【内涵】transformer之位置编码
- 前言
- 带着问题来解读
-
- 问题1:为什么transformer需要位置编码?
- [问题2:绝对位置编码与 伪相对位置编码?](#问题2:绝对位置编码与 伪相对位置编码?)
- 问题3:相对位置编码rope是什么,为什么成为当前的主流?
- 问题4:外推问题与相对位置编码
前言
带着问题来解读
问题1:为什么transformer需要位置编码?
attention模块具有置换等变性(Permutation Equivariant),结合transformer架构中的其他模块都是point-wise操作,再结合基于transformer架构进行问题建模时都会建模为seq内的dimension(例如文本分类的类别数,token预测的码表数)而非seq间导致了采用transformer架构进行问题建模的输出具有置换不变性(Permutation Invariant)。这个回答有点绕,也有点咬文嚼字,但感觉对自己的理解是有必要的。主要是想强调三点:1.置换等变性与置换不变性的差异;2.除去attention模块,其他模块是point-wise的这一点的重要性;3.问题的建模都会归结为seq内的维度数。
置换等变性 :如果打乱输入的顺序,输出的结果也会随之发生相同的位移/打乱,但每个向量对应的计算数值保持一致。置换不变性 :如果打乱输入的顺序,输出的结果完全不变(比如求和或取最大值)。
我们来设想,假如我们不要位置编码会怎样。我们来做一个具体的文本分类的例子,通过台词来判断这个电影是日常片还是恐怖片。一个序列:"人骑马"和"马骑人"经过attention之后,获得的结果计算数值是一样的,顺序会和输入的顺序一样,这个是attetnion模块的"置换等变性"。但是一开始理解会有一个隐隐的感觉:这两者的输出还是不一样的,因为毕竟它们的index还是不一样的0.1 , 0.2 , 0.3和0.3, 0.2, 0.1,只要index不一样,如果再往"下"走,就有可能将index利用起来来产生最终结果的差异。作为一个CV过来的人,很显然,只要来一个weight,就能体现出这种差异性。
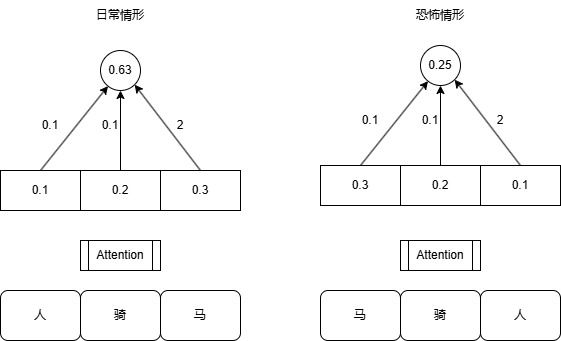
这样设计,即使attention结构是置换等变性,但是我们也可以通过一个最后的weight操作,来将index的信息(某种给程度上就代表了位置信息)融入到最终的结果中,做到文本分类的区分。举这个例子是想表明,如果单单的讲attention结构是置换等变性(我看网上有的说法会直接讲其具有置换不变性,应该是不严谨的),似乎不足以体现position编码信息的必要性。
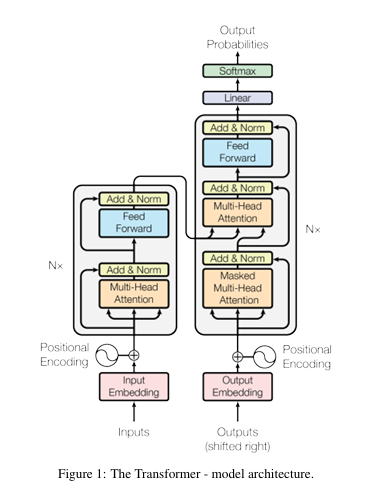
再回过头来看transformer架构图,里面的两处feed-forward,和一处linear"似乎"都是我们需要的weight可以将index的信息融入到tensor流中,这样按照上面"人骑马"的例子,就会对结果造成差异,position编码的必要性似乎就被打破了,但其实这样理解是有问题的。因为这里的feed forward和linear都是point-wise的(或者说是sequence-wise的),换句话讲,即使是在softmax层之前的那一个linear层,它并不是CV领域的FCN(全连接层,自己一开始是直接将其误理解为fcn层在nlp领域的一种叫法,事实上不是这样的)。
再来看最终的问题建模方式,如果是bert这样的encode-only结构,它会有一个cls token,然后cls token与其余的token之间做attention,形成一个 B ∗ 1 ∗ c l a s s n u m B*1*classnum B∗1∗classnum的tensor, 来在classnum这一个维度上分类,此时相当于用单一序列的attention操作来做分类头,就是置换不变性了(并不是一个weight操作,具体的可以看【内涵】VIT解读这里面的tensor流)。而如果是完整的encoder-decoder来做问题建模,最后的linear层也是point-wise(或者说sequence-wise)操作,其升维和降维都是在sequence内而非sequence间,所以还是将attention结构特例化到了seq=1的程度来建模问题,从而是置换不变性。
这三点都是很重要的,因为它们结合起来才是tranfromer架构需要positon编码的原因,也是论文题目《attention is all you need》口气这么大的原因。因为此时除了attention这一个结构,transformer中其余的所有操作:add, layernorm, 残差,feed forward, linear都是point-wise操作(再强调一下,这里的feed forward和linear不是cver眼中的全连接层或者说MLP层,至此MLP, CNN, RNN都不存在了,只有attention这一个稍稍复杂的结构了),已经简单到不值得一提了。所以你所需要的只是attention(其实它也很简单)。point-wise操作会有很多好处:例如序列长度更加灵活,而且由于所有的operation都简单到极致,某种程度上也是transformer infra带来了很大的便利,大家有的时候都有点,attention和transformer两个词等价了,加速了attention就是在加速transformer,attention的瓶颈也就是transformer的瓶颈。
问题2:绝对位置编码与 伪相对位置编码?
