前言
YOLO 系列是目标检测领域非常经典的一条路线,而 YOLOv1 更是整个系列的起点。
如果说 R-CNN 系列代表的是"先找框,再分类"的两阶段思路,那么 YOLOv1 则直接把目标检测变成了一个回归问题,输入整张图片,直接输出目标的位置和类别。
本文结合 YOLOv1 原论文 You Only Look Once: Unified, Real-Time Object Detection 和学习笔记,对 YOLOv1 的核心思想、网络结构、损失函数和优缺点做一次系统梳理。
1. YOLOv1 想解决什么问题
在 YOLO 出现之前,目标检测领域的主流方法是 R-CNN 系列为代表的两阶段(two-stage)方法。这类方法的基本流程是:
-
第一步:在图像上生成候选框(region proposals)
-
第二步:对每个候选框做分类和位置回归
这种方法虽然准确率较高,但存在明显的痛点:速度慢、流程复杂、难以端到端优化。

举一个直观的例子:R-CNN 需要提取约 1000 个候选区域,每个区域单独通过卷积网络进行分类,整个过程就像批改试卷时先圈出重点,再逐一仔细审阅,精度虽高但效率自然上不去。
YOLOv1 的提出者 Joseph Redmon 等人换了一个全新的视角:
把目标检测看成一个回归问题,直接从图像像素回归出边界框坐标和类别概率。
这意味着整个检测过程只需要一次前向传播,所以速度非常快。
2. YOLOv1 的核心思想
