文献介绍

文献题目: scMarkerAgent:基于大语言模型证据智能体的细胞标志物图谱
研究团队: 曹晨(南京医科大学)
发表时间: 2026-04-06
发表期刊: 预印本
DOI: 10.21203/rs.3.rs-9224570/v1
摘要
基于证据增强且可靠的细胞类型注释仍然是单细胞 RNA-seq 分析中的主要瓶颈,尤其是对于稀有细胞、过渡态细胞及疾病相关细胞群体。为解决这一问题,作者提出了 scMarkerAgent ,一个基于证据的细胞标志物资源库,该资源利用大语言模型辅助的文献整理框架构建而成。它整合了 294,692 篇全文出版物,提供了 890,296 条高质量的细胞类型-标志物注释,涵盖人、小鼠和大鼠的 50,233 种细胞类型。scMarkerAgent 还整合了 82,165 条经过整理的负向标志物注释以及 417,812 条疾病背景注释,从而提高了同源细胞类型的分辨能力以及恶性细胞的识别能力。每条细胞类型-标志物注释均有句子层面的文献证据直接支持。在细胞注释流程中,候选标签会通过基于大语言模型的推理步骤进一步优化,该步骤同时结合正向和负向标志物进行综合评估。与现有资源相比,scMarkerAgent 在标志物、组织、细胞类型及疾病方面的覆盖范围更广。该资源已作为一个符合 FAIR 原则的数据库发布,并附带一个无需编程的网络平台,支持标志物检索、自动化细胞注释以及可自定义的细胞评分(访问地址: https://www.markeragent.net)。
前言
单细胞 RNA 测序(scRNA-seq)彻底改变了人们对健康和疾病状态下细胞异质性的研究。scRNA-seq 分析中的一个关键步骤是细胞类型注释,它从根本上影响了对谱系组成、细胞状态及疾病相关细胞群体的下游解读。然而,准确且可靠的注释仍然具有挑战性,尤其是在存在稀有亚型、过渡态细胞或疾病特异性转录程序的情况下。
在实践中,细胞注释得到多种计算策略的支持,包括参考图谱映射、基于标志物的方法,以及近期兴起的大语言模型辅助工作流程。其中,基于标志物的细胞类型注释因其不依赖于匹配的参考数据集且具有直接的生物学可解释性而仍然被广泛采用。然而,其准确性关键取决于标志物知识的完整性、质量和可用性,并且该过程通常仍需要专家验证。
为了支持基于标志物的注释,研究者已开发了多个经过整理的标志物资源和工具,例如 CellMarker Accordion (CMA)、CellMarker 2.0 和 Annotation of Cell Types (ACT)。尽管这些资源提高了可及性,但仍面临显著的实际局限性。第一,人工整理难以跟上迅速扩增的文献,导致更新缓慢且对新描述的细胞亚型(尤其是在疾病背景下的亚型)覆盖不全。第二,可重复性常受阻碍,因为许多资源仅报告细胞类型-标志物关联及其来源文献,却常常省略原文中支持这些论断的确切句子。缺乏直接的文本证据使得验证关键的背景细节(如组织特异性、疾病背景或实验条件)变得困难,也增加了解决不同研究间冲突注释的复杂性。最后,大多数现有资源主要关注正向标志物,对负向标志物的支持有限,尽管预期不表达的标志物可以提高注释的特异性,尤其是当密切相关的细胞群体共享重叠的正向标志物特征时。
基于大语言模型的方法已被探索用于减少细胞类型注释所需的工作量和专业知识。特别是,基于 AI 智能体的方法结合了专门注释算法和大语言模型增强知识检索的优势,提供了可解释、可验证且适应性强的流程。然而,依赖大语言模型作为生物学知识的主要来源引发了对其训练数据透明度与可追溯性、易产生幻觉和偏见的可能性,以及输出非确定性的担忧,这些因素都使评估和可重复性变得复杂。这些局限性催生了一种替代范式:将大语言模型用作从文献中提取可验证证据并基于这些证据进行推理的智能体,而不是将其作为缺乏来源的、不透明的知识库。
研究结果
1. 基于多智能体框架的大规模文献检索细胞标志物注释
作者收集了 294,692 篇全文出版物 ,并采用一个提取智能体(Extract Agent) 获取了 1,352,754 条候选细胞类型-标志物记录 。每条记录包含结构化字段,涵盖组织、细胞类型、疾病、物种、标志物及其极性,并与句子层面的文献证据相关联,以确保端到端的可追溯性。随后,应用一个独立的质量控制智能体(QC Agent) ,依据六条强制性规则对每条候选记录进行验证。经过质量控制过滤并将数据集限定为三种模式物种(人、小鼠和大鼠)后,保留了 890,296 条高置信度的记录 用于下游分析(Fig. 1A)。