bash
We also experimented with using learned positional embeddings [9] instead, and found that the two versions produced nearly identical results (see Table 3 row (E)).绝对位置编码就是将pos_embedding建模为一个关于绝对位置 i i i的函数: p o s e m b e d ( i ) pos_{embed}(i) posembed(i),而相对位置编码的方式则是将pos_embedding建模为一个关于相对位置其实也就是是offset的函数: p o s e m b e d ( i − j ) = p o s e m b e d ( o f f s e t ) pos_{embed}(i-j)=pos_{embed}(offset) posembed(i−j)=posembed(offset)。例如【内涵】VIT解读中提到的位置编码就是一种绝对位置编码。transformer原生的位置编码是采用了三角函数的方式,虽然它实验下来这种做法和learnable的绝对位置编码指标相同,但是三角函数的位置编码是有一种隐含的相对位置关系在里面: p o s ( i + k ) pos(i+k) pos(i+k)和 p o s ( i ) pos(i) pos(i)的特征表示可以用和 k k k相关的线性变换得到。

绝对位置编码是无法做到外推,虽然三角函数的位置编码可以做到形式上的外推,但是并不具有实际的物理意义。
问题3:相对位置编码rope是什么,为什么成为当前的主流?
rope的做法是通过绝对的位置编码形式实现了相对位置编码的效果。具体来讲不再是通过相加的操作, p o s ( i ) + q pos(i) + q pos(i)+q而是相乘的操作 p o s ( i ) ∗ q pos(i)*q pos(i)∗q来融合seq_embedding和pos_embedding。然后通过转换之后发现attention之后其可以转换为相对位置编码的形式 p o s ( i ) q ∗ ( p o s ( j ) q ) T = q ∗ p o s ( j − i ) ∗ q T pos(i)q*(pos(j)q)^T=q*pos(j-i)*q^T pos(i)q∗(pos(j)q)T=q∗pos(j−i)∗qT。作者发现另外一种类似于三角函数编码(其物理意义为旋转矩阵)的形式可以实现上述操作。
p o s ( i ) = ( c o s ( w i ) − s i n ( w i ) s i n ( w i ) c o s ( w i ) ) pos(i)= \\begin{pmatrix} cos(wi) \& -sin(wi) \\\\ sin(wi) \& cos(wi) \\\\ \\end{pmatrix} pos(i)=(cos(wi)sin(wi)−sin(wi)cos(wi))
上面讲过相对位置编码打败了绝对位置编码是因为其良好的外推性质。而rope之所以脱颖而出,是因为其相对编码方式,在计算的时候是以绝对位置编码的方式参与的。这种操作可以通过变量代换法, q ∗ = ( p o s ( i ) q ) ; k ∗ = ( p o s ( j ) k ) q^*=(pos(i)q); k^*=(pos(j)k) q∗=(pos(i)q);k∗=(pos(j)k),来做替换,在attention的外部完成位置信心的融合,而此时attention作为一个黑盒子,业界关于attention的各种加速操作都可以不加修改的运用(例如flash attention)。
问题4:外推问题与相对位置编码
使用了相对位置编码,就可以和外推问题或者说目前比较流行的长文本结合起来啦。例如:。。。。。(10万个词)。。。复旦大学在哪里?此时复和旦在做attention的时候,只需要用到其相对位置信息为 j − i = 1 j-i=1 j−i=1,而不受其实际位于绝对位置10万+的影响。当然相对位置可以这样不断的offset(滑动),但是其总有一个滑动窗口的问题,大家一般的做法是offset>一定的阈值,就认为很远了,然后用同一个数值进行近似,这样做有一定的道理,但终究是治标不治本。所以长文本目前还是一个亟待解决的问题。