一、哈希表概述
(一)哈希表查找定义
当我们使用线性表进行查找时,需要进行一系列和关键字的比较,查找的效率依赖于查找过程中所进行的次数。那我们可不可以避免这种"比较"的过程,直接通过关键字进行查找呢?
希望不经过任何比较,一次存取便能得到所查记录,那就必须在记录的存储位置和它的关键字之间建立一个确定的对应关系 f ,使每个关键字和结构中一个唯一的存储位置相对应。
也就是说,只需要通过某个函数 f ,使得 存储位置 = f(关键字) ;这样我们就可以通过查找关键字而不需要比较就可以直接找到所查记录。这就是一种新的存储技术------散列技术。
**散列技术(哈希技术)**是在记录的存储位置和它的关键字之间建立一个确定的对应关系 f ,使得每个关键字 key 对应一个存储位置 f(key) 。查找时,根据这个确定的对应关系找到给定值 key 的映射 f(key) ,若查找集合中存在这个记录,则必定在 f(key) 的位置上。
我们把这种对应关系 f 称为散列函数 ,又称为哈希函数 ;按这个思想,采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表 或哈希表 ;关键字对应的记录存储位置我们称为散列地址或哈希地址。
(二)哈希表查找步骤
1.在存储时,通过哈希函数计算记录的哈希地址,并按此哈希地址存储该记录;
2.当查找记录时,通过同样的哈希函数计算记录的散列地址,按此哈希地址访问该记录。
简单来说,就是在那哪存的,上哪去找;怎么存的,就怎么去找。由于存取用的是同一个哈希函数,因此结果当然也是相同的。
所以说,哈希技术既是一种存储方法,也是一种查找方法。
注意 :与线性表不同的是,哈希技术的记录之间不存在什么逻辑关系,它只与关键字有关联 。因此,散列主要是面向查找的存储结构。
(三)哈希表的优缺点
哈希技术最适合的求解问题是查找与给定值相等的记录。
优点:对于查找来说,简化了比较过程,效率就会大大提高;
缺点:哈希技术不具备很多常规数据结构的能力。比如那种同样的关键字,它能对应很多记录的情况,却不适合用哈希技术;同样哈希表也不适合范围查找。
(四)冲突
对不同的关键字可能得到同一哈希地址,即 key1 != key2 ,而 f(key1) = f(key2) ,这种现象称为冲突 ; key1 和 key2 称为这个哈希函数的同义词。
注意 :冲突只能尽可能地少,而不能完全避免。
因此,在建造哈希表时不仅要设定一个"好"的哈希函数,而且要设定一种处理冲突的方法。
二、哈希函数的构造方法
什么算是好的哈希函数?
(1)计算简单
(2)哈希地址分布均匀
