博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈
Python语言、Flask框架、Tensorflow深度学习、LSTM神经网络算法股票价格预测、scikit-learn机器学习、东方财富数据源、Echarts可视化、HTML
功能模块
- 涨停板热点分析
- 首页功能模块介绍
- 大盘指数行情分析
- 个股量化分析
- 大盘资金流向分析
- 大盘市场基本面估值分析
- 个股收益量化分析
- 股票价格预测
- 龙虎榜热股排名
- 注册登录模块
项目介绍
本项目是一个基于Flask框架构建的股票数据分析与预测系统,集成了TensorFlow实现的LSTM神经网络模型用于股票价格趋势预测。系统通过爬虫技术从东方财富等平台获取实时及历史行情数据,利用scikit-learn进行数据预处理与特征工程。平台提供了涨停板热点分析、大盘与个股量化分析、资金流向监控、市场估值评估、龙虎榜热股排名等多个功能模块,并借助Echarts实现丰富的可视化图表展示,为投资者提供全面的技术面与基本面分析工具。
2、项目界面
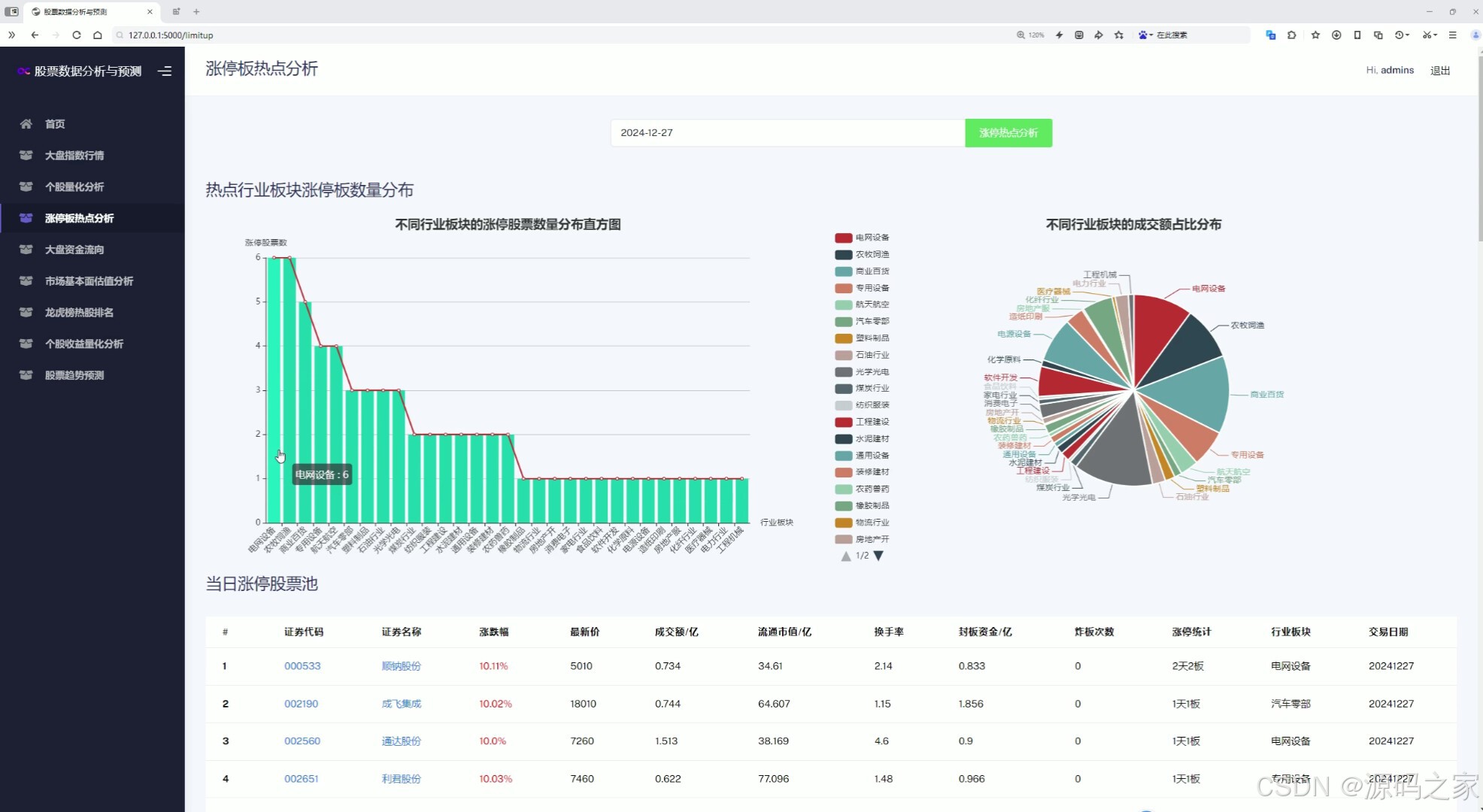
(1)涨停板热点分析---热点行业板块涨停板数量分布直方图、不同行业板块的成交额占比分布、当日涨停股票池
该页面为股票数据分析系统的涨停板热点分析模块,包含行业板块涨停股票数量分布直方图、不同行业板块成交额占比饼图,以及当日涨停股票信息表格,可按日期进行热点分析查询。
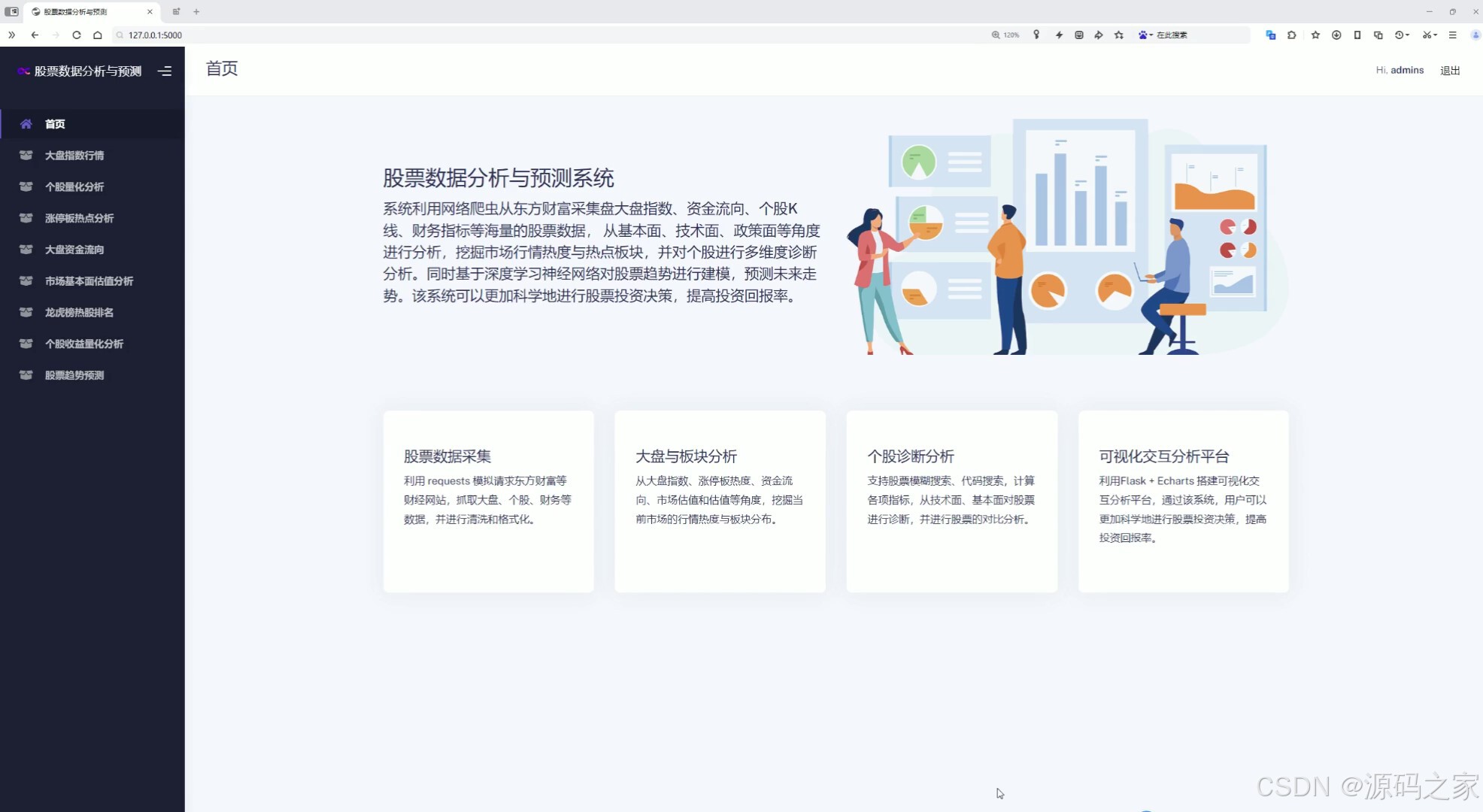
(2)首页---功能模块介绍
该页面是股票数据分析与预测系统的首页,左侧为导航栏,右侧介绍了系统整体功能,并通过卡片模块展示了股票数据采集、大盘与板块分析、个股诊断分析、可视化交互分析平台四项核心功能,配有相关分析图示。
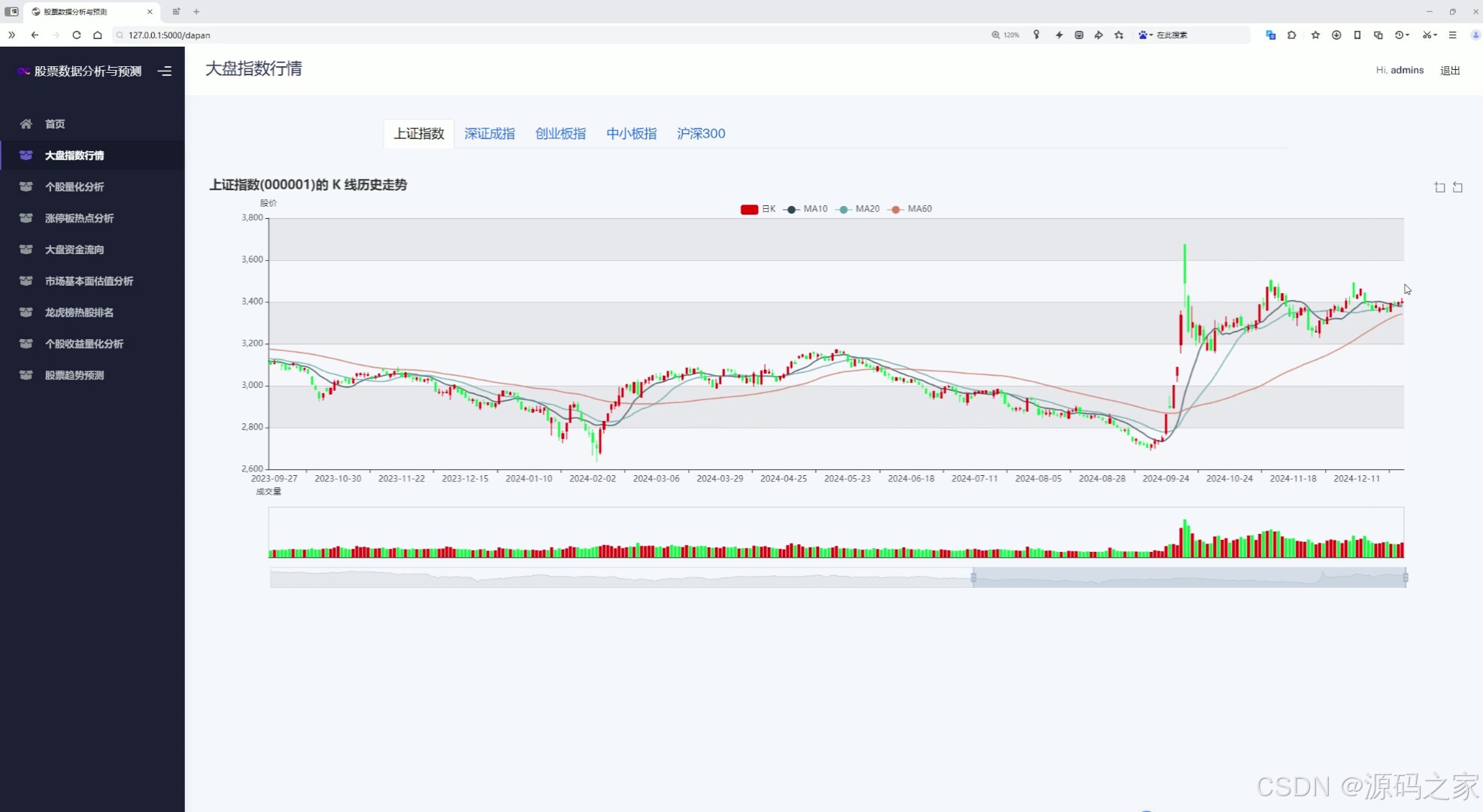
(3)大盘指数行情分析---上证、深证、创业板、中小指、沪深300指数K线图
该页面是股票数据分析系统的大盘指数行情模块,可切换查看不同指数,图中展示了上证指数的日K线历史走势及成交量数据,并叠加了多条均线指标,直观呈现指数价格趋势与成交变化。
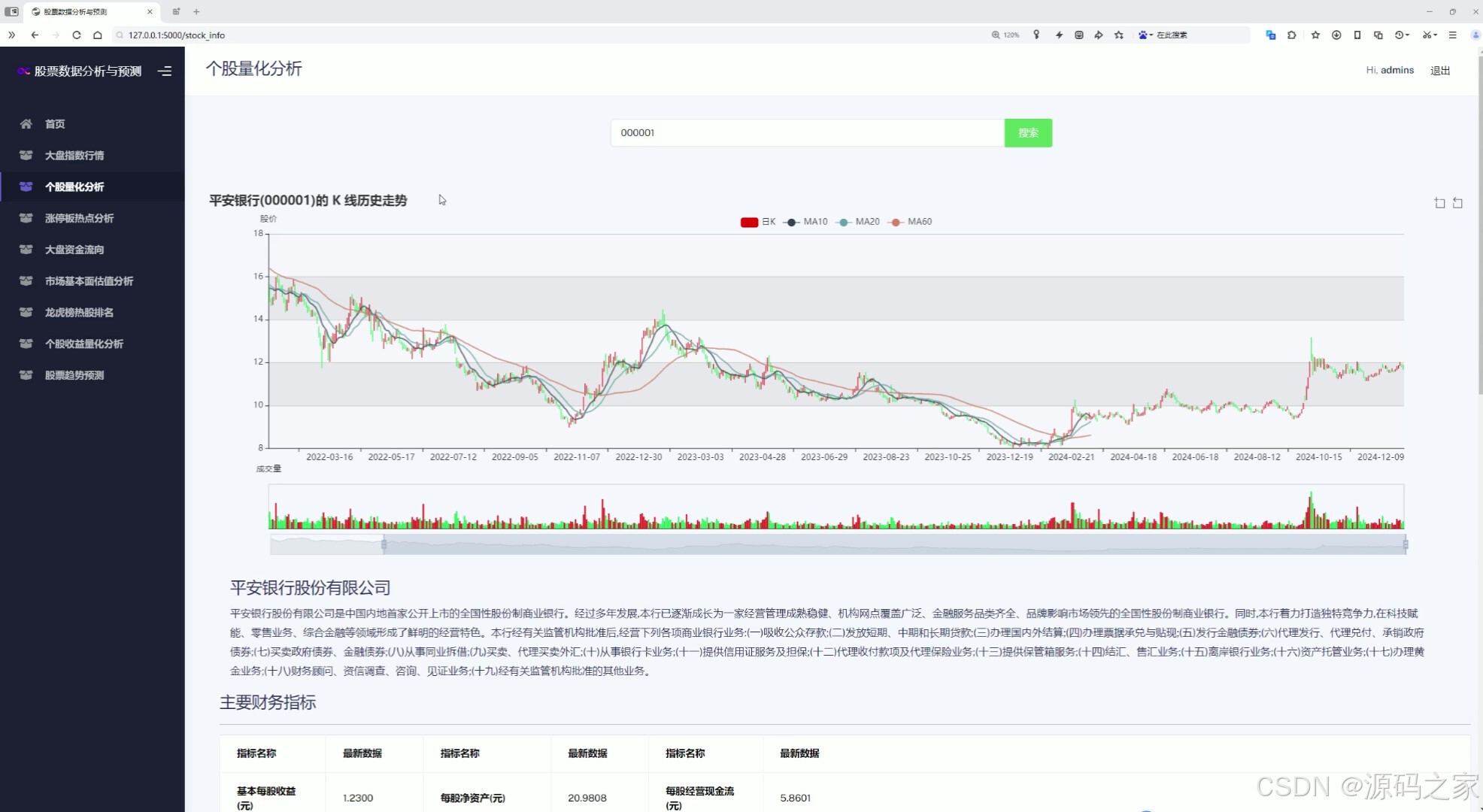
(4)个股量化分析---输入股票代码,全方位分析
该页面为个股量化分析模块,支持股票代码搜索,图中展示了对应个股的日K线历史走势、均线指标与成交量数据,同时还包含公司简介及主要财务指标信息。
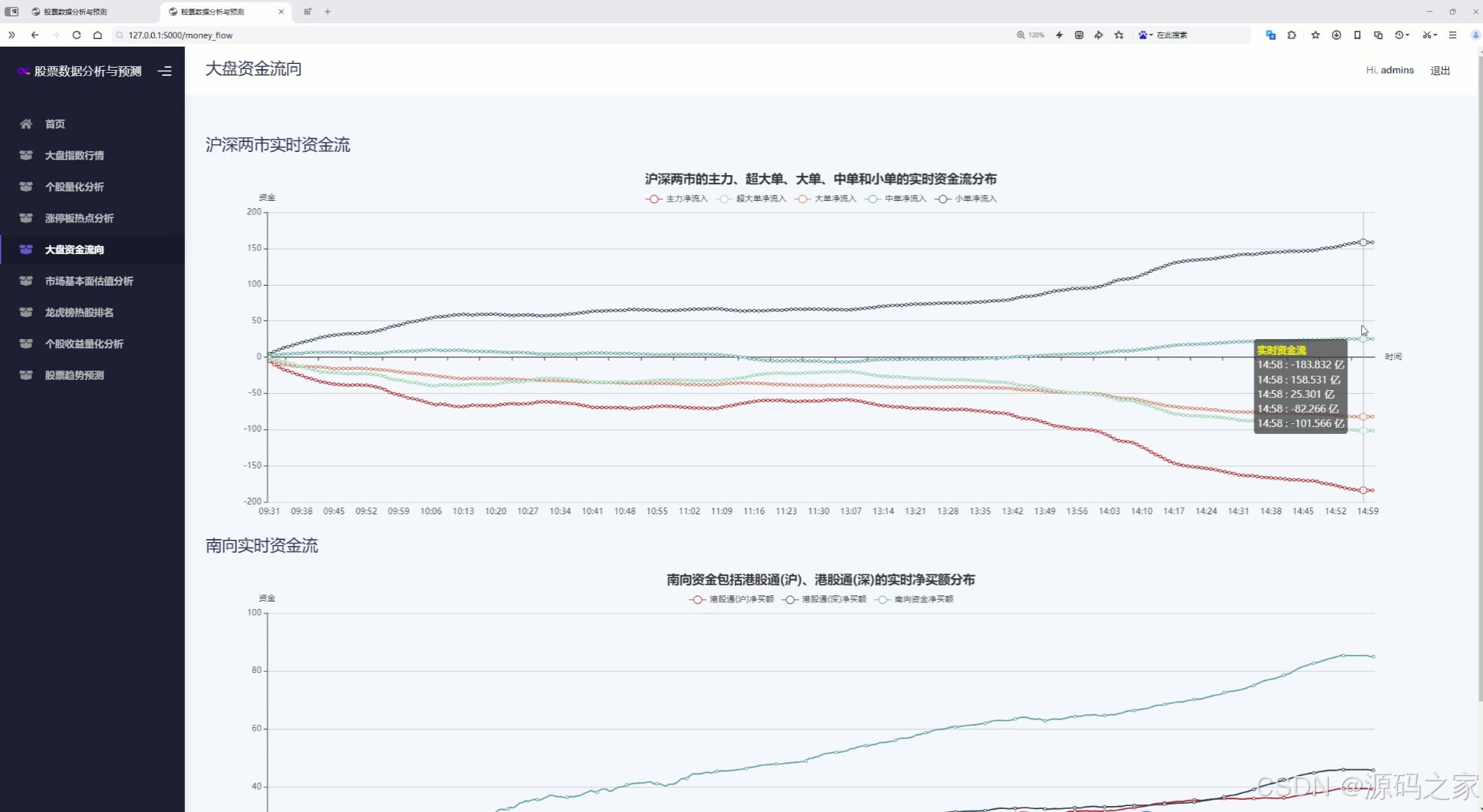
(5)大盘资金流向分析---沪深两市实时资金流向、南向实时资金流向
该页面是大盘资金流向分析模块,包含沪深两市主力及各单量级别的实时资金流分布折线图,以及南向资金实时净流入分布折线图,可直观展示不同口径资金的实时流向与趋势变化。
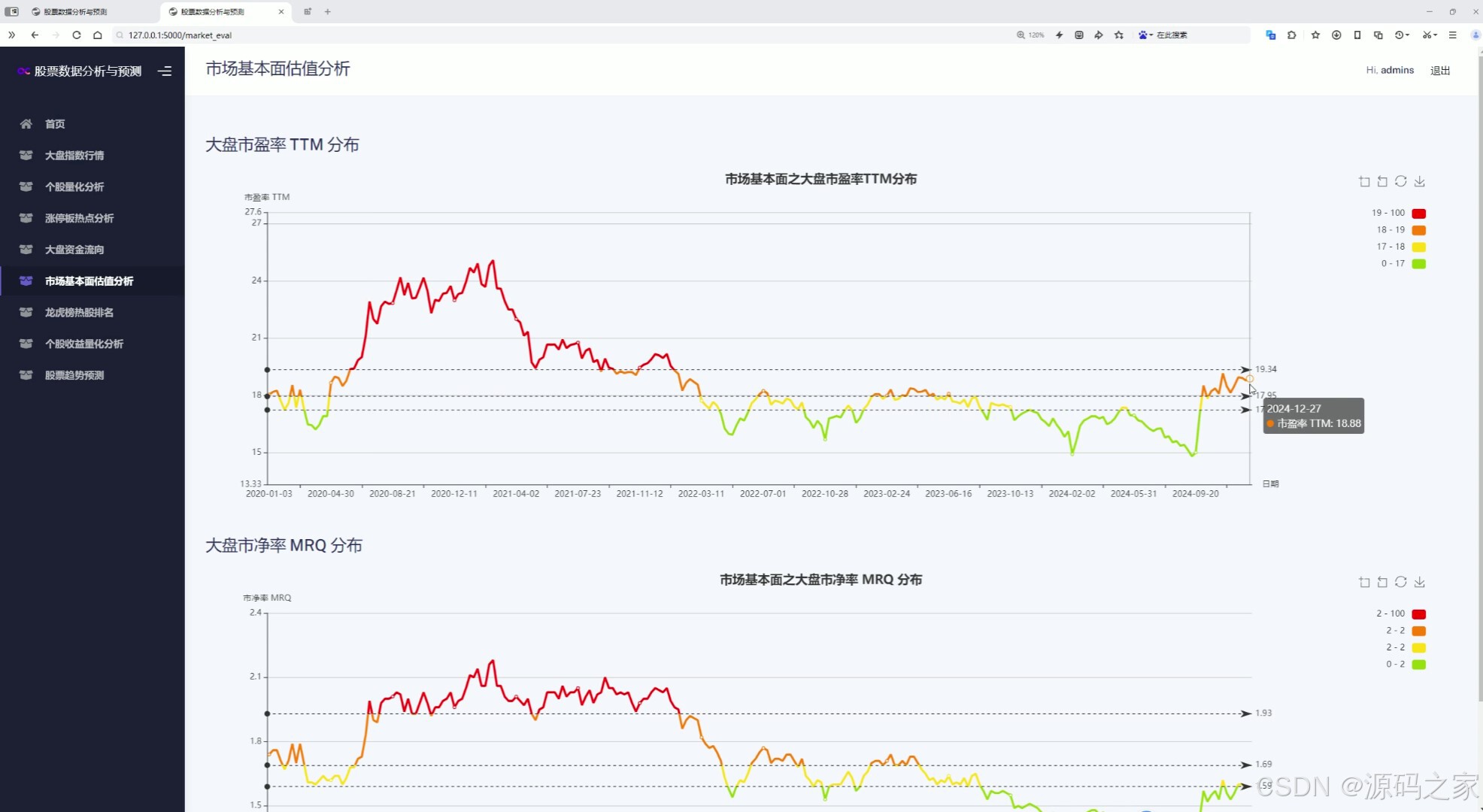
(6)大盘市场基本面估值分析----市盈率分布、市净率分布