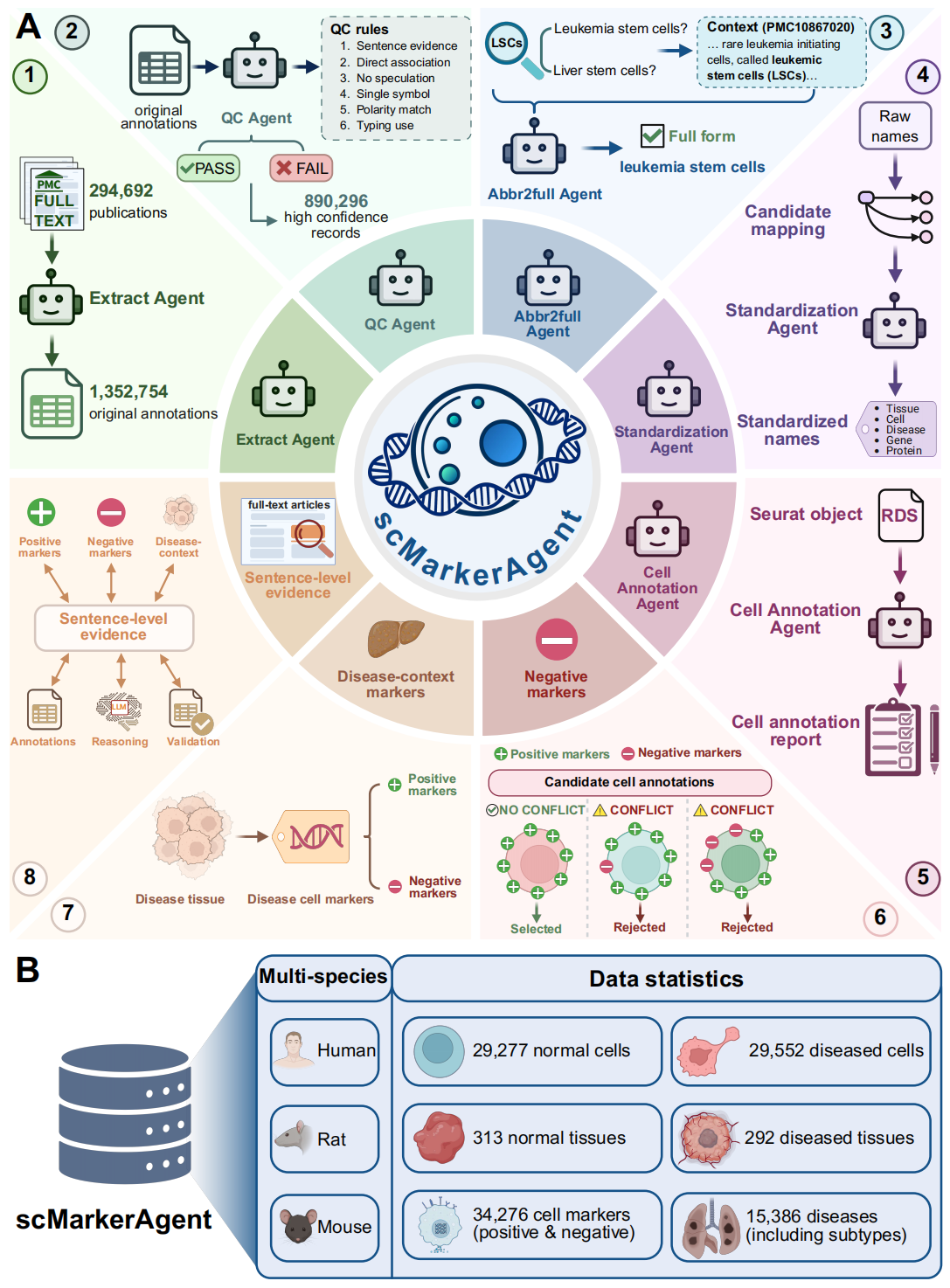
Figure 1. scMarkerAgent 概览
(A) scMarkerAgent 多智能体框架及核心功能。采用四个基于大语言模型的智能体,提取智能体(Extract Agent)、质量控制智能体(QC Agent)、简称转全称智能体(Abbr2full Agent)和标准化智能体(Standardization Agent),来支持基于证据的知识构建,同时将细胞注释智能体(Cell Annotation Agent)集成到网络平台中,用于自动化细胞注释和报告生成。重点突出三个关键特征:句子层面的证据、疾病背景标志物以及负向标志物。
(B) scMarkerAgent 的多物种汇总统计。
为减少文献中异质性简称所带来的错误,作者引入了一个简称转全称智能体(Abbr2full Agent) ,利用出版物的特定上下文来扩展组织和细胞类型的缩写(例如,在必要时将"LSCs"解析为 leukemia stem cells 而非 liver stem cells),从而在下游标准化处理之前提高名称的一致性(Fig. 1A)。
鉴于不同研究之间命名法的异质性可能阻碍跨数据集的整合,作者执行了候选映射,并随后应用了一个标准化智能体(Standardization Agent) 。该智能体将原始名称标准化为规范术语,同时在无法精确匹配时保留非标准名称(Fig. 1A)。组织按照 Uberon Ontology 进行标准化,细胞类型映射到细胞本体(Cell Ontology),疾病与疾病本体(Disease Ontology)对齐。标志物名称通过 NCBI 资源进行标准化,并在适用情况下链接到 Entrez 和 Ensembl 等标识符,从而提高了不同研究之间注释的一致性。
在当前发布的版本中,scMarkerAgent 涵盖三个物种,并在正常和疾病背景下提供了广泛的覆盖范围,包括 29,277 条正常背景下的细胞注释 、29,552 条疾病背景下的细胞注释 、313 种正常组织 、292 种患病组织 、34,276 种细胞标志物 以及 15,386 种疾病 (Fig. 1B)。
2. scMarkerAgent:一个符合 FAIR 原则、经文献整理的细胞标志物数据库
基于上述由智能体整理的数据,作者开发了 scMarkerAgent 网络平台,用于细胞类型注释和资源检索(访问地址:https://www.markeragent.net)。该平台按照 FAIR(可查找、可访问、可互操作、可重用)原则设计,所有注释均来源于经过系统整理、证据验证的文献;每条条目均可完全追溯至其原始来源,确保了透明度和可靠性。
作者将 scMarkerAgent 设计为一个交互式、无需编程的平台,支持三个紧密集成的工作流程:跨物种、组织、细胞类型、疾病和标志物极性的标志物检索与浏览(Supplementary Fig. 1);针对用户上传数据集的基于证据的细胞类型注释(Fig. 2A,B);以及针对用户指定细胞类型的可自定义细胞评分,支持使用正向或负向标志物(Fig. 2C,D)。
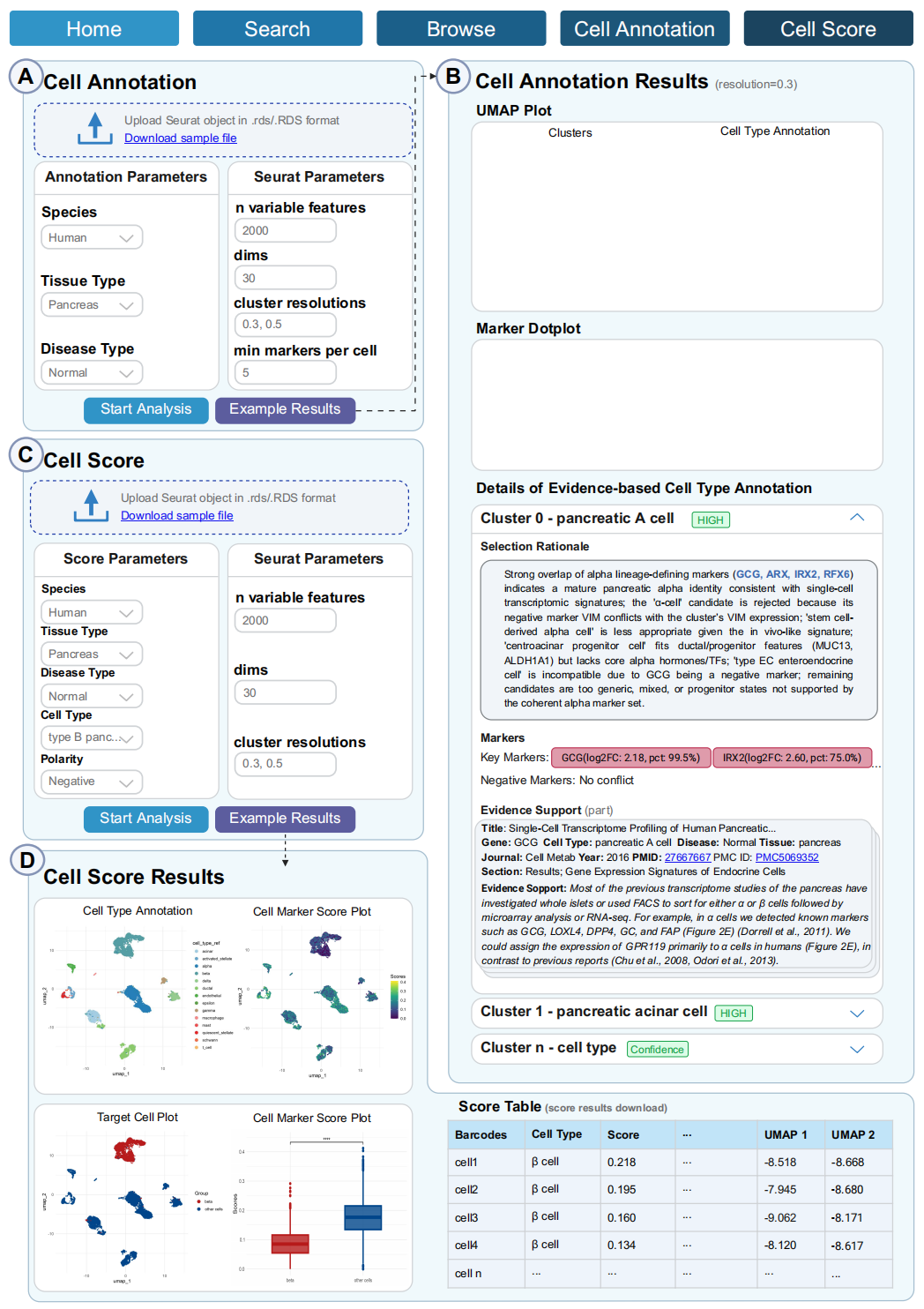
Figure 2. scMarkerAgent 的细胞注释和细胞评分页面
(A) 细胞注释页面允许用户上传 Seurat 对象,并使用细胞注释智能体(Cell Annotation Agent)设置注释相关参数及 Seurat 参数以进行细胞注释。
(B) 细胞注释结果页面显示基于聚类和细胞类型注释的 UMAP 图,以及展示细胞-标志物关系的标志物点图。对于每个聚类,结果提供基于证据的细胞类型注释的详细信息。
(C) 细胞评分页面允许用户上传 Seurat 对象,并设置评分相关参数及 Seurat 参数,以对指定细胞类型进行评分。
(D) 细胞评分结果页面以图表和表格形式呈现评分结果。
