目前的主流医疗大模型虽然"理论满分",但在真实诊断中却频频翻车。究其原因,现有方法多局限于静态的"开卷问答",直接把完整病历塞给模型让它猜结果。这种方式完全破坏了临床特有的迭代推理过程,导致模型极易陷入"先入为主"的认知偏差,缺乏主动搜集关键证据的能力。
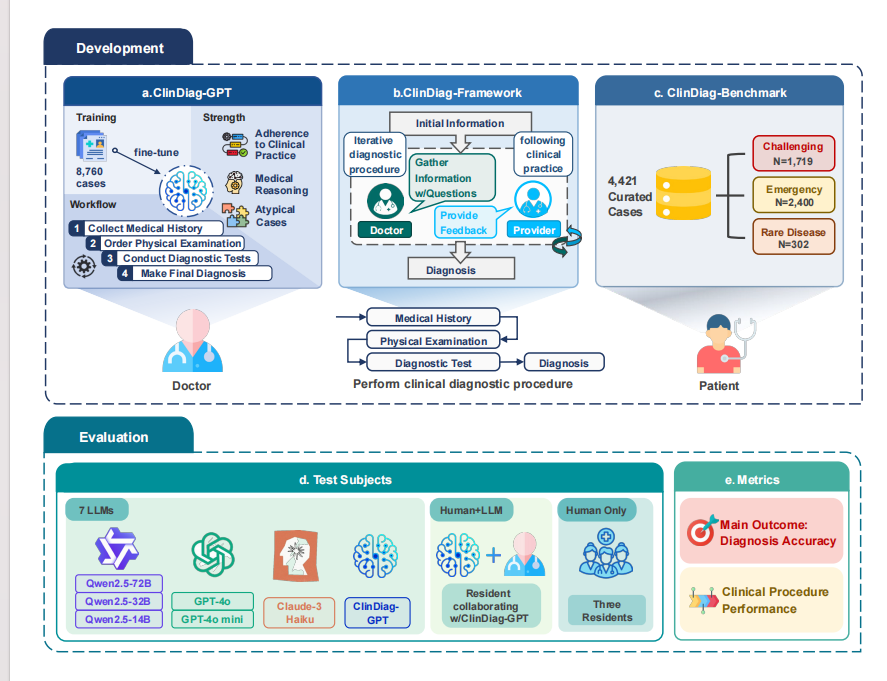
基于此,作者洞察到:真正的临床诊断就像破案,必须经历"病史问诊---查体---化验---确诊"的全局动态过程。为此,团队构建了含4421个真实病例的ClinDiag-Benchmark,并提出模拟人类医生逐步推理的全新模型与评测框架,致力于彻底激活和提升大模型在真实医疗场景下的动态诊断能力。

我整理了这篇论文的完整架构图、核心算法解析及零上手复现教程,感兴趣的dd!
二、 核心方法(建模方法)
-
整体思路:在临床诊断流程域进行多轮智能体交互(Agent Interaction)操作,以实现模拟真实医生逐步收集证据并精准诊断的目的。
-
关键公式与步骤 : 该动态诊断流程可被抽象为一个条件概率的序列生成过程,最终输出诊断 的表达式如下:
- 关键组件说明:为患者初始陈述; 分别代表通过多轮交互迭代获取的病史(History)、体格检查(Examination)和诊断测试(Test)结果; 为通过LoRA进行微调的模型参数。
-
技术实现要点 :
-
角色区分与信息控制:引入Doctor Agent(负责推理和提问)与Provider Agent(充当患者或病历库)。规则限制Provider不得"抢答",无数据时必须拒答,以此还原真实的未知诊断环境。
-
一致性与多样性保障:为了让模型掌握问诊的"专业感"与"逻辑约束",通过筛选7616个高维度多轮真实对话进行监督微调(SFT),并将模型温度超参数设置为0.3,实现推理可靠性与问询多样性的平衡。
-
三、 实验验证与效果
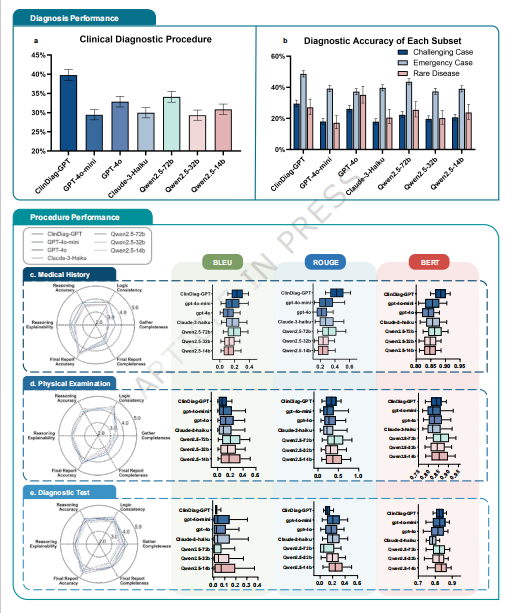
- 主实验对比:在动态临床诊断任务中,基于Qwen2.5-72B微调的ClinDiag-GPT取得了39.76%的诊断准确率,全面超越了GPT-4o、Claude-3等基线大模型。
-
深入分析:多维度误差分析表明,ClinDiag-GPT在四大诊断阶段的错误率显著低于主流模型,并大幅减少了"锚定偏见"和"确认偏见"。消融测试进一步揭示,简单的Prompt优化或多个Agent内部辩论无法从根本上解决动态诊断短板,高质量流程数据的监督微调才是核心。
-
结论与价值:本文的最大贡献是证明了"人机协作"的巨大红利。三臂对比实验显示:医生与ClinDiag-GPT合作,能将诊断准确率一举提升至45%,并将诊断耗时从22分钟大幅压缩至15分钟,展现出成为临床辅诊系统底座的巨大价值。
四、 小编总结
本文犀利地打破了医疗AI盲目追求"静态做题"的迷局,从现实痛点出发,量身定制了支持动态多轮交互的评估基准与微调模型ClinDiag-GPT。该研究不仅证明了针对性微调能有效纠正AI临床看病时的认知偏差,更用实打实的数据揭示了"医生与AI强强联手"才是未来智慧医疗的最优解。