该页面是市场基本面估值分析模块,包含大盘市盈率TTM分布和市净率MRQ分布两张折线图,用不同颜色分段展示指标随时间的变化趋势,直观呈现市场整体估值水平的历史波动情况。
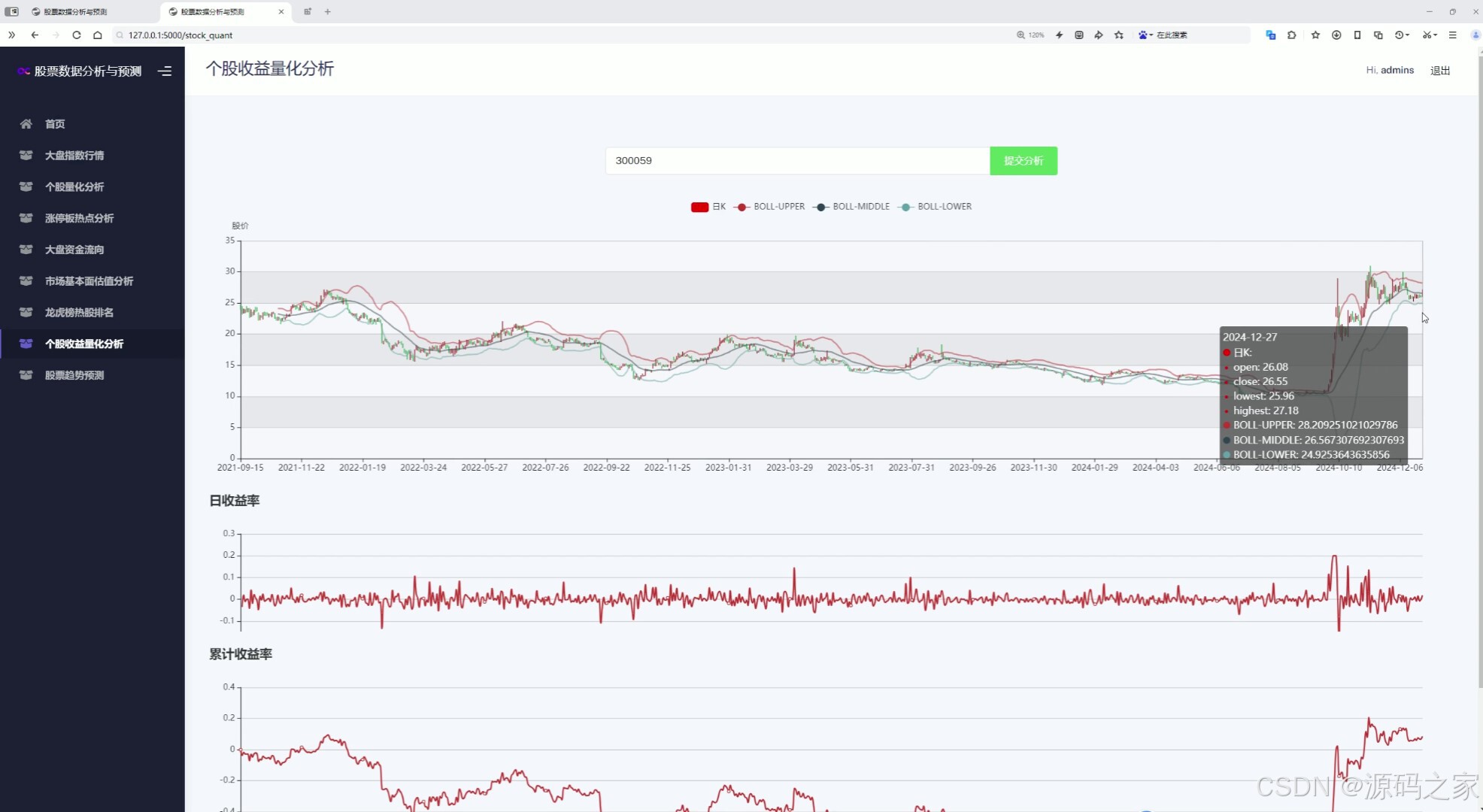
(7)个股收益量化分析---日收益率、月收益率、累计收益率
该页面是个股收益量化分析模块,可输入股票代码提交分析,图中包含叠加了布林带指标的日K线走势,以及日收益率和累计收益率的变化折线图,用于直观展示个股价格波动与收益情况。
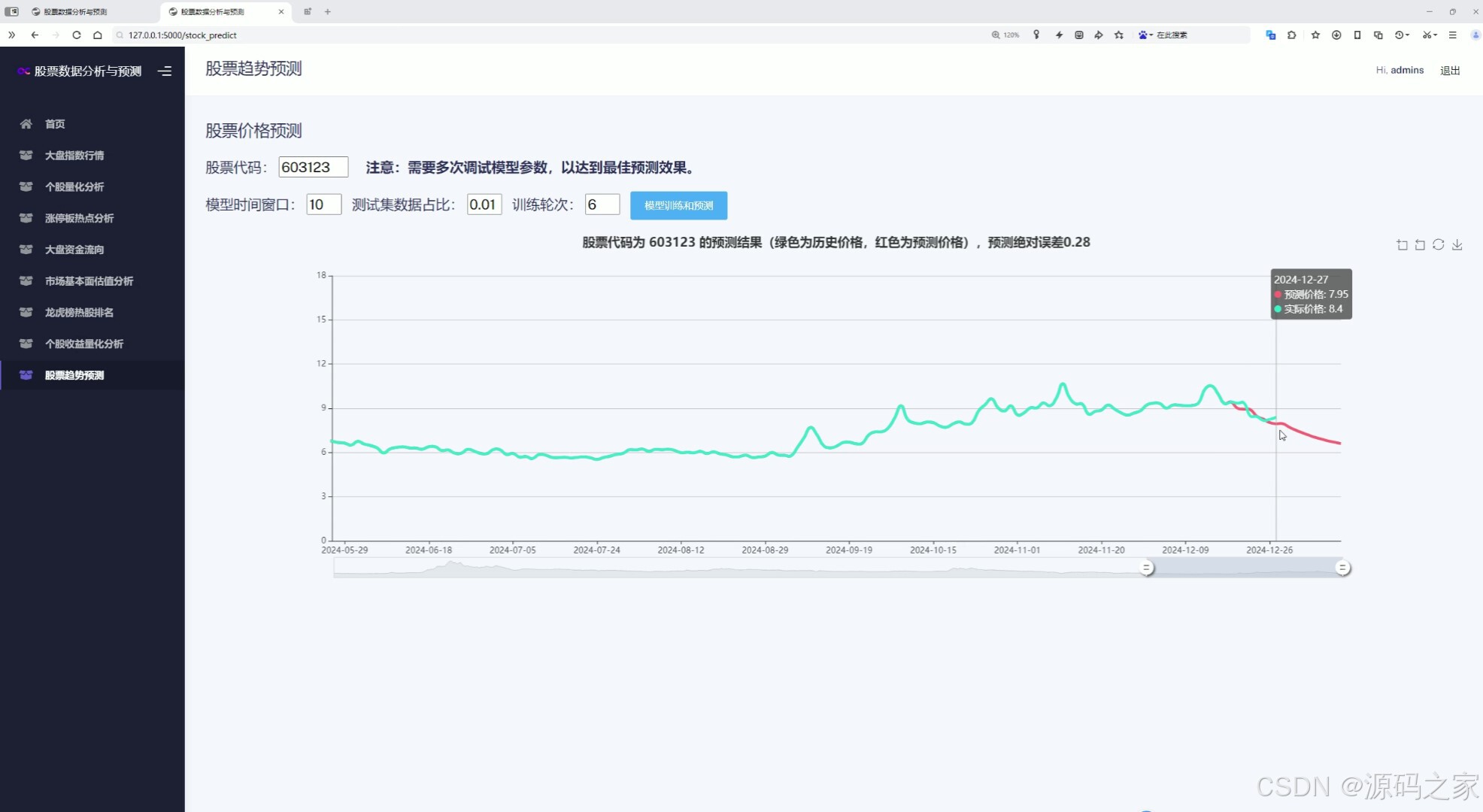
(8)股票价格预测----输入特征值:股票代码、模型时间窗口、测试集占比、训练轮次
该页面是股票趋势预测模块,可设置股票代码及模型参数并提交训练预测,图中用不同颜色的折线分别展示个股的历史价格走势与预测价格走势,直观呈现模型对未来价格趋势的预测结果。
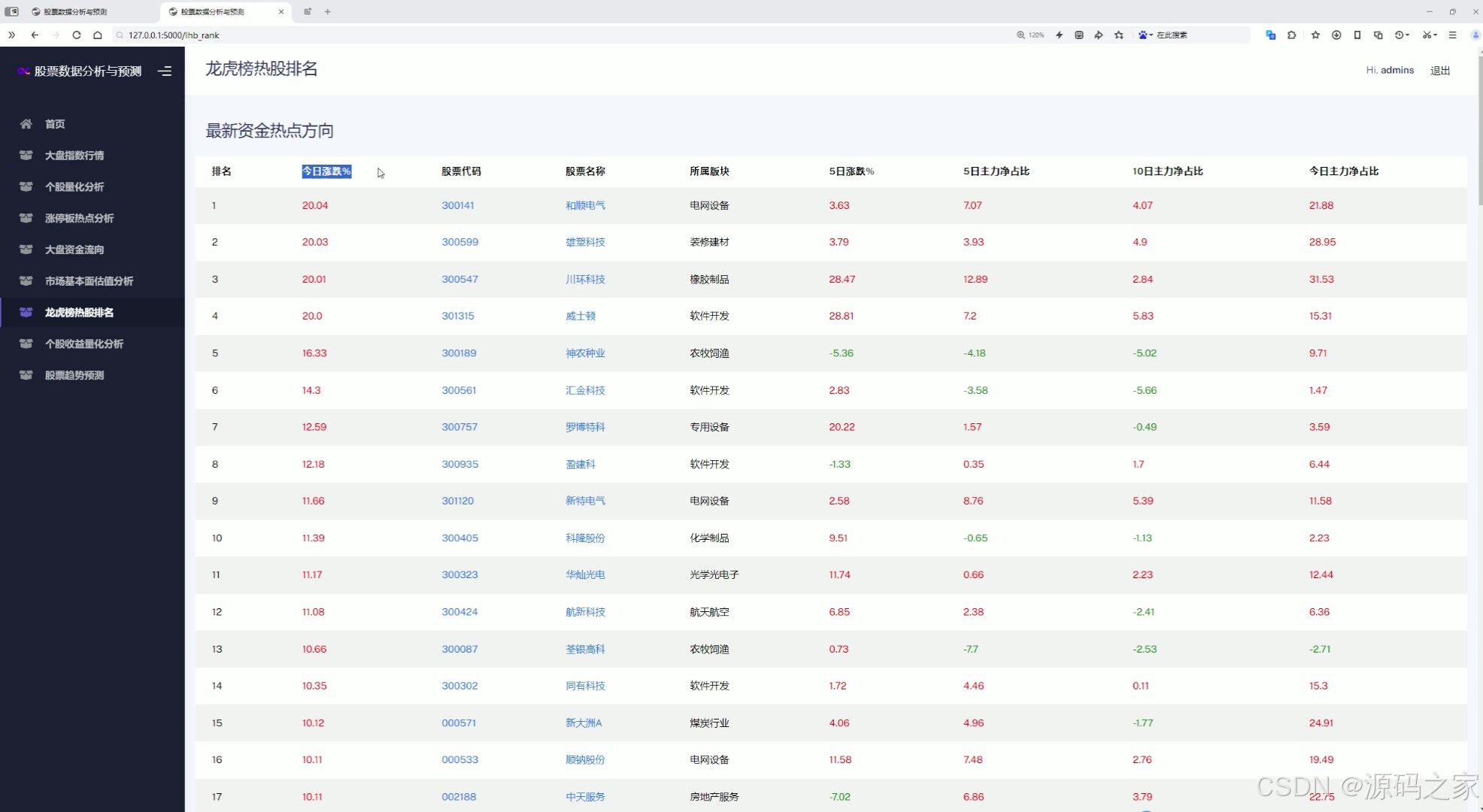
(9)龙虎榜热股排名
该页面为龙虎榜热股排名模块,通过表格形式展示最新资金热点方向,包含个股排名、涨跌幅、股票代码、所属板块及多日主力资金占比等信息,便于用户快速了解市场热门个股及资金动向。
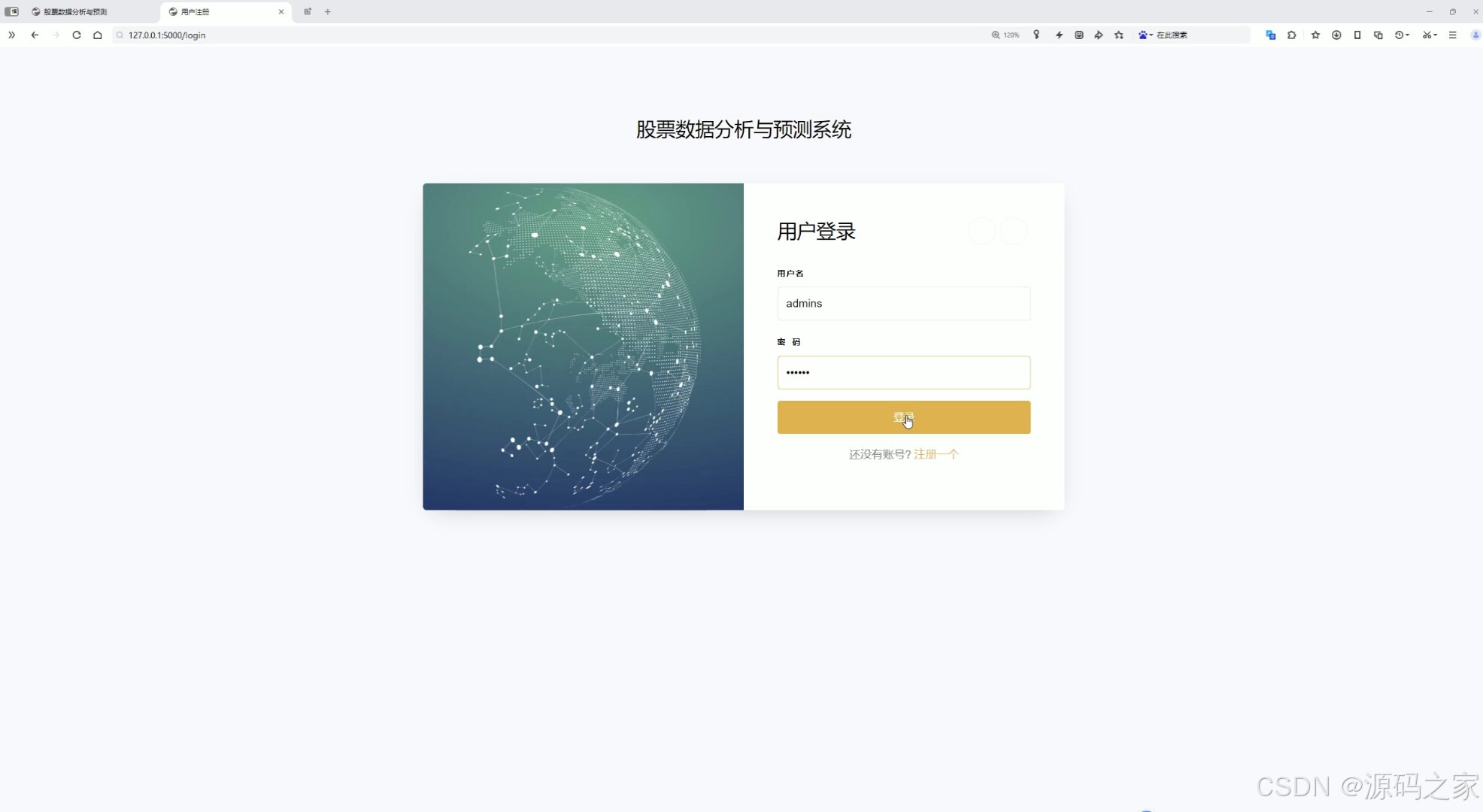
(10)注册登录模块
该页面是股票数据分析与预测系统的用户登录界面,提供用户名和密码输入框、登录按钮及注册入口,用户可通过输入账号密码完成身份验证以进入系统,保障数据与功能的访问权限。
3、项目说明
一、技术栈说明
本系统后端采用Python语言与Flask轻量级Web框架进行开发,核心预测功能基于Tensorflow框架搭建LSTM神经网络算法模型,用于股票价格趋势预测。数据层面通过爬虫技术从东方财富获取实时及历史行情数据,并借助scikit-learn机器学习库完成数据预处理、特征工程及标准化处理。前端可视化采用Echarts图表库实现交互式数据展示,配合HTML构建用户界面。整体架构涵盖数据采集、模型训练、量化分析及可视化展示等环节。
二、功能模块详细介绍
-
涨停板热点分析
该模块提供当日市场热点板块的全面分析。界面包含热点行业板块涨停板数量分布直方图,直观展示各行业涨停股票数量差异;不同行业板块成交额占比饼图,反映资金在各板块间的分配情况;以及当日涨停股票池表格,列出涨停个股的详细信息。用户可按日期切换查询,快速捕捉市场热点动向。
-
首页功能模块介绍
首页采用左侧导航栏与右侧内容区域的布局设计,右侧通过卡片模块形式展示了系统的四项核心功能,包括股票数据采集、大盘与板块分析、个股诊断分析、可视化交互分析平台,每项功能均配有相关分析图示,帮助用户快速了解系统能力并导航至相应功能页面。
-
大盘指数行情分析
本模块支持用户切换查看上证指数、深证成指、创业板指、中小板指及沪深300指数等主要股指。界面展示各指数的日K线历史走势图及成交量数据,并叠加多条均线指标,直观呈现指数价格趋势与成交量的变化关系,便于用户进行技术面分析。
-
个股量化分析
用户输入股票代码后,系统对该个股进行全方位分析。界面展示个股的日K线历史走势、均线指标及成交量数据,同时提供公司简介及主要财务指标信息,涵盖市盈率、市净率等基本面数据,帮助用户综合评估个股的投资价值。
-
