SGLang 推理服务基础性能评测
- 写在最前面
- 一、测试对象与环境说明
- 二、部署与启动
-
- [2.1 官方 Docker 镜像与本文落地方式](#2.1 官方 Docker 镜像与本文落地方式)
- [2.2 SSH 登录与远端环境检查](#2.2 SSH 登录与远端环境检查)
- [2.3 服务启动前的必要准备](#2.3 服务启动前的必要准备)
- [2.4 SGLang 服务启动](#2.4 SGLang 服务启动)
- [2.5 接口验证与模型确认](#2.5 接口验证与模型确认)
- [三、SGLang 这一阶段的性能重点](#三、SGLang 这一阶段的性能重点)
- 四、测试方法
-
- [4.1 基础正确性验证](#4.1 基础正确性验证)
- [4.2 重点特性一:流式响应体验](#4.2 重点特性一:流式响应体验)
- [4.2 重点特性二:并发扩展性](#4.2 重点特性二:并发扩展性)
- [4.4 补充观察](#4.4 补充观察)
- 五、小结
- [附录 A:统一 benchmark 入口](#附录 A:统一 benchmark 入口)
- [附录 B:完整启动脚本](#附录 B:完整启动脚本)
- [附录 C:兼容性问题与排查记录](#附录 C:兼容性问题与排查记录)
- [附录 D:Docker 参考路径与镜像说明](#附录 D:Docker 参考路径与镜像说明)
- [附录 E:benchmark_sglang.py文件内容](#附录 E:benchmark_sglang.py文件内容)

🌌你好!这里是 晓雨的笔记本 在所有感兴趣的领域扩展知识,感谢你的陪伴与支持~ 👋 欢迎添加文末好友,不定期掉落福利资讯
写在最前面
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
SGLang 推理服务基础性能评测
在昇腾 Atlas 800I A2 环境中部署 SGLang,并对 Qwen3-0.6B 做基础性能与正确性评测
------单卡 Atlas 800I A2 实例下的服务启动、流式响应与并发扩展性实测
本文以 SGLang 在昇腾 Atlas 800I A2 环境中的实际落地为主线,先完成服务部署与启动,再围绕基础正确性、流式首 Token 响应和并发扩展性进行基线测试。主线为跑通服务所需的必要命令;详细兼容性排查详见附录。
| 项目 | 内容 |
|---|---|
| 测试对象 | SGLang 推理服务 |
| 模型 | Qwen/Qwen3-0.6B |
| 测试实例 | Atlas 800I A2 单卡实例(宿主机资源为 4 ×Atlas 800I A2) |
| 代码基线 | SGLang 仓库版本 7603b226c;Python 3.11.6 |
| 评测重点 | 流式响应体验、并发扩展性、基础正确性验证 |
| 结果口径 | 当前结果为 graph-off 基线结果,不代表最终最优性能上限 |
本文关注三个问题: 一是 SGLang 能否在当前昇腾 Atlas 800I A2 单卡实例上稳定启动;二是流式场景下首 Token 返回是否足够快;三是并发提升后吞吐与时延如何变化。
更新后的结果显示: 流式 TTFT 约 79.93 ms;1 / 4 / 8 并发下请求吞吐约为 2.93 / 3.28 / 6.43 req/s,输出吞吐约为 93.89 / 104.80 / 205.89 tok/s。
需要说明的是: 当前启动参数中使用了 --disable-cuda-graph。原因是在autodl租用云环境下,开启 graph capture 后服务会在 graph runner 初始化阶段失败,因此本文所有数据应理解为 graph-off 条件下的基线值。
一、测试对象与环境说明
本次租用云环境未直接使用容器拉起服务,实际评测链路是在宿主环境按等价组件完成部署与启动。官方文档已给出 Ascend NPU 对应镜像/tag 与组件版本映射,如有条件使用docker可参考官方文档。
| 字段 | 说明 |
|---|---|
| 模型名称 | Qwen/Qwen3-0.6B |
| 模型架构 | Qwen3ForCausalLM |
| 模型类型 | qwen3 |
| 模型识别 | model_path=Qwen/Qwen3-0.6B;tokenizer_path=Qwen/Qwen3-0.6B |
| 宿主机资源 | 4 ×Atlas 800I A2,单卡 64GB高速片上内存 |
| 本文实例口径 | 单卡实例,服务日志显示 tp_size=1 |
