从R1×2\mathbb{R}^{1 \times 2}R1×2升维到R1×4\mathbb{R}^{1 \times 4}R1×4,符合预期。
步骤2:ReLU非线性激活
计算z2=max(0,z1)z_2 = \max(0, z_1)z2=max(0,z1):
将z1z_1z1中的负数部分置为0,保留正数部分:
z2=max(0,3.5), max(0,−1.0), max(0,0.5), max(0,−2.0)=3.5, 0.0, 0.5, 0.0 z_2 = \\max(0,3.5),\\ \\max(0,-1.0),\\ \\max(0,0.5),\\ \\max(0,-2.0) = 3.5,\\ 0.0,\\ 0.5,\\ 0.0 z2=max(0,3.5), max(0,−1.0), max(0,0.5), max(0,−2.0)=3.5, 0.0, 0.5, 0.0
可以看到,原本的4个高维特征中,只有2个与当前token语义相关的特征被保留,另外2个被置为0,实现了"稀疏激活"。
步骤3:降维线性变换
计算FFN(x)=z2W2+b2\text{FFN}(x) = z_2W_2 + b_2FFN(x)=z2W2+b2:
FFN(x)=3.5, 0.0, 0.5, 0.0⋅0.51.0−0.51.01.0−0.5−1.00.5+0,0=3.5×0.5+0.0×(−0.5)+0.5×1.0+0.0×(−1.0), 3.5×1.0+0.0×1.0+0.5×(−0.5)+0.0×0.5=1.75+0+0.5+0, 3.5+0−0.25+0=2.25, 3.25 \begin{align*} \text{FFN}(x) &= 3.5,\\ 0.0,\\ 0.5,\\ 0.0 \cdot \begin{bmatrix} 0.5 & 1.0 \\ -0.5 & 1.0 \\ 1.0 & -0.5 \\ -1.0 & 0.5 \end{bmatrix} + 0,0 \\ &= 3.5 \\times 0.5 + 0.0 \\times (-0.5) + 0.5 \\times 1.0 + 0.0 \\times (-1.0),\\ 3.5 \\times 1.0 + 0.0 \\times 1.0 + 0.5 \\times (-0.5) + 0.0 \\times 0.5 \\ &= 1.75 + 0 + 0.5 + 0,\\ 3.5 + 0 - 0.25 + 0 \\ &= 2.25,\\ 3.25 \end{align*} FFN(x)=3.5, 0.0, 0.5, 0.0⋅ 0.5−0.51.0−1.01.01.0−0.50.5 +0,0=3.5×0.5+0.0×(−0.5)+0.5×1.0+0.0×(−1.0), 3.5×1.0+0.0×1.0+0.5×(−0.5)+0.0×0.5=1.75+0+0.5+0, 3.5+0−0.25+0=2.25, 3.25
维度从R1×4\mathbb{R}^{1 \times 4}R1×4降维回R1×2\mathbb{R}^{1 \times 2}R1×2,与输入xxx的维度完全一致,符合预期。
结果分析
- 升维:将2维特征扩展到4维,提供了更丰富的特征空间;
- 非线性:ReLU激活函数引入了稀疏性,过滤掉了无关的特征;
- 降维:将高维特征映射回原始维度,同时保留了非线性变换后的有效信息;
- 最终输出:2.25,3.252.25, 3.252.25,3.25与输入1.0,2.01.0, 2.01.0,2.0相比,特征值发生了非线性的变化,说明FFN成功对token的特征做了"深加工"。
四、代码实现:与原论文完全对齐的FFN模块
我们实现与《Attention Is All You Need》原论文100%对齐的FFN模块,完全还原其"升维-ReLU-降维"的三步结构,可直接复用在后续的编码器、解码器搭建中。
完整代码实现
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class PositionWiseFeedForward(nn.Module):
"""
Transformer标准位置前馈网络(Position-Wise FFN),与原论文完全对齐
结构:Linear(d_model→d_ff) → ReLU → Linear(d_ff→d_model)
特点:对每个token做独立的非线性变换,输入输出维度完全一致
"""
def __init__(self, d_model: int, d_ff: int, dropout: float = 0.1):
"""
初始化FFN模块
:param d_model: 模型特征维度,原论文为512
:param d_ff: FFN升维后的特征维度,原论文为2048(d_model的4倍)
