目录
[AI ASIC (Application-Specific Integrated Circuit) ------ 专用集成电路](#AI ASIC (Application-Specific Integrated Circuit) —— 专用集成电路)
[Systolic Array (脉动阵列)](#Systolic Array (脉动阵列))
DSP:数字信号处理

DSP 是一种专门为连续实时流媒体数据(如音频、视频、传感器数据)进行快速数学运算的微处理器。典型代表公司Texas Instruments、Qualcomm。可以理解为:
DSP = 专门处理数字信号的CPU
DSP采用Harvard 架构( 指令和数据空间分开),擅长执行 这种乘累加**(MAC)运算**------ DSP内部有大量MAC单元。它是定量的、指令驱动的,虽然灵活性不如通用CPU,但处理数学函数*(如FFT傅里叶变换、FIR滤波、卷积)*的效率远高于CPU。
GPU是通用并行计算,依赖复杂的缓存层次和调度。而DSP专门做信号处理 ,没有复杂控制逻辑、图形流水线、缓存层级等限制,因此具有功耗低、高性能的特点。
VLIW(Very Long Instruction Word),普通CPU一条指令执行一个操作(如 ADD R1, R2, R3),而DSP里的VLIW一条指令执行多个操作(如 ADD | MUL | LOAD | STORE),一条VLIW指令可以触发多个MAC单元,硬件不需要去分析指令间的依赖关系(这部分工作交给了编译器),所以硬件结构可以做得非常简单、省电。
DSP编程和调试困难。DSP需要手动优化并行(比如要考虑流水线冲突、缓存访问、寄存器使用、延迟槽等),不像CPU-编译器自动处理。为了压榨性能,开发者往往需要手写汇编或使用复杂的内置函数 (Intrinsics)------ 由于 VLIW 的并行性是显式的,开发者必须精确管理时槽(Slot),一旦发生内存冲突(Bank Conflict),性能会断崖式下跌。另外,VLIW 架构对编译器的依赖度极高。如果编译器不够"聪明",无法有效打包指令,那么硬件的并行能力就会被荒废。
FGPA:可编程阵列

FPGA = 可以重新编程的硬件
LUT (Lookup Table): FPGA 并不是像 CPU 那样执行指令,而是利用"查找表"来模拟逻辑门。你想实现一个复杂的数学函数?FPGA 会通过配置 LUT 和触发器(Flip-Flop)++在物理上连出一套专属于这个函数的电路++。
举个例子,计算:y=a*b+c
在CPU里就是执行:y = a*b + c; 这个语句,而在FPGA里需要搭一个乘法器+加法器形成硬件电路,所以其执行速度非常快。
可配置连接 (Routing): 就像面包板上的跳线,FPGA 内部有极其复杂的布线资源,允许你把成千上万个逻辑单元连接成任意形状。
在 Python 或 C 中,代码是顺序执行的;在 Verilog 中,所有代码块(always 块)在时钟边沿触发时是同时发生的,因而它可以实现极致的并行。如果你需要同时计算 1000 个加法,CPU 需要循环,而 FPGA 可以直接在芯片表面铺设 1000 个加法器电路。
FPGA开发流程:代码 → 综合 → 布局 → 布线 → 生成比特流,FPGA 厂商(如 AMD/Xilinx 或 Intel/Altera)的开发软件极其庞大且闭源。如果遇到软件本身的 Bug(例如布线器跑挂了),开发者往往无能为力。
此外,因为工具要做:生成逻辑电路→放置逻辑单元→规划连线→优化时序一系列工作,类似于自动设计芯片,所以编译需要很长时间,可能编译几个晚上都是常态。
这里需要区分一下:
FPGA慢在编译,在开发阶段 把所有的复杂性都消化掉了,从而换取了运行阶段极致的响应速度和能效比。

