Note:强化学习(五)
2026 | ming

十二. 强化学习的分类
至此,到这里我们已经学习了很多强化学习算法了,现在就来对这些强化学习算法归归类。大体分类如图12.1所示。
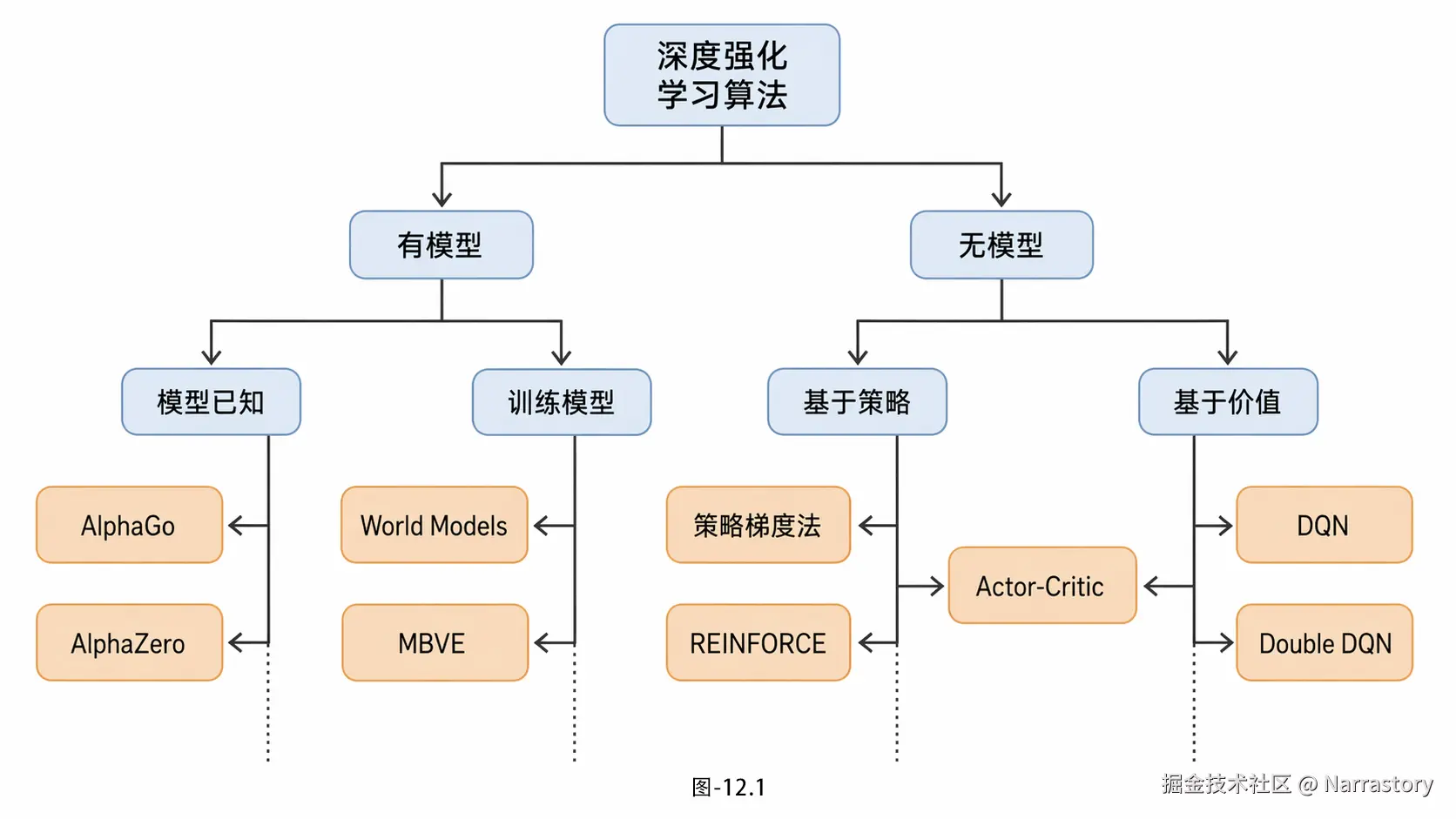
12.1 依据环境模型
① 有没有环境模型?(Model-Free vs Model-Based)
强化学习里最本质的一个分野,就是智能体是否知道环境的动力学 ------也就是状态怎么转移、奖励怎么给。我们通常把这条边界叫作 Model-Free 和 Model-Based 的分界。
Model-Free:不建模,直接干
这是目前深度学习时代最主流、最"暴力"的一派。它的核心思想很简单:我不去琢磨环境是怎么运转的,我只关心在当前状态下做什么动作最划算。 Q-Learning、DQN、REINFORCE、Actor-Critic,全部属于这一阵营。
Model-Free 的优势在于通用性------你不需要知道状态转移概率 P(s′∣s,a) 和奖励函数 R(s,a) 的具体形式,只要能源源不断地跟环境交互拿到 (s,a,r,s′) 四元组,就能更新策略或价值函数。代价也很明显:样本效率低。你往往需要在环境里"摸爬滚打"数百万步,才能让策略稳定下来。
② Model-Based:先建个"世界模型",再思考
另一派则认为,如果我能学到一个靠谱的环境模型,那智能体就可以在脑子里做规划(Planning),而不必事事都亲自试错。Model-Based 方法通常又细分成两类:
第一类:环境模型是已知的。 在围棋、象棋这类棋盘游戏里,规则是确定的------你知道当前落子后棋盘会变成什么样,也知道输赢的奖励是多少。这种情况下,你不需要"学习"模型,直接拿它来做规划就行。AlphaGo、AlphaZero 就是典型代表,它们用蒙特卡洛树搜索(MCTS)在已知的游戏规则里"推演"未来,再配合神经网络做价值评估和策略先验,从而做出远超人类的决策。
第二类:环境模型是学出来的。 更现实的情况是,环境模型未知,但我们可以从交互经验中训练一个世界模型来近似它。比如 World Models 就尝试让智能体学习一个压缩的环境表示(VAE)和一个预测未来状态的动态模型(RNN),然后在这个"梦境"里训练策略。还有 MBVE(Model-Based Value Estimation)这类方法,用学到的模型来辅助价值估计或生成虚拟经验,从而减少对真实环境采样的依赖。
有意思的是,这个方向最近又火起来了------大家发现,如果模型学得够准,智能体几乎可以在"脑内"完成大部分训练,只在必要时去真实环境里验证一下。这跟我们人类"先在脑子里过一遍再行动"的直觉非常像,也是通向通用智能(AGI)的一条很有吸引力的路径。
12.2 依据价值策略函数
如果说第一条轴回答的是"用不用模型",那第二条轴回答的就是"学什么"。
① Value-Based:学价值函数
这一派的核心是估计价值函数 。我们通常认为,只要能准确估计出状态-动作价值 Q∗(s,a),最优策略自然就出来了------每个状态选 Q 值最大的动作就行。
Qπ(s,a)=Eπk=0∑∞γkrt+k+1 st=s,at=a
DQN 就是这一派的扛把子。它用一个神经网络 Q(s,a;θ) 去近似最优动作价值函数,通过最小化 Bellman 误差来更新参数。Value-Based 方法的好处是相对稳定、样本利用率高(可以重用经验回放里的数据);缺点是它天然只能处理离散动作空间,而且对超参数比较敏感。
② Policy-Based:直接学策略
另一派则认为,与其绕弯子学价值函数,不如直接对策略 πθ(a∣s) 进行参数化,然后端到端地优化策略。REINFORCE 就是这里的代表。
它的优化目标通常是期望累积奖励:
J(θ)=Eπθt=0∑Trt
策略梯度的基本形式如下:
∇θJ(θ)=Eπθ∇θlogπθ(a∣s)⋅Gt
Policy-Based 方法最大的优势是动作空间友好 ------无论是离散的还是连续的,甚至高维的,它都能直接输出动作分布。而且策略的更新是单调的,不容易出现 Value-Based 里那种 Q 值估计改进但策略退化的情况。不过它的问题也很头疼:方差大,训练不稳定,经常需要玩很多局才能拿到一个靠谱的梯度估计。
③ Actor-Critic:两边都要
既然 Value-Based 方差低但表达能力受限,Policy-Based 灵活但方差高,那能不能把两者结合起来?Actor-Critic 就是这个思路的产物。
它同时维护两个网络:
- Critic :负责估计价值函数 V(s) 或 Q(s,a),给当前策略"打分";
- Actor :负责输出策略 πθ(a∣s),根据 Critic 的打分来调整自己的动作概率。
REINFORCE 里的 Gt 是一个蒙特卡洛回报,噪声很大;而 Actor-Critic 用 Critic 的估计值(比如 TD 误差 δt=rt+γV(st+1)−V(st))来代替 Gt,从而大幅降低了方差。后面的 A3C、PPO、SAC 等算法,本质上都是 Actor-Critic 框架的变体。
看到这里你可能会问:既然 Model-Based 听起来这么优雅,为什么现在工业界和学术界的主流还是 Model-Free?
