
文章目录
- 摘要
- 一、3DGS及其衍生方法
- 二、高斯泼溅的高频细节
- [三、Neural Gabor Splatting](#三、Neural Gabor Splatting)
- [四、Frequency-aware Densification Strategy (频率感知稠密化策略)](#四、Frequency-aware Densification Strategy (频率感知稠密化策略))
- [五、优化损失(Optimization )](#五、优化损失(Optimization ))
- 实验
Neural Gabor Splatting: Enhanced Gaussian Splatting with Neural Gabor for High-frequency Surface Reconstruction
来源: 东京大学
摘要
近年来,三维高斯泼溅(3DGS)作为一种强大的三维重建和新型视图合成方法迅速崛起。其采用高斯基元的显式表示方式,实现了快速训练、实时渲染以及便捷的后期处理(如编辑和表面重建)。然而,3DGS存在一个关键缺陷:对于具有高频外观细节的场景,基元数量会急剧增加------因为每个基元仅能表示单一颜色 ,导致每个明显的颜色过渡都需要多个基元。为克服这一局限,我们提出了神经Gabor溅染方法:通过为每个高斯基元添加轻量级多层感知器,使其能够在单一基元内模拟多种颜色变化。为进一步控制基元数量,我们引入了频率感知密集化策略,根据频率能量选择不匹配的基元进行剪枝和克隆。该方法能够准确重建具有挑战性的高频表面,并通过在Mip-NeRF360和高频数据集(如棋盘格图案)等标准基准上的大量实验验证了其有效性,相关结果还得到了全面消融实验的支持。
一、3DGS及其衍生方法
3DGS通过一组高斯基元对场景进行建模,并采用 alpha 混合技术进行光栅化处理。与 NeRF 相比,这种显式表示方式能够实现快速训练和实时渲染,并天然支持多种下游应用,例如Sugar10,11的表面重建 、4DGS、Mega35,36,39等动态场景建模、稀疏视图重建6,7,17以及场景编辑9,15,21,32。然而,典型场景可能需要数十万至数百万个基元,导致巨大的内存占用。为此,研究者提出了多种压缩方法2,29,30。
另一研究方向则致力于提升基元本身的表达能力:例如,2DGS11利用高斯圆盘更精确地逼近表面;3d-hgs16则引入Half-Gaussian splatting以捕捉锐利边缘。尽管取得了这些进展,但由于每个基元所需的参数量庞大,数据规模仍是亟待解决的挑战。
二、高斯泼溅的高频细节
