Hi,大家好,欢迎来到维元码簿。
本文属于 《Claude Code 源码 Deep Dive》 系列,专注于工具系统中的 运行时流水线 板块。如果你想了解整个系列,可以先看系列开篇 | Claude Code 源码架构概览:51万行代码的模块地图。
本文聚焦一件事:从模型输出 tool_use 到结果回流------工具执行的完整链路。
读完全文,你将能回答这几个问题:
- 工具调用是怎么发起和识别的? 模型怎么"决定"要用一个工具,系统怎么从 streaming 流中识别出 tool_use block?
- 模型输出
tool_use后,到工具真正执行,中间经历了什么? 答案:一条包含 Zod 校验、Hook 系统、权限检查、并发调度的完整流水线。 - 5 个工具同时调用,为什么有的并行有的串行? 答案:StreamingToolExecutor 根据只读/写入/并发安全标注调度。
- 一个 Bash 命令出错了,其他正在跑的工具会怎样? 答案:错误级联取消,siblingAbortController 一刀切。
本篇覆盖的源码范围
| 模块 | 核心文件 | 核心代码行 | 文件总行 | 职责 |
|---|---|---|---|---|
| 执行引擎 | src/services/tools/toolExecution.ts |
L150-599(classifyToolError + buildSchemaNotSentHint + checkPermissionsAndCallTool) | 1745 行 | 完整执行流水线 |
| 并发调度 | src/services/tools/StreamingToolExecutor.ts |
L40-405(StreamingToolExecutor 类) | 530 行 | 只读并行、写入串行、错误级联 |
| Hook 执行 | src/services/tools/toolHooks.ts |
L39-435(runPostToolUseHooks → runPreToolUseHooks) | 650 行 | Pre/PostToolUse 钩子执行 |
| Hook 类型 | src/utils/hooks.ts |
L330-359(HookResult + AggregatedHookResult 类型定义) | 5022 行 | Hook 决策类型定义 |
| 消息构建 | src/utils/messages.ts |
L4288(createToolResultMessage) | 5512 行 | ToolResultBlockParam 组装 |
前情提要:从注册到运行
在姊妹篇Claude Code 深度拆解:工具系统------30+ 工具怎么统一注册、按需加载中,我们知道了工具怎么定义、怎么注册、怎么排序进入 tools[] 数组。在姊妹篇Claude Code 深度拆解:工具系统------30+ 内置工具地图与 MCP / Skills 协作中,我们知道了 30+ 工具的分类和 Tools/MCP/Skills 的协作关系。
但还有一个核心问题没回答:模型说"我要用 Bash 跑个命令"------接下来发生什么?
从模型输出了一个 tool_use block,到工具结果回流到 messages[] 数组,中间要经过 8 个步骤的流水线。这就是本文要拆解的完整链路。
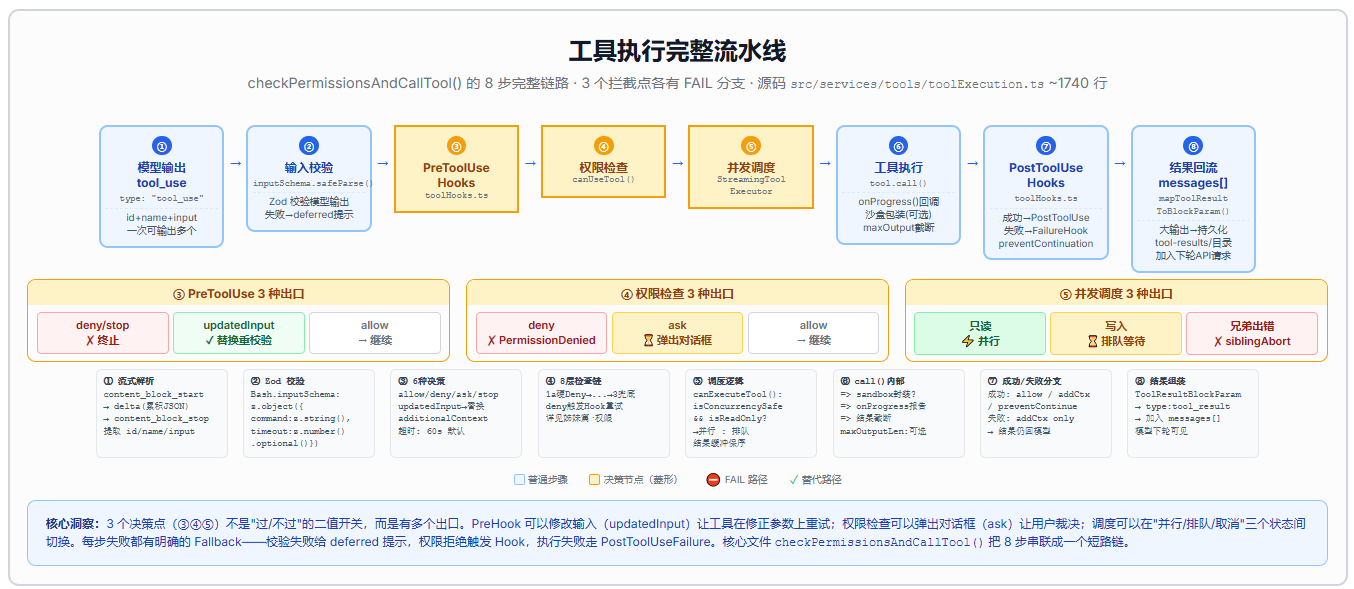
第一步:工具调用的发起------大模型怎么指挥使用工具
大模型不会"调用"工具,它只能"输出"一种特殊的数据结构------tool_use block。真正执行工具的是 Claude Code 的运行时。
理解这一点是理解整个工具执行流水线的前提。模型只是一个文本生成器,它没有能力执行任何代码、读写任何文件。它的"指挥方式"非常简单:在生成的文本中嵌入一个结构化的指令,告诉运行时"我想用这个工具,参数是这些"。运行时识别出这个指令,执行工具,然后把结果喂回给模型。