一个直白的答案是:模型太难学准了 。在复杂环境(比如高维视觉输入的机器人控制)里,你学到的世界模型往往有偏差,而这个偏差会在多步规划里像滚雪球一样放大------这就是所谓的 Model Bias 或 Compounding Error。一旦模型预测错了,基于它的规划就会彻底跑偏。相比之下,Model-Free 虽然"笨",但它每一步都跟真实环境交互,反而更鲁棒。
不过,随着世界模型(World Models)和基于 Transformer 的序列建模(比如 Decision Transformer、GPT-style Trajectory Modeling)的发展,Model-Based 方法正在迎来新一轮复兴。未来的趋势很可能是混合范式------先用 Model-Free 学到一个好的策略或价值函数,再用学到的模型做数据增强、规划或策略蒸馏。
十三. AC算法的现代优化
13.1 共享权重
在我们之前讲解基础Actor-Critic(AC)算法时,一直采用的是"分离网络"设定------Actor网络(策略网络 π )和Critic网络(价值网络 V )各自独立,拥有专属的权重参数,互不干扰。Actor负责输出动作的概率分布,Critic负责评估当前状态的价值,两者各司其职,但这种分离式设计,在实际训练中其实存在可优化的空间,而"共享权重"就是现代AC算法中最常用、最有效的优化方向之一。
首先我们明确核心定义:共享权重,本质上是让Actor和Critic网络共用一部分底层的特征提取网络,仅在网络的顶层(输出层)进行分流,如图13.1所示,一部分权重用于输出策略 π(a∣s)(Actor分支),另一部分权重用于输出状态价值 V(s)(Critic分支)。简单来说,就是"底层同源、顶层分流",而非之前的"从头到尾完全分离"。
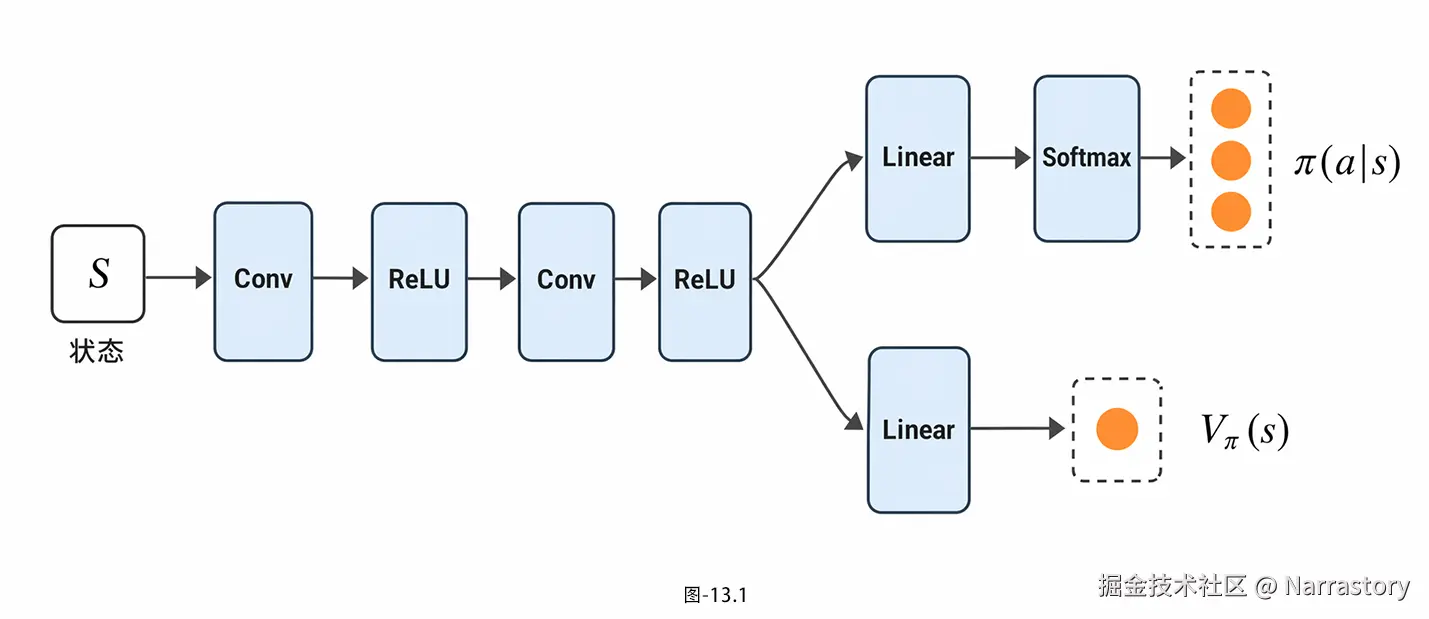
基础AC的分离网络, Actor和Critic需要分别学习状态的特征表示------两者输入都是状态s,却要重复做"从原始状态中提取有效特征"的工作,这会导致参数数量冗余,不仅增加了模型的存储成本,还会减慢训练速度,尤其在状态维度较高(比如图像输入)的场景下,这种冗余带来的效率损耗会更明显。
而共享底层权重后,特征提取的工作只需要做一次,Actor和Critic复用这部分特征,相当于"一个特征提取器,服务两个任务",既减少了参数总量,又能让两个网络在训练中相互促进------Critic学习到的状态价值特征,能帮助Actor更好地理解状态与动作的关联;Actor学习到的动作偏好,也能辅助Critic更精准地评估状态价值,从而提升整体的训练收敛速度。这一优化思路,也为后续A2C、PPO等更高效的AC变体奠定了基础------后续我们会发现,几乎所有主流的现代AC算法,都沿用了这一共享权重的设计。
13.2 A2C算法
常规原生串行AC算法,在落地工程训练时我们会发现它的运行逻辑是:单环境串行逐时序交互+逐样本单步梯度更新。全程只能依托单条环境轨迹滚动采集交互样本,不仅样本采集效率极低,CPU算力长期闲置浪费,我们知道现代CPU基本上都有6核8核等,完全可以采用多线程,在多个并行环境中收集训练数据,从而来加速训练。
更关键的是,串行逐样本更新梯度波动幅度偏大,参数迭代震荡明显,训练后期容易出现收敛不稳、小幅震荡不收敛的问题。哪怕搭配优势函数校准策略梯度,算力利用率低、训练节奏碎片化的硬缺陷依旧没法规避。
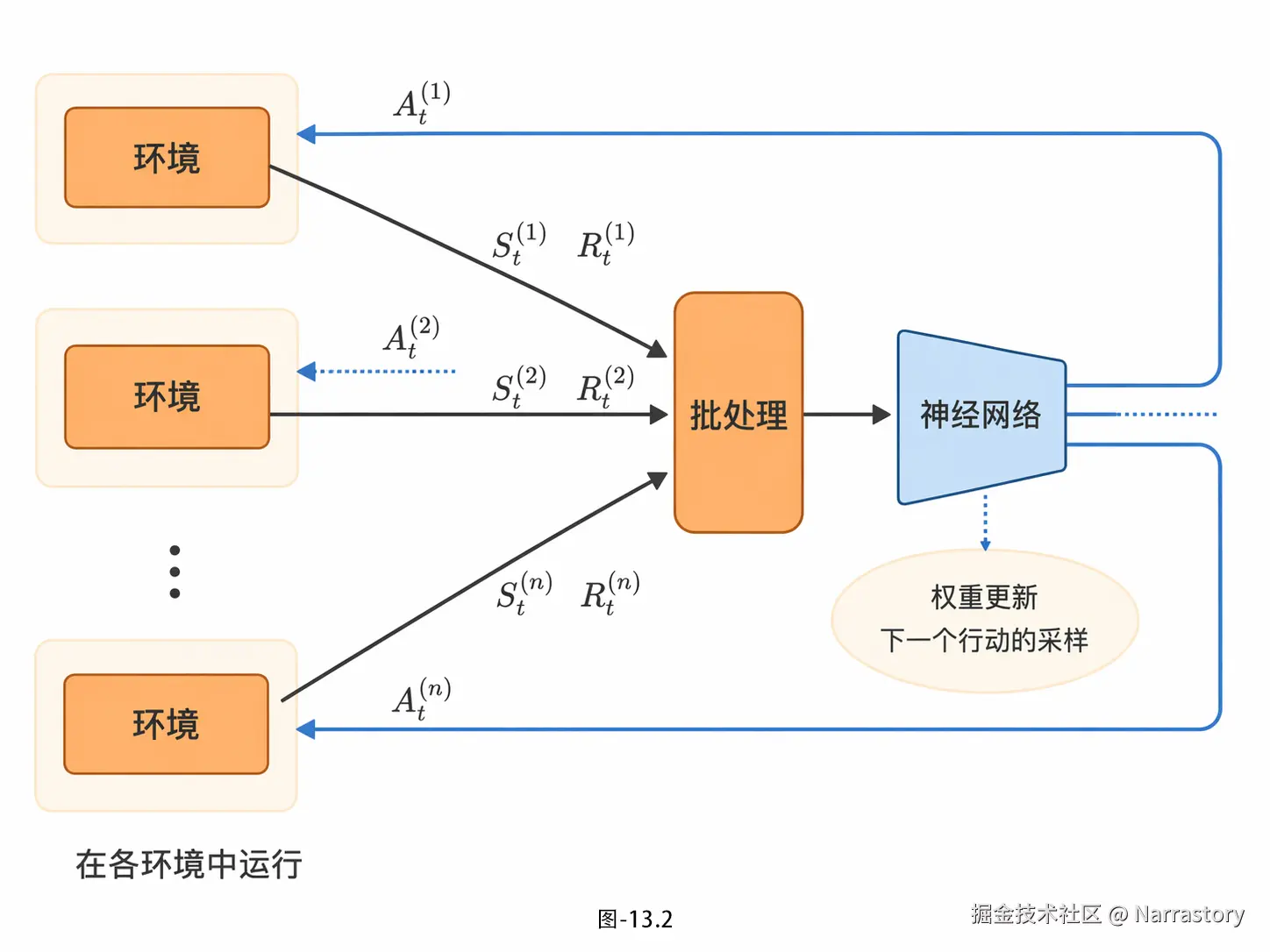