| 服务最大上下文 | context_len = 40960 |
| 代码目录 | /data/sglang |
| SGLang 版本 | 7603b226c |
| 操作系统 | Linux 5.15.0-113-generic |
| Python 版本 | 3.11.6 |
本次采用的最终启动参数如下。这组参数首先服务于"稳定启动、可重复压测"的目标,而不是一开始就追求极限吞吐。
bash
--device npu
--attention-backend ascend
--host 127.0.0.1
--port 8188
--mem-fraction-static 0.4
--chunked-prefill-size 4096
--disable-cuda-graph二、部署与启动
2.1 官方 Docker 镜像与本文落地方式
根据 SGLang 的 Ascend NPU 安装文档, Atlas 800I A2 对应的官方镜像 tag 可以按 v0.5.6-cann8.5.0-910b 的形式获取。本文实际云环境未直接采用容器拉起服务,因此后文以宿主环境中的等价部署过程为准。
bash
docker pull docker.io/lmsysorg/sglang:v0.5.6-cann8.5.0-910b2.2 SSH 登录与远端环境检查
首先进行SSH 登录。进入远端 shell 后,后续命令均默认在服务器侧连续执行。
bash
ssh -p 32222 root+vm-5PTbsRmbvxgp2C8w@106.75.235.239
python3 --version
npu-smi info
cd /data/sglang && git rev-parse --short HEAD2.3 服务启动前的必要准备
在当前租用环境中,直接拉起服务并不能成功。最终跑通链路前,需要完成四类准备:补齐 sgl_kernel_npu、切换到 headless OpenCV、统一 Triton/Triton-Ascend 版本,以及补充 torch_npu/torch 的动态库路径。下面保留最终生效的必要命令;更细的排查过程见附录 C。
bash
# 1) 安装 sgl_kernel_npu
python3 -m pip install pybind11
python3 -m pip install /tmp/sgl-kernel-npu/sgl_kernel_npu-2026.3.1-cp311-cp311-linux_x86_64.whl
# 2) 修复 OpenCV / libGL 冲突
python3 -m pip uninstall -y opencv-python
python3 -m pip install --force-reinstall opencv-python-headless==4.11.0.86
python3 -m pip install --force-reinstall --no-deps numpy==1.26.4
# 3) 统一 Triton / Triton-Ascend 版本
python3 -m pip uninstall -y triton triton-ascend
python3 -m pip install --no-deps --force-reinstall "triton==3.2.0"
python3 -m pip install --no-deps --force-reinstall "triton-ascend==3.2.0"
# 4) 运行时环境
source /usr/local/Ascend/ascend-toolkit/latest/set_env.sh
export LD_LIBRARY_PATH=/usr/local/lib64/python3.11/site-packages/torch_npu/lib:/usr/local/lib64/python3.11/site-packages/torch/lib:$LD_LIBRARY_PATH
export PYTHONPATH=/data/sglang/python:$PYTHONPATH2.4 SGLang 服务启动
完成上述准备后,再写入启动脚本并以最终参数拉起服务。这里为最小可复现版本。
bash
cat >/tmp/start_sglang_8188.py <<'PY'
import runpy
import sys
import torch
sys.path.insert(0, "/data/sglang/python")
lib = torch.library.Library("torchvision", "DEF")
