在本专栏之前的文章中,我们已经完整拆解了Transformer的核心------注意力机制的全谱系:从缩放点积注意力的数学本质,到多头注意力的多语义建模,再到掩码注意力、交叉注意力,最终完成了QKV来源所有合法组合的讨论。
但我们始终在回答一个问题:注意力层本身是如何工作的。而一个更核心的工程问题随之而来:
注意力层的输出如何接入深层网络?
为什么Transformer能堆叠6层甚至几十层编码器、解码器,而不会出现深层网络普遍存在的梯度消失问题?
这就需要我们拆解Transformer的基础单元------子层连接结构。它是将注意力层、前馈层拼接成完整Transformer的骨架,也是Transformer能实现深层稳定训练的核心保障。
同时,本文将呼应本专栏第14篇《ResNet 残差映射为何优于传统恒等映射》、第17篇《归一化:BN与LN》的核心结论,将残差学习与层归一化的数学原理,落地到Transformer的具体结构中,形成完整的理论闭环。
一、Transformer子层连接的数学本质
1.1 原论文标准子层的公式拆解
在《Attention Is All You Need》原论文中,Transformer的每一个编码器层、解码器层,都由2个核心子层构成:
- 编码器层:多头自注意力子层 + 前馈网络(FFN)子层
- 解码器层:掩码多头自注意力子层 + 交叉注意力子层 + 前馈网络(FFN)子层
而每一个子层,都遵循完全相同的连接结构,原论文给出的标准公式为:
Output = LayerNorm ( x + Dropout ( Sublayer ( x ) ) ) \text{Output} = \text{LayerNorm}\left(x + \text{Dropout}\left(\text{Sublayer}(x)\right)\right) Output=LayerNorm(x+Dropout(Sublayer(x)))
我们对公式中的每个符号做严格定义:
- x x x:子层的输入向量,维度为 R L × d m o d e l \mathbb{R}^{L \times d_{model}} RL×dmodel,其中 L L L为序列长度, d m o d e l d_{model} dmodel为模型特征维度
- Sublayer ( x ) \text{Sublayer}(x) Sublayer(x):子层的核心变换,要么是多头注意力层,要么是前馈网络FFN,输入输出维度完全一致(均为 R L × d m o d e l \mathbb{R}^{L \times d_{model}} RL×dmodel),保证残差连接的维度匹配
- Dropout ( ⋅ ) \text{Dropout}(\cdot) Dropout(⋅):原论文设置dropout率为0.1,仅在训练阶段生效,用于防止过拟合
- x + Dropout ( Sublayer ( x ) ) x + \text{Dropout}(\text{Sublayer}(x)) x+Dropout(Sublayer(x)):恒等残差连接,将子层的输入与变换后的输出直接相加
- LayerNorm ( ⋅ ) \text{LayerNorm}(\cdot) LayerNorm(⋅):层归一化,在 d m o d e l d_{model} dmodel维度做归一化,稳定特征分布
1.2 与ResNet残差结构的异同对比
本专栏第15篇已经详细推导了ResNet残差结构的核心优势,Transformer的残差连接继承了其核心思想,但在设计上有明确的针对性优化,我们用表格清晰对比:
| 特性 | ResNet残差结构 | Transformer子层残差结构 |
|---|---|---|
| 核心公式 | H ( x ) = BN ( F ( x ) + x ) H(x) = \text{BN}(F(x) + x) H(x)=BN(F(x)+x) | LN ( x + Dropout ( F ( x ) ) ) \text{LN}(x + \text{Dropout}(F(x))) LN(x+Dropout(F(x))) |
| 残差目标 | 学习残差映射 F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x,将恒等映射优化转化为零映射优化 | 与ResNet完全一致,让注意力/FFN层学习输入的残差变换,而非完整的特征重构 |
