C++AI多模型聊天系统(一)项目背景意义与整体架构、核心基类实现
- 前言及项目背景
- 一、项目环境搭建
- 二、用到的技术栈
- 三、项目整体架构设计
-
- [1. 架构图](#1. 架构图)
- [2. 类图](#2. 类图)
- 四、项目日志类实现
- 五、项目基础类的实现
-
- [5.1 数据结构设计(common.h)](#5.1 数据结构设计(common.h))
-
- [5.1.1 为什么用 ContentItem 而不是直接存字符串?](#5.1.1 为什么用 ContentItem 而不是直接存字符串?)
- [5.1.2 Message 为什么提供两个构造函数?](#5.1.2 Message 为什么提供两个构造函数?)
- [5.1.3 Config 为什么用继承体系?](#5.1.3 Config 为什么用继承体系?)
- [5.1.4 Session 和 ModelInfo 的定位](#5.1.4 Session 和 ModelInfo 的定位)
- [5.2 抽象接口设计(LLMProvider.h)](#5.2 抽象接口设计(LLMProvider.h))
前言及项目背景
一句话定位:
这是一个纯C++实现、零额外服务依赖的多模型AI聊天系统------采用SQLite + httplib轻量技术栈,目标是让开发者无需部署数据库或Web服务器,就能在自己的应用中接入主流大模型。
- 大模型技术爆发后,网络上涌现了大量基于Python的AI应用教程------用Flask调个API、用LangChain搭个链,十几行代码就能跑通一个demo。这个开发体验确实好,但它掩盖了一个现实问题:
Python方案的便利性是建立在厚重依赖之上的。 Flask、LangChain、各种SDK,一层层包下去,等想在C++服务端或嵌入式设备上接入大模型时,会发现要么找不到对应的库,要么依赖链重得离谱。
这个项目不是为了替代Python方案,而是探索另一条路径:在C++生态里,用最少的依赖、最轻量的组件,实现一个能用的多模型AI对话系统。
一、项目环境搭建
- 本项目基于 Ubuntu 24.04 LTS 开发,环境配置依赖均为轻量级开源库,无需复杂的依赖管理
bash
sdk/
├── 3rdparty/ #第三方库
├── include/ # 头文件
│ ├── util/ # 工具类(日志)
│ ├── core/ # 核心基类、结构体
│ └── model/ # 模型适配层
├── src/ # 源文件
│ ├── util/
│ ├── core/
│ └── model/
├── CMakeLists.txt # 构建文件
└── log/ # 日志输出目录二、用到的技术栈
- 本项目选用轻量、稳定、跨平台的技术栈,符合服务端 / 嵌入式部署需求:
| 分类 | 技术选型 | 官方下载链接 | Ubuntu 一键安装命令 | 项目适配说明 |
|---|---|---|---|---|
| 运行系统 | Ubuntu 24.04 LTS | Ubuntu官网 | 预装,无需安装 | 服务器/桌面版均可 |
| 开发语言 | C++17(g++编译器) | GNU GCC官网 | sudo apt install g++ -y |
支持C++17及以上 |
| 构建工具 | CMake | CMake官网 | sudo apt install cmake make -y |
项目编译核心工具 |
| 日志库 | spdlog | spdlog GitHub | sudo apt install libspdlog-dev -y |
异步线程安全日志 |
| JSON解析 | JsonCpp | JsonCpp GitHub | sudo apt install libjsoncpp-dev -y |
接口数据序列化 |
| 数据存储 | SQLite3 | SQLite官网 | sudo apt install libsqlite3-dev -y |
会话历史持久化 |