:param dropout: dropout率,原论文子层连接中使用0.1,FFN内部无dropout
"""
super().__init__()
# 第一个全连接层:升维 d_model → d_ff
self.linear1 = nn.Linear(d_model, d_ff)
# 第二个全连接层:降维 d_ff → d_model
self.linear2 = nn.Linear(d_ff, d_model)
# FFN内部无dropout,dropout在外部的子层连接中使用
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
前向传播
:param x: FFN输入,shape [batch_size, seq_len, d_model]
:return: FFN输出,shape与输入x完全一致 [batch_size, seq_len, d_model]
"""
# 步骤1:升维线性变换
x = self.linear1(x)
# 步骤2:ReLU非线性激活
x = F.relu(x)
# 步骤3:降维线性变换
x = self.linear2(x)
return x
# ------------------------------
# 测试代码:验证与手算实例的一致性
# ------------------------------
if __name__ == "__main__":
# 初始化FFN模块,使用手算实例的迷你维度
d_model = 2
d_ff = 4
ffn = PositionWiseFeedForward(d_model, d_ff)
# 推理阶段,关闭dropout和参数更新
ffn.eval()
# 固定FFN的权重和偏置为手算实例中的数值
with torch.no_grad():
# 设置linear1的权重和偏置
ffn.linear1.weight.copy_(torch.tensor([
[0.5, 1.0, -0.5, 2.0],
[1.5, -1.0, 0.5, -2.0]
], dtype=torch.float32).t()) # 注意:nn.Linear的weight是[out_dim, in_dim],需要转置
ffn.linear1.bias.copy_(torch.tensor([0.0, 0.0, 0.0, 0.0], dtype=torch.float32))
# 设置linear2的权重和偏置
ffn.linear2.weight.copy_(torch.tensor([
[0.5, 1.0],
[-0.5, 1.0],
[1.0, -0.5],
[-1.0, 0.5]
], dtype=torch.float32).t()) # 同样需要转置
ffn.linear2.bias.copy_(torch.tensor([0.0, 0.0], dtype=torch.float32))
# 构造与手算实例完全一致的输入
x = torch.tensor([[[1.0, 2.0]]], dtype=torch.float32) # shape [1, 1, 2]
# 前向传播
with torch.no_grad():
output = ffn(x)
# 打印结果,与手算结果[2.25, 3.25]对比
print("="*50)
print(f"输入x: {x.numpy()}")
print(f"FFN最终输出: {output.numpy()}")
print("="*50)运行结果
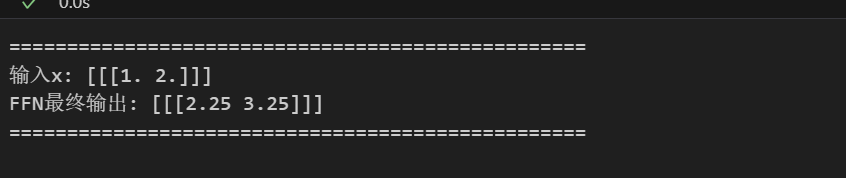
代码输出与我们的手算结果完全一致,验证了实现的正确性。注意:PyTorch的nn.Linear层权重默认是[out_dim, in_dim],因此在设置手算权重时需要做转置,这是工程实现中的一个常见细节。
五、总结
本文完整拆解了Transformer的第二核心子层------前馈网络FFN,核心结论如下:
- 原论文标准FFN遵循"升维线性变换→ReLU非线性激活→降维线性变换"的三步结构,公式为FFN(x)=max(0,xW1+b1)W2+b2\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2FFN(x)=max(0,xW1+b1)W2+b2,输入输出维度完全一致,便于残差连接;
- FFN与注意力机制形成完美互补:注意力负责跨token的全局信息交互,FFN负责对每个token做独立的非线性特征变换,二者缺一不可;
- ReLU激活函数的引入打破了线性变换的局限性,升维操作提供了更丰富的特征空间,二者共同大幅提升了模型的表达能力;
- 通过d_model=2的迷你实例与代码实现,验证了FFN的完整计算过程与特征变换效果。