对于基于证据的细胞类型注释,细胞注释模块允许用户上传 Seurat 对象(Fig. 2A)。候选细胞类型标签首先通过 ScType 生成,随后一个基于大语言模型的注释智能体执行基于证据的选择,并生成一份可解释的报告(Fig. 2B)。在此过程中,正向标志物提供支持信号,而负向标志物则作为排除约束,在标志物存在冲突时标记出生物学上不合理的候选类型,从而改善对密切相关或过渡态细胞群体的区分能力。
细胞评分模块使用户能够对数据库中感兴趣的细胞类型进行自定义评分(Fig. 2C)。它利用正向标志物特征来帮助识别目标细胞群体,并在必要时利用负向标志物特征来帮助排除混杂群体。评分结果以图表和表格形式呈现(Fig. 2D)。
重要的是,整个工作流程可以在线完成,无需专门的计算技能,这使得 scMarkerAgent 对不同背景的用户都易于使用。交互式报告会自动生成,有助于在一个简洁、用户友好的环境中快速验证和迭代优化注释结果。
3. scMarkerAgent 基准测试评估
为了评估 scMarkerAgent 的性能,作者将其与三个已发表的高质量参考图谱:Cell Marker Accordion (CMA)、CellMarker 2.0 和 Annotation of Cell Types (ACT),在 15 个不同维度上进行了系统比较(详见方法部分)。首先,虽然 CMA 是通过整合 23 个现有细胞标志物数据库和细胞分选资源构建而成,但 scMarkerAgent 包含的总注释数量约为 CMA 的 3.66 倍,并且远超人工整理的 CellMarker 2.0 和 ACT(Fig. 3A)。其次,scMarkerAgent 在这四个数据库中覆盖了最多的独特标志物(Fig. 3B)。尽管 CellMarker 2.0 和 ACT 也从文献中整理细胞标志物并进行了最终整合,但每个数据库整合的出版物数量均少于 10,000 篇。相比之下,scMarkerAgent 包含的出版物数量约为 CellMarker 2.0 的 17.74 倍,约为 ACT 的 34.89 倍。由于 CMA 不提供文献来源注释,其该项计数为零(Fig. 3C)。
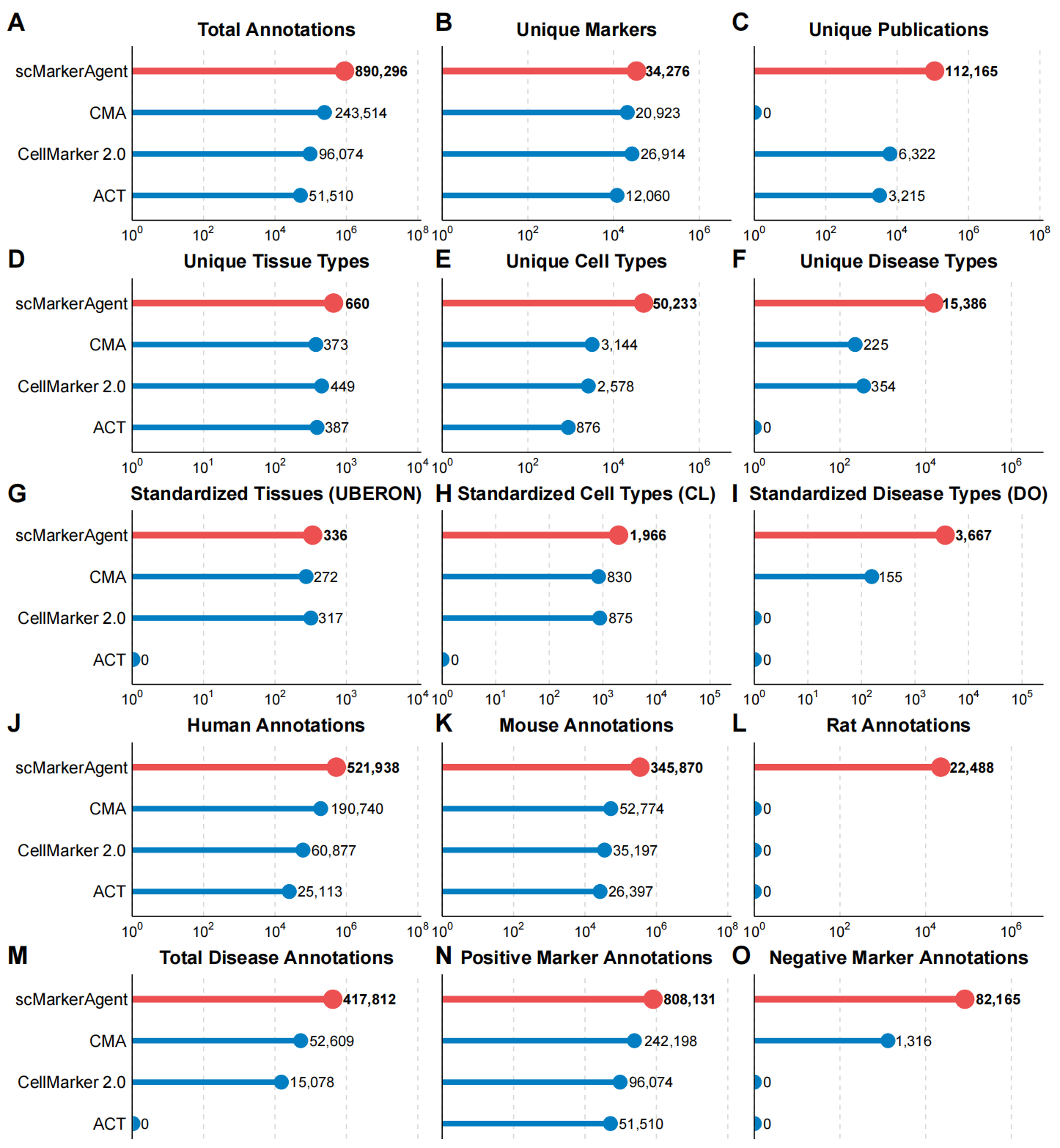
Figure 3. scMarkerAgent 与 CMA、CellMarker 2.0 及 ACT 在 15 个维度上的比较
此外,scMarkerAgent 包含的组织、细胞类型和疾病数量均显著高于其他三个数据库(Fig. 3D-F)。考虑到不同研究中对相同生物实体的命名可能存在不一致性,作者分别使用 Uberon Ontology、Cell Ontology 和 Disease Ontology 对组织、细胞和疾病名称进行了标准化,同时保留并合并了非标准化的名称(详见方法部分)。值得注意的是,scMarkerAgent 中组织、细胞类型和疾病的总计数以及标准化计数均更高,从而为细胞注释和下游分析提供了更广泛的参考覆盖范围(Fig. 3G-I)。
在物种覆盖范围方面,scMarkerAgent 为人、小鼠和大鼠提供的注释均多于其他数据库,并且独占地包含了大鼠注释,这是其他资源未涵盖的模式物种(Fig. 3J-L)。此外,scMarkerAgent 包含的来源于疾病样本的注释数量最多,是排名第二的 CMA 的 7.94 倍,为病理背景下的细胞类型注释提供了更大的疾病相关参考资源(Fig. 3M)。scMarkerAgent 还包含数量最多的正向标志物注释(Fig. 3N)以及数量最多的负向标志物注释(Fig. 3O),这对于区分高度相似的细胞类型可能非常有用。
4. scMarkerAgent 提供更准确的细胞类型-标志物注释
