文章目录
-
- 前言
- [一、MoE 架构再进化:万亿参数下的高效稀疏化](#一、MoE 架构再进化:万亿参数下的高效稀疏化)
-
- [1.1 MoE 的基本原理回顾](#1.1 MoE 的基本原理回顾)
- [1.2 V4 的 MoE 设计](#1.2 V4 的 MoE 设计)
- [二、混合注意力机制:CSA + HCA 的长文本突破](#二、混合注意力机制:CSA + HCA 的长文本突破)
-
- [2.1 为什么不用 SSM 替代注意力?](#2.1 为什么不用 SSM 替代注意力?)
- [2.2 CSA:压缩稀疏注意力(Compressed Sparse Attention)](#2.2 CSA:压缩稀疏注意力(Compressed Sparse Attention))
- [2.3 HCA:重压缩注意力(Heavily Compressed Attention)](#2.3 HCA:重压缩注意力(Heavily Compressed Attention))
- [2.4 交替堆叠的层间协作](#2.4 交替堆叠的层间协作)
- 三、流形约束超连接(mHC):给残差连接戴上"紧箍咒"
-
- [3.1 传统残差连接的问题](#3.1 传统残差连接的问题)
- [3.2 mHC 的数学原理](#3.2 mHC 的数学原理)
- [3.3 工程价值](#3.3 工程价值)
- [四、Muon 优化器与训练工程](#四、Muon 优化器与训练工程)
-
- [4.1 从 AdamW 到 Muon 的范式转变](#4.1 从 AdamW 到 Muon 的范式转变)
- [4.2 MuonClip:Kimi 的原创贡献](#4.2 MuonClip:Kimi 的原创贡献)
- [4.3 异构 KV 缓存设计](#4.3 异构 KV 缓存设计)
- [五、FP4 QAT 量化:极致压缩下的性能平衡](#五、FP4 QAT 量化:极致压缩下的性能平衡)
- 六、工程化挑战与部署考量
-
- [6.1 双平台适配](#6.1 双平台适配)
- [6.2 框架兼容性](#6.2 框架兼容性)
- [6.3 长文本场景的成本分析](#6.3 长文本场景的成本分析)
- 总结
前言
2026 年 4 月 24 日,DeepSeek V4 预览版正式发布,同步开源了 V4-Pro(总参数 1.6 万亿,激活 490 亿)和 V4-Flash(总参数 2840 亿,激活 130 亿)两个版本。这组数据本身已经足够震撼,但更让技术圈沸腾的是它交出的成绩单:
- 百万 token 原生上下文,KV 缓存降至前代的十分之一
