文章目录
Llamafactory安装和使用
Llamafactory已经出来很久了,自己也用了比较长的时间,一直想着写一遍博客用于记录,然后一直拖着(小声BB:主要还是懒了)以下内容用于个人使用的总结文档,感觉应该属于比较保姆级别的总结了,希望可以帮到需要的朋友。当然,也可以看下Llamafactory的GitHub链接,对应的GitHub中文文档,对应的官方推荐中文视频
如果文档有说得不对的地方,劳烦大佬指正,非常的感谢!
一、Llamafactory安装
1.云显卡
由于个人的笔记本太垃圾了,所以我一般都是直接通过AutoDL的云显卡去安装,并通过vscode的SSH去连接后再使用。如何去通过SSH去连接AutoDL,可以参考AutoDL文档 。
(1)安装llamafactory需要python>=3.11,并且为了方便演示以及环境的隔离,所以直接创建一个新的环境
shell
conda create -n llamafactory python=3.12.2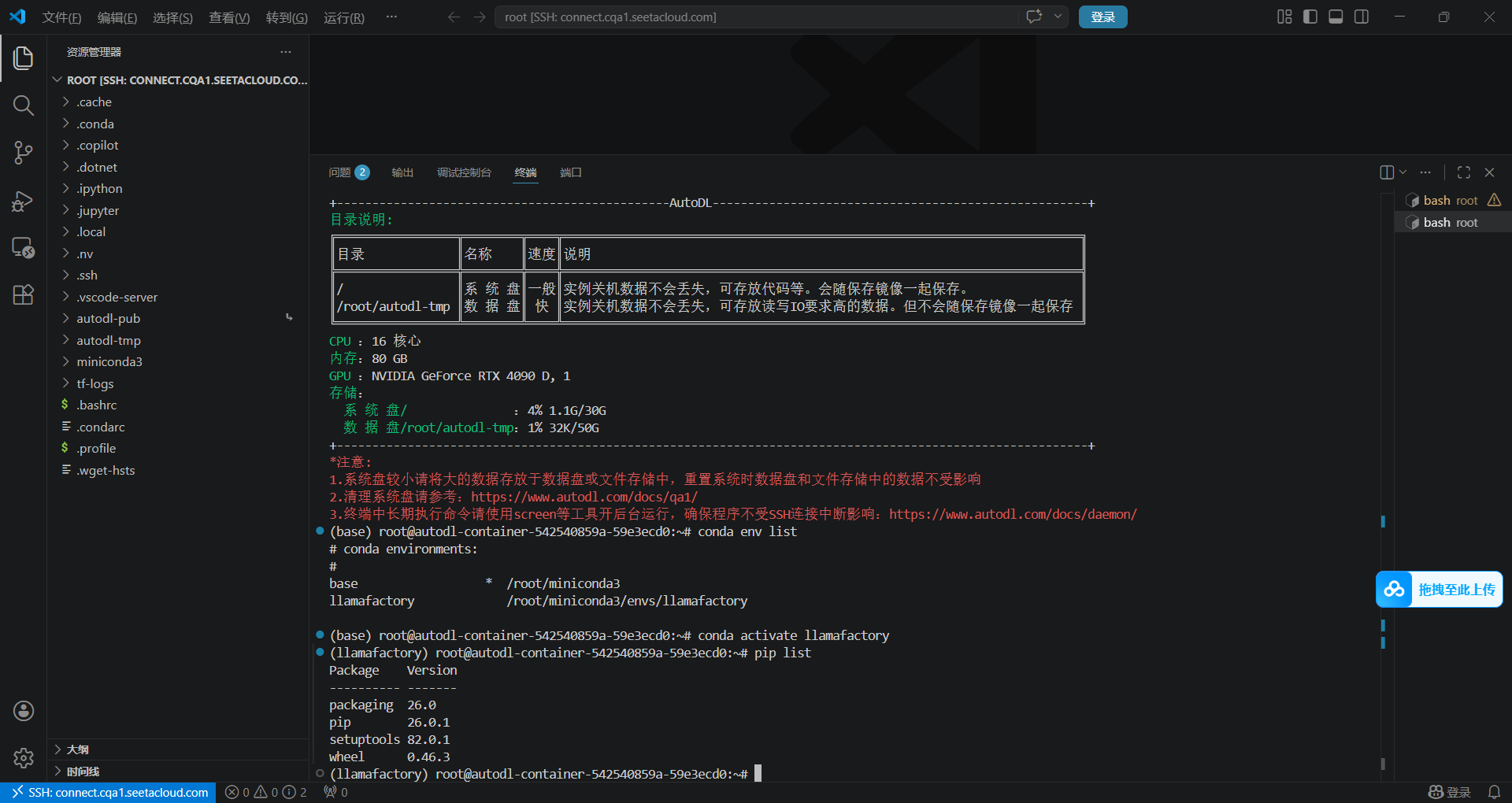
(2)按照官方的文档,本次我们使用源码进行安装。当然,如果git 拉取源码失败,可以通过下载压缩包后,复制过去进行解压也是一样的。截止2026年4月13日,我通过git clone命令,它会装Llamafactory的0.9.5.dev0,目前github仓库最高是v0.9.4
shell
git clone --depth 1 https://github.com/hiyouga/LlamaFactory.git
cd LlamaFactory
pip install -e .
pip install -r requirements/metrics.txt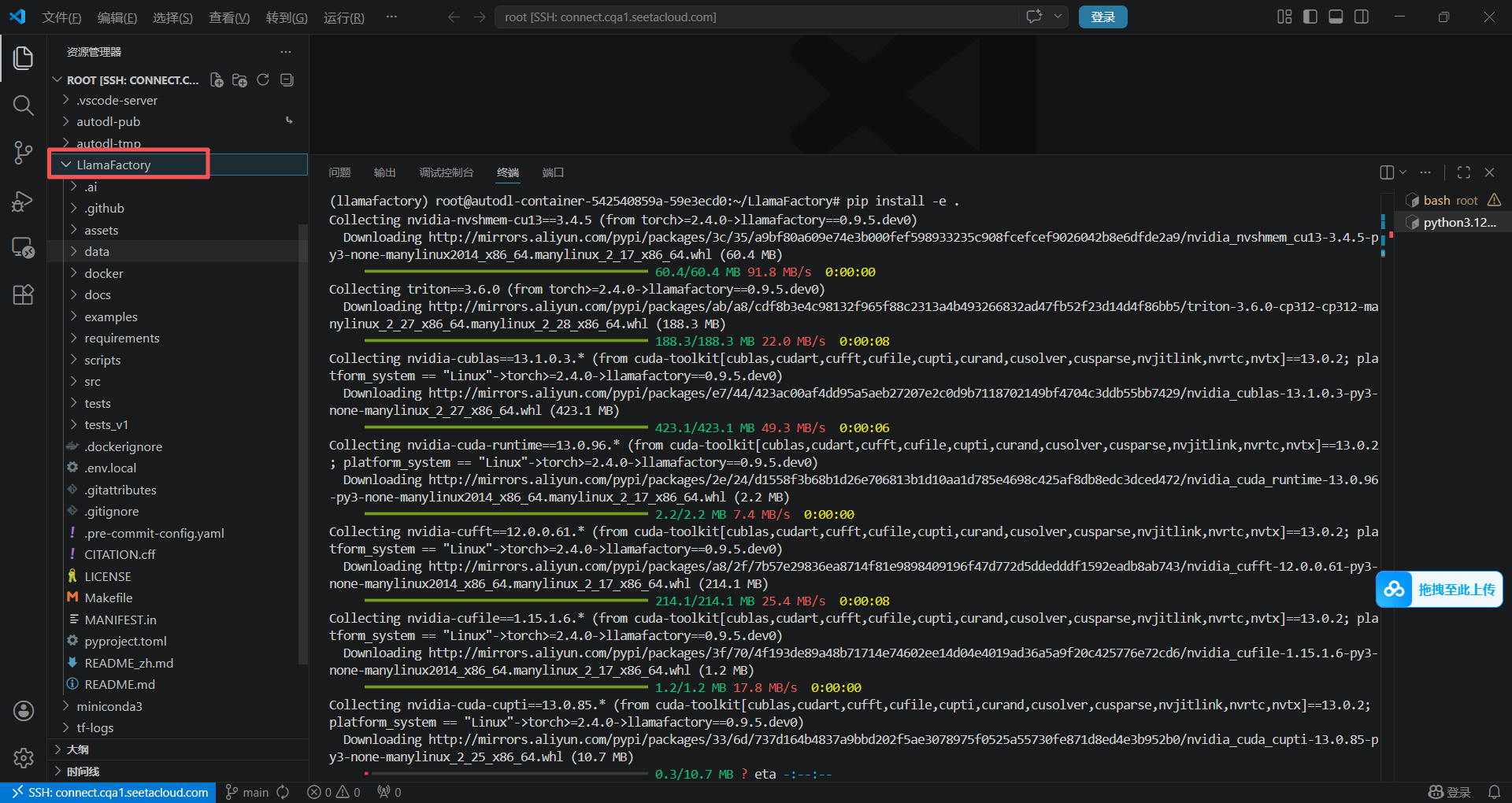
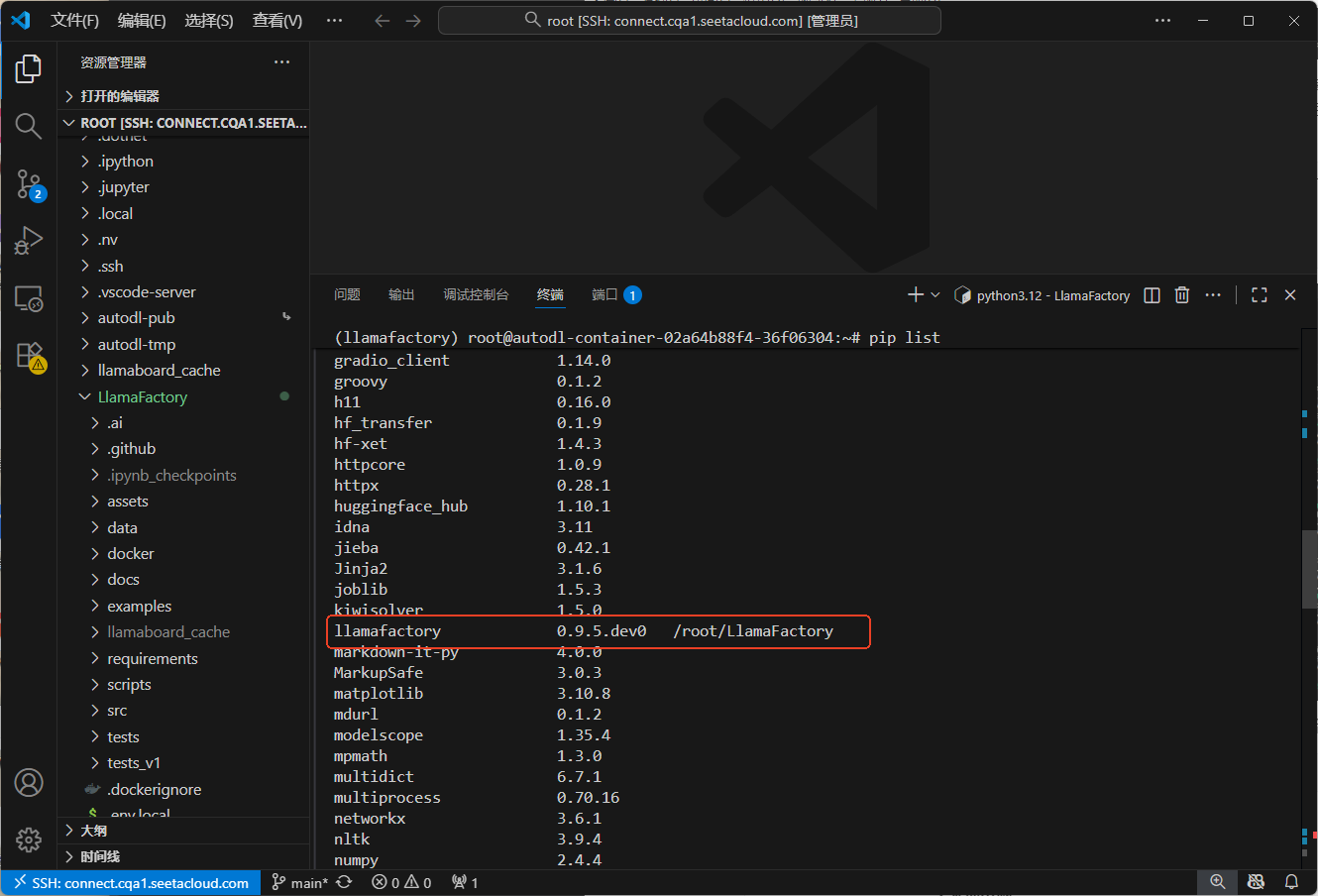
(3)当执行完上面的命令后,再执行下面的启动命令即可启动llamafactory,在页面中可以选择language一栏中选择zh即可变成中文字体了,当显示如下图时,证明成功安装。注意:如果按照上面操作后,执行命令无效时,多半是没切环境。
shell
llamafactory-cli webui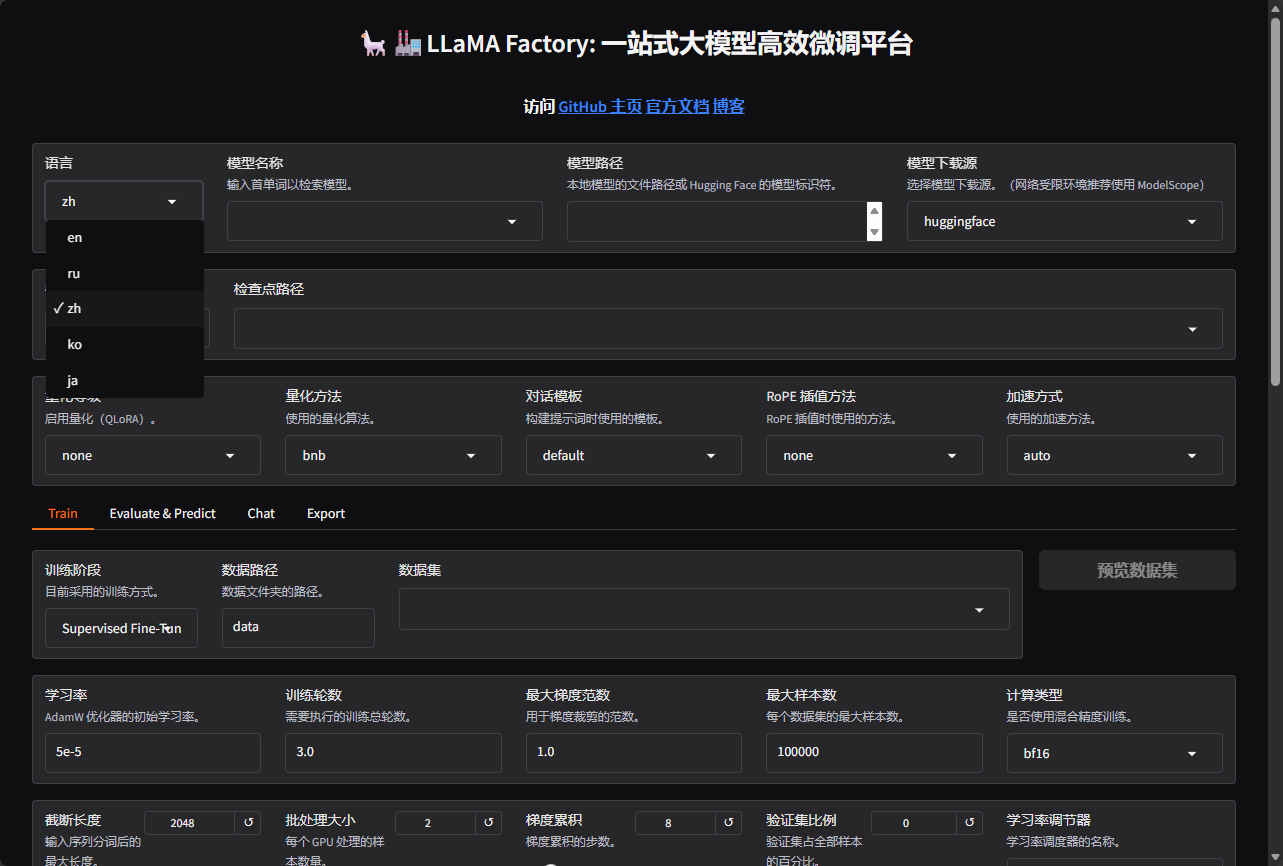
2.本地电脑
在官方链接中,也提供了Windows11的安装方式,都是非常简单,具体的操作自行查阅。
docker方式
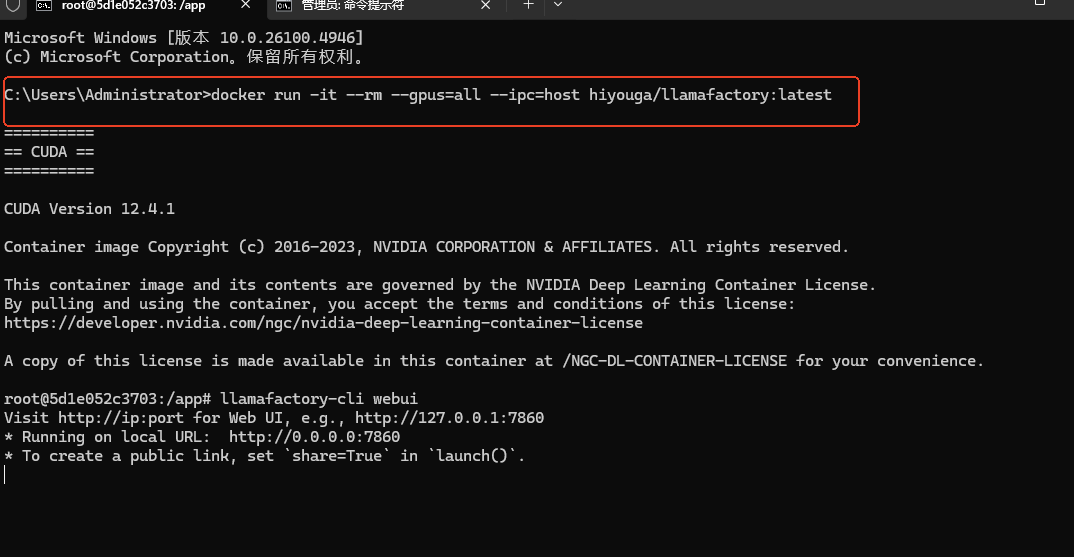
前提需要电脑安装有docker桌面版本和wsl2,当执行下面是命令,会拉取一个llamafactory的镜像,下面是具体的操作。**注意:**需要提前打开docker桌面版本,不然会报错,具体报错在 五.常见问题中第6个问题。
shell
docker run -it --rm --gpus=all --ipc=host hiyouga/llamafactory:latest因为我之前有安装过,所以当执行的时候,会直接进入到/app#中,并且在docker中能看到具体的镜像。wsl的安装和docker的汉化可以查看B站up的视频。
二、微调
1.Lora与Qlora的解释和区别
具体的详解可以查看这两个链接,具体链接为: lora详解和Qlora详解 。由于太过于学术了,下面我会用比较通俗和浅显的方式解释他们。当然还是推荐看一下上面的链接,会加深对他们的理解。
lora部分
假设整个LLM所有参数是W ,lora微调不是直接微调整个模型的参数,而是引入了一个低秩的矩阵ΔW ,我们训练的其实只有这个低秩矩阵ΔW。"引入 ΔW"其实就是:在模型旁边加了一个很小的可训练模块,用来微调模型行为 ,两个小矩阵 A 和 B 相乘得到 ΔW 。其中A矩阵是 m*r ,B矩阵是r*n,正因为r 非常的小,所以称为低秩矩阵 ,r 是控制"你允许这次微调学多少新信息结构"。lora微调,调的就是这个低秩矩阵ΔW ,调完后再将ΔW和W进行合并,所谓的合并其实就是W的参数进行了调整,比如某个参数0.8变成了0.8+0.05=0.85。所以,原始模型是只进行正向传播,不进行反向传播,从而达到冻结参数的效果。而低秩矩阵是要进行前向与反向传播后,参数更新只更新ΔW,所以参与训练的参数量就非常的少。最后合并操作,即ΔW+W ,表示LoRA 的效果直接加到原模型里,就得到最终的模型W'。