| 网络通信 | httplib | cpp-httplib GitHub | 手动下载单头文件 | 无依赖、纯头文件HTTP库 |
- 其中,cpp-httplib由于是单文件头文件库,未提供Ubuntu官方apt安装包,需手动下载至项目第三方库目录,具体操作命令如下:
bash
# 先进入我们的项目目录
cd /project/sdk/3rdparty/httplib
# 直接下载头文件
wget https://raw.githubusercontent.com/yhirose/cpp-httplib/master/httplib.h
三、项目整体架构设计
1. 架构图
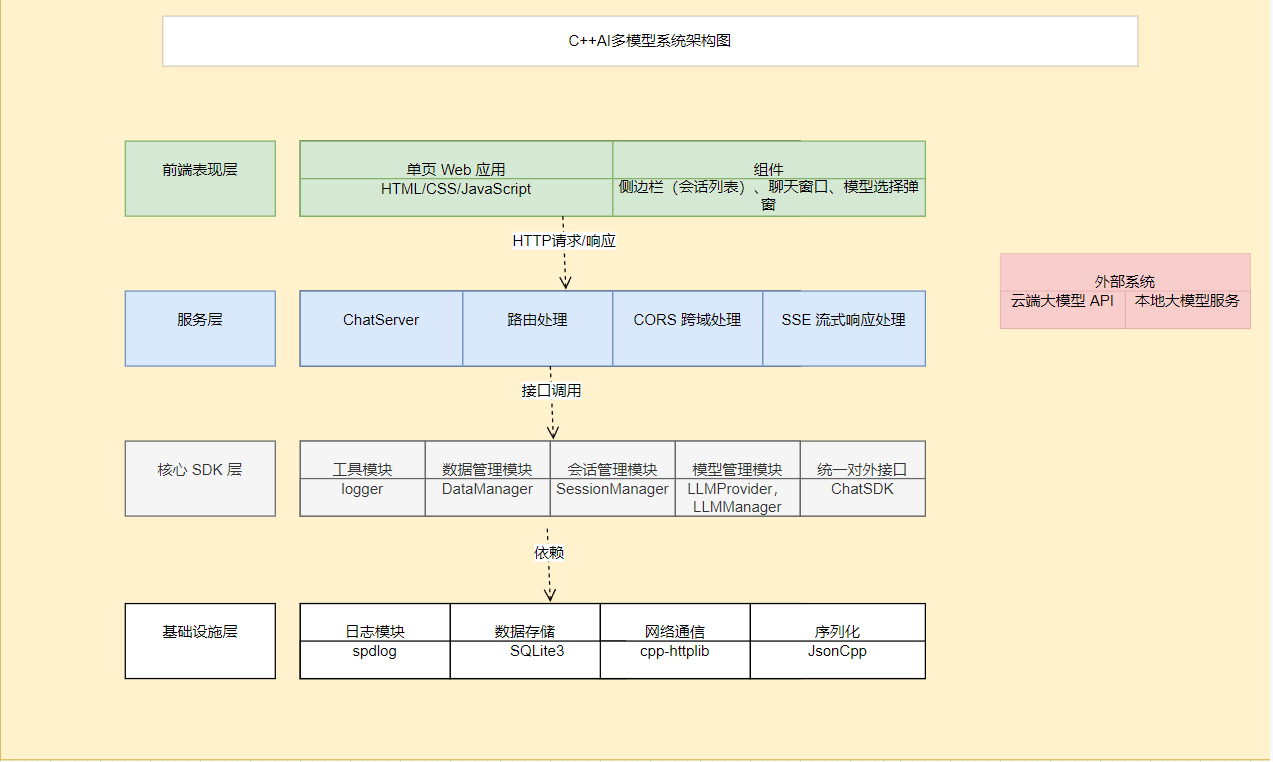
整个项目分为 4 层核心结构
-
交互层:用户操作界面(聊天窗口、模型选择、会话管理)
-
服务层:前后端通信桥梁,接收用户请求,转发给核心模块
-
核心 SDK 层(项目灵魂):统一管理模型、会话、日志、数据存储
-
依赖层:底层工具库(网络、日志、数据库)+ 外部大模型(云端 / 本地)
2. 类图
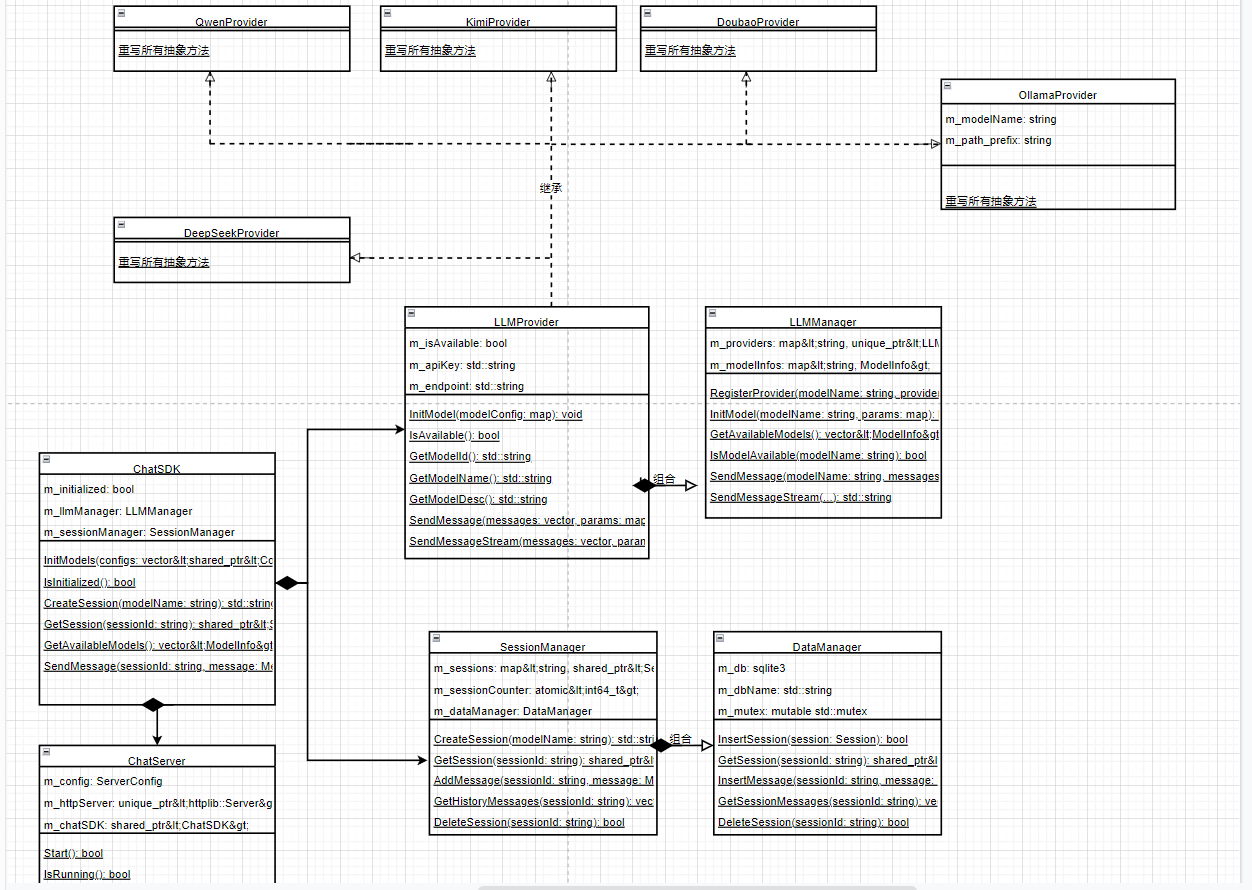
核心类只有3组
- LLMProvider(抽象基类)
所有模型的统一接口,不管是云端豆包/Kimi,还是本地Ollama,都必须遵循这套规则。 - 模型适配类
对应每个模型的实现类,专门负责和对应模型通信,翻译请求/响应。 - 管理类
LLMManager:管理所有模型,统一调度SessionManager:管理聊天会话,保存历史记录ChatSDK:对外提供统一调用入口,封装所有核心功能
四、项目日志类实现
-
日志系统是服务端项目的基础设施。项目运行中发生了什么、哪里出了问题、AI返回了什么内容,全靠日志来记录。
-
封装一个单例包装层的目的:一是统一初始化入口,二是通过宏定义自动注入文件名和行号,三是万一以后想换日志库只改这一层就行。
include/util/myLog.h
cpp
#pragma once
#include <memory>
#include <spdlog/spdlog.h>
#include <string>
#include <mutex>
namespace myLog{
class logger{
public:
static void InitLogger(
const std::string& loggerName,//日志名字
const std::string& loggerFile,//日志的文件
spdlog::level::level_enum loglevel = spdlog::level::info);
// 获取日志实例
static std::shared_ptr<spdlog::logger>& GetLogger();
private:
logger() {};
logger(const logger&) = delete;//静止拷贝,复制
logger& operator=(const logger&)=delete;//静止传数据
static std::shared_ptr<spdlog::logger> s_logger;//定义日志
static std::mutex s_mutex;
};
}
#define LOG_TRACE(format, ...) myLog::logger::GetLogger()->trace(std::string("[{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__,##__VA_ARGS__)
#define LOG_DBG(format, ...) myLog::logger::GetLogger()->debug(std::string("[{:>10s}:{:<4d}] ") +format, __FILE__, __LINE__,##__VA_ARGS__)