这不是 Claude Code 的发明,而是 Anthropic API 的标准协议------所有使用 tool_use 的应用都遵循同样的机制。
tool_use 的数据结构------模型输出的"指令"
Anthropic API 的响应格式中,content 字段是一个数组,数组元素可以是 text 类型(普通文本)或 tool_use 类型(工具调用指令)。当模型决定使用工具时,它不是输出一段自然语言说"请帮我执行 git status",而是输出一个结构化的 JSON block:
typescript
// ===== 模型输出的 assistant message(还原 Anthropic API 原始响应结构) =====
{
role: "assistant",
content: [
{ type: "text", text: "让我检查一下仓库状态。" }, // 普通文本
{ // ↓ 工具调用指令
type: "tool_use",
id: "toolu_01A09q90qw90lq917835lq9",
name: "Bash",
input: { command: "git status" }
}
]
}上面是我们人工整理后的结构。但如果你好奇模型实际吐出的原始 token 长什么样,它大概是这样的(简化示意):
流式 token 序列(逐 token 吐出):
content_block_start: { type: "text", index: 0 }
→ "让我检查一下仓库状态。"
content_block_stop
content_block_start: { type: "tool_use", index: 1, id: "toolu_01A09q90..." }
→ "name": "Bash"
→ "input": { "command": "git status" }
content_block_stop模型在流式输出时,先吐一个 content_block_start 事件告诉运行时"这是一个 tool_use block",然后逐 token 输出 name 和 input 字段,最后 content_block_stop 标记结束。运行时根据 content_block_start 中的 type: "tool_use" 判断这是一个工具调用指令,等 block 结束后提取完整的 name + input,去工具池中查找并执行。
这就是为什么叫"流式解析": 模型不是一次性给出完整 JSON,而是一个 token 一个 token 地吐,运行时需要从流中拼装出完整的 tool_use block。
tool_use block 包含三个关键字段:
| 字段 | 类型 | 含义 | 示例 |
|---|---|---|---|
id |
string | 唯一标识,用于匹配后续的 tool_result | "toolu_01A09q90..." |
name |
string | 工具名,对应 tools[] 中注册的 name |
"Bash" / "Read" |
input |
object | 工具参数,结构由工具的 inputSchema 定义 | { command: "git status" } |
name 是模型和运行时之间的"握手协议"------模型在 System Prompt 中看到了工具的 name 和 Schema,输出时用 name 指定要调用哪个工具,用 input 传入参数。运行时收到后,根据 name 在工具池中找到对应的 Tool 对象,用 input 作为参数执行。
tool_result 的数据结构------运行时回传的"执行结果"
运行时执行完工具后,不是直接把结果塞回模型的上下文------而是构造一个 tool_result block,作为 user message 发送给模型:
typescript
// 运行时构造的 user message(工具结果)
{
role: "user",
content: [
{
type: "tool_result",