lib.define("nms(Tensor dets, Tensor scores, float iou_threshold) -> Tensor")
sys.argv = [
"sglang.launch_server",
"--model-path", "Qwen/Qwen3-0.6B",
"--device", "npu",
"--attention-backend", "ascend",
"--trust-remote-code",
"--host", "127.0.0.1",
"--port", "8188",
"--mem-fraction-static", "0.4",
"--chunked-prefill-size", "4096",
"--disable-cuda-graph",
]
runpy.run_module("sglang.launch_server", run_name="__main__")
PY
nohup bash -lc '
source /usr/local/Ascend/ascend-toolkit/latest/set_env.sh
export LD_LIBRARY_PATH=/usr/local/lib64/python3.11/site-packages/torch_npu/lib:/usr/local/lib64/python3.11/site-packages/torch/lib:$LD_LIBRARY_PATH
export SGLANG_USE_MODELSCOPE=1
export SGLANG_SET_CPU_AFFINITY=1
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export STREAMS_PER_DEVICE=32
export PYTHONPATH=/data/sglang/python:$PYTHONPATH
python3 /tmp/start_sglang_8188.py
' >/tmp/sglang8188.log 2>&1 &2.5 接口验证与模型确认
服务拉起后,不是直接进入压测,而是先确认服务已经进入可请求状态,模型标识与类型识别正确。
bash
curl -sS http://127.0.0.1:8188/health
curl -sS http://127.0.0.1:8188/v1/models
curl -sS http://127.0.0.1:8188/model_info
curl -sS -X POST http://127.0.0.1:8188/generate -H 'Content-Type: application/json' -d '{"text":"你好,请只回复一个词:测试","sampling_params":{"temperature":0,"max_new_tokens":8},"stream":false}'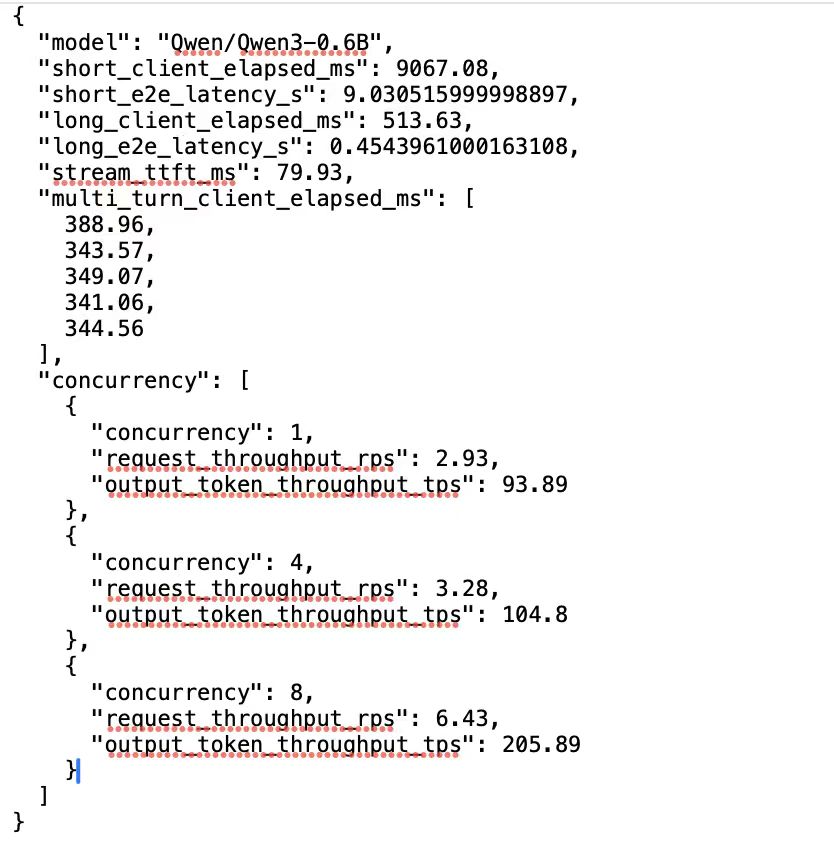
图 2 服务启动后日志片段与请求处理记录
三、SGLang 这一阶段的性能重点
从官方文档和 v0.5.6 release highlights 看,SGLang 在这一阶段重点强调的不是单一模型适配,而是高性能 serving runtime:包括连续批处理、前缀缓存、chunked prefill、并行扩展,以及围绕 JIT Kernels、内存管理与调度兼容性的多项性能优化。结合当前数据,本文只抓住最容易形成闭环的两个点进行重点评测:流式响应体验和并发扩展性。
| 官方能力方向 | 与本文的关系 |
|---|---|
| 低时延流式返回 | 对应 TTFT 与流式总响应时间 |
| continuous batching / 调度扩展 | 对应 1 / 4 / 8 并发吞吐变化 |
| chunked prefill | 作为当前启动参数的一部分,影响长上下文行为 |
| CUDA graph / 内存优化 | 当前环境未跑通,因此本文结果为 graph-off 基线 |
四、测试方法
这里我们运行 benchmark脚本(详见附录)。
bash
python3 benchmark_sglang.py --base-url http://127.0.0.1:8188 --model Qwen/Qwen3-0.6B --concurrency 1,4,8 --out benchmark_results.json| 指标 | 含义 |
|---|---|