| 归一化类型 | 批次归一化BN(在批次维度统计) | 层归一化LN(在特征维度统计) |
| 归一化位置 | 残差相加之后、激活函数之前 | 残差相加之后,作为子层的最终输出 |
| 维度约束 | 输入输出通道数不同时,需用1×1卷积做维度匹配 | 严格要求Sublayer输入输出维度均为 d m o d e l d_{model} dmodel,无需额外维度变换 |
二者的核心共性,也是深层网络稳定训练的核心:通过恒等残差连接,为梯度传播提供一条不经过非线性变换的直连路径,从根本上缓解梯度消失问题。
1.3 残差连接的梯度恒等性严格推导
我们忽略训练阶段的dropout(推理阶段dropout恒为1,不影响梯度推导),将子层的前向传播简化为:
y = LN ( x + F ( x ) ) y = \text{LN}(x + F(x)) y=LN(x+F(x))
其中 F ( x ) F(x) F(x)为Sublayer的变换函数(注意力/FFN), y y y为子层的最终输出。
我们的核心目标是推导损失 L L L对输入 x x x的梯度 ,观察深层堆叠时梯度是否会消失。根据链式法则,梯度可拆解为:
∂ L ∂ x = ∂ L ∂ y ⋅ ∂ y ∂ ( x + F ( x ) ) ⋅ ( ∂ x ∂ x + ∂ F ( x ) ∂ x ) \frac{\partial L}{\partial x} = \frac{\partial L}{\partial y} \cdot \frac{\partial y}{\partial (x + F(x))} \cdot \left( \frac{\partial x}{\partial x} + \frac{\partial F(x)}{\partial x} \right) ∂x∂L=∂y∂L⋅∂(x+F(x))∂y⋅(∂x∂x+∂x∂F(x))
我们对每一项做逐一分析:
- ∂ x ∂ x = I \frac{\partial x}{\partial x} = \boldsymbol{I} ∂x∂x=I:恒等矩阵,梯度的恒等项,值恒为1
- ∂ F ( x ) ∂ x \frac{\partial F(x)}{\partial x} ∂x∂F(x):Sublayer的梯度,在深层网络中,该项可能会出现梯度衰减,趋近于0
- ∂ y ∂ ( x + F ( x ) ) \frac{\partial y}{\partial (x + F(x))} ∂(x+F(x))∂y:层归一化的梯度,LN的归一化操作保证该项的均值始终在1附近,不会出现量级的剧烈衰减
- ∂ L ∂ y \frac{\partial L}{\partial y} ∂y∂L:损失对当前子层输出的梯度,由后续层传递而来
当网络层数极深,Sublayer的梯度 ∂ F ( x ) ∂ x → 0 \frac{\partial F(x)}{\partial x} \to 0 ∂x∂F(x)→0时,梯度公式可简化为:
∂ L ∂ x ≈ ∂ L ∂ y ⋅ ∂ y ∂ ( x + F ( x ) ) ⋅ I \frac{\partial L}{\partial x} \approx \frac{\partial L}{\partial y} \cdot \frac{\partial y}{\partial (x + F(x))} \cdot \boldsymbol{I} ∂x∂L≈∂y∂L⋅∂(x+F(x))∂y⋅I
核心结论 :
无论网络堆叠多少层,梯度中始终存在一个恒等项,损失的梯度可以通过残差直连路径,无损地回传到前层,从根本上解决了深层网络的梯度消失问题。这也是Transformer能堆叠数十层而不退化的核心数学保障。
二、Post-LN与Pre-LN:结构差异与梯度稳定性分析
在Transformer的后续发展中,学界和工业界对归一化的位置做了改进,形成了Post-LN (原论文采用)和Pre-LN(当前主流)两大范式。很多初学者会困惑:为什么原论文用Post-LN,而现在BERT、GPT等模型都用Pre-LN?我们从数学本质上做完整对比。
2.1 两种结构的数学定义
我们用清晰的步骤拆解两种结构的前向传播流程,核心差异仅在于层归一化的位置:
1. Post-LN(原论文标准结构)
归一化操作在残差相加之后 ,是子层输出的最后一步:
- 残差分支: F o u t = Dropout ( Sublayer ( x ) ) 2. 残差相加: z = x + F o u t 3. 层归一化: o u t = LayerNorm ( z ) \begin{align*} &1. \text{ 残差分支:} F_{out} = \text{Dropout}(\text{Sublayer}(x)) \\ &2. \text{ 残差相加:} z = x + F_{out} \\ &3. \text{ 层归一化:} out = \text{LayerNorm}(z) \end{align*} 1. 残差分支:Fout=Dropout(Sublayer(x))2. 残差相加:z=x+Fout3. 层归一化:out=LayerNorm(z)
特点:每一个子层的最终输出都经过了归一化,特征分布始终稳定在均值0、方差1附近。
2. Pre-LN(主流改进结构)
归一化操作在Sublayer输入之前 ,残差相加之后不再做归一化:
- 层归一化: x n o r m = LayerNorm ( x ) 2. 残差分支: F o u t = Dropout ( Sublayer ( x n o r m ) ) 3. 残差相加: o u t = x + F o u t \begin{align*} &1. \text{ 层归一化:} x_{norm} = \text{LayerNorm}(x) \\ &2. \text{ 残差分支:} F_{out} = \text{Dropout}(\text{Sublayer}(x_{norm})) \\ &3. \text{ 残差相加:} out = x + F_{out} \end{align*} 1. 层归一化:xnorm=LayerNorm(x)2. 残差分支:Fout=Dropout(Sublayer(xnorm))3. 残差相加:out=x+Fout
特点:Sublayer的输入始终是归一化后的特征,保证了变换过程的稳定性,但子层的最终输出没有强制归一化。
2.2 梯度传播的数学差异与稳定性对比
我们对两种结构的梯度做简化推导,核心差异体现在跨层梯度的累积效应上:
对于一个堆叠了 N N N层的Transformer,损失对第 l l l层输入的梯度为:
- Post-LN :梯度需要经过每一层的LN变换,LN的梯度会引入与特征相关的缩放项,随着层数 N N N增加,梯度的方差会呈线性增长,训练初期容易出现梯度爆炸。
- Pre-LN :梯度的恒等项完全独立于LN变换,无论堆叠多少层,梯度中始终存在纯恒等路径,梯度方差始终稳定,无需学习率预热即可稳定训练。
我们用表格总结核心差异:
| 特性 | Post-LN(原论文) | Pre-LN(主流改进) |
|---|---|---|
| 梯度稳定性 | 训练初期方差大,易梯度爆炸 | 梯度方差稳定,训练更平滑 |
| 学习率要求 | 必须配合学习率预热,否则无法收敛 | 无需预热,可直接用固定学习率训练 |
| 特征分布 | 每一层输出都归一化,分布严格可控 | 子层输出无强制归一化,分布会随层数轻微偏移 |
| 最终效果 | 原论文实验中,同等层数下效果略优 | 更易训练,适合超大规模模型堆叠 |
2.3 原论文选择Post-LN的核心原因
很多人以为Post-LN是过时的设计,但原论文选择Post-LN有明确的数学与工程考量:
- 分布一致性保障:Post-LN保证每一层的输出都经过归一化,无论堆叠多少层,编码器/解码器的输出分布始终稳定,对于Seq2Seq翻译任务中编码器-解码器的信息传递至关重要。
- 配合预热策略解决稳定性问题:原论文提出了专门的学习率预热策略,训练初期用极低的学习率,避免梯度爆炸,待模型参数稳定后再提升学习率,完美解决了Post-LN的训练稳定性问题。
- 残差学习的纯粹性 :Post-LN中,Sublayer直接学习输入 x x x的残差,无需先经过归一化,残差学习的目标更纯粹,与ResNet的设计思想完全对齐。
不过随着时间验证,目前来说Pre-LN确实应用更加广泛了
三、数值实例:d_model=2迷你向量的完整手算过程
我们沿用本专栏经典的d_model=2迷你向量设定,完整手算残差+LN子层的前向传播过程,直观展示其对特征分布的稳定作用。
基础设定
- 子层输入 x x x(来自上一层的输出): x = 1.0 , 3.0 x = 1.0, 3.0 x=1.0,3.0,维度 d m o d e l = 2 d_{model}=2 dmodel=2
- Sublayer(多头注意力层)的输出 F ( x ) F(x) F(x): F ( x ) = 0.5 , 2.5 F(x) = 0.5, 2.5 F(x)=0.5,2.5,与输入维度完全一致