那么大模型在lora微调起到什么作用呢?
- 载体的作用,虽然基座模型参数不更新,但每一层的前向传播都必须完整经过基座网络------LLM,只有在这个高维语义空间里lora的小矩阵才有意义,才能得到修正。
- 桥梁的作用,基座只算梯度,不更新 :基座权重
W会参与梯度计算,但计算完直接丢弃,参数纹丝不动 ,只有低秩矩阵A和B会接收梯度、被优化器更新
Qlora部分
从上面的lora部分我们知道,LLM所有参数都是要参与前向计算的,即使不训练 W,我们还是要"加载整个 W"。假设要微调671B的模型,即使使用lora微调,W仍然是FP16,显存占用依然很大。所以,Qlora在 LoRA 的基础上多做了一步,原来的模型FP16 → 4bit (量化操作),剩下的操作都是和lora微调一样的了。QLoRA = "压缩后的大模型" + "LoRA微调模块" ,需要注意的是:Qlora微调时候,LLM只是加载权重参数时候用的是4BIT,LLM在计算时候还是会将4bit临时解量化 回 FP16/BF16 精度,并和全精度的 LoRA 适配器 (ΔW) 一起计算。
本质的区别:
Lora:不动模型结构,不压缩模型,只加ΔW,LoRA 解决"怎么少训练参数"。打个比喻:专家(类比大模型,完整记忆),小抄(LoRA)。问题就在于:专家太占地方(显存大)。
Qlora:先压缩模型(比如FP16→4bit),再加ΔW,QLoRA 解决"模型太大装不下"。打个比喻:把专家"压缩记忆"(变模糊一点),小抄(LoRA)。
那有了Qlora是否意味着就不需要lora了呢?其实不是的,Qlora做了量化,量化≠完全无损,4bit 一定会有信息损失。大多数情况下Qlora≈ LoRA(效果接近),但是在精度敏感的任务(比如代码生成、数学推理)就必须要上Lora才行了。并且在合并时候Lora是无缝合并回基座模型的,而Qlora需要反量化才行,并且lora微调是可以直接使用vllm进行部署,Qlora需要转换格式,大部分情况下,我们都是使用lora微调较多而不是Qlora。QLoRA 并不是用来取代 LoRA 的,而是在显存受限场景下的一种更高效实现,当资源充足时,LoRA 仍然是更简单、更稳定、精度更高的选择,当资源有限时,QLoRA 则可以让大模型微调变得可行。
2.Llamafactory的Lora微调方式
(1)数据集
上面已经解释了Lora和Qlora是什么以及他们的区别,现在开启微调之旅!在微调之前需要去huggingface或者是modelscope下载要微调的数据集。本次我使用的是一个开源的数据集,石油工程(油气井工程)问答数据集
不同的任务需要不同的数据集格式,那么这些数据集格式应该是什么样子的呢?其实可以在下载好的Llamafactory的data下有一个README_zh.md文件 ,或者直接去github上看官方的详解:llamafactory数据集详解 。因为本次微调是问答类型的,微调的数据集格式直接使用alpaca格式就行,后期我们要使用自己的数据集,完全可以仿造alpaca格式,类似下面的:
json
## 单轮次对话格式
[
{
"instruction": "识别并解释给定列表中的两个科学理论:细胞理论和日心说。",
"input": "",
"output": "细胞理论是生物科学的一个理论,它认为.....。"
},
{
"instruction": "输入三支篮球队的名称并生成一个适当的口号。",
"input": "输入:俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队。",
"output": "输出: \"雷霆,公牛和网队:各显神通,角逐群雄!\""
},
]
## 多轮次对话格式
[
{
"instruction": "解释什么是神经网络", // 必填:用户核心指令
"input": "", // 选填:补充上下文
"output": "神经网络是...", // 必填:期望的模型回答
"system": "你是一位AI专家", // 选填:系统提示词
"history": [] // 选填:对话历史(如果是空,表示这条数据是单次对话)
},
{