为了评估 scMarkerAgent 衍生注释的准确性和完整性,作者在涵盖不同组织、物种和疾病背景的多种 scRNA-seq 数据集上,对基于标志物数据库的工作流与一种无数据库、仅用大语言模型的注释工作流进行了基准测试。为了实现基于标志物资源的有对照比较,作者采用 ScType 作为基于标志物数据库工作流的统一注释算法。ScType 支持用户自定义的标志物输入,并通过基于特异性的方法在各聚类和候选细胞类型之间进行加权,从而整合正向和负向标志物。具体而言,作者比较了使用 ACT、CellMarker 2.0、CMA 和 scMarkerAgent 中标志物的 ScType 方法。此外,作者还评估了一个细胞注释智能体工作流(ScType+scMarkerAgent+LLM),这是一个两阶段的聚类水平框架:首先,ScType 使用来自 scMarkerAgent 且与物种、组织和疾病匹配的标志物,对每个聚类的候选细胞类型进行排序;然后,大语言模型通过解读候选列表、重叠的正向和负向标志物及其在相关生物学背景中的支持证据,来选择最终的细胞类型身份(详见补充说明1)。同时,在适用的情况下,将 CASSIA 作为无数据库、由大语言模型驱动的注释工作流进行了基准比较。
作者组装了基准数据集,包括正常人外周血单个核细胞、正常人肺、正常人和小鼠胰腺、小鼠2型糖尿病胰腺、大鼠肺以及人胶质母细胞瘤。所有数据集均使用 Seurat v5.3.0 流程进行处理。为确保不同研究之间的可比性,作者在聚类水平上评估注释,并将每个聚类的真实标注定义为该聚类中经作者验证或专家共识认可的最主要细胞类型。根据先前描述的评分方案,每个预测注释被赋予1分、0.5分或0分,分别对应于与真实标注完全匹配、部分匹配或不匹配。
作为示例,作者在一个已发表的人肺单细胞图谱(584,944 个细胞)上评估了这些工作流,该图谱为 24 个细胞聚类提供了作为真实标注的专家共识注释。所有方法在主要谱系水平上(上皮、免疫、基质及其他)均达到了高度一致性,但在精细亚型分辨率和错误率方面观察到了明显差异(Fig. 4A-F,Supplementary Fig. 2 and Supplementary Tables S1 and S2)。
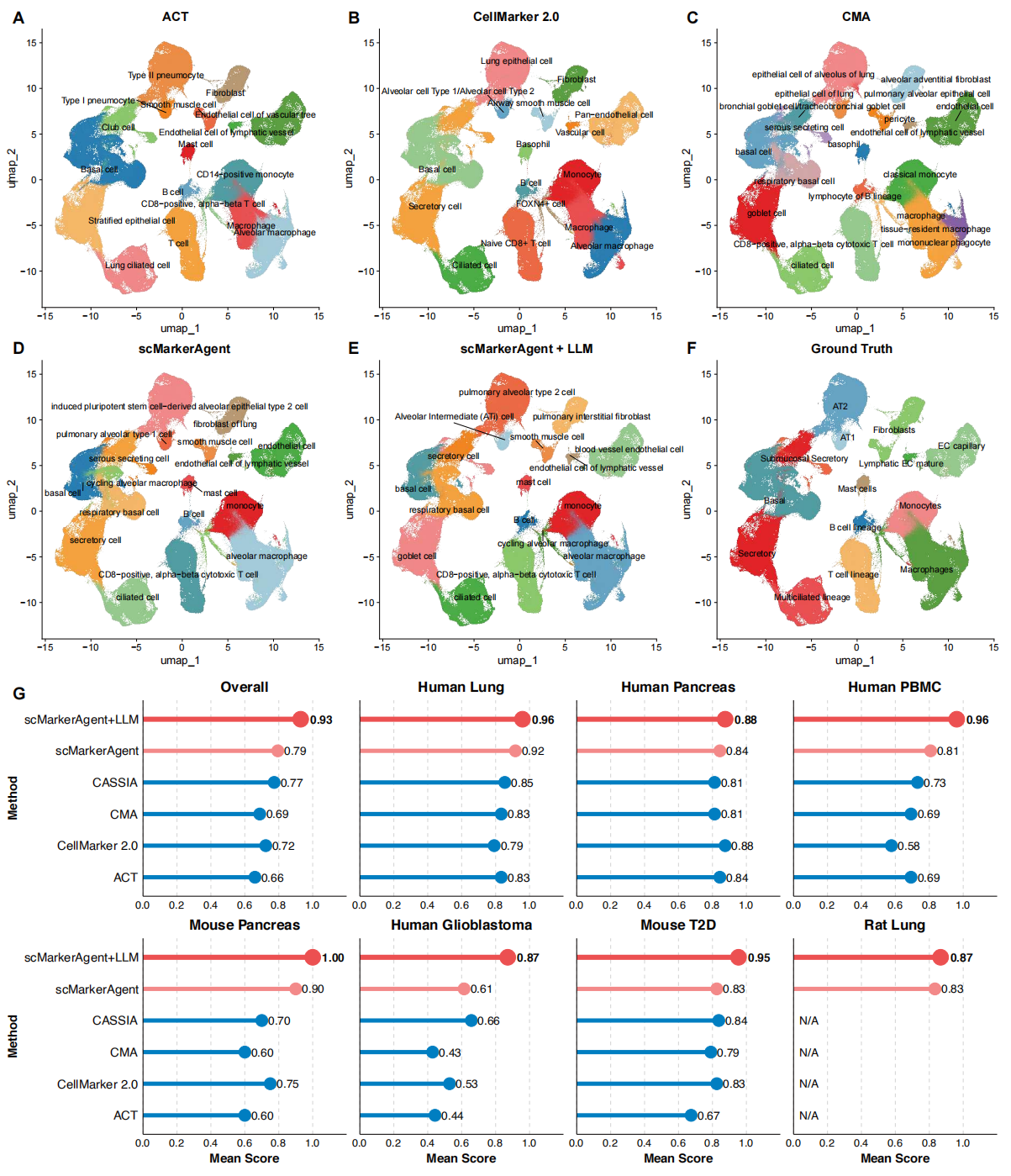
Figure 4. 细胞注释智能体(ScType+scMarkerAgent+LLM)在真实场景细胞类型注释中的表现及其与同类标志物或注释资源的比较
(A) ACT
(B) CellMarker 2.0
(C) CMA
(D) scMarkerAgent
(E) scMarkerAgent+LLM
(F) 作者注释(真实标注)
(G) cMarkerAgent+LLM 工作流与其他数据库或注释工作流的平均注释得分比较。除 CASSIA 外,此处展示的所有方法均为基于 ScType 的工作流;为清晰起见,图表面板标签中省略了"ScType+"前缀。
基准测试结果表明,相对于公共标志物数据库,由 scMarkerAgent 驱动的 ScType 在整个基准测试组中实现了持续较强的注释准确性,并且这种优势通过基于 scMarkerAgent 衍生标志物证据的大语言模型引导优化得到了进一步增强。在人肺数据集(24 个聚类)中,ScType+scMarkerAgent 正确注释了绝大多数细胞聚类(21 个完全匹配、2 个部分匹配和 1 个不匹配),优于所有其他参考数据库。这包括正确识别了其他方法遗漏或错误注释的特化细胞类型。例如,一个增殖性肺泡巨噬细胞群体被 scMarkerAgent 识别出来,而某些基线方法错误地将该聚类注释为增殖性T细胞或未定义的循环细胞。类似地,一个肥大细胞聚类被 scMarkerAgent 准确注释,而两个公共数据库(CellMarker 2.0 和 CMA)将这些细胞错误分类为嗜碱性粒细胞。
随后基于大语言模型的优化解决了初始 ScType+scMarkerAgent 预测中剩余的几个错误。值得注意的是,最初被 ScType+scMarkerAgent 识别为肺泡I型细胞的一个聚类,被大语言模型重新分类为肺泡中间细胞,这与该聚类中同时表达 AT1 和 AT2 标志基因的情况一致。更广泛地说,大语言模型的推理优化基于 scMarkerAgent 检索到的明确句子级证据,表1中提供了具有代表性的支持性参考文献和陈述。在另一个案例中,大语言模型纠正了 ScType+scMarkerAgent 对循环基底上皮细胞的错误分配(原本被错误注释为巨噬细胞),将其正确识别为呼吸道基底细胞。