tool_use_id: "toolu_01A09q90qw90lq917835lq9", // ← 匹配 tool_use 的 id
content: "On branch main\nnothing to commit...", // 工具输出
is_error: false // 是否为错误
}
]
}id 和 tool_use_id 是配对的钥匙。 模型可能一次输出多个 tool_use block,每个有唯一的 id。运行时执行后,用 tool_use_id 把结果和对应的 tool_use 配对------模型看到结果时,知道这个结果是哪个工具调用产生的。
一次完整的工具调用------数据在 messages 中的流转
把上面两段放在一起,一次完整的工具调用在 messages 数组中是这样的:
messages = [
// 第一轮:用户提问
{ role: "user", content: "检查一下仓库状态" },
// 第二轮:模型输出 tool_use
{ role: "assistant", content: [
{ type: "text", text: "让我检查一下仓库状态。" },
{ type: "tool_use", id: "toolu_01A", name: "Bash",
input: { command: "git status" } }
]},
// 第三轮:运行时回传 tool_result
{ role: "user", content: [
{ type: "tool_result", tool_use_id: "toolu_01A",
content: "On branch main\nnothing to commit...",
is_error: false }
]},
// 第四轮:模型根据结果继续回复
{ role: "assistant", content: "仓库状态正常,在 main 分支上,没有未提交的更改。" }
]注意第三轮的 role 是 user------从 API 的角度看,tool_result 是"用户"发送的。这是因为 Anthropic API 的对话格式要求 assistant 和 user 交替出现,tool_result 被视为 user 的一种特殊消息。
多工具并发时的数据结构
模型一次可以输出多个 tool_use block。 这是理解并发调度的关键------模型不是串行地"用一个工具,等结果,再用下一个",而是在一个 assistant message 中同时输出多个 tool_use block:
{ role: "assistant", content: [
{ type: "text", text: "我来同时读取这两个文件。" },
{ type: "tool_use", id: "toolu_01A", name: "Read",
input: { file_path: "/src/index.ts" } },
{ type: "tool_use", id: "toolu_01B", name: "Read",
input: { file_path: "/src/utils.ts" } }
]}运行时收到后,并行执行两个 Read,然后把两个 tool_result 放在同一个 user message 中回传:
{ role: "user", content: [
{ type: "tool_result", tool_use_id: "toolu_01A",
content: "// index.ts 的内容...", is_error: false },
{ type: "tool_result", tool_use_id: "toolu_01B",
content: "// utils.ts 的内容...", is_error: false }
]}多个 tool_use 和多个 tool_result 通过 id ↔ tool_use_id 精确配对------这就是为什么 id 字段如此重要:没有它,模型无法知道哪个结果对应哪个调用。
小结:大模型指挥工具的协议
回到核心问题:大模型是怎么指挥使用工具的?