| TTFT | 流式请求从发出到首个片段返回的时间 |
| Client Elapsed | 客户端看到的总耗时 |
| e2e_latency | 服务端记录的端到端推理耗时 |
| Request Throughput | 单位时间完成的请求数 |
| Output Token Throughput | 单位时间生成的输出 token 数 |
4.1 基础正确性验证
我们首先验证基础链路是否正确:服务是否识别到正确模型、接口是否正常返回、基础生成与多轮对话是否能够持续跑通。
| 验证项 | 结果 |
|---|---|
| 模型识别 | /model_info 返回 model_path 与 tokenizer_path 均为 Qwen/Qwen3-0.6B |
| 模型类型 | model_type=qwen3,architectures="Qwen3ForCausalLM" |
| 接口返回 | /health、/v1/models、/model_info、/generate 均返回成功 |
| 多轮链路 | /v1/chat/completions 连续五轮均能返回结果 |
4.2 重点特性一:流式响应体验
对推理服务而言,用户最直接感受到的不是离线 batch 的总时长,而是请求发出后多久能看到第一个可读片段。因此,本文把流式 TTFT 作为第一个重点特性来观察。
| 场景 | 结果 |
|---|---|
| 流式首 Token 延迟(TTFT) | 79.93 ms |
| 流式总响应时间 | 344.18 ms |
图 3 benchmark_results.json 摘要截图
从最终结果看,流式 TTFT 约为 79.93 ms,总响应时间约为 344.18 ms。对于 0.6B 规模模型和当前 graph-off 口径而言,这说明服务在用户可感知的首响应阶段已经具备较好的交互体验。
4.2 重点特性二:并发扩展性
SGLang 这一阶段的另一个公开性能重点,是在 serving runtime 中提升吞吐并保持较低调度开销。结合当前数据,最适合观察的就是 1、4、8 并发下的扩展性变化。
| 并发数 | 请求数 | 总耗时 | 平均耗时 | P95 | 请求吞吐 | 输出吞吐 |
|---|---|---|---|---|---|---|
| 1 | 8 | 2726.54 ms | 340.73 ms | 352.57 ms | 2.93 req/s | 93.89 tok/s |
| 4 | 8 | 2442.64 ms | 1220.75 ms | 1227.28 ms | 3.28 req/s | 104.80 tok/s |
| 8 | 8 | 1243.39 ms | 1233.78 ms | 1242.84 ms | 6.43 req/s | 205.89 tok/s |
从 1 并发到 8 并发,请求吞吐从 2.93 req/s 提升到 6.43 req/s,输出吞吐从 93.89 tok/s 提升到 205.89 tok/s;与此同时,单请求平均时延也从约 340.73 ms 上升到约 1233.78 ms。
这说明当前版本的并发扩展并非"免费提速":吞吐随着并发提升而增长,但时延也同步抬高。这组数据更适合理解为当前 graph-off、单卡实例下的服务基线,而不是峰值上限。
4.4 补充观察
冷启动现象:短文本首轮请求的客户端总耗时约为 9.07 s,明显高于后续大多数请求。结合服务日志,这更像是首轮请求承担了冷启动或首次请求额外开销,而不是短文本本身更慢。
长上下文现象:本轮长上下文测试的 prompt_tokens 约为 7210,客户端总耗时约为 513.63 ms。由于首轮短请求出现明显冷启动,长上下文结果不宜直接理解为"长文本比短文本更快",更合理的解释是两者承担了不同的启动阶段开销。
多轮对话现象:五轮对话请求分别约为 388.96、343.57、349.07、341.06、344.56 ms,整体落在 341--389 ms 区间,说明在当前测试口径下,多轮消息累积并没有带来特别剧烈的时延波动。
graph 关闭的影响:由于当前环境开启 graph capture 时会在 graph runner 初始化阶段失败,本文所有结果均应理解为 graph-off 基线值。后续如果 graph 问题得到修复,首轮时延、并发吞吐和可用显存分配都可能发生变化。
五、小结
把这次实测验证了大模型的推理能力和服务在昇腾 Atlas 800I A2 单卡实例上,能形成一条有效的启动、验证与压测链路。
| 结论项 | 结论 |
|---|---|