A2C 全称 Advantage Actor-Critic,核心思路就是:多智能体绑定独立并行环境、全时序同步联动、统一批处理组网训练。
实操起来非常直观:智能代理在各自的环境中独立运行,因此,时刻 t 的状态在各个环境中不同。于是我们将时刻 t 在各个环境中的状态同步地作为批处理汇总,进行神经网络的训练。此时,从神经网络的输出(策略的概率分布)中对下一个行动进行采样,并将采样后的行动传给各个环境。实验表明,即使A2C采取了同步更新,其性能也不会下降。另外,A2C更易于实现,它可以高效地利用GPU等计算资源。因此,实践中A2C使用得更多。流程图如图13.2所示。
13.3 熵正则化
在 Actor-Critic 方法里,我们通常让策略网络输出一个动作概率分布,然后采样执行。如果一切顺利,策略会迅速把大部分概率集中到那些"看起来不错"的动作上。这听上去很高效,但也会带来一个经典问题:一旦策略过早地变成近乎确定性,探索就基本停止了。你可能会困在局部最优里,却误以为自己已经找到了全局最优策略。
为了让策略保持"好奇心",熵正则化是一类非常优雅且实用的技巧。它的核心思想非常简单:鼓励策略不要过于自信,尤其在训练早期,让动作分布保持一定的"均匀感"。 这和笔记里说的"前期尽可能平均,后期逐渐集中"完全一致。
我们需要一个函数,当概率分布接近均匀时输出较大值,而当分布集中在一个动作上时输出较小值。信息论中的香农熵完美符合这个需求。对于离散动作空间,给定状态 s 下策略 πθ(⋅∣s) 的熵定义为:
H(π(⋅∣s))=−a∈A∑π(a∣s) log π(a∣s)
可以这样直观理解:如果所有动作的概率都差不多,比如 π=0.25,0.25,0.25,0.25,那么你在该状态下"不知道"智能体会选哪个动作,这种不确定性对应高熵;反之,如果某个动作概率接近1,比如 π=0.99,0.01,0,0,你几乎可以肯定智能体会选它,熵就接近0。把它当作正则项,恰好鼓励了探索。
标准的策略梯度(例如 A2C)中,策略的损失函数是负的期望优势乘以对数概率,即:
Lpolicy(θ)=−Es,a∼πθlogπθ(a∣s)A(s,a)
我们只是在这个损失后面加上一个带负号的熵项。因为损失是要最小化的,而我们希望熵尽量大,所以减去熵:
Ltotal(θ)=Lpolicy(θ)−βEsH(πθ(⋅∣s))
这里的 β>0 是一个超参数,用来控制探索的强度。公式的直觉是:如果你当前的策略很有把握(熵很小),那这个正则项就会施加一个不小的惩罚,逼迫策略重新"发散"一些,去试试别的动作。 当我们在做梯度下降时,熵对应的梯度会推动概率分布远离确定性,让低概率的动作也能分到一些概率质量。
在 A2C 或 PPO 这类算法中,加上熵正则化几乎是标配。它可以有效防止策略"过早崩塌"到次优的确定性动作,尤其在奖励稀疏的环境下,多坚持一会儿随机探索往往能发现更好的 long-term 回报。
13.4 广义优势估计GAE
阅读提示: 这一节是整章中数学最密集的部分。TD误差、蒙特卡洛回报、指数加权平均、递推关系......这些概念会密集出现。如果你第一遍没有完全消化,完全正常。另外,GAE的效果非常不错,它能大幅提升A2C算法的性能,是必须掌握的优化技巧之一。
直观地说,GAE 想解决的问题是:我们既不想像 REINFORCE 那样完全依赖蒙特卡洛回报,因为方差太大;也不想只用一步 TD 误差,因为它太依赖当前价值函数,偏差可能较大。所以 GAE 用一个参数 λ,在两者之间做平滑折中。
①. 为什么 Actor-Critic 需要优势估计?