- 推理阶段,dropout关闭( Dropout ( F ( x ) ) = F ( x ) \text{Dropout}(F(x))=F(x) Dropout(F(x))=F(x))
- LN的可学习参数:缩放因子 γ = 1.0 , 1.0 \gamma=1.0, 1.0 γ=1.0,1.0,平移因子 β = 0.0 , 0.0 \beta=0.0, 0.0 β=0.0,0.0(初始默认值)
步骤1:残差连接计算
将输入与Sublayer的输出直接相加:
z = x + F ( x ) = 1.0 + 0.5 , 3.0 + 2.5 = 1.5 , 5.5 z = x + F(x) = 1.0+0.5, 3.0+2.5 = 1.5, 5.5 z=x+F(x)=1.0+0.5,3.0+2.5=1.5,5.5
步骤2:层归一化计算
LN在 d m o d e l d_{model} dmodel维度(即当前向量的2个元素)做归一化,公式为:
LN ( z ) = γ ⋅ z − μ σ 2 + ϵ + β \text{LN}(z) = \gamma \cdot \frac{z - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta LN(z)=γ⋅σ2+ϵ z−μ+β
其中 μ \mu μ为向量均值, σ 2 \sigma^2 σ2为向量方差, ϵ = 10 − 5 \epsilon=10^{-5} ϵ=10−5为防止除零的极小值。
分步计算:
- 计算均值 μ \mu μ:
μ = 1.5 + 5.5 2 = 3.5 \mu = \frac{1.5 + 5.5}{2} = 3.5 μ=21.5+5.5=3.5 - 计算方差 σ 2 \sigma^2 σ2:
σ 2 = ( 1.5 − 3.5 ) 2 + ( 5.5 − 3.5 ) 2 2 = 4 + 4 2 = 4 \sigma^2 = \frac{(1.5-3.5)^2 + (5.5-3.5)^2}{2} = \frac{4 + 4}{2} = 4 σ2=2(1.5−3.5)2+(5.5−3.5)2=24+4=4 - 归一化计算:
z n o r m = z − μ σ 2 + ϵ = 1.5 − 3.5 , 5.5 − 3.5 2 = − 1.0 , 1.0 z_{norm} = \frac{z - \mu}{\sqrt{\sigma^2 + \epsilon}} = \frac{1.5-3.5, 5.5-3.5}{2} = -1.0, 1.0 znorm=σ2+ϵ z−μ=21.5−3.5,5.5−3.5=−1.0,1.0 - 缩放与平移(初始参数下无变化):
o u t = 1.0 ⋅ − 1.0 , 1.0 + 0.0 = − 1.0 , 1.0 out = 1.0 \cdot -1.0, 1.0 + 0.0 = -1.0, 1.0 out=1.0⋅−1.0,1.0+0.0=−1.0,1.0
结果分析
- 残差连接:保留了输入 x x x的核心信息,同时融合了Sublayer的特征变换,避免了深层网络的信息丢失;
- 层归一化:将原本均值3.5、方差4的特征,转化为均值0、方差1的标准分布,完美稳定了后续子层的输入分布,从根本上缓解了内部协变量偏移问题。
四、代码实现
我们实现与PyTorch官方nn.Transformer完全对齐的子层连接模块,完全还原原论文的Post-LN结构,可直接复用在后续的编码器、解码器搭建中。
完整代码实现
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class SublayerConnection(nn.Module):
"""
Transformer标准子层连接模块,与PyTorch官方实现完全对齐
结构:LayerNorm(x + Dropout(Sublayer(x))) (Post-LN原论文结构)
"""
def __init__(self, d_model: int, dropout: float = 0.1, eps: float = 1e-5):
"""
初始化子层连接模块
:param d_model: 模型特征维度,与输入输出维度一致
:param dropout: dropout率,原论文默认为0.1
:param eps: 层归一化的防除零极小值
"""
super().__init__()