#define LOG_INFO(format, ...) myLog::logger::GetLogger()->info(std::string("[{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__,##__VA_ARGS__)
#define LOG_WARN(format, ...) myLog::logger::GetLogger()->warn(std::string("[{:>10s}:{:<4d}] ") +format, __FILE__, __LINE__,##__VA_ARGS__)
#define LOG_ERR(format, ...) myLog::logger::GetLogger()->error(std::string("[{:>10s}:{:<4d}] ") +format, __FILE__, __LINE__,##__VA_ARGS__)
#define LOG_CRIT(format, ...) myLog::logger::GetLogger()->critical(std::string("[{:>10s}:{:<4d}] ") +format, __FILE__, __LINE__,##__VA_ARGS__)src/util/myLog.cpp
cpp
#include "../../include/util/myLog.h"
#include <spdlog/sinks/stdout_color_sinks.h>
#include <spdlog/sinks/basic_file_sink.h>
#include <spdlog/async.h>
namespace myLog {
std::shared_ptr<spdlog::logger> logger::s_logger= nullptr;//日志变量
std::mutex logger::s_mutex;//线程安全锁
//日志初始化接口,调用函数
void logger::InitLogger(const std::string& loggerName, const std::string& loggerFile, spdlog::level::level_enum loglevel )
{
//检查锁,保证只能一个线程初始化日志对象
if(s_logger== nullptr){
std::lock_guard<std::mutex> lock(s_mutex);//创建互斥锁
if(s_logger == nullptr)
{
spdlog::init_thread_pool(32768,1);//设置默认日志对象为 _logger
//带颜色日志对象
if ("stdout" == loggerFile)
{
s_logger = spdlog::stdout_color_mt(loggerName);
}
else
{
//创建一个文件输出日志器,写入指定文件中
s_logger = spdlog::basic_logger_mt<spdlog::async_factory>(loggerName, loggerFile);
}
}
//日志消息
s_logger->set_pattern("[%H:%M:%S][%n][%-7l][%v]");
s_logger->set_level(loglevel);
spdlog::flush_on(loglevel);
}
}
std::shared_ptr<spdlog::logger>& logger::GetLogger()
{
return s_logger;
}
}核心设计点:
- 双重检查锁定(DCL) :
InitLogger里先判空再加锁、加锁后再判空,保证多线程环境下只初始化一次 - 文件/控制台双模式 :传
"stdout"走彩色控制台输出,传文件名走异步文件写入 - 宏封装 :
LOG_INFO("xxx")实际展开时会自动拼接[文件名:行号],这是spdlog的fmt格式化能力,调试时定位问题非常方便
五、项目基础类的实现
