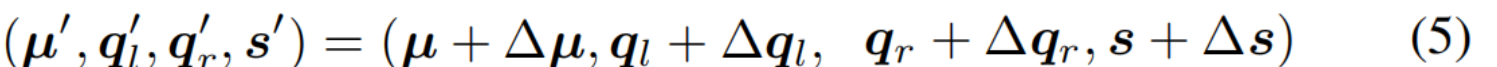文章目录
- 摘要
- 现有问题
- 一、预备知识:4DGS
-
- [1.1 4D Gaussian Splatting](#1.1 4D Gaussian Splatting)
- [1.2 基于形变的建模:K-planes Factorization](#1.2 基于形变的建模:K-planes Factorization)
- 二、网络框架
- [三、时空畸变场(Spatio-Temporal Distortion Field)](#三、时空畸变场(Spatio-Temporal Distortion Field))
- 四、Optimization (优化)
-
- [4.1 位姿联合优化 (Pose Optimization)](#4.1 位姿联合优化 (Pose Optimization))
- [4.2 损失函数 (Loss Function):5项](#4.2 损失函数 (Loss Function):5项)
- 实验
-
- [拓展:参数化 4D 旋转矩阵的两个代数几何工具](#拓展:参数化 4D 旋转矩阵的两个代数几何工具)
SparseCam4D: Spatio-Temporally Consistent 4D Reconstruction from Sparse Cameras
项目主页: 浙大CAD;InSpatio Research
摘要
高质量的4D重建技术能够实现对动态现实世界的逼真且沉浸式的渲染效果。然而,与仅需单台相机即可完整捕捉静态场景不同,高质量动态场景通常需要部署数十甚至数百台同步工作的密集摄像机阵列。这种对昂贵实验室设备的依赖严重限制了实际应用的可扩展性。
我们提出SparseCam4D,一种基于稀疏摄像机的动态重建框架,充分利用了丰富但存在不一致性的生成观测数据 。核心创新在于 时空畸变场"(Spatio-Temporal Distortion Field),它为在空间和时间维度上建模生成观测数据中的不一致性提供了统一机制。并开发出一套完整的处理流程。在多摄像机动态场景基准测试中对方法进行了评估,获得了时空一致性极强的高保真渲染效果,并显著优于现有方法。
现有问题
随着相机控制视频扩散模型 2,3,48取得显著进展,可以利用其生成高质量的时空数据 ,从而为4D重建提供额外的观测依据。然而,这些逼真的生成结果往往存在时空不一致性,例如表面闪烁以及物体在不同视角和时间维度上的运动不稳定(如图2),这些问题会破坏动态场景的连贯性,并导致严重的模糊和伪影现象。
一、预备知识:4DGS
1.1 4D Gaussian Splatting
4D Gaussian Splatting 核心思想是将时间 t t t 视为一个独立的正交坐标维度,从而将 3D 高斯直接"提升 (lift)"为 4D 高斯。参数化表示为:
-
中心位置 (Center): μ = ( μ x , μ y , μ z , μ t ) \mu = (\mu_x, \mu_y, \mu_z, \mu_t) μ=(μx,μy,μz,μt)
-