"instruction": "解释什么是大语言模型", // 必填:用户核心指令
"input": "", // 选填:补充上下文
"output": "大语言模型是...", // 必填:期望的模型回答
"system": "", // 选填:系统提示词
"history": [
[
"什么是人工智能?",
"人工智能是让机器模拟人类智能的技术科学......" # 第一轮的历史对话
],
[
"什么是机器学习?",
"机器学习是让计算机从数据中学习规律的方法......" # 第二轮的历史对话
]
},
]
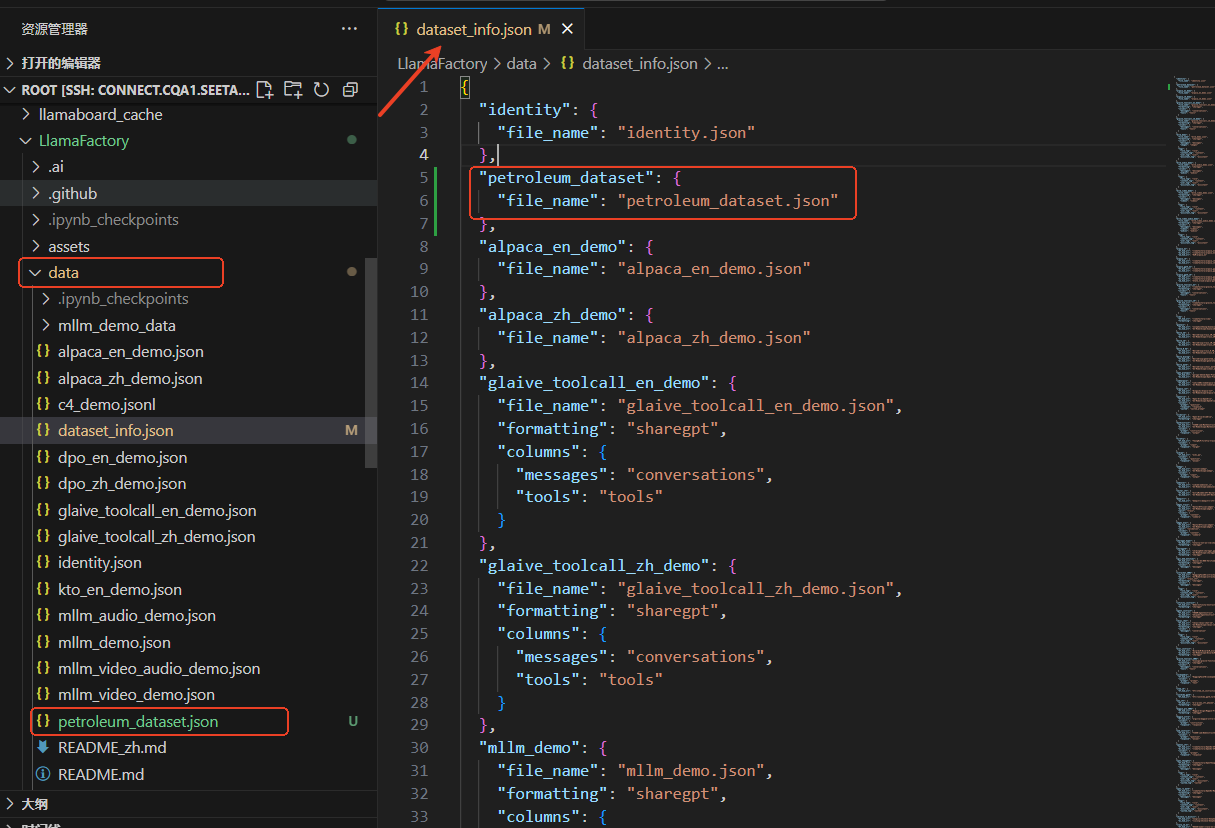
下载好数据集后,我们需要将它放到Llamafactory/data,并且在dataset_info.json中将数据集的名字写上,这样Llamafactory的UI界面才能关联得上,如下图
(2)模型
本次微调的模型是Qwen3-8B的模型,因为是lora微调,在选择模型时候最好是用instruct或者chat版本的,这些都是经过人工校准过的,现在Qwen系列到了3版本后,官方就不怎么加入后缀了,只会在模型卡片中写模型所处于的阶段,比如下图。
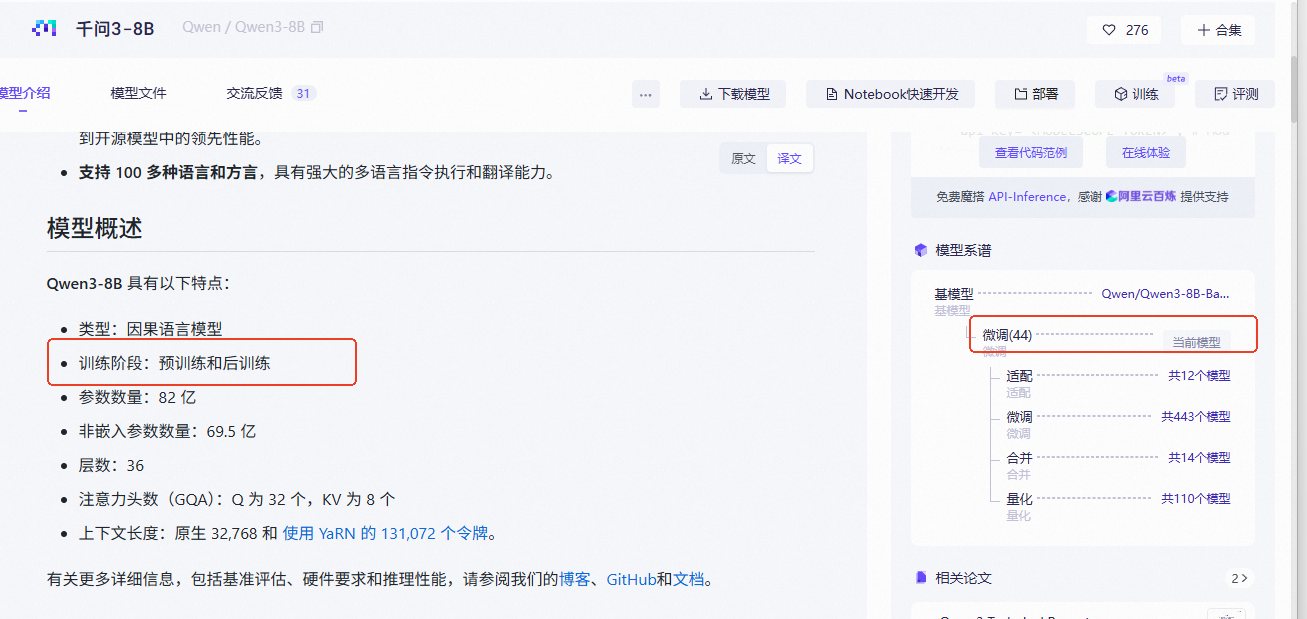
Base、Instruct、Chat 模型核心区别对比表
| 对比维度 | Base 模型 (基座模型) | Instruct 模型 (指令模型) | Chat 模型 (对话模型) |
|---|---|---|---|
| 通俗理解 | "博览群书的鹦鹉" 只懂模仿人类说话的规律,不懂怎么对话。 | "忠诚的执行秘书" 听懂命令,直接给结果,不废话。 | "贴心的客服专员" 不仅听懂命令,还能拉扯、有礼貌、懂避讳。 |
| 训练阶段 | 仅 预训练 | 预训练 + 监督指令微调 (SFT) | 预训练 + SFT + 人类偏好对齐 (RLHF/DPO) |
| 训练数据 | 万亿级无标注文本(网页、书籍、代码) | 高质量的 【指令 + 回答】 配对数据 | 多轮对话数据 + 人类打分偏好数据(好/坏回答对比) |
| 交互方式 | 文本续写(你给上半句,它接下半句) | 单轮/简单多轮指令(你提要求,它给结果) | 复杂多轮对话(能结合上下文连续聊天、追问) |
| 回答风格 | 随性、发散、可能重复、不知何时停止 | 直接、干练、格式规整(如直接给代码/摘要) | 拟人化、礼貌、有引导语(如"好的,为您解答...") |
| 是否有人工矫正 | 无 | 有(人工撰写标准答案教它怎么做) | 深度有(人工打分矫正价值观、安全性和语气) |
| 安全/拒答机制 | 无(通常问什么答什么,可能输出有害内容) | 较弱或基础(主要靠SFT数据里带的少量拒答样本) | 极强(经过专门的安全对齐,懂得拒绝不当请求) |
| 典型代表 | Qwen3-8B-Base, Llama-3-8B | Qwen3-8B (现多省略Instruct后缀), Llama-3-8B-Instruct | ChatGPT, 豆包, 文心一言(面向C端的底层) |
| 主要用途 | 作为"原材料"供研究人员做二次开发 | 作为微调的最佳起点、API工具调用、智能体大脑 | 直接当成产品发布给普通C端用户聊天使用 |
| 微调适用性 | 不适合直接微调(除非你打算自己从零做SFT) | 最适合微调(已经懂规矩,只需注入领域知识) | 可用,但需谨慎(有时太"圆滑",微调容易破坏安全对齐) |
现在使用下面的代码下载模型,执行后,就会自动下载模型到/root/autodl-tmp/Qwen3_8b目录中,如下图
python
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-8B',cache_dir='/root/autodl-tmp/Qwen3_8b')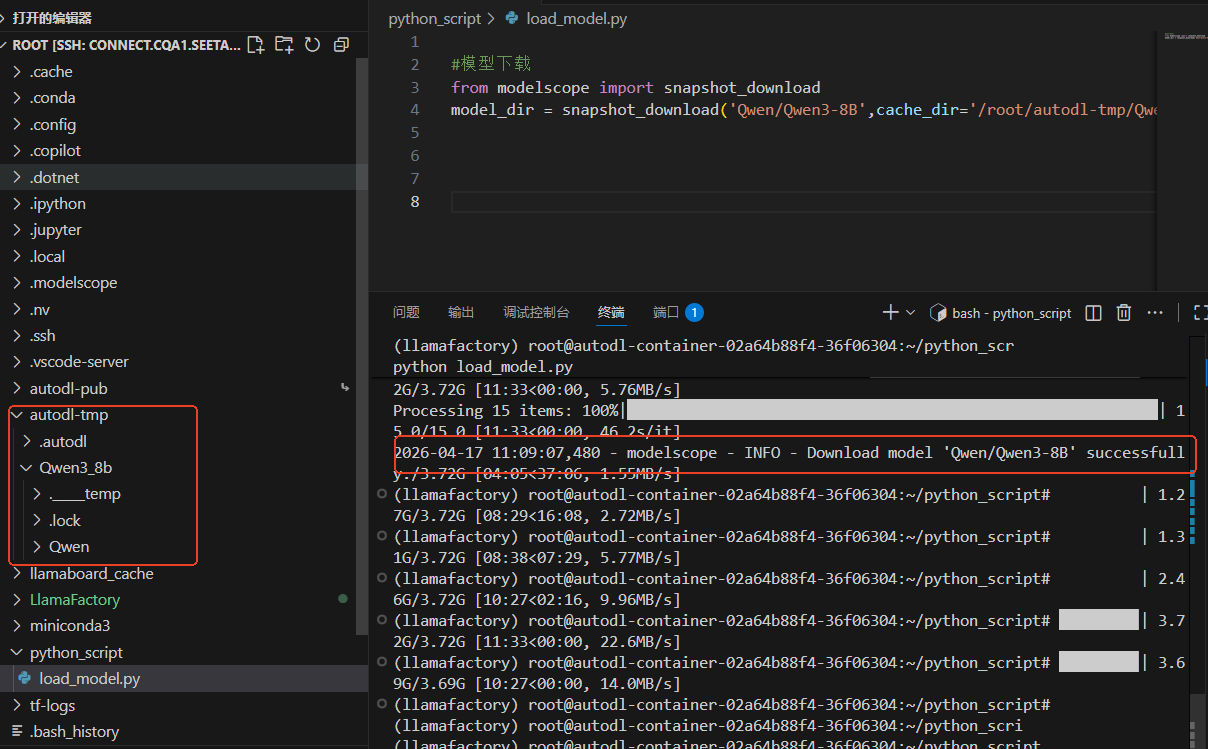
(3)训练
万事俱备只欠东风,现在只需要将下载的模型、下载的数据集以及配置一些参数,训练就可以开启了。下面我会列出lora微调需要注意调整的一些参数,以及一些参数该如何计算。
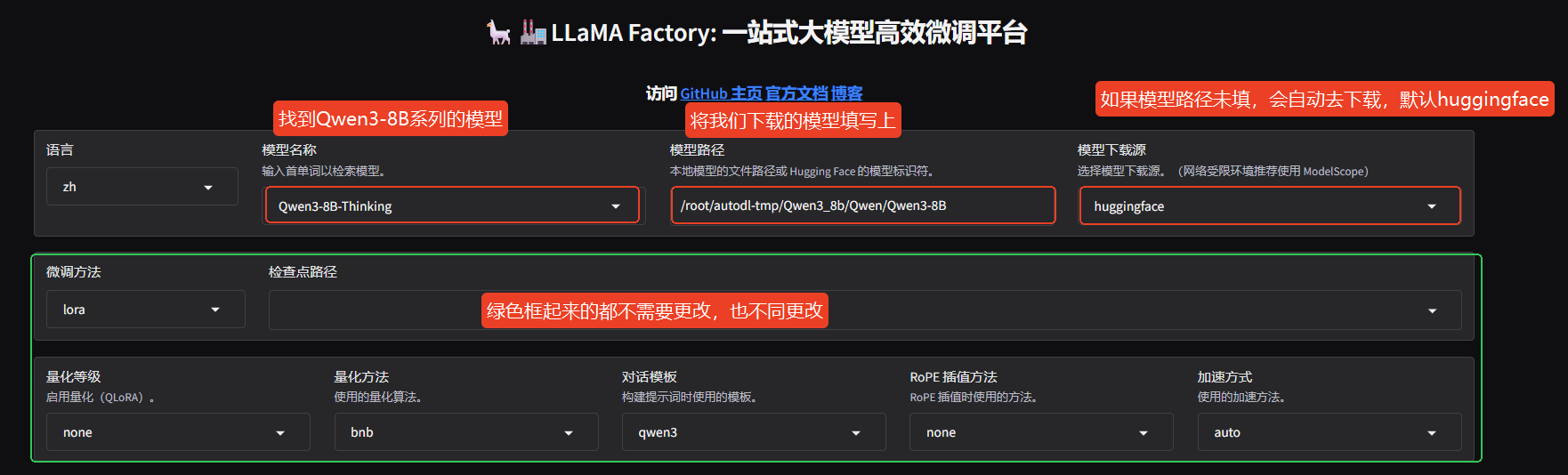