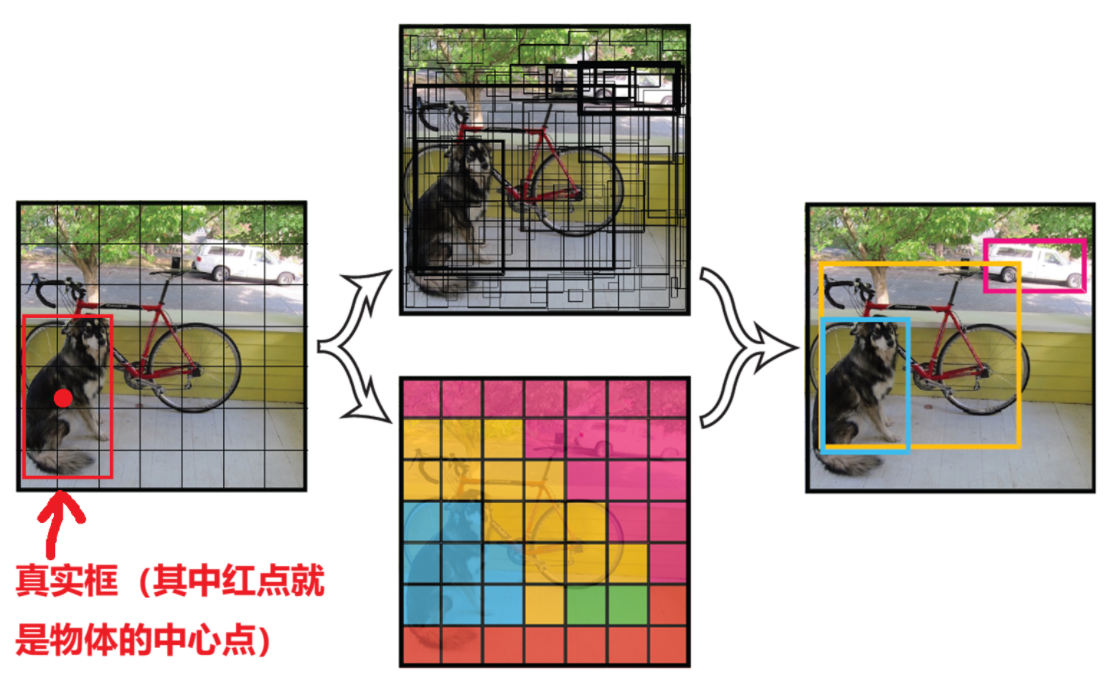
YOLOv1 的核心设计可以用一句话概括:一张图 = S×S 个网格 + B 个边界框 + C 个类别概率。
具体来说,算法步骤大致如下:
-
划分网格:将输入图像划分为 S×S 个网格(论文中常用 S=7)。
-
网格负责制:如果某个目标的中心点落在某个网格内,那么这个网格就负责预测该目标。
-
每个网格的输出:
-
预测 B 个边界框(论文中 B=2)
-
每个边界框包含 5 个参数 :
(x, y, w, h, confidence) -
同时预测 C 个类别概率(PASCAL VOC 数据集上 C=20)
-
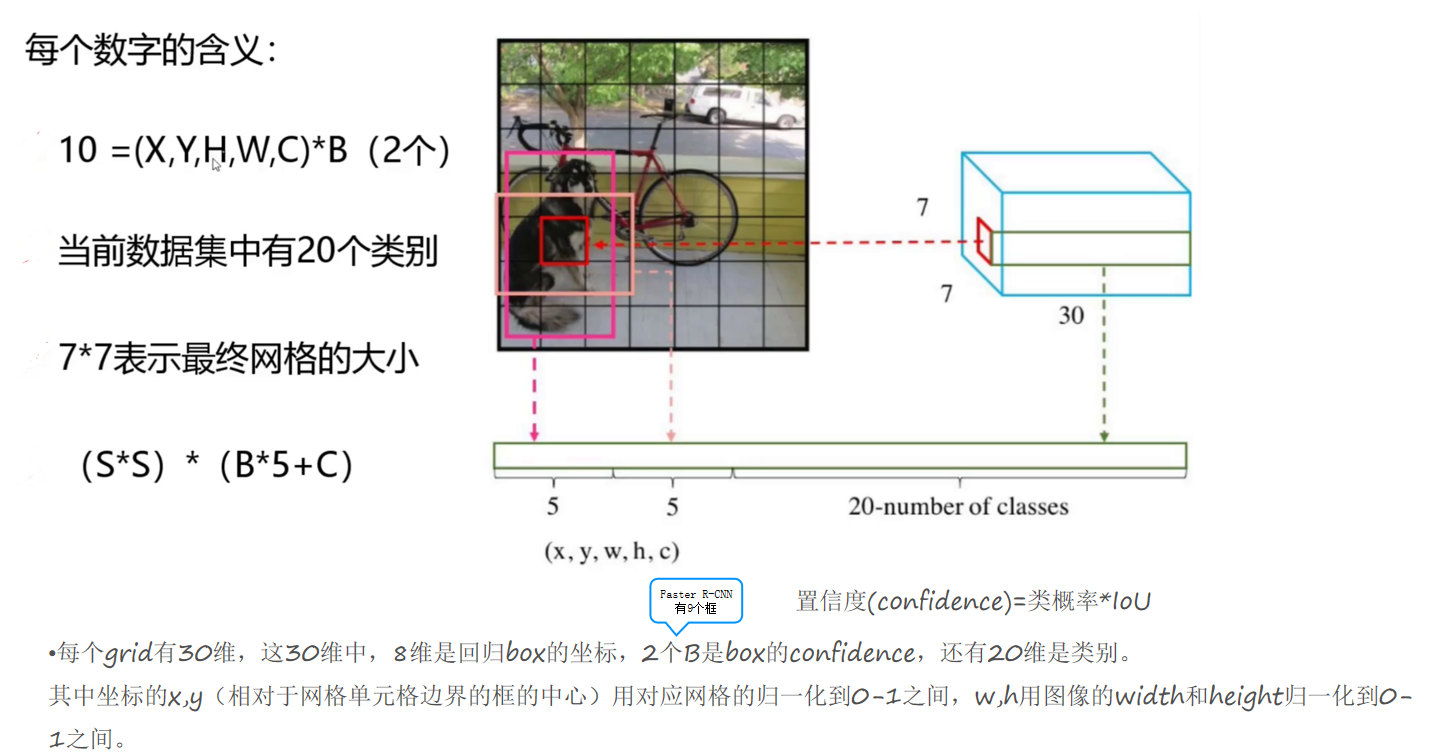
因此,最终输出的张量维度为:
S × S × (B × 5 + C)
在经典的 PASCAL VOC 配置下,输出维度就是:
7 × 7 × (2×5 + 20) = 7 × 7 × 30
这也就是我们经常听到的 7×7×30 的由来。
3. 边界框和置信度怎么理解
边界框的参数(x, y, w, h)
每个边界框包含 4 个坐标参数:
-
(x, y) : 边界框的中心坐标,是相对于当前网格左上角的偏移量(取值范围在 0~1 之间)。
-
(w, h) : 边界框的宽度和高度,是相对于整个图像尺寸的比例(取值范围也在 0~1 之间)。
这种归一化设计的好处是:无论输入图像尺寸如何变化,边界框的数值都能保持在一个稳定的范围内,利于模型训练。