3DGS的一个关键局限在于其在建模高频细节时效率低下。Poison-splat 18指出,对于色彩过渡频繁的图像,基本图形的数量会急剧增加,因为每个基本图形仅能编码单一颜色。为解决这一问题,多种方法允许基本图形承载更丰富的外观信息:3D Gabor Splatting33和3DGabSplat40采用增强型高斯核替代传统高斯核,从而实现对三维空间高频模式的直接优化;另一种方法是将精细纹理嵌入基本图形5,22,26,34,并与其它参数协同优化;此外还存在一种用于表现锐利边缘的技术------由于高斯核的形状特性,这类边缘容易被模糊处理。Zhou等人41提出了一种方法,利用微型 MLP 来表征各类基本图形的形状,该方法可在重建场景中实现锐利边缘切换,且每个基本图形仅需单一颜色。近期研究如神经纹理斑块技术(NTS)31和神经壳状纹理斑块技术(NEST)38,通过在每个基本图形内编码空间变化的色彩信息,在提升表现力的同时减少了基本图形的数量。
三、Neural Gabor Splatting
为了在单个基元内表示复杂的颜色模式和视角依赖性 ,作者为 每个基元引入了一个独立的、轻量级的 MLP(参数为 Θ k \Theta_k Θk)来预测 RGB 值。
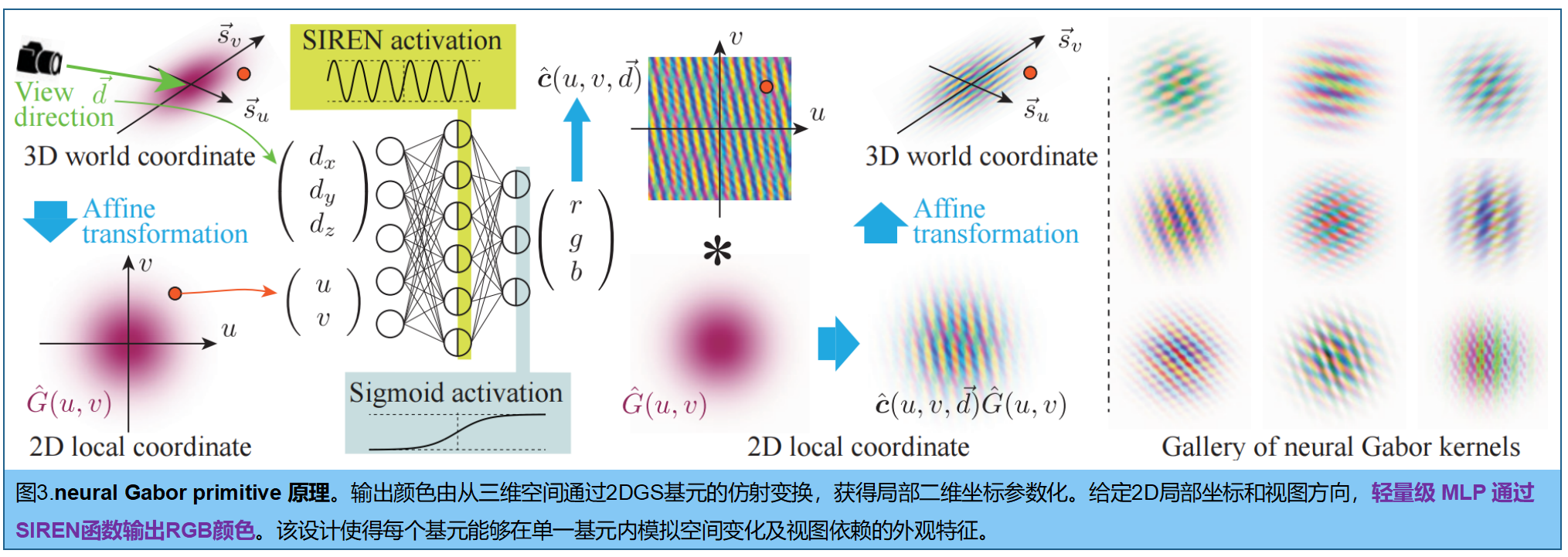
- 网络架构 : 采用了单隐藏层的 SIREN(Sinusoidal Representation Networks,下面有解释)架构,包含 6 个隐藏神经元。每个高斯基元配备了一个极其轻量的"单隐藏层" SIREN,隐式地执行了位置编码,非常适合拟合高频信号。
和 2DGS 类似,像素的最终颜色是解析光栅化的高斯基元的加权和: c = ∑ k K c ^ k ( Θ k , u , v , d ⃗ ) α k G ^ k T k \mathbf{c} = \sum_{k}^{K} \hat{\mathbf{c}}_k(\Theta_k, u, v, \vec{d}) \alpha_k \hat{G}_k T_k c=k∑Kc^k(Θk,u,v,d )αkG^kTk c ^ k ∈ R 3 \hat{\mathbf{c}}_k \in \mathbb{R}^3 c^k∈R3:神经 Gabor 预测的颜色。 α k \alpha_k αk:不透明度。 G ^ k \hat{G}_k G^k:归一化的 2D 高斯核。 T k T_k Tk:累积透射率。 颜色预测 c ^ k \hat{\mathbf{c}}_k c^k 由逐基元的 MLP 定义: c ^ k = Sigmoid W ˉ k sin { ω 0 ( W k y + b k ) } + b ˉ k ( 7 ) \hat{\mathbf{c}}_k = \text{Sigmoid} \left \\bar{\\mathbf{W}}_k \\sin\\{\\omega_0(\\mathbf{W}_k \\mathbf{y} + \\mathbf{b}_k)\\} + \\bar{\\mathbf{b}}_k \\right(7) c^k=SigmoidWˉksin{ω0(Wky+bk)}+bˉk(7)