大盘资金流向分析
该模块提供沪深两市主力及各单量级别的实时资金流分布折线图,同时包含南向资金实时净流入分布折线图。用户可直观观察不同口径资金的实时流向与趋势变化,判断市场资金动向和主力态度。
-
大盘市场基本面估值分析
本模块展示市场整体估值水平的历史波动情况。包含大盘市盈率TTM分布折线图和市净率MRQ分布折线图,采用不同颜色分段展示指标随时间的变化趋势,辅助用户判断市场当前处于高估或低估区间。
-
个股收益量化分析
用户输入股票代码提交分析后,界面呈现叠加布林带指标的日K线走势图,以及日收益率和累计收益率的变化折线图。该模块直观展示个股的价格波动特征与收益表现,帮助用户评估股票的收益风险特征。
-
股票价格预测
用户可设置股票代码、模型时间窗口、测试集占比及训练轮次等参数,提交后系统调用LSTM神经网络模型进行训练和预测。界面中采用不同颜色的折线分别展示个股的历史价格走势与预测价格走势,直观呈现模型对未来价格趋势的预测结果。
-
龙虎榜热股排名
该模块以表格形式展示最新资金热点方向的龙虎榜个股排名,包含个股排名、涨跌幅、股票代码、所属板块及多日主力资金占比等信息,便于用户快速了解市场热门个股及机构游资的资金动向。
-
注册登录模块
系统提供用户登录界面,包含用户名和密码输入框、登录按钮及注册入口。用户需通过账号密码完成身份验证后方可进入系统,保障数据访问权限和系统安全性。
三、项目总结
本项目整合Python、Flask、Tensorflow、LSTM等多项技术,构建了一个功能完备的股票数据分析与预测平台。系统不仅实现了基于深度学习算法的股票价格趋势预测,还涵盖了涨停板热点捕捉、大盘与个股量化分析、资金流向监控、市场估值评估、龙虎榜热股追踪等多种实用功能。通过Echarts可视化技术将复杂数据以图表形式直观呈现,降低了用户分析门槛。该系统为投资者提供了从数据采集、技术分析到模型预测的全流程工具支持。
4、核心代码
python
#!/usr/bin/python
# coding=utf-8
from flask import jsonify, Blueprint
import pandas as pd
import numpy as np
import json
from service.stock_spider import EastmoneySpider
from service import tech_util
import service.analysis_util as analysis_util
import random
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, LSTM, LSTM
from sklearn.metrics import mean_absolute_error
api_blueprint = Blueprint('api', __name__)
em_spider = EastmoneySpider()
@api_blueprint.route('/search_stock_index/<stock_input>')
def search_stock_index(stock_input):
"""
搜索大盘指数或个股的行情数据
