一、图的基本概念
1.1 图的定义
图G由顶点集V和边集E组成,记为G=(V,E)
| 要素 | 说明 |
|---|---|
| V(G) | 顶点的有限非空集 |
| E(G) | 顶点之间关系的集合 |
重要 :线性表可以是空表,树可以是空树,但图不可以是空图。顶点集V必须非空,但边集E可以为空。
1.2 基本术语
1. 有向图 vs 无向图
| 类型 | 边的形式 | 说明 |
|---|---|---|
| 有向图 | <v, w> |
v称为弧尾 ,w称为弧头,表示v→w |
| 无向图 | (v, w) 或 (w, v) |
v和w互为邻接点 |
2. 简单图 vs 多重图
| 类型 | 条件 |
|---|---|
| 简单图 | ① 不存在重复边;② 不存在顶点到自身的边 |
| 多重图 | 两顶点之间边数可超过1条,允许顶点通过边与自身关联 |
这里仅讨论简单图。
3. 顶点的度、入度、出度
| 图类型 | 定义 | 重要结论 |
|---|---|---|
| 无向图 | 度TD(v) = 依附于v的边数 | 所有顶点的度之和 = 2|E| |
| 有向图 | 入度ID(v) = 以v为终点的边数;出度OD(v) = 以v为起点的边数 | 所有顶点的入度之和 = 出度之和 =|E| |
注:符号含义对照表
| 符号 | 含义 | 类型 | 举例 |
|---|---|---|---|
E |
边集(Edge Set) | 集合 | E = {(A,B), (B,C)} |
| ` | E | ` | 边的条数 |
很多人会偷懒直接用
E表示边数,但它本质上是|E|。
顶点v的度:TD(v) = ID(v) + OD(v)
4. 路径与回路
| 术语 | 定义 |
|---|---|
| 路径 | 顶点序列 v₀, v₁, ..., vₙ |
| 路径长度 | 路径上边的数量 |
| 回路(环) | 第一个顶点和最后一个顶点相同的路径 |
| 简单路径 | 路径中顶点不重复出现 |
| 简单回路 | 除首尾外,其余顶点不重复的回路 |
| 距离 | 从u到v的最短路径的长度(不存在则为∞) |
若一个图有n个顶点,且有大于n-1条边 ,则此图一定有环。
5. 子图
若
V' ⊆ V且E' ⊆ E,则称G'是G的子图。
| 类型 | 定义 |
|---|---|
| 生成子图 | 满足 V(G') = V(G) 的子图 |
并非V和E的任何子集都能构成子图------E'中的边关联的顶点必须在V'中。
6. 连通性(无向图)
| 术语 | 定义 |
|---|---|
| 连通 | 从v到w存在路径 |
| 连通图 | 图中任意两个顶点都是连通的 |
| 连通分量 | 无向图中的极大连通子图 |
若一个图有n个顶点,边数少于n-1 ,则此图必然是非连通的。
7. 强连通性(有向图)
| 术语 | 定义 |
|---|---|
| 强连通 | 从v到w和从w到v都有路径 |
| 强连通图 | 图中任意一对顶点都是强连通的 |
| 强连通分量 | 有向图中的极大强连通子图 |
有向图强连通的最少边数:n条(形成一个环)
8. 生成树与生成森林
| 术语 | 定义 |
|---|---|
| 生成树 | 连通图的极小连通子图,包含所有顶点和n-1条边 |
| 生成森林 | 非连通图中,每个连通分量的生成树共同构成 |
区分:极大连通子图(连通分量)要求包含尽可能多的顶点和边;极小连通子图(生成树)要求保持连通且边数最少。
9. 其他术语
| 术语 | 定义 |
|---|---|
| 完全图 | 无向:` |
| 稀疏图/稠密图 | ` |
| 网 | 边上带有权值的图 |
| 有向树 | 一个顶点的入度为0,其余顶点的入度均为1的有向图 |
二、图的存储及基本操作
2.1 邻接矩阵法
#define MaxVertexNum 100
typedef struct {
VertexType vex[MaxVertexNum]; // 顶点表