- 输入端 y ∈ R 5 \mathbf{y} \in \mathbb{R}^5 y∈R5:这是局部空间坐标 ( u , v ) (u, v) (u,v) 和视角方向 d ⃗ \vec{d} d 的拼接向量。
- 线性仿射变换 ( W k y + b k ) (\mathbf{W}_k \mathbf{y} + \mathbf{b}_k) (Wky+bk):这是隐藏层的基础线性映射。
- 核心频率乘子 ω 0 \omega_0 ω0:这是 SIREN 的标志性超参数(论文中设为 30)。在正弦激活前乘以一个较大的 ω 0 \omega_0 ω0,相当于极大地扩大了第一层网络能覆盖的频段范围。它使得输入坐标的微小变化能够在正弦函数中产生多个周期的剧烈震荡,从而赋予网络极强的"高频表达能力"。
- 正弦激活函数 sin { ⋅ } \sin\{\cdot\} sin{⋅}:隐式地完成了特征的高频映射,让单个基元能够表达其覆盖区域内复杂的反射率变化或纹理,而不需要像传统 3DGS 那样存一堆球谐函数(SH)系数。
- 输出层 W ˉ k , b ˉ k \bar{\mathbf{W}}_k, \bar{\mathbf{b}}_k Wˉk,bˉk 与 Sigmoid:最后通过一个线性层将高维特征映射到 3 维,并通过 Sigmoid 压缩到 (0, 1) 的 RGB 颜色空间,得到预测颜色 c ^ k \hat{\mathbf{c}}_k c^k。
SIREN 架构原理:SIREN(Sinusoidal Representation Networks) 是隐式神经表示(INR)领域的一个经典网络架构,2020 年Sitzmann 提出。
- 传统的 MLP 通常使用 ReLU 激活函数,这导致网络存在强烈的谱偏置(Spectral Bias)------即网络倾向于快速学习低频平滑信号,而极难拟合包含尖锐边缘、复杂纹理的高频信号。在传统 NeRF 中,为了解决这个问题,通常需要在输入端显式地加入位置编码(Positional Encoding, PE)。
- SIREN 抛弃了 ReLU,直接使用周期性正弦函数(Sine)作为激活函数。这种设计让网络无需显式的位置编码,就能自然且高效地拟合极高频率的信号及其导数。
四、Frequency-aware Densification Strategy (频率感知稠密化策略)