在下图中,模型名称中Qwen3-8B相关的模型会有:Qwen3-8B-Base、Qwen3-8B-Thinking、Qwen3-8B-Thinking-AWQ,根据 (2)模型的内容 我们可以知道,这里应该选择 Qwen3-8B-Thinking,绿色框中 "微调方法" 默认选择lora即可。
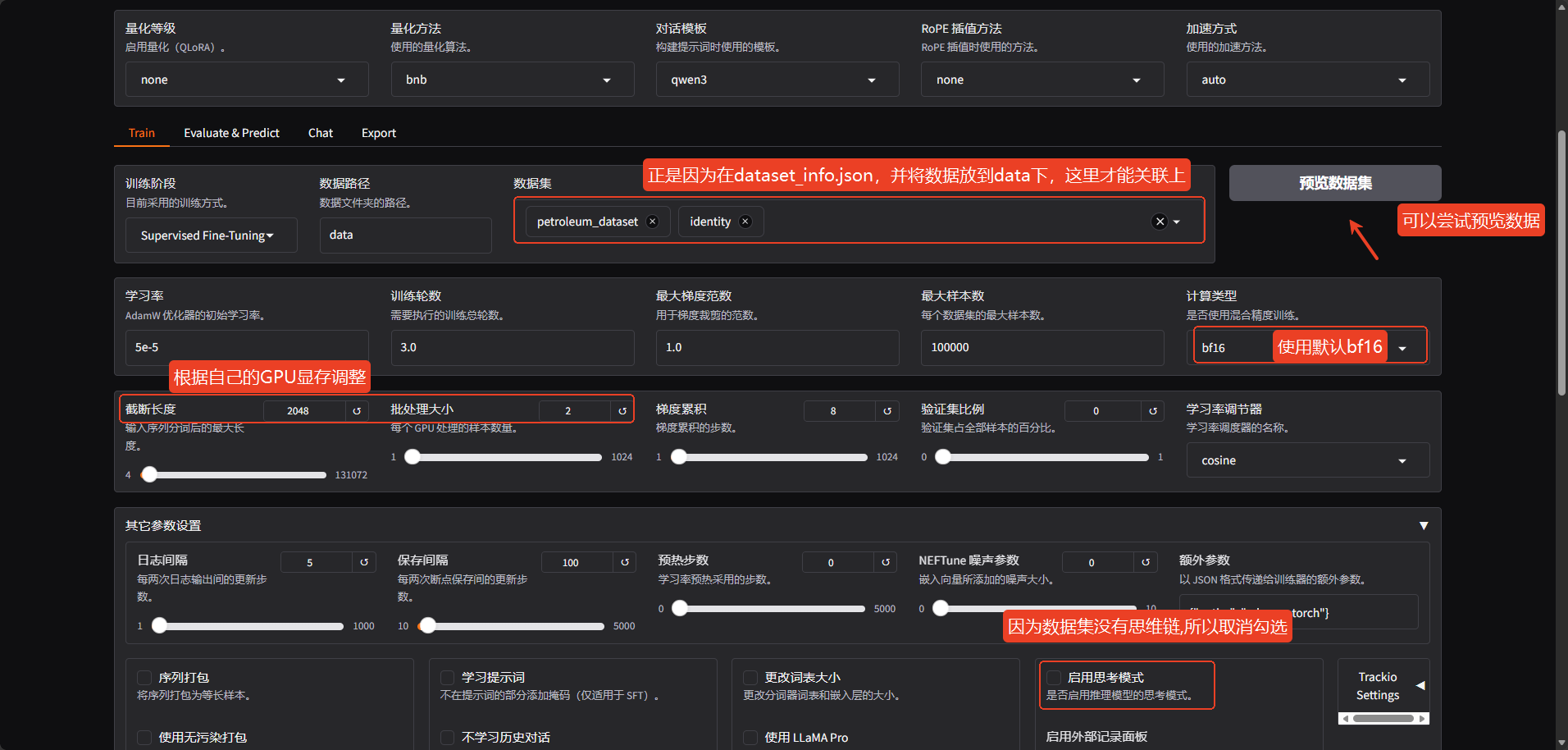
在下图中,其实只有 "启用思考模式" 需要注意,其余的都是根据自己的设备去选择。因为llamafactory训练时,都是以step进行计数的,下面是介绍训练轮次和step的关系以及梯度累积、最大梯度范数是什么。
有效批次大小 = 批处理大小 ∗ 梯度累积 有效批次大小 = 批处理大小 * 梯度累积 有效批次大小=批处理大小∗梯度累积
一个 E p o c h 的 S t e p 数 = 数据集总样本数 有效批次大小 一个 Epoch 的 Step 数 = \dfrac{数据集总样本数}{有效批次大小} 一个Epoch的Step数=有效批次大小数据集总样本数
总训练 S t e p 数 = 一个 E p o c h 的 S t e p 数 ∗ 训练轮数 ( E p o c h s ) 总训练Step数 = 一个Epoch的Step数 * 训练轮数(Epochs) 总训练Step数=一个Epoch的Step数∗训练轮数(Epochs)
最大梯度范数 L 2 : ∥ g ∥ 2 = ∑ i g i 2 最大梯度范数L2: \|g\|_2 = \sqrt{\sum_i g_i^2} 最大梯度范数L2:∥g∥2=∑igi2
梯度累积可以理解为攒多个 batch 的梯度,更新一次参数。为什么要这么设计,是因为显存不够。最大梯度范数默认是L2,作用是防止梯度过大导致梯度爆炸、loss 飙升、出现 NaN、训练直接崩掉,一般情况下默认即可。如果∣∣g∣∣>1.0,那么就会执行 g ∗ 1.0 ∣ ∣ g ∣ ∣ \large g*\frac{1.0}{∣∣g∣∣} g∗∣∣g∣∣1.0
举例:假设梯度向量 g = 3 , 4,那么 ∥ g ∥ 2 = 3 2 + 4 2 \|g\|_2 = \sqrt{3^2+4^2} ∥g∥2=32+42 =5,超过了 1.0 → 触发裁剪,缩放比例 = 1 / 5 = 0.2,新的梯度就变成:3x0.2=0.6,4x0.2=0.8
本次训练,我的训练轮数设置为10轮,对模板选择的是qwen3_nothink,因为我的数据集中并没有思维链。图中仅仅用于参数说明,学习率设置为2e-4,参考的是FAQs | 常见问题:微调效果无法令人满意链接。(小声BB:之前试过默认参数,训练了3轮,效果很差)
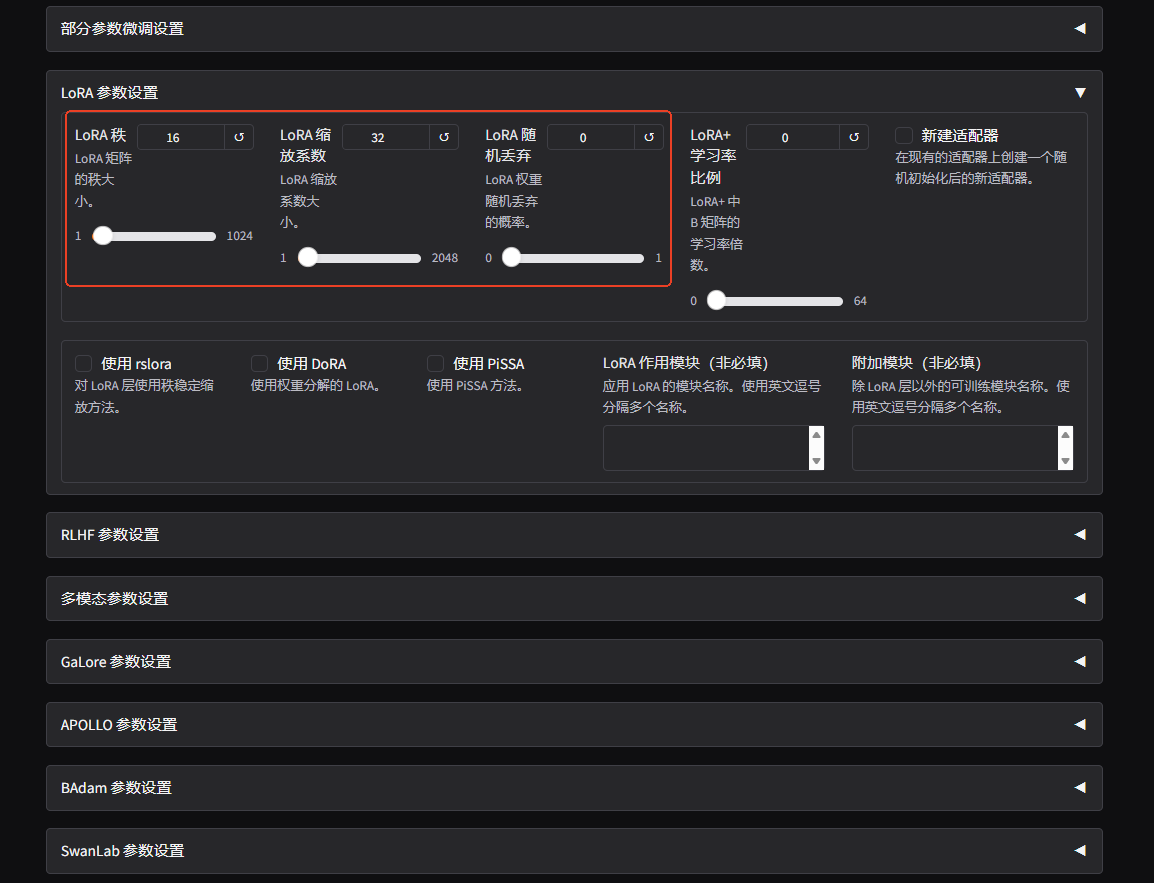
在下图中,我们只需要再设置LoRA秩、LoRA 缩放系数和LoRA 随机丢弃即可。LoRA秩就是前面lora部分提到的A矩阵 m*r 和B矩阵r*n的r。LoRA 缩放系数是用于对 A矩阵、B矩阵进行缩放,缩放强度是 α r \Large\frac{α}{r} rα,写成数学公式是: W ′ ( 合并后模型 ) = W ( 原始矩阵权重 ) + α r ⋅ A B ( 可训练的模块即 l o r a 权重 ) W'(合并后模型)=W(原始矩阵权重)+\frac{α}{r}·AB(可训练的模块即lora权重) W′(合并后模型)=W(原始矩阵权重)+rα⋅AB(可训练的模块即lora权重),如果说r 是决定能学多复杂,那么α控制 LoRA 更新对原模型的"整体影响幅度"。经验值,α是两倍的r,一般r是设置8~32就行,如果数据量太小就设置8就行,数据量大就往大一点设置。
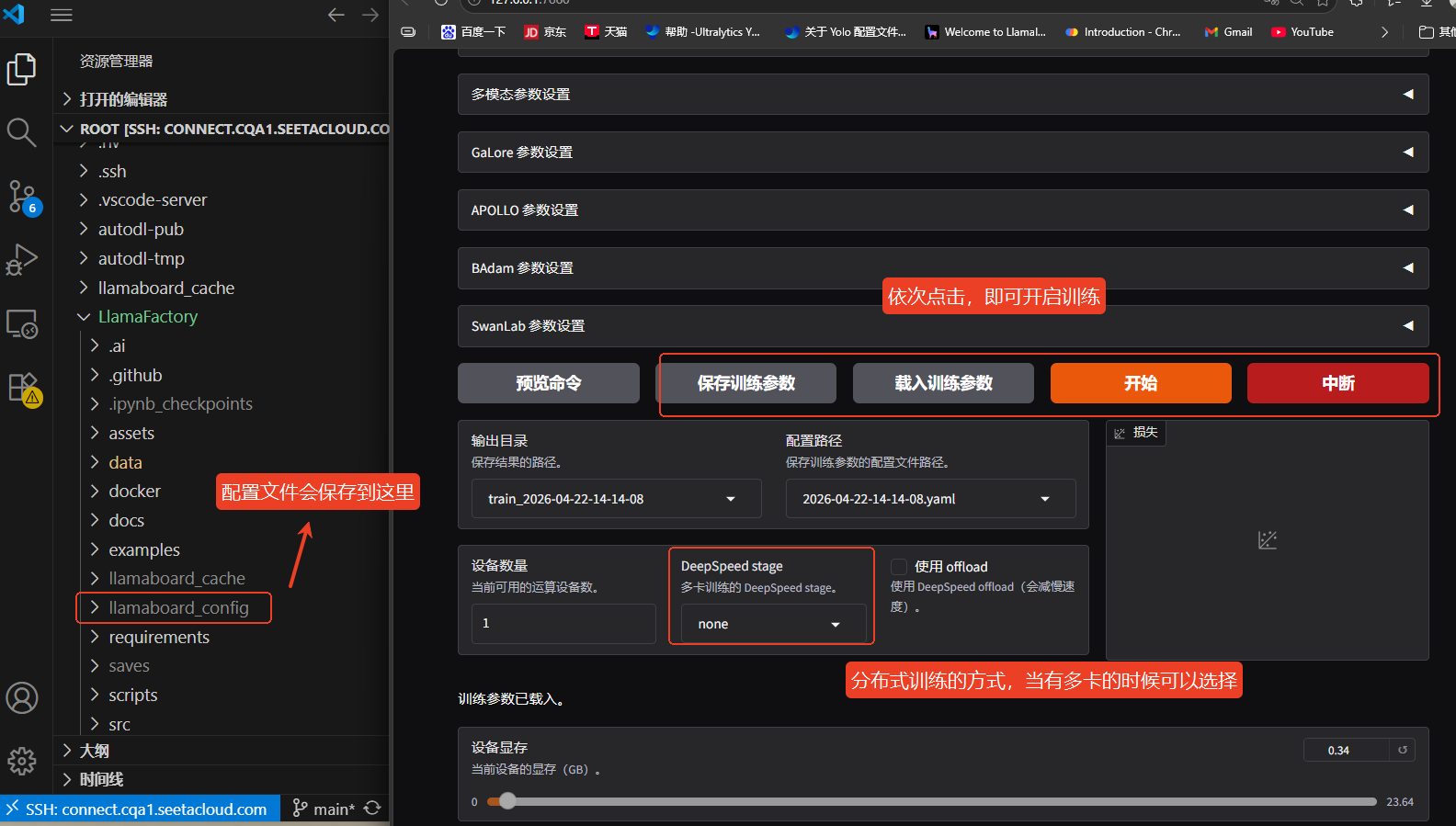
(4)简单测试一下
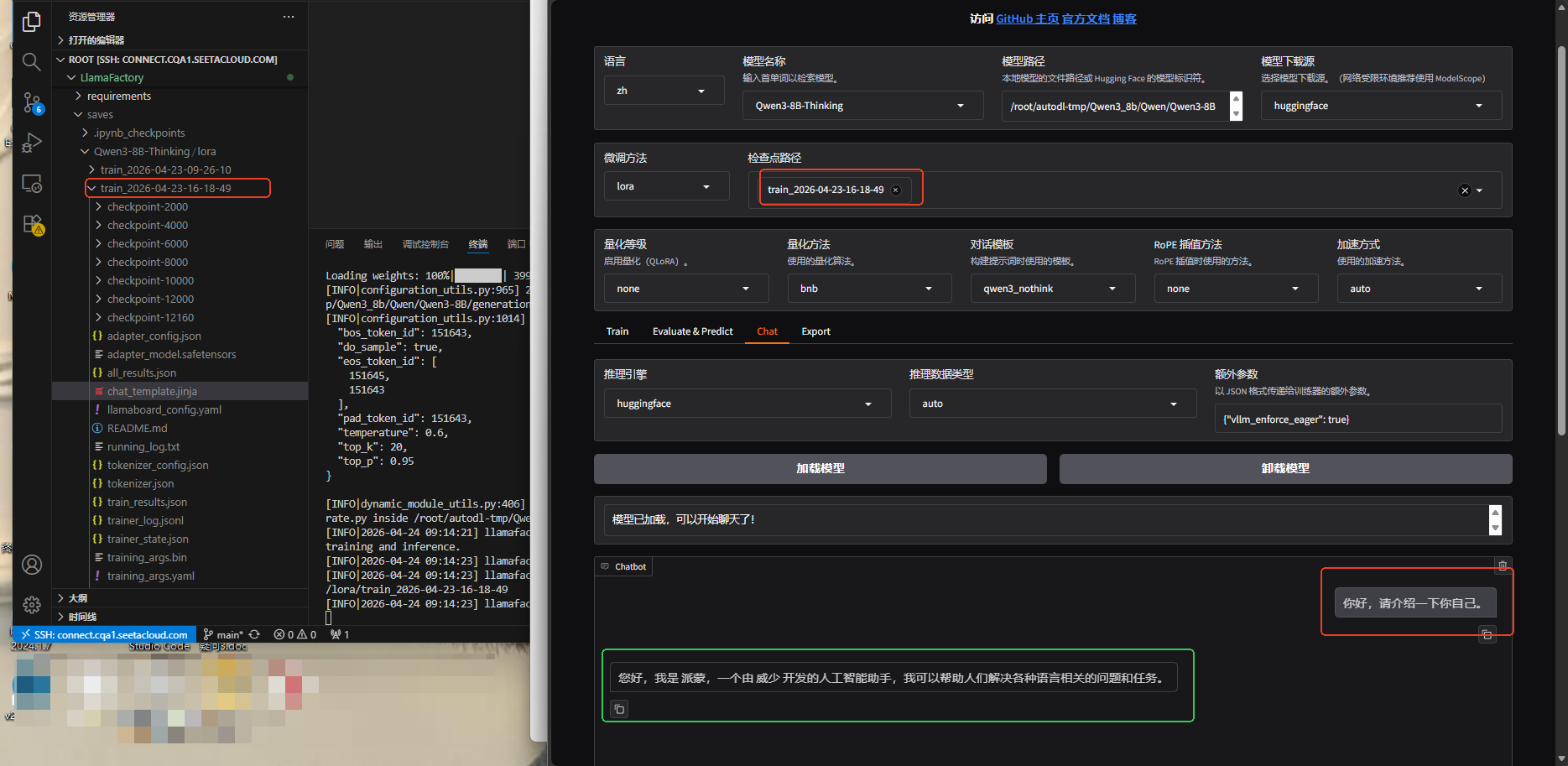
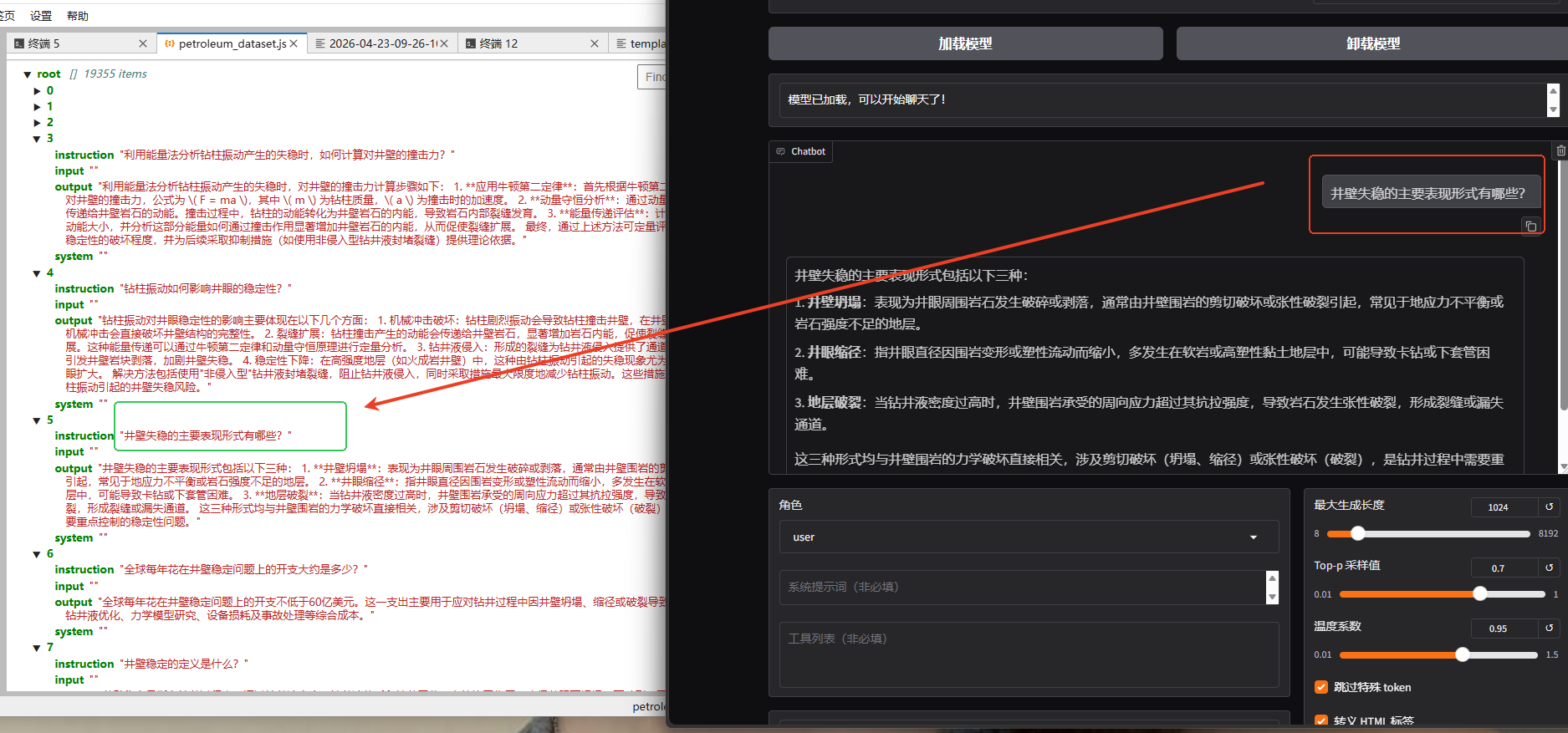
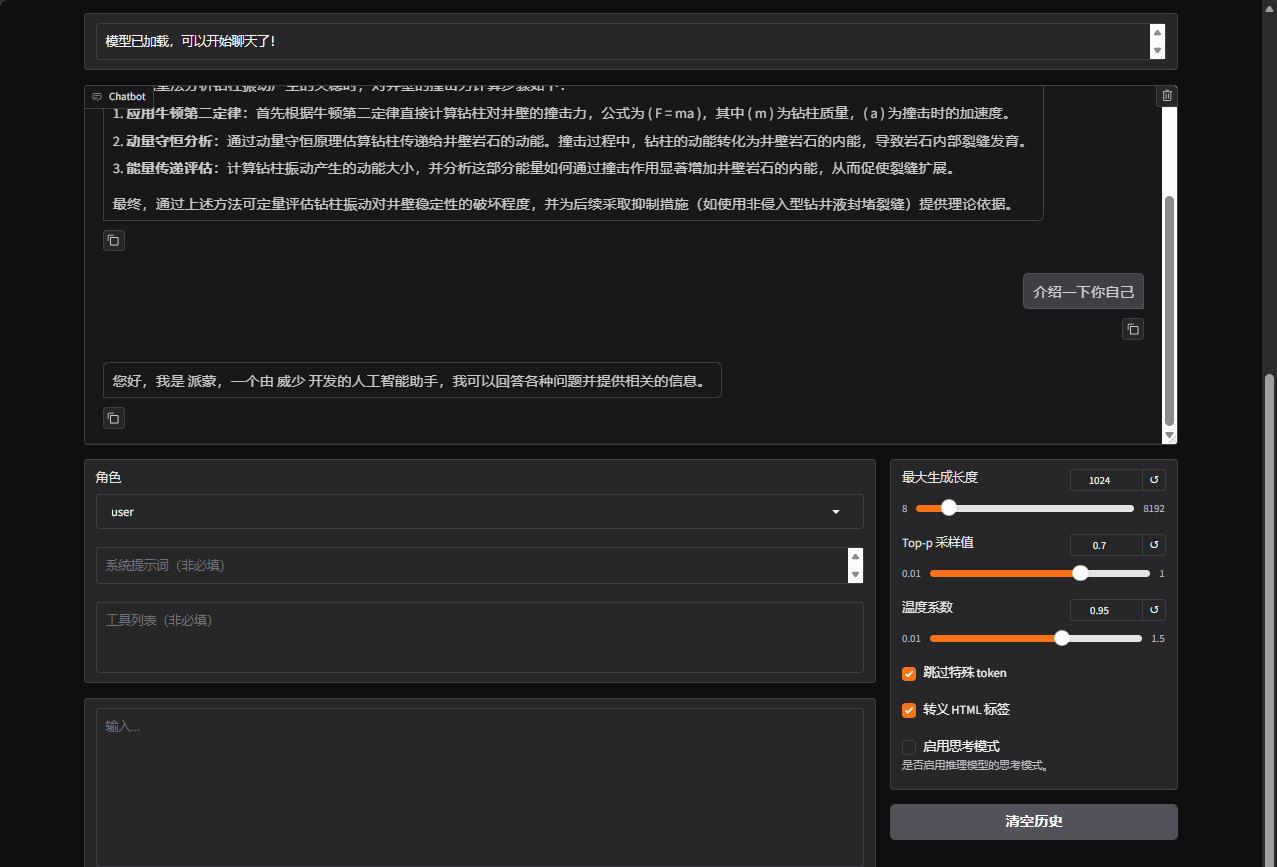
训练完成后,会在Llamafactory/saves存放训练后的lora模型,可以将lora加载进来,注意:基座模型也要加载进来的,也就是Qwen3-8B的那个模型。首先测试一下自我认知是否修改过来了,然后再测试一些关于石油相关的问题,从下图中能看出模型是已经将数据集的知识学习进去了的。