答案是一个三步协议:
- 注册 :系统把工具的 name + inputSchema 发给模型(这就是
tools[]数组) - 指挥 :模型在输出中嵌入
tool_useblock(name + input),告诉运行时"我想用这个工具" - 回传 :运行时执行工具后,构造
tool_resultblock(tool_use_id + content),喂回模型
模型看不到工具的执行过程------它只负责"点菜"(输出 tool_use),运行时负责"做菜"(执行工具)和"上菜"(回传 tool_result)。模型在下一轮推理中看到工具结果后,再决定下一步------继续调用工具,还是直接回复用户。
这个协议决定了流水线的起点和终点:从 tool_use 开始,到 tool_result 结束。中间的 7 个步骤(校验、Hook、权限、调度、执行、Hook、映射)都是运行时内部的工程实现------模型对此一无所知。
从 streaming 流中解析 tool_use block。 上面讲的是逻辑结构,但在实际运行中,模型的输出是流式的------它不是一次性给出完整 JSON,而是一个 token 一个 token 地吐出来。系统需要从流中识别出 tool_use block:
content_block_start事件:收到一个type: "tool_use"的 block 开始标记content_block_delta事件:逐个接收name和input的 tokencontent_block_stop事件:block 结束,完整的 tool_use block 可以被解析
关键点:模型一次可以输出多个 tool_use block。 比如模型可能同时说"帮我读这个文件,再搜索那个关键词"------输出两个 tool_use block,一个 Read,一个 Grep。这就是为什么需要并发调度:多个工具调用需要被同时处理,但又要保证安全和正确。
第二步:输入校验------Zod safeParse
模型并不擅长生成合法输入。 虽然工具的 JSON Schema 已经发给了模型,但模型输出仍然可能不符合 Schema------参数名拼错、类型不匹配、缺少必填字段,这些都是常见的事。
Zod 是什么? Zod 是 TypeScript 的 Schema 校验库------它定义了一套类型规则,用来在运行时验证数据是否符合预期。比如一个工具的 inputSchema 规定了 file_path 必须是 string 类型且必填,如果模型输出 { file_path: 123 }(数字而非字符串),Zod 就能检测出来并返回详细的错误信息。源码注释写得很直白:
"Validate input types with zod (surprisingly, the model is not great at generating valid input)" ---
src/services/tools/toolExecution.tsL614
所以在进入任何业务逻辑之前,第一步是输入校验:
typescript
const parseResult = tool.inputSchema.safeParse(input)inputSchema 是每个工具在 buildTool() 时注册的 Zod Schema,safeParse() 不会抛异常,而是返回 { success: boolean, data?, error? }。
校验失败时怎么办?系统不会直接崩溃,而是:
- 格式化错误信息(
error.format()),让模型能理解哪里出了问题 - 如果是延迟加载的工具,生成
buildSchemaNotSentHint()------告诉模型"这个工具的完整 Schema 没发给你,你需要先用 ToolSearchTool 搜索并加载它" - 把错误信息作为 tool_result 返回给模型,让模型在下一次推理中修正
这一步是流水线的安全网------它不拦截恶意输入(那是权限系统的事),而是修复模型的不精确输出。
第三步:PreToolUse Hooks------执行前的拦截器
Hook 系统是工具执行的"中间件层"。 它在输入校验之后、权限检查之前介入,可以在不修改工具代码的前提下改变工具行为。
三类 Hook:
| Hook 类型 | 触发时机 | 典型用途 |
|---|---|---|
| PreToolUse | 工具执行前 | 拦截危险操作、修改工具输入 |
| PostToolUse | 工具执行成功后 | 记录日志、添加额外上下文 |
| PostToolUseFailure | 工具执行失败后 | 错误报告、自动重试 |
PreToolUse 是最强大的------它的决策不只是"允许/拒绝":
| 决策类型 | 效果 |
|---|---|
allow |
放行,继续执行 |
deny |
拒绝,工具不执行 |
ask |
弹出对话框让用户决定 |
stop |
终止整个 Agent 回合 |
updatedInput |
修改工具输入------这是 Hook 最强大的能力 |
additionalContext |
添加额外上下文给模型 |