置信度 confidence
置信度的计算公式为:
confidence = Pr(Object) × IOU(pred, truth)
其中:
-
Pr(Object) : 表示当前边界框内是否含有物体。含有物体则为 1,否则为 0。
-
IOU(pred, truth) : 预测框与真实框(ground truth)的交并比,衡量预测框位置的准确程度。
这个定义的两层含义很巧妙:
-
如果框里没有物体,置信度应接近 0(因为 Pr(Object)=0)
-
如果框里有物体且预测得很准,置信度就会接近 1(因为 Pr(Object)=1,且 IOU 接近 1)
IOU图解如下:

类别概率
类别概率定义为:
Pr(Class_i | Object)
表示在框内有物体的前提下,该物体属于第 i 类的概率。
在测试时,最终用于评估的类别得分通常可以理解为:
Pr(Class_i | Object) × confidence
这个乘积结合了"框内是否有物体""框得有多准""类别是否正确"三重信息,是一个全面的评分。
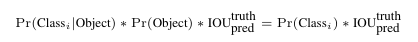
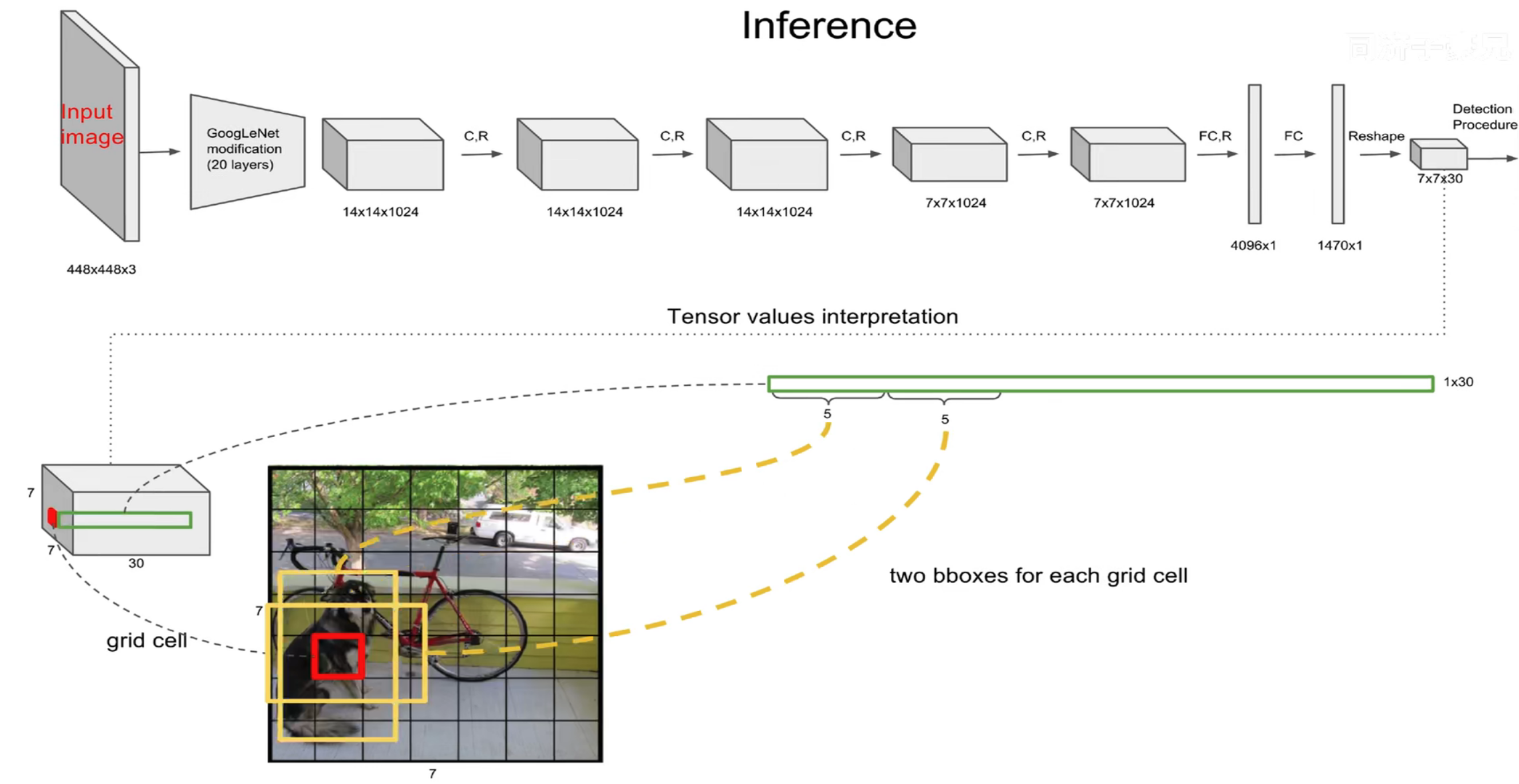
4. YOLOv1 的网络结构
YOLOv1 的网络结构深受 GoogLeNet 启发,但做了一些简化:没有使用复杂的 Inception 模块,而是采用 1×1 卷积加 3×3 卷积的简洁组合。其中 1×1 卷积主要用于跨通道的信息整合和通道降维。