协方差矩阵 (Covariance): Σ ∈ R 4 × 4 \Sigma \in \mathbb{R}^{4 \times 4} Σ∈R4×4。与 3DGS 类似,它被分解为缩放矩阵 S = diag ( s x , s y , s z , s t ) S = \text{diag}(s_x, s_y, s_z, s_t) S=diag(sx,sy,sz,st) 和 4D 旋转矩阵 R ∈ R 4 × 4 R \in \mathbb{R}^{4 \times 4} R∈R4×4。
4D 旋转的数学处理:为了在欧氏空间中参数化 4D 旋转矩阵,作者提到了两种数学上等价的代数几何工具:
-
一对各向同性旋转 (pair of isotropic rotations): R = L ( q l ) R ( q r ) R = L(q_l)R(q_r) R=L(ql)R(qr)
-
包含 8 个系数的归一化 4D 转子 (4D rotor): R = F m a p ( F n o r m ( r ) ) R = \mathcal{F}{map}(\mathcal{F}{norm}(\mathbf{r})) R=Fmap(Fnorm(r))
时间切片与渲染 (Temporal Slicing):给定时间戳 t t t,通过"时间切片"操作将 4D 高斯的属性投影到对应的 3D 子空间中。投影公式为:
G 3 D ( x , t ) = e − 1 2 λ ( t − μ t ) 2 e − 1 2 x − μ ( t ) T Σ 3 D − 1 x − μ ( t ) \mathcal{G}{3D}(x, t) = \text{e}^{-\frac{1}{2}\lambda(t-\mu_t)^2} \text{e}^{-\frac{1}{2}x-\\mu(t)^T \Sigma{3D}^{-1} x-\\mu(t)} G3D(x,t)=e−21λ(t−μt)2e−21x−μ(t)TΣ3D−1x−μ(t)
注:公式前半部分控制高斯在时间轴上的衰减,后半部分是标准的空间高斯分布。渲染遵循标准的 3DGS 可微光栅化,稠密化 (densification) 操作会在空间和时间双维度上同时进行。
1.2 基于形变的建模:K-planes Factorization
不直接在 4D 空间构建基元,而是通过隐式特征平面来解耦时空维度,进而计算形变场。
- K-planes 概念 :将任意 d d d 维场景分解为 k = ( d 2 ) k = \binom{d}{2} k=(2d) 个 2D 平面。给定一个坐标输入,K-planes 会将其映射为特征向量,再通过一个微型 MLP 解码出目标属性值。
- 4D Hex-planes 则是将动态 4D 场景分解为 6 个平面: 【3 个纯空间平面: x y , x z , y z xy, xz, yz xy,xz,yz】 与【 3 个时空平面: x t , y t , z t xt, yt, zt xt,yt,zt】