在其他基准数据集(人 PBMC、人和小鼠胰腺、小鼠 T2D 胰腺、大鼠肺和人胶质母细胞瘤;Supplementary Figs. 3-8)中,ScType+scMarkerAgent 再次实现了与参考注释最高的总体一致性(Fig. 4G):在人 PBMC 和胰腺数据集中,scMarkerAgent 至少 75% 的聚类与真实标注完全匹配,其余聚类获得部分匹配或不匹配评分,且在不同物种间的表现大致一致。例如,在小鼠胰腺数据集中,ScType+scMarkerAgent 对 10 个聚类中的 8 个(80%)实现了完全匹配,没有任何不匹配。相比之下,在胶质母细胞瘤数据集中,所有方法相对于正常组织都表现出准确性下降,ScType+scMarkerAgent 仍然产生了最多与专家一致的注释,但仅有约 46% 的聚类(16/35)完全匹配,约 26% 不匹配,这可能与恶性组织中增加的异质性和状态可塑性有关。值得注意的是,与"整合更多来源必然提高性能"的普遍预期相反,尽管 CMA 整合了包括 CellMarker 2.0 在内的 23 个标志物资源,但在小鼠胰腺和人胶质母细胞瘤基准测试中,其注释得分均低于 CellMarker 2.0,这表明这种整合可能引入了质量较低或不一致的标志物注释。
此外,为了与无数据库、由大语言模型驱动的注释范式进行基准比较,作者纳入了 CASSIA,这是一个最近提出的用于细胞类型注释的多智能体大语言模型框架。总体而言,在两种方法均被评估的数据集中,CASSIA 在聚类水平上的注释表现与 ScType+scMarkerAgent 大致相当,但并未超越 ScType+scMarkerAgent+LLM。相对于依赖公共标志物数据库的 ScType 工作流,CASSIA 最明显的优势体现在胶质母细胞瘤数据集中。与基于 ScType 的工作流不同,CASSIA 不使用显式的标志物参考数据库;相反,它依赖于大语言模型的参数化知识。在实践中,其错误更多反映为谱系水平的错误分配或仅输出状态信息,并且其自由文本注释在不同聚类之间标准化程度较低。例如,在人肺数据集中,CASSIA 对巨噬细胞群体交替使用多种描述,而非使用如"肺泡巨噬细胞"这样一致的标签;并且对于一个增殖性巨噬细胞聚类,它返回了仅包含状态信息的标签"循环/有丝分裂细胞(G2/M期富集)",而不是带有谱系信息的注释"循环肺泡巨噬细胞"。相比之下,ScType+scMarkerAgent+LLM 产生了更标准化、带有谱系信息的标签,如"肺泡巨噬细胞"和"循环肺泡巨噬细胞"。
5. 负向标志物改善细胞类型区分与恶性细胞界定
为了进一步理解最初被注释为 AT1 的聚类为何被 ScType+scMarkerAgent+LLM 框架纠正为 ATi 细胞,作者检视了大语言模型的推理过程(见补充表S1):
该聚类共表达 AT1 标志物(AGER)以及具有过渡态或 AT2 特征(KRT8、SFTPB)的基因,这是 ATi 细胞的典型特征。排名最高的成熟 AT1 被拒绝,因为其负向标志物 KRT8 在该聚类中也有表达,表明存在生物学冲突;iAT1 YAP5SA 因其负向标志物 SFTPB 和 NAPSA 重叠而被排除。鉴于上皮谱系标志物(例如 NKX2-1 和 EPCAM)的存在以及缺乏内皮细胞标志特征,内皮支架细胞不太可能。肺泡上皮祖细胞缺乏此处观察到的关键过渡态标志物(KRT8 和 SFTPB)。诱导型 AT1 和宽泛的肺泡上皮细胞标签对于这种标志物模式而言,其特异性不如 ATi。间皮细胞和杯状细胞候选类型与肺泡上皮特征不符。
与大语言模型的推理一致,作者可视化了人肺数据集中 AGER、KRT8 和 SFTPB 的表达(Fig. 5A-C)。AT1 标志物 AGER 在 AT1 聚类中显示出强烈且特异性的上调(log2FC = 8.67,PCT = 0.955;Fig. 5A),这很可能解释了为什么其他方法将该聚类注释为肺泡 I 型细胞。然而,这些方法未纳入一个关键的生物学规则:AT1 细胞不应表达 AT2 相关标志物,如 KRT8 和 SFTPB。如 Fig. 5B,C 所示,KRT8 和 SFTPB 在该聚类中也高度表达。值得注意的是,在 scMarkerAgent 中,KRT8 被列为 AT1 细胞的负向标志物;因此,纳入负向标志物约束使得该框架能够解决标志物冲突,并得出更准确的注释 ATi 细胞。