updatedInput 是一个很容易被忽视但极其重要的能力:Hook 可以在执行前修改工具的参数。比如一个 PreToolUse Hook 可以检测到 BashTool 的 command 参数中有 rm -rf,把 rm -rf 替换成 rm -i(交互式确认),然后以修改后的参数继续执行------不需要拒绝,也不需要弹框。
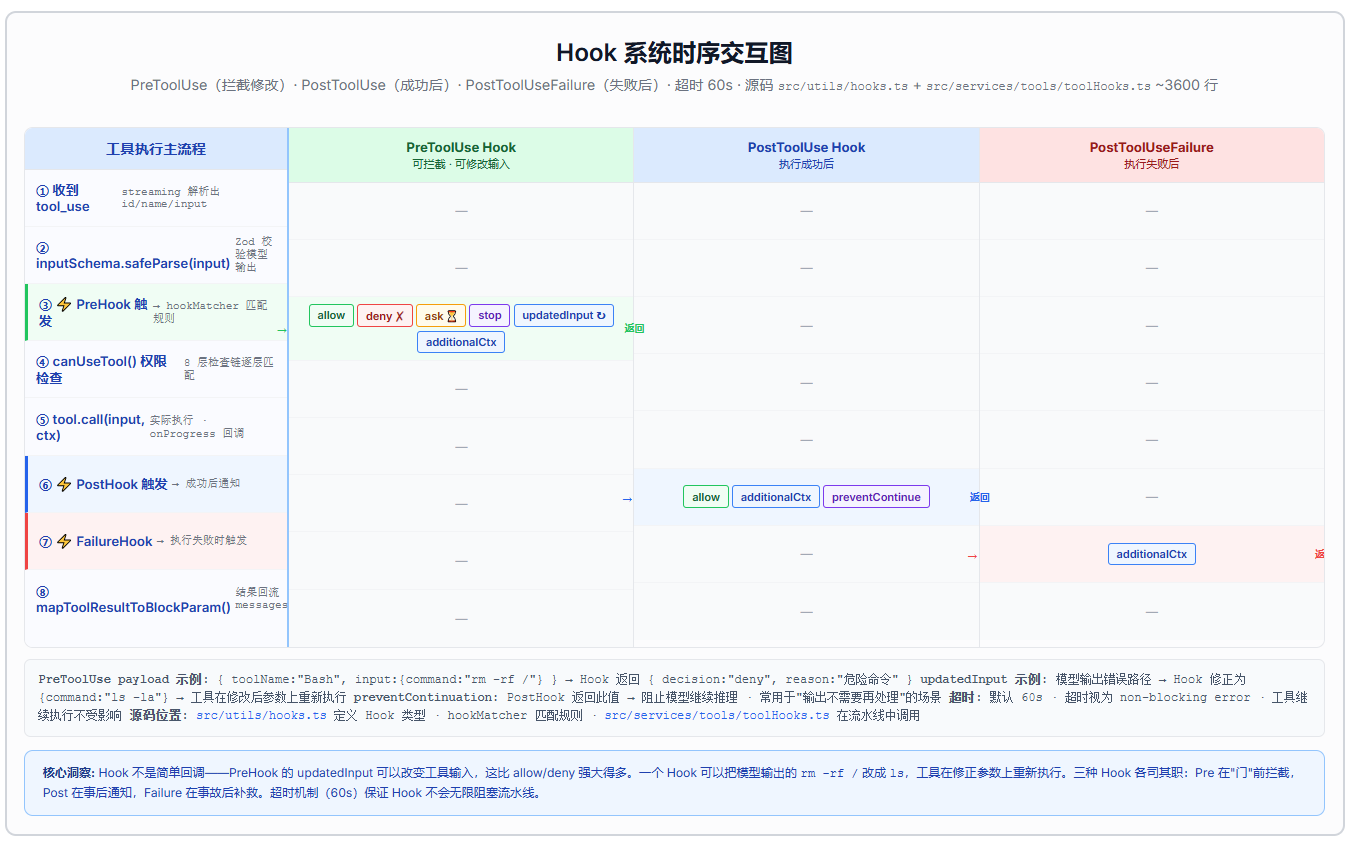
Hook 执行有超时机制------默认 60 秒。超时后视为 non-blocking error,工具继续执行。这个设计很实用:一个第三方 Hook 卡住了不应该阻塞整个 Agent 的工作流。
第四步:权限检查------canUseTool 决策
权限检查是流水线的核心决策点。 它决定了一个工具调用能不能执行。
权限决策有三种结果:
| 决策 | 行为 |
|---|---|
allow |
放行,进入并发调度 |
deny |
拒绝,返回错误信息给模型 |
ask |
弹出对话框让用户确认 |
权限被拒绝后,系统还会触发 PermissionDenied Hook------这是一个重试机制,让 Hook 有机会在权限拒绝后做额外处理。
权限系统的 8 层检查链是姊妹篇Claude Code 深度拆解:工具系统------权限、沙盒与错误处理的核心内容,这里只讲它在流水线中的位置:在 Hook 之后、执行之前。 这个顺序很重要------Hook 可以修改输入,权限检查的是修改后的输入。
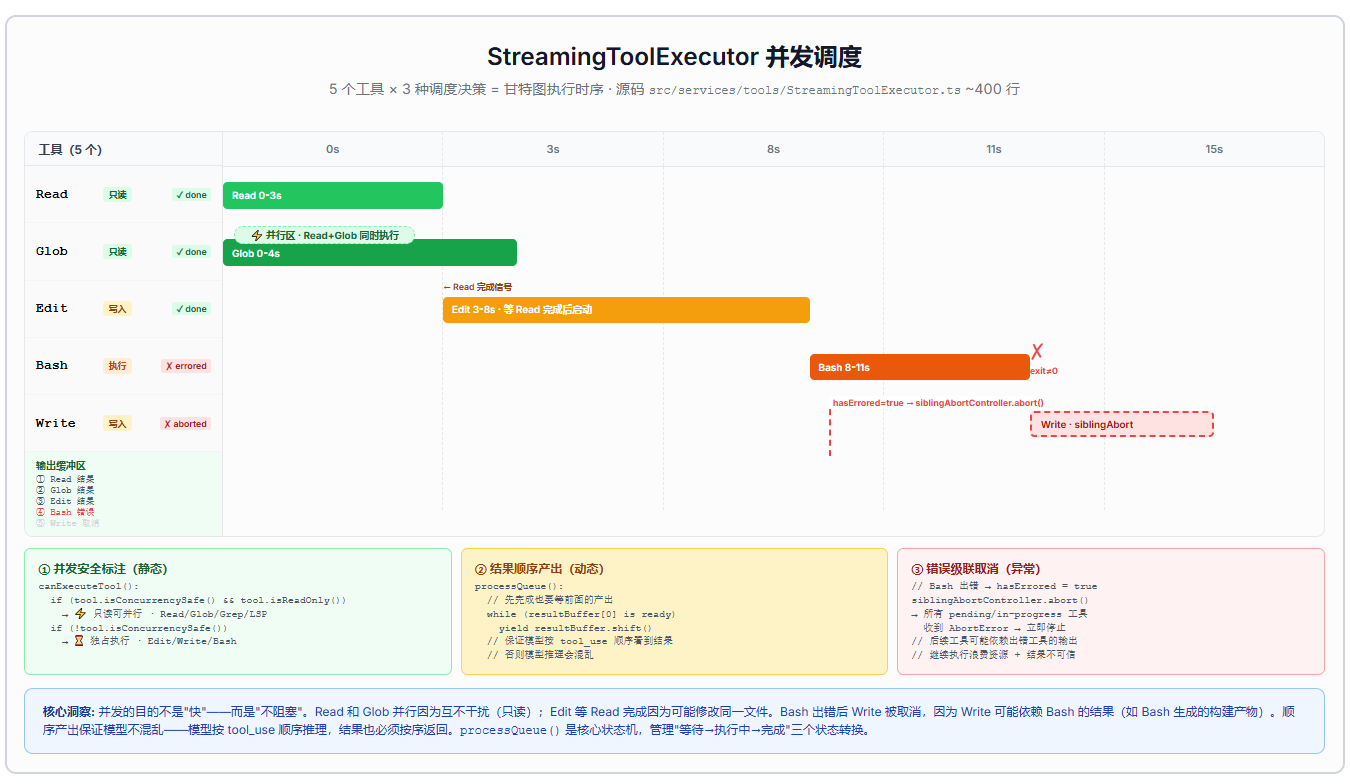
第五步:并发调度------"调度"到底意味着什么
这是本文最核心的章节。
很多人看到"并发调度"会理解为"并行 vs 串行"的二选一------能并行就并行,不能并行就串行。但 Claude Code 的调度远比这复杂,它是一个三层决策:
第一层:并发安全标注(静态)
每个工具在定义时就标注了自己是否并发安全------isConcurrencySafe() 返回值决定了它能不能和其他工具同时跑:
| 工具类型 | isConcurrencySafe | 原因 |
|---|---|---|
| Read | true |
只读,不修改任何状态 |
| Glob / Grep | true |
只搜索,不修改 |
| Edit | false |
修改文件,并行写入可能冲突 |
| Write | false |
覆盖文件,必须独占 |
| Bash | false |
执行命令可能修改文件系统 |
这是静态标注------工具定义时就确定了,不会在运行时改变。它回答的问题是:"这个工具能不能和其他工具同时执行?"