- Codeforces 评分 3206 分,超越 GPT-5.4,在人类选手中排第 23 名
- 推理算力仅为 V3.2 的 27%,V4-Flash 输出价格低至每百万 token 0.28 美元
然而作为架构师,我更关心的是------这些性能跃升背后的技术原理是什么? DeepSeek 没有跟风 SSM 或门控 DeltaNet 路线,而是另辟蹊径,在注意力机制、残差连接、优化器三个核心组件上实现了原创性突破。本文将从工程架构视角,逐层拆解 V4 的三大核心技术:混合注意力机制(CSA+HCA)、流形约束超连接(mHC)、以及 Muon 优化器的规模化应用。
一、MoE 架构再进化:万亿参数下的高效稀疏化
1.1 MoE 的基本原理回顾
混合专家(Mixture of Experts, MoE)架构的核心思想是:不是所有参数都需要参与每次前向传播。通过门控网络(Router)动态选择少数专家(Expert)处理当前输入,可以在保持模型表达能力的同时,大幅降低推理时的激活参数量。
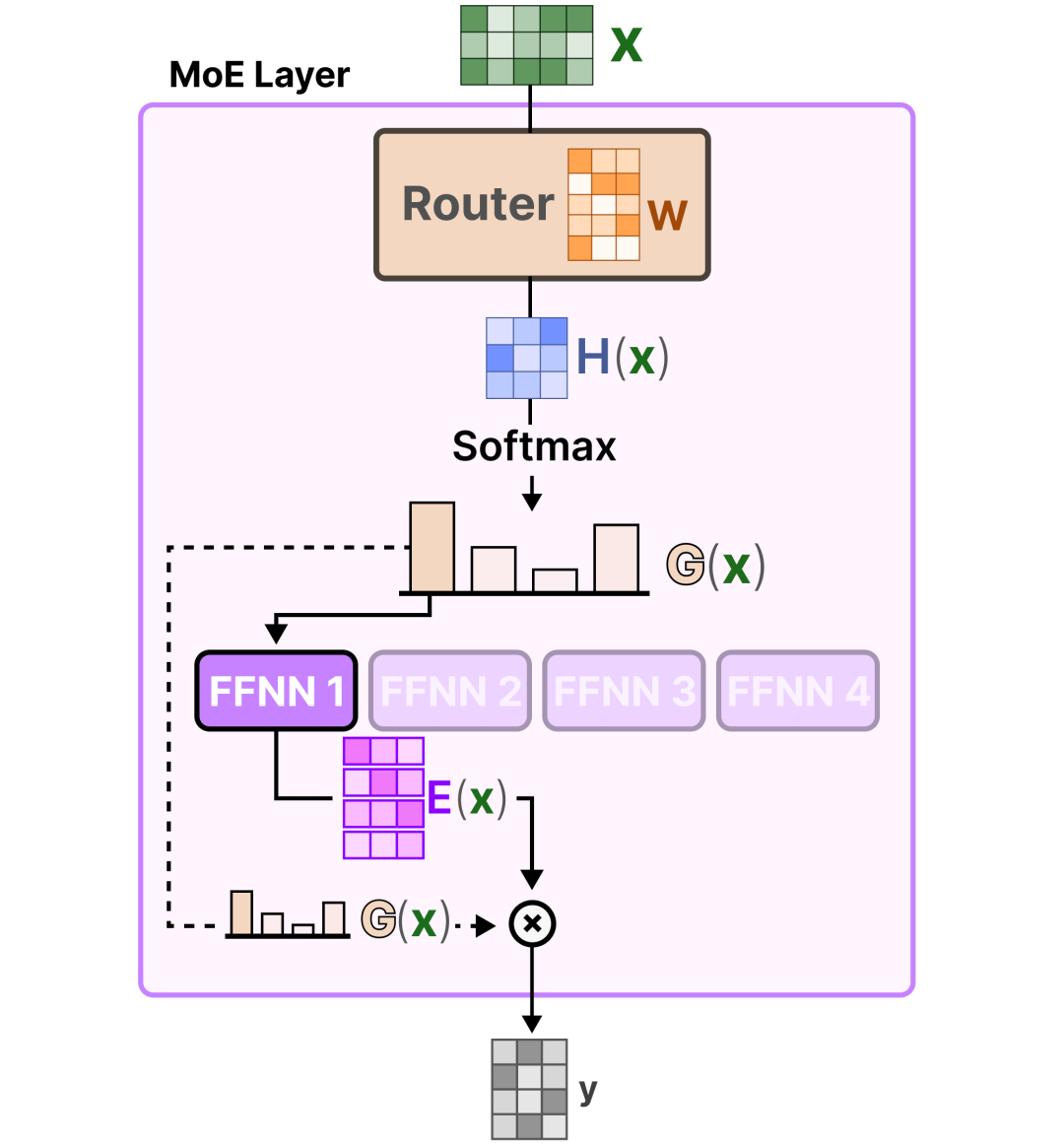
1.2 V4 的 MoE 设计
DeepSeek V4 延续了 MoE 架构路线,但在以下几个方面做了关键升级:
| 维度 | V3 | V4-Pro |
|---|---|---|
| 总参数量 | 671B | 1.6T |
| 激活参数量 | 37B | 49B |
| 专家数量 | 256 | 更大规模 |
| 每 token 激活专家数 | 8 | 动态调整 |
| 上下文窗口 | 128K | 1M(100万) |
关键设计点:
-
细粒度专家切分:将 FFN 层拆分为大量小型专家,每个专家专注于特定类型的模式识别。这种设计使得在 1.6 万亿参数规模下,每次推理仅激活约 490 亿参数,激活率约 3%。
-
负载均衡约束:通过辅助 loss 强制 Router 均匀分配 token 到各专家,避免"强者愈强"的马太效应导致部分专家退化。
-
共享专家机制:部分专家被设计为"共享专家",对所有 token 激活,捕获通用特征;其余为"路由专家",按输入内容动态选择。
这种"大总参 + 小激活"的设计,是 V4 能在保持顶尖性能的同时控制推理成本的关键。
二、混合注意力机制:CSA + HCA 的长文本突破
长文本处理一直是 LLM 的工程瓶颈。传统的 Softmax Attention 计算复杂度和 KV 缓存都随序列长度呈 O ( n 2 ) O(n^2) O(n2) 增长,百万 token 场景下直接面临显存爆炸。
2.1 为什么不用 SSM 替代注意力?