"""
market_type = None
if stock_input == '上证指数':
stock = {'code': '000001', 'name': '上证指数'}
market_type = 1
elif stock_input == '深证成指':
stock = {'code': '399001', 'name': '深证成指'}
elif stock_input == '中小板指':
stock = {'code': '399005', 'name': '中小板指'}
elif stock_input == '创业板指':
stock = {'code': '399006', 'name': '创业板指'}
elif stock_input == '沪深300':
stock = {'code': '399300', 'name': '沪深300'}
elif stock_input == '北证50':
stock = {'code': '899050', 'name': '北证50'}
else:
stock = em_spider.stock_index_search(stock_input)
# 获取该股票的历史数据,前端绘制 K 线图
# 获取历史K线数据
stock_df = em_spider.get_stock_kline_factor_datas(security_code=stock['code'], period='day', market_type=market_type)
stock_df = stock_df[['date', 'open', 'close', 'low', 'high', 'volume']]
stock_df.sort_values(by='date', ascending=True, inplace=True)
kline_data = stock_df.values.tolist()
# 计算 MA 指标
stock_df['MA5'] = tech_util.MA(stock_df['close'], N=5)
stock_df['MA10'] = tech_util.MA(stock_df['close'], N=10)
stock_df['MA20'] = tech_util.MA(stock_df['close'], N=20)
stock_df['MA60'] = tech_util.MA(stock_df['close'], N=60)
stock_df.fillna('-', inplace=True)
return jsonify({
'name': '{}({})'.format(stock['name'], stock['code']),
'dates': stock_df['date'].values.tolist(),
'klines': kline_data,
'volumes': stock_df['volume'].values.tolist(),
'tech_datas': {
'MA5': stock_df['MA5'].values.tolist(),