3.Llamafactory的Qlora微调方式
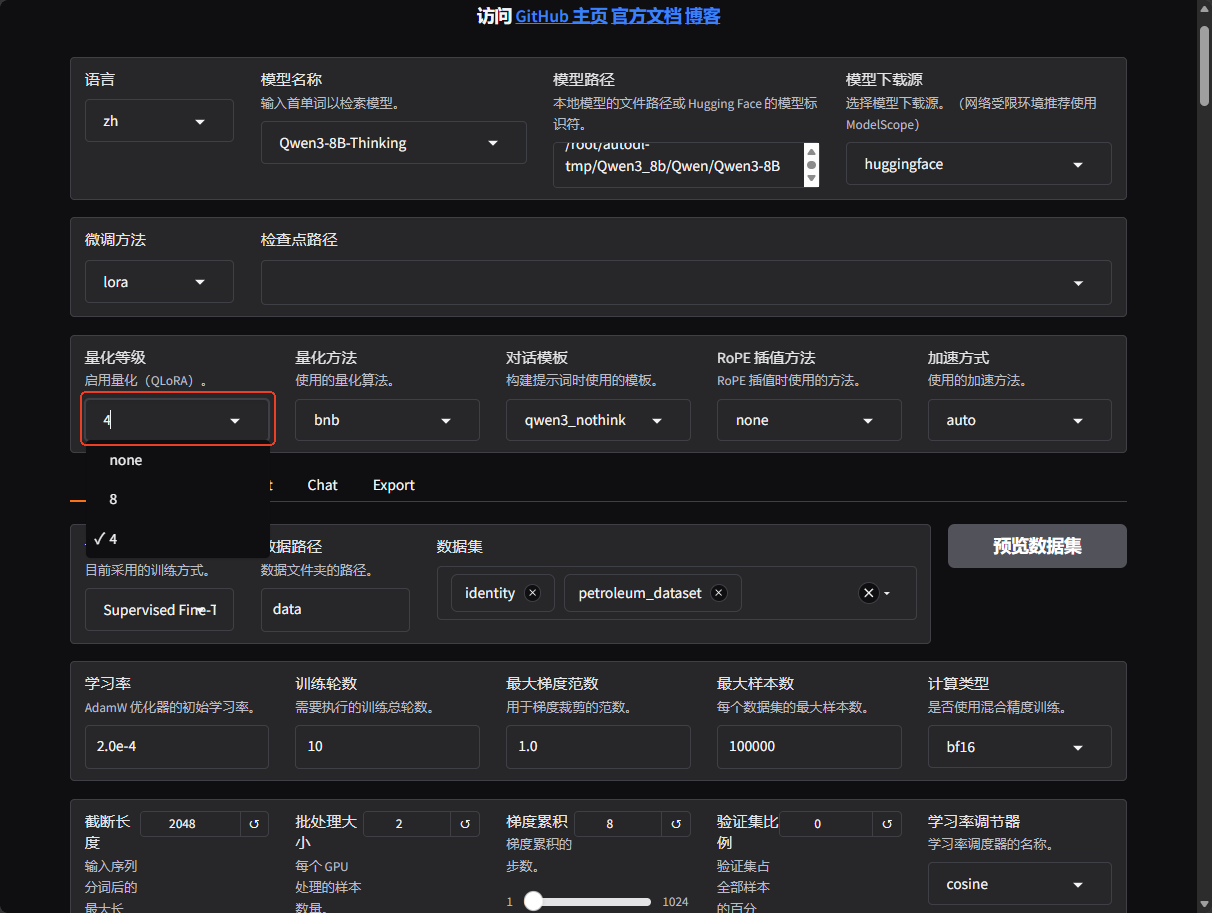
Qlora微调上Lora微调几乎是一样的,只需要设置量化等级,训练时候就会自动开启QLoRA。Qlora启动4bit大部分时候是比8bit好的,因为加载的批次会更加高。既然Qlora会带来精度的损失,如何让Qlora训练的效果差不多等同于lora呢,可以将batchsize提升,然后lora秩也跟着提升。
三、合并
训练好lora模型后,它是一个单独的文件,我们可以将它打包成huggingface格式的模型,所以我们需要将基座模型和lora模型进行合并。把 LoRA 的 ΔW 加回到基座模型 W 上,生成一个新的完整权重,不涉及梯度,所以选择cpu即可,因为是合并操作,所有涉及量化的操作都用选择,填写导出目录后闭合模型即可。
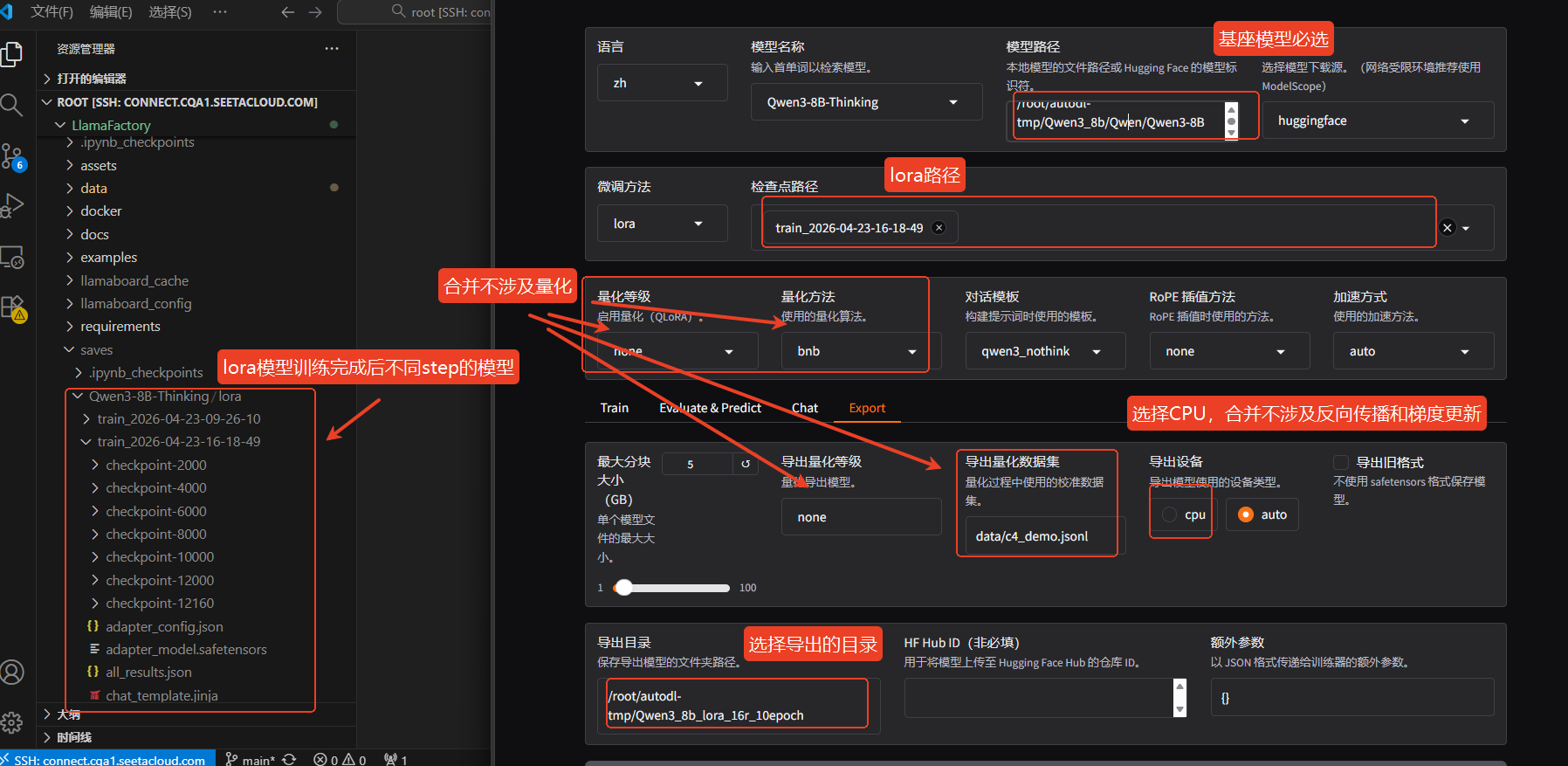
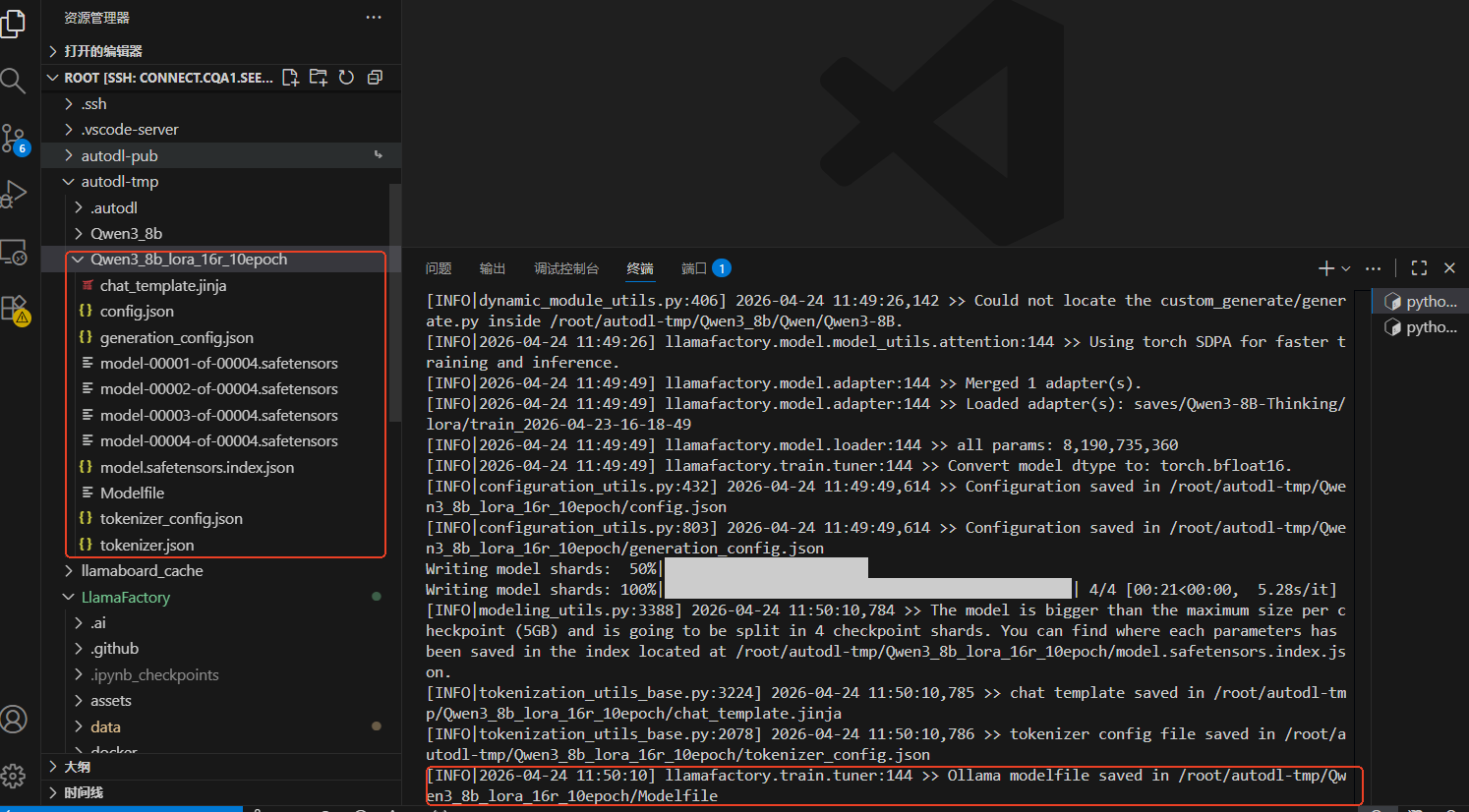
合并成功后,后台是可以看到Ollama modelfile saved in 保存的路径的字样,并且在目录中能看到保存后的模型和modelscope、huggingface格式是一样的。
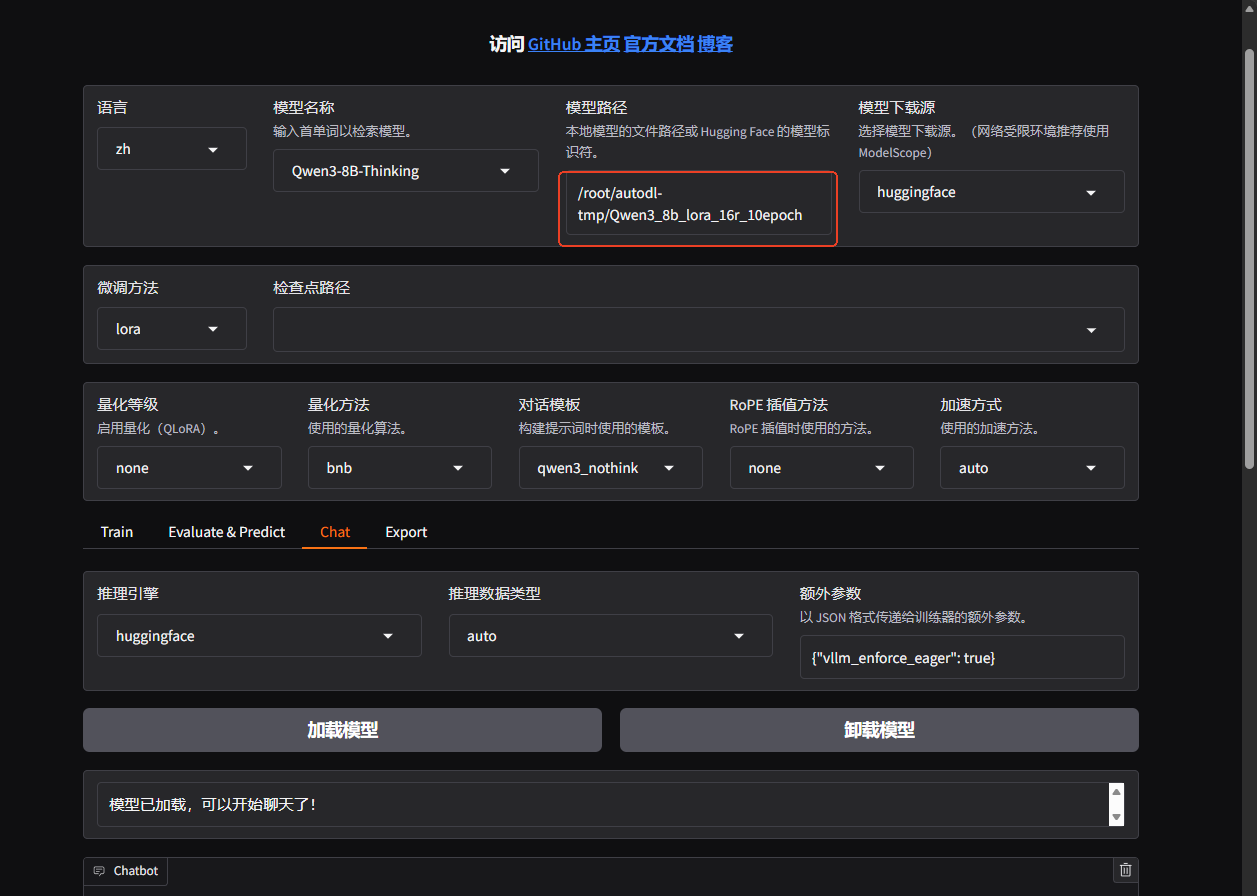
合并后的模型可以直接使用,不需要再通过加载lora模型了,如下图:
四、量化
1.什么是量化
量化的本质是数值的映射关系,可以把量化理解成"把高清图片压缩成低清图片",虽然细节丢了一点,但整体还能看,而且更省空间。量化其实就是在做一件事:
把"连续的浮点数",映射到"有限的整数集合"
比如:
- 原来的浮点数数值可能是:
0.123、-1.56、3.78 - 量化后只能变成:
-128 ~ 127(int8)里的某个整数中
量化通常用这个公式表示:
Q=round(R/S)+Z
可以简单理解为 量化 = 先缩放 + 再平移,下面是每个参数的解释:
- R :原始值(要量化的值,比如上面的
0.123、-1.56、3.78) - S(scale):缩放因子(控制"压缩比例")
- Z(zero point):零点(控制"整体平移,让映射与被映射的值的0刻度对齐")
- Q :量化后的整数值(int8 / int4,比如上面的
-128 ~ 127)
举个例子:将浮点数 -0.2, 0.15 映射到整数 0, 5,已知条件如下面的表格
| 参数 | 值 | 说明 |
|---|---|---|
| min | -0.2 | 浮点数最小值 |
| max | 0.15 | 浮点数最大值 |
| qmin | 0 | 整数最小值 |
| qmax | 5 | 整数最大值 |
1.先计算缩放因子S = (max - min) / (qmax - qmin) = (0.15 - (-0.2)) / (5 - 0) = 0.35 / 5 = 0.07,0.07表示整数的每个刻度代表0.07个浮点单位。(用于理解的比喻:3个苹果,2个人分,3/2=1.5,一人分到1.5个苹果,一个人代表1.5个苹果)
2.计算零点Z =qmin - round (min / S ) = 0 - round(( -0.2) / 0.07 ) = 0 - round(-2.857...) ≈ 3 ,round (min / S )表示:浮点数的最小值,在"整数刻度尺"上,大概落在第几个刻度,如果不考虑平移,浮点数-0.2 会落在整数的"第 -3 个刻度"附近。还可以这么去理解:既然0.07表示整数每个刻度代表0.07个浮点单位,那么浮点数的最小值相当于几个整数呢,则round (min / S )。那么0 - round (min / S ),其实就是让整数刻度这把尺子向右移动了3个位置,就是为了让-0.2和整数的0在同一个位置上。
3.有了S和R后,那么每个数值都能直接通过round(R/S)+Z计算出量化后的值了,所以通过公式,我们可以得出:
S(缩放因子):解决"刻度粗细"问题,让浮点范围的"长度"适配整数范围的"长度",但不关心"起点在哪"
Z(零点):解决"位置对齐"问题,把缩放后的数据"整体平移",让最小值对齐整数起点,确保不溢出、不浪费、0 点精确。
2.llamafactory执行量化
(1)GGUF格式转换与Ollama的部署