这套表示方法在 Deformation-based NeRF 和 4DGS 中都被广泛采用。在 NeRF 中 (World-to-Canonical):估计从世界空间到标准空间的映射 M : ( p , t ) → Δ p \mathcal{M}: (p, t) \rightarrow \Delta p M:(p,t)→Δp。网络获取目标时间 t t t 处空间点 p p p 的偏移量 Δ p \Delta p Δp,然后将 p + Δ p p + \Delta p p+Δp 输入基础的静态 NeRF 模型进行渲染。 在 4DGS 中 (Canonical-to-World):估计从标准空间到世界空间的映射 F : ( G , t ) → Δ G \mathcal{F}: (\mathcal{G}, t) \rightarrow \Delta \mathcal{G} F:(G,t)→ΔG。在时间 t t t,计算标准 3D 高斯基元 G \mathcal{G} G 各种属性(如位置、缩放、旋转)的偏移量/形变。最终变形后的高斯表示为 G ′ = G + Δ G \mathcal{G}' = \mathcal{G} + \Delta \mathcal{G} G′=G+ΔG,然后通过视图矩阵 M = R ∣ T M = R\|T M=R∣T 进行常规的微分溅射渲染: I = S ( M , G ′ ) I = S(M, \mathcal{G}') I=S(M,G′)。
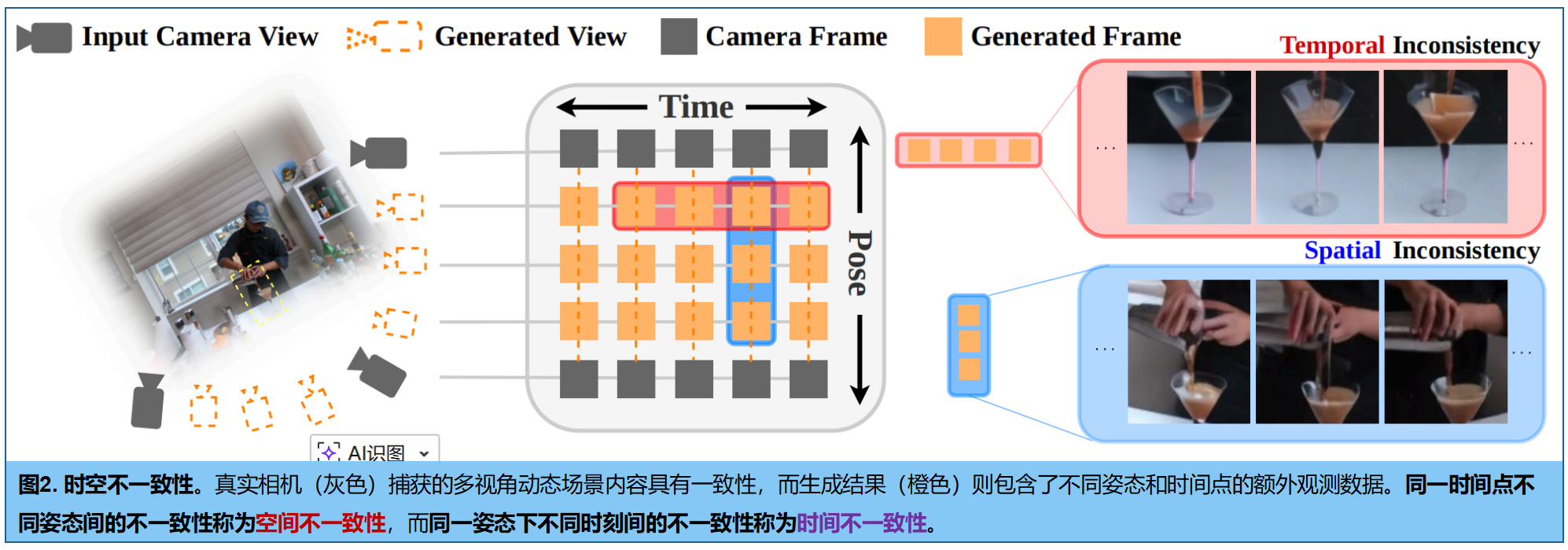
二、网络框架
使用稀疏的真实相机视频训练 4DGS 时,为了补充视角,使用视频扩散模型生成额外的视角序列:
-
输入定义: 真实输入视图记为 V I V_I VI,扩散模型生成的辅助视图记为 V G V_G VG。
-
核心痛点: 去除4DGS 重建中由于扩散模型的时空几何不一致性(geometric inconsistencies)导致的伪影(artifacts)。
-
解决思路 : 引入 时空畸变场(Spatio-temporal distortion field F \mathcal{F} F),建模生成视图中的误差/不一致性。
映射关系定义为: F : ( G 4 D , t , s ) → Δ G 4 D \mathcal{F}: (\mathcal{G}{4D}, t, s) \rightarrow \Delta\mathcal{G}{4D} F:(G4D,t,s)→ΔG4D。其中 t t t 是时间索引, s s s 是相机姿态(Pose)索引。最终渲染生成视图时,使用的是叠加了畸变项的 4D 高斯: G 4 D ′ = G 4 D + Δ G 4 D \mathcal{G}'{4D} = \mathcal{G}{4D} + \Delta\mathcal{G}_{4D} G4D′=G4D+ΔG4D。
三、时空畸变场(Spatio-Temporal Distortion Field)
坐标空间从 4D 变成了 5D: c = { x , y , z , t , s } c = \{x, y, z, t, s\} c={x,y,z,t,s}。包括空间 ( x , y , z ) (x,y,z) (x,y,z) ,时间 ( t ) (t) (t),生成视图的位姿ei'ziei'zeie索引 ( s ) (s) (s)