| 服务可用性 | SGLang 已能在当前Atlas 800I A2 单卡实例上成功启动,对外提供 /v1/models、/model_info、/generate 和 /v1/chat/completions 接口。 |
| 流式体验 | TTFT 约 79.93 ms,总流式响应时间约 344.18 ms,首响应体验较好。 |
| 并发扩展性 | 1/4/8 并发下请求吞吐约为 2.93 / 3.28 / 6.43 req/s;输出吞吐约为 93.89 / 104.80 / 205.89 tok/s。 |
| 结果边界 | 当前结果为 graph-off 基线值,可作为后续继续优化时的参考,而非最终上限。 |
其中,关于--disable-cuda-graph 参数原因为:开启 graph capture 时,服务会报出 "0 active drivers (\[\])" 的错误,无法进入可请求状态;关闭后,服务能够正常完成权重加载、KV Cache 分配并对外提供接口。因此本文结果只能定义为 graph-off 基线值。
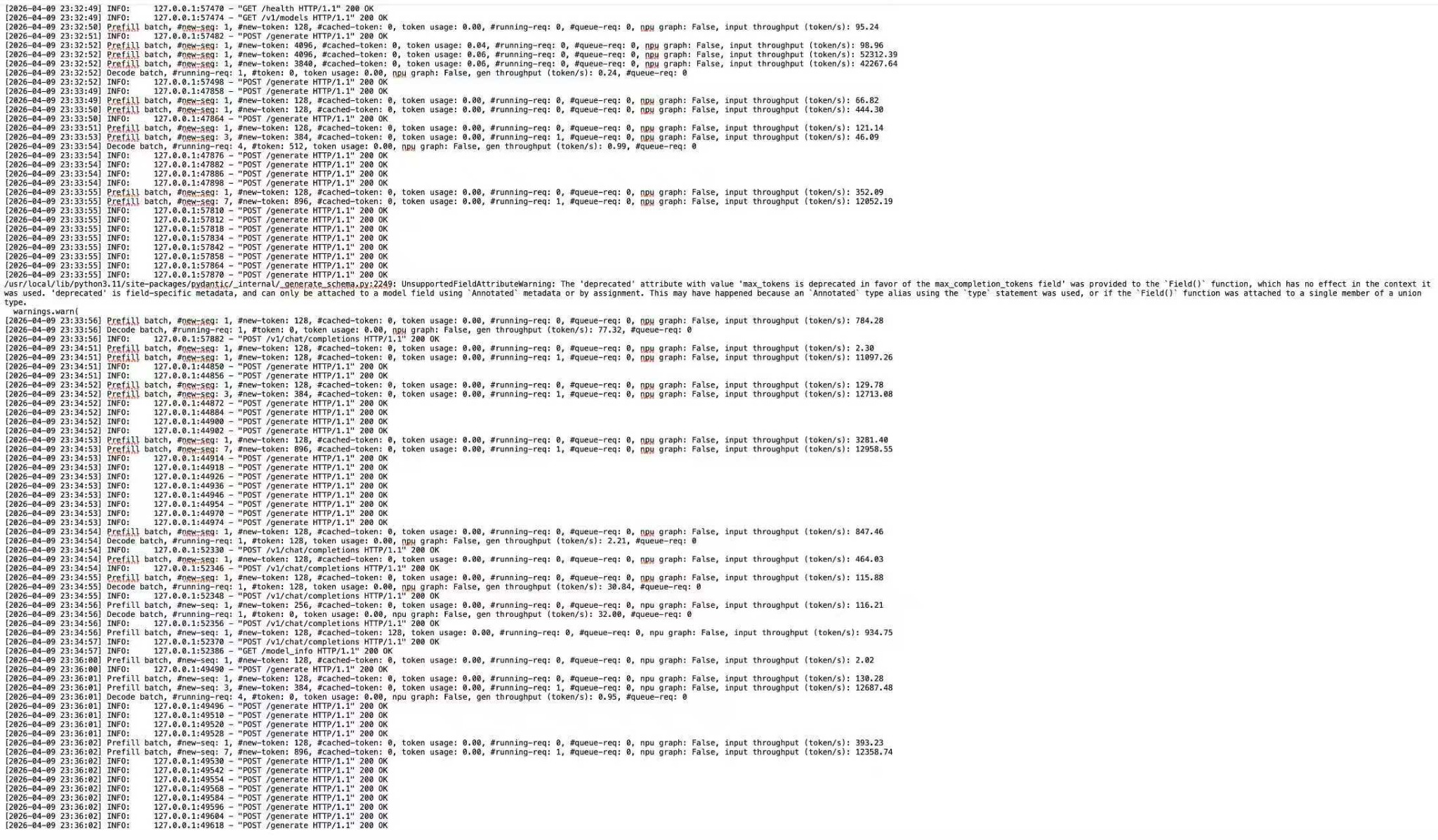
图 1 开启 graph capture 时的初始化失败截图
附录 A:统一 benchmark 入口
正文使用的 benchmark 统一入口如下。
bash
python3 benchmark_sglang.py --base-url http://127.0.0.1:8188 --model Qwen/Qwen3-0.6B --concurrency 1,4,8 --out benchmark_results.json| 输出字段 | 说明 |
|---|---|
| short_request | 短文本请求结果 |
| long_context_request | 长上下文请求结果 |
| stream_ttft | 流式 TTFT 与总耗时 |
| multi_turn | 多轮对话结果 |
| concurrency | 1 / 4 / 8 并发结果 |
附录 B:完整启动脚本
python
import runpy
import sys
import torch
sys.path.insert(0, "/data/sglang/python")
lib = torch.library.Library("torchvision", "DEF")
lib.define("nms(Tensor dets, Tensor scores, float iou_threshold) -> Tensor")
sys.argv = [
"sglang.launch_server",
"--model-path", "Qwen/Qwen3-0.6B",
"--device", "npu",
"--attention-backend", "ascend",
"--trust-remote-code",
"--host", "127.0.0.1",
"--port", "8188",
"--mem-fraction-static", "0.4",
"--chunked-prefill-size", "4096",
"--disable-cuda-graph",
]
runpy.run_module("sglang.launch_server", run_name="__main__")附录 C:兼容性问题与排查记录
这一部分保留更完整的兼容性修复方向,供同类环境落地时参考。
bash
# sgl_kernel_npu 安装包准备
python3 -m pip install pybind11
python3 -m pip install /tmp/sgl-kernel-npu/sgl_kernel_npu-2026.3.1-cp311-cp311-linux_x86_64.whl
# OpenCV / libGL
python3 -m pip uninstall -y opencv-python
python3 -m pip install --force-reinstall opencv-python-headless==4.11.0.86
python3 -m pip install --force-reinstall --no-deps numpy==1.26.4
# Triton / Triton-Ascend
python3 -m pip uninstall -y triton triton-ascend
python3 -m pip install --no-deps --force-reinstall "triton==3.2.0"