(一)直接定址法
取关键字的某个线性函数值 为哈希地址。即f(key) = a * key + b (a, b为常数)
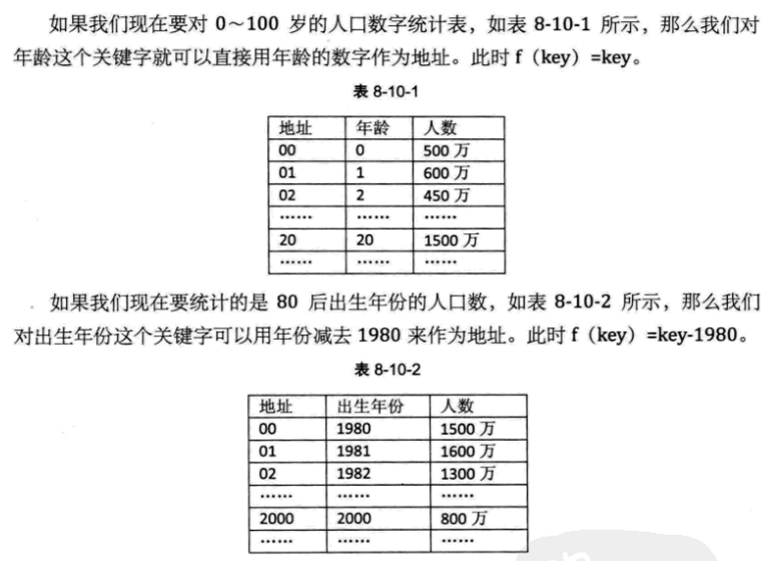
这样的哈希函数优点就是简单、均匀,也不会产生冲突 ,但问题是这需要事先知道关键字的分布情况 ,适合查找表较小且连续的情况。由于这样的限制,在现实应用中,此方法虽然简单,但却并不常用。
(二)数字分析法

抽取 :抽取方法是使用关键字的一部分来计算散列存储位置的方法,这在散列函数中是常常用到的手段。
数字分析法通常适合处理关键字位数比较大 的情况,如果事先知道关键字的分布 且关键字的若干位分布较均匀,就可以考虑用这个方法。
(三)平方取中法
取关键字平方后的中间几位为哈希地址。
这是一种较常用的构造哈希函数的方法。通常在选定哈希函数时不一定能知道关键字的全部情况,取其中哪几位也不一定合适,而一个数平方后的中间几位数和数的每一位都相关,由此使随机分布的关键字得到的哈希地址也是随机的,取的位数由表长决定。
平方取中法比较适合不知道关键字的分布 ,而位数又不是很大的情况。
(四)折叠法
折叠法是将关键字从左到右分割 成位数相等的几部分(注意最后一部分位数不够时可以短些),然后将这几部分叠加求和 ,并按哈希表表长,取后几位作为哈希地址。
折叠法中数位叠加可以有移位叠加 和间界叠加 两种方法。移位叠加是将分割后的每一部分的最低位对齐,然后相加;间界叠加是从一端向另一端沿分割界来回折叠,然后对齐相加。

折叠法事先不需要知道关键字的分布,适合关键字位数较多的情况。
(五)除留余数法
取关键字被某个不大于哈希表表长 m 的数 p 除后所得余数为哈希地址。即对于哈希表长为 m 的哈希函数公式为:f(key) = key mod p (p <= m)。mod 是取模(求余数)的意思。
这是一种最简单 ,也最常用的构造哈希函数的方法。它不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后再取模。
注意:在使用除留余数法时,对 p 的选择很重要。若 p 选的不好,容易产生同义词。

由众人经验得知:若哈希表表长为 m ,可以选 p 为小于或等于表长(最好接近 m)的最小质数 或不包含小于 20 的质因数的合数。
(六)随机数法
选择一个随机函数,取关键字的随机函数值 为它的哈希地址。即 f(key) = random(key) ,其中 random 为随机函数。
通常,当关键字长度不等时,采用此法构造哈希函数较恰当。
1.如果关键字是字符串如何处理?