基础类决定了整个SDK的数据模型和扩展骨架。这部分代码不多,但每处设计都有对应的业务考量。
5.1 数据结构设计(common.h)
cpp
#pragma once
#include <string>
#include <vector>
#include <ctime>
namespace ai_chat_sdk {
// 多模态内容项
struct ContentItem {
std::string type; // 文本图片URL
std::string text; // 文本内容
std::string image_url; // 图片URL
};
//单条对话消息(支持多模态)
struct Message {
std::string messageId;
std::vector<ContentItem> contents; // 多模态内容列表(可以同时包含文本和图片)
std::time_t timeStamp;
std::string role;
Message(const std::string& role, const std::string& text)
: role(role) {
ContentItem item;
item.type = "input_text";
item.text = text;
contents.push_back(item);
timeStamp = std::time(nullptr);
}
// 多模态构造函数(用于发送图片+文本)
Message(const std::string& role, const std::vector<ContentItem>& contents)
: contents(contents),role(role){
timeStamp = std::time(nullptr);
}
Message() = default;
};
struct Config{
std::string modelName;
double temperature = 0.7;
int maxTokens = 2048;
virtual ~Config() = default;
};
//云端大模型
struct APIConfig : public Config{
std::string apiKey;
std::string endpoint;
};
// 本地
struct OllamaConfig : public Config {
std::string endpoint;
};
struct ModelInfo{
std::string modelId;
std::string modelName;
std::string modelDescription;
std::string provider;
std::string endpoint;
bool isAvailable = true;
ModelInfo(const std::string& modelName = "", const std::string& modelDesc = "",
const std::string& provider = "", const std::string& endpoint = "")
: modelName(modelName), modelDescription(modelDesc), provider(provider), endpoint(endpoint) {}
};
struct Session{
std::string sessionId;
std::string modelName;
std::vector<Message> messages;
std::time_t createTime;
std::time_t lastUpdateTime;
Session(const std::string& modelName = "") : modelName(modelName) {}
};
}5.1.1 为什么用 ContentItem 而不是直接存字符串?