python3 -m pip install --no-deps --force-reinstall "triton-ascend==3.2.0"
rm -rf /usr/local/lib64/python3.11/site-packages/triton/backends/amd
rm -rf /usr/local/lib64/python3.11/site-packages/triton/backends/nvidia
# 动态库路径
source /usr/local/Ascend/ascend-toolkit/latest/set_env.sh
export LD_LIBRARY_PATH=/usr/local/lib64/python3.11/site-packages/torch_npu/lib:/usr/local/lib64/python3.11/site-packages/torch/lib:$LD_LIBRARY_PATH附录 D:Docker 参考路径与镜像说明
官方文档已给出 Ascend NPU 对应的镜像/tag 与组件版本映射。对 Atlas 800I A2 来说,可以使用 v0.5.6-cann8.5.0-910b 这一类 tag 作为参考。本文实际环境没有直接用容器拉起服务,因此正文结果仍以后续宿主环境落地为准。
bash
# Atlas 800I A2 对应镜像 tag 参考
docker pull docker.io/lmsysorg/sglang:v0.5.6-cann8.5.0-910b
# 参考启动形式
docker run --privileged --network=host --ipc=host --shm-size=16g --device=/dev/davinci0 --device=/dev/davinci_manager --device=/dev/hisi_hdc -v ~/.cache:/root/.cache docker.io/lmsysorg/sglang:v0.5.6-cann8.5.0-910b python3 -m sglang.launch_server --model-path Qwen/Qwen3-0.6B --attention-backend ascend附录 E:benchmark_sglang.py文件内容
benchmark_sglang.py完整脚本如下:
python
#!/usr/bin/env python3
import argparse
import concurrent.futures
import json
import statistics
import time
import urllib.request
def post_json(url: str, payload: dict, timeout: int = 120) -> dict:
req = urllib.request.Request(
url,
data=json.dumps(payload).encode("utf-8"),
headers={"Content-Type": "application/json"},
)
with urllib.request.urlopen(req, timeout=timeout) as resp:
body = resp.read().decode("utf-8", "ignore")
return json.loads(body)
def run_short(base_url: str) -> dict:
payload = {
"text": "请用中文简要介绍一下昇腾 NPU 在大模型推理中的作用。",
"sampling_params": {"temperature": 0, "max_new_tokens": 32},
"stream": False,
}
start = time.perf_counter()
data = post_json(f"{base_url}/generate", payload, timeout=120)
elapsed = time.perf_counter() - start
return {
"client_elapsed_s": elapsed,
"response": data,
"request": payload,
}
def run_long(base_url: str) -> dict:
context = "昇腾平台支持高性能推理与训练。" * 900
payload = {
"text": "请阅读下面的上下文并总结要点:\n" + context,