'MA10': stock_df['MA10'].values.tolist(),
'MA20': stock_df['MA20'].values.tolist(),
'MA60': stock_df['MA60'].values.tolist()
}
})
@api_blueprint.route('/query_jibenmian_info/<stock_input>')
def query_jibenmian_info(stock_input):
"""获取基本面信息"""
stock = em_spider.stock_index_search(stock_input)
zyzb_table, jgyc_table, gsjj, gsmc = em_spider.get_ji_ben_mian_info(stock['code'])
# 股票的核心题材
concept_boards = em_spider.get_stock_core_concepts(stock['code'])
print(concept_boards)
# 概念板块html
concept_html = """
<div class="">
<div class="card-header">
<h3>核心概念板块</h3><hr/>
</div>
<div class="">
<table class="table table-hover" style="table-layout:fixed;word-break:break-all;">
<thead>
<tr>
<th scope="col" width="8%">#</th>
<th scope="col" width="10%">概念板块</th>
<th scope="col" width="70%">概念解读</th>
<th scope="col" width="12%">最新涨幅</th>
</tr>
</thead>
<tbody>
{}
</tbody>
</table>
</div>
</div>
"""
trs = ''
for i, conenpt in enumerate(concept_boards):
trs += """
<tr>
<td>{}</td>
<td>{}</td>
<td>{}</td>
<td style="color: {}">{}%</td>
</tr>
""".format(i+1, conenpt['board_name'], conenpt['board_reason'], 'red' if conenpt['board_yield']>0 else 'green' ,conenpt['board_yield'])
concept_html = concept_html.format(trs)
return jsonify({
'zyzb_table': zyzb_table,
'jgyc_table': jgyc_table,
'gsjj': gsjj,
'gsmc': gsmc,
'concept_boards': concept_html
})
@api_blueprint.route('/limitup_analysis/<trade_date>')