四、Optimization (优化)
4.1 位姿联合优化 (Pose Optimization)
由于生成视频帧存在几何不一致性,传统的 COLMAP 在估计这些帧的相机外参时,对齐精度会大打折扣。为了缓解这个问题,作者放弃了完全信任 COLMAP 的位姿,而是将相机外参(Camera Extrinsics)作为可学习变量,与 4D 高斯属性一起进行联合优化。
4.2 损失函数 (Loss Function):5项
- 真实视图的光度重构损失 ( L input \mathcal{L}{\text{input}} Linput): L1 损失和 D-SSIM(结构相似性)损失的加权和。 L input = ( 1 − λ ) L 1 + λ L D-SSIM \mathcal{L}{\text{input}} = (1 - \lambda)\mathcal{L}1 + \lambda\mathcal{L}{\text{D-SSIM}} Linput=(1−λ)L1+λLD-SSIM
- 生成辅助视图的感知损失 ( L gen \mathcal{L}{\text{gen}} Lgen):对于生成视图,不直接应用 L1 损失。引入感知损失(LPIPS)学习"纹理和结构上的高维相似性"。 L gen = λ 1 L 1 + λ 2 L lpips \mathcal{L}{\text{gen}} = \lambda_1\mathcal{L}1 + \lambda_2\mathcal{L}{\text{lpips}} Lgen=λ1L1+λ2Llpips
- 相机位姿正则化 ( L pose \mathcal{L}{\text{pose}} Lpose):入一个锚点正则化项,强制优化后的位姿不能偏离 COLMAP 提供的初始位姿太多。其中 T T T 和 q q q 分别是优化后的平移向量和旋转四元数, T ^ \hat{T} T^ 和 q ^ \hat{q} q^ 是 COLMAP 给出的初始值。 L pose = λ p ( ∣ ∣ T − T ^ ∣ ∣ + ∣ ∣ q − q ^ ∣ ∣ ) \mathcal{L}{\text{pose}} = \lambda_p(||T - \hat{T}|| + ||q - \hat{q}||) Lpose=λp(∣∣T−T^∣∣+∣∣q−q^∣∣)
- 空间平滑正则化 ( L TV \mathcal{L}_{\text{TV}} LTV)。沿用了 K-Planes 的标准做法,在特征网格平面上应用总变分(Total Variation, TV)损失
- 位姿轴的二阶平滑正则化 ( L smooth \mathcal{L}_{\text{smooth}} Lsmooth)。由于扩散模型生成的视角,希望在位姿轴(不同视角间)是连续变化的,但在时间轴(前后帧之间)可以突变。因此在包含"姿态维度 s s s"的三个空间平面 C = { x s , y s , z s } C = \{xs, ys, zs\} C={xs,ys,zs} 上施加平滑约束。具体做法是应用一个二阶导数滤波器(Second derivative filter,具体采用离散二阶差分的 L2 范数),惩罚相邻姿态之间的特征变化率的突变,从而迫使畸变场在视角移动时保持平滑:
L smooth = λ s 1 ∣ C ∣ ∑ c ∈ C 1 N i N s ∑ i , s ∣ ∣ ( P c i , s − 1 − P c i , s ) − ( P c i , s − P c i , s + 1 ) ∣ ∣ 2 2 \mathcal{L}{\text{smooth}} = \lambda_s \frac{1}{|C|} \sum{c \in C} \frac{1}{N_i N_s} \sum_{i,s} ||(\boldsymbol{P}_c^{i, s-1} - \boldsymbol{P}_c^{i, s}) - (\boldsymbol{P}_c^{i, s} - \boldsymbol{P}_c^{i, s+1})||_2^2 Lsmooth=λs∣C∣1c∈C∑NiNs1i,s∑∣∣(Pci,s−1−Pci,s)−(Pci,s−Pci,s+1)∣∣22
(注: P c i , s \boldsymbol{P}_c^{i,s} Pci,s 表示在平面 c c c 上,空间索引为 i i i、姿态索引为 s s s 处的特征值。集合 C = { x s , y s , z s } C = \{x_s, y_s, z_s\} C={xs,ys,zs} 对应 Ennea-plane 中的三个空间-位姿平面)
实验
数据集 。选择三个真实世界数据集,训练 在能够充分覆盖场景内容的两到三个选定视角上进行,评估则在所有其他视角上完成。
- Neural 3D Video 数据集13:该数据集包含六段室内多视角视频序列,由18至21台同步摄像机以2704×2028分辨率和30帧/秒的速度同步录制。根据43的方法,我们对视频进行二分降采样(每场景使用300帧)进行训练和评估。
- Technicolor 数据集26:该数据集包含五段室内多视频序列,由4×4同步摄像机阵列以2048×1088分辨率采集,帧率为60Hz。根据1的方法,我们在全分辨率下进行训练和评估(每场景使用50帧)。
- Nvidia Dynamic Scenes 数据集46:该数据集包含六段室外多视角视频序列,每段由12台同步摄像机以1920×1080分辨率和60Hz帧率拍摄。我们使用半分辨率帧(每场景100帧)进行训练和评估。
训练细节 。基于Pytorch ,每个场景迭代30,000次;每次迭代随机选取一张输入视角图像和一张生成视角图像。 前3000次迭代采用base训练设置作为预热阶段 ,随后 同时进行相机优化和畸变场训练(相机优化在7000次迭代后停止) 。生成视角采用相机控制的图像到视频扩散模型 48:Viewcrafter,每序列生成L=25帧。对于未经校准的生成视角和相机,我们在t=0时刻使用 COLMAP 27,28获取粗略的姿态和点云初始化。权重因子 λ 、 λ1 、 λ2 、 λp 和 λs 分别设置为0.2、0.02、0.2、0.1和 10 − 4 10^{-4} 10−4。所有实验均在单块Nvidia A800 GPU上进行,以确保结果可直接比较。