其实无论时英文字符,还是中文字符,也包括各种各样的符号,它们都可以转化为某种数字来对待,比如 ASCLL 码或者 Unicode 码等,因此也就可以使用上面的这些方法。
2.实际工作中需视不同的情况采用不同的哈希函数。通常,考虑的因素有:
(1)计算哈希函数所需时间(包括硬件指令的因素)
(2)关键字的长度
(3)哈希表的大小
(4)关键字的分布情况
(5)记录的查找频率
三、处理哈希冲突的方法
(一)开放定址法
开放定址法就是一旦发生了冲突 ,就去寻找下一个空的哈希地址,只要哈希表足够大,空的哈希地址总能找到,并将记录存入。
它的公式是:
f(key) 为哈希函数;
m 为哈希表表长;
为增量序列,有下列3种取法:
(1)= 1, 2, 3, ... , m - 1 ;称线性探测再散列


堆积 :不是同义词 的两个关键字却需要争夺同一个地址的现象。
堆积的出现,使得我们需要不断处理冲突,无论是存入还是查找效率都会大大降低。
(2);称二次探测再散列

增加平方运算的目的是为了不让关键字都聚集在某一块区域。
(3) = 伪随机数序列 ;称伪随机探测再散列
伪随机数是说,如果我们设置随机种子相同,则不断调用随机函数可以生成不会重复的数列,我们在查找时,用同样的随机种子,它每次得到的数列时相同的,相同的当然可以得到相同的散列地址。
(二)再散列函数法/再哈希法
均是不同的哈希函数,每当同义词产生地址冲突时,就换一个哈希函数计算,直到冲突不再发生。
这种方法能够使得关键字不易产生聚集 ,但增加了计算的时间。
(三)链地址法
将所有关键字为同义词的记录 存储在同一线性链表 中,我们称这种表为同义词子表 ,在散列表中只存储所有同义词子表的头指针。
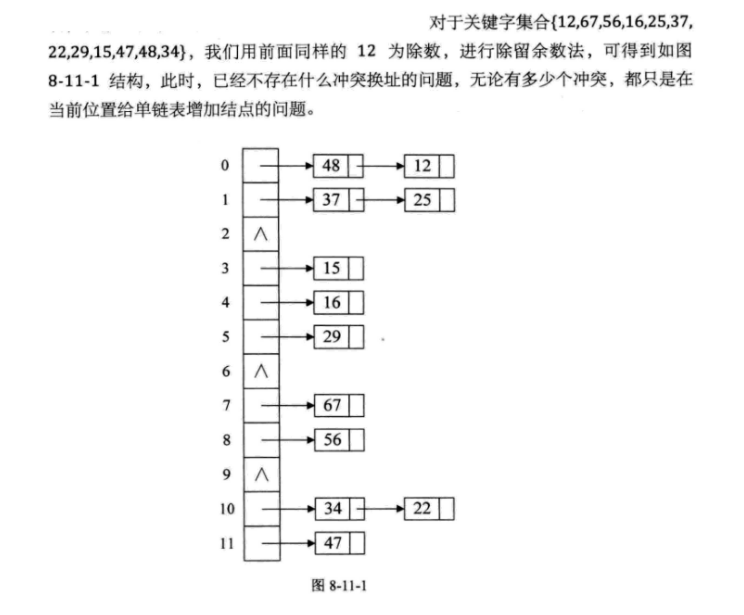
链地址法对于可能会造成很多冲突的哈希函数 来说,提供了绝不会出现找不到地址 的保障。当然,这也就带来了查找时需要遍历单链表的性能损耗。
(四)公共溢出区法
建立一个公共的溢出区 ,用来存放所有冲突的关键字。
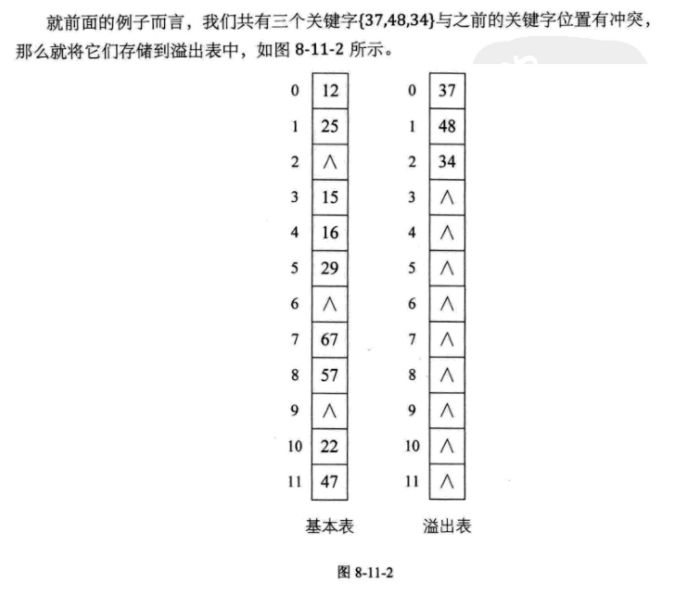
在查找时,对给定值通过哈希函数计算出哈希地址后,先与基本表的相应位置进行对比 ,如果相等 ,则查找成功;如果不相等 ,则到溢出表去进行顺序查找。
如果相对于基本表而言,有冲突的数据很少的情况下,公共溢出区的结构对查找性能来说还是非常高的。
四、哈希表查找算法C语言实现(除留余数法+链地址法)
(一)哈希表的结构体的设计
cpp
#include <assert.h>
#include <stdlib.h>
#include <stdio.h>
#define MAXSIZE 12 //定义哈希表长为数组的长度
//链地址法对应的单链表的有效结点结构体设计
typedef struct LA_Node
{
int data; //数据域
struct LA_Node* next; //指针域
}LA_Node;
//链地址法的表头结构体设计
typedef struct LinkAddress
{
LA_Node LA_arr[MAXSIZE]; //动态数组,存储单链表的头指针
}LinkAddress;(二)计算哈希地址函数
cpp
int Get_HashAddress(int key) {
return key % MAXSIZE; //使用除留余数法
}(三)初始化
cpp