引入 MLP 后,标准 3DGS 稠密化策略失效。核心动机:传统 3DGS 的自适应稠密化依赖于基元中心位置梯度的幅值。但在 Neural Gabor 中,由于 MLP 能够学习到高频的外观细节,颜色会在局部发生剧烈变化,这导致梯度经常异常偏大。如果直接沿用基于梯度的稠密化,会导致过度增长(Excessive densification),产生大量不必要的冗余基元。
解决方案:在频域中计算损失,以便专门在缺乏高频细节(如纹理模糊)的区域进行基元的克隆或分裂 。对于给定的相机视角 π \pi π,第 k k k 个基元 γ k \gamma_k γk 的误差 E k π E_k^\pi Ekπ 由其对图像像素误差 ε π ( u ) \varepsilon_\pi(\mathbf{u}) επ(u) 的贡献加权累加得到: E k π = ∑ u ∈ Pixels ε π ( u ) w k π ( u ) E_k^\pi = \sum_{\mathbf{u} \in \text{Pixels}} \varepsilon_\pi(\mathbf{u}) w_k^\pi(\mathbf{u}) Ekπ=u∈Pixels∑επ(u)wkπ(u)其中,逐像素的频域误差 ε π \varepsilon_\pi επ 的计算方式如下: ε π = ∥ Avg ( F − 1 ( Bandcrop ( F ( G T π ) ) ) ) − Avg ( F − 1 ( Bandcrop ( F ( I π ) ) ) ) ∥ 1 \varepsilon_\pi = \left\| \text{Avg}(\mathcal{F}^{-1}(\text{Bandcrop}(\mathcal{F}(GT_\pi)))) - \text{Avg}(\mathcal{F}^{-1}(\text{Bandcrop}(\mathcal{F}(I_\pi)))) \right\|1 επ= Avg(F−1(Bandcrop(F(GTπ))))−Avg(F−1(Bandcrop(F(Iπ)))) 1 F \mathcal{F} F 和 F − 1 \mathcal{F}^{-1} F−1:快速傅里叶变换(FFT)及其逆变换。 G T π GT\pi GTπ 和 I π I_\pi Iπ:分别是相机 π \pi π 下的真值图像和渲染图像。Bandcrop \text{Bandcrop} Bandcrop:频段裁剪操作,用于提取特定的带限频率成分 (作者选取了 3 个频段:(0.01, 0.10), (0.10, 0.20), (0.20, 0.40))。 Avg \text{Avg} Avg:局部均值滤波(核大小为 17),用于构建对方向不对齐具有鲁棒性的误差度量。
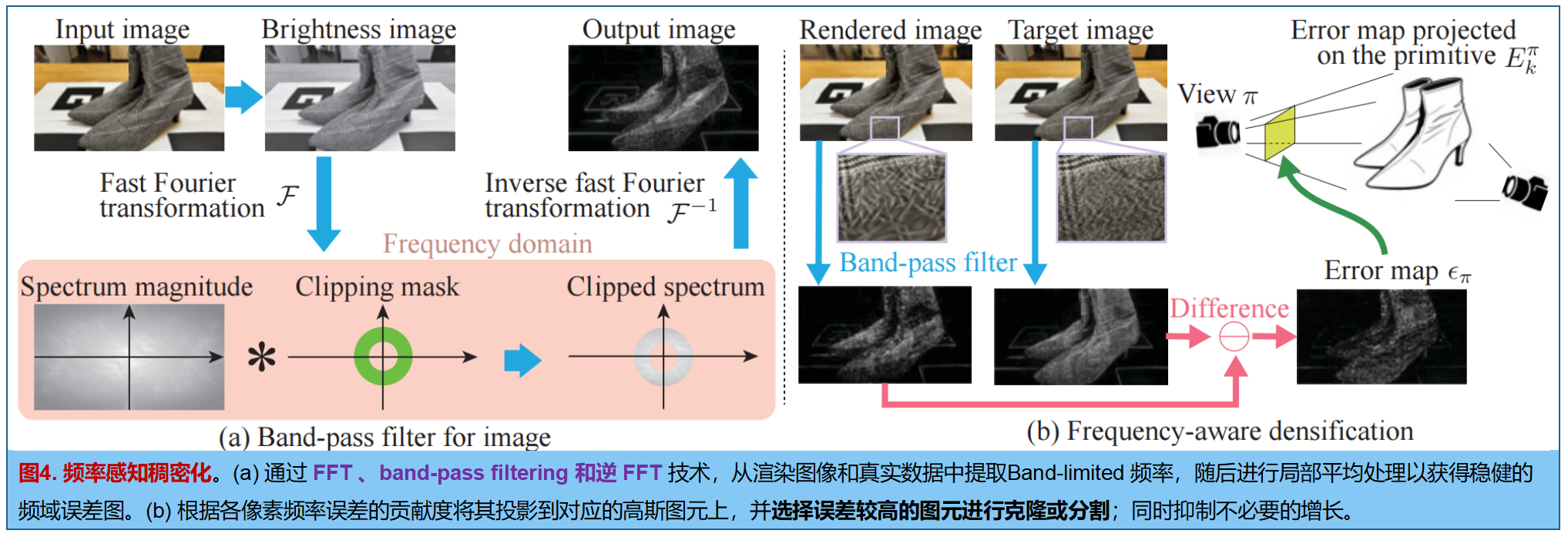