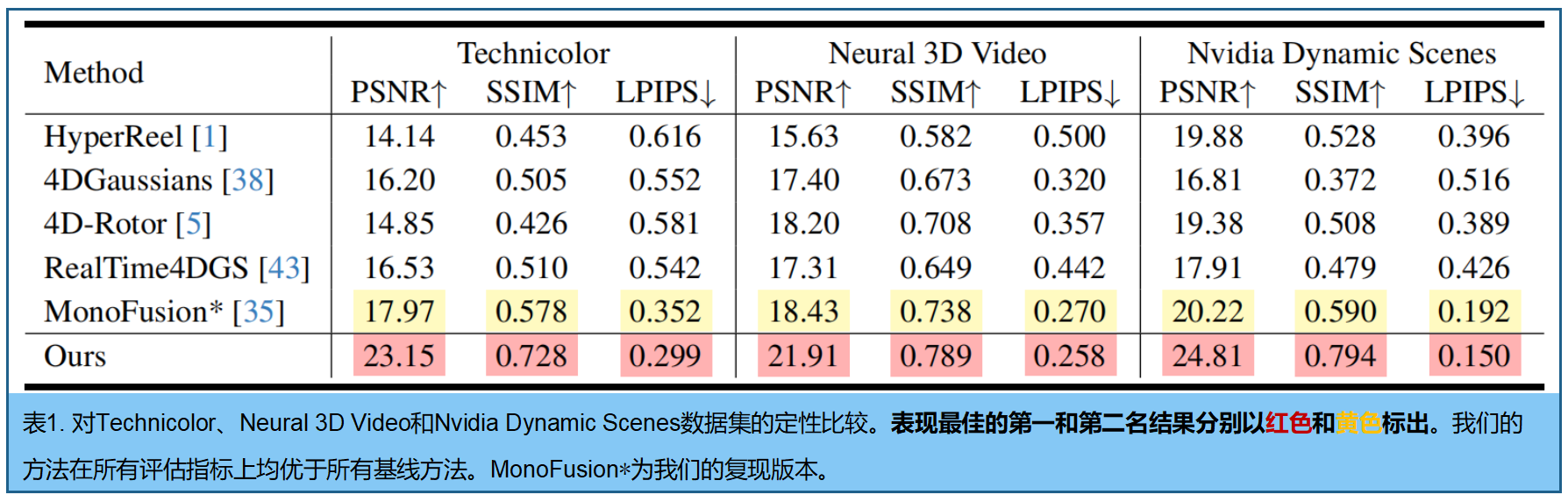

图4. 不同方法在Technicolor、Neural 3D Video和Nvidia Dynamic Scenes]数据集上的定性比较。对比的动态场景重建方法有 MonoFusion、4DGS、4DRotor5和Realtime4DGS。SparseCam4D生成视觉效果可靠且细节更清晰
#pic_center =70%x80%
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ ∏ \prod ∏ a b c \sqrt{abc} abc ∑ a b c \sum{abc} ∑abc
/ $$ E \mathcal{E} E
拓展:参数化 4D 旋转矩阵的两个代数几何工具
3D 空间中,旋转(属于李群 S O ( 3 ) SO(3) SO(3))具有 3 个自由度,我们通常用四元数(4 个参数)或旋转矩阵( 3 × 3 3 \times 3 3×3)结合正交约束来表示。而在 4D 空间中,旋转(属于李群 S O ( 4 ) SO(4) SO(4))具有 6 个自由度。如何可微且无奇点地在神经网络中参数化这 6 个自由度,是 4DGS 遇到的数学难点。论文中提到了两种等价的工具:

3.1 九平面特征 (Ennea-plane)
按照 K-planes 的逻辑,5D 空间两两组合应该有 ( 5 2 ) = 10 \binom{5}{2} = 10 (25)=10 个平面。
但是,纯粹的 ( t , s ) (t, s) (t,s) 组合(时间-姿态平面)并不包含任何空间信息,无法编码空间几何的畸变,因此被合理舍弃。剩下的刚好是 9 个平面:
-
3 个纯空间平面 : x y , x z , y z xy, xz, yz xy,xz,yz
-
3 个时空平面 : x t , y t , z t xt, yt, zt xt,yt,zt
-
3 个空间-姿态平面 : x s , y s , z s xs, ys, zs xs,ys,zs
3.2 特征提取与融合
将 5D 坐标投影到这 9 个 2D 网格平面上,使用双线性插值(bilinear interpolation)提取每个平面的特征:
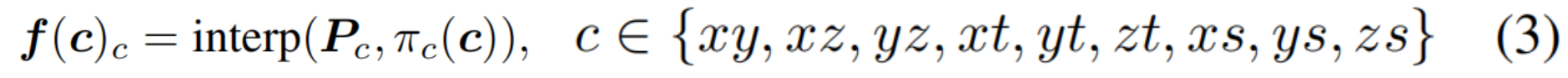
将提取的特征先进行逐元素相乘 (element-wise multiplication) 融合,然后再跨多分辨率层级进行拼接 (concatenation)。
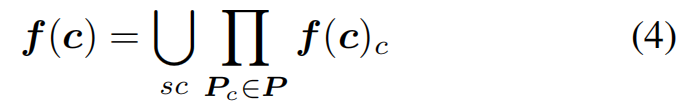
3.3 属性编码
提取出的融合特征向量 f f f 会被送入一个轻量级的多头 MLP(Multi-head MLP),输出 4DGS各属性的畸变偏移量:位置偏移: Δ μ \Delta\mu Δμ、旋转偏移: Δ q l , Δ q r \Delta q_l, \Delta q_r Δql,Δqr (两个四元数表示 4D 旋转)、缩放偏移: Δ s \Delta s Δs