void Init_LA(LinkAddress* pla) {
//0.断言:检查传入的指针是否为空
assert(pla != NULL);
for (int i = 0; i < MAXSIZE; i++) {
//初始状态哈希表为空,无单链表,故数组中每个元素存放的头结点的next域为NULL;数据域浪费掉
pla->LA_arr[i].next = NULL;
}
}(四)查找
cpp
LA_Node* Search_LA(LinkAddress* pla, int key) {
//0.断言:检查传入的指针是否为空
assert(pla != NULL);
//1.计算哈希地址(数组下标)
int index = Get_HashAddress(key);
//2.遍历对应下标链表,查找目标key
for (LA_Node* p = pla->LA_arr[index].next; p != NULL; p = p->next)
{
if (p->data == key) //若找到,则返回结点指针
{
return p;
}
}
return NULL; //若找不到,返回NULL
}(五)插入
cpp
//购买新结点
LA_Node* BuyLANode(int key) {
//1.调用malloc申请一块大小为sizeof(LA_Node)的内存用来存放结点
LA_Node* pnewnode = (LA_Node*)malloc(sizeof(LA_Node));
if (pnewnode == NULL) exit(EXIT_FAILURE); //检查malloc是否成功
//2.结点初始化
pnewnode->data = key; //将key赋值给新结点的数据域
pnewnode->next = NULL; //将新结点的指针域置空,确保它暂时不指向其他结点
return pnewnode; //返回新结点指针
}
//插入
bool Insert_LA(LinkAddress* pla, int key) {
//0.断言:检查传入的指针是否为空
assert(pla != NULL);
//1.先查找:如果key已存在,不重复插入
LA_Node* p = Search_LA(pla, key);
if (p != NULL) return true;
//2.计算key的哈希地址(数组下标)
int index = Get_HashAddress(key);
//3.创建新结点
LA_Node* pnewnode = BuyLANode(key);
//4.头插法:把新结点插入到对应链表的头部
pnewnode->next = pla->LA_arr[index].next;
pla->LA_arr[index].next = pnewnode;
return true;
}(六) 删除
cpp
bool Delete_LA(LinkAddress* pla, int key) {
//0.断言:检查传入的指针是否为空
assert(pla != NULL);
//1.先查找:如果key不存在,无需删除
LA_Node* q = Search_LA(pla, key);
if (q == NULL) return false;
//2.计算key的哈希地址(数组下标)
int index = Get_HashAddress(key);