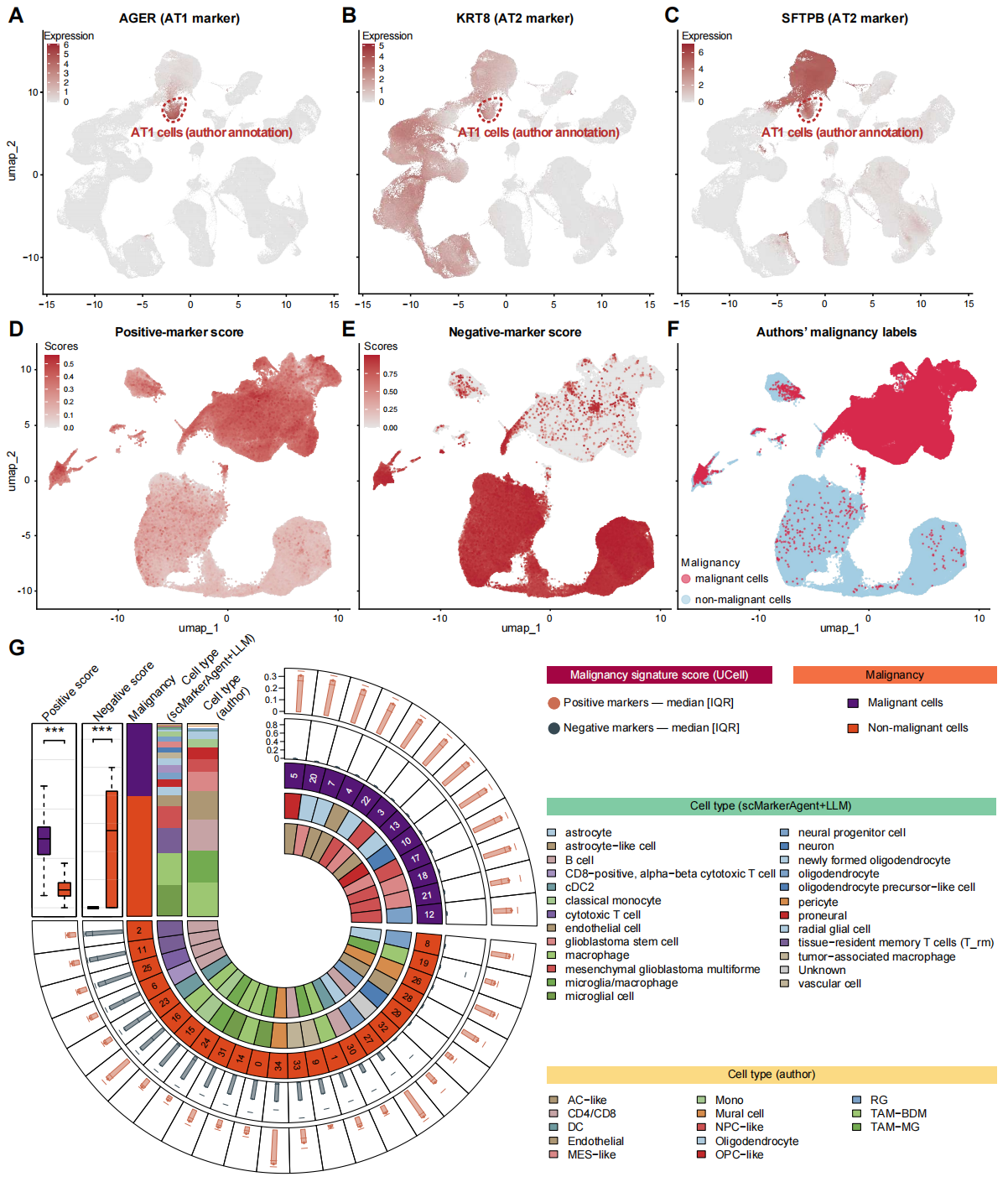
Figure 5. 数据集中负向标志物的表达情况
(A-C) 人肺数据集中(A)AGER、(B)KRT8 和(C)SFTPB 的表达情况。红色虚线框出的是作者注释为 AT1(肺泡I型细胞)的区域。
(D-E) 使用 scMarkerAgent 中胶质母细胞瘤(D)正向标志物和(E)负向标志物对人胶质母细胞瘤数据集进行基因集评分的结果。
(F) 作者注释的恶性标签。
(G) 人胶质母细胞瘤数据集的汇总图。从外圈到内圈,该图展示的内容依次为:正向标志物评分(中位数四分位距)、负向标志物评分(中位数四分位距)、恶性状态(恶性与非恶性)、细胞类型预测结果(scMarkerAgent+LLM)以及作者的细胞类型注释。
除了作为排除约束用于区分细胞类型之外,负向标志物在肿瘤 scRNA-seq 中的恶性细胞识别方面也很有价值,有助于减少仅使用正向标志物时可能出现的错误分类。在肿瘤 scRNA-seq 中准确识别恶性细胞是区分肿瘤内在转录程序与肿瘤微环境中非恶性细胞来源信号的关键先决条件。这使得能够可靠地刻画肿瘤内异质性以及与进展和治疗耐药相关的肿瘤细胞状态,从而为基于机制的治疗策略提供信息。
scMarkerAgent 包含 417,812 条疾病相关背景下的细胞类型-标志物注释。以胶质母细胞瘤为例,作者从 scMarkerAgent 中检索了胶质母细胞瘤特异性的正向和负向标志物集,并使用 UCell 计算每个细胞的特征评分。恶性细胞中的正向标志物评分普遍较高(Fig. 5D),并且与作者最初使用 SCEVAN iCNV 分析分配的恶性标签大致一致(Fig. 5F),而负向标志物评分则呈现相反趋势(Fig. 5E)。总之,这些互补信号表明,负向标志物可以作为排除约束,并提高恶性细胞识别的稳健性,其效果优于单独使用正向标志物(Fig. 5G)。
综上所述,这些结果支持 scMarkerAgent 注释的广度和可靠性,并强调了在 scRNA-seq 分析中联合纳入负向和正向标志物可以改善细胞类型区分和恶性细胞界定。
6. scMarkerAgent+LLM 提升脑组织空间转录组学的注释性能与标准化水平
利用 Sun 等人发表的空间转录组数据集,作者在一个包含 32 个切片、共计 2,327,742 个空间位点的 Seurat 对象上评估了 scMarkerAgent+LLM 的性能,所有结果及其支持证据可在 https://spatial.markeragent.net 进行交互式探索(Fig. 6A)。
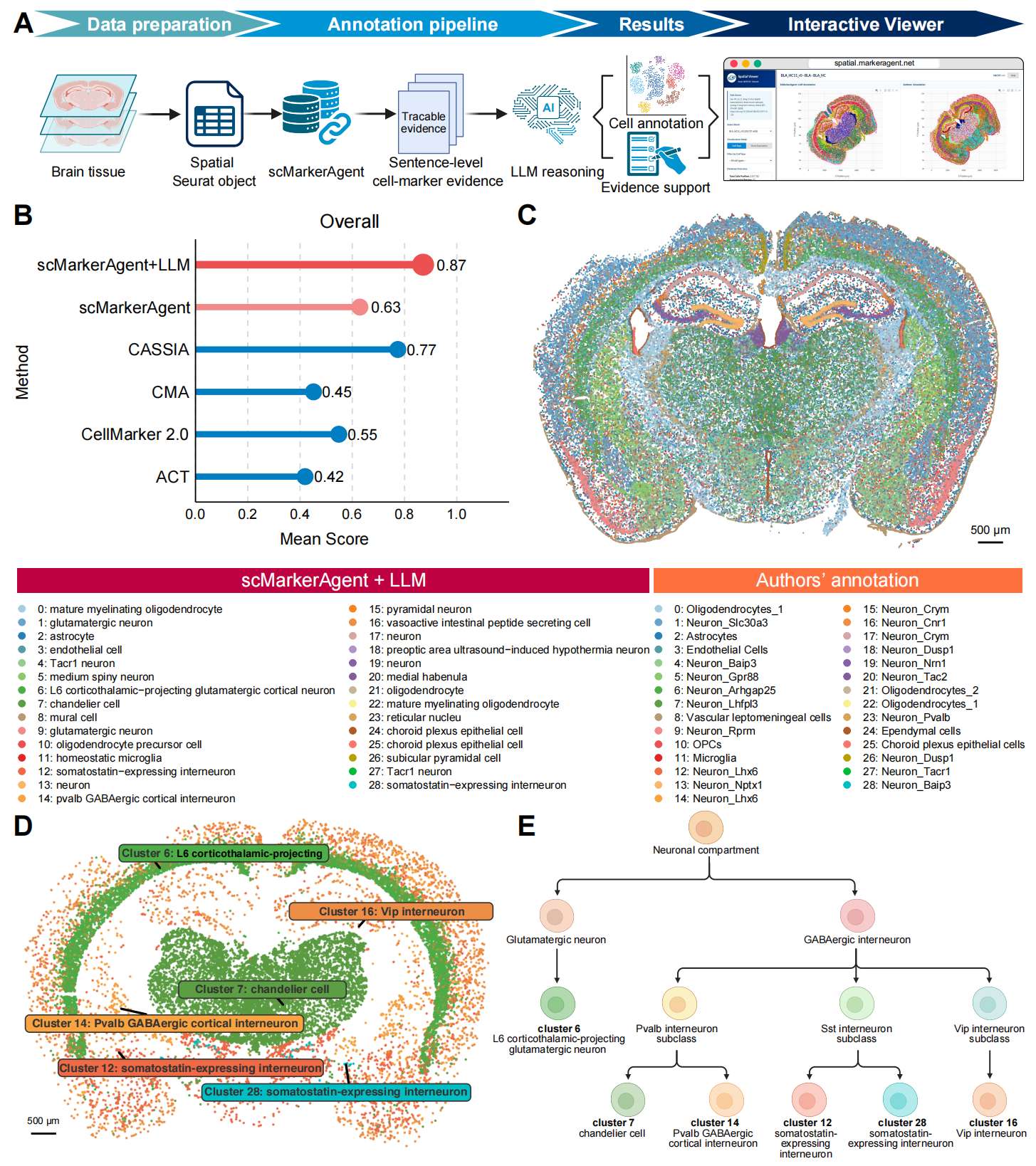
Figure 6. scMarkerAgent+LLM 工作流在空间转录组学中的表现
(A) 数据处理流程。
(B) scMarkerAgent+LLM 与单独 scMarkerAgent 以及具有代表性的基于数据库或基于大语言模型的注释工作流在聚类水平平均注释得分上的比较。
(C) 按聚类身份着色的空间坐标图,左侧为 scMarkerAgent+LLM 注释的细胞类型图例,右侧为 Sun 等人原始注释的细胞类型图例;图中提供了聚类 ID(0-28),以便与所显示区域直接对应。
(D) 部分优化后神经元注释的 DimPlot 图。
(E) 所选优化后神经元注释的分类示意图。
在这个具有挑战性的脑组织空间数据集上,scMarkerAgent 实现了 0.63 的平均注释得分,比传统的基于标志物数据库的工作流高出 10% 以上;而基于大语言模型的优化进一步将性能提升至 0.87(Fig. 6B)。同时,纯大语言模型驱动的 CASSIA 工作流也优于传统的基于标志物数据库的方法,这一模式表明,在异质性强、状态丰富的环境中,基于推理的注释尤其有用,因为仅依赖标志物的工作流可能难以解析精细的细胞身份。纯大语言模型驱动的方法(CASSIA)排名第二,突显了注释过程中推理的重要性;然而,其输出相对缺乏标准化(例如,聚类 4 返回的是一个冗长的、带有区域和标志物限定描述的叙述性标签;Supplementary Table S3),而 scMarkerAgent 则提供了受控词汇表,支持一致的标签命名和跨聚类比较(Fig. 6B)。总体而言,作者观察到,相对于作者主要基于标志物的聚类标签,scMarkerAgent+LLM 提高了亚型和状态的分辨率,同时仍然以差异表达标志物和明确的标志物一致性检查为基础(Fig. 6C)。