第二层:结果依赖管理(动态)
先完成的工具不能先产出------必须按模型输出的顺序返回结果。
这听起来反直觉:为什么不让先完成的先返回?因为模型的下一轮推理需要按顺序看到所有工具结果。如果 Read 先返回了,但模型期望先看到 Grep 的结果,那么模型可能会基于不完整的信息做出错误的推理。
StreamingToolExecutor 内部维护了一个结果缓冲区:每个工具执行完成后,结果被放入缓冲区;只有当前序位置的工具都已产出时,结果才按顺序流出。
第三层:错误级联传播(异常)
一个 Bash 命令出错,不是"那个工具失败其他继续",而是"全部停下"。
为什么?因为后续工具可能依赖出错工具的输出。假设模型同时调用了 Read 和 Edit------Read 读取文件内容,Edit 修改文件。如果 Read 出错了,Edit 的修改可能基于错误的信息,继续执行只会让事情更糟。
hasErrored 标志位 + siblingAbortController 实现了这个逻辑:任何一个工具出错,设置 hasErrored = true,然后通过 siblingAbortController 发出取消信号,所有并行工具立即终止。
说人话:"调度"就是在安全、正确、性能三个维度之间找平衡------能并行就并行(性能),不能并行就排队(安全),顺序产出保证模型不混乱(正确)。
第六步:工具执行------tool.call()
通过了校验、Hook、权限、调度四关之后,工具终于可以执行了。
每个工具的 call() 方法是它的核心实现。这一步是流水线中最"单纯"的一步------输入已经校验过了,权限已经检查过了,并发已经调度好了,工具只需要做自己的事。
执行过程中有两个机制值得关注:
进度回调(onProgress)。 有些工具执行时间很长(比如 BashTool 跑一个长时间的构建命令),进度回调让工具可以实时报告执行状态。用户在终端上看到的"正在执行..."提示,就是通过 onProgress 回调更新的。
沙盒封装。 BashTool 的执行会被沙盒封装------即使命令被允许执行,也运行在沙盒环境中,文件系统和网络访问受限制。沙盒和权限是两条独立防线,在姊妹篇Claude Code 深度拆解:工具系统------权限、沙盒与错误处理中展开。
第七步:结果映射与回流
工具执行完了,但结果不能直接丢给模型------需要格式转换。
mapToolResultToToolResultBlockParam() 将工具的原始输出转为 Anthropic API 要求的 ToolResultBlockParam 格式------这个格式的完整结构在第一步中已经展开讲过,这里重点讲转换过程中的工程细节:
tool_use_id:从对应的 tool_use block 的id复制,确保配对content:工具的原始输出,可能是文本、JSON、错误信息等is_error:如果工具执行失败(如 ShellError),设为true,模型会据此调整策略
转换后的 ToolResultBlockParam 被加入下一轮 API 请求的 messages[] 数组------模型在下一轮推理中就能看到工具结果,然后决定下一步。
大输出的持久化。 工具输出可能非常大(比如 Read 一个几千行的文件),不可能全部塞进 messages。当输出超过 getMaxOutputLength() 时,系统会:
- 把完整输出写入
tool-results/目录(临时文件) - 在
ToolResultBlockParam中只包含截断后的输出 + 文件路径 - 模型需要完整内容时,可以用 Read 工具读取临时文件