转换成GGUF之前,需要安装llama.cpp工具,llama.cpp的github的cmake构建方式其实是为了加载 GGUF 模型并运行推理,但是太过于繁琐,并且我个人是只用python的。所以,只需要安装llama.cpp后,安装所需要依赖即可,推理使用Ollma去做也是一样的。
llama.cpp安装的具体操作如下:
shell
############# 个人建议,最好要做环境的隔离,不要都放在一个环境中 #############
git clone https://github.com/ggerganov/llama.cpp.git # 克隆仓库
pip install -r llama.cpp/requirements.txt # 安装所需依赖
# 如果不量化,保留模型的效果
python llama.cpp/convert_hf_to_gguf.py 自己模型路径 --outtype f16
--verbose --outfile 输出的具体路径
# 例如:
python convert_hf_to_gguf.py /root/autodl-tmp/Qwen3_8b_lora_16r_10epoch --outtype f16 --verbose --outfile /root/autodl-tmp/Qwen3_8b_q8_0/Qwen3_8b_lora_16r_10epoch_q8_0.gguf
# 如果需要量化(加速并有损效果),直接执行下面脚本就可以
python llama.cpp/convert_hf_to_gguf.py 自己模型路径 --outtype
量化类型 --verbose --outfile 输出的具体路径
# 例如:
python convert_hf_to_gguf.py /root/autodl-tmp/Qwen3_8b_lora_16r_10epoch --outtype q8_0 --verbose --outfile /root/autodl-tmp/Qwen3_8b_q8_0/Qwen3_8b_lora_16r_10epoch_q8_0.gguf
# 验证是否安装好依赖:
python convert_hf_to_gguf.py -h # 如果安装好了,应该会输出很多的参数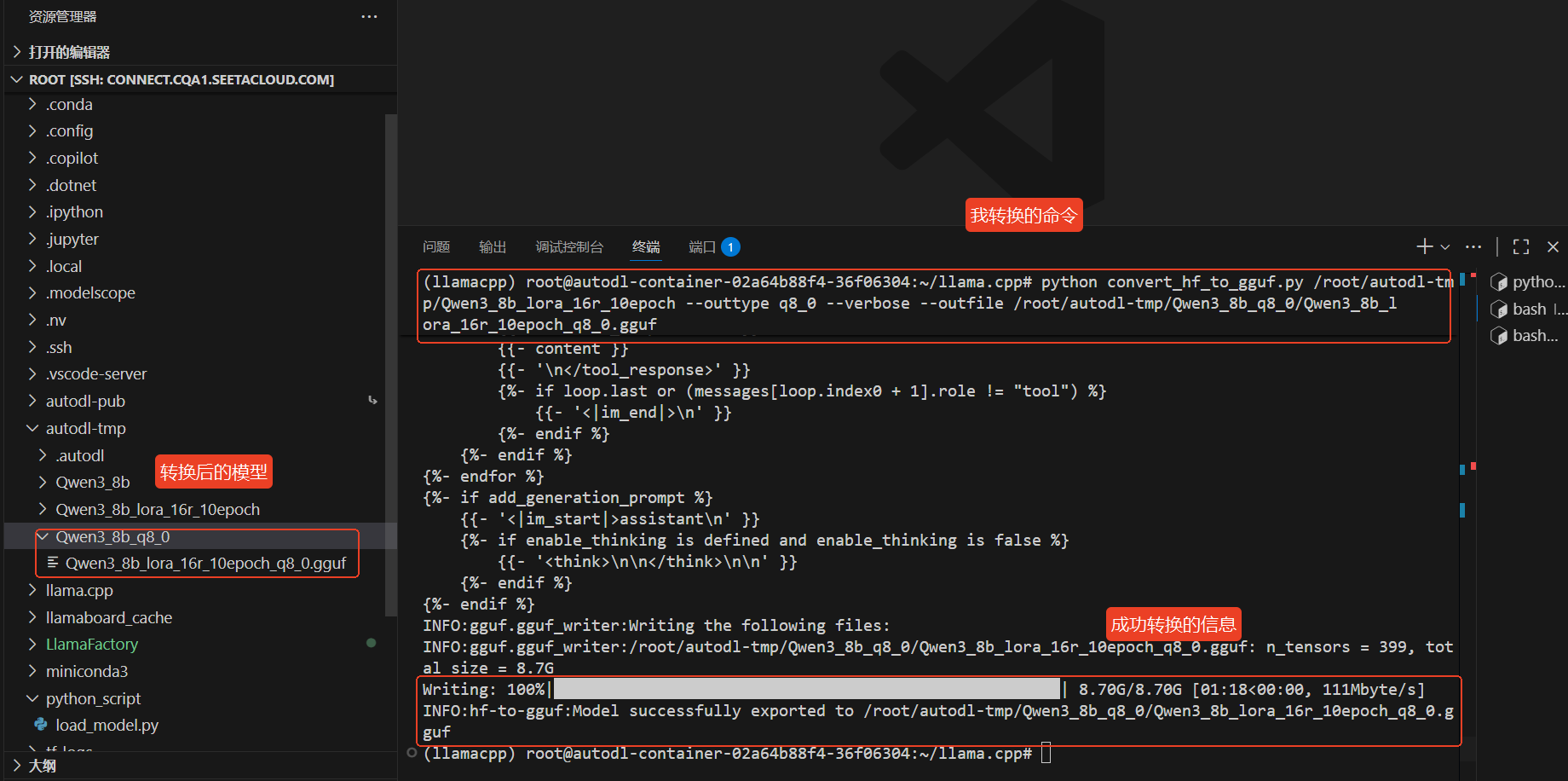
上图中可以看到已经成功的将模型导入并量化成8bit模型了,现在使用Ollama去部署这个模型,首先需要安装Ollama,具体安装如下:
shell
# 官方命令:
curl -fsSL https://ollama.com/install.sh | sh
# modelscope的方式,具体链接如下:
https://www.modelscope.cn/models/modelscope/ollama-linux
# 验证是否安装成功
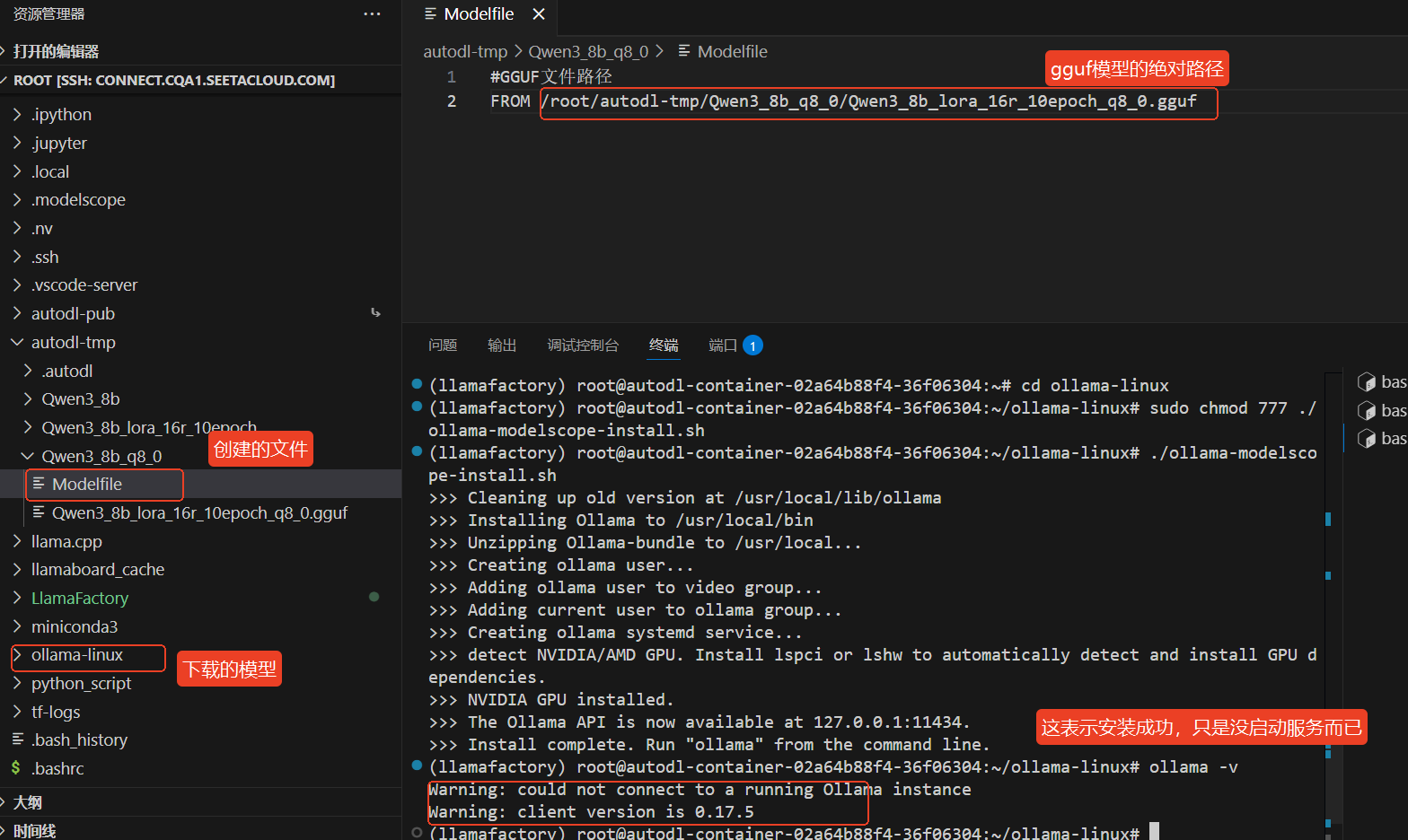
ollama -v # 输出:ollama version x.x.x**Ollama如何去部署这个模型呢?**可以参考Ollama导入模型(Importing a Model - Ollama)的链接,我们需要创建一个meta文件,根据官方的文档,这里直接创建一个名字为Modelfile的文件,不需要写后缀的,名字可以随意起,重点是文件的内容。
下面图中演示的是使用modelscope方式进行安装和Modelfile的文件的内容
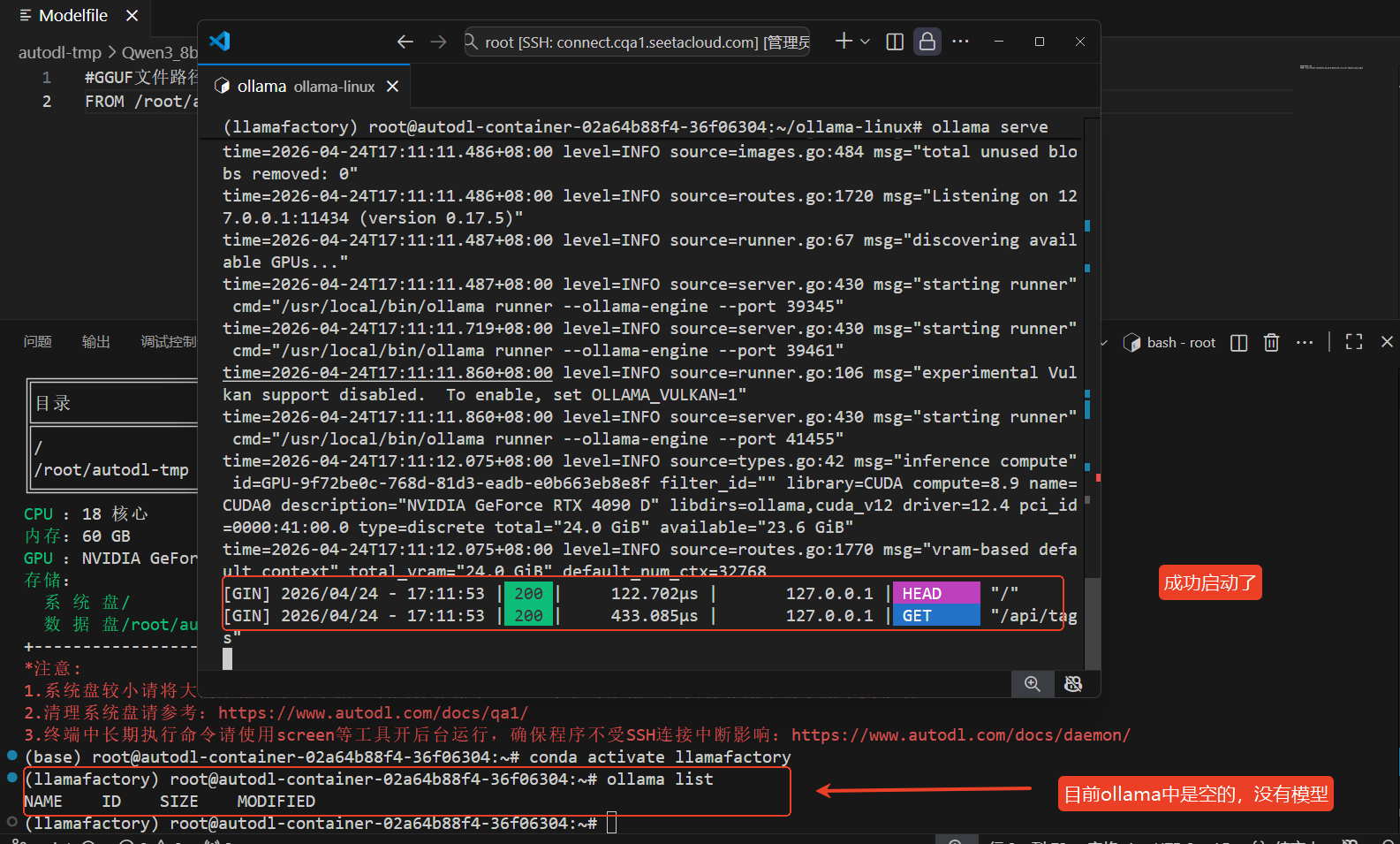
下图中表示安装后,使用ollama serve启动服务。
然后使用ollama create命令创建自定义模型,将模型添加到仓库中ollama create Qwen3_8B_q8_0 --file /root/autodl-tmp/Qwen3_8b_q8_0/Modelfile,名字是随便写的。但是在添加之前,建议先终端中进行设置仓库的位置,不然模型比较大,磁盘不一定够用,具体操作如下命令
cmd
# 切环境
(base) root@autodl-container-02a64b88f4-36f06304:~#conda activate llamafactory