2025-2026 年间,Mamba、DeltaNet 等 SSM 架构一度被视为注意力的替代方案。但 DeepSeek 的选择很明确:不抛弃注意力,而是改造它。原因有二:
- 注意力机制在长程依赖建模上的理论优势已被充分验证
- SSM 在复杂推理和代码生成任务上仍有精度差距
DeepSeek 的解法是:混合注意力机制------在不同层交替使用 CSA 和 HCA。
2.2 CSA:压缩稀疏注意力(Compressed Sparse Attention)
CSA 的核心思路是局部压缩 + 稀疏选择:
-
分组压缩:将输入序列每 4 个 token 的 KV 缓存压缩为 1 个条目,序列长度直接降至原来的 1/4。
-
轻量索引:通过一个轻量级的索引器(Indexer),对压缩后的 KV 条目进行重要性评分。
-
Top-K 稀疏选择:每个 Query 仅关注评分最高的 512-1024 个压缩条目,而非全量计算。
python
# CSA 伪代码示意(非官方实现,仅为原理说明)
def compressed_sparse_attention(Q, KV_compressed, top_k=1024):
# Step 1: 轻量索引器计算重要性分数
scores = lightweight_indexer(Q, KV_compressed) # [seq_len, compressed_seq_len]
# Step 2: Top-K 选择
top_indices = torch.topk(scores, k=top_k, dim=-1).indices
# Step 3: 仅对选中的 KV 条目计算注意力
KV_selected = gather(KV_compressed, top_indices)
output = scaled_dot_product_attention(Q, KV_selected)
return output通过这种设计,CSA 在局部范围内保留了足够的信息密度,同时将计算量大幅压缩。
2.3 HCA:重压缩注意力(Heavily Compressed Attention)
如果说 CSA 是"局部精细压缩",HCA 则是"全局激进摘要":
- 压缩比 128:1:每 128 个 token 合并为 1 个摘要向量
- 全局稠密计算:虽然压缩比激进,但在全局范围内保持稠密注意力计算
- 职责分工:HCA 主要捕获全局长距离依赖,与 CSA 形成互补
2.4 交替堆叠的层间协作
V4 的 Transformer 层中,CSA 和 HCA 交替堆叠:
[CSA 层] → [HCA 层] → [CSA 层] → [HCA 层] → ...同时,所有层仍然基于注意力机制,并将压缩标记流与滑动窗口注意力标记连接。这种设计既保留了注意力的表达能力,又通过分层压缩策略将百万 token 场景下的推理成本降至可接受范围。
实际效果:
- 推理算力降至 V3.2 的 27%
- KV 缓存降至前代的 1/10
- 原生支持 100 万 token 上下文
三、流形约束超连接(mHC):给残差连接戴上"紧箍咒"
如果说注意力机制是 Transformer 的"眼睛",那么残差连接就是它的"骨架"。长期以来,标准残差连接几乎从未被改动过------直到 DeepSeek V4。
3.1 传统残差连接的问题
深层 Transformer 网络中,残差连接的累积效应容易导致:
- 数值爆炸:多层叠加后信号幅值指数级增长
- 梯度不稳定:训练初期容易出现 loss spike
- 归一化依赖:高度依赖 LayerNorm/ RMSNorm 来压制幅值
3.2 mHC 的数学原理
DeepSeek 的解决方案是将残差映射矩阵约束在双随机矩阵流形(Birkhoff 多面体)上:
B n = { X ∈ R n × n ∣ X i j ≥ 0 , ∑ j X i j = 1 , ∑ i X i j = 1 } \mathcal{B}n = \{ X \in \mathbb{R}^{n \times n} \mid X{ij} \geq 0, \sum_j X_{ij} = 1, \sum_i X_{ij} = 1 \} Bn={X∈Rn×n∣Xij≥0,j∑Xij=1,i∑Xij=1}
这个约束保证了两件事:
- 谱范数 ≤ 1:信号在深层传播时不会发散
- 信息守恒:每层的输入信息总量不会无故放大或缩小
3.3 工程价值
- 仅增加 6.7% 计算代价,换来训练稳定性的质的提升
- 减少对归一化层的依赖,网络设计更灵活
- DeepSeek 是目前已知唯一将 mHC 投入生产的实验室
从架构师视角看,这是一个典型的"用数学约束换取工程确定性"的设计范式。它不追求参数的堆砌,而是通过结构化的约束让深层网络的训练过程更可预测、更可控。