完整结构如下:
| 组成部分 | 具体说明 |
|---|---|
| 输入尺寸 | 448 × 448 × 3 的彩色图片 |
| 卷积层 | 24 个卷积层(前 20 层是骨干网络 Backbone) |
| 全连接层 | 2 个全连接层 |
| 输出尺寸 | 7 × 7 × 30 的特征图 |
网络中交替使用卷积层和最大池化层进行下采样,逐步提取图像的抽象特征。
值得一提的是,YOLOv1 还有一个轻量版本 Fast YOLO。它通过减少卷积层数量来换取更快的推理速度,当然是以牺牲部分精度为代价的------这为目标检测的应用场景(如实时边缘部署)提供了更多灵活性。
5. YOLOv1 的训练方式
YOLOv1 的训练过程分为两个阶段:
第一阶段:分类预训练
先在 ImageNet 1000 类分类数据集 上对网络的前 20 个卷积层进行预训练。预训练时的输入尺寸为 224×224,这是当时 ImageNet 分类任务的通行做法。
第二阶段:检测微调
随后,在预训练模型的基础上,添加剩余的 4 个卷积层和 2 个全连接层,构成完整的 24 个卷积层检测网络。接着,在 PASCAL VOC 2007 和 2012 数据集 上进行目标检测任务的微调。此时输入图像尺寸会从 224×224 调整为 448×448,以便于检测更细小的目标。
训练中的关键技巧
-
激活函数:使用 Leaky ReLU 替代标准 ReLU,避免神经元死亡问题。