在少突胶质细胞谱系中,当成熟髓鞘程序明确时,作者宽泛的少突胶质细胞标签得到了优化:例如,聚类 0 和 22 从少突胶质细胞类别升级为成熟髓鞘化少突胶质细胞,这一判断得到了典型成熟髓鞘和致密化标志物(聚类 22 中的 Mog、Plp1、Mag、Cldn11 和 Mal)的支持;而聚类 21 则有意保留为更一般的少突胶质细胞,因为标志物证据不足以证明其为完全终末状态的标签。
在神经元分区中,作者经常使用以标志物为中心的命名方式(例如 Neuron_),这些名称并未明确编码谱系或功能类别。作者的框架将这些标志物组合转化为与既定神经生物学一致的标准化的、可解释的身份。这些包括:聚类 6(由 Rprm 驱动)被识别为 L6 皮质丘脑投射谷氨酸能神经元;聚类 7(Vipr2、Pvalb)被识别为 PV 中间神经元特化类型,如枝形吊灯细胞;聚类 14(Pvalb、Lhx6、Sox6、Tac1)被识别为 Pvalb GABA 能皮质中间神经元;聚类 12 和 28 被识别为表达生长抑素的中间神经元(例如聚类 12 中具有 Sst 程序,伴随Sox6/Npy/Crhbp,以及聚类 28 中的 Chodl/Crhbp);聚类16(Htr3a、Vip)被识别为 VIP 中间神经元。重要的是,这些优化反映了谱系一致的组合,而非单一标志物的命名,因此提高了跨聚类的可比性(Fig. 6D,E)。
当作者的标签与典型标志物模块冲突时,scMarkerAgent+LLM 纠正了非神经元聚类中的谱系归属。这一点在聚类 24 中最为明显:脉络丛上皮细胞身份(Ttr、Folr1、Krt18、Cldn2、Igfbp2)提供了比室管膜细胞类型标签更一致的上皮和分泌程序。在聚类 8 中,血管壁细胞或周细胞程序(Acta2、Myl9、Cspg4、Rgs5)支持血管壁细胞身份,而非更宽泛的软脑膜相关命名。
综上所述,这些结果表明,scMarkerAgent+LLM 在脑组织空间转录组学中既提高了准确性,也提升了亚型或状态的分辨率。此外,与纯大语言模型驱动的注释不同,它通过将决策建立在差异表达标志物和明确的一致性检查基础上,从而保持标准化、可比较的细胞类型名称。
讨论
总之,基于标志物的注释所面临的主要瓶颈不仅仅是标志物的稀缺,更在于缺乏可审核的、具有情境感知能力的证据以及原则性的冲突处理机制。通过将每条记录与句子层面的证据相关联并应用质量控制过滤,scMarkerAgent 将从文献中提取的细胞类型-标志物陈述转化为可追溯、结构化的注释。在此框架基础上,基于 ScType 的预过滤、负向标志物排除以及以大语言模型基于 scMarkerAgent 所提供标志物证据进行的推理,共同提高了 scRNA-seq 基准数据集和空间转录组学中细胞类型注释的准确性和可解释性。
句子层面证据的价值不仅限于提供更精细的引用。它使得对标志物知识的直接验证成为可能,并支持解释注释分歧产生的原因。当关于某条细胞类型-标志物注释出现冲突时,用户可以追溯到原始证据句子,检查组织、疾病背景和实验条件等因素,从而判断分歧是源于情境差异、命名不一致还是证据不足。重要的是,这种以证据为核心的标志物范式不同于基于参考图谱的、训练驱动的方法。大多数参考图谱映射或监督分类器依赖于带标签的训练数据,对训练参考的代表性敏感,并且当出现新的细胞类型或疾病状态时通常需要重新训练或调整。相比之下,scMarkerAgent 可以通过添加新的细胞类型-标志物注释及其支持句子来进行扩展,无需模型预训练,从而能够更快地整合新近被描述的细胞群体,同时保持可解释性和可追溯的来源。