EdgeType edge[MaxVertexNum][MaxVertexNum]; // 邻接矩阵(边表)
int vexnum, arcnum; // 当前顶点数和边数
} MGraph;特点:
| 图类型 | 邻接矩阵特点 |
|---|---|
| 无向图 | 一定是对称矩阵,第i行(列)非零元素个数 = 顶点i的度 |
| 有向图 | 第i行非零元素个数 = 出度;第i列 = 入度 |
重要结论:
-
空间复杂度:O(n²)
-
判断两点是否有边:O(1)
-
确定图中边数:需遍历整个矩阵
-
稠密图适合邻接矩阵
-
Aⁿij = 从i到j长度为n的路径数量
2.2 邻接表法
#define MaxVertexNum 100
typedef struct ArcNode { // 边表结点
int adjvex; // 邻接点位置
struct ArcNode *nextarc; // 下一条边的指针
// InfoType info; // 网边权值
} ArcNode;
typedef struct VNode { // 顶点表结点
VertexType data; // 顶点信息
ArcNode *firstarc; // 第一条边
} VNode, AdjList[MaxVertexNum];
typedef struct {
AdjList vertices; // 邻接表
int vexnum, arcnum; // 顶点数和边数
} ALGraph;特点:
| 图类型 | 空间复杂度 | 特点 |
|---|---|---|
| 无向图 | O(n + 2|E|) | 每条边出现两次 |
| 有向图 | O(n + |E|) | --- |
-
稀疏图适合邻接表
-
找所有邻接点:邻接表高效;邻接矩阵需扫描整行
-
判断两点是否有边:邻接表需遍历边表,效率较低
-
有向图入度:需遍历所有顶点的边表
-
邻接表的表示不唯一(取决于输入顺序)
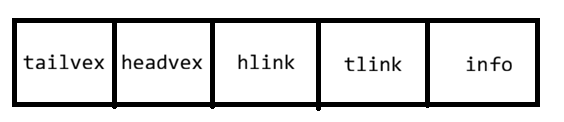
2.3 十字链表(有向图)
每条弧用一个弧结点 表示,每个顶点用一个顶点结点表示。
弧结点结构:
顶点结点结构:
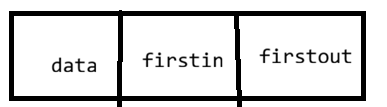
优点:容易找到以v为尾的弧(出度)和以v为头的弧(入度)
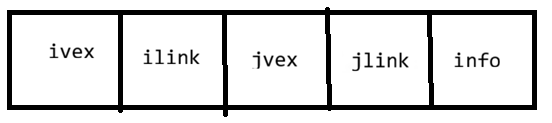
2.4 邻接多重表(无向图)
每条边只用一个结点表示,解决了邻接表中一条边用两个结点表示的问题。
边结点结构:
顶点结点结构:
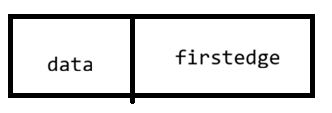
优点:判断边是否存在只需遍历一次
2.5 四种存储方式对比
| 存储方式 | 空间复杂度 | 找相邻边 | 删除边/顶点 | 适用场景 | 表示唯一性 |
|---|---|---|---|---|---|
| 邻接矩阵 | O(n²) | 遍历行/列O(n) | 删边方便,删顶点需移动数据 | 稠密图 | 唯一 |
| 邻接表 | 无向O(n+2|E|),有向O(n+|E|) | 方便 | 不方便 | 稀疏图 | 不唯一 |
| 十字链表 | O(n+|E|) | 方便 | 方便 | 有向图 | 不唯一 |
| 邻接多重表 | O(n+|E|) | 方便 | 方便 | 无向图 | 不唯一 |
三、图的遍历
3.1 广度优先搜索(BFS)
类似于树的层序遍历 ,借助队列实现,按路径长度递增的顺序访问顶点。
bool visited[MAX_VERTEX_NUM];
void BFSTraverse(Graph G) {
for (int i = 0; i < G.vexnum; i++) visited[i] = FALSE;
InitQueue(Q);
for (int i = 0; i < G.vexnum; i++)
if (!visited[i]) BFS(G, i);