-
防止过拟合:
-
Dropout:在全连接层加入 Dropout,随机丢弃部分神经元。
-
数据增强:采用随机缩放(最大为原图 20%)、平移、翻转等数据增强策略,人工扩充训练样本,提升模型的泛化能力。
-
-
学习率策略:采用逐步调整的学习率方案,避免训练初期参数更新过于剧烈导致不稳定。
6. YOLOv1 的损失函数
YOLOv1 的损失函数设计是一个重点,也是一个难点。作者全部采用了平方和误差(sum-squared error),因为它易于优化。
整体损失函数由三部分构成:
-
坐标损失
-
置信度损失
-
分类损失
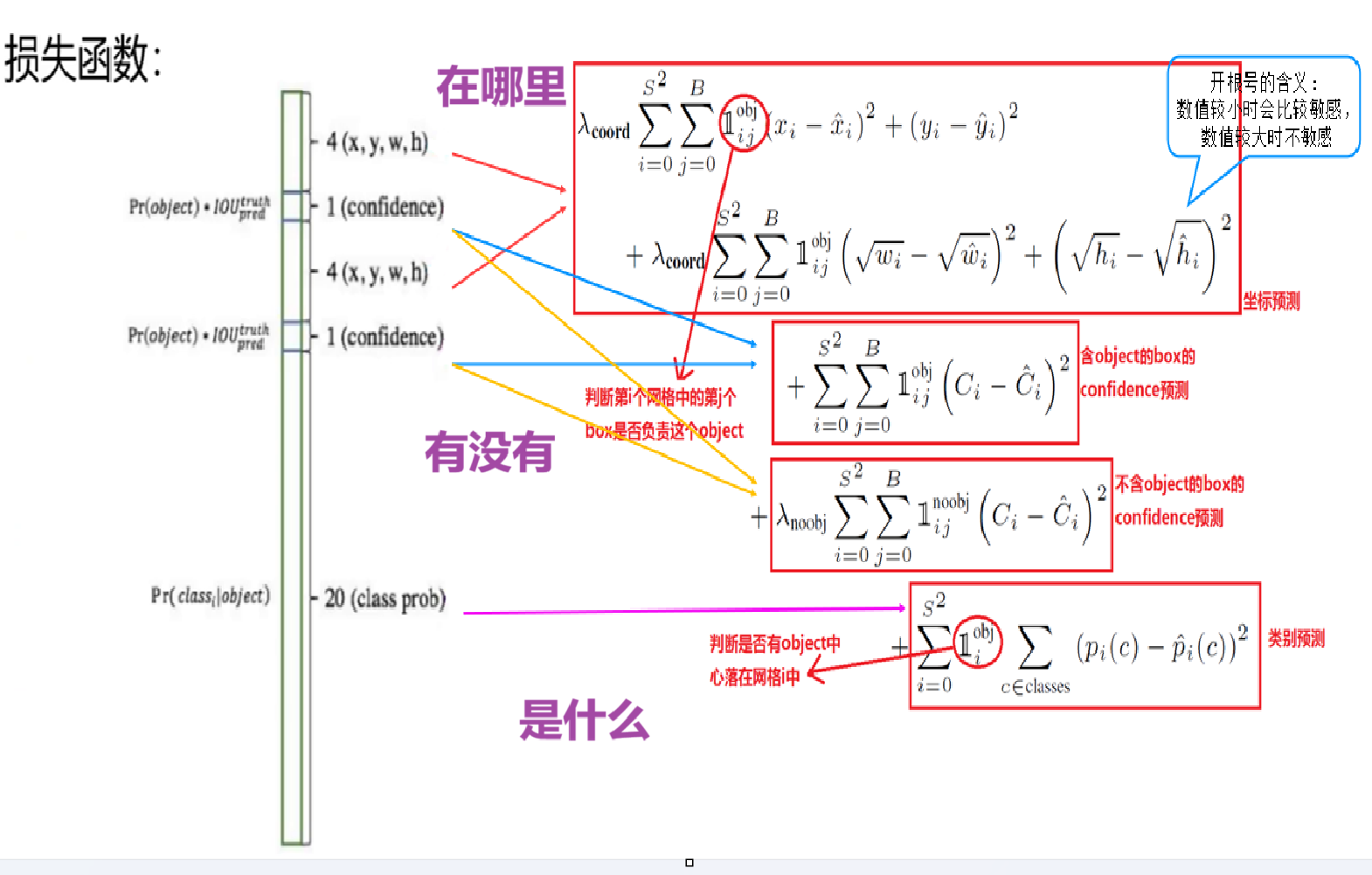
为什么需要加权?
平方和误差对所有部分的权重是等价的,但这显然不合理:
-
一张图像中大部分网格是背景区域(没有物体)
-
这些背景网格的 confidence 应该趋近于 0
-
如果坐标损失和背景置信度损失的权重相同,模型会被大量的背景样本带偏,而忽略了对真正重要的物体预测的学习
因此,作者对不同部分设置了不同的权重:
| 损失项 | 权重系数 | 说明 |
|---|---|---|
| 坐标损失(有物体的格子) | λ_coord = 5 | 强化位置回归的重要性 |
| 无物体置信度损失 | λ_noobj = 0.5 | 减少大量背景干扰 |
| 有物体置信度损失 | 1 | 正常权重 |
| 分类损失 | 1 | 正常权重 |
为什么对 w 和 h 开平方根?