在策略梯度类算法中,我们更新 Actor 时,通常希望知道:当前这个动作 (a_t) 在状态 (s_t) 下到底比平均水平好多少?这个"好多少",就是优势函数:
Aπ(st,at)=Qπ(st,at)−Vπ(st)
如果 (Aπ(st,at)>0),说明这个动作比当前策略的平均表现更好,应该提高它的概率。
如果 (Aπ(st,at)<0),说明这个动作比平均水平更差,应该降低它的概率。
因此,在 Actor-Critic 中,策略梯度通常可以写成:
∇θJ(θ)Et∇θlogπθ(at∣st)A\^t
这里的核心问题是: A^t 到底应该怎么估计?
这就是 GAE 要解决的问题。
②. 从一步 TD 误差开始
我们先定义一步 TD 误差:
δtV=rt+γV(st+1)−V(st)
其中:
- rt 是当前时刻获得的奖励;
- V(st) 是当前状态价值;
- V(st+1) 是下一个状态价值;
- γ是折扣因子。
这个式非常重要。它的含义是:我原来以为状态 st 的价值是 V(st), 但现在我实际走了一步,发现它应该接近 rt+γV(st+1)。 两者的差距,就是 TD 误差。
如果 V(s) 已经非常接近真实价值函数,那么: δtV=rt+γV(st+1)−V(st)就可以看成当前动作的一种优势估计。于是我们得到单步优势估计器:
A^t(1)=rt+γV(st+1)−V(st)=δtV
它的优点是方差小,因为只看一步奖励和一个 bootstrap 价值估计。
但缺点也很明显:它非常依赖 V(s) 的准确性。如果 Critic 估计得不好,那么这个优势估计就会带有较大偏差。
③. 从一步优势推广到 k 步优势
既然一步 TD 太短,那我们自然可以多看几步。两步优势估计器为:
A^t(2)=rt+γrt+1+γ2V(st+2)−V(st)
这个式子的意思是:先真实地走两步,拿到 rt 和 rt+1, 然后从 st+2 开始再用价值函数 V(st+2) 进行估计。
有意思的是,这个两步优势估计器也可以写成两个 TD 误差的折扣和:
A^t(2)=δtV+γδt+1V
我们可以展开验证一下:
δtV+γδt+1V=(rt+γV(st+1)−V(st))+γ(rt+1+γV(st+2)−V(st+1))=rt+γV(st+1)−V(st)+γrt+1+γ2V(st+2)−γV(st+1)=rt+γrt+1+γ2V(st+2)−V(st)
中间的 γV(st+1) 和 −γV(st+1) 正好抵消掉了。这就是一个典型的"望远镜求和"结构。
继续推广,k 步优势估计器可以写成:
A^t(k)=l=0∑k−1γlrt+l+γkV(st+k)−V(st)
也可以等价写成:
A^t(k)=l=0∑k−1γlδt+lV
这个公式非常关键。它说明:k 步优势估计,本质上就是从当前时刻开始,把未来 k 个 TD 误差按照 γ 折扣加起来。
④. k 步估计的偏差-方差权衡
现在我们已经有了一组优势估计器:
A^t(1),A^t(2),A^t(3),⋯
它们的性质并不一样。一步估计:
A^t(1)=δtV
优点是方差小,缺点是偏差可能大,因为它非常依赖 V(st+1)。
多步估计:
A^t(k)=l=0∑k−1γlrt+l+γkV(st+k)−V(st)
随着 k 增大,它越来越接近蒙特卡洛回报,偏差会降低,但方差会增大。
如果 k 一直走到 episode 结束,并且终止状态价值为 0,那么就接近:
A^tMC=l=0∑T−t−1γlrt+l−V(st)
这就是蒙特卡洛优势估计。所以,我们面对的是一个经典问题:一步 TD:低方差,高偏差。 蒙特卡洛:低偏差,高方差。 那有没有一种方法,可以在它们之间连续调节?GAE 的答案是:有。
⑤. GAE 的核心思想:对 k 步优势做指数加权平均
GAE 的定义是:
A^tGAE(γ,λ)=(1−λ)(A^t(1)+λA^t(2)+λ2A^t(3)+λ3A^t(4)+⋯)
也就是:
A^tGAE(γ,λ)=(1−λ)k=1∑∞λk−1A^t(k)
这里的 λ∈0,1 是 GAE 的核心参数。它控制我们到底更相信短步估计,还是更相信长步估计。当 λ 较小时,权重会快速衰减,GAE 更接近一步 TD。当 λ较大时,长步估计也会获得较高权重,GAE 更接近蒙特卡洛估计。
这里的权重是指数衰减的:
1,λ,λ2,λ3,⋯
因为: 0≤λ≤1 ,所以越长的 k 步估计,权重通常越小。
⑥. GAE 的完整推导
我们从定义开始:
A^tGAE(γ,λ)=(1−λ)(A^t(1)+λA^t(2)+λ2A^t(3)+⋯)
前面已经知道:
A^t(1)=δtVA^t(2)=δtV+γδt+1VA^t(3)=δtV+γδt+1V+γ2δt+2V
所以代入 GAE:
A^tGAE(γ,λ)=(1−λ)δtV+λ(δtV+γδt+1V)+λ2(δtV+γδt+1V+γ2δt+2V)+⋯
接下来,把相同的 TD 误差项合并。
先看 δtV 的系数:
1+λ+λ2+⋯=1−λ1
再看 γδt+1V 的系数:
λ+λ2+λ3+⋯=1−λλ
再看 γ2δt+2V 的系数:
λ2+λ3+λ4+⋯=1−λλ2
因此:
A^tGAE(γ,λ)=(1−λ)δtV1−λ1+γδt+1V1−λλ+γ2δt+2V1−λλ2+⋯=δtV+γλδt+1V+(γλ)2δt+2V+⋯
最终得到 GAE 最常用的形式:
A^tGAE(γ,λ)=l=0∑∞(γλ)lδt+lV
这就是 GAE 的核心公式。它非常漂亮:GAE 不是直接对奖励做折扣求和,而是对未来的 TD 误差做折扣求和。 折扣因子不再只是 γ,而是 γλ。
⑦. 如何理解 λ?