"sampling_params": {"temperature": 0, "max_new_tokens": 32},
"stream": False,
}
start = time.perf_counter()
data = post_json(f"{base_url}/generate", payload, timeout=180)
elapsed = time.perf_counter() - start
return {
"client_elapsed_s": elapsed,
"response": data,
"request": payload,
}
def run_stream(base_url: str) -> dict:
payload = {
"text": "请用中文简要介绍一下昇腾 NPU 在大模型推理中的作用。",
"sampling_params": {"temperature": 0, "max_new_tokens": 32},
"stream": True,
}
req = urllib.request.Request(
f"{base_url}/generate",
data=json.dumps(payload).encode("utf-8"),
headers={"Content-Type": "application/json"},
)
start = time.perf_counter()
first = None
raw_lines = []
with urllib.request.urlopen(req, timeout=120) as resp:
for raw in resp:
line = raw.decode("utf-8", "ignore").strip()
if not line:
continue
raw_lines.append(line)
if first is None:
first = time.perf_counter()
end = time.perf_counter()
return {
"request": payload,
"ttft_s": None if first is None else first - start,
"client_total_s": end - start,
"raw_body_preview": "\n\n".join(raw_lines[:10]),
}
def run_multi_turn(base_url: str, model: str) -> list:
prompts = [
"请介绍一下 SGLang。",
"它在推理场景里解决了什么问题?",
"如果部署在昇腾 NPU,上线前应该关注哪些指标?",
"继续补充吞吐和时延指标的区别。",
"最后用三条建议总结性能测试的注意事项。",
]
messages = [{"role": "user", "content": prompts[0]}]
results = []
for prompt in prompts:
messages.append({"role": "user", "content": prompt})
payload = {
"model": model,
"messages": messages,
"temperature": 0,
"max_tokens": 32,
"stream": False,
}
start = time.perf_counter()
data = post_json(f"{base_url}/v1/chat/completions", payload, timeout=120)
elapsed = time.perf_counter() - start
results.append({
"client_elapsed_s": elapsed,
"response": data,
"request": payload,
})
messages.append(data["choices"][0]["message"])
return results
def run_concurrency(base_url: str, levels: list[int]) -> dict:
def one(i: int):
payload = {
"text": f"请概括 SGLang 的推理特点。样本 {i}",
"sampling_params": {"temperature": 0, "max_new_tokens": 32},
"stream": False,