}
void BFS(ALGraph G, int i) {
visit(i); visited[i] = TRUE;
EnQueue(Q, i);
while (!QueueEmpty(Q)) {
DeQueue(Q, v);
for (ArcNode *p = G.vertices[v].firstarc; p; p = p->nextarc) {
w = p->adjvex;
if (!visited[w]) {
visit(w); visited[w] = TRUE;
EnQueue(Q, w);
}
}
}
}性能分析:
-
空间复杂度:O(n)(辅助队列)
-
时间复杂度:
-
邻接表:O(n + |E|)
-
邻接矩阵:O(n²)
-
BFS求单源最短路径(非带权图):
void BFS_MIN_Distance(Graph G, int u) {
for (int i = 0; i < G.vexnum; i++) d[i] = ∞;
visited[u] = TRUE; d[u] = 0;
EnQueue(Q, u);
while (!QueueEmpty(Q)) {
DeQueue(Q, u);
for (w = FirstNeighbor(G, u); w >= 0; w = NextNeighbor(G, u, w))
if (!visited[w]) {
visited[w] = TRUE;
d[w] = d[u] + 1;
EnQueue(Q, w);
}
}
}广度优先生成树:
-
邻接矩阵存储:生成树唯一
-
邻接表存储:生成树可能不唯一
3.2 深度优先搜索(DFS)
类似于树的先序遍历 ,借助**递归(栈)**实现,遵循"尽可能深"地探索的策略。
bool visited[MAX_VERTEX_NUM];
void DFSTraverse(Graph G) {
for (int i = 0; i < G.vexnum; i++) visited[i] = FALSE;
for (int i = 0; i < G.vexnum; i++)
if (!visited[i]) DFS(G, i);
}
void DFS(ALGraph G, int i) {
visit(i); visited[i] = TRUE;
for (ArcNode *p = G.vertices[i].firstarc; p; p = p->nextarc) {
j = p->adjvex;
if (!visited[j]) DFS(G, j);
}
}性能分析:
-
空间复杂度:O(n)(递归工作栈)
-
时间复杂度:
-
邻接表:O(n + |E|)
-
邻接矩阵:O(n²)
-
深度优先生成树/森林:
-
连通图:一棵生成树
-
非连通图:生成森林
3.3 图的遍历与连通性
| 图类型 | 遍历特点 |
|---|---|
| 无向图 | 调用BFS/DFS的次数 = 连通分量数 |
| 有向图 | 一次遍历不一定能访问所有顶点,需外层循环确保全覆盖 |
四、思考
1. 邻接矩阵 ≈ 城市之间的直达航班表
行是出发城市,列是到达城市,单元格填1表示有直达航班。对角线是自己的城市(0),矩阵对称表示往返都有航班。
2. 邻接表 ≈ 微信好友列表每个用户有一个好友列表(边表),只存储自己的好友,不存储非好友关系。空间利用率高。
3. BFS ≈ 六度分隔理论你认识的朋友是第一层,朋友的朋友是第二层......BFS正是按这个层层递进的顺序探索"社交网络"中的人际关系。
4. DFS ≈ 走迷宫沿着一条路一直走,走到死胡同就退回上一个岔路口,换一条路继续走,直到走遍所有路。
注:以上内容参考 2027年数据结构考研复习指导 王道论坛 组编,其中有一些个人想法,如有任何错误或不妥,欢迎各位大佬指出,如果各位有一些有意思的想法,也可以和我交流一下~感谢!
五、明日计划
图(下)--- 最小生成树、最短路径、拓扑排序、关键路径