四、Muon 优化器与训练工程
4.1 从 AdamW 到 Muon 的范式转变
主流大模型训练长期依赖 AdamW 优化器,它对每个参数独立做自适应缩放。但 AdamW 有一个隐含假设:参数之间是独立的。
Muon 的核心创新在于对整个梯度矩阵做 Newton-Schulz 正交化:
X k + 1 = 3 2 X k − 1 2 X k 3 X_{k+1} = \frac{3}{2}X_k - \frac{1}{2}X_k^3 Xk+1=23Xk−21Xk3
这使得更新方向在矩阵空间中更加均匀,避免了 AdamW 在高维空间中可能出现的"某些方向过度更新、某些方向更新不足"的问题。
4.2 MuonClip:Kimi 的原创贡献
DeepSeek V4 的技术报告明确引用了 Kimi 团队的 MuonClip 工作:
- 在 Muon 基础上加入 QK-clip 机制
- 控制注意力 logits 的数值范围,防止极端值
- Kimi K2 在 15.5 万亿 token 预训练中实现全程零 loss spike
V4 继承了这一优化器方案,并在万亿参数规模上验证了其有效性。这也是中国开源社区"技术互相加持"的一个典型案例------Kimi 用 DeepSeek 首创的 MLA,DeepSeek 用 Kimi 验证的 Muon。
4.3 异构 KV 缓存设计
V4 在工程层面还设计了异构 KV 缓存结构:
- 压缩 KV 与 滑动窗口 KV 分开管理
- 支持磁盘级存储卸载
- 与 CSA/HCA 的压缩策略深度协同
这套设计让百万 token 上下文不再是"纸面参数",而是可以实际运行的工程方案。
五、FP4 QAT 量化:极致压缩下的性能平衡
V4 在量化技术上同样激进,采用了 FP4 量化感知训练(QAT):
| 量化精度 | 显存占用 | 精度损失 |
|---|---|---|
| FP16/BF16 | 基准 | 无 |
| INT8 | ~50% | 轻微 |
| INT4 | ~25% | 可控 |
| FP4(QAT) | ~25% | 最小 |
FP4 相比 INT4 的优势在于保留了符号位和小数位的灵活分配,更适合注意力分数和激活值的分布特性。通过量化感知训练,模型在训练阶段就适应了低精度表示,部署时的精度损失被最小化。
这为 V4-Flash 版本的轻量化部署奠定了基础------让普通硬件也能运行前沿模型能力。
六、工程化挑战与部署考量
作为架构师,在评估一项新技术时,除了看性能指标,更要看落地可行性。以下是我关注的几个现实问题:
6.1 双平台适配
V4 已完成 NVIDIA GPU 和 华为昇腾 NPU 双平台验证。这对国内企业是一个重要信号------不再被单一硬件生态绑定。但同时也意味着:
- 两套推理栈需要分别优化
- 算子兼容性需要持续维护
- 昇腾生态的工具链成熟度仍在追赶中
6.2 框架兼容性
全新的混合注意力架构和 mHC 连接,对现有深度学习框架提出了适配要求:
- PyTorch 原生实现需要自定义算子
- vLLM、TGI 等推理框架需要新增 CSA/HCA 的 paged attention 支持
- 迁移成本在短期内不可忽视
6.3 长文本场景的成本分析
虽然 V4 的 KV 缓存降至 1/10,但百万 token 场景的实际成本仍需理性评估:
- 预填充阶段:CSA/HCA 的压缩策略有效,但首次处理仍需要完整扫描
- 增量生成阶段:KV 缓存管理是关键,异构设计有效但增加了复杂度
- 磁盘卸载:支持磁盘级存储是好事,但 I/O 延迟可能成为新的瓶颈
总结
DeepSeek V4 的技术架构,代表了一种"不追风口、回归本质"的技术路线。它没有用 SSM 替换注意力,而是通过 CSA+HCA 的混合设计在注意力框架内解决了长文本效率问题;它没有简单地堆砌参数,而是用 mHC 的数学约束让深层网络训练更稳定;它没有闭门造车,而是吸纳了开源社区(如 Kimi 的 MuonClip)的验证成果。
对于正在做技术选型的架构师和开发者,我的建议是:
- 关注 V4-Flash 版本:284B 总参、13B 激活,更适合企业级私有化部署
- 评估长文本需求:如果你的业务涉及法律文档、学术论文、代码库分析等场景,V4 的百万上下文+低成本架构值得优先验证
- 做好迁移准备:新架构意味着新算子、新推理栈,建议先在非核心业务线做 POC 验证
开源的价值不只是"免费使用",更是"可以拆开来看"。DeepSeek V4 近 60 页的技术报告已经公开,建议有精力的同学直接阅读原始论文------那里面藏着更多工程细节。
如果你正在评估 V4 在你的业务场景中的落地方案,或者对 CSA/HCA 的具体实现有疑问,欢迎在评论区交流。