λ 可以看成一个"未来 TD 误差信任系数"。GAE 的公式是:
A^tGAE(γ,λ)=δtV+γλδt+1V+(γλ)2δt+2V+⋯
如果 λ=0,那么:
A^tGAE(γ,0)=δtV
也就是单步 TD 误差。此时估计方差较小,但对 Critic 的依赖更强,偏差可能更大。如果 λ=1,那么:
A^tGAE(γ,1)=l=0∑∞γlδt+lV
在有限 episode 中,这会退化为接近蒙特卡洛形式的优势估计:
A^tGAE(γ,1)≈l=0∑T−t−1γlrt+l−V(st)
此时偏差较小,但方差较大。所以:
λ=0⇒one-step TD advantageλ=1⇒Monte Carlo advantage
而实际深度强化学习中,我们通常取一个中间值,例如: λ=0.95。这也是 PPO、A2C 等算法里非常常见的设置。它背后的直觉是:不完全相信一步 TD,也不完全相信整条轨迹的蒙特卡洛回报,而是在两者之间取一个比较稳的折中。
⑧. GAE 的递推形式
虽然 GAE 的定义看起来是一个无限和:
A^t=δt+γλδt+1+(γλ)2δt+2+⋯
但在代码里,我们不会真的展开所有项,而是利用递推关系。
先写出下一时刻的 GAE:
A^t+1=δt+1+γλδt+2+(γλ)2δt+3+⋯
两边乘上 γλ:
γλA^t+1=γλδt+1+(γλ)2δt+2+(γλ)3δt+3+⋯
再加上 δt:
δt+γλA^t+1=δt+γλδt+1+(γλ)2δt+2+⋯
这正好就是: A^t,所以:
A^tGAE=δt+γλA^t+1GAE
这就是 GAE 在代码中的核心递推公式。如果考虑 episode 终止,我们需要加上 done mask:
δt=rt+γ(1−dt)V(st+1)−V(st)
其中 dt=1 表示当前 transition 后 episode 结束。递推式也变成:
A^t=δt+γλ(1−dt)A^t+1
这个 (1−dt) 很重要。它表示:如果当前 episode 已经结束,就不能再把下一个 episode 的价值接到当前 episode 后面。
⑨. GAE 和 value target 的关系
在 Actor-Critic 里,GAE 主要用于更新 Actor,因为它提供了优势估计: A^t。但 Critic 也需要训练目标。通常我们会用:
R^t=A^t+V(st)
也就是:
value target=advantage+current value estimate
直观理解是:
A(st,at)=Q(st,at)−V(st)
所以反过来:
Q(st,at)=A(st,at)+V(st)
因此,GAE 得到的优势 A^t 加上当前价值估计 V(st),就可以作为 Critic 的回归目标:
LV=Et(Vϕ(st)−R\^t)2
在 PPO / A2C 的实现中,经常会看到类似逻辑:
R^t=A^t+V(st)
然后用 R^t 训练 Critic,用 A^t 更新 Actor。
十四. 现代A2C算法模板
在实际研究或工程项目中,从头实现一个强化学习算法往往耗时且容易出错。所以,拥有一份结构清晰,易于扩展的代码模板就很重要。本节将为你提供一份现代 A2C算法的标准实现骨架,它整合了多项在实践中被反复验证有效的优化技巧,并可直接在 Gymnasium 的 CartPole‑v1 和 LunarLander‑v3 环境上运行测试。
这份模板的核心思想很朴素:让算法实现既保持学术上的严谨,又具备工业级的可读性与可迁移性。代码中的注释极其详尽,每一处关键计算都尽量用与公式对应的变量名来命名,因此你完全可以把它当成一份"可运行的数学推导"。无论你是想快速验证某个小想法------比如调整优势估计的 λ 参数、更换策略网络的激活函数,还是想将其直接嵌入到一个更复杂的多智能体或分层强化学习系统中------只需修改很少的地方就能跑通实验。
首先引入必要库:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributions import Categorical
from typing import Tuple, Optional
import gymnasium as gym
from gymnasium.wrappers.vector import NumpyToTorch
from tqdm import tqdm
from collections import deque
import time
# 绘图函数需要引入的库
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.ticker import AutoMinorLocator14.1 GAE
python
class GAE:
"""
广义优势估计器 (Generalized Advantage Estimator, GAE),用于策略梯度方法。
使用 TD(λ) 风格的递归计算优势,并在回合(episode)边界处进行截断。
"""
def __init__(self, gamma: float, gae_lambda: float):
"""
参数:
gamma: 折扣因子 (0 < gamma ≤ 1)
gae_lambda: GAE 参数 (0 ≤ gae_lambda ≤ 1),控制偏差-方差权衡。
取值越大,方差越小但偏差越大;lambda=1 时退化为蒙特卡洛,
lambda=0 时退化为 TD(0)。
"""
self.gamma = gamma
self.gae_lambda = gae_lambda
def __call__(self, done: torch.Tensor, rewards: torch.Tensor, values: torch.Tensor) -> torch.Tensor:
"""
计算 GAE 优势。
参数:
done: 形状 (batch_size, n_steps) 的张量。若该时间步结束时回合终止则为 1.0,
否则为 0.0。用于在终止处截断信用分配。
rewards: 形状 (batch_size, n_steps) 的奖励张量。
values: 形状 (batch_size, n_steps + 1) 的状态价值估计张量。
values[:, -1] 是最后一步之后状态的"引导值"(bootstrap value),
即 V(s_{T+1}),若该状态为终止状态则通常为 0。
返回:
advantages: 形状 (batch_size, n_steps) 的优势估计张量 A_t。
"""
batch_size, n_steps = rewards.shape
# 输入校验:values 必须比 rewards 多一个时间步(包含 V(s_{T+1}))
assert values.shape == (batch_size, n_steps + 1), \
f"values 的形状 {values.shape} 必须是 (batch_size, n_steps+1)"
advantages = torch.zeros_like(rewards)
# 反向递归的初始运行变量
last_advantage = 0.0 # A_{T+1} = 0,优势估计在序列末尾为 0
last_value = values[:, -1] # V(s_{T+1}),来自最后一步之后的 bootstrap
# 从最后一个时间步开始向前遍历
for t in reversed(range(n_steps)):
# mask: 若回合在时间步 t 结束(done[:, t] == 1),mask = 0;否则 mask = 1。
mask = 1.0 - done[:, t]
# 终止回合的重置:如果 done 为 1,则接下来用到的 V(s_{t+1}) 和 A_{t+1} 都应为 0
last_value = last_value * mask
last_advantage = last_advantage * mask
# TD 误差: δ_t = r_t + γ * V(s_{t+1}) - V(s_t)
delta = rewards[:, t] + self.gamma * last_value - values[:, t]
# GAE 递归: A_t = δ_t + γ * λ * A_{t+1}
last_advantage = delta + self.gamma * self.gae_lambda * last_advantage
advantages[:, t] = last_advantage
# 更新 last_value 为 V(s_t),供下一步(t-1)使用。
# 若回合在 t 终止,那么从 t-1 看 V(s_t) 应当为 0(终态价值为 0),
# 因此乘上 mask 将其置零。
last_value = values[:, t] * mask
return advantages14.2 价值策略网络
python
class ActorCriticNet(nn.Module):
"""
带有共享特征主干的Actor-Critic网络。
本实现遵循现代策略梯度方法中的常见设计:
- 一个共享编码器提取状态特征
- 两个独立的"头"分别用于:
* 策略(Actor):输出动作的 logits(未归一化分数)
* 价值函数(Critic):估计 V(s)
关键设计选择:
- 使用LayerNorm稳定训练
- 使用正交初始化提升RL的收敛性
- 输出logits而不是概率,以获得更好的数值稳定性
适用算法:
- A2C / A3C
- PPO
- 其他基于离散动作的在线策略RL算法
"""
def __init__(self, state_dim: int, action_dim: int, hidden_size: int = 256):
"""
参数:
state_dim (int): 输入状态空间的维度。
action_dim (int): 离散动作的数量。
hidden_size (int): 共享特征主干中隐藏层的大小。
"""
super().__init__()
# 共享特征提取器:两层全连接 + LayerNorm + ReLU
self.shared = nn.Sequential(
nn.Linear(state_dim, hidden_size),
nn.LayerNorm(hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.LayerNorm(hidden_size),
nn.ReLU(),
)
# 动作头:输出每个动作的logits
self.actor = nn.Linear(hidden_size, action_dim)
# 价值头:输出一个标量V(s)
self.critic = nn.Linear(hidden_size, 1)
self._init_weights()
def _init_weights(self):
"""
使用正交初始化网络参数。
为什么要用正交初始化?