}
start = time.perf_counter()
data = post_json(f"{base_url}/generate", payload, timeout=120)
elapsed = time.perf_counter() - start
meta = data.get("meta_info", {})
return {
"ok": True,
"client_elapsed_s": elapsed,
"e2e_latency_s": meta.get("e2e_latency"),
"completion_tokens": meta.get("completion_tokens", 0),
"id": i,
}
summary = {"levels": []}
for level in levels:
request_count = 8
wall_start = time.perf_counter()
with concurrent.futures.ThreadPoolExecutor(max_workers=level) as ex:
results = list(ex.map(one, range(request_count)))
wall = time.perf_counter() - wall_start
output_tokens = sum(item["completion_tokens"] for item in results)
lats = [item["client_elapsed_s"] for item in results]
summary["levels"].append({
"concurrency": level,
"requests": request_count,
"wall_time_s": wall,
"request_throughput_rps": request_count / wall,
"output_token_throughput_tps": output_tokens / wall,
"results": results,
"avg_client_elapsed_s": statistics.mean(lats),
"p95_client_elapsed_s": max(lats),
})
return summary
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--base-url", default="http://127.0.0.1:8188")
parser.add_argument("--model", default="Qwen/Qwen3-0.6B")
parser.add_argument("--out", default="benchmark_results.json")
parser.add_argument("--concurrency", default="1,4,8")
args = parser.parse_args()
levels = [int(x) for x in args.concurrency.split(",") if x.strip()]
result = {
"base_url": args.base_url,
"model": args.model,
"short_request": run_short(args.base_url),
"long_context_request": run_long(args.base_url),
"stream_ttft": run_stream(args.base_url),
"multi_turn": run_multi_turn(args.base_url, args.model),
"concurrency": run_concurrency(args.base_url, levels),
"generated_at": time.strftime("%Y-%m-%d %H:%M:%S"),
}
with open(args.out, "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print(f"saved to {args.out}")
if __name__ == "__main__":
main()hello,这里是 晓雨的笔记本。如果你喜欢我的文章,欢迎三连给我鼓励和支持:👍点赞 📁 关注 💬评论,我会给大家带来更多有用有趣的文章。
原文链接 👉 ,⚡️更新更及时。
欢迎大家点开下面名片,添加好友交流。