带通滤波器(Band-pass Filter):只允许特定频段的频率通过,而将高于或低于这个频段的频率全部阻挡(过滤掉)。当一张图像经过快速傅里叶变换(FFT)转换到频域(Spectrum magnitude)后,中心点代表低频成分,越往边缘代表极高频成分。
实现细节:每 100 次迭代进行一次评估,随机采样 20 个训练视角累加误差。稠密化阈值设为 0.01。因为 FFT/IFFT 在 GPU 上高度并行,且每 100 步才算一次,所以额外计算开销可忽略。克隆/分裂出来的新基元会继承父基元的 MLP 权重。引入了渐进式不透明度重置(gradual opacity reset)替代硬重置,但为了避免伪影,没有采用 alpha 合成损失。
五、优化损失(Optimization )
最终的 Loss 是 L 1 L_1 L1 损失和 SSIM(结构相似性)损失的加权组合: Loss = λ L 1 + ( 1 − λ ) L SSIM \text{Loss} = \lambda L_1 + (1 - \lambda)L_{\text{SSIM}} Loss=λL1+(1−λ)LSSIM 初始化策略 :由于采用了单基元表达多重颜色模式,如果初始化不当,基元容易在优化过程中坍缩成细小、单色的块。为了防止这种情况, MLP 的权重初始化严格遵循了 SIREN 模型的初始化方案,确保基元从一开始就具备表达复杂模式的潜力。
实验
基于已发布的2DGS 实现了neural Gabor splatting。所有实验均在GeForce RTX 3090 GPU上完成。该方法在所有场景下的运行速度为每秒30至500帧(FPS)。训练时间约为2DGS的两倍,主要原因是权重更新所需原子加法运算数量增加。
数据集采用Mip-NeRF360数据集 3中的全部七个场景、 DTU 数据集 12中的四个场景以及Tanks and Temples数据集 14中的两个场景作为基准数据集。此外,为评估高频纹理场景的性能,我们还使用了High-Frequency数据集进行了实验。
针对每种方法和数据集,设定基元的初始数量和最大数量 。选择最大数量是为了确保不同方法间的总数据量保持一致。由于我们的方法旨在使用少量基元精确重建具有高频特征的场景 ,因此只需相对较少的稠密化步骤即可达到最大基元数量。超过特定迭代次数后,精度提升趋于饱和。因此,所有实验均采用2万次训练迭代。对于3DGS、2DGS、3D Gabor splating及本方法,输入图像在训练和评估阶段均被调整为1600×1066像素。初始点随机采自各数据集的 SfM 点云。在3DGS和2DGS中,密度化策略优先选取位置梯度较大的基元,同时确保基元总数不超过预设上限。剪枝策略沿用了原始实现方式,从而在基元数量接近最大阈值时实现了密度化与剪枝之间的平衡。