- 在RL中广泛使用(如OpenAI Baselines、Stable-Baselines3)
- 有助于保持层间信号传播,避免梯度消失/爆炸
- 实验表明能带来更稳定、更快的收敛
增益(gain)设置说明:
- ReLU层:使用 calculate_gain('relu') 保持信号幅度
- Actor头:小增益(0.01)→ 防止策略一开始过于自信,鼓励探索
- Critic头:增益为1.0 → 回归任务的标准缩放
"""
for module in self.shared.modules():
if isinstance(module, nn.Linear):
nn.init.orthogonal_(module.weight, gain=nn.init.calculate_gain("relu"))
nn.init.constant_(module.bias, 0.0)
elif isinstance(module, nn.LayerNorm):
# LayerNorm的weight初始化为1,bias初始化为0
nn.init.constant_(module.weight, 1.0)
nn.init.constant_(module.bias, 0.0)
# Actor:较小增益使初始策略近似均匀分布
nn.init.orthogonal_(self.actor.weight, gain=0.01)
nn.init.constant_(self.actor.bias, 0.0)
# Critic:标准增益
nn.init.orthogonal_(self.critic.weight, gain=1.0)
nn.init.constant_(self.critic.bias, 0.0)
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
"""
网络的前向传播。
参数:
x (torch.Tensor): 输入状态,形状为 (batch_size, state_dim)
返回:
logits (torch.Tensor): 动作的logits(未归一化分数),形状 (batch_size, action_dim)
value (torch.Tensor): 状态价值估计 V(s),形状 (batch_size, 1)
注意:
- 返回logits而不是概率,是为了数值稳定;softmax会在后续的Categorical分布内部隐式完成。
"""
features = self.shared(x)
logits = self.actor(features)
value = self.critic(features)
return logits, value
def get_action_and_value(
self, x: torch.Tensor, action: Optional[torch.Tensor] = None
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
"""
计算动作、对数概率、熵以及状态价值。
这是一个整合了以下步骤的便捷方法:
- 前向传播
- 动作采样或评估
- 对数值概率计算
- 熵计算(常用于探索正则化)
参数:
x (torch.Tensor):
输入状态,形状可以为:
- (batch_size, state_dim) 批量状态
- (state_dim,) 单个状态
action (Optional[torch.Tensor]):
如果提供了指定的动作,则计算该动作下的log_prob和熵,
通常用于训练更新阶段(如PPO的importance sampling)。
如果为None,则从当前策略中随机采样一个动作,
通常用于与环境交互阶段。
返回:
action (torch.Tensor): 采样得到的(或传入的)动作
log_prob (torch.Tensor): 所选动作对应的对数概率
entropy (torch.Tensor): 动作分布的熵(用作探索奖励)
value (torch.Tensor): 状态价值估计
实现细节:
- 使用 Categorical(logits=logits) 而非直接传入probs:
→ 避免softmax带来的数值不稳定
- 自动处理单个状态的输入:
→ 内部添加batch维度,计算完成后再移除
"""
# 检测是否为单个状态(没有batch维度)
single_input = x.dim() == 1
if single_input:
x = x.unsqueeze(0) # 添加 batch 维度
# 前向传播得到logits和value
logits, value = self.forward(x)
# 基于logits构建类别分布(内部会自动做softmax)
dist = Categorical(logits=logits)
if action is None:
# 与环境交互:采样一个动作
action = dist.sample()
# 计算该动作的对数概率
log_prob = dist.log_prob(action)
# 计算分布的熵(用于探索奖励)
entropy = dist.entropy()
# 如果输入是单个状态,去掉之前添加的batch维度
if single_input:
action = action.squeeze(0)
log_prob = log_prob.squeeze(0)
entropy = entropy.squeeze(0)
value = value.squeeze(0)
return action, log_prob, entropy, value14.3 A2C Agent
python
class A2C:
"""
Advantage Actor-Critic (A2C) 算法实现(带 GAE 与并行环境)。
A2C 的核心流程:
- 使用多个并行环境收集 rollout 数据
- 计算广义优势估计 (GAE)
- 联合优化策略网络(Actor)与价值网络(Critic)
- 包含学习率线性衰减、奖励缩放、评估等功能
"""
def __init__(
self,
envs, # 向量化训练环境(支持自动 reset)
eval_env, # 评估用的单环境(通常与训练环境相同但不并行)
state_dim: int, # 状态向量的维度
action_dim: int, # 离散动作空间的维度
hidden_size: int = 256, # 策略/价值网络的隐藏层大小
lr: float = 7e-4, # 初始学习率
min_lr_rate: float = 0.01, # 学习率衰减时的最小倍率(相对于初始 lr)
gamma: float = 0.99, # 折扣因子
gae_lambda: float = 0.95, # GAE 的 λ 参数
value_loss_coef: float = 0.5, # 价值损失在总损失中的系数
entropy_coef: float = 0.01, # 熵正则项系数
max_grad_norm: float = 0.5, # 梯度裁剪的最大范数
rollout_steps: int = 128, # 每次 rollout 收集的步数(每个环境)
avg_eval_window: int = 20, # 计算评估奖励滑动平均的窗口大小
rewards_scale_rate: float = 1.0, # 奖励缩放因子(用于奖励归一化)
):
# 保存环境与基本配置
self.envs = envs
self.eval_env = eval_env
self.num_envs = envs.num_envs # 并行环境的数量
self.rollout_steps = rollout_steps
self.value_loss_coef = value_loss_coef
self.entropy_coef = entropy_coef
self.max_grad_norm = max_grad_norm
self.global_step = 0 # 全局训练步数计数器
self.init_lr = lr
self.min_lr_rate = min_lr_rate
self.avg_eval_window = avg_eval_window # 滑动平均窗口大小(用于评估指标显示)
self.rewards_scale_rate = rewards_scale_rate
# 初始化 Actor-Critic 网络与优化器(使用 RMSprop)
self.actor_critic = ActorCriticNet(state_dim, action_dim, hidden_size)
self.optimizer = torch.optim.RMSprop(
self.actor_critic.parameters(),
lr=lr,
alpha=0.99,
eps=1e-5
)
# 广义优势估计器
self.gae = GAE(gamma, gae_lambda)
# 重置所有并行环境,获取初始观测
self.current_obs, _ = self.envs.reset()
def rewards_normalize(self, rewards: torch.Tensor) -> torch.Tensor:
"""通过除以缩放因子来对奖励进行缩放,用于稳定训练。"""
return rewards / self.rewards_scale_rate
def collect_rollouts(self, n_steps: int):
"""
从并行的向量化环境中收集指定步数的轨迹数据。
参数:
n_steps: 每个环境需要向前执行的步数。
返回:
一个字典,包含:
- states: 形状 [num_envs, n_steps, *state_shape] 的状态序列
- actions: 形状 [num_envs, n_steps] 的动作序列(int32)
- advantages: 归一化后的优势估计,形状 [num_envs, n_steps]
- returns: TD(λ) 回报(值目标),形状 [num_envs, n_steps]
"""
self.actor_critic.eval() # 收集数据时切换到评估模式(不启用 dropout/batchnorm)
states_list, actions_list, values_list, rewards_list, dones_list = [], [], [], [], []
with torch.no_grad(): # 不记录梯度,减少内存消耗
for _ in range(n_steps):
obs_tensor = self.current_obs
states_list.append(obs_tensor)
# 通过 Actor-Critic 网络获取动作、对数概率、熵和当前状态价值
act, _, _, val = self.actor_critic.get_action_and_value(obs_tensor)
actions_list.append(act)
values_list.append(val.squeeze(-1)) # 价值输出形状变为 [num_envs]
# 执行动作,接收环境反馈
next_obs, rew, term, trunc, _ = self.envs.step(act.int().cpu().numpy())
# 确保所有数据都是 PyTorch 张量
if not torch.is_tensor(rew):
rew = torch.as_tensor(rew)
if not torch.is_tensor(term):
term = torch.as_tensor(term)
if not torch.is_tensor(trunc):
trunc = torch.as_tensor(trunc)
if not torch.is_tensor(next_obs):
next_obs = torch.as_tensor(next_obs)
rewards_list.append(rew)
# 终止信号:环境自然结束或人为截断均视为 done
dones_list.append(torch.logical_or(term, trunc).float())
self.current_obs = next_obs
# 将列表堆叠成张量,时间维度统一放在 dim=1
states = torch.stack(states_list, dim=1) # [num_envs, n_steps, ...]