# 设置仓库位置(这个命令每次开启新的终端都要设置一次,不然新的终端会找不到模型)
(llamafactory) root@autodl-container-02a64b88f4-36f06304:~#export OLLAMA_MODELS=/root/autodl-tmp/ollama_models
#将仓库位置打印出来
(llamafactory) root@autodl-container-02a64b88f4-36f06304:~#echo $OLLAMA_MODELS /root/autodl-tmp/ollama_models
# 启动服务
(llamafactory) root@autodl-container-02a64b88f4-36f06304:~#ollama serve 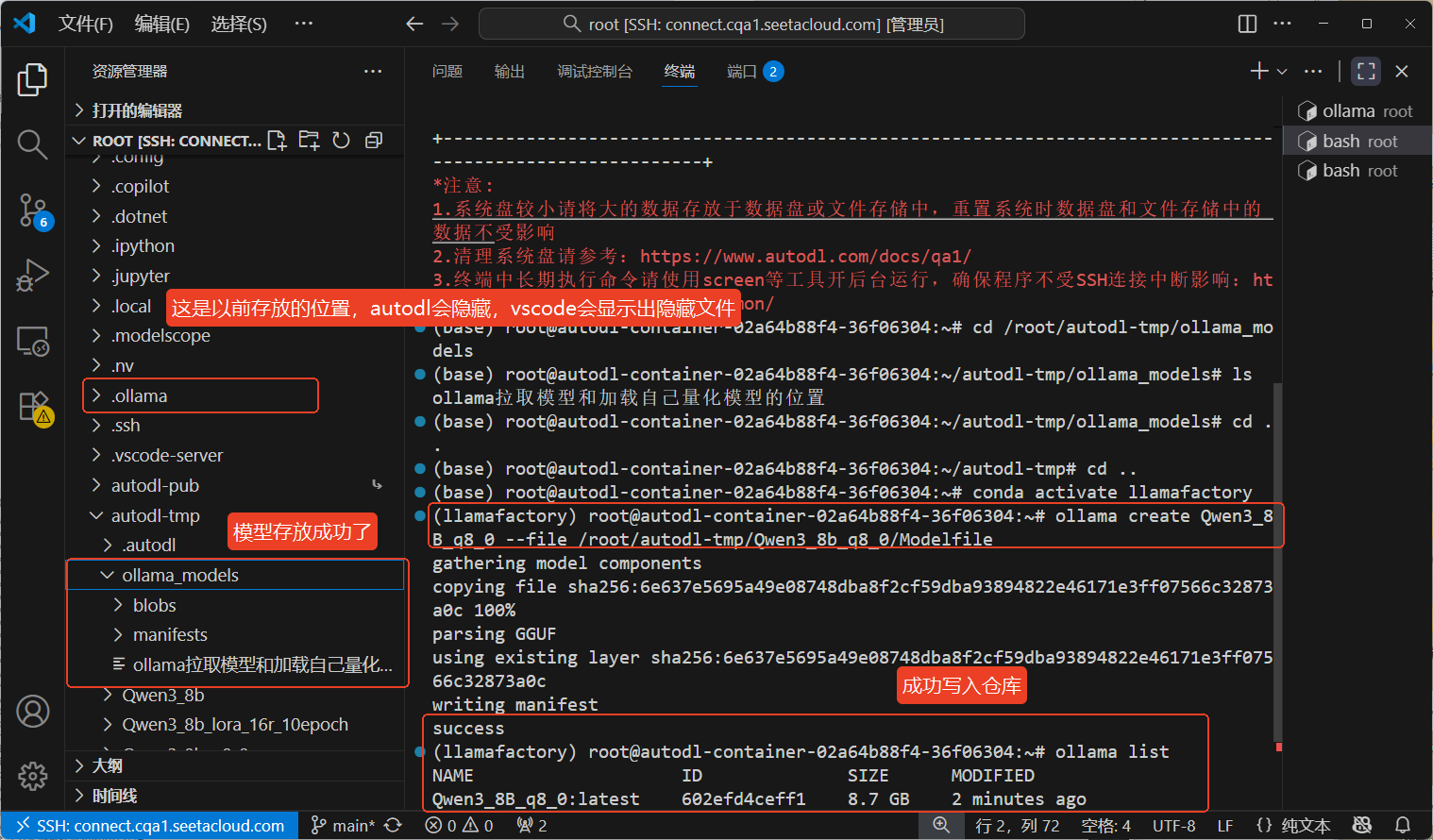
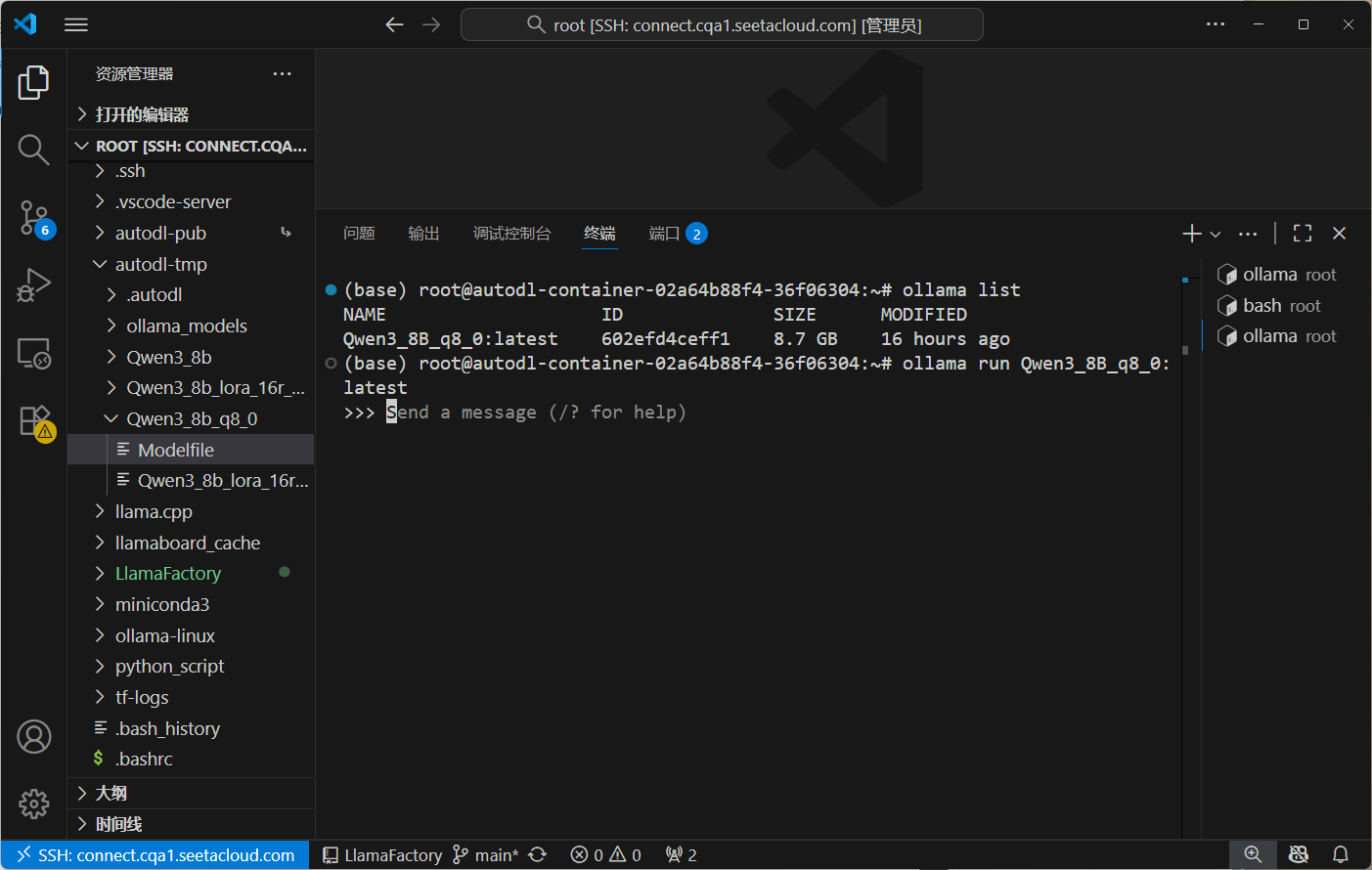
五.常见问题
1.如何判断模型需要的数据集是什么样的格式呢?
答 :一般在lora微调时候,其实直接使用llamafactory提供的数据格式即可,具体数据集的格式,需要去看官方的相关链接:llamafactory数据集详解 :
- 单轮问答(最常用、推荐新手)→ Alpaca 格式
- 多轮对话(做聊天机器人)→ ShareGPT 格式
2.在llamafactory上测试模型是没问题的,但是在vllm上面部署后测试的模型对话却有了问题。
答 :一般是因为对话模板出现了问题,需要将llamafactory的对话模板导出,然后vllm在部署的时候将对话模板加上,注意:vllm需要的对话模板是.jinja格式的。具体导出方式如下:
(后续更新后,会贴上来...)
3.启动llamafactory时候出现告警的原因
python
/root/miniconda3/envs/llamafactory/lib/python3.12/site-packages/torch/cuda/__init__.py:180: UserWarning: CUDA initialization: The NVIDIA driver on your system is too old (found version 12040). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver. (Triggered internally at /pytorch/c10/cuda/CUDAFunctions.cpp:119.)
return torch._C._cuda_getDeviceCount() > 0 在autodl中启动 llamafactory-cli webui命令时候可能会出现上面的终端告警,告警会导致无法使用GPU微调。这是因为环境的驱动版本支持的最高的cuda是12.4,而在安装llamafactory的时候,安装的cuda版本又太高了,导致会出现告警并提示驱动版本太旧。具体的原因如下:
-
pip install -e .会自动检测当前目录下是否有 pyproject.toml / setup.py / setup.cfg(Python 包的配置文),然后就触发了pyproject.toml 依赖解析。
-
llamafactory在v0.9.4后,安装依赖的文件从setup.py文件变变更成了pyproject.toml后,pyproject.toml文件中有写: "torch>=2.4.0","torchvision>=0.19.0","torchaudio>=2.4.0"。那么,会自动安装最新的torch和最新 nvidia-* CUDA 组件(cu13)。个人的电脑或者镜像驱动可能不是cu13的版本,很多人的可能是12.4的或者是其他的版本,那么执行这个命令后,它会自动取安装最新的torch以及最新的驱动,就会导致和自己的电脑或者镜像不兼容。
解决方式:
创建constraints.txt,然后写入要安装的torch,torchvision,torchaudio版本,比如下面我写的。然后安装命令变成pip install -e . -c constraints.txt,这样操作后,pip 行为变成:仍然读取 pyproject.toml,但被 constraints 强制锁某些包的版本,这样就解决了告警。
shell
torch==2.5.1