AI ASIC (Application-Specific Integrated Circuit) ------ 专用集成电路

ASIC 是为了某一特定应用而定制生产 的芯片。AI ASIC(如 Google 的 TPU、华为的昇腾)是专门为深度学习设计的。因为只做AI计算,它比GPU更快、省电、小面积。
核心特性: 硬件逻辑在出厂时就已固化,无法更改。
优势: 针对特定算法(如 Transformer 或 CNN)进行了极致优化。在能效比 (Performance/Watt) 和单位成本上是所有架构中最强的。
劣势: 研发周期长(2-3年),研发成本极高(千万美金起步),且一旦算法架构发生巨大变迁(如从 CNN 转向全新的拓扑),芯片可能面临淘汰。
Systolic Array (脉动阵列)
它并非一种独立的芯片,而是一种芯片内部的计算结构。它是大多数 AI ASIC(如 TPU)实现矩阵乘法(GEMM)的核心。
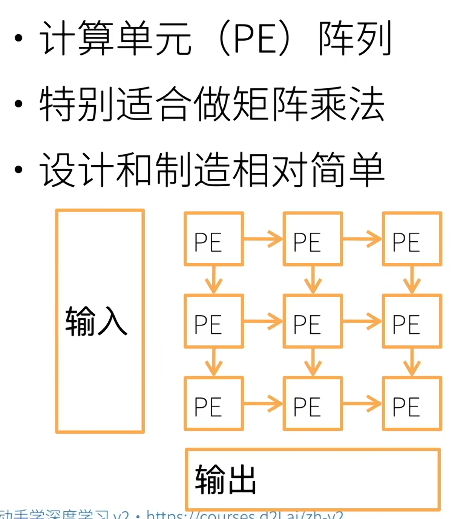
- 工作原理: 数据像血液经过心脏脉动一样,在处理单元(PE)阵列中流动。每个单元接收上方和左侧的数据,计算后传给下方和右侧。典型结构:
|---------------------------------|-------------------|
| A → → → ↓ ↓ ↓ → → → ↓ ↓ ↓ → → → | 每个节点:乘法 + 加法 同时工作 |
- 核心逻辑: 减少内存访问。传统计算中,每做一次加法都要去内存读一次数据;在脉动阵列中,数据进入阵列后会被重复使用多次,极大地解决了"存储墙"带来的带宽瓶颈。
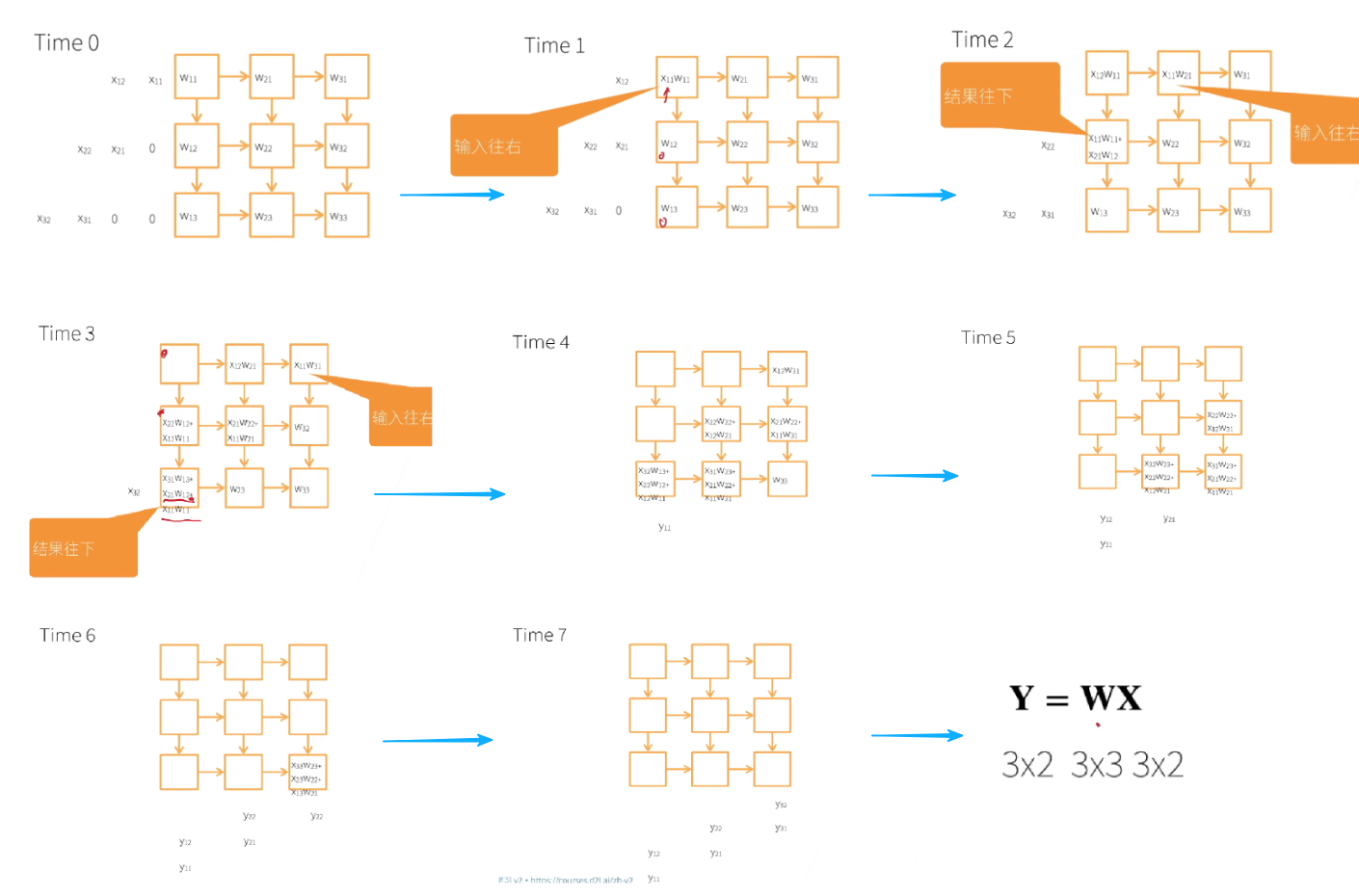
//案例:下面是一个矩阵乘法流程图。在Systolic Array中,所有元素同时计算

总结

通用性高 ←------------------------------------------→ 专用性高
CPU→GPU → DSP → FPGA → AI ASIC
↓
Systolic Array(常作为AI ASIC内部结构)
- DSP:专门优化数字信号处理
- FPGA:可重构硬件,非常灵活
- AI ASIC :为AI专门设计的芯片,Systolic Array是AI芯片内部常见的计算结构(不是芯片类型,而是架构)