actions = torch.stack(actions_list, dim=1).to(torch.int32)
values = torch.stack(values_list, dim=1)
rewards = torch.stack(rewards_list, dim=1).to(torch.float32)
dones = torch.stack(dones_list, dim=1)
# 可选奖励缩放
rewards = self.rewards_normalize(rewards)
# 计算下一状态的价值,用于 GAE 中的 Bootstrap
with torch.no_grad():
next_val = self.actor_critic.forward(self.current_obs)[1].squeeze(-1) # [num_envs]
# 将最后一时刻的价值拼接到 values 尾部,方便 GAE 计算
values_full = torch.cat([values, next_val.unsqueeze(1)], dim=1) # [num_envs, n_steps+1]
# 使用 GAE 计算优势估计
advantages = self.gae(dones, rewards, values_full) # [num_envs, n_steps]
# TD(λ) 回报 = 优势 + 价值(即值函数的目标)
returns = advantages + values
# 对优势进行标准化(均值 0,标准差 1),稳定训练
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
return dict(
states=states,
actions=actions,
advantages=advantages,
returns=returns
)
def update(
self,
states: torch.Tensor, # [num_envs, n_steps, ...]
actions: torch.Tensor, # [num_envs, n_steps]
advantages: torch.Tensor, # [num_envs, n_steps]
returns: torch.Tensor, # [num_envs, n_steps]
) -> Tuple[float, float, float, float]:
"""
利用收集到的 rollout 数据更新 Actor-Critic 网络。
参数:
states: 观察序列
actions: 执行的动作
advantages: 归一化后的优势
returns: 回报(值目标)
返回:
(policy_loss, value_loss, entropy_loss, total_loss) 各项损失的标量值
"""
self.actor_critic.train() # 切换为训练模式
# 将多环境多步数据展平为一大批次,便于一次性计算
batch_states = states.reshape(-1, *states.shape[2:])
batch_actions = actions.reshape(-1)
batch_advantages = advantages.reshape(-1)
batch_returns = returns.reshape(-1)
# 重新计算当前策略下这些动作的对数概率、熵以及状态价值
_, log_probs_curr, entropies_curr, values_curr = \
self.actor_critic.get_action_and_value(batch_states, batch_actions)
values_curr = values_curr.squeeze(-1) # 确保形状与回报一致
# 策略损失(最大化优势 * 对数概率 ≈ 最小化负的优势 * 对数概率)
policy_loss = -(log_probs_curr * batch_advantages).mean()
# 价值损失(均方误差,使价值估计接近回报)
value_loss = F.mse_loss(values_curr, batch_returns) * self.value_loss_coef
# 熵损失(最大化熵 ≈ 最小化负熵,乘以系数)
entropy_loss = -entropies_curr.mean() * self.entropy_coef
# 总损失
loss = policy_loss + value_loss + entropy_loss
# 梯度更新
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.actor_critic.parameters(), self.max_grad_norm)
self.optimizer.step()
return policy_loss.item(), value_loss.item(), entropy_loss.item(), loss.item()
def update_lr(self, total_steps: int):
"""
根据当前训练进度线性衰减学习率。
学习率从 init_lr 线性下降,最终降至 init_lr * min_lr_rate。
"""
progress = self.global_step / total_steps # 训练进度 [0, 1]
new_lr = self.init_lr * (1.0 - progress) # 线性衰减
new_lr = max(new_lr, self.init_lr * self.min_lr_rate) # 不低于下限
for param_group in self.optimizer.param_groups:
param_group['lr'] = new_lr
def evaluate(self, eval_env: gym.Env, episodes: int = 5, deterministic: bool = True):
"""
在评估环境中运行若干回合,返回平均奖励与平均回合长度。
参数:
eval_env: 评估环境(单环境)
episodes: 评估回合数
deterministic: 是否使用确定性动作(argmax)
返回:
(mean_reward, mean_length): 平均总奖励与平均步数
"""
self.actor_critic.eval()
reward_list, length_list = [], []
with torch.no_grad():
for ep in range(episodes):
obs, _ = eval_env.reset()
done = False
episode_rewards = 0.0
episode_length = 0
while not done:
# 如果观测是一维,则添加 batch 维度
if obs.dim() == 1:
obs = obs.unsqueeze(0)
logits, _ = self.actor_critic(obs) # 得到动作 logits
if deterministic:
action = torch.argmax(logits, dim=-1)
else:
dist = Categorical(logits=logits)
action = dist.sample().unsqueeze(-1).view(-1)
next_obs, reward, termin, trunc, _ = eval_env.step(action)
done = termin.item() or trunc.item()
episode_rewards += reward.item()
episode_length += 1
obs = next_obs
reward_list.append(episode_rewards)
length_list.append(episode_length)
mean_reward = torch.tensor(reward_list, dtype=torch.float32).mean().item()
mean_length = torch.tensor(length_list, dtype=torch.float32).mean().item()
return mean_reward, mean_length
def train(self, total_steps: int, eval_interval: int = 30000):
"""
主训练循环。
参数:
total_steps: 总环境交互步数(所有环境累计)
eval_interval: 每隔多少步进行一次评估
返回:
metrics: 包含训练过程中记录的损失、评估奖励等信息的字典
"""
metrics = {
'policy_losses': [],
'value_losses': [],
'entropy_losses': [],
'total_losses': [],
'eval_rewards': [],
'eval_lengths': [],
'total_time_ms': 0.0,
}
# 检查评估间隔是否合理(至少需要一次完整的 rollout)
min_step = self.rollout_steps * self.num_envs
if eval_interval < min_step:
raise ValueError(f"eval_interval must be >= {min_step}")
# 计算下一次评估的步数边界
next_eval_step = ((self.global_step // eval_interval) + 1) * eval_interval
start_time = time.time()
# 用于保存最近几次评估奖励,以便计算滑动平均
recent_rewards = deque(maxlen=self.avg_eval_window)
with tqdm(total=total_steps, desc="Training A2C") as progress_bar:
while self.global_step < total_steps:
# 1. 收集 rollout 数据
rollout_data = self.collect_rollouts(self.rollout_steps)
self.global_step += self.rollout_steps * self.num_envs
# 2. 更新学习率
self.update_lr(total_steps)
# 3. 用收集的数据更新网络
policy_loss, value_loss, entropy_loss, total_loss = self.update(**rollout_data)
# 4. 评估(如果达到指定的步数间隔)
if self.global_step >= next_eval_step:
mean_reward, mean_length = self.evaluate(self.eval_env)
metrics['eval_rewards'].append(mean_reward)
metrics['eval_lengths'].append(mean_length)
recent_rewards.append(mean_reward)
# 计算滑动平均奖励
avg_reward = sum(recent_rewards) / len(recent_rewards) if recent_rewards else 0.0
progress_bar.set_postfix(
{
f"avg_reward_{self.avg_eval_window}": f"{avg_reward:.3f}",
"lengths": f"{mean_length:.3f}",
}
)
next_eval_step += eval_interval
# 更新进度条
progress_bar.update(self.rollout_steps * self.num_envs)
# 记录各项损失
metrics['policy_losses'].append(policy_loss)
metrics['value_losses'].append(value_loss)
metrics['entropy_losses'].append(entropy_loss)
metrics['total_losses'].append(total_loss)
# 计算总训练耗时(毫秒)
metrics['total_time_ms'] = (time.time() - start_time) * 1000
return metrics14.4 绘图函数
如下的绘图函数只是一个工具函数,没有必要去学习了解,只要会使用即可
python
def plot_eval_rewards(
metrics: dict,
total_steps: int,
smooth_window: int = 20,
y_percentile_range: tuple = (2, 98),
):
rewards = metrics.get("eval_rewards", [])
if len(rewards) == 0:
raise ValueError("No evaluation rewards found in metrics.")