torchvision==0.20.1
torchaudio==2.5.14.如果我要训练的数据集是有思维链的,请问如何操作呢?
答:在训练过程中,一般不会开启思维链模式,然后数据集中的思维链可以将它和输出放到一起,比如下面这种:
json
{
"messages": [
{"role": "user", "content": "问题"},
{
"role": "assistant",
"content": "<think>推理过程</think>\n最终答案"
}
]
}5.llamafactory在微调的时候,微调的是哪些参数,它怎么知道要微调哪些参数呢?
答 :是人为指定的,不是模型自己觉得的。当在llamafactory中选择模型时候,它会去查找模型文件夹下的 config.json,LLaMA-Factory 底层其实还是huggingface的PEFT 库,PEFT 会遍历整个 PyTorch 模型的 named_modules(),然后找到对应的"q_proj", "v_proj"模块,然后对他们进行微调。
6.拉取镜像出现failed to connect to the docker API at npipe:////./pipe/dockerDesktopLinuxEngine; check if the path is correct and if the daemon is running: open //./pipe/dockerDesktopLinuxEngine: The system cannot find the file specified.
答:因为docker桌面版并没有打开,需要打开后才行。
7.在AutoDL的jupyter中成功运行了llamafactory-cli webui,但是本地电脑却无法访问http://127.0.0.1:7860。
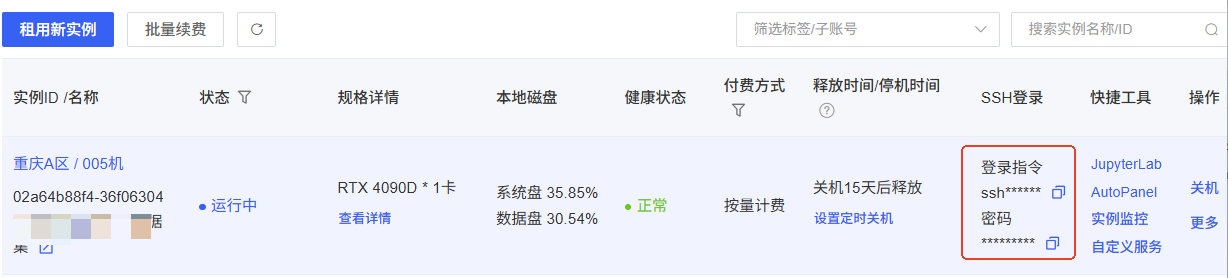
答 :因为没有做网络穿透导致的,AutoDL实例没有独立公网 IP,容器端口不能直接通过我们本地电脑去访问,必须通过 AutoDL 提供的端口映射机制或SSH 隧道才能访问,具体操作链接:SSH隧道的方法。那为什么VScode却可以呢,因为VScode它自带了网络穿透。下面演示我是如何操作的:
1.获取登录指令和密码:比如我的登录指令:ssh -p 4xxx1 root@connect.cqa1.seetacloud.com,密码是:gyyyyyyyyf
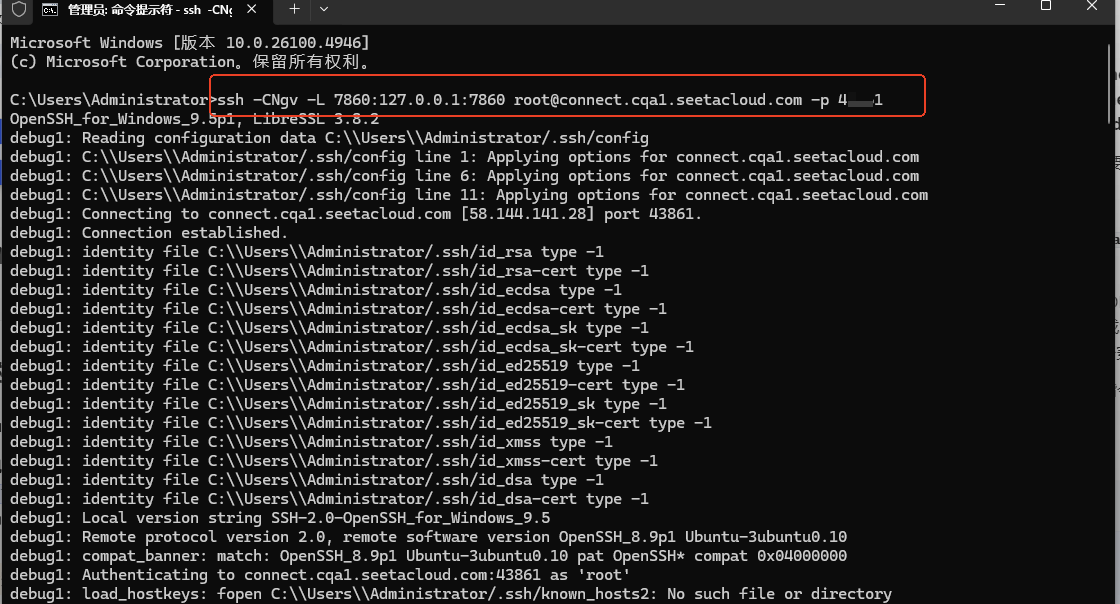
2.因为llamafactory启动后会提供http://127.0.0.1:7860。直接使用本地电脑的7860映射到Autodl实例的7860中。根据官方文档,在本地电脑中启动cmd后,按照规则填写后,本地电脑就可以访问llamafactory提供的地址了:
8.在Autodl上安装Ollama失败原因
在安装Ollama时候出现了报错:
shell
(llamafactory) root@autodl-container-02a64b88f4-36f06304:~/LlamaFactory# curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
ERROR: This version requires zstd for extraction. Please install zstd and try again:
- Debian/Ubuntu: sudo apt-get install zstd
- RHEL/CentOS/Fedora: sudo dnf install zstd
- Arch: sudo pacman -S zstd答 :这是因为在autodl中缺少了缺少 zstd(Zstandard 解压工具),Ollama 安装脚本下载的是 .zst 压缩包,没有这个工具就解不开。具体操作如下:
shell
apt-get update
apt-get install -y zstd
curl -fsSL https://ollama.com/install.sh | sh # 官方提供的方式,但是个人建议使用Modelscope的方式去安装,不然会安装得特别的慢(我到底还是忘不了派蒙吧)