cpp
ContentItem {
type // "input_text" 或 "input_image"
text // 文本内容
image_url // 图片URL
}- 因为要支持多模态。一条消息可能同时包含"帮我看看这张图"的文字和一张图片的URL。如果直接把内容存成一个字符串,后续给不同模型拼JSON时就分不清哪段是文字、哪段是图片------DeepSeek要拼成
"content": "文本内容",Kimi多模态要拼成"content": [{"type":"text",...}, {"type":"image_url",...}]。用结构体把图文拆开,各Provider各取所需。
5.1.2 Message 为什么提供两个构造函数?
一个接收 (role, text),内部自动包一层 ContentItem------这是90%使用场景(纯文本对话)的快捷方式。另一个接收 (role, vector<ContentItem>),给需要传图的场景用。提供便利的同时不丢掉多模态能力。
5.1.3 Config 为什么用继承体系?
基类存通用的 temperature、maxTokens。APIConfig 多存 apiKey 和 endpoint(云端模型需要联网鉴权),OllamaConfig 只多存 endpoint(本地模型不需要API Key)。
这样 ChatSDK::InitModels 里用 dynamic_pointer_cast 判断类型,对Ollama走本地初始化逻辑、对云端模型走API初始化逻辑------一个循环处理所有模型,扩展新模型类型只需加新的Config子类。
5.1.4 Session 和 ModelInfo 的定位
Session 是会话的完整快照:绑定哪个模型、有哪些历史消息、什么时候创建/最后活跃。messages 字段让 GetHistoryMessages 可以优先走内存缓存,命中率高时完全不查数据库。
ModelInfo 是模型的"名片",GetAvailableModels 返回的就是这个结构的列表,上层(比如Web页面)拿到后可以直接渲染模型选择列表。
5.2 抽象接口设计(LLMProvider.h)
cpp
#pragma once
#include <functional>
#include <string>
#include <map>
#include <vector>
#include "common.h"
namespace ai_chat_sdk {
class LLMProvider {
public:
virtual void InitModel(const std::map<std::string, std::string>& modelConfig) = 0;
virtual bool IsAvailable() const = 0;
virtual std::string GetModelId() const = 0;
virtual std::string GetModelName() const = 0;
virtual std::string GetModelDesc() const = 0;
virtual std::string SendMessage(
const std::vector<Message>& messages,
const std::map<std::string, std::string>& requestParam) = 0;
virtual std::string SendMessageStream(
const std::vector<Message>& messages,
const std::map<std::string, std::string>& requestParam,
const std::function<void(const std::string&, bool)>& callback) = 0;
virtual ~LLMProvider() = default;
protected:
bool m_isAvailable = false;
std::string m_apiKey;
std::string m_endpoint;
};
}这个接口的设计遵循了几个原则:
1. 依赖倒置。 LLMManager 和 ChatSDK 只依赖 LLMProvider 接口,不依赖任何具体模型类。新增一个模型,只需要写一个继承 LLMProvider 的子类,然后在 RegisterBuiltinProviders 里注册,上层代码一行不用改。
2. 配置与实现分离。 InitModel 不关心API Key从哪来、Endpoint是什么,它只接收一个 map<string,string>。配置的管理(从文件读、从环境变量读、硬编码)由调用方负责,Provider只负责"拿到配置后把自己初始化好"。
3. 双模式消息发送。 SendMessage 是传统请求-响应模式,适合"发一句等回复"的场景。SendMessageStream 带回调,每个分块到达时立刻通知上层,适合"打字机效果"的流式输出。同一个接口层同时支持两种模式,上层切换时不需要改调用逻辑。
4. 最小化接口。 没有多余的"取消请求"、"暂停生成"等方法,因为目前用到的HTTP库和模型API本身不原生支持这些操作。接口只定义当前真实需要的功能,避免"为了设计而设计"的空方法。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343我的C++AI多模型聊天系统项目专栏
欢迎来阅读指出不足
https://blog.csdn.net/2402_83322742/category_13159665.html?spm=1001.2014.3001.5482