def limitup_analysis(trade_date):
"""涨停板热点分析"""
print(trade_date)
trade_date = trade_date.replace('-', '')
limit_up_stocks = em_spider.get_limit_up_stocks(trade_date=trade_date)
print(json.dumps(limit_up_stocks, ensure_ascii=False))
trs = ''
concept_counts = {}
concept_moneys = {}
for i, stock in enumerate(limit_up_stocks):
if stock['行业板块'] not in concept_counts:
concept_counts[stock['行业板块']] = 0
concept_counts[stock['行业板块']] += 1
if stock['行业板块'] not in concept_moneys:
concept_moneys[stock['行业板块']] = 0
concept_moneys[stock['行业板块']] += stock['成交额']
tr = """
<tr>
<th scope="row">{}</th>
<td><a href="http://127.0.0.1:5000/stock_info?search={}" target="_blank">{}</a></td>
<td><a href="http://127.0.0.1:5000/stock_info?search={}" target="_blank">{}</a></td>
<td style="color:red">{}%</td>
<td>{}</td>
<td>{}</td>
<td>{}</td>
<td>{}</td>
<td>{}</td>
<td>{}</td>
<td>{}</td>
<td>{}</td>
<td>{}</td>
</tr>
""".format(i+1, stock['证券代码'], stock['证券代码'], stock['证券名称'], stock['证券名称'],
round(stock['涨跌幅'], 2), stock['最新价'], round(stock['成交额'] / 100000000, 3),
round(stock['流通市值'] / 100000000, 3), round(stock['换手率'], 2),
round(stock['封板资金'] / 100000000, 3), stock['炸板次数'],
stock['涨停统计'], stock['行业板块'], stock['交易日期'])
trs += tr
# 行业板块数量分布
concept_counts = sorted(concept_counts.items(), key=lambda x: x[1], reverse=True)
print(concept_counts)
concepts = [c[0] for c in concept_counts]