在计算坐标损失时,对宽度 w 和高度 h 进行了开方处理。原因在于:大框和小框在误差尺度上天然不同。
举个例子:预测大框时,偏移 10 像素可能影响不大;但预测小框时,同样偏移 10 像素可能导致严重的定位错误。通过开方,可以让小框误差获得更大的惩罚权重,一定程度上缓解了大框与小框之间的权重不均问题。
7. 推理阶段和 NMS
YOLOv1 在推理时只需一次网络前向传播即可得到检测结果,速度快是它的核心优势之一。
由于 YOLOv1 的输出张量中存在 7×7×2=98 个边界框 (每个格子预测 2 个框),多个网格或多个边界框可能会重复检测到同一个目标,导致大量的冗余框。
为了解决这个问题,YOLOv1 在后处理阶段使用了 NMS(非极大值抑制)。NMS 的核心流程是:
-
对所有边界框按置信度得分降序排列。
-
选取当前最高得分的框,抑制掉与其IoU 重叠度大于设定阈值的其他同类框。
-
重复上述步骤,直到所有框都被处理完毕。
NMS 只在预测阶段使用,训练阶段不需要。这样可以显著减少重复检测,提升最终输出结果的整洁度和准确性。
8. YOLOv1 的优点
YOLOv1 的出现为目标检测领域带来了革命性的变化,其主要优势体现在以下几个方面:
-
⚡ 速度极快 :在 Titan X GPU 上,标准版本可达到 45 帧/秒(fps) ,轻量版本 Fast YOLO 更是高达 155 帧/秒,真正实现了实时目标检测。
-
🤝 端到端训练:将目标检测整体建模为回归问题,统一了整个流程,不需要复杂的区域提议和繁琐的流水线设计。
-
🌍 能利用全局上下文信息 :与基于滑动窗口或区域提案的方法只能看到图像局部不同,YOLO 在预测时使用了整张图的全局信息,因此在判断背景区域时更有依据。
-
🎯 结构相对简单:网络结构清晰,容易理解和实现。
-
🚫 背景误检较少:因其利用了全图信息,模型对背景区域的学习效果往往优于仅看局部区域的两阶段方法。
9. YOLOv1 的缺点
尽管 YOLOv1 意义重大,但作为开山之作,它也存在明显的局限性:
| 缺点 | 具体表现 |
|---|---|
| 小目标检测效果差 | 7×7 的网格对于密集分布的小物体来说过于粗糙,尤其是那些只占图像很小区域的物体常常被忽略 |
| 密集目标容易漏检 | 每个网格只能预测一个物体(即只能输出一个类别),当多个物体的中心落在同一个网格内时,模型就会顾此失彼 |
| 定位精度有限 | 对不常见的长宽比和形状泛化能力较弱,定位误差相对较大 |
| 框数量受限 | 每个网格只预测 B=2 个边界框,这个限制在目标密集的场景下会成为明显的性能瓶颈 |
正因为存在这些不足,后续的 YOLOv2、YOLOv3 等版本才不断在架构设计、损失函数、训练策略等方面进行改进,逐步攻克了这些痛点。
10. 总结
YOLOv1 的意义绝不只是"快"这么简单。它更重要的是提出了一种全新的目标检测范式:
目标检测不一定非要先提候选框,也可以直接把整张图映射到检测结果。
正是这个看似大胆的想法,开启了单阶段(one-stage)目标检测算法的新纪元。从技术深度来看,YOLOv1 对输入到输出的整个映射关系做了非常紧凑的数学表达------用一个 7×7×30 的张量实现了对空间位置、尺度、类别信息的统一编码,这在当时堪称巧妙的建模创新。
如果你刚开始学习 YOLO 系列,YOLOv1 是最值得先读懂的一篇论文。理解了它的设计思想和演进逻辑,后续 YOLOv2、YOLOv3 等一系列改进版本,就都是在它的基础上一步步演化出来的。
学习计算机视觉算法时,研读经典论文往往是最好的起点------它不仅告诉你 YOLO 是什么,更让你看懂了一个想法从"打破常规"到"引领潮流"的完整轨迹。
📚 参考资料
-
YOLOv1 原论文:You Only Look Once: Unified, Real-Time Object Detection(CVPR 2016)
-
arXiv 链接:https://arxiv.org/abs/1506.02640
-
官方代码(Darknet):https://github.com/pjreddie/darknet
希望这篇文章能帮助大家系统地理解 YOLOv1 的核心思想与技术细节。如果觉得有帮助,欢迎点赞、收藏、转发支持!