这是一种"按需加载"的思想------上下文中只保留摘要,完整内容按需获取。这和姊妹篇Claude Code 深度拆解:工具系统------30+ 工具怎么统一注册、按需加载中延迟加载的设计思路一致:不用的不花钱------渐进式披露再次体现。
错误级联取消------一个 Bash 出错,全部停下
虽然在前面的并发调度章节已经提到了错误级联,但这个机制足够重要,值得单独展开。
当 StreamingToolExecutor 中的一个工具执行出错时:
- 设置
hasErrored = true - 触发
siblingAbortController.abort() - 所有正在执行的工具收到
AbortSignal,立即终止 - 所有等待执行的工具被取消(不再调度)
为什么不让它们跑完?两个原因:
- 资源浪费:如果后续工具的输入依赖出错工具的输出,继续执行只是在浪费 token 和时间
- 结果不可信:基于错误信息的后续操作可能产生连锁错误,比直接停止更危险
这是一种"快速失败"(Fail Fast)的设计哲学------与其在错误的基础上继续操作,不如立即停止,让模型根据错误信息重新规划。
模型 Fallback 时的工具清理
还有一种特殊情况:模型本身出了问题。
当 streaming 过程中发生 fallback(比如当前模型不可用,切换到备用模型),所有 pending 和 in-progress 的工具调用都需要被清理:
discard()机制:丢弃所有 pending/in-progress 工具- 新建
StreamingToolExecutor实例,避免旧的tool_use_id泄漏到新模型的上下文中
为什么需要清理?因为 tool_use_id 是和特定模型的对话绑定在一起的。切换模型后,旧的 tool_use_id 对新模型没有意义------如果残留,模型可能会尝试匹配不存在的工具调用,导致上下文混乱。
本章小结
这条流水线读下来,我对 StreamingToolExecutor 的设计印象最深。一开始我以为并发调度就是简单的"只读并行、写入串行",但源码告诉我它是一个三层决策:静态标注决定能不能并行,结果缓冲保证按序产出,错误级联确保快速失败。这三层解决的是三个完全不同的问题------性能、正确性、安全性,但它们被揉在同一个调度器里,彼此配合。你单独看某一层觉得理所当然,但三层叠在一起的时候,复杂度是很高的。这个设计让我意识到,Agent 系统的"并发"和传统编程的并发不是一回事------传统并发关心的是线程安全,而 Agent 系统的并发还要关心"模型能不能正确理解乱序结果"这个问题。
另一个让我意外的是工具调用发起的方式。我之前一直觉得模型在"调用"工具,但读源码之后才明白------模型只是输出了一个 JSON 结构,真正执行工具的是运行时。这个区分看起来微妙,但它决定了整条流水线的架构:模型是"点菜"的,运行时是"做菜"的,中间的校验、Hook、权限、调度都是运行时单方面的事,模型对此一无所知。这种职责分离让我重新理解了为什么 Agent 系统可以在不改变模型的前提下做这么多工程优化------因为模型和工具执行之间有一层完整的运行时可以做文章。
系列导航:
本文属于 《Claude Code 源码 Deep Dive》 系列中「工具系统」命题的子篇章,专注于 运行时流水线。
姊妹篇(可独立阅读):
- Claude Code 深度拆解:工具系统------30+ 工具怎么统一注册、按需加载
- Claude Code 深度拆解:工具系统------30+ 内置工具地图与 MCP / Skills 协作
- Claude Code 深度拆解:工具系统------权限、沙盒与错误处理
如果这篇文章对你有帮助,欢迎点赞收藏 支持一下。如果你对 Claude Code 源码感兴趣,欢迎关注本系列 后续更新。有任何想法或疑问,欢迎评论区留言讨论 👋