作者的分析表明,精细注释的错误通常并非源于缺少强效的正向标志物,而是源于缺乏能够明确排除生物学上不合理候选注释的负向标志物证据。在 AT1 到 ATi 的区分案例中,像 AGER 这样的强效正向标志物在固定权重评分方案中可能主导决策,使标签偏向 AT1。然而,KRT8 和 SFTPB 的共表达与典型的 AT1 程序相悖:SFTPB 通过反映保留的 AT2 相关特征提供了反对 AT1 的负面证据,而 KRT8 则为一种中间态、类似 ATi 的身份提供了正向支持,这种身份与混合或过渡态的转录程序一致,这与先前的研究相符。通过系统性地整理负向标志物,scMarkerAgent 使此类不相容性变得明确,并将决策逻辑从"哪个候选类型得分更高"转变为"哪些候选类型与观察到的标志物模式不一致"。在 scMarkerAgent+LLM 工作流中,大语言模型不仅遵循 ScType的固定权重;相反,它基于检索到的句子进行证据引导的推理,评估谱系特异性,并同时考虑正向支持证据和负向标志物冲突。更广泛地说,这种冲突感知策略减少了对少数主导性正向标志物的过度依赖,并在密切相关群体共享标志物或过渡态混合转录程序的精细注释场景中提高了稳健性和可解释性。
在肿瘤和糖尿病胰腺等疾病背景下,观察到所有方法的注释准确性均可能下降,这与转录可塑性增加、谱系程序与状态程序混杂以及疾病-微环境信号相互纠缠的情况相一致。scMarkerAgent 通过数据与算法两方面的创新来应对这些挑战。在数据方面,它整合了数量显著更多的疾病背景标志物注释,使候选身份和证据与疾病样本中常见的非经典表达组合模式对齐。在算法方面,作者联合利用正向和负向标志物,同时实施证据约束的候选过滤和冲突解决,使得恶性细胞的界定既通过捕获恶性程序来引导,也通过排除微环境细胞来辅助。这种方法减少了仅依赖正向标志物时更易出现的模糊性和错误分类。
基于作者的比较,大语言模型似乎在推理复杂标志物组合和生成标准化输出方面很有用,而其主要风险则源于不可验证的知识来源和输出不稳定性。基础模型通常依赖于大规模预训练和下游微调,涉及大量计算成本,其性能与训练数据的覆盖范围紧密相关。在单细胞应用中,基于 Transformer 的方法可以将基因视为标记来学习表达模式,并在一定程度的跨组织、跨条件迁移能力,这推动了大语言模型和基础模型工具生态系统的增长。然而,纯大语言模型驱动或纯生成式工作流仍面临实际局限性。首先,预测结果通常依赖于参数化知识,缺乏可审核的证据链,使得难以证明选择某个标签的理由。其次,输出可能漂移为非标准的自由文本命名,降低了跨聚类和数据集的一致性。第三,当训练语料库中未包含新的细胞类型或疾病亚型时,模型可能产生听起来合理但证据薄弱的推断。因此,作者仅在证据检索和候选约束之后才调用大语言模型。然后,模型仅使用 scMarkerAgent 支持的标志物证据和预定义的候选集来解决冲突并分配名称,从而在 scRNA-seq 和空间转录组学中保留了大语言模型推理的优势,同时减少了不可追溯或不一致的输出。
尽管有这些改进,scMarkerAgent 仍然存在文献覆盖偏差。常见组织和细胞类型关联的注释更多,而不常见的组织或新近报道的发现可能缺乏足够的支持。此外,随着 scRNA-seq 技术的进步,过时的细胞本体术语可能无法跟上新细胞类型的出现。提高细胞本体更新速度将有利于跨研究分析和细胞图谱构建。此外,本研究仅评估了 scMarkerAgent 数据库内 ScType 的应用,并未测试其他基于标志物的注释方法。进一步的算法优化可能会提高注释准确性。
未来的工作将从两个方面扩展 scMarkerAgent。首先,除了目前对人、小鼠和大鼠的覆盖范围外,作者将纳入更多物种的标志物注释,以扩展其在多种生物体研究中的适用性。其次,作者计划建立一个自动化的、带版本控制的发布机制,每季度进行更新,以持续整合新发表的证据,从而及时纳入新报道的细胞类型和标志物。
总之,scMarkerAgent 提供了一个基于句子级别证据的标志物资源,提高了标志物驱动的细胞类型注释的透明度和可解释性。通过将正向和负向标志物与候选约束的大语言模型推理相结合,它能够在跨物种的单细胞数据集(包括疾病背景下的数据集)以及空间转录组学中,实现更可靠的精细注释。
--------------- 结束 ---------------
注:本文为个人学习笔记,仅供大家参考学习,不得用于任何商业目的。如有侵权,请联系作者删除。