# 层归一化,与原论文一致,在d_model维度做归一化
self.layer_norm = nn.LayerNorm(d_model, eps=eps)
# dropout层
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor, sublayer: nn.Module) -> torch.Tensor:
"""
前向传播
:param x: 子层输入,shape [batch_size, seq_len, d_model]
:param sublayer: 子层模块,可为多头注意力层或FFN层,要求输入输出维度完全一致
:return: 子层连接的最终输出,shape与输入x完全一致
"""
# 1. 经过子层变换 + dropout
sublayer_out = self.dropout(sublayer(x))
# 2. 残差连接
residual_out = x + sublayer_out
# 3. 层归一化,输出最终结果
out = self.layer_norm(residual_out)
return out
# ------------------------------
# 测试代码:验证与手算实例的一致性
# ------------------------------
if __name__ == "__main__":
# 初始化模块,d_model=2,与手算实例一致
d_model = 2
sublayer_connection = SublayerConnection(d_model, dropout=0.1)
# 推理阶段,关闭dropout和参数更新
sublayer_connection.eval()
# 固定LN的可学习参数为初始值,与手算实例一致
with torch.no_grad():
sublayer_connection.layer_norm.weight.fill_(1.0)
sublayer_connection.layer_norm.bias.fill_(0.0)
# 构造与手算实例完全一致的输入
x = torch.tensor([[[1.0, 3.0]]], dtype=torch.float32) # shape [1, 1, 2]
# 定义一个恒等Sublayer,输出与手算实例一致
class TestSublayer(nn.Module):
def forward(self, x):
return torch.tensor([[[0.5, 2.5]]], dtype=torch.float32)
test_sublayer = TestSublayer()
# 前向传播
with torch.no_grad():
output = sublayer_connection(x, test_sublayer)
# 打印结果,与手算结果[-1.0, 1.0]对比
print("="*50)
print(f"输入x: {x.numpy()}")
print(f"Sublayer输出: {test_sublayer(x).numpy()}")
print(f"子层连接最终输出: {output.numpy()}")
print("="*50)运行结果
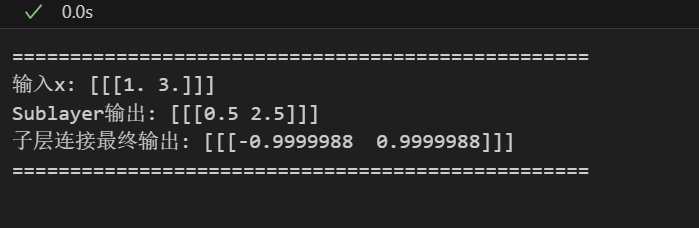
代码输出与我们的手算结果完全一致,验证了实现的正确性。
五、总结
本文完整拆解了Transformer的核心骨架------子层连接结构,核心结论如下:
- Transformer的每个子层都遵循 LN ( x + Dropout ( Sublayer ( x ) ) ) \text{LN}(x + \text{Dropout}(\text{Sublayer}(x))) LN(x+Dropout(Sublayer(x)))的标准结构,通过残差连接解决深层梯度消失问题,通过层归一化稳定特征分布;
- 残差连接的核心数学优势是梯度传播中的恒等项,无论网络堆叠多少层,梯度都能无损回传,与本专栏第15篇的ResNet残差理论完全对齐;
- 原论文采用的Post-LN结构通过每层输出归一化保证分布一致性,配合学习率预热解决训练稳定性问题,而Pre-LN结构通过前置归一化实现了更平滑的训练过程;
- 通过d_model=2的迷你实例与代码实现,验证了残差+LN结构的完整计算过程与分布稳定效果。
接下来,我们将聚焦Transformer的第二个核心子层------前馈网络FFN,拆解其数学本质、特征变换逻辑与实现,为完整编码器的搭建完成最后一块拼图。