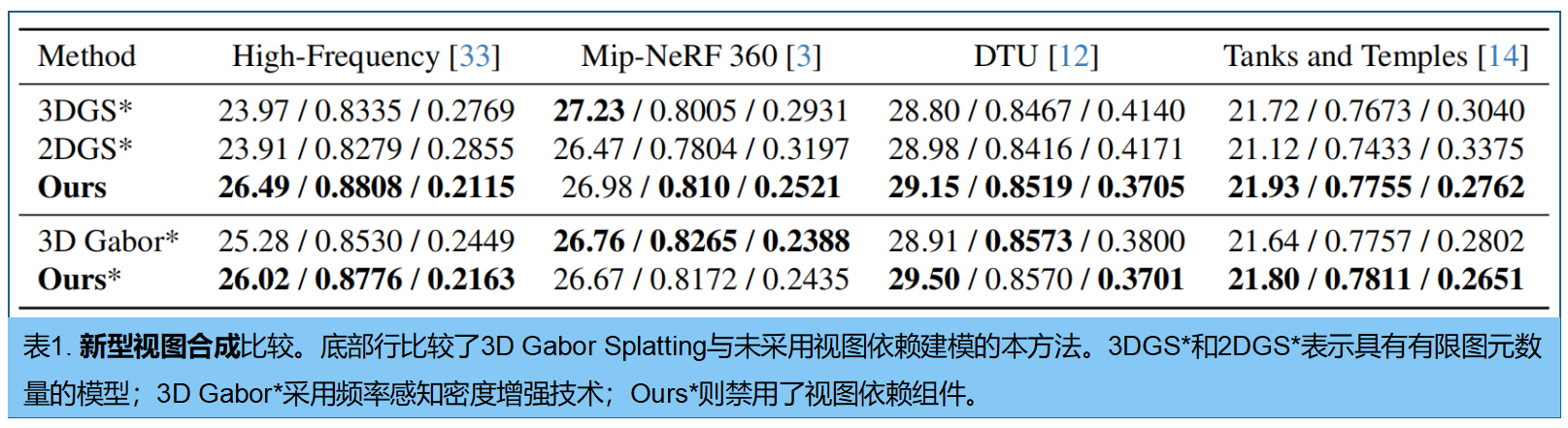
表1展示了所有数据集上的 PSNR 、 SSIM 和 LPIPS 评分。对于高频数据集,我们将最大图元数量设定为20,000,并初始化了5,000个点;对于 DTU 数据集,使用了最多20,000个图元及2,000个初始点;对于Mip-NeRF360数据集,最大图元数量根据场景不同介于200,000至3,000,000之间,初始点数为4,000至600,000。3DGS和2DGS的最大图元

图5.基准 数据集与高频数据集的定性 NVS 结果 。外部与内部场景的新型视图渲染效果。尽管数据量相同,我们的方法仍能渲染清晰锐利的精细细节。
预算和质量的权衡
高频数据集上 ,通过逐步缩减数据预算(从100%降至1%)------该预算值相对于无约束的3DGS进行定义------以验证本方法在严格内存预算条件下的有效性。针对每种方法,我们调整了最大基元数量以匹配目标内存占用量。对于NEST和 NTS ,我们分别通过降低哈希网格和三平面分辨率来缩减其外观表示的容量以适应目标内存需求(例如:NEST采用4级结构,字典大小为16; NTS 采用96级三平面分辨率,通道数为8 )。如图6所示,在严格预算条件下,NEST和 NTS 因固定的外观处理开销而性能急剧下降;而我们的方法在低预算场景下更具鲁棒性,且始终优于3DGS。我们在 SSIM 中也观察到了类似的趋势。从定性上看,激进的预算削减会导致基线模型出现伪影或结构崩溃,而我们的方法则能保持几何结构与外观的一致性。 图6还展示了在5%数据预算条件下重建的结果。

训练时间分析 。 我们报告了在低数据预算条件下Boots模型的训练时间,此时不同方法对图元数量的计算方式存在差异(表3)。与3DGS相比,我们的方法因需对每个图元进行 MLP 评估而产生额外成本。然而,在低预算场景下,运行时间仍具实用性,因为频率感知稠密化技术有效抑制了图元的过度增长。其计算成本与NEST和 NTS 相当,表明相较于传统的神经点扩散方法并未产生显著额外开销。渲染速度的对比数据详见补充材料。
局限性 。尽管该方法在高频表面重建方面效果显著,但仍存在若干局限:首先,其不直接适用于Volumetric Phenomena(体现象/体积现象,指的是在三维空间中具有体积感、不限于表面形状的光学效果) ,且将其扩展至动态场景仍非易事;其次,虽然该方法能减少图元数量,但需对每个图元进行 MLP 计算,从而增加额外的计算开销 ;再者, 在低频场景中, MLP 的表达能力可能未得到充分利用 ;最后,该表示方法仍受限于轻量级MLP的容量,参数共享或基于码本的压缩等改进方案具有广阔前景。