num_evals = len(rewards)
steps = np.linspace(total_steps / num_evals, total_steps, num_evals)
if smooth_window is None:
smooth_window = max(3, num_evals // 20)
if smooth_window % 2 == 0:
smooth_window += 1
def moving_average(data, window):
if window >= len(data):
return np.full_like(data, np.mean(data))
pad = window // 2
padded = np.pad(data, pad, mode="edge")
smoothed = np.convolve(padded, np.ones(window) / window, mode="valid")
return smoothed
avg_rewards = moving_average(rewards, smooth_window)
if y_percentile_range is not None:
lower = np.percentile(rewards, y_percentile_range[0])
upper = np.percentile(rewards, y_percentile_range[1])
margin = (upper - lower) * 0.05
y_lim = (lower - margin, upper + margin)
else:
y_lim = None
plt.style.use("seaborn-v0_8-whitegrid")
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(
steps,
rewards,
color="#1f77b4",
alpha=0.55,
linewidth=1.0,
marker="o",
markersize=3,
label="Raw eval reward",
)
ax.plot(
steps,
avg_rewards,
color="#d65027",
linewidth=2.0,
label=f"Smoothed (window={smooth_window})",
)
ax.set_xlabel("Environment Steps", fontsize=12)
ax.set_ylabel("Mean Evaluation Reward", fontsize=12)
ax.set_title("Rewards", fontsize=14, pad=12)
ax.legend(fontsize=10, frameon=True, fancybox=True, framealpha=0.8)
if y_lim is not None:
ax.set_ylim(*y_lim)
ax.set_xlim(0, total_steps)
ax.xaxis.set_minor_locator(AutoMinorLocator())
ax.yaxis.set_minor_locator(AutoMinorLocator())
ax.tick_params(axis="both", which="major", direction="in", length=4, width=1)
ax.tick_params(axis="both", which="minor", direction="in", length=2, width=0.5)
fig.tight_layout()
return fig14.5 CartPole-v1 环境测试
注意:下面的代码最好放到if __name__ == "__main__":中哦,否则大概率会报错。
python
# 创建训练环境,num_envs为并行环境数
envs = gym.make_vec("CartPole-v1", num_envs=16, vectorization_mode="async")
# 将环境的输出全部转化成torch数据格式
envs = NumpyToTorch(envs)
# 创建测试环境
eval_env = gym.make_vec("CartPole-v1",num_envs=1)
eval_env = NumpyToTorch(eval_env)
agent = A2C(
envs,
eval_env,
4,
2,
lr=7e-4,
gamma=0.99,
rollout_steps=5,
entropy_coef=0.01,
rewards_scale_rate=4,
)
metrics = agent.train(60000, eval_interval=600)
envs.close() # 关闭环境
eval_env.close()
# 绘制reward图并保存到本地
plot = plot_eval_rewards(metrics,60000)
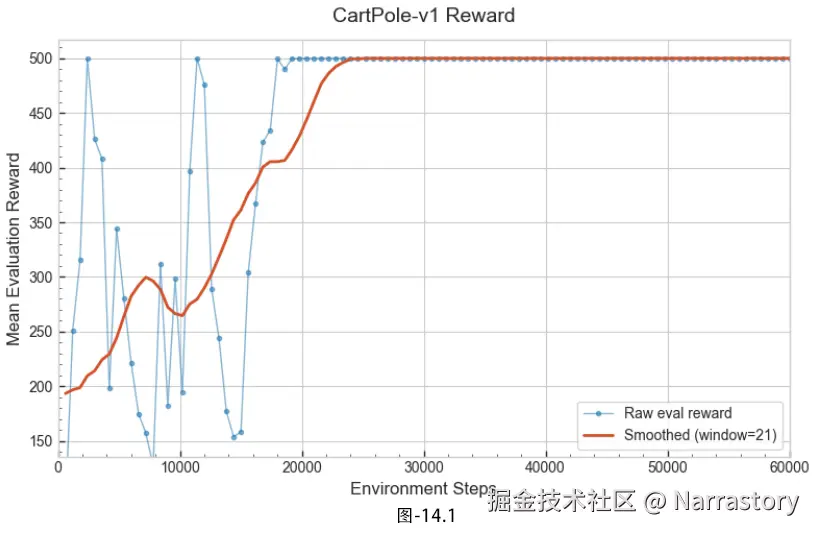
plot.savefig("a2c_cartpole.png")下图展示了 CartPole‑v1 训练过程中输出的奖励曲线。可以看到,虽然整个程序总共执行了 60k 环境步数,但由于使用了多环境并行架构,完成训练只花了不到半分钟------A2C 在时钟效率上的优势不言而喻。另外,相比早先实现的朴素 Actor‑Critic,这套优化的 A2C 模板在稳定性和收敛速度上有了质的飞跃:回报曲线虽然前期比较震荡,波动相比之下就显得非常小,并且能立马收敛,并在大约 200 个回合后就稳定在环境奖励的上限。
14.6 LunarLander-v3 环境测试
python
# 创建训练环境
envs = gym.make_vec(
"LunarLander-v3",
continuous=False,
gravity=-10.0,
enable_wind=True,
wind_power=10.0,
turbulence_power=1.0,
num_envs=8, # 并行环境数
vectorization_mode="async",
)
# 将环境的输出全部转化成torch数据格式
envs = NumpyToTorch(envs)
# 创建测试环境
eval_env = gym.make_vec(
"LunarLander-v3",
continuous=False,
gravity=-10.0,
enable_wind=True,
wind_power=10.0,
turbulence_power=1.0,
num_envs=1, # 测试环境只需要一个即可,不需要并行
)
eval_env = NumpyToTorch(eval_env)
agent = A2C(
envs,
eval_env,
8,
4,
lr = 7e-4,
gamma=0.99,
rollout_steps=128,
entropy_coef=0.01,
rewards_scale_rate=80,
)
metrics = agent.train(600000, eval_interval=5000)
envs.close() # 关闭环境
eval_env.close()
# 绘制reward图并保存到本地
plot = plot_eval_rewards(metrics,600000)
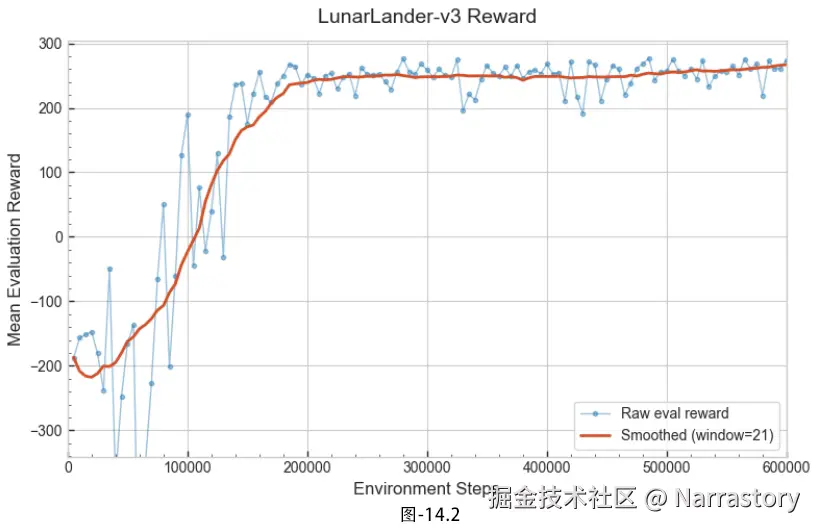
plot.savefig("a2c_lunarLander.png")在更具挑战性的 LunarLander‑v3 上,输出的奖励曲线如下图所示。即便总环境步数提升到了 600k,所有运算依然在 2 分钟内便结束了,速度令人满意。更重要的是,整个收敛过程始终非常稳健:平均回报稳步攀升,中途没有出现明显的性能退化或剧烈抖动,并最终稳定在 200 分以上------这通常被视为已成功解决该任务的标志。这组实验再一次印证,这套现代的 A2C 模板能够优雅地扩展到更复杂的控制问题,在保持出色样本效率的同时,也提供了极为可靠的训练稳定性。对于需要快速迭代算法的研究者而言,A2C无疑是一个理想的基础框架。
END~