//3.找到待删除结点q的直接前驱,用指针p指向
LA_Node* p = &pla->LA_arr[index];
for (; p->next != q; p = p->next);
//4.跨越指针(指的是p结点把q结点跨过去)+释放待删除结点的内存
p->next = q->next;
free(q);
q = NULL; //避免野指针
return true;
}(七)打印
cpp
void Show(LinkAddress* pla) {
//0.断言:检查传入的指针是否为空
assert(pla != NULL);
//1.遍历哈希表的每一个桶(数组每一行)
for (int i = 0; i < MAXSIZE; i++)
{
printf("第%d行:", i); //打印当前是第几个链表
//2.遍历第i个链表,跳过头结点
for (LA_Node* p = pla->LA_arr[i].next; p != NULL; p = p->next)
{
printf("%d->", p->data); // 打印节点数据
}
printf("\n"); //一行打印完换行
}
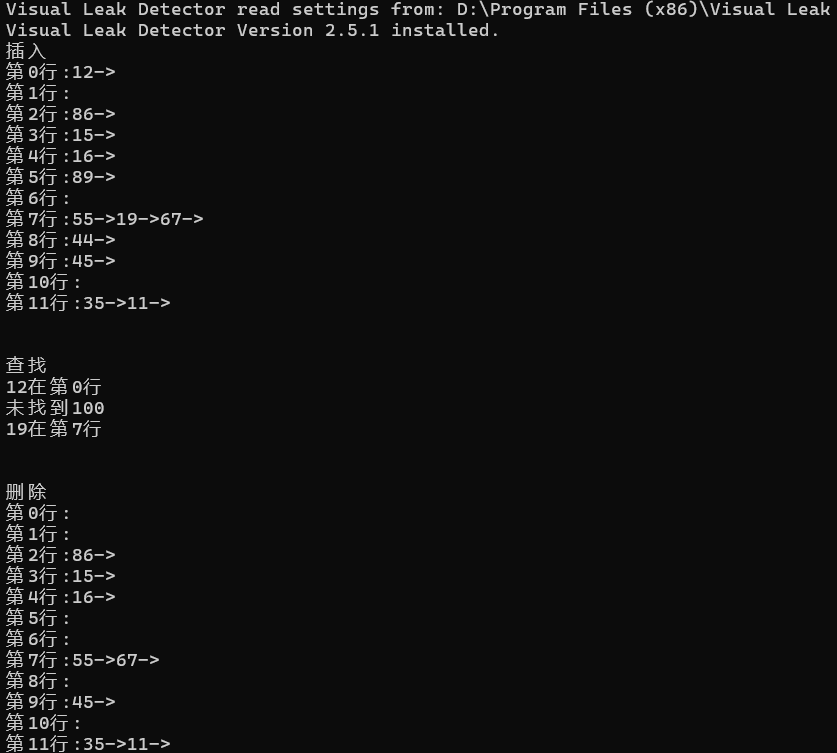
}(八)主函数测试
cpp
int main() {
LinkAddress hash;
//初始化
Init_LA(&hash);
//插入
printf("插入\n");
Insert_LA(&hash, 12);
Insert_LA(&hash, 45);
Insert_LA(&hash, 67);
Insert_LA(&hash, 89);
Insert_LA(&hash, 11);
Insert_LA(&hash, 15);
Insert_LA(&hash, 19);
Insert_LA(&hash, 55);
Insert_LA(&hash, 44);
Insert_LA(&hash, 35);
Insert_LA(&hash, 16);
Insert_LA(&hash, 86);
Insert_LA(&hash, 89);
Show(&hash);
printf("\n\n");
//查找
printf("查找\n");
int val = 12;
if (Search_LA(&hash, val) == NULL) printf("未找到%d\n", val);
else printf("%d在第%d行\n", val, Get_HashAddress(val));
val = 100;
if (Search_LA(&hash, val) == NULL) printf("未找到%d\n", val);
else printf("%d在第%d行\n", val, Get_HashAddress(val));
val = 19;
if (Search_LA(&hash, val) == NULL) printf("未找到%d\n", val);
else printf("%d在第%d行\n", val, Get_HashAddress(val));
printf("\n\n");
//删除
printf("删除\n");
Delete_LA(&hash, 12);
Delete_LA(&hash, 44);
Delete_LA(&hash, 89);
Delete_LA(&hash, 19);
Show(&hash);
}