# 行业板块资金流入占比
result = {
'tbody': trs,
'concept': concepts,
'limit_up_count': [c[1] for c in concept_counts],
'concept_moneys': [concept_moneys[c] for c in concepts]
}
return jsonify(result)
@api_blueprint.route('/predict_stock_price/<code>/<look_back>/<test_ratio>/<train_epochs>')
def predict_stock_price(code, look_back, test_ratio, train_epochs):
"""股票价格预测"""
prices_df = em_spider.get_stock_kline_factor_datas(security_code=code, period='day', market_type=None)
prices_df = prices_df.sort_values(by='date', ascending=True)
print(prices_df.head())
test_count = int(float(test_ratio) * prices_df.shape[0])
train = prices_df['close'].values.tolist()[:-test_count]
test = prices_df['close'].values.tolist()[-test_count:]
def create_dataset(prehistory, dataset, look_back):
dataX = []
dataY = []
history = prehistory
for i in range(len(dataset)):
x = history[i:(i + look_back)]
y = dataset[i]
dataX.append(x)
dataY.append(y)
history.append(y)
return np.array(dataX), np.array(dataY)
# 数据集构造
look_back = int(look_back)
trainX, trainY = create_dataset([train[0]] * look_back, train, look_back)
testX, testY = create_dataset(train[-look_back:], test, look_back)
print(trainX.shape, testX.shape)
# 根据参数构建lstm模型
def create_lstm_model():
"""
单层 LSTM 神经网络
"""
d = 0.2
model = Sequential()
model.add(LSTM(16, input_shape=(look_back, 1), return_sequences=False))
model.add(Dropout(d))
model.add(Dense(1, activation='relu'))
model.compile(loss='mse', metrics=['mae'])
return model
model = create_lstm_model()
train_epochs = int(train_epochs)
model.fit(trainX, trainY, epochs=train_epochs, batch_size=4, verbose=1)
# predict
lstm_predictions = model.predict(testX)
lstm_predictions = [float(r[0]) for r in lstm_predictions]
lstm_error = mean_absolute_error(testY, lstm_predictions)
print('Test MSE: %.3f' % lstm_error)
lstm_predictions = train + lstm_predictions
all_time = prices_df['date'].values.tolist()
future_x = []
pred_price = testY[-1]
future_count = 10
i = 0
test_x = prices_df['close'].values.tolist()[-look_back:]
test_x = np.array([test_x])
print('test_x:', test_x)
print('test_x:', test_x.shape)
for future in range(future_count):
i += 1
# ratio = random.random() / 100 if random.random() > 0.5 else -random.random() / 100
# pred_price *= (1 + ratio)
pred_price = model.predict(test_x)[0][0]
pred_price = float(pred_price)
test_x = test_x[0][1:]
test_x = np.append(test_x, pred_price)
test_x = np.array([test_x])
print('test_x:', test_x)
future_x.append(pred_price)
all_time.append(f'未来{i}个交易日')
# print(future_x)
all_data = prices_df['close'].values.tolist()
all_data += [None] * 5
lstm_predictions = lstm_predictions + future_x
return jsonify({'all_time': all_time,
'all_data': all_data,
'add_predict': lstm_predictions,
'test_count': future